基于Hadoop平臺的農產品價格數據爬取和存儲系統的研究
2017-04-14 00:47:02楊曉東郜魯濤楊林楠劉建陽
計算機應用與軟件 2017年3期
關鍵詞:頁面
楊曉東 郜魯濤 楊林楠* 劉建陽
1(云南農業大學基礎與信息工程學院 云南 昆明 650201)2(云南省信息技術發展中心 云南 昆明 650228)
基于Hadoop平臺的農產品價格數據爬取和存儲系統的研究
楊曉東1郜魯濤1楊林楠1*劉建陽2
1(云南農業大學基礎與信息工程學院 云南 昆明 650201)2(云南省信息技術發展中心 云南 昆明 650228)
目前許多大型農貿市場和農業信息商務平臺都在實時發布每天各地區不同農產品的價格數據。針對數據更新快、數據量大、數據形式多樣,使數據的爬取和存儲以及后續的分析工作變得困難,提出基于Hadoop的農產品價格爬取及存儲系統。利用HttpClient框架結合線程池通過多線程爬取,爬取結束后執行完整性檢查,過濾出信息不完整的網頁,進行二次爬取直到信息完整。對爬取到的網頁使用正則表達式進行解析和清洗,提取有用的數據,以文本文件的形式存入HDFS(Hadoop Distributed File System ),此后爬取到的數據以追加的方式寫入HDFS 文件中。實驗表明HDFS的寫入性能滿足爬取數據不斷遞增的現狀,副本數越少,數據塊越大,寫入性能越好。
分布式系統 爬蟲 Hadoop HDFS 正則表達式
0 引 言
隨著互聯網的快速發展,預計2020年全球數字規模將達到40 ZB[1],數據類型以結構化、半結構化和非結構化三種為主,其中半結構化和非結構化數據的存儲是當下面臨的主要問題。如今全國各地的大型農貿交易市場和農業信息商務平臺,借助互聯網的實時性高、傳播速度快、覆蓋面廣等特點,在實時發布農產品價格,更新供需數據。出現價格數據不斷增加卻過于分散的情況,因此通過網絡爬蟲爬取相關網頁,抽取有價值的數據進行存儲和應用十分重要。
Hadoop分布式框架支持海量存儲,快速數據訪問的分布式處理,具有可擴展性、失效轉移等特點[2-3]。其中HDFS是分布式文件系統,提供高吞吐量的數據訪問,能存儲從GB級到TB級別大小的單個文件,以及數千萬量級的文件數量。針對從農產品價格網站爬取到的網頁大小不等,文件數量過多等特點,HDFS不像其他文件系統,一個小于數據塊大小的文件占據整個塊。
HDFS文件系統將元數據文件存儲在Namenode節點的內存中,因此存儲的文件總數與Namenode的內存容量密切相關。文獻[4]-文獻[7]針對HDFS文件系統的弊端,分別提出了優化方案,使文件存儲數量和寫入效率都有了提升。本文存儲的文件普遍在百兆以上,不斷爬取數據進行追加操作,會使單個文件的大小不斷增大,而文件數量不會增加。針對HDFS文件系統的不同配置,進行寫入性能的測試和比較。
