App軟件用戶評論與評分星級一致性判斷方法*
2017-04-24 02:37:27向祺鑫丁家滿汪海濤
計算機與數字工程 2017年4期
冉 猛 姜 瑛 向祺鑫 丁家滿 汪海濤
(1.云南省計算機技術應用重點實驗室 昆明 650500)(2.昆明理工大學信息工程與自動化學院 昆明 650500)
App軟件用戶評論與評分星級一致性判斷方法*
冉 猛1,2姜 瑛1,2向祺鑫1,2丁家滿1,2汪海濤1,2
(1.云南省計算機技術應用重點實驗室 昆明 650500)(2.昆明理工大學信息工程與自動化學院 昆明 650500)
由于網絡評論的自由性和隨意性,App軟件用戶評論與評分星級的不一致給用戶選擇App軟件帶來了困難。提出綜合分析用戶評論和評分星級二者間的關系,首先通過分析App軟件特征情感詞對的語法關系,結合詞典和網絡情感詞,量化用戶對App軟件的情感傾向程度;再計算每條評論中用戶對App軟件的綜合評分,并與評分星級進行比較以判斷用戶評論與評分星級是否一致;最后通過實驗驗證了方法的有效性。
App軟件; 用戶評論; 評分星級; 一致性; 特征情感詞對; 網絡情感詞
1 引言
隨著移動智能終端的風靡,以Android系統和iOS系統為代表的App軟件用戶快速增加。大多數用戶在選擇App軟件之前會查看用戶評論和評分星級。然而,由于網絡評論的自由性,用戶評論的情感傾向程度與評分星級常常會出現不一致的情況。這給用戶選擇App軟件帶來了困難,因此判斷App軟件的用戶評論與評分星級是否一致成為需要解決的問題。
用戶評論分析在商品領域日趨成熟,而App軟件作為一種新型體驗型產品,有如下特點:1)App軟件開發周期短,開發者可以通過用戶評論了解用戶需求,從而有針對性地制定開發策略[1],以提高App軟件的質量;2)用戶在選擇App軟件前無法通過廣告或品牌獲得該軟件的質量[2]。目前,用戶評論分析在App軟件領域取得了一系列的研究成果。Gao等[3]通過從不同的App軟件用戶評論中提取主題評論,構建主題動態更新模型。AlQuwayfili等[4]將App軟件評論分為可信和不可信兩類評論。