基于Scrapy的工業漏洞爬蟲設計
2017-03-10 21:46:05孫歆戴樺孔曉昀趙明明
網絡空間安全 2017年1期
孫歆++戴樺++孔曉昀++趙明明

【 摘 要 】 工業控制系統的漏洞是工業安全中極其重要的資源信息,也是對工控系統進行威脅分析和安全等級鑒定的重要依據。論文設計實現了一個基于Scrapy的工業漏洞網絡爬蟲,能對工控系統安全漏洞網站上的漏洞信息進行抓取和分析,并進行結構化處理,為實際項目開發提供重要的漏洞數據信息。
【 關鍵詞 】 工業控制系統;工控漏洞;爬蟲;Scrapy
Design of Industrial Vulnerabilities Web Crawler Based on Scrapy
Sun Xin 1 Dai Hua 1 Kong Xiao-yun 2 Zhao Ming-ming 3
(1.Electric Power Research Institute of State Grid Zhejiang Electric Power Company ZhejiangHangzhou 310014;
2.State Grid Zhejiang Electric Power Company ZhejiangHangzhou 310008;
3. Beijing China-power Information Technology Co., Ltd. Beijing 100192)
【 Abstract 】 Industrial control system vulnerabilities are extremely resource information of industrial activities on industrial safety, and they are also an important basis for the threat analysis and safety identification of industrial control system. This paper designed and implemented a web crawler for industrial vulnerabilities that based scrapy framework. The crawler can crawl and analyze vulnerability information on web sites, and provide structured vulnerability imformation for actual projects.
【 Keywords 】 industrial control system;industrial vulnerabilities;web crawler;scrapy
1 引言
互聯網信息資源的極速增長使得基于傳統搜索引擎獲取信息的方式越來越難以滿足人們對有效信息的獲取要求。而當所需的信息體量大時,采用純人工采集數據信息更是無法滿足生產需求。針對這樣的情況,使用某種自動化技術實現從互聯網上自動采集符合需求的結構化信息是非常有必要的。
網絡爬蟲是一種能夠實現對互聯網信息資源進行自動采集整理的程序,它彌補了人工采集的缺陷。通過網絡爬蟲不僅能夠為搜索引擎采集網絡信息,而且可以作為定向信息采集器,采集定制網站下的特定信息,如商品信息,漏洞信息等。
2 網絡爬蟲
2.1 爬蟲概述
網絡爬蟲[1] (Web Crawler)通常又被稱為網絡蜘蛛(Web Spider),是一個能夠自動在互聯網上漫游并可以自動下載網頁進行信息結構化提取的程序或者腳本。網絡爬蟲的特征鮮明[2],主要體現在三個方面。
(1)強壯性好,網絡爬蟲的程序具備超強的執行力。
(2)智能性好,主要體現在獲取和分析Web頁面以及利用URL鏈接進行爬行等方面。
(3)能夠將Web信息進行過濾存儲等。
網絡爬蟲按照系統結構及其實現技術,大致可分成四種[3]類型:通用網絡爬蟲[4](General Purpose Web Crawler)、聚焦網絡爬蟲[5](Focused Web Crawler)、增量式網絡爬蟲[6](Incremental Web Crawler)、深層網絡爬蟲(Deep Web Crawler)。實際應用過程中爬蟲系統通常是由幾種爬蟲技術相結合實現的。
