基于綜合聚類的供電服務滿意度測評樣本分配研究及應用
2017-03-23 22:35:12樊立攀田曉霞黃徐珂
湖北電力 2017年2期
樊立攀,葉 利,田曉霞,尚 凡,黃徐珂
(1.國網湖北省電力公司客戶服務中心,湖北 武漢 430077;2.國網武漢供電公司,湖北 武漢 430013)
0 引言
近年來,供電服務工作面臨著創新服務方式和全面提升服務質量的緊迫要求。開展供電服務滿意度測評已成為衡量供電服務質量的重要指標。整個測評過程包含以下4個重要環節:構建指標體系、計算指標權重、分配調研樣本、錄入數據并計算滿意度得分。樣本分配方法的選取直接決定了供電服務滿意度測評數據的客觀性和真實性。在實際測評中,樣本分配方案僅從用電水平上區分各地市公司的樣本量,造成各個地市樣本區分度不高、樣本集代表性差的問題。
國內外相關文獻中,客戶滿意度測評樣本分配大多采用單一用電特性結合分層抽樣為基礎的方法[1]。文獻[2]提出基于明顯用電特征和對用戶類型進行分層抽象的方案,該方案在一定程度上優化了樣本集,但沒有全面考慮影響樣本集代表性的因素。文獻[3]中使用基于細分業務和抽補的樣本分配方案,保證了樣本分布與總體分布的近似一致。文獻[4]根據服務類別和客戶類別2個維度對樣本進行分配,但對數據維度充分性以及重要度特征考慮不足。因此需要優化樣本集選取,使樣本區分度較高,樣本集代表性較強。
針對上述問題,本文在充分研究樣本分配影響因素的基礎上,挖掘具有樣本集代表性的屬性因素,將其納入分層抽樣的分配原則中,用以提高樣本的區分度和代表性。在樣本分配中,保證所有地市的樣本量滿足置信度和抽樣誤差的要求,對于缺失數據進行插補數據預處理,建立基于綜合聚類的樣本分配方案,最后通過實例驗證了該方案的實效性和可行性。
1 調查樣本容量分析
樣本量大小的選取直接影響測評的精準度,測評的精準度越高,需要調查的樣本數和涉及面就越多,同時工作的難度和復雜度也越高。因此需要在保證抽樣調查對估計數據的精確度,盡量減少調查單位數,確保必要的抽樣數目。
根據統計學原理:

其中:n代表所需要的樣本量;
t代表概率度,一般置信度95%時,t=1.96;
p代表總體方差,一般取0.5;
d代表抽樣誤差。
根據式(1)可知,當選定樣本量為16 000時,此時的樣本水平滿足95%置信度下,抽樣誤差為0.01%。根據綜合測評樣本和專項測評樣本3:13確定專項樣本份數為3 000份,綜合樣本份數為13 000份。
2 綜合聚類分析模型
2.1 K-means聚類原理及其具體思想
K-means聚類原理是數據點到原型的某種距離建立目標函數,利用函數求極值的方法得到迭代運算的調整規則。K-means聚類算法的優點主要集中在:
(1)K-means聚類算法原理簡單、易于編程實現;
(2)對大數據集有較高的效率并且是可伸縮性的;
(3)時間復雜度近于線性,而且適合挖掘大規模數據集。
計算各類聚類中心時,采用歐幾里德距離。歐幾里德距離的遠近與相似程度成反比。歐幾里德距離的計算公式如式2所示。
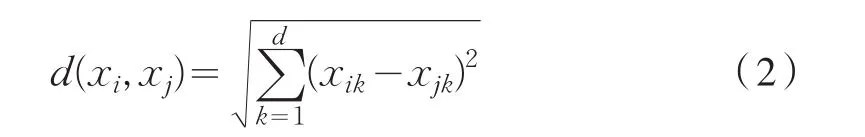
2.2 樣本聚類原則
聚類分析需選擇合適的聚類原則才進行不同分類。在綜合考慮地區經濟水平、用電特性和業務量水平3個方面的因素上,選取每類顯著性特征因素(人均GDP、客戶數和萬戶業務量)進行分類分析。
(1)人均GDP:根據相關研究,人均GDP與人均用電量呈正相關,用戶使用電能和用電場合也會相應增多,與電力部門接觸的頻率也相對較多。因此對人均GDP較高的地區,也應當投入較多的精力進行供電服務客戶滿意度調查。
(2)客戶數:一般情況下,客戶數與售電量成正相關,地區客戶數越多,則該地區的總售電量也越多。用電客戶和售電量越多,則客戶與供電服務接觸的頻率也越高。
(3)萬戶業務量:萬戶業務量越大,則電網和客戶接觸的接觸次數就越多。在辦理業務的過程中,客戶能直觀地對電力部門及電力工作人員的相關工作情況留下一定印象,這一印象則會在某些方面對供電服務滿意度評價起決定性作用。
2.3 樣本缺失預處理
在測評工作開展的實際過程中,樣本數據會產生一定的缺失。針對這種情況,必須采取一定的數據預處理手段,目前常用的數據預處理手段主要采用插補法,插補法包括均值插補、眾數插補、中位數插補等。
(1)均值插補:均值插補是指對所有的缺失數據,用所有回答單元觀測值的均值進行插補,通過均值插補方法處理數據,能有效地減少缺失數據對最終結果的影響。因此,當樣本缺失數過大時,采用均值插補。
(2)眾數插補:當非缺失數據為非對稱分布,且僅有一個眾數時,此時最宜采用眾數插補。眾數代表了一組數據中出現最多的變量值,其不受極端值影響,能夠體現一組數據的主流趨勢。在樣本信息較大的情況下,眾數插補能夠最大程度地保持樣本的特征及趨勢。
(3)中位數插補:當數據信息呈非對稱分布,且不存在眾數或存在多個眾數時,此時宜采用中位數插補的方法。利用中位數插補法能夠保證插補值與其他數據的離差最小,從而保證整體數據的整體均衡性。
對于數據信息Xi,通常有以下四種數據分布,如圖2-圖4所示:

圖1 左偏分布 Fig.1 Left-skewed

圖2 右偏分布Fig.2 Right-skewed

圖3 對稱分布Fig.3 Symmetrical
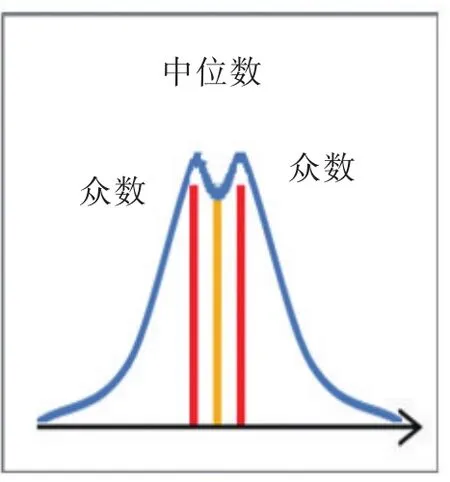
圖4 眾數分布Fig.4 Polymodal
(1)當數據信息如圖1所示呈左偏分布時,其眾數>中位數>平均值,應采用眾數插補;
(2)當數據信息如圖2所示呈右偏分布時,其眾數<中位數<平均值,應采用眾數插補;
(3)當數據信息如圖3所示呈對稱分布時,其眾數=中位數=平均值,應采用均值插補;
(4)當數據信息如圖4所示,存在多個眾數,應采用中位數插補。
綜上所示,樣本缺失預處理流程如下:首先判斷缺失數據是否超過閥值(本測評數據缺失20%以上,視為超過閾值),若缺失值未超過閥值,則分析非缺失數據的分布,根據不同的數據分布,采用不同的方法對缺失數據進行數值插補。插補模型流程圖如圖5所示。

