基于KPCA—RVM的轉子故障診斷
2017-05-11 10:54:27王海瑞張楠
價值工程 2017年15期
關鍵詞:故障診斷
王海瑞+張楠
摘要:針對轉子故障振動信號特點,提出了一種基于核主成分分析及相關向量機(KPCA-RVM)的故障診斷方法。首先對故障信號用核主成分分析的方法進行降維處理以去除冗余信息以提高對數據進行計算處理的速度及正確率。之后使用相關向量機的方法對特征信息進行分類識別,以識別轉子的正常、不對中、不平衡、碰磨以及松動五種不同運行狀態。最后將本文所使用的方法與3種其他常見模型方法進行對比,結果表明本方法在轉子故障識別上具有良好的可行性以及更好的實用性。
Abstract: Base on the characteristics of the rotor fault, a method based on Kernel Principal Component Analysis and Relevant Vector Machine to diagnose rotor fault has been proposed. In this essay, firstly KPCA has been used to reduce the dimension of fault signals to remove redundancy information and improve the accuracy and computation speed, then RVM has been used to diagnose fault state which including normal condition, misalignment, unbalance, friction and looseness, finally, three other methods have been used to comprise with the method which is provided, and indicate the feasibility and practicability of the provided method in rotor fault diagnosis.
關鍵詞:故障診斷;轉子;核主成分分析;相關向量機
Key words: fault diagnosis;rotor;KPCA;RVM
中圖分類號:U226.8+1 文獻標識碼:A 文章編號:1006-4311(2017)15-0154-03
0 引言
轉子是旋轉機械中的核心部件之一,典型的常見轉子故障包括松動、碰磨、不對中以及不平衡等,當這些故障出現時,將對機械設備的正常運行造成很大負面影響甚至可能造成運行事故,因此當故障正在或者即將發生時,及時準確的故障診斷具有十分重要的意義。
通常情況下,轉子故障診斷依靠分析轉子振動信號,這一信號常包含其他信號干擾,并且在故障的發生后可能會對整體機械誘發出新的振動[1]。因此使用主成分分析(Principal Component Analysis)方法對獲取到的信號進行降維運算以獲取更準確數據。但傳統PCA方法很難實現在不同尺度下的非線性特征提取,這對降維結果的精確性造成不少影響,因此本文使用基于核的主成分分析(Kernel Principal Component Analysis)方法對數據特征進行處理。