上述研究主要是針對用戶評論的主題和可信度等對用戶選擇App軟件有影響,但是缺少對用戶評論和評分星級二者進行綜合分析研究。Guzman等[5]基于貪婪聚類算法來挖掘用戶評論信息中用戶對App軟件所持的正反態度。Harman等[6]采用實體映射和極性挖掘的方法,來判斷用戶評論對App軟件的正反態度。上述文獻將用戶評論的傾向劃分成正反兩個等級,但是忽略了用戶評論與評分星級是否一致給用戶選擇App軟件帶來影響。
因此,本文首先提取App軟件用戶評論中的特征情感詞對;然后分析App軟件特征情感詞對的語法關系,并計算用戶對App軟件的情感傾向的綜合評分;最后將綜合評分劃分為五個等級,以判斷App軟件用戶評論與評分星級是否一致。
2 一致性判斷方法
2.1 提取App軟件特征情感詞對
目前,大多數研究通過提取用戶評論中的特征詞和情感詞來獲得用戶對產品特征進行的描述。本文通過對海量的用戶評論數據進行分析后發現,用戶在對App軟件的評論中特征詞、情感詞和副詞具有對應關系。例如,用戶對“微信”App軟件評論:“下載很麻煩”,其中用情感詞“麻煩”修飾特征詞“下載”,用副詞“很”修飾情感詞“麻煩”。因此,本文稱為App軟件特征情感詞對,并對其做如下定義。
定義1:App軟件特征情感詞對f=(Wh,Wd,Wa)。其中,Wh代表用戶評論中用戶關注的App軟件特征;Wa為情感詞;Wd為副詞。
為了對用戶評論與評分星級一致性進行更好的判斷,本文在文獻[7]同時提取特征詞、情感詞的基礎上對特征詞、副詞、情感詞進行同時提取,即提取App軟件特征情感詞對f。此外,一條用戶評論可能會涉及到多個f,其中每個f中的特征是不同的,且用戶所表達的情感傾向程度也不相同。因此,本文對App軟件特征情感詞對集做如下定義。
定義2:App軟件特征情感詞對集F={f1,f2,…,fn},其中,fi為App軟件特征情感詞對,i=1,2,…,n。
2.2 計算情感傾向程度綜合評分
目前用戶的情感傾向分析主要通過基于詞典[8]和句法分析[9],然后結合挖掘算法進行判斷。在App軟件用戶評論中,網絡情感詞、副詞的強度差異以及副詞和否定詞共現語序引起語義差異都會影響用戶的情感傾向程度。因此,本文從情感詞的極性詞出發,基于f中Wh、Wd、Wa三者的語法關系,結合《知網》情感詞語料詞典和網絡情感詞,對情感傾向程度進行逐級量化計算,最后再計算每條評論的綜合評分。
