改進粒子群優化的分段在線盲信號分離算法*
2017-03-16 07:22:37張立毅
計算機與生活 2017年3期
王 哲,張立毅,2,陳 雷,2,3+,李 鏘
1.天津大學 電子信息工程學院,天津 300072
2.天津商業大學 信息工程學院,天津 300134
3.天津大學 精密儀器與光電子工程學院,天津 300072
改進粒子群優化的分段在線盲信號分離算法*
王 哲1,張立毅1,2,陳 雷1,2,3+,李 鏘1
1.天津大學 電子信息工程學院,天津 300072
2.天津商業大學 信息工程學院,天津 300134
3.天津大學 精密儀器與光電子工程學院,天津 300072
盲源分離(blind source separation,BSS)是指在混合系數未知的情況下,從混合信號中恢復出源信號的過程。在實時盲源分離問題中,學習速率的選擇對于算法的性能有著至關重要的作用。為了得到合適的學習速率,提出了如下盲源分離的步長選擇算法:通過衡量當前時刻輸出信號的依賴程度,將整個信號分離過程分為快速分離和精細分離兩個階段。在快速分離階段,應用粒子群優化算法確定學習速率,而在精細分離階段,采用分段函數來確定學習速率。仿真結果證實,新算法比使用固定或其他自適應學習速率的算法有更快的收斂速度和更好的穩態性能。
盲源分離(BSS);學習速率;分階段學習;粒子群優化
1 引言
盲信號分離是指僅根據觀測到的混合數據向量來恢復原始信號或信源,而在這一過程中混合矩陣未知。它在生物醫學信號處理[1]、圖像處理[2]與語音識別[3]等領域都有著廣闊的應用前景。
盲信號的分離算法分為離線和在線兩種。其中離線方法[4]收斂快,穩定性好,但是不適用于實時處理,因而在許多場合并不適用。而在線方法[5-9]雖然具體的形式不同,但是都屬于最小均方差(least mean square,LMS)算法,存在一個學習速率參數的優選問題。本文的主要研究內容是在線方法中學習速率參數的優選問題。
在LMS算法中,學習速率通常取常數,但這存在收斂速度與穩態性能之間的矛盾。當學習速率較大時,收斂速度較快,但是穩態性能差;而當學習速率較小時,穩態性能相對較好,但是收斂速度較慢。解決上述矛盾最簡單的方法是使學習速率隨時間而變化,如指數遞減等方法。但此類方法涉及一些參數選擇的問題,當參數選擇不當時,分離結果并不理想。
在上述方法中,學習速率是提前確定的,稱之為非自適應的學習速率。此外,還有另一類方法稱之為自適應的學習速率。自適應學習速率的思想最早由Amari[10]提出。隨后人們提出了各種適用于LMS算法的自適應學習速率算法[11-12]。此外,由于BSS(blind source separation)的特殊性和重要性,人們又提出了一系列針對BSS的自適應學習速率算法[13-14]。
除此之外,還有一些基于當前分離狀態來確定學習速率的方法。Zhang等人[15]提出了分階段學習的方法。這種方法有著很好的穩態性能,但是如果想要獲得很快的收斂速度,函數的選擇十分困難。Lou等人[16]用一個模糊系統去決定學習速率。這種方法可以達到較好的分離效果,但是需要建立隸屬函數和模糊推斷系統。Hsieh等人[17]利用改進的粒子群優化方法來確定學習速率。這種方法獲得了很快的收斂速度,但是在分離后期存在較大的波動性。Ou等人[18]提出利用滑動參數組合兩個不同步長的分離系統。該方法在一定程度上緩解了系統收斂速度與穩態性能的矛盾,然而在組合兩個分離系統的過程中,引入了一系列參數,這些參數的選擇需要一定的經驗,且在不同環境下的參數選擇不同。
為了進一步加快算法的收斂速度并保持更好的穩態性能,受分階段學習方法[15]和改進粒子群優化方法[17]的啟發,本文提出了一個更為高效的方法來兼顧收斂速度和穩態性能。將整個信號分離過程分為兩個階段:快速分離階段和精細分離階段。快速分離階段希望通過盡可能少的數據來達到較好的分離結果。考慮到粒子群優化方法有著很快的收斂速度,因而將粒子群優化方法用于快速分離階段確定學習速率。而對于精細分離階段,希望選擇較小的學習速率來保證好的穩態性能,因此選擇較為平緩的函數來確定學習速率。
本文組織結構如下:第2章簡要回顧了盲源分離和粒子群優化的基本原理;第3章提出了改進粒子群優化的分段在線盲信號分離算法;第4章進行仿真實驗并分析實驗結果;第5章總結全文。
2 基本理論
2.1 盲源分離問題
盲源分離的混合模型可以表示如下:

式中,X(t)=[x1(t),x2(t),…,xm(t)]T是m路混合信號;S(t)= [s1(t),s2(t),…,sn(t)]T是n路源信號;A是m×n的未知混合矩陣。
盲源分離的目的是從混合信號x1(t),x2(t),…,xm(t)中恢復出源信號s1(t),s2(t),…,sn(t),而在這一過程中,并不知道混合矩陣A的值。為了簡化問題,此處假設m=n,即源信號數目與混合信號數目相同。令分離矩陣為W,維數為n×m,則解混系統定義如下:

式中,Y(t)=[y1(t),y2(t),…,yn(t)]T,它是對源信號的估計。
根據文獻[19],把互信息I(W)作為目標函數,則有:

式中,Λ是非奇異對角陣;P是置換矩陣。典型ICA(independent component analysis)算法可以寫為如下形式:
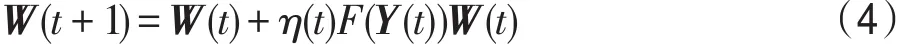
式中,η(t)表示學習速率,它的選擇直接影響系統的性能。針對不同的算法,F(Y(t))的選擇不同。
2.2 粒子群優化
粒子群優化(particle swarm optimization,PSO)算法最早是在1995年由Kennedy和Eberhart[20]提出的。粒子群優化屬于智能優化方法的一種,相比于傳統優化方法,它具有更快的計算效率和尋找全局最優的能力。
一個粒子群中包括許多粒子,每個粒子都是優化問題的一個潛在解。假設粒子數目為s,維數為D。針對單個粒子,一般有3個特征:當前位置xi,當前速度vi以及單個粒子的歷史最優位置pbesti;而考慮整個粒子群,則還有另一個特征為所有粒子的歷史最優位置gbest。每個粒子的移動是根據以上特征確定的。每個粒子的速度更新公式如下:

式中,i∈1,2,…,s表示粒子的數目;j∈1,2,…,D表示粒子的維數;vi,j表示第i個粒子在第j維上的速度;c1、c2稱為學習因子或加速系數,一般為正常數;ζ、ξ是在[0,1]上均勻分布的偽隨機數;k表示運動的代數。新的粒子位置計算如下:

在每一代變化后,需要考慮pbesti和gbest的更新問題:

式中,f表示代價函數。
Shi等人[21]將慣性權重w引入到PSO,很好地平衡了全局搜索能力與局部搜索能力。新的速度更新公式如下:

式中,w可以是一個正常數或是隨時間變化的函數。
Hsieh等人[17]將反轉因子T引入到PSO,擴大了粒子群的搜索空間。速度更新公式如下:
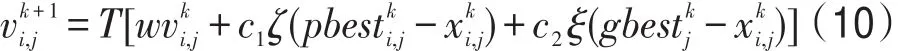
式中,T表示反轉因子。對于隨機選取一半粒子,T=1;而對于剩余粒子,T=-1。
3 基于改進粒子群的分段在線盲信號分離
本文把粒子群算法用于分階段學習中,從而提出了一種有效的方法來選擇合適的學習速率η(t)。
3.1 分階段分離
將整個信號的分離過程分為兩個階段:快速分離階段和精細分離階段。
在快速分離階段,主要希望通過盡可能少的迭代次數來使分離結果達到一個可接受的程度。在信號的實時分離過程中,因為存儲量有限,無法對所有的信號進行存儲,所以在訓練過程中損失的數據就無法再得到恢復。因此在快速分離階段,收斂速度是衡量算法性能的一個關鍵因素。
在精細分離階段,已經有了相對較好的分離結果,因此收斂速度在此時對整體性能影響并不大。而這一階段的主要任務有兩個:一是選擇合適的學習速率,進一步提高分離精度;另一方面則是保證分離過程中較小的波動。
接下來需要找到一個指標將整個分離過程進行分段。根據文獻[16],知道yi(t)和yj(t)的依賴程度可以由它們的二階相關度與高階相關度來衡量。其中二階相關性rij(t)及高階相關性hrij(t)定義如下:

式中,i,j=1,2,…,m且i≠j;ρ(yi(t))為非線性函數。
為了實現實時盲信號分離,需要遞歸地計算rij(t)和hrij(t)。假設輸出信號是廣義平穩的,則在任意時刻t,信號x(t)的均值計算如下:

式中,λ為遺忘因子,其取值在0到1之間。記Pij(t)=cov[ρ(yi(t)),yj(t)],Rij(t)=cov[yi(t),yj(t)],Qi(t)=cov[ρ(yi(t))],則有如下遞歸公式:

通過遞歸計算得到Rij(t)、Pij(t)和Qi(t)后,根據式(11)、(12),可以得到rij(t)和hrij(t)。
為了進一步衡量系統的總體分離狀態,又定義了如下函數[15]:

式中,Dij(t)表示第i路信號與第j路信號的依賴性。

式中,Di(t)表示第i路信號的分離程度。
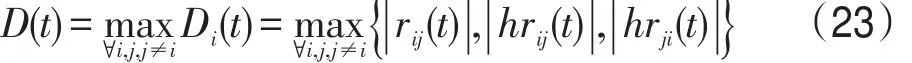
式中,D(t)表示所有信號的整體分離程度。根據D(t)可以對整個分離過程進行分段。當D(t)>0.25時,認為分離過程處于快速分離階段;而當D(t)≤0.25時,認為分離過程處于精細分離階段。
3.2 改進粒子群算法確定學習速率
對于快速分離階段,本文利用粒子群算法在每次迭代中選擇合適的步長,在保證系統穩定的前提下使得收斂速度盡可能快。
本文采用式(10)作為改進粒子群算法速度的更新公式。代價函數是粒子群算法中另一個重要的成分。Di(t)表示第i路信號的分離程度,人們希望Di(t)在學習過程中快速減小。根據極小極大原理,定義粒子群的代價函數如下:

粒子群算法的計算量通常較大,如果把每個時刻視為相互獨立,并在每一時刻都使用一次粒子群算法來確定當前時刻的學習速率,則很難滿足實時性要求。事實上,對于相鄰時刻而言,輸出信號的分離狀況是十分相似的。因此,不同時刻下的最優學習速率也是緩慢變化的。為了在分離性能和計算量之間取得平衡,在整個分離過程中,利用改進的粒子群優化算法來確定學習速率,而在每個時刻粒子群僅僅移動一代,并選擇當前的全局最優解作為當前時刻的學習速率。相鄰時刻的最優速率通常是相似的,因此將前一時刻的pbesti和gbest保留至下一時刻,用于影響新的時刻中粒子群的運動。
在文獻[17]中,為了保證在分離后期的學習速率維持穩定,將上一時刻的所有粒子位置都直接傳遞到新的時刻。然而,這種方法很容易使得整個粒子群過早地收斂。如果聲源位置發生變化,很難快速找到新的最優學習速率。由于僅僅將粒子群用于快速分離階段,而無須考慮分離后期的波動程度,對于每個新的時刻,都對粒子群的粒子位置進行重新初始化,只保留上一時刻的pbesti和gbest。通過在每個時刻最小化式(24)中的目標函數f,即可實現在保證系統穩定的前提下使得收斂速度盡可能快。
3.3 非線性函數確定多維學習速率
對于精細分離階段,人們希望學習速率的變化是平滑的。此外,在這一階段,可能有些信號已經先分離出來,而還有一些信號分離結果并不好,此時,不同的輸出成分需要不同的學習速率。因此,用Λ(t)來代替η(t),從而迭代公式(4)變為如下形式:

式中,Λ(t)=diag(η1(t),η2(t),…,ηm(t))。ηi(t)的取值取決于第i路信號的分離程度。當第i路信號的分離效果較好時,ηi(t)的取值較小,從而保證波動較小。而當第i路信號的分離效果較差時,ηi(t)的取值較大,從而提高算法的分離精度。而第i路的分離效果可以由Di(t)來衡量,ηi(t)是關于Di(t)的非線性函數[15]:

這類非線性函數保證了算法在精細分離階段有著較高的分離精度和很小的波動。
4 實驗分析
在本文的實驗過程中,4路信號如下:

式中,noise(t)服從[-1,1]的均勻分布。用于衡量高階相關性的非線性函數為。粒子數目為10,w=0.24,c1=c2=0.5。在快速分離過程中,步長為標量,因此粒子群的維數為1。相比文獻[17],本文粒子群的應用中不需要考慮分離后期的波動穩定,因此為了得到更快的收斂速度,粒子位置的取值在0.01~0.04間。
為了證實本文算法的有效性,對所有算法采用相同的迭代公式[22]:

式中,η(t)是由本文算法所確定的學習速率,?(Y(t))=Y2(t)sign(Y(t)),ψ(Y(t))=3tanh(10Y(t))。
為了評價算法的性能,引入串音誤差[23]crosstalking error)來評價算法性能:

式中,P=(pij)=WA;W表示計算得到的分離矩陣;A表示源信號混合過程中真實的混合矩陣。
4.1 聲源位置固定的實時盲信號分離
當聲源位置固定時,混合矩陣A是4×4的固定矩陣,即在混合過程中A不會發生變化。令A內元素服從[-1,1]的均勻分布,每次實驗中通過隨機確定混合矩陣A來得到混合信號。本文以10 kHz的速率對信號采樣,信號長度為3 000采樣點。將本文算法與定步長0.010、0.005、分階段算法[15]、改進粒子群算法[17]、組合系統[18]進行比較。

Fig.1 Cross-talking errors for fixed source locations圖1 聲源位置固定的串音誤差曲線
圖1表示了對于6種步長選擇算法的30次獨立運行得到的串音誤差均值的收斂曲線。從圖1中可以看出,在分離早期,本文算法具有較快的分離速度,從而保證了利用最少的數據集得到了較好的分離結果。同時,在分離后期,本文算法穩態性能較好,保證了分離系統的高精度。
表1列出了對于5種步長選擇算法的30次獨立運行得到的均值和標準差的平均值。為了能公平地比較系統在平穩階段的性能,取3 000個采樣點中最后100個點進行計算。串音誤差均值越小,則說明分離的精度越高。串音誤差標準差越小,則說明平穩階段的波動越小。從表1中可以看出,相比其他算法,本文算法有著更高的精度和更小的波動。

Table 1 Mean and standard deviation of cross-talking error for fixed source locations表1 聲源位置固定的串音誤差的均值和標準差
4.2 聲源位置可變的實時盲信號分離
在實際應用中,通常無法保證聲源的位置在混合過程中始終固定不變。對于線下的盲信號分離算法,很難處理源信號位置發生變化的情況。而對于實時盲信號分離算法而言,通過選擇恰當的學習速率,可以處理源信號位置可變的情況。
在實驗中,令A內元素仍服從[-1,1]的均勻分布。但在每次實驗過程中,在3 000采樣點時刻重新隨機選擇混合矩陣A的元素改變信號的混合方式,從而得到在混合過程中聲源位置發生變化的混合信號。信號的采樣頻率為10 kHz,信號長度為6 000采樣點。圖2為4路源信號經過兩種不同隨機混合方式后得到的混合信號。
圖3為對聲源位置發生變化的混合信號進行處理得到的分離信號。從圖3中可以看出,本文算法在3 000點時刻混合方式發生變化后,在經過大約500個采樣點后可以恢復較高的分離精度。