圖5 插補模型流程圖Fig.5 Interpolation flowchart
3 基于綜合聚類的樣本分配方案

式中,Scorecity——各地市綜合指數。
根據式3,可計算出各地市歸一化綜合指數。將歸一化綜合指數進行降序排列,由等距選取原則選出第1、5、10、14名地市公司作為初始聚類中心,城市類別的物理含義如下:A、B、C、D類城市分別代表代表人均GDP、客戶數、萬戶業務量的綜合水平處于高水平、中高水平、中低水平、低水平。
由于同一類城市的區域經濟性、用電特性、業務量水平相近,所以對于同一類城市,采用相同的抽樣比。全省平均抽樣比為0.74‰。四類城市按照A、B、C、D類順序,抽樣比在全省抽樣比的±n%范圍內依次遞減。n的取值根據實際情況選取,本報告僅例取n=10為例,即A、B、C、D類城市的抽樣比在全省抽樣比0.74‰*(100%±10%)=0.67‰~0.81‰之間依次遞減。在保持每個地市的樣本符合抽樣誤差和置信度的最低要求和分配結果的比例特性的前提下,對結果進行取整微調,使專項綜合樣本比例大致保持在13:3,最終分配結果如表1。
3.1 各單位樣本總體分配
利用K-means動態聚類對上述14個地市進行分類。本方案擬將14個地市供電公司分為A、B、C、D四類等級,引入地市歸一化綜合指數值的概念量表征各個地市公司的綜合水平,該地市的綜合指數可由該地市的歸一化人均GDP、歸一化客戶數和歸一化萬戶業務量直接相加得到,即:
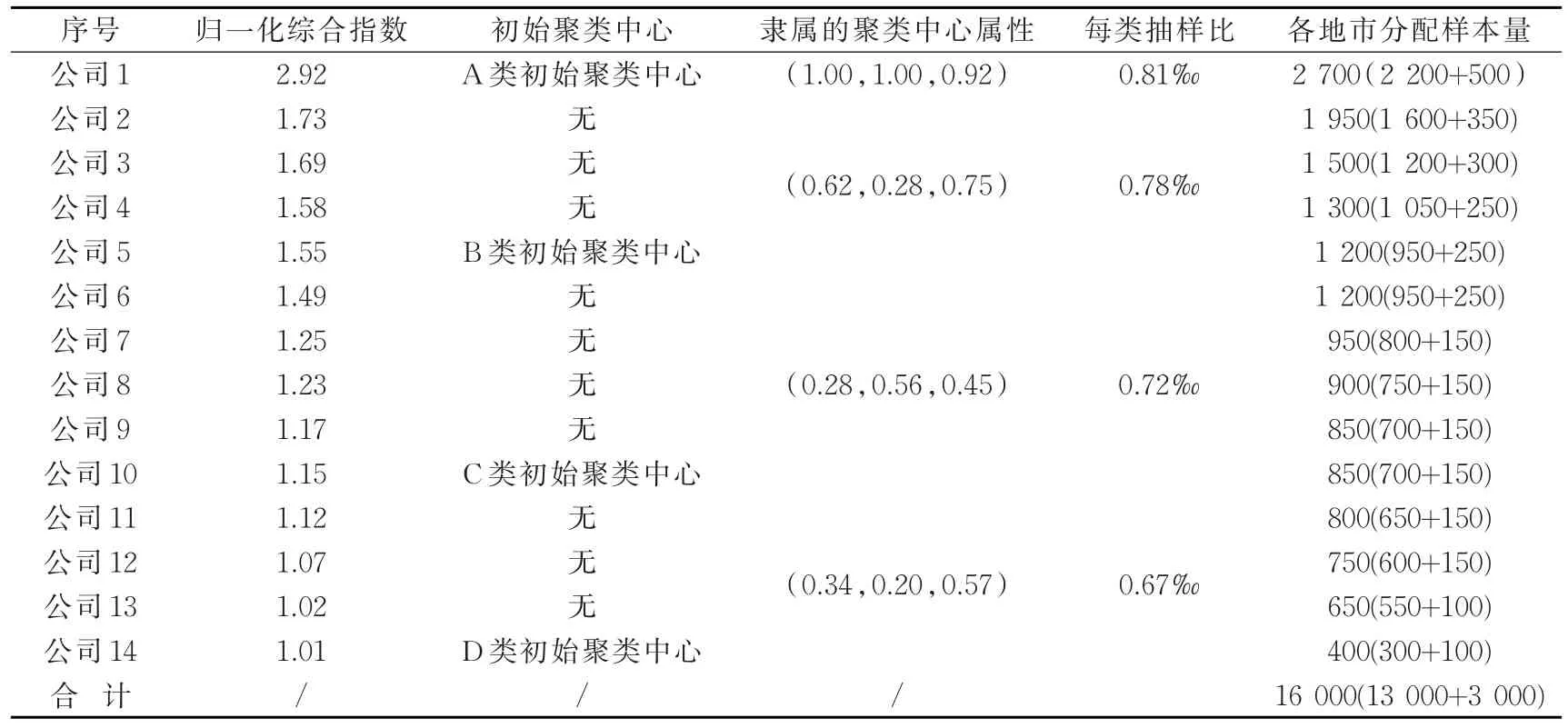
表1 各單位屬性信息和樣本分配結果Tab.1 Attribute information and sample allocation results
3.2 綜合樣本各類客戶樣本分配
各單位客戶將分為5個類別進行抽樣,分別為大工業客戶、一般工商業客戶、政府事業單位客戶、城鎮居民客戶、農村居民客戶。考慮到大工業客戶和政府事業單位客戶的數量較少。因此這兩類客戶根據每個地市的綜合樣本量采取分級定量分配。
一般工商業客戶、城鎮居民客戶、農村居民客戶的樣本容量則根據2016年上半年的用電結構數據計算得出。具體計算公式如下:
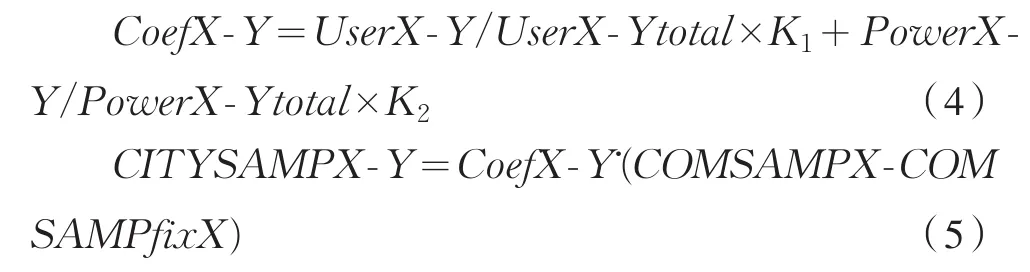
式中,CoefX_Y——地市供電公司各類客戶系數,表示X地市中的Y類客戶系數;
UserX_Y——X單位中的Y類客戶數;
UserX_Ytotal——X單位3類總客戶數;
PowerX_Y——X單位Y類客戶近一年售電量;
PowerX_Y total——X單位3類客戶近一年的總售電量;
CITYSAMPX_Y——X單位Y類客戶樣本數;
COMSAMPX——X單位綜合樣本量;
COMSAMPfixX——X單位定量客戶樣本量;
K1、K2——待定系數。
其中K1、K2取值如下:
結合實際情況,K1=0.6,K2=0.4,各單位各類客戶樣本量分配如表2所示。