2.2.1 網絡情感詞的處理
App軟件用戶評論是一種典型的網絡評論,大多數用戶往往會使用網絡情感詞來表達對App軟件的情感傾向。例如“這就是個SB軟件”中的“SB”是名詞,對當前App軟件表達出強烈的反面情感。目前,《知網》詞典不能識別這類詞,但這些詞語又能表達用戶對App軟件的情感傾向。因此,本文建立了網絡情感詞語庫,收集了諸如“SB”等App軟件用戶評論中出現的高頻度網絡情感詞共計137個,并對這部分情感詞進行權重極性的定義,計算公式如下:
F(nr)=F(nd)*F(na)
(1)
式中,F(nr)表示用戶評論中某個特征的情感傾向程度得分,F(nd)為副詞的極性參數,F(na)表示網絡情感詞的原極性。
2.2.2 副詞及副詞和否定詞共現情況的處理
由于App軟件用戶評論中的副詞和否定詞對情感傾向程度量化結果有著很重要的影響,因此,本文對副詞和否定詞進行處理。現有研究中發現,副詞存在不同的強度等級,文獻[10]基于《知網》詞典的程度語料庫,將副詞分為6種類別,其中“最”和“超”兩類的極性參數都是“1.6”,因此,本文將這兩類進行合并為“最”類,結果如表1所示。

表1 副詞分類及極性參數表
對于否定詞的處理,姚天昉等[8]對否定前綴的極性處理方法是先取反,再除以2,按照該算法,“不很滿意”和“很不滿意”的情感傾向程度是一樣的。然而,這并沒有考慮否定詞和副詞共現時語序不同所引起的語義差異。因此,本文先根據文獻[10]將否定詞的極性參數設為-0.5,再將否定詞和副詞共現的情況分為兩種,對情感傾向程度進行分別計算。
1) 副詞在否定詞之前,否定程度是逐漸遞增的,例如“畫面很不好”。因此,本文計算情感傾向程度量化的公式如下:
F(DNP)=-0.5*F(d)*F(a)
(2)
式中,F(DNP)表示副詞在否定詞之前的情感傾向程度得分,-0.5為否定詞的極性參數,F(d)為副詞的極性參數,F(a)為情感詞的原極性。