2.2 Python與爬蟲
當前主流的編程語言都有自己的爬蟲框架,如Java有Nutch、C++有Larbin,Python有Scrapy等。由于本文設計的爬蟲是基于Python語言的,所以在這里主要討論運用Python語言來設計實現爬蟲系統。
2.2.1 Urllib與爬蟲
Urllib是python語言的一個模塊,在編寫爬蟲程序時主要功能是利用該模塊提供的方法(Urlopen、Urlretrieve)進行網頁下載,再結合正則表達式re模塊以及Beautifulsoup模塊對網頁上的信息進行結構化提取。
2.3.2 Scrapy與爬蟲
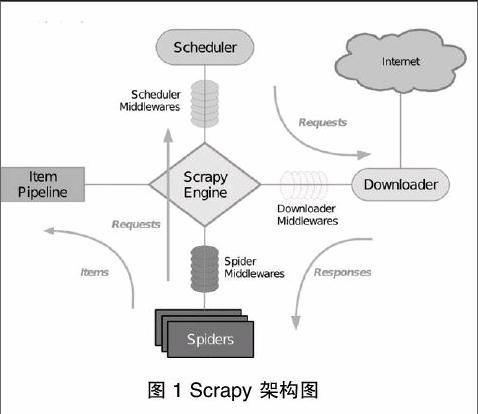
Scrapy[7]是一個基于Twisted[8],可以爬取并結構性提取網站數據的異步爬蟲應用框架。它用途廣泛,常被應用于數據挖掘、信息處理等場景。Scrapy 設計理念先進而簡單,效率高、可擴展性好,可移植性佳(在主流的操作系統平臺上都具備良好的性能)Scrapy由引擎(Engine)、調度器(Scheduler)、下載器(Downloader)、蜘蛛(Spiders)和數據管道(Item Pipeline)五大部分組成,其中還包括各種輔助中間件(Middlewares)協同實現爬蟲的精細功能。
(1)引擎:Scrapy Engine 是用來控制整個爬蟲系統的數據處理流程,并進行事務處理的觸發,負責接收和轉發其他各個模塊間的請求和相應。
(2)調度器:Scheduler維護著爬蟲的爬取優先級隊列,決定著下一個要爬取的URL,從Scrapy引擎接收請求并排序加入隊列,并在引擎發出請求之后返回響應。爬蟲的爬取優先級隊列是一個簡單的內存隊列,爬蟲之間不能共享隊列,也無法固化到磁盤,如果發生錯誤或者程序崩潰,隊列中的所有信息都將丟失,因此每一個爬蟲都維護著一個屬于自己的內存隊列。
(3)下載器:Downloader 主要功能是從引擎處獲取要下載的URL ,然后向服務器發送下載請求下載頁面,通過下載器中間件(Downloader Middlewares)實現各種網絡協議(如HTTP、FTP等)數據的下載,然后將所下載的網頁內容傳遞給蜘蛛(Spiders)進行下一步的處理。
(4)蜘蛛:蜘蛛模塊負責解析下載的網頁,并抽取需要進一步爬取的超鏈接,它是由用戶自己定義的,用戶白定義的每個蜘蛛都能處理用戶指定的一個或一組域名,也是說用戶通過蜘蛛來定義特定網站的抓取和解析規則。蜘蛛在整個抓取過程中的處理流程如下:
首先獲取第一個URL的初始請求,當請求返回后調取一個回調函數。第一個請求是通過調用start_requests()方法。該方法默認從start_urls中的Url中生成請求,并執行解析來調用回調函數。
在回調函數中,你可以解析網頁響應并返回項目對象和請求對象或兩者的迭代。這些請求也將包含一個回調,然后被Scrapy下載,然后有指定的回調處理。
在回調函數中,你解析網站的內容,同程使用的是Xpath選擇器,并生成解析的數據項。
最后,從蜘蛛返回的項目通常會進駐到項目管道。
蜘蛛分析出來的結果有兩種:一種是需要繼續抓取的鏈接;另一種是需要保存的數據。兩種結果是可以混雜在同一個結果列表里返回的,引擎會通過列表元素的數據類型進行區分,數據被封裝成Item類型,請求則被封裝成Request類型,Request類型的數據會轉發給調度器進行調度,下載后通過指定的回調函數處理。
(1)項目管道:Item Pipeline的主要責任是負責處理有蜘蛛從網頁中抽取的項目,其主要任務是分析、驗證和存儲數據。當頁面被蜘蛛解析后,將被發送到項目管道,并經過幾個特定的次序處理數據操作。數據管道中對數據的操作都是由開發人員自定義的函數方法,并可以在配置文件中指定其操作順序。對數據信息的處理還包括判定是否需要在項目管道中繼續執行下一步或是直接丟棄掉不處理。
項目管道通常執行的過程有清洗HTML數據、驗證解析到的數據(檢查項目是否包含必要的字段)、檢查是否是重復數據(如果重復就刪除)、將解析到的數據存儲到數據庫等。