1 爬蟲系統的設計與實現
本系統針對特定農產品價格網站進行數據爬取,系統總共分為4個模塊:爬取、完整性檢查、解析、HDFS存儲。爬蟲系統基于Hadoop框架通過URL并行爬取網頁,針對不同網頁的內容分類方式,根據需要設定爬取深度為n,保證數據爬取的完整性。在爬取過程中,由于網絡或者被爬取網站所在服務器的穩定性,可能導致網頁爬取失敗。所以每次發起Http請求都會驗證返回值,保證請求成功。使用正則表達式對網頁進行解析,將解析得到的數據以文本文件格式存入HDFS。抽取特定標簽中包含的URL放入請求函數中,循環執行上述過程直到爬取深度達到n值。
1.1 爬蟲基本原理
網絡爬蟲的主要作用是從網上下載網頁進行使用,可以建立索引提供搜索引擎的功能,解析其中的數據進行分析挖掘等[8-14]。其基本工作原理如下:首先初始化一個URL,判斷該URL是否處理過,如果沒有,則根據要求遍歷該URL中的鏈接地址,爬取所有遍歷的網頁直到結束。然后根據一定的遍歷算法傳入新的初始化URL,繼續遍歷鏈接,爬取網頁,直到待初始化隊列中沒有可用的URL為止。網絡爬蟲工作原理如圖1所示。
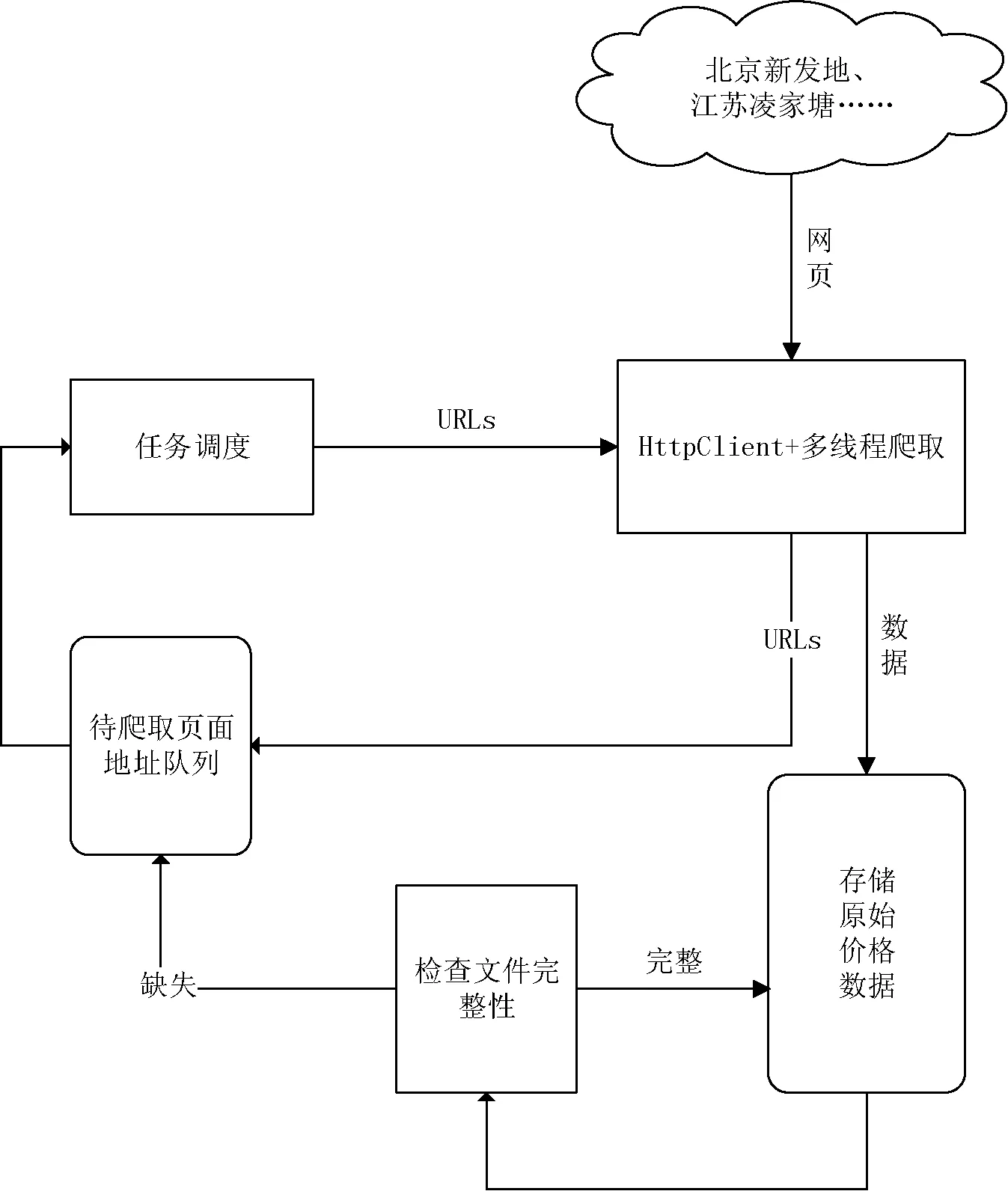
圖1 網絡爬蟲工作原理圖
1.2 爬取策略設計
在進行農產品價格數據爬取過程中,發現價格的發布方式主要分為兩類:一類是以表格的形式列出所有價格數據,不支持品種、產地等方式篩選查看價格數據,例如北京新發地農產品批發市場。此類網站分頁較多,但是網頁中鏈接的頁面較少,可以使用深度優先爬取網頁。目前有近30萬條農產品價格數據,分為1萬多個頁面,每個頁面的Http地址可以按規則進行分解,使用多線程技術爬取頁面,提高爬取的速度。另一類是支持品種、產地等篩選的價格數據表格,例如一畝田農產品商務網站。數據分頁較少,但是網頁中的鏈接頁面多,適合廣度優先的搜索策略,遍歷所有需要的鏈接地址爬取網頁。
1.3 爬取模塊
本爬蟲系統的爬取模塊主要任務是讀取URL地址并將其放入集合,拆分隊列,使用多線程技術獲取網頁。基于爬取策略,分析網站內容的組織形式,對于URL地址滿足特定規律即URL地址中只有部分路徑或者網頁名不相同,同時知道總的頁面數,可拆分頁面數放入不同的線程進行處理,在每個線程中通過變量循環遍歷所有待爬取網頁地址。以江蘇凌江唐農產品批發市場為例,該市場目前共發布近1 000 000條數據,66 000多個頁面。每個頁面對應一個URL地址,形成一個有66 000多個地址的URL列表,將列表進行拆分放入線程池,通過HttpClient框架發起GET請求并下載價格數據進行解析。最終存入HDFS中,通過配置形成3個副本的自動備份。如圖2為爬取模塊工作機制。
