個人信用評分模型比較數據挖掘分析
2017-03-25 22:21:13李卯
時代金融 2017年6期
李卯
【摘要】為了有效控制和防范信貸風險,商業銀行必須對借款人做出準確的信用評估。本文通過利用傳統的Logistic回歸與隨機森林模型,分別建立信用評分模型,并比較兩個模型的優缺點以達到最佳的預測效果,從而有效的降低商業銀行的個人信用評估風險,更好地實現銀行利潤最大化。
【關鍵詞】信用評分 Logistic回歸 隨機森林
一、引言
常用的信用評分技術一般分統計學方法和非統計學方法。統計學方法包括線性回歸、判別分析、Logistic回歸,決策樹等,非統計學方法包括線性規劃、神經網絡、遺傳算法等。但是對于這些開發信用模型的技術,哪種方法最好,還沒有一致的結論。
Logistic回歸方法以其強大的穩健性和泛化能力被較多地應用到評估方法中;神經網絡對不完全信息具有很強的處理能力,能夠解決現實生活中的非線性問題,而且分類精度非常高,也是優先選擇的信用評估方法;支持向量機能處理小樣本、高維度的數據,并且獲得較高的分類精度,對處于發展階段的信用評估系統也是一個不錯的選擇。
總的來說評價指標體系被分為兩大類:體現還款能力的指標和體現還款意愿的指標。這些指標相對較容易獲得,并且能在一定程度上反映個人的真實還款能力和還款意愿,但是這些指標比較片面,容易出現誤判,而且門檻非常高。
本文以真實的信貸數據為分析對象,使用常見的Logistic回歸、隨機森林來進行研究。利用它們分別建立模型,對客戶進行分類,并比較模型預測結果。對比發現,兩個模型都有一定的預測能力,能將好壞客戶適度地區分開來。
二、樣本數據
本文建模時所采用的數據集Credit是一家數據挖掘網站上提供的真實數據,客戶資料為一家德國信貸銀行的信貸審批數據(German Credit data)。該數據包含了個人客戶在向銀行提出貸款申請時所提供的個人信息(如:性別、年齡、資產情況等)。其中該數據包括1000條記錄,定義了兩類信用卡客戶,第一類為700個“好客戶”,第二類為300個“壞客戶”。該數據集中有21個變量,其中20個是特征變量(自變量),而good-bad是響應變量(因變量)。
三、實證研究
(一)Logistic回歸分析
在建立Logistic回歸模型時,隨機選取700樣本作為訓練集,余下300樣本作為測試集,以0.5為概率界限,對訓練集樣本和測試集樣本中的客戶進行預測分類。
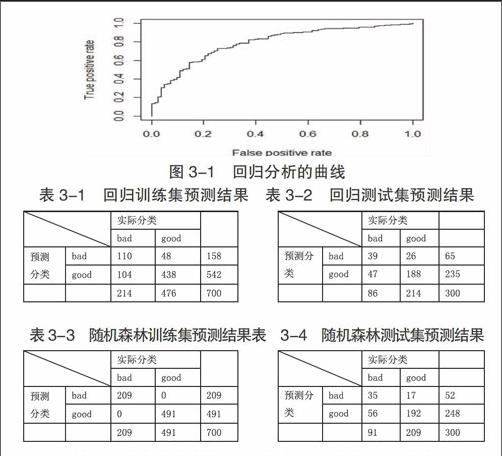
本文利用軟件選用逐步變量選擇法,從模型的輸出結果中,可以計算出一個客戶是一個好客戶的概率:首先,使用樣本中為“好客戶”的比率作為閾值。對整個數據集進行預測,雖然總的精度達到0.74,但是對于“壞客戶”的預測錯誤率為74/(12+74)=0.86,沒有達到理想中的效果。當閾值為0.5時預測效果沒有達到理想狀況,因此嘗試采用曲線來選擇最佳的診斷界限值,使用軟件得出回歸分析的曲線如圖3-1所示。
通過曲線確定的閾值,并由此進行預測,其分類混合矩陣如下所示。
由預測結果可知,測試集樣本預測結果精度高達0.76,而且“壞客戶”預測為“好客戶”的錯誤率下降到26/(39+26)=0.4。采用ROC曲線來確定閾值,對訓練集來說,這種預測方式不僅總的預測精度得到提升,更重要的事對“壞客戶”的預測精度得到提升,因為預測成功可能產生違約風險的“壞客戶”對于銀行來說才是最重要的。
(二)隨機森林分析
本文選取500顆樹在訓練集上建立隨機森林模型,與Logistic回歸一樣,隨機選取700樣本作為訓練集,余下300樣本作為測試集,在測試集上進行預測。通過基于OOB數據的模型誤判率均值確定隨機森林模型當mtry數值為10時誤差最小。
由結果可以看到,訓練樣本誤差率為0,測試樣本誤差率為(56+17)/300=0.24。從結果看,隨機森林預測結果的誤差率是比較小的。
四、總結
在將信用好的客戶判定為信用不好的客戶從而拒絕其貸款申請的方面,無論是訓練樣本還是測試樣本,其預測正確精度是:隨機森林大于Logistic回歸模型;在第二類誤判,即將信用不好的客戶判定為信用好的客戶從而接受其貸款申請方面,無論是訓練樣本還是測試樣本,其預測正確精度是:隨機森林大于Logistic回歸模型(一般而言,在銀行和其他金融機構的實際操作中,第二類誤判給銀行造成的損失更大)。從整體分類精度來看,隨機森林的整體預測精度能達到75%以上,而傳統的Logistic回歸模型整體分類精度只能達到70%左右。
從以上分析可以得出,兩種方法都可用于信用評分模型,其中Logistic回歸目前在信用評價領域應用最為廣泛,而隨機森林算法是數據挖掘領域較為成功的算法。從預測結果也可以看出,模型的穩健性是Logistic回歸的優點,而缺點在于其預測精度不如隨機森林等數據挖掘算法;對于隨機森林算法,其模型的訓練效果和預測精度都很好。綜上所述,本文認為利用隨機森林算法建立信用評分模型比較合適的方法。
傳統的分析方法與新型的機器學習方法各有利弊,在選擇和運用時要注意具體情況。在此也可以做出如此猜想,將傳統的分析方法與機器學習相結合使用。例如,可嘗試采用參數方法與非參數方法相結合的方式建立混合模型,即用決策樹或隨機森林提取特征變量交互作用項,引入到回歸方程中,從而完善Logistic回歸,起到變量選擇,考慮交互作用項的作用。
在國際金融危機背景下,利用先進的計量分析技術構建有效的消費者信用評估體系成為平衡控制風險與追求增長的關鍵。消費者信用評估是通過建立信用評分模型,對信貸申請客戶的后續信用行為進行預測,并基于客戶的特征變量將其劃分為“好客戶”和“壞客戶”,其分類精度直接關系信貸的風險。
參考文獻
[1]任瀟,姜明輝,車凱,王尚.個人信用評估組合模型選擇方案研究[J].哈爾濱工業大學學報,2016(5),67-71.
[2]朱曉明,劉治國.信用評分模型綜述[J].統計與決策,2007(2):103-105.
[3]蕭超武,蔡文學,黃曉字,陳康.基于隨機森林的個人信用評估模型研究及實證分析[J].管理科學,2014(6):111-113.
[4]王帥.個人信用評分混合模型研究[D].華東師范大學碩士學位論文,2010.
[5]張麗娜,趙敏.我國商業銀行個人信用評分指標體系分析[J].市場周刊(理論研究),2007(8):115-117.