2) 否定詞在副詞之前,這種情況是把原來的程度降低,例如:“畫面不很好”和“畫面相對好”,這兩句表達的情感傾向程度大體相同,在語義上是能夠相互推衍的[11]。因此,本文將這種情況的否定詞極性參數設置為表1中“欠”類的極性參數,計算公式如下:
F(NDP)=0.6*F(d)*F(a)
(3)
式中,F(NDP)表示否定詞在副詞之前的情感傾向程度得分,0.6為否定詞極性參數。
2.2.3 量化情感傾向程
由于用戶對App軟件特征評論的情感傾向程度由副詞、否定詞、情感詞共同決定,因此,接下來將計算App軟件用戶評論信息中情感傾向程度的量化結果,計算公式如下:
F(or)=F(oa)*F(od)*F(on)
(4)
式中,F(oa)為情感詞的原極性,F(od)為副詞的極性參數,F(on)為否定詞的極性參數。當副詞或否定詞為空時,極性參數設為1;當副詞和否定詞共現時,則根據式(2)和式(3)進行計算。
2.2.4 計算綜合評分
用戶對App軟件的情感傾向程度由F中的綜合評分來決定。然而,F中每個f中用戶所表達的情感傾向程度是有差異的。因此,為了對用戶評論與評分星級進行更準確的一致性判斷,需要對F中多個f的情感傾向程度進行綜合量化計算。情感傾向程度的綜合評分計算公式如下:
(5)
式中,F(ri)表示用戶評論中對第i個特征評論的情感傾向程度得分,F(ri)包含F(nr)、F(or)等情況,n表示F中f的個數。計算情感傾向程度綜合評分流程圖如圖1所示。
2.3 劃分綜合評分等級
通過2.2節中分析,可以計算出F(O)的取值范圍是[-1.6,+1.6],因為從表1中可以看出極性參數的最大值是1.6,正面、反面情感詞的極性分別為+1、-1,且本文中的否定副詞極性參數為-0.5。所以5星中最大取值為1.6*1=1.6;4星的最大取值為1,最小值為-1*(-0.5)=0.5,即5星的取值區間為(1,1.6],4星的取值區間為[0.5,1]。綜合評分等級劃分區間如表2所示。
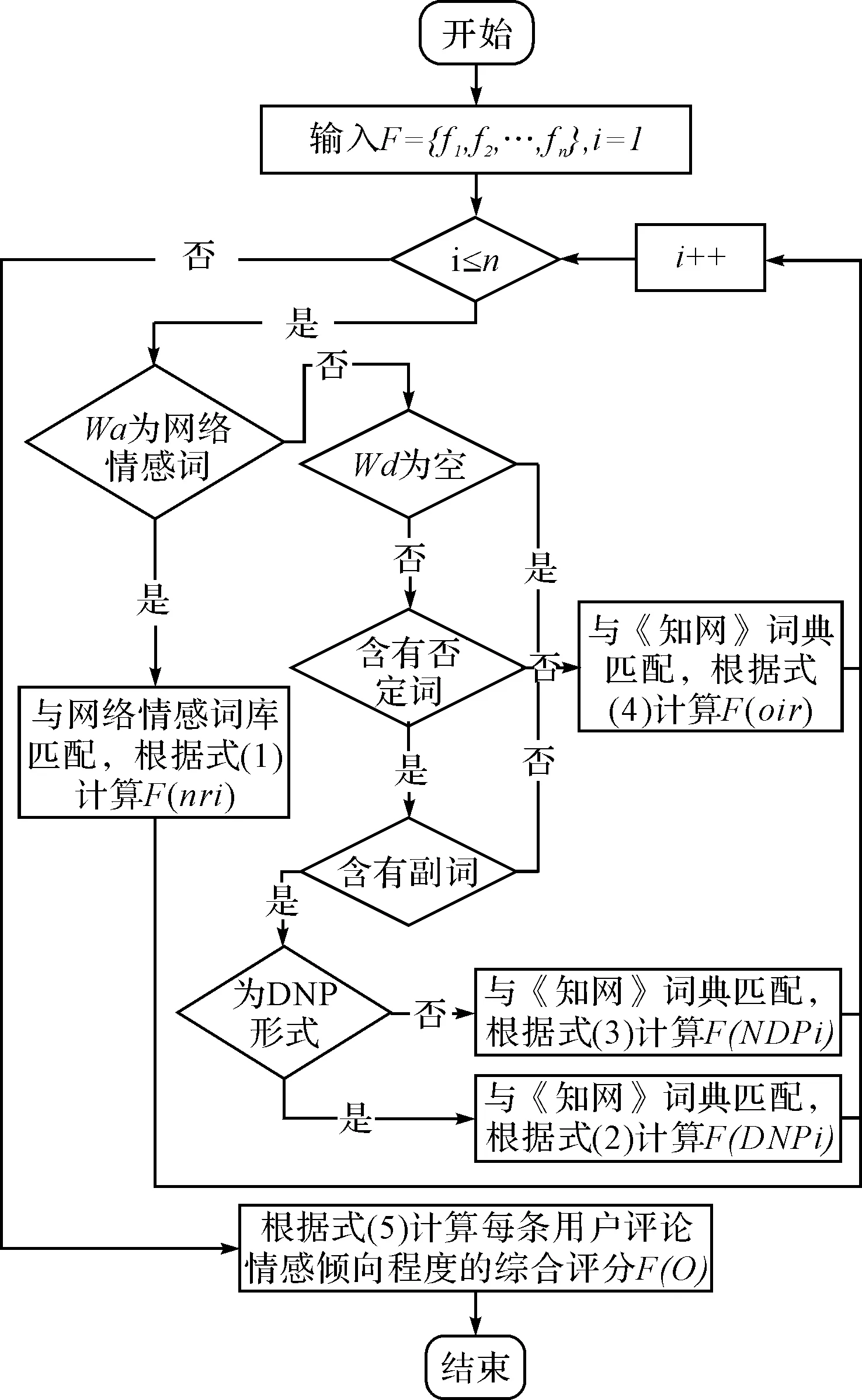
圖1 計算情感傾向程度綜合評分流程圖
