基于OpenCL的FFT算法研究
2017-04-14 00:47:21彭先蓉左顥睿
計(jì)算機(jī)應(yīng)用與軟件 2017年3期
關(guān)鍵詞:實(shí)驗(yàn)
賈 格 彭先蓉 左顥睿
1(中國科學(xué)院光電技術(shù)研究所 四川 成都 610209)2(中國科學(xué)院大學(xué) 北京 100039)
基于OpenCL的FFT算法研究
賈 格1,2彭先蓉1左顥睿1
1(中國科學(xué)院光電技術(shù)研究所 四川 成都 610209)2(中國科學(xué)院大學(xué) 北京 100039)
快速福利葉變換在圖像處理領(lǐng)域,尤其是在圖像復(fù)原算法中作為常用的計(jì)算工具,將時(shí)域計(jì)算轉(zhuǎn)變?yōu)轭l域計(jì)算,在工程應(yīng)用中有著非常重要的意義。采取多線程分塊以及并行的映射方法,可以使FFT算法最大程度并行。針對(duì)OpenCL的存儲(chǔ)層次特點(diǎn)和算法層次的優(yōu)化,在AMD GPU平臺(tái)上取得了明顯的加速效果。優(yōu)化后的算法性能比具有相同處理能力的CPU平臺(tái)提高了7倍,比具有相同處理能力的CUDA提高了4倍。
傅里葉變換 OpenCL GPU 并行加速
0 引 言
隨著GPU通用計(jì)算的高速發(fā)展,大量的算法被成功移植到GPU平臺(tái),并且取得了良好的加速效果。而且GPU的應(yīng)用研究也越來越廣泛,通用計(jì)算適用領(lǐng)域也越來越大。但是已有的研究一般只限于單一的平臺(tái),而OpenCL(開放式計(jì)算語言)是面向異構(gòu)計(jì)算平臺(tái)的通用編程框架[2,3,6],為GPU通用計(jì)算的跨平臺(tái)移植提供了新的解決方案。由于GPU硬件結(jié)構(gòu)體系本身的差異,造成了GPU硬件平臺(tái)高效移植有很大難度,所以高效的移植不僅僅是功能的移植,高效的移植也就成為當(dāng)前可待研究的問題。
1 OpenCL簡(jiǎn)介
OpenCL平臺(tái)模型定義了使用OpenCL設(shè)備的一個(gè)高層描述[1]。這個(gè)模型如圖1所示,OpenCL平臺(tái)通常包含一個(gè)宿主機(jī)(host)和多個(gè)OpenCl設(shè)備。宿主機(jī)同OpenCl設(shè)備程序外部的交互,主要包括程序和I/O的交互。宿主機(jī)與一個(gè)或多個(gè)OpenCL設(shè)備連接,設(shè)備就是執(zhí)行指令流(或kernel函數(shù))的地方,通常OpenCL設(shè)備被稱為計(jì)算設(shè)備。設(shè)備可以是GPU、CPU、DSP或者其他類型的處理器。圖2所示為OpenCl的抽象模型。OpenCL應(yīng)用執(zhí)行模型中使用主機(jī)端程序?qū)Χ鄠€(gè)支持OpenCL的計(jì)算設(shè)備進(jìn)行統(tǒng)一的調(diào)度和管理。圖2中分別包括兩個(gè)OpenCl設(shè)備,一個(gè)為CPU作為宿主機(jī),一個(gè)GPU作為執(zhí)行設(shè)備。然后定義了兩個(gè)命令隊(duì)列,一個(gè)是面向CPU的亂序命令隊(duì)列,在宿主機(jī)上執(zhí)行,另一個(gè)為面向GPU的有序命令隊(duì)列,在OpenCl設(shè)備上執(zhí)行。然后宿主機(jī)程序定義了一個(gè)程序?qū)ο螅瑢⑦@個(gè)程序?qū)ο蠓謩e編譯后給兩個(gè)OpenCL設(shè)備提供內(nèi)核。接下來宿主機(jī)端定義程序所需的內(nèi)核對(duì)象,并將他們分別映射到內(nèi)核參數(shù)中。在OpenCL的內(nèi)存模型中,通常根據(jù)線程訪問權(quán)限的不同定義以下四種內(nèi)存空間:分別為全局內(nèi)存、局部內(nèi)存、常量內(nèi)存、和私有內(nèi)存,它們?cè)诔绦蛑械氖褂梅绞胶艽蟪潭壬蠜Q定了程序的性能,一般來講,它們的大小和訪問速度都是不同的。
