基于奇異值分解的銀行客戶數據隱私保護算法研究
2017-03-27 15:58:54季文韜
電子技術與軟件工程 2017年4期
摘 要 如何在保護客戶數據隱私的前提下進行有效的數據挖掘,已經成為金融業數據挖掘領域的重要課題。用矩陣的奇異值分解進行數據擾動,不僅能消除數據噪音,還能獲得準確的聚類效果。本文提出了一種奇異值分解的聚類算法,實驗表明算法能有效的保護客戶數據隱私,而且保留了聚類分析的準確特征。
【關鍵詞】奇異值分解 隱私保護 聚類分析
隨著數據挖掘技術和機器學習算法的快速發展,數據隱私保護問題已經越來越引起人們的關注。目前的隱私保護方法主要分為兩類:
(1)對原始數據值進行扭曲、擾動、隨機化和匿名化,使數據使用者不能得出數據的原始值。
(2)修改數據挖掘算法,使分布式數據挖掘中的參與者在不知道確切數據值的情況下仍能得出數據挖掘的結果。
數據擾動是隱私保護數據挖掘應用的重要組成部分,我們利用奇異值分解(Singular value decomposition)SVD)對保密數值屬性進行擾動,并在矩陣分解的基礎上進行隱私數據聚類。我們所提出的的奇異值分解聚類方法,不僅可以滿足保護敏感數據屬性的要求,同時保留K-means聚類分析的一般特點,能得到準確的數據模型和分析結果。
1 算法的理論基礎
1.1 K-均值聚類算法
K-均值聚類算法是一個將包含有n個對象的數據集劃分成k 個聚類的過程,使同一聚類中的對象屬性相似度較高,而不同聚類中的對象屬性相似度較小。聚類分析的基本指導思想就是最大程度地實現類中對象相似度最大,類間對象相似度最小。
1.2 奇異值分解
奇異值分解在數據挖掘的應用中,特別是在文本挖掘中并不是新技術,但在隱私保護的數據擾動中的應用是最近興起的。一個奇異值分解的顯著特點是在降維壓縮數據的同時維持主要的數據模式。矩陣分解的主要目的是從原始數據集獲得一些低維的,對象和屬性的近似關聯的數據結構。
奇異值分解的顯著特點是在降維壓縮數據的同時保護了主要的數據模式。在隱私保護金融數據挖掘應用中,擾動的數據集Ak可以在同時提供數據隱私保護,還保留了原始數據的可用性,使其真實地表現原始的數據集結構。
奇異值分解(SVD)是一種常見的數據挖掘矩陣分解方法和信息檢索方法。它開始被用來降低數據集的維度。文獻[3]提出了用SVD進行數據擾動的技術,在文獻[4]中,SVD技術是用來擾動數據集的模式部分。
2 SVD-clustering模型及算法
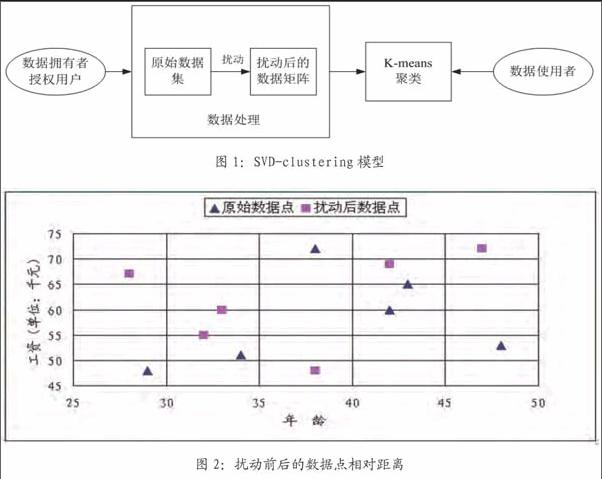
SVD-clustering模型包含兩部分:數據擾動部分和數據的聚集部分。模型如圖1所示。我們假設只有數據的擁有者和授權用戶才可以對數據進行處理。經過數據擾動,原始的數據集轉換成完全不同的數據矩陣,數據使用者利用K-means聚類等數據挖掘算法對擾動的數據進行檢索。因為數據使用者未經授權不能得到原始數據,這樣,包含隱私保密信息的原始數據就得到了保護。
2.1 SVD-clustering算法流程
輸入:初始矩陣D,劃分的聚類的數目K
輸出:轉換后的矩陣D',聚類結果
(1)在矩陣D中找出需要保密的數據屬性序列(ai)i=1,2,…,n.形成一個新的矩陣A,A=[a1, a2,…,an];
(2)用SVD算法對矩陣D進行分解SVD(A)=UWVT;
(3)找出擾動后的矩陣AK=UkWkVkT;
(4)用Ak的值更新數據庫D,形成新的矩陣D′;
(5)在矩陣 D′中對保密數據的屬性進行聚類分析。
2.2 算法示例
樣本數據如表1所示,在隱私保護的第一階段采用匿名保護,用編號代替被采樣者,假設已經去除了標識符(如姓名、身份證號碼、地址等)。在這個樣本中我們比較關注年齡和年薪兩個屬性,假設數據的使用者想利用這些人的年齡和年薪對他們進行分類。但是這些屬性值都是保密的信息,即要對這兩個屬性進行隱私保護。
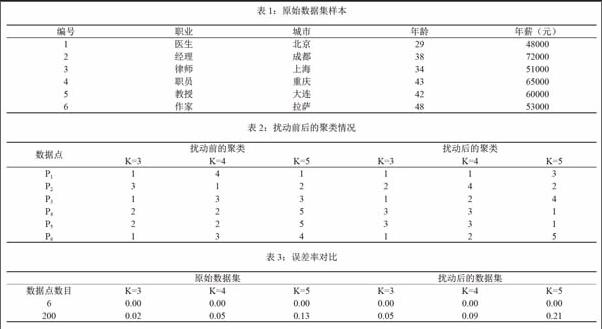