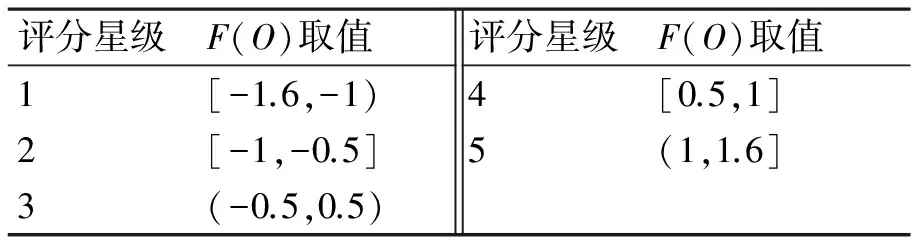
表2 綜合評分等級劃分表
3 實驗結果及分析
3.1 數據來源及處理
為了驗證本文方法的有效性,從安卓電子市場隨機抓取了7大類29個App軟件的21371條用戶評論信息,并據此建立了App軟件用戶評論庫,部分信息如表3所示。

表3 App軟件用戶評論(部分)
由表3可以看出,雖然有的用戶給App軟件打的評分星級很高,但是用戶評論中表達出來的情感傾向卻是負面態度。因此,用戶評論與評分星級確實存在不一致的情況。本文使用ICTCLAS 2016作為數據預處理的工具,并提取了App軟件特征情感詞對,部分數據處理結果如表4所示。

表4 數據處理結果(部分)
3.2 實驗結果及分析
針對以上實驗數據,運用本文方法對App軟件用戶評論與評分星級進行了一致性判斷。為了判斷方法的有效性,本文邀請了一些App軟件用戶對用戶評論與評分星級的一致性進行了人工標注。部分判斷結果如表5所示。
由實驗可以得出,用戶評論與評分星級一致的評論平均僅有39.25%,各類App軟件的判斷結果如圖2所示。其中,“社交”類僅有30.82%。可見,當前的App軟件用戶評論中,大部分用戶評論與評分星級是不一致的。

表5 一致性判斷結果(部分)
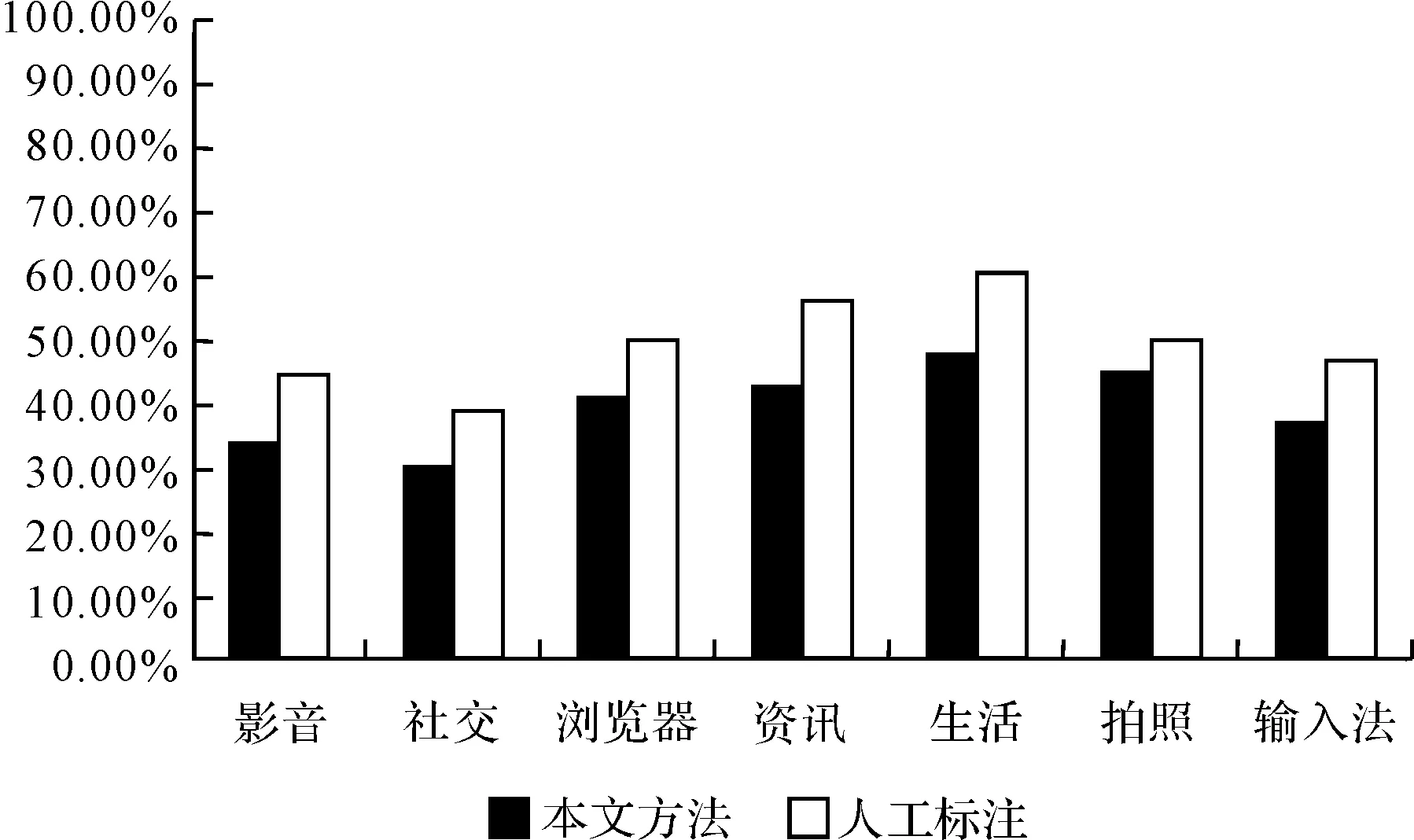
圖2 App軟件用戶評論與評分星級一致性結果
通過與人工標注進行比較,本文方法判斷結果的準確率平均為79.07%,相關結果如表6所示。
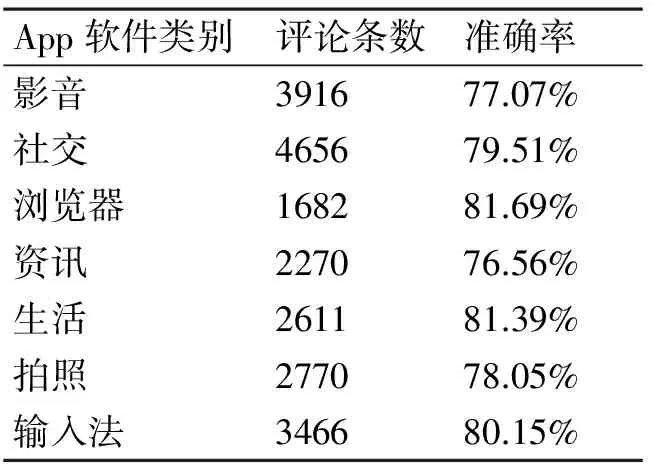
表6 本文方法判斷結果的準確率
由表6可以看出,“資訊”類的用戶評論準確率最低,為76.56%,該類一致性判斷結果如圖3所示,這類App軟件評分星級中2星和1星的準確率偏低,僅有57.14%和59.80%,這種現象在7類App軟件中均存在。
通過分析,主要由兩類原因導致:一是用戶如果對App軟件不滿意,就會在發表評論時說一些罵人的錯別字,在進行分詞和情感傾向程度量化時,分詞工具和算法均不能識別這些錯別字,從而影響了判斷結果的準確率;二是目前收集的網絡情感詞不夠全面,導致在量化情感傾向程度時不夠準確,從而影響了用戶評論與評分星級一致性的準確性。