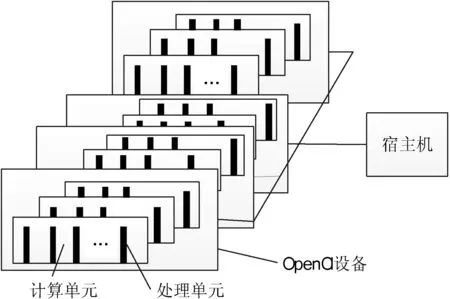
圖1 OpenCl平臺(tái)模型
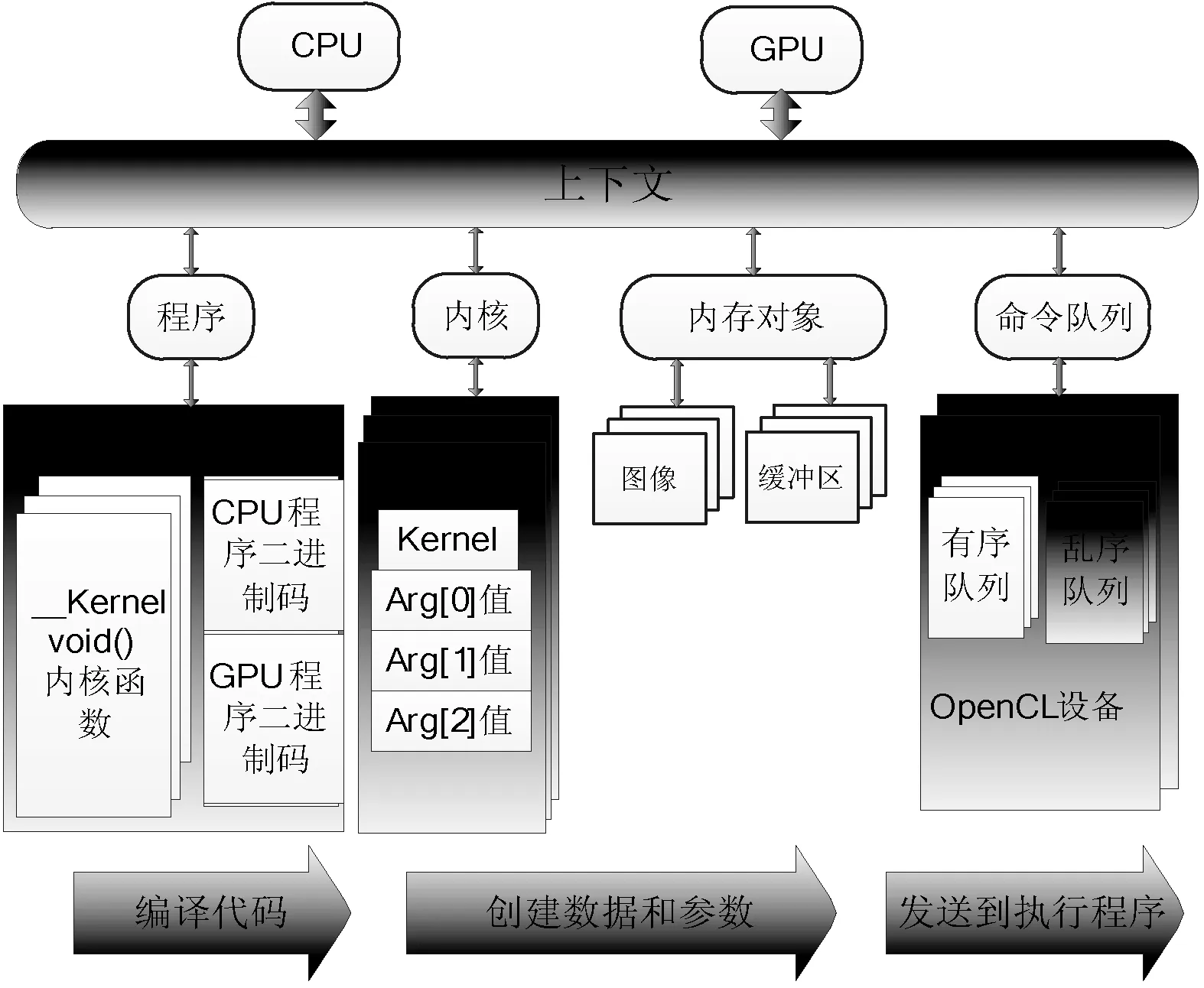
圖2 OpenCl應(yīng)用執(zhí)行模型
2 FFT簡(jiǎn)介
快速傅里葉變換FFT是離散傅利葉變換DFT的快速算法[7,9],具有廣泛的應(yīng)用研究和工程價(jià)值,常被應(yīng)用于數(shù)字濾波和信號(hào)分解中。二維快速傅里葉變換(2D-FFT)是圖像處理領(lǐng)域,尤其是在圖像復(fù)原算法中作為常用的頻域計(jì)算工具,在工程應(yīng)用中有著非常重要的意義,典型的有圖像頻譜分析、卷積計(jì)算等。通常來說,在實(shí)際工程中會(huì)遇到高分辨率的圖像,但是對(duì)于這種圖像的二維傅里葉變換計(jì)算量非常大并且數(shù)據(jù)動(dòng)態(tài)范圍寬,硬件設(shè)計(jì)實(shí)現(xiàn)難度大,一定程度上制約了其在工程中的應(yīng)用。通常的做法是利用二維傅里葉變換的數(shù)據(jù)可分性,圖像的二維FFT可分為兩次的一維FFT實(shí)現(xiàn),分別是行方向和列方向。對(duì)于二維FFT的高速實(shí)現(xiàn)平臺(tái),一般以高性能DSP、FPGA、通用GPGPU芯片為核心器件的三種常用平臺(tái),并在系統(tǒng)設(shè)計(jì)中采用多核計(jì)算,多級(jí)流水線以及乒乓緩存等常用并行處理技術(shù)。本文利用二維傅里葉變換的共軛對(duì)稱性,實(shí)信號(hào)變換周期對(duì)稱性等特性減少存儲(chǔ)資源和計(jì)算量,并通過OpenCL工具在GPU平臺(tái)對(duì)算法加速。
3 FFT算法原理及其改進(jìn)
3.1 利用周期對(duì)稱性減少FFT算法冗余計(jì)算
對(duì)于實(shí)信號(hào)的FFT,通常利用傅里葉變換的對(duì)稱性,可以將N點(diǎn)的實(shí)序列實(shí)現(xiàn)奇偶分離,變成一個(gè)N/2點(diǎn)的復(fù)數(shù)序列,將計(jì)算N點(diǎn)的實(shí)序列FFT變?yōu)橐粋€(gè)N/2點(diǎn)的復(fù)數(shù)序列FFT,然后利用對(duì)應(yīng)關(guān)系將N/2點(diǎn)的復(fù)數(shù)序列FFT輸出對(duì)應(yīng)到N點(diǎn)的實(shí)數(shù)序列結(jié)果輸出。這樣做將實(shí)信號(hào)FFT的計(jì)算量減少近一半。下面介紹它的基本原理:對(duì)于一個(gè)N點(diǎn)的實(shí)序列x(n),我們根據(jù)奇偶序號(hào),分別抽取奇數(shù)序列g(shù)(n)和偶數(shù)序列h(n),分別將它們的離散傅里葉變換分別記為G(k)和H(k)。由FFT時(shí)間抽取基2算法得到如下關(guān)系式。
(1)
(2)
令y(n)=g(n)+j·h(n),則y(n)為N/2點(diǎn)的復(fù)序列。y(n)的離散傅里葉變換Y(k)為:
(3)
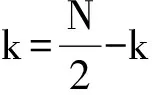
(4)

(5)
將復(fù)序列Y(k)、G(k)、H(k)的實(shí)虛部分開,分別記為Yr(k)、Gr(k)、Hr(k)和Yi(k)、Gi(k)、Hi(k),代入式(5),則有:
(6)
(7)
同理可以得到:
(8)
(9)
從上面兩個(gè)式子可以看出,只需要得出構(gòu)造的N/2點(diǎn)復(fù)序列y(n)的傅里葉變換結(jié)果Y(k),然后利用上述四個(gè)關(guān)系式就可以得到g(n)和h(n)的結(jié)果G(k)和H(k);然后再代入式(1)和式(2),就可以得到N點(diǎn)實(shí)序列x(n)的傅里葉變換結(jié)果X(k)。實(shí)驗(yàn)中采取此種方法,可以將實(shí)信號(hào)FFT的計(jì)算量減少近一半,特別是針對(duì)于較高分別率的圖像的時(shí)候,在N值取值比較大,節(jié)約的計(jì)算量對(duì)于運(yùn)算速度的提升非常明顯。
3.2 算法復(fù)雜度分析
如圖3上半部分表示常規(guī)的2D-FFT運(yùn)算,經(jīng)過行變換后,再經(jīng)過列變換,即輸出結(jié)果;下半部分表示本文改進(jìn)后的算法運(yùn)算模塊,多了數(shù)據(jù)預(yù)處理模塊和數(shù)據(jù)恢復(fù)模塊。其中,數(shù)據(jù)預(yù)處理:將輸入分辨率為M×N的圖像f(x,y),對(duì)于各行數(shù)據(jù)按奇偶序號(hào)分離;然后將每行的奇、偶序列組成N/2點(diǎn)的復(fù)數(shù)數(shù)據(jù)fc(x,y)。數(shù)據(jù)恢復(fù):對(duì)于N/2點(diǎn)的復(fù)數(shù)中間數(shù)據(jù)結(jié)果Fc(u,v),根據(jù)式(6)-式(9)即可以得到F(u,v)的數(shù)據(jù)結(jié)果。
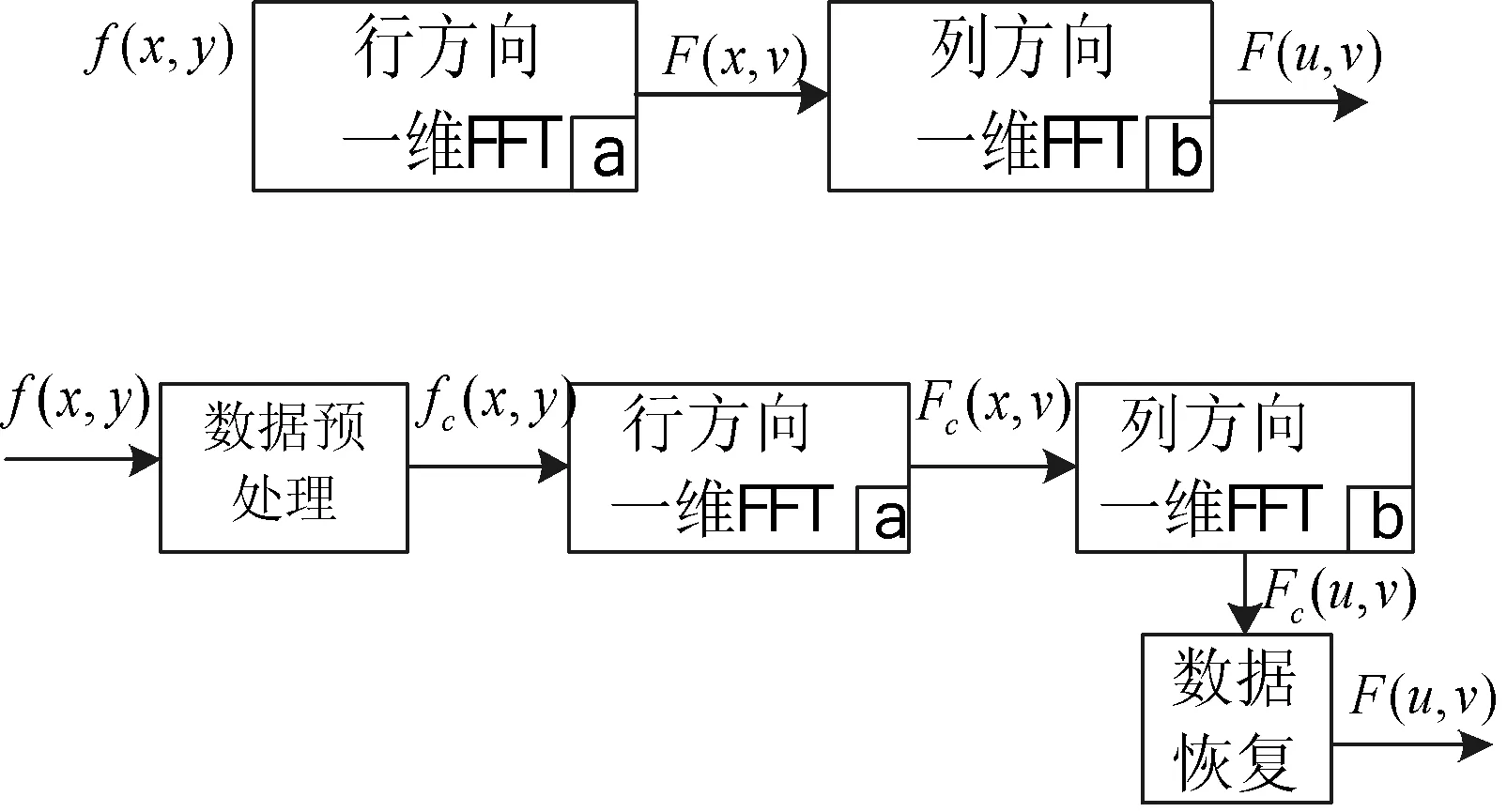
圖3 常規(guī)算法和本文算法處理流程
本文改進(jìn)方法大幅縮減了一維FFT的計(jì)算量,從N點(diǎn)變換轉(zhuǎn)化為N/2點(diǎn)變換,計(jì)算量縮減了50%,但是引入的其他模塊會(huì)帶來一定的成本增量,導(dǎo)致計(jì)算成本要小于50%的減少量。表1在計(jì)算量,包括乘加次數(shù)給出了常規(guī)FFT算法和本文改進(jìn)方法的比較。
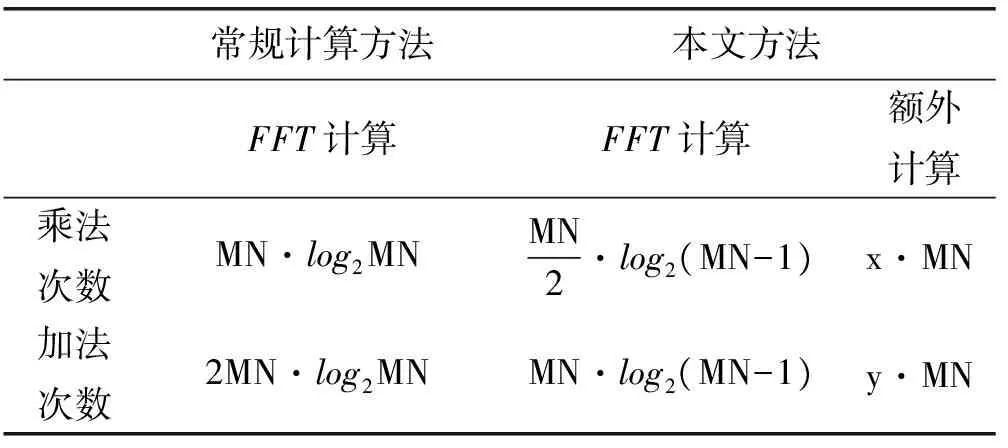
表1 算法復(fù)雜度對(duì)比
表1中,M,N代表圖像的尺寸大小,x,y代表額外等效的參數(shù)。在計(jì)算量方面,所有的計(jì)算等效為基本的乘加次數(shù)。對(duì)于無法轉(zhuǎn)換的操作,比如數(shù)據(jù)的轉(zhuǎn)存,移位開銷則間接地等效成乘加運(yùn)算。進(jìn)一步可以得到本文方法相對(duì)常規(guī)方法所減少的計(jì)算量表達(dá)式:
(10)
(11)
從上式可知,減少量與圖像的大小有關(guān),圖像越大,減少量相對(duì)更大。理論上分析,忽略數(shù)據(jù)轉(zhuǎn)存以及內(nèi)存中移位的時(shí)間開銷,僅針對(duì)額外的數(shù)據(jù)計(jì)算,根據(jù)圖3中數(shù)據(jù)預(yù)處理模塊和數(shù)據(jù)恢復(fù)模塊可知,x=2,y=4。對(duì)于128×128的圖像,γ=39.286%,η=39.286%;對(duì)于512×512的圖像,γ=41.7%,η=41.7%。從理論上分析,可以減少40%左右的計(jì)算量。