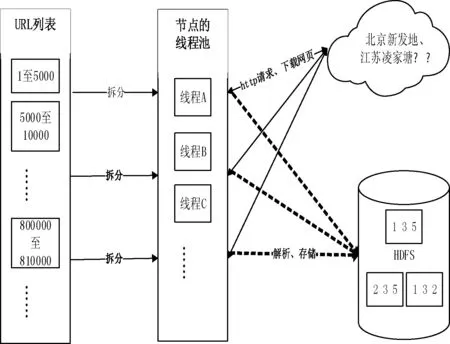
圖2 爬取模塊工作機制
1.4 解析模塊
不同網頁的編碼方式差異較大,使用正則表達式針對不同的編碼方式生成規則模板過濾信息,可以有效提取內容,但是會使解析工作變得繁雜和冗余,需要不斷地設計解析規則。本文通過標簽名或標簽對中的唯一特征值鎖定標簽對,再抽取標簽對中的內容,實驗表明能快速有效提取信息,避免大量重復設計解析規則。如圖3為數據解析過程。

圖3 數據解析過程
通過重載FileSystem提供的get()函數確定要使用的文件系統以及讀取配置文件,使用open()函數來獲取文件的輸入流,獲取Html類型信息后通過標簽名或特征值使用正則表達式解析DOM。以北京新發地農產品批發市場公布的網頁價格數據為例,從body標簽開始獲取“class=table”的標簽對,再從該標簽對中獲取包含價格數據的標簽對“class=hq_table”,最后利用Java的split()方法通過空格拆分數據,解析出需要的數據。如圖4所示為解析前數據格式,圖5為解析后的數據格式。

圖4 解析前數據格式
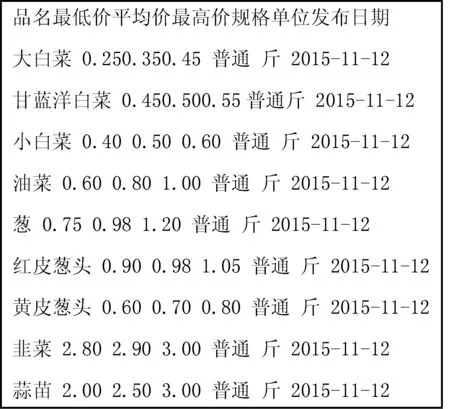
圖5 解析后數據格式
2 HDFS存儲模塊
相對于傳統的分布式文件系統,HDFS具有高容錯性和高可用性的特點[15]。HDFS的“一次寫,多次讀”的特性,很好地支持大數據量的一次寫入、多次讀取,有助于對元數據的保存和后期的查詢分析。HDFS文件系統包括一個主控節點NameNode和一組DataNode節點,NameNode用于管理整個文件系統的命名空間和元數據,DataNode是實際存儲和管理文件的數據塊。圖2中HDFS包含三個小方塊,每個方塊代表一個DataNode節點,節點中重復的數字表示數據的副本,本系統通過配置hdfs-site.xml文件中的dfs.replication屬性,將副本數設置為3個。
分布式文件系統HDFS提供了命令行和API兩種文件操作方式,包含常用的寫入、讀取、關閉等操作。本系統使用正則表達式解析原始網頁并保存為文本文件格式,此后通過append()方法向文件中不斷追加解析出來的數據。以下是通過API將數據寫入HDFS的過程:
1) 通過Path類定義需要的路徑,該路徑為即將寫入數據的路徑。
2) 在創建文件系統實例前,需要獲取當前的環境變量,Configuration類提供了封裝好配置的實例,該配置在core-site.xml中設置。
3) 接下來需要重載HDFS文件系統提供的get()方法,加載當前環境變量和建立讀寫路徑。