常見的模式識別分類方法包括人工神經網絡(Artificial Neuro Network,ANN),支持向量機(Support Vector Machine,SVM)等,這些方法在故障診斷中都有大量應用,但同時這些方法也有各自的局限性使其在一定程度上對其在工程上的實際應用帶來不穩定影響。相關向量機(Relevance Vector Machine, RVM)方法與前者相比具有參數易設置、模型結構易于確定等優點,故而本文使用這一方法進行故障分類。
1 特征提取
1.1 PCA方法基本原理
主成分分析(Principal Component analysis,PCA)又名主元分析,被廣泛應用于特征提取、有損數據壓縮、降維及數據可視化中[2]。PCA屬于一種線性的數據降維方法,它可以實現在對一個含有大量相關數據的數據集進行降維處理的同時盡可能多的保持數據內部的差異性,這為后續的分類過程中能得到更準確的分類結果是十分有益的。
在對數據進行處理時,首先需要得到采樣數據組成的矩陣,其中包括個采樣點,如下所示:
2.3 RVM的“二叉樹”分類
由于相關向量機是一種二元分類方法,因而在故障診斷中需要使用多模式分類的方法以實現多分類問題的解決。常見的組合分類方法包括“一對余”(One Against Rest, OAR),“一對一”(One Against One,OAO),“二叉樹”(Binary Tree,BT)法和“有向無環圖”(Direct Acyclic Graph, DAG)法[7]。二叉樹方法是很常用的一種決策樹方法,相比于其他類型的分類器,“二叉樹”分類方法具有構造的RVM二分類器數量少,訓練所需要的樣本數量相對較少,測試時間相對較短的優點[10]。在本文中使用了如圖1所示的多分類器組合結構。
2.4 故障診斷模型
結合轉子故障診斷的實際需求及以上理論基礎,提出了如圖2所示的故障診斷模型。
首先,獲取轉子的振動信號,之后將振動信號中有意義部分的特征進行提取,然后將獲取到的不同運行狀態(正常或故障)的故障信息進行KPCA降維。
在故障類型識別中,首先將經過處理的特征選取適當數量樣本作為訓練樣本,然后使用這些樣本對相關向量機進行訓練,訓練結束后該已被訓練好的相關向量機即可對新得到的數據進行故障辨識,最終得到診斷結果。
3 轉子故障診斷實例
實驗數據來源一小型轉子試驗臺的實驗數據,轉速為3200轉,共包括五種不同的轉子運行狀態,分別為正常、不對中、不平衡、松動以及碰磨。數據為12通道的轉子振動數據,5種運行狀態每種狀態選取了40組樣本,共計200組樣本組成故障樣本集。以K-fold交叉驗證方法為基礎將樣本集二分成訓練集和測試集,如表1所示。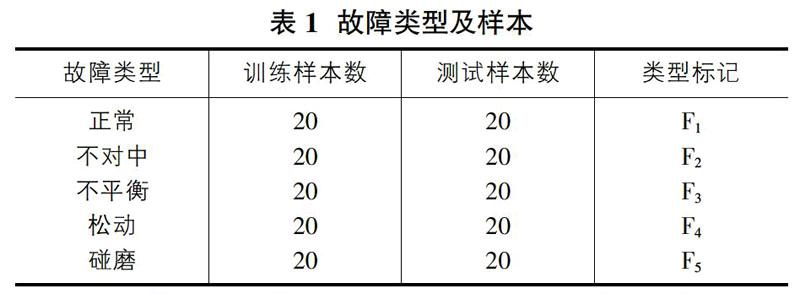
由于樣本數據維度較大,包含一定量的冗余信息,在對這樣的數據樣本進行處理時會耗費大量計算時間,并且實際上冗余信息并不是十分重要,可以經過降維處理去掉這些信息并對后續識別處理幾乎不造成影響,故而使用降維的方法提取主要特征信息。在研究中通過計算,將主元方差累積貢獻率的最小值設為95%,將樣本用KPCA的方法進行降維處理,采用RBF徑向基函數作為核函數,參數降維后的故障數據樣本如表2所示。
使用上面所得到的特征數據對RVM進行訓練,在相關向量機分類器的訓練中同樣適用RBF徑向基函數作為核函數,其中核函數的參數。訓練結束后使用測試樣本進行測試,通過將測試樣本進行測試后的狀態識別率為94%,具體每一類測試結果如表3所示。
總體來看識別的準確率較高,其中錯誤識別可能是由于特征量較為相似而訓練樣本不足所導致。為進一步的驗證本文所使用的故障診斷模型的優越性,將實驗數據和幾種現有常用方法進行了對比測試,測試結果如表4所示。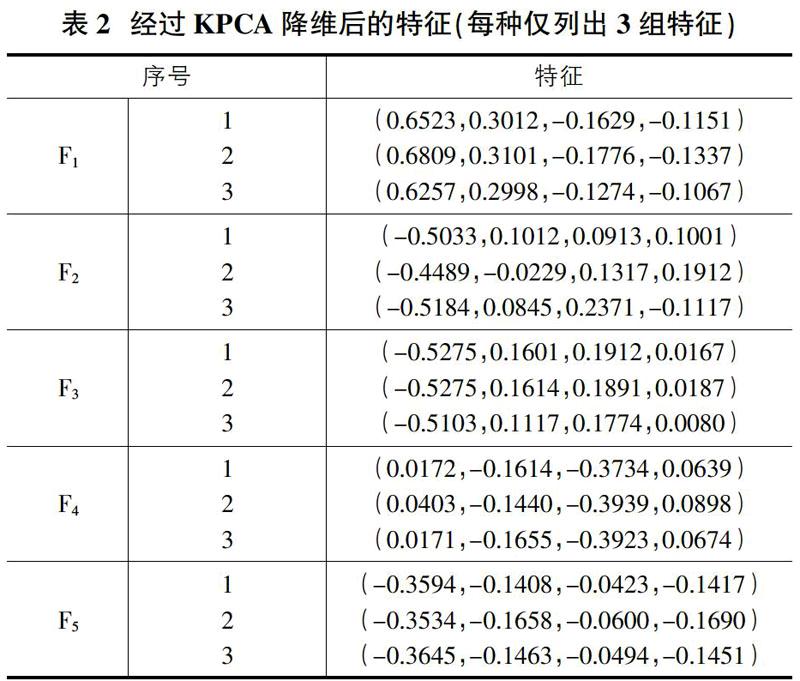