(2)中間件:Middlewares是位于Scrapy引擎和各個模塊之間的鉤子框架,主要是用來處理Scrapy引擎和各模塊之間的請求及響應。它提供了一個自定義代碼的方式來擴展Scrapy的功能。Scrapy的中間件有下載器中問件、蜘蛛中間件以及調度器中間件。其中,常用的下載器中間件和蜘蛛中間件如表1所示。
Scrapy處理數據的流程步驟。
(1)Scrapy引擎打開一個初始的域名,并定位到相應的蜘蛛處理屬于這個域名的URL,然后讓蜘蛛獲取第一個要爬取的URL。
(2)Scrapy引擎從蜘蛛那里獲得第一個需要爬取的URL,并將該URL包裝成請求并指定響應該請求的回調函數,然后將其發送給調度器。
(3)Scrapy引擎向調度器請求下一步要進行爬取的頁面。
(4)調度器將下一個要爬取的URL以請求的方式返回給Scrapy引擎,Scrapy引擎通過下載器中間件將請求發送給下載器。
(5)當下載器執行請求、下載完網頁以后,下載的頁面內容通過下載器中間件發送給Scrapy引擎。
(6)Scrapy引擎在收到下載器的返回的下載數據后,通過蜘蛛中問件將響應數據發送到蜘蛛進行數據處理。
(7)蜘蛛解析下載的頁面并返回網頁解析后的數據,然后將抽取出的要繼續爬取的URL再次封裝成請求發送給Scrapy引擎。
(8)Scrapy引擎將解析完成的數據發送至數據處理流水線,并將新的URL爬取請求繼續轉發給調度器。
(9)系統重復步驟2-8,直到調度器中沒有新的請求時,關閉爬蟲。
3 定制工業漏洞爬蟲系統
在前面已經了解Scrapy原理的基礎上,本節將要設計一個爬蟲系統用于結構化提取工業控制系統漏洞信息。
3.1 工業漏洞爬蟲的特點
與傳統的網絡爬蟲不同,工業漏洞爬蟲有著特定的爬取需求,其目標站點是明確已知的,而且在目標站點網頁上需要提取的結構化信息也是明確的。因此,一般的爬蟲相比,其具有三個特點。
(1)特定的需求:工業控制系統相關的漏洞(簡稱工控漏洞)主要包括工業控制系統中PLC、DCS、上位機軟件等相關的漏洞信息。因此爬蟲系統的需求定位非常明確,只關注工控方面的信息即可。
(2)明確的目標:工業漏洞爬蟲的的目標站點是非常明確的。通過前期的調研工作,我們選擇國家信息安全漏洞共享平臺中工控系統專題(http://ics.cnvd.org.cn/)和美國國家漏洞庫(https://web.nvd.nist.gov/)兩個站點作為目標站點。
(4)明確的字段:在國家信息安全漏洞共享平臺的工控專題站點的頁面上,對于一個具體的漏洞新以表格的形式列出了和漏洞相關的基本信息。那么,對于此次的爬蟲系統而言,只需要抓取網頁上所列出的漏洞屬性信息,比如漏洞名稱、發布時間、漏洞描述等。
3.2 爬蟲系統的架構流程
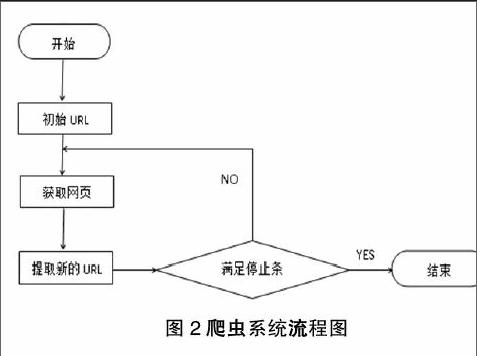
網絡爬蟲根據預先設定的一個或若干初始種子 URL開始,以此獲得初始網頁上的URL列表 ,在爬行過程中不斷從 URL 隊列中獲一個的 URL,進而訪問并下載該頁面。頁面下載后頁面解析器去掉頁面上的 HTML 標記后得到頁面內容 , 將摘要、 URL 等信息保存到 Web數據庫中, 同時抽取當前頁面上新的 URL,保存到 URL隊列, 直到滿足系統停止條件 。其工作流程如圖2所示。
3.3 爬蟲系統詳細設計
3.3.1 網頁結構與數據分析
目標站點目標頁面上的信息基本是以表格形式呈現,其中屬性信息包括漏洞名稱、CNVD編號、CVE編號、發布時間,危害級別、影響產品、漏洞描述、參考鏈接、解決方案、漏洞發現者等。根據實際項目需求,爬蟲抓取信息時不會全部保存列表上的屬性信息,只會保存項目所需數據信息。因此,將結構化的數據信息定義成如下格式:
{
“_id”:
“vulName”:
“vulDescription”:
“vulAdvisory”:
“refWebsite”:
“deviceName”:
“firmwareVersion”:
“integImpact”:
…
}。
3.3.2 數據定義
通過對Scrapy框架的學習研究以及前面對結構化數據的分析,利用Scrapy提供的Item類進行數據字段定義。對應item.py中主要的代碼如下:
import scrapy
class VulItem(scrapy.Item):