Fig.2 4 mixed signals for changed source locations圖2 聲源位置發生變化的4路混合信號

Fig.3 Separated signals from mixed signals for changed source locations圖3 從聲源位置發生變化的混合信號中得到的分離信號
圖4表示了對于6種步長選擇算法在聲源位置發生變化時得到的串音誤差均值的收斂曲線。從圖4中可以看出,本文步長選擇算法避免了改進粒子群算法[17]中的最優值過早收斂現象。在聲源位置發生變化后,保證了較快的分離速度和較高的分離精度。
5 總結
本文提出了一種高效的方法來選擇實時信號分離中的學習速率。將粒子群方法應用于分階段學習的快速分離過程中,一方面充分利用了粒子群算法在學習過程早期的快速收斂性;另一方面也克服了它在后期的不穩定性。實驗結果表明,本文步長選擇算法可以使在線實時分離具有更快的收斂速度與更高的分離精度。同時,此算法可以適用于混合過程發生變化的混合信號,在混合方式發生變化后,能在很短的時間內恢復出較高精度的分離信號。
[1]Acharjee P,Kalogeropoulou D,Douvis J.Independent vector analysis for gradient artifact removal in concurrent EEG-fMRI data[J].IEEE Transactions on Biomedical Engineering, 2015,62(7):1750-1758.
[2]Minh H Q,Wiskott L.Multivariate slow feature analysis and decorrelation filtering for blind source separation[J].IEEE Transactions on Image Processing,2013,22(7):2737-2750.
[3]Jun S,Kim M,Oh M,et al.Robust speech recognition based on independent vector analysis using harmonic frequency dependency[J].Neural Computing&Applications,2013,22 (7/8):1321-1327.
[4]Marchetti F,Pampaloni G.Efficient variant of algorithm fastICA for independent component analysis attaining the Cramér-Rao lower bound[J].IEEE Transactions on Neural Networks,2006,17(5):1265-1277.
[5]Riccardo B,Hong P,Roychowdhury V P.Independent component analysis based on nonparametric density estimation [J].IEEE Transactions on Neural Networks,2004,15(1): 55-65.
[6]Vrins F,Verleysen M.On the entropy minimization of a linear mixture of variables for source separation[J].Signal Processing,2005,85(5):1029-1044.
[7]Pham D T.Blind separation of instantaneous mixture of sources via an independent component analysis[J].IEEE Transactions on Signal Processing,2015,44(11):2768-2779.
[8]Cheng Hao,Yu Na,Liu Jun.Improved natural gradient algorithms for multi-channel signal separation[J].Applied Mechanics and Materials,2014,651-653:2326-2330.
[9]Fu G S,Phlypo R,Anderson M,et al.Blind source separation by entropy rate minimization[J].IEEE Transactions on Signal Processing,2014,62(16):4245-4255.
[10]Amari S.A theory of adaptive pattern classifiers[J].IEEE Transactions on Electronic Computers,1967,EC-16(3):299-307.
[11]Lee H S,Kim S E,Lee J W,et al.A variable step-size diffusion LMS algorithm for distributed estimation[J].IEEE Transactions on Signal Processing,2015,63(7):1808-1820.
[12]Sang M J,Seo J H,Park P G.Efficient variable step-size diffusion normalised least-mean-square algorithm[J].Electronics Letters,2015,51(5):395-397.
[13]Chambers J A,Jafari M G,Mclaughlin S.Variable step-size EASI algorithm for sequential blind source separation[J]. Electronics Letters,2004,40(6):393-394.
[14]Xu Pengcheng,Yuan Zhigang,Jian Wei,et al.Variable stepsize method based on a reference separation system for source separation[J].Journal of Sensors,2015(5):1-7.
[15]Zhang Xianda,Zhu Xiaolong,Bao Zheng.Grading learning for blind source separation[J].Science in China,2003,46 (1):31-44.
[16]Lou Shuntian,Zhang xianda.Fuzzy-based learning rate determination for blind source separation[J].IEEE Transactions on Fuzzy Systems,2003,11(3):375-383.
[17]Hsieh S T,Sun T Y,Lin C L,et al.Effective learning rate adjustment of blind source separation based on an improved particle swarm optimizer[J].IEEE Transactions on Evolutionary Computation,2008,12(2):242-251.
[18]Ou Shifeng,Gao Ying,Zhao Xiaohui.Adaptive combination algorithm and modified scheme for blind source separation [J].Journal of Electronics and Information Technology,2011, 33(5):1243-1247.
[19]Comon P.Independent component analysis,a new concept[J]. Signal Processing,1994,36(3):287-314.
[20]Eberhart R,Kennedy J.A new optimizer using particle swarm theory[C]//Proceedings of the 6th International Symposium on Micro Machine and Human Science,Nogoya,Japan, Oct 4-6,1995.Piscataway,USA:IEEE,1995:39-43.
[21]Shi Y H,Eberhart R.A modified particle swarm optimizer [C]//Proceedings of the 1998 IEEE World Congress on Computational Intelligence Evolutionary Computation,Anchorage,USA,May 4-9,1998.Piscataway,USA:IEEE,1998: 69-73.
[22]Cichocki A,Rummert E,Unbehauen R,et al.A new on-line adaptive algorithm for blind separation of source signals [C]//Proceedings of the 1994 International Symposium on Artificial Neural Networks,Tainan,China,Oct 15-18,1994: 406-411.
[23]Yang H H,Amari S I,Cichocki A.Information-theoretic approach to blind separation of sources in non-linear mixture[J].Signal Processing,1998,64(3):291-300.
附中文參考文獻:
[18]歐世峰,高穎,趙曉暉.自適應組合型盲源分離算法及其優化方案[J].電子與信息學報,2011,33(5):1243-1247.