3.3 算法仿真分析
為了驗(yàn)證本文2D-FFT快速算法的正確性,以及計(jì)算效率。在個(gè)人PC平臺(tái)上,使用Matlab軟件環(huán)境,完成了4組對(duì)比試驗(yàn),分別對(duì)64×64、128×128、256×256、512×512的圖像進(jìn)行了測(cè)試,測(cè)試結(jié)果如表2所示。

表2 二維FFT處理時(shí)間對(duì)比
可以看出,本文方法相對(duì)于常規(guī)方法速度有顯著的提升,速度提升30%左右,接近于上面給出的理論提升量。實(shí)驗(yàn)表明改進(jìn)算法具有快速處理的優(yōu)點(diǎn)。圖4為實(shí)驗(yàn)得到的頻域數(shù)據(jù)圖,(a)和(d)為常用的測(cè)試圖Cameraman和Plane,(b)和(e)為本文算法得到的中間結(jié)果,(c)和(f)為恢復(fù)得到的最后結(jié)果。

圖4 實(shí)驗(yàn)結(jié)果圖
4 OpenCL實(shí)驗(yàn)結(jié)果及其分析
4.1 OpenCL算法實(shí)現(xiàn)
傳統(tǒng)算法如圖5所示[4]。一般的FFT采用三層循環(huán),通常對(duì)于N點(diǎn)變換,可以分為M級(jí),N=2M,每一級(jí)有N/2個(gè)蝶形單元。當(dāng)前組完成后,完成下一組;當(dāng)前級(jí)完成后,完成下一級(jí);傳統(tǒng)的方法都是串行的。如圖5所示的8點(diǎn)的FFT變換,共分為3級(jí),每一級(jí)間有4個(gè)蝶形運(yùn)算,對(duì)于蝶形間的計(jì)算和級(jí)間的運(yùn)算都是串行依次進(jìn)行的。分析可知:在同一級(jí)中具有相同旋轉(zhuǎn)因子的蝶形單元,可以通過備份多個(gè)旋轉(zhuǎn)因子以達(dá)到并行執(zhí)行;在同一級(jí)中具有不同旋轉(zhuǎn)因子的蝶形單元,因?yàn)閿?shù)據(jù)不存在相關(guān)依賴性,本身就是可以并行執(zhí)行的;而對(duì)于相鄰級(jí)使用的旋轉(zhuǎn)因子也并非完全不同,根據(jù)這個(gè)規(guī)律可以將旋轉(zhuǎn)因子存儲(chǔ)為二維查找表來實(shí)現(xiàn),減少計(jì)算量。

圖5 N=8時(shí),蝶形運(yùn)算圖
本文旨在將傳統(tǒng)的算法通過OpenCl在GPU平臺(tái)上進(jìn)行并行加速,因此需要找出算法中可以并行的部分,對(duì)于算法并行粒度的劃分如圖6所示。對(duì)于二維FFT,局部工作組通常是一行或者幾行的大小,局部工作組之間是并行的;由若干個(gè)線程組成一個(gè)線程塊,然后由若干個(gè)線程塊組成一個(gè)局部工作組,本文中最小的處理單元是一個(gè)線程,而一個(gè)線程對(duì)應(yīng)著一個(gè)蝶形計(jì)算單元,即一個(gè)線程處理兩個(gè)點(diǎn)的數(shù)據(jù)。線程塊之間是并行的,算法中每個(gè)蝶形單元也是并行的,對(duì)于每個(gè)數(shù)據(jù)點(diǎn)都是并行計(jì)算的,F(xiàn)FT算法實(shí)現(xiàn)了真正的數(shù)據(jù)并行。試驗(yàn)中將旋轉(zhuǎn)因子放到全局內(nèi)存表中,將待處理的數(shù)據(jù)通過全局內(nèi)存讀取到局部內(nèi)存中。