表2 各供電單位綜合樣本各類客戶分配結果Tab.2 Comprehensive allocation results
3.3 各地市單位專項樣本分配
各單位專項指標為業擴報裝服務、供電質量服務、抄表交費服務、營業廳服務、信息渠道服務、故障搶修服務和投訴處理服務。在計算過程中,六個專項指標的重要程度由指標權重決定。綜合考慮上述原因,2016年各地市各專項指標樣本量之比為1,如表3所示。

表3 各地市各專項分配結果Tab.3 Specialized allocation results
3.4 分配數據缺失處理
2015年,滿意度測評缺失數據情況如表4所示。
將原處理方法(缺項取‘0’值處理)與均值處理方法的結果作對比,如表5所示。

表4 滿意度測評缺失數據匯總Tab.4 Missing data aggregation

表5 原處理方法(缺項取‘0’值處理)與綜合插補處理方法的結果對比Tab.5 Comparison between original method and comprehensive interpolation
通過上述分析,即超過90%的地市公司將不會對綜合插補處理后的排名產生抱怨。因此說明了對缺失項采用綜合插補方法相對原來的采用‘0’值的處理方法要更加合理。
綜上,基于綜合聚類的滿意度測評樣本方法分配方案整體流程如圖6所示。

圖6 基于綜合聚類的樣本分配方案流程圖Fig.6 Sample allocation flowchart based on comprehensive clustering
4 結語
本文提出了一種綜合聚類樣本分配方法,通過綜合考慮影響樣本分配的各項因素,選取強關聯性因素聚類分配,使樣本分配結果更加突出各個測評單位的差異性,采用多種數據插補處理模型,減少了數據缺失造成的誤差。依據此方案進行樣本分配,能有效改善樣本結構,使樣本分配結果更加客觀、科學,方便后續樣本的分配。
(References)
[1] 王鶴,張婷.基于服務藍圖的電力客戶滿意度評價研究[J].華北電力大學學報(社會科學版).2007,2(4):7-11.WANG He,ZHANG TingJournal.Research on electric customer satisfactory evaluation based on the service blueprinttheory.JournalofNorth China Electric Power University(Social Sciences),2007,2(4):7-11.
[2] 莊凌暉.如何制定科學合理的供電客戶滿意度抽樣調查方案[J].中國電力教育,2011(15):84-85.ZHUANG LinHui.How to set up a scientific and reasonable sampling survey of Customer satisfaction.China Electric Education,2011(15):84-85.
[3] 羅智超,吳育青.基于電力細分業務抽樣調查的客戶滿意度模型[J]廣東電力,2010,23(11):64-66.LUO Zhichao,WU Yuqing.Customersatisfaction model based on sub electric business sampling[J].Guangdong Electric Power 2010,23(11):64-66.
[4] 張立娟,張克眾.提高基層供電服務滿意度策略分析[J].電力需求側管理,2015,17(1):49-51.ZHANG Lijuan,ZHANG Kezhong.Strategy analysis of improving service satisfaction of basic level power supply[J].Power DSM 2015,17(1):49-51.
[5] 王平,鄒珊剛.電力行業用戶滿意度指數模型構建與實證研究[J].武漢理工大學學報(信息與管理工程版),2006,28(3):145-149.Wang Ping,Zou Shangang.Construction and empirical Analysis of the customers satisfaction index of chi?nese electricity industry[J].Journal of WUT(Informa?tion&Management Engineering)2006,28(3):145-149.
[6] 霍映寶,徐莉,吳國英.供電行業用戶滿意度模型構建及實證研究[J].管理學報,2009,12(6):1696-1701.HUO Yingbao,XU Li,WU Guoying.Construction and empirical analysis of the customer satisfaction model for power supply industry[J].Chinese Journal of Management,2009,6(12):1696-1701.
[7] 霍映寶.供電服務質量與客戶滿意關系的實證研究[J].統計與信息論壇,2008,5(10):39-43.HUO Yingbao.An empirical research on the rela?tionship between power supply service quality and customer satisfaction[J].Statistics&Information Fo?rum,2008,5(10):39-43.
猜你喜歡
工會博覽(2023年3期)2023-04-06 15:52:34
小康(2021年7期)2021-03-15 05:29:03
鐵道通信信號(2020年9期)2020-02-06 09:15:22
活力(2019年19期)2020-01-06 07:34:38
雜文月刊(2019年15期)2019-09-26 00:53:54
今日農業(2019年12期)2019-08-15 00:56:32
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