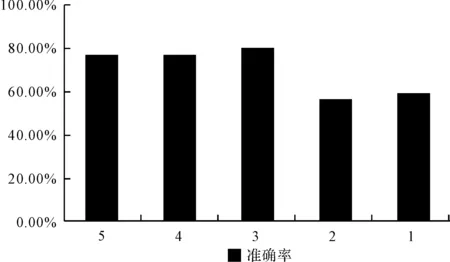
圖3 “資訊”類用戶評論與評分星級一致性判斷結果的準確率
4 結語
本文提出了用戶評論的一致性判斷方法。該方法通過分析App軟件特征情感詞對的語法關系,結合詞典和網絡情感詞,量化用戶對App軟件的情感傾向程度,以計算每條評論中用戶對App軟件的綜合評分,并與用戶評分星級中的五個等級進行比較,從而判斷用戶評論與評分星級是否一致。實驗證明了該方法的有效性,為了進一步提高方法的準確性,下一步將在App軟件特征情感詞對提取、網絡情感詞的收集等方面進行深入研究。
[1] Lin Hao, Li X, Tan Y, et al. The economic role of rating behavior in third-party application market[C]//International Conference on Information Systems,2011:26.
[2] 劉洋,廖貅武,劉瑩.在線評論對應用軟件及平臺定價策略的影響[J].系統工程學報,2014,29(4):560-570.
LIU Yang, LIAO Xiuwu, LIU Ying. The impact of online comment on software and platform’s pricing strategies[J]. Journal of Systems Engineering,2014,29(4):560-570.
[3] Gao C, Xu H, Hu J, et al. AR-Tracker: Track the Dynamics of Mobile Apps via User Review Mining[C]//Service-Oriented System Engineering(SOSE), 2015 IEEE Symposium on. IEEE,2015:284-290.