圖6 算法并行粒度和存儲(chǔ)共享
在OpenCL模型中,要取得足夠高的加速性能,需要非常多的線程才能夠提高計(jì)算效能,隱藏計(jì)算的訪存延時(shí),本文根據(jù)OpenCL多線程執(zhí)行模式的特點(diǎn),對(duì)FFT算法的分析如圖7所示。將算法按級(jí)劃分成M級(jí),N=2M,每一級(jí)有N/2個(gè)蝶形運(yùn)算單元,因?yàn)槊恳患?jí)的蝶形單元數(shù)據(jù)沒有相關(guān)性,可以完全并行執(zhí)行;在每一級(jí)間是數(shù)據(jù)通信,實(shí)驗(yàn)中采取原址計(jì)算,即將前級(jí)蝶形運(yùn)算的結(jié)果繼續(xù)存放在原來位置,而次級(jí)運(yùn)算的時(shí)候,按照索引的地址從新位置讀取數(shù)據(jù),將上一級(jí)產(chǎn)生的結(jié)果輸出作為后一級(jí)的數(shù)據(jù)輸入,實(shí)現(xiàn)數(shù)據(jù)在各級(jí)操作級(jí)中流動(dòng)起來。實(shí)驗(yàn)中分為log2N級(jí),每一級(jí)中有N/2個(gè)線程塊,每一個(gè)線程塊完成一個(gè)蝶形運(yùn)算,當(dāng)每一級(jí)的蝶形運(yùn)算完成后通過柵攔函數(shù)同步,數(shù)據(jù)流入下一級(jí)。然后下一級(jí)進(jìn)行同類運(yùn)算,直至完成M級(jí)計(jì)算。另外,每一個(gè)蝶形單元的兩個(gè)輸入操作數(shù)的地址根據(jù)線程號(hào)和當(dāng)前級(jí)數(shù)共同確定。同步柵攔barrier是為了確保線程間的同步,保證數(shù)據(jù)的準(zhǔn)確性。采用OpenCl提供的庫函barrier(CLK_LOCAL_MEM_FENCE)實(shí)現(xiàn)線程塊內(nèi)的線程同步,它保證線程塊中的線程執(zhí)行到barrier處才繼續(xù)執(zhí)行后面的語句。通過同步可以避免當(dāng)一個(gè)線程塊中的一些線程訪問共享存儲(chǔ)器的同一地址時(shí)可能發(fā)生的讀寫錯(cuò)誤問題。

圖7 算法多線程并行示意圖
4.2 存儲(chǔ)層次的優(yōu)化
① 局部存儲(chǔ)器是GPU片上的高速存儲(chǔ)器,是能夠被相同線程塊中的線程同時(shí)訪問的可讀寫存儲(chǔ)器。在實(shí)驗(yàn)中,按照?qǐng)D7,將算法流程分為多級(jí),上級(jí)的數(shù)據(jù)輸出作為下一級(jí)的輸入,數(shù)據(jù)完全在級(jí)間流動(dòng),數(shù)據(jù)操作采用同址方式。如果將輸入數(shù)據(jù)從全局內(nèi)存搬移到局部內(nèi)存中,就可以大大提高線程訪問數(shù)據(jù)的速度,通常來說全局內(nèi)存具有非常高的訪存延時(shí)。在內(nèi)核函數(shù)設(shè)計(jì)中,首先將顯存所需的數(shù)據(jù)搬遷到局部內(nèi)存中,最后處理完成后,再從局部內(nèi)存搬遷至顯存中,計(jì)算過程,只在局部內(nèi)存中完成,而訪問全局內(nèi)存也只需要兩次,大大提高了計(jì)算效率。