4) 通過FSDataOutputStream類創建輸出流,其中write()方法可以對數據文件進行相應的寫操作。為了提高寫入速度,以及解析過程不影響寫入性能,使用Java的多線程技術對數據流進行操作,將解析好的數據提前放入隊列再執行寫入操作。
5) 執行完寫操作后,通過closeStream()方法關閉當前線程的寫出流,再用notify()方法喚醒另一個線程執行寫操作。數據寫入HDFS的流程如圖6所示。
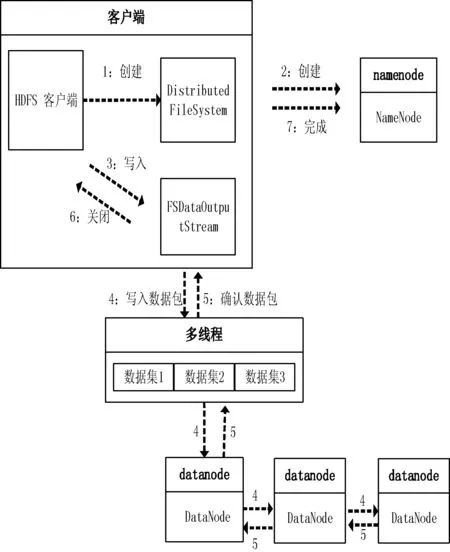
圖6 數據寫入HDFS的流程圖
3 實驗結果及分析
本系統可以解析并存儲北京新發地農產品批發市場、江蘇凌家塘農副產品批發市場、浙江省金華農產品批發市場、北京城北回龍觀商品交易市場等。實驗選取從北京新發地和江蘇凌家塘農產品批發市場爬取的價格數據為測試對象。
3.1 測試環境
測試使用了3臺服務器搭建測試環境,每臺服務器的硬件配置見表1所示,Hadoop版本為2.6.0。

表1 硬件配置
3.2 測試數據
測試數據集為爬取的80 000多個網頁,原始數據集共120多GB,通過正則表達式對數據解析后寫入HDFS。
3.3 測試場景
數據塊是磁盤進行數據讀/寫的最小單位,HDFS也一樣,增大HDFS的塊大小,可以減少尋址開銷。實驗通過設置不同的塊大小和副本數量,比較HDFS的寫入性能。如圖7和圖8為不同數據塊大小,不同副本數的寫入時間比較。
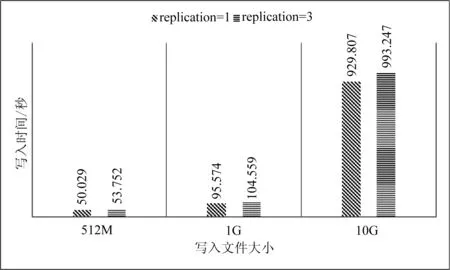
圖7 HDFS寫入性能(64 MB/塊)
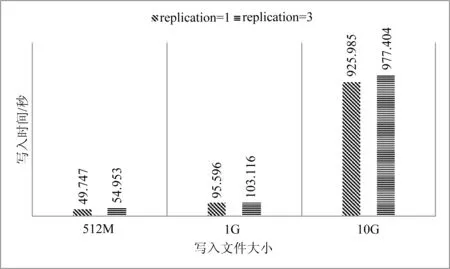
圖8 HDFS寫入性能(128 MB/塊)
3.4 實驗結果
實驗過程用多線程技術預先解析數據,排除了解析速度慢導致的延遲和誤差。通過實驗數據可以看出1個副本的寫入速度要比多個副本快,時間差距會隨著數據量的變大而增大。數據塊大小設置為64和128MB時的寫入速度相近,總體來看,當設置數據塊為128MB時寫入速度要比64MB時略快。
4 結 語
本文針對網絡資源的不斷豐富,爬取到的數據量巨大,而且增長速度快等特點,導致后期的存儲和分析難的現狀。設計了網絡爬蟲系統并且利用Hadoop平臺的HDFS文件系統進行存儲,并進行了寫入性能的實驗設計。從實驗得到的數據來看HDFS能很好地支持網絡爬蟲爬取的數據不斷遞增的現狀。即使設置了多副本的備份機制,也能很好地進行數據的寫入和自動備份。充分利用Hadoop平臺的優勢,對已經解析和清洗后的數據進行分析、挖掘是下一步的主要研究工作。
[1]IDC最新數字宇宙研究報告:中國數據量增長顯著[EB/OL].2013-03-01.http://www.searchbi.com.cn/showcontent_70996.htm.