通過對比可以看出相較于其他方法,本文所提出的KPCA-RVM模型識別正確率最高。在特征提取方面,KPCA的耗時比PCA要長,但通過核主成分分析降維后的數據識別正確率會稍高于使用普通主成分分析方法得到的數據的分類結果,說明使用核函數對非線性情況進行處理會提高降維準確度,更有利于對特征量的識別分類。SVM方法與RVM方法相比,RVM的訓練需要消耗更多時間,但在分類時速度較快。總體來說,仍以KPCA-RVM模型為最佳。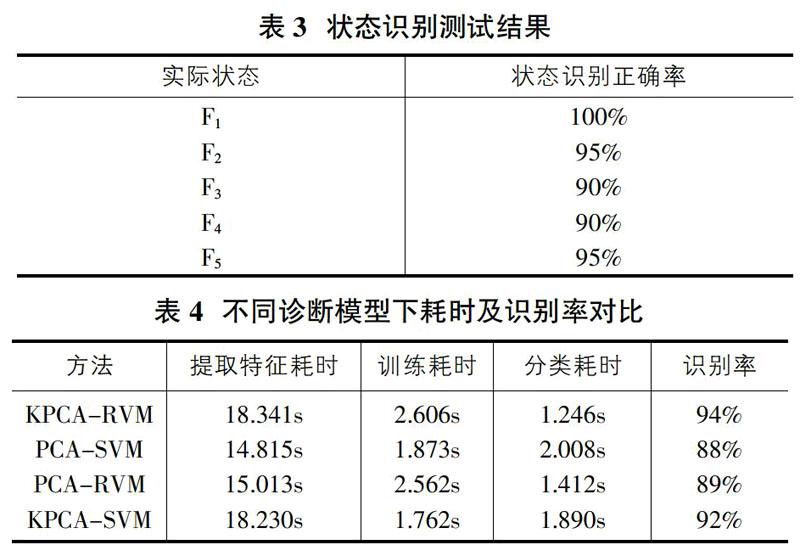
4 結論
本文通過將核主成分分析與相關向量機優點進行結合,提出了一種以核主成分分析方法進行特征提取,后以相關向量機以“二叉樹”法進行多故障分類的轉子故障診斷模型。通過實驗結果可以看出這一方法在轉子故障診斷問題上切實可行并具有較高的識別正確率,通過與PCA方法和SVM方法的對比得出本文所提出模型較之常見方法的優異性所在。實驗結果表明本文所涉及模型具有識別率高,分類時間較短的優點。
參考文獻:
[1]李舜酩.轉子振動故障信號的盲分離[J].航空動力學報,2005,20(5):751-756.
[2]Bishop. C. M (2006). Pattern Recognition and Machine learning.577.
[3]Vapnik. V. N (2000). 統計學習理論的本質[M].清華大學出版社,2000:1-5.
[4]陽同光,桂衛華.基于KPCA與RVM感應電機故障研究[J].電機與控制學報,2016,20(9):89-95.
[5]李偉紅,龔衛國,陳偉民,梁毅雄,尹克重.基于小波分析與KPCA的人臉識別方法[J].計算機應用,2005,25(10):2339-2341.
[6]Tipping. M. E (2001), Sparse Bayesian Learning and the Relevance Vector Machine[J]. Journal of Machine Learning Research, 2001(1):211-244.
[7]柳長源.相關向量機多分類算法的研究與應用[D].哈爾濱工程大學,2013.
[8]張維強,趙榮珍,李坤杰.基于MSKPCA和SVM的轉子故障診斷模型及應用[J].機械設計與制造,2015,10(10):4-8.
[9]馬登武,范庚,張繼軍.相關向量機及其在故障診斷與預測中的作用[J].海軍航空工程學院學報,2013,28(2):154-160.
[10]王冉,陳進.支持向量機決策樹分類器在轉子故障診斷中的應用[J].振動與沖擊,2010,29:258-260.
猜你喜歡
一重技術(2021年5期)2022-01-18 05:42:10
水泵技術(2021年3期)2021-08-14 02:09:20
裝備制造技術(2020年3期)2020-12-25 05:22:30
制造技術與機床(2018年11期)2018-11-23 01:07:42
電子制作(2018年10期)2018-08-04 03:24:46
制造技術與機床(2017年10期)2017-11-28 05:20:43
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
振動工程學報(2014年2期)2014-03-01 01:15:22
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
振動、測試與診斷(2014年4期)2014-03-01 01:14:00