② 進(jìn)程的充分利用。在實(shí)驗(yàn)中針對(duì)N點(diǎn)FFT變換,實(shí)際上只用到了N/2個(gè)線程,將局部工作組劃分為一行的時(shí)候,就會(huì)造成N/2個(gè)空線程的資源浪費(fèi)。對(duì)于一個(gè)線程完成一個(gè)蝶形運(yùn)算單元,也就是完成兩點(diǎn)的數(shù)據(jù)變換,因此利用此點(diǎn)可以提高線程的利用率。實(shí)驗(yàn)中利用N個(gè)線程完成2N點(diǎn)的變換,每N/2個(gè)線程分別完成一行的變換,充分利用了線程,提高了計(jì)算資源的利用率,實(shí)驗(yàn)速度得到了顯著提升。
③ 內(nèi)存的讀寫優(yōu)化。針對(duì)2D-FFT算法,有大量的存儲(chǔ)數(shù)據(jù)讀取,因此提高速度,可以對(duì)數(shù)據(jù)的讀寫進(jìn)行優(yōu)化。實(shí)驗(yàn)中讀數(shù)據(jù)的讀寫速度進(jìn)行測(cè)試,對(duì)于128×128的數(shù)據(jù)進(jìn)行讀取,從全局存儲(chǔ)器讀到共享存儲(chǔ)器需要13μs,不論是按行讀取還是按列讀取;而從共享存儲(chǔ)器寫到全局存儲(chǔ)器則需要分為按行寫和按列寫,按行寫為32μs,按列寫則是85μs,可以發(fā)現(xiàn)寫的時(shí)候按行寫會(huì)大大節(jié)省時(shí)間。在2D-FFT變換中,行變換完成后需要進(jìn)行一個(gè)轉(zhuǎn)置,接著進(jìn)行列變換,對(duì)讀寫時(shí)間的分析得出最大耗時(shí)的地方是轉(zhuǎn)置,所以實(shí)驗(yàn)中采取的做法是在行變換完成后仍然按行寫到全局內(nèi)存,在列變換的時(shí)候任然采取按列讀,這樣極大地減小了按列寫的時(shí)間和轉(zhuǎn)置的時(shí)間,實(shí)驗(yàn)速度得到了近40%的提升。
④ 內(nèi)存的寫優(yōu)化。實(shí)驗(yàn)中發(fā)現(xiàn)在寫的過程中,同樣是按行寫,但是按行順序?qū)懞桶葱衼y序?qū)懀匀淮嬖谥俣鹊牟町悾虼嗽趯懙倪^程中,預(yù)先對(duì)數(shù)據(jù)排序后,然后依次往全局內(nèi)存寫數(shù)據(jù),實(shí)驗(yàn)結(jié)果有一定的提升。
4.3 實(shí)驗(yàn)結(jié)果
本文在基于Windows操作系統(tǒng)上和AMDGPU實(shí)現(xiàn)了該算法,驗(yàn)證了OpenCL的FFT算法實(shí)際的性能。實(shí)驗(yàn)中所用到的平臺(tái)和配置如表3所示,程序基于AMD的OpenCl開發(fā)包,并在OpenCl1.2的環(huán)境下編譯。為了驗(yàn)證對(duì)比本文算法的性能,和文獻(xiàn)[4]基于CUDA版本的算法以及基于CPU版本的FFT算法做了對(duì)比,其中文獻(xiàn)[4]的處理器和顯卡配置如表4所示。

表3 本文的平臺(tái)配置

表4 文獻(xiàn)[4]的實(shí)驗(yàn)硬件配置
現(xiàn)有的GPGPU通用計(jì)算的處理流程一般為:CPU端作為宿主機(jī)先處理少部分邏輯運(yùn)算,然后通過調(diào)用API函數(shù)將大量的計(jì)算任務(wù)交給OpenCL設(shè)備(GPU)。但是內(nèi)存和顯存的實(shí)際位置不一樣,所以CPU端通過內(nèi)存對(duì)象將操作數(shù)據(jù)送到GPU顯存中,等到GPU處理完畢,然后再通過內(nèi)存對(duì)象送回到CPU內(nèi)存中。實(shí)驗(yàn)中的計(jì)算時(shí)間為FFT算法的總運(yùn)算時(shí)間,包括在CPU上執(zhí)行邏輯函數(shù)的時(shí)間和在GPU上執(zhí)行kernel函數(shù)的時(shí)間,以及從CPU拷貝數(shù)據(jù)到GPU顯存的時(shí)間。表5對(duì)比了本文和其他平臺(tái)的實(shí)驗(yàn)結(jié)果。