[2]BorisLublinsky,KevinTSmith,AlexeyYakubovich.ProfessionalHadoopSolution[M].Wrox,2013:3-4.
[3]TomWbite.Hadoop:TheDefinitiveGuide[M].O’ReillyMedia,2010:497.
[4] 張海,馬建紅.基于HDFS的小文件存儲與讀取優化策略[J].計算機系統應用,2014,23(5):167-171.
[5] 李鐵,燕彩蓉,黃永鋒,等.面向Hadoop分布式文件系統的小文件存取優化方法[J].計算機應用,2014,34(11):3091-3095,3099.
[6] 張春明,芮建武,何婷婷.一種Hadoop小文件存儲和讀取的方法[J].計算機應用與軟件,2012,29(11):95-100.
[7] 尹穎,林慶,林涵陽.HDFS中高效存儲小文件的方法[J].計算機工程與設計,2015(2):406-409.
[8] 孔濤,曹丙章,邱荷花.基于MapReduce的視頻爬蟲系統研究[J].華中科技大學學報(自然科學版),2015(5):129-132.
[9] 程錦佳.基于Hadoop的分布式爬蟲及實現[D].北京郵電大學,2010.
[10] 萬濤.基于Hadoop的分布式網絡爬蟲研究與實現[D].西安電子科技大學,2014.
[11] 王慶紅,李廣凱,周育忠,等.一種基于銀行家算法的網絡爬蟲資源配置策略[J].智能系統學報,2015(3):494-498.
[12]PrashantDahiwale,MMRaghuwanshi,LateshMalik.PDDCrawler:Afocusedwebcrawlerusinglinkandcontentanalysisforrelevanceprediction[C]//InternationalConferenceonInformationRetrieval,7-8,Nov,2014.
[13] 于娟,劉強.主題網絡爬蟲研究綜述[J].計算機工程與科學,2015,37(2):231-237.
[14] 周中華,張惠然,謝江.基于Python的新浪微博數據爬蟲[J].計算機應用,2014,34(11):3131-3134.
[15] 黃宜華,苗凱翔.深入理解大數據:大數據處理與編程實踐[M].北京:機械工業出版社,2014:57,65-68.
RESEARCH ON DATA CRAWLING AND STORAGE SYSTEM OF AGRICULTURALPRODUCT PRICE BASED ON HADOOP PLATFORM
Yang Xiaodong1Gao Lutao1Yang Linnan1*Liu Jianyang2
1(CollegeofBasicScienceandInformationEngineering,YunnanAgricultureUniversity,Kunming650201,Yunnan,China)2(YunnanInformationTechnologyDevelopmentCenter,Kunming650228,Yunnan,China)
At present, many large farm product markets and agricultural information commerce platforms release the information of agricultural product prices from different regions in real-time each day. Because of a large number of various fast-updating data, the data crawling and storage as well as the following analysis work come to be difficult. Therefore, we put forward a data crawling and storage system of agricultural product price based on Hadoop. We implement multi-threaded crawling by HttpClient framework combined with thread pool and finish integrity checking. After filtering out the web pages whose information is incomplete, we crawl again until the information comes to be complete. We analyze and clean the crawled web pages by regular expression, and save the useful extracted data in the form of text file into HDFS (Hadoop Distributed File System). The data crawled later is supplemented into HDFS. Experiment shows that the writing performance of HDFS can satisfy the incremental crawling data. The less duplicates are, the bigger the data block is, then the better the writing performance is.
Distributed system Crawler Hadoop HDFS Regular expression
2016-03-12。國家“十二五”科技支撐計劃課題(2014BAD10B03)。楊曉東,碩士生,主研領域:數據挖掘。郜魯濤,講師。楊林楠,教授。劉建陽,高級工程師。
TP393
A
10.3969/j.issn.1000-386x.2017.03.013
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
電腦愛好者(2022年3期)2022-05-30 10:48:04
工業設計(2016年1期)2016-05-04 03:58:09
通信技術(2012年4期)2012-02-15 07:10:35
電腦愛好者(2011年11期)2011-06-22 08:20:18
網絡安全技術與應用(2011年3期)2011-03-14 06:44:46
赤峰學院學報·自然科學版(2010年11期)2010-09-21 11:30:50
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