為了達到隱私保護的目的,我們利用SVD-clustering模型對數據進行擾動。圖2顯示經過擾動后各個數據對象在擾動前后聚類中的相對距離。
3 實驗結果分析
為簡單起見,我們只考慮轉化兩個隱私數據屬性,年齡和年薪。每次聚類包含6個數據點,在表2中,分別表示包含年齡和工資兩個屬性的六個數據點。在擾動前,當K=3時,對象1,3,6在聚類1中,對象4,5在聚類2中,對象2在聚類3中,在數據擾動后,當K=3時,數據1,3,6在聚類1中,對象2在聚類2中,對象4,5在聚類3中。
實驗的效率根據原始數據和擾動后數據的合法點聚類檢測出來的。在進行數據擾動后聚類的簇元素和原始數據聚類后的簇元素應該一致,但是在數據擾動過程中可能存在一些潛在的問題:一些噪音點中斷了聚類過程;一個聚類中的數據點變成噪音點;一個數據點從一個聚類轉移到另一個聚類。由于我們采用的K-means聚類算法已經消除了噪音,所以我們驗證結果的時候只考慮第三種情況。
3.1 誤差率分析
其中,N 代表原始數據集 D中點的個數,k 為聚類的個數,D'為擾動后的數據集,|Clusteri(D)|代表第 i個聚類中的合法數據點的個數。從表3中可以看到,利用SVD-clustering算法得到的誤差率在0.1% 左右,可以證明我們的算法在數據擾動前后聚集的準確性非常好。
3.2 相對誤差分析
當一個數據矩陣擾動后,它的屬性值也發生改變,數據值的變化可以用范數的相對誤差表示。這樣,可以用RE(Relative Error)表示原始值D到擾動后的屬性值D′的變化。
其中||D||F是矩陣D的歐式范數,D'為擾動后的數據集。可以看出,RE的數值越大,表明數據擾動的程度越大,即數據的保密性能越好。
4 結論
我們提出一個奇異值分解的聚類方法,用來擾動保密數值的屬性,以滿足銀行客戶隱私保護的要求,同時保留K-means聚類分析的一般特點.實驗結果表明,該方法在高準確性隱私保護應用中非常有效,保證聚類挖掘結果正確性的基礎上,對數據集中的敏感屬性也進行了很好的隱私保護。
參考文獻
[1]R.Agrawal,R.Srikant.Privacy-preserving data mining.in:Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data,2000,439-450.
[2]J.Wang,J.Zhang,W.Zhong,S.Xu,A novel data distortion approach via selective ssvd for privacy protection.2009.
[3]V.Verykios,E.Bertino,I.Fovino,L.Provenza,Y.Saygin,Y.Theodoridis. State-of-the-art in privacy preserving data mining.ACM SIGMOD Record,2014,3(01):50-57.
[4]L.Hubert,J.Meulman,W.Heiser.Two purposes for matrix factorization: a historical appraisal.SIAM Review,2009,42(04):68-82.
[5]張國榮,印鑒.應用等距變換處理聚類分析中的隱私保護[J].計算機應用研究,2015(07):83-86.
[6]黃偉偉,柏文陽.聚類挖掘中隱私保護的幾何數據轉換方法[J].計算機應用研究,2006(06):180-184.
作者簡介
季文韜(1986-),男,河南省南陽市人。主要研究方向為隱私保護數據挖掘。
魏巍 (1992-),男,河南省南陽市人。主要研究方向為數據處理。
作者單位
1.中國農業銀行成都青羊支行 四川省成都市 610015
2.電子科技大學成都學院通信與信息工程系 四川省成都市 610500