表5 FFT算法的運(yùn)行總時(shí)間 單位:us
實(shí)驗(yàn)數(shù)據(jù)表明:當(dāng)圖像數(shù)據(jù)小的時(shí)候,GPU和CPU之間數(shù)據(jù)相互拷貝的時(shí)間會(huì)抵消很大一部分并行加速的時(shí)間,所以加速比很小,當(dāng)數(shù)據(jù)規(guī)模增大的時(shí)候,這種加速效果就逐步提升。本文中AMD Radeon HD 7450支持最大工作組大小為256,所以只針對(duì)最大圖像數(shù)據(jù)為512×512。從實(shí)驗(yàn)數(shù)據(jù)可以看出,文獻(xiàn)[4]基于CUDA的方法和本文方法結(jié)果基本一致,相比較CPU版本有4~7倍的加速。但是考慮到NVIDIA GTX 465浮點(diǎn)運(yùn)算峰值為1 277.7 GFLOPs,Inter i7 core 3770浮點(diǎn)運(yùn)算峰值為282 GFLOPs,而AMD Radeon HD 7450的浮點(diǎn)運(yùn)算峰值僅為300 GFLOPs,因此本文的算法相對(duì)于文獻(xiàn)[4]有4倍的加速,相對(duì)于CPU版本有真正意義上的4~7倍的加速。對(duì)于同樣浮點(diǎn)運(yùn)算能力的處理器來說,這個(gè)加速效果還是很明顯的。
5 結(jié) 語
本文實(shí)現(xiàn)了基于OpenCL的高速FFT計(jì)算。通過分析2D-FFT算法的可并行性特點(diǎn),將算法分級(jí),多線程分塊,充分利用了數(shù)據(jù)間的非相關(guān)性,實(shí)現(xiàn)了數(shù)據(jù)的充分流動(dòng),極大地提高了并行度;針對(duì)OpenCL的存儲(chǔ)層次特點(diǎn)和算法層次的優(yōu)化,明顯地提高了運(yùn)算的速度,和相同浮點(diǎn)運(yùn)算能力的平臺(tái)相比,具有4倍左右的良好加速比。
[1] AMD上海研發(fā)中心.跨平臺(tái)的多核與眾核編程講義OpenCL的方式[M].2010.
[2] Aaftab Munshi,benedict R Gaster,Timothy G Mattson,et al.OpenCL Programming Guide[M].Pearson Education,2012.
[3] AMD Corporation.Accelerated Parallel Processing OpenCL TM[Z].Jan.2011.
[4] 趙麗麗,張盛兵,張萌,等.基于CUDA的高速FFT計(jì)算[J].計(jì)算機(jī)應(yīng)用研究,2011,28(4):1556-1559.
[5] 張櫻,張?jiān)迫?龍國平,等.基于OpenCL的圖像模糊化算法優(yōu)化研究[J].計(jì)算機(jī)科學(xué),2012,39(3):259-263.
[6] Khronos group.OpenCL-The open standard for parallel programming of heterogeneous systems[OL].http://www.khronos. org/opencl/.
[7] 溫博,張啟衡,張建林.高分辨圖像二維FFT正反變換實(shí)時(shí)處理方法及硬件實(shí)現(xiàn)[J].計(jì)算機(jī)應(yīng)用研究,2011,28(11):4376-4379.