WANG Zhe was born in 1992.He is an M.S.candidate at Tianjin University.His research interests include computational intelligence and blind source separation,etc.
王哲(1992—),男,山西太原人,天津大學人工智能實驗室碩士研究生,主要研究領域為智能計算,盲源分離等。

ZHANG Liyi was born in 1963.He received the Ph.D.degree from Beijing Institute of Technology in 2003.Now he is a professor at Tianjin University of Commerce and Ph.D.supervisor at Tianjin University.His research interests include signal detecting and processing,intelligence computation and information processing,etc.
張立毅(1963—),男,山西忻州人,2003年于北京理工大學獲得博士學位,現為天津商業大學教授,天津大學博士生導師,主要研究領域為信號檢測與處理,智能計算,信息處理等。

CHEN Lei was born in 1980.He received the Ph.D.degree from Tianjin University in 2011.Now he is an associate professor at Tianjin University of Commerce.His research interests include blind signal processing and hyper spectral imagery processing,etc.
陳雷(1980—),男,河北唐山人,2011年于天津大學獲得博士學位,現為天津商業大學副教授,主要研究領域為盲信號處理,高光譜圖像處理等。

LI Qiang was born in 1974.He received the Ph.D.degree in signal and information processing from Tianjin University in 2003.Now he is a professor and Ph.D.supervisor at Tianjin University.His research interests include intelligence information processing,filter design,digital system and micro-system design,etc.
李鏘(1974—),男,山西太原人,2003年于天津大學獲得博士學位,現為天津大學教授、博士生導師,主要研究領域為智能信息處理,濾波器設計,數字系統,微系統設計等。
Grading Learning Based on Improved Particle Swarm Optimization Blind Source Separation*
WANG Zhe1,ZHANG Liyi1,2,CHEN Lei1,2,3+,LI Qiang1
1.School of Electronic and Information Engineering,Tianjin University,Tianjin 300072,China
2.School of Information Engineering,Tianjin University of Commerce,Tianjin 300134,China
3.School of Precision Instrument and Opto-electronics Engineering,Tianjin University,Tianjin 300072,China
+Corresponding author:E-mail:chenleitjcu@126.com
The purpose of blind source separation(BSS)is to recover the unknown source signals from their linear mixtures without the knowledge of the mixing coefficients.For real-time BSS,the learning rate has an important influence on the algorithm performance.In order to select an appropriate learning rate,this paper proposes an efficient algorithm.According to the dependence between separating signals in current timeslot,the whole signal separation process is divided into two stages:the rapid separation stage and the precise separation stage.A particle swarm optimization method is applied to the rapid separation stage to determine the learning rate,and the learning rate in the precise separation stage is decided by a piecewise function.Simulation experiments demonstrate that significant improvements of convergence speed and stability are achieved by the proposed algorithm when compared to fixed or other adaptivelearning rate methods.
blind source separation(BSS);learning rate;grading learning;particle swarm optimization
10.3778/j.issn.1673-9418.1604055
A
:TN911.7
*The National Natural Science Foundation of China under Grant No.61401307(國家自然科學基金);the Postdoctoral Science Foundation of China under Grant No.2014M561184(國家博士后科學基金);the Application Infrastructure and Cutting-Edge Technology Research Projects of Tianjin under Grant No.15JCYBJC17100(天津市應用基礎與尖端技術研究項目).
Received 2016-04,Accepted 2016-06.
CNKI網絡優先出版:2016-06-23,http://www.cnki.net/kcms/detail/11.5602.TP.20160623.1139.002.html
WANG Zhe,ZHANG Liyi,CHEN Lei,et al.Grading learning based on improved particle swarm optimization blind source separation.Journal of Frontiers of Computer Science and Technology,2017,11(3):365-372.
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國生殖健康(2019年3期)2019-02-01 06:12:26
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