[4] AlQuwayfili N, AlRomi N, AlZakari N, et al. Towards classifying applications in mobile phone markets: The case of religious apps[C]//Current Trends in Information Technology(CTIT), 2013 International Conference on. IEEE,2013:177-180.
[5] Guzman E, Maalej W. How do users like this feature? a fine grained sentiment analysis of app reviews[C]//Requirements Engineering Conference(RE), 2014 IEEE 22nd International. IEEE,2014:153-162.
[6] Harman M, Jia Y, Zhang Y. App store mining and analysis: MSR for app stores[C]//Proceedings of the 9th IEEE Working Conference on Mining Software Repositories. IEEE Press,2012:108-111.
[7] 扈中凱,鄭小林,吳亞峰,等.基于用戶評論挖掘的產品推薦算法[J].浙江大學學報:工學版,2013,47(8):1475-1485. HU Zhongkai, ZHENG Xiaolin, WU Yafeng, et al. Product recommendation algorithm based on users’ comments mining[J]. Journal of Zhejiang University(Engineering Science),2013,47(8):1475-1485.
[8] 姚天昉,婁德成.漢語語句主題語義傾向分析方法的研究[J].中文信息學報,2007,21(5):73-79. YAO Tianfang, LOU Decheng. Research on semantic orientation analysis for topics in Chinese sentences[J]. Journal of Chinese Information Procession,2007,21(5):73-79.
[9] 馮時,付永陳,陽鋒,等.基于依存句法的博文情感傾向分析研究[J].計算機研究與發展,2012,49(11):2395-2406. FENG Shi, FU Yongchen, YANG Fen, et al. Blog Sentiment Orientation Analysis Based on Dependency Parsing[J]. Journal of Computer Research and Development,2012,49(11):2395-2406.
[10] 林欽和.基于情感計算的商品評價分析系統設計與實現[D].上海:復旦大學,2013. LIN Qinhe. Design and Implementation of the Product Comments Analysis System Based on Affective Computing[D]. Shanghai: Fudan University,2013.
[11] 尹洪波.否定詞與副詞共現的句法語義研究[D].北京:中國社會科學院研究生院,2008. YIN Hongbo. Research on Syntax and Semantics for Co-occurring of Negatives and Adverbs[D]. Beijing: Graduate School of Chinese Academy of Social Sciences,2008.
Consistency Judgment Method Between User’s Comment and User’s Mark for App Software
RAN Meng1,2JIANG Ying1,2XIANG Qixin1,2DING Jiaman1,2WANG Haitao1,2
(1. Yunnan Key Lab of Computer Technology Application, Kunming 650500)(2. Faculty of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650500)
Due to the freedom and randomness of the network comments, the inconsistence between the user’s comment and user’s mark of App software makes it difficult to choose App software. This paper presents a method by analyzing the relationships among user’s comment and user’s mark. Firstly, through analyzing the grammar relationships in App software’s feature-sentiment-word-pairs, the user’s emotional tendency about App software is quantified combining with the dictionary and the network sentiment words. After calculating the user’s comprehensive score of App software, the consistency of App software user’s comment is judged by comparing this score and the user’s mark. Finally, experimental results show that the method is effective.
App software, user’s comment, user’s mark, consistency, feature-sentiment-word-pairs, network sentiment word Class Number TP311
2016年10月3日,
2016年11月26日
國家自然科學基金(編號:60703116,61063006,61462049);云南省應用基礎研究計劃項目(編號:2013FZ020)資助。
冉猛,男,碩士研究生,研究方向:軟件工程、大數據分析。姜瑛,女,博士,教授,研究方向:軟件工程、大數據分析等。向祺鑫,男,碩士研究生,研究方向:軟件工程、軟件質量保證與測試。丁家滿,男,碩士,副教授,研究方向:軟件工程、云計算。汪海濤,女,碩士,高級工程師,研究方向:軟件工程。
TP311
10.3969/j.issn.1672-9722.2017.04.021
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