[8] 左顥睿,張啟衡,徐勇,等.基于GPU的并行優(yōu)化技術(shù)[J].計(jì)算機(jī)應(yīng)用研究,2009,26(11):4115-4118.
[9] 范進(jìn),金生震,孫才紅.超高速FFT處理器的設(shè)計(jì)與實(shí)現(xiàn)[J].光學(xué)精密工程,2009,17(9):2241-2246.
RESEARCH ON FFT ALGORITHM BASED ON OPENCL
Jia Ge1,2Peng Xianrong1Zuo Haorui1
1(InstituteofOpticsandElectronics,ChineseAcademyofSciences,Chengdu610209,Sichuan,China)2(GraduateUniversityofChineseAcademyofSciences,Beijing100039,China)
Fast Fourier transform, as a commonly used computational tool in the field of image processing, especially in image restoration algorithm, transforms the time-domain computation into frequency-domain computation and has great significance for engineering applications. By adopting thread blocks and parallel mapping method, we can make FFT algorithm reach the maximum degree of parallelism. In view of the storage features of OpenCL and the optimisation of the algorithm, the AMD GPU platform has been significantly accelerated. Compared with CPU platform and CUDA with the same processing capability, the performance of the optimised algorithm has increased by 7 times and 4 times respectively.
Fast Fourier transform OpenCL GPU Parallel speedup
2016-01-20。賈格,博士生,主研領(lǐng)域:并行加速,圖像盲復(fù)原。彭先蓉,研究員。左顥睿,副研究員。
TP302
A
10.3969/j.issn.1000-386x.2017.03.042
猜你喜歡
作文·小學(xué)低年級(jí)(2025年2期)2025-02-13 00:00:00
小雪花·小學(xué)生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學(xué)低年級(jí)(2024年2期)2024-04-29 00:00:00
作文·小學(xué)低年級(jí)(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(bào)(2022年4期)2022-08-09 08:52:06
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
