Cache替換算法LRU和2Q的深度分析
2017-03-29 07:45:18張恒瑞王紅
現代計算機 2017年4期
關鍵詞:效率
張恒瑞,王紅
(遼寧工程技術大學電子與信息工程學院,葫蘆島 125105)
Cache替換算法LRU和2Q的深度分析
張恒瑞,王紅
(遼寧工程技術大學電子與信息工程學院,葫蘆島 125105)
Cache替換算法是內存和CPU交互時速度保證的關鍵,傳統的LRU算法在處理偶然性數據訪問時造成緩存污染嚴重,但其實現簡單,命中率和效率尚可,故成為現今大多情況下使用的算法;2Q算法通過設置兩個隊列,A1隊列通過暫存數據減弱偶發性數據的影響,實現同樣簡單且有不錯的性能。通過編制的詞法分析器分析程序代碼得來的數據進行算法性能的比較。
Cache替換算法;LRU;2Q;命中率;性能
0 引言
Cache作為一種媒介大大提升了CPU和內存的訪問速度,為了增加Cache的訪問命中率,替換策略的選取大為重要,如今的替換策略大都以程序的局部性原理作為理論基礎,分別從時間局部性和空間局部性作為著眼點,闡釋不一樣的替換算法。LRU作為經典的替換策略,實現簡單,但對于特定的數據有很大的缺陷,2Q算法從某種程度上緩解了緩存污染,但是將一個隊列變成兩個隊列勢必會影響性能,如何平衡這兩者的關系成為重點。
1 問題抽象
將對Cache的操作簡化為get和set操作,get(key)表示通過其緩存地址key得到內容value,未命中count++,增加鍵值對(key,value)表示入緩存,緩存滿時按策略刪除,set(key,value),若key存在則修改對應緩存中value值,若不存在則增加鍵值對(key,value)表示入緩存,count,緩存滿時按策略刪除,可以通過其count值判斷其命中情況,運行時間來比較其效率。
2 LRU
2.1 LRU原理
LRU,最近最少使用算法,從時間局部性著手,如果數據在最近被訪問,將來也很有可能訪問,基本的思想是建立一個鏈表,當訪問命中時,將節點插入鏈表頭部,當鏈表達到長度限制時刪除鏈表尾節點。
上述過程在查找訪問過程和刪除尾節點處復雜度達到了O(n)[1],鏈表的好處在于插入刪除的復雜度為O(1),而在訪問節點處復雜度高達O(n),訪問檢索處的復雜度可以通過紅黑樹或hash表予以優化,而普通的單鏈表在刪除某節點時需要知道上一個節點,當檢索到當前節點后,還需從頭訪問到上一個節點才能刪除該節點,同時最后一個節點的刪除也需要從頭訪問,時間復雜度為O(n),故采用雙向鏈表[2],插入和刪除的復雜度都為O(1)。
2.2 具體實現
因為關于Cache替換中內存也占有很大地位,而hash占有較大的空間復雜度,所以運用紅黑樹作為數據的存儲結構,C++的標準庫Map實現了紅黑樹,list實現了雙向鏈表,總的時間復雜度為O(logn),去除Map的定位功能,對鏈表的插入刪除僅需O(1),以下的代碼為了精簡,使用了map和list的stl庫。


2.3 分析
LRU算法實現簡單,效率也不錯,但面對偶發性的訪問數據無力,造成緩存污染嚴重。假設緩存容量為100,操作序列為1-101循環訪問,若采用LRU算法,當訪問101時會將1刪除,之后每次訪問都會將下次訪問數據從緩存刪除,命中率大大降低。
32 Q算法
3.1 基本原理
2Q算法緩解了LRU對弱空間局限性的無力,在2Q算法里,有兩個隊列A1和A2[3],A1為FIFO隊列,A2為LRU隊列,若數據在A1和A2中都沒命中,將數據插入A1隊列尾部,若A1滿,A1頭部出隊,當數據在A1命中時,將其刪除,并將數據插入A2尾部,A2滿時將A2頭部出隊。
3.2 具體實現
程序中對A1和A2隊列采用list雙向鏈表,并采用map進行訪問檢索,保證插入刪除時的復雜度為O(1),對key先在A2進行map訪問檢查,若未命中檢查A1,若命中執行list刪除操作,并將數據插入A2,代表數據入Cache,為hot數據,避免LRU中一次訪問就入Cache造成偶發性數據污染緩存,若在A1未命中,將數據以FIFO的形式入A1。

3.3 分析
以上為簡化的2Q操作,在簡化操作中,A1和A2所占比例是問題的關鍵,A1比例大時,緩存容量變少,命中率降低,而A1比例小時,找出數據人緩存的時間變長,如何平衡好A1和A2所占比例是問題的關鍵[4]。如圖1所示,比較下LRU和2Q在緩存為3000,200000次隨機數測試下的運行效率和命中率可以發現2Q的運行效率明顯較好。
仔細看后,發現兩種算法的未命中次數都顯得很高,原因在于測試選用的是隨機數進行的,在隨機數模式下,程序的局部性原理便不再起作用,替換算法之間的差距也變小了,如何進行有效果且具有一定的規模的數據測試呢。下面決定采用編寫的簡易詞法分析器對大量程序分析后得到的數據結果作為替換算法的測試數據。運用詞法分析器對超過7000行的代碼進行分析得到50000余條數據,作為替換算法的輸入文件進行運算,在數據范圍在1000以內,緩存容量為300得到如圖2結果。

圖1 LRU和2Q比較結果
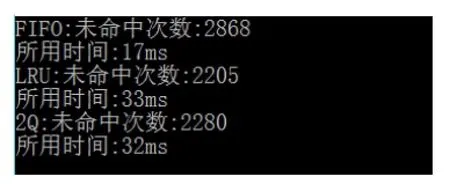
圖2 三種算法比較結果
結果中可看出最簡單的FIFO算法命中次數最差,在實際的情況下多次訪問主存會造成時間效率差,相對的LRU和2Q算法命中次數較好,雖然運行時間稍長于FIFO,在較少的訪問主存下會使總的時間效率大大提升,在大多實際情況下,LRU算法運行效率尚可,在大量偶發性數據下,可以采用2Q算法予以改進。
[1]海子.LRU Cache.[2014-5-23].http://www.cnblogs.com/dolphin0520/p/3741519.html.
[2]黃賢明.基于LRU改進算法的實時數據庫緩存機制[J].工業控制計算機,2015(12):63-64.
[3]flychao88.緩存淘汰算法-LRU算法.[2013-11-20].http://flychao88.iteye.com/blog/1977653.
[4]Linux Memory.Cache替換算法之:2Q.[2015-5-20].http://www.jianshu.com/p/4f3ca27300c2.
Depth Analysis of LRU and 2Q on Cache Replacement Algorithm
ZHANG Heng-rui,WANG Hong
(School of Electronic and Information Engineering,Liaoning Technical University,Huludao 125105)
Cache replacement algorithm is the key to ensure the speed of memory and CPU interaction,the traditional LRU algorithm in dealing with accidental data access caused by cache pollution,but its implementation is simple and the hit rate and efficiency can be used now,in most cases the algorithm,the 2Q algorithm by setting two queue,queue A1 reduces the influence of sporadic data through the temporary storage of data,to achieve the same performance is simple and has good,through the use of lexical analyzer analysis program code to compare the performance of the data algorithm.
Cache Replacement Algorithm;LRU;2Q;Hit Rate;Performance
1007-1423(2017)04-0017-03
10.3969/j.issn.1007-1423.2017.04.014
王紅(1979-),女,遼寧莊河人,講師,碩士研究生,研究方向為計算機系統結構、計算機控制及應用
2016-12-07
2017-01-20
張恒瑞(1996-),男,本科生
猜你喜歡
瘋狂英語·初中天地(2021年5期)2021-07-21 02:24:28
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
遼寧經濟(2017年6期)2017-07-12 09:27:16
中國衛生(2016年9期)2016-11-12 13:27:54
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國洗滌用品工業(2015年7期)2015-02-28 19:02:38
電子設計工程(2015年12期)2015-02-27 12:06:10
中國衛生(2014年11期)2014-11-12 13:11:32