vulName = scrapy.Field()
vulDescription= scrapy.Filed()
…
3.3.3 編寫Spider
VulSpider是自定義編寫的用于爬取漏洞信息的爬蟲類,繼承自scrapy.CrawlSpider類。類主體中定義了幾種屬性和方法。
(1)Name屬性,定義的是蜘蛛名字的字符串,具有唯一性,在Scrapy啟動爬蟲是使用。
(2)allowed_domains屬性,包含了Spider允許爬取的域名(Domain)列表(List)。
(3)Start_urls屬性,URL列表。當沒有制定特定的URL時,Spider將從該列表中開始進行爬取。 因此,第一個被獲取到的頁面的URL將是該列表之一。 后續的URL將會從獲取到的數據中提取。
(4)Rules屬性,一個包含一個(或多個)Rule對象的集合(List)。每個Rule對爬取網站的動作定義了特定表現。Rule對象在下邊會介紹。如果多Rule匹配了相同的鏈接,則根據他們在本屬性中被定義的順序,第一個會被使用。
(5)Parse_item方法,當Response指定的回調函數。
VulSpider主要的代碼如下:
class VulSpider(CrawlSpider):
name = 'vul'
allowed_domains = ['cnvd.org.cn']
start_urls = ['http://ics.cnvd.org.cn/?max=20&offset=0']
rules = [Rule(SgmlLinkExtractor(allow=r'\?max=20&offset=\d+?'), callback='parse_url', follow=True)]
def parse_url(self, response):
sel = Selector(text=response.body)
for i in range(1, 21):
url = sel.xpath('//div[@class="list"]/table/tbody[@id="tr"]/tr[i]/td[i]/a/@href').extract()
Yield Request(url, callback=parse_item)
def parse_item(self, response):
……
3.3.4 數據存儲
網絡爬蟲爬取的數據信息不僅量大,而且往往是結構化或者非結構化的數據。傳統關系型數據庫并不是很適合存儲和處理這種數據信息,而NoSQL在處理文檔類數據是有著非常良好的性能的。因而,爬蟲系統選擇分布式的非關系型數據庫MongoDB對爬取的數據進行存儲。
首先,在爬蟲系統的setting.py文件中配置連接參數,其中包括數據處理的項目管道、連接的服務器、端口、數據庫名、表名。然后,在 項目管道文件pipelines.py中定義數據庫連接函數。定義的主要代碼如下:
class VulPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(settings['MONGO_SERVER'],settings['MONGO_PORT'])
db = connection[settings['MONGO_DB']]
self.collection = db[settings['MONGO_COLLECTION']]
def process_item(self, item, spider):
……
return item
以上代碼首先創建了一個VulPipeline類,其構造函數初始化該類并建立一個與數據庫服務器的連接。process_item()函數解析后的數據項。
3.3.5 反爬措施
為了防止被網絡爬蟲爬取網頁上的數據,很多網站都對網絡爬蟲進行了限制。工業漏洞爬蟲利用Scrapy框架本身的優勢并采取一定措施來避免被網站限制。采取的措施主要包括三種。
(1)設置延時:download_delay表示下載器在下載同一個站點下一個網頁前需要等待的時間,這個時間如果太短,網絡爬蟲被Ban的概率則會大大增加。在settings.py中配置DOWNLOAD_DELAY = 3,3表示等待的秒數。
(2)禁止Cookies:可 以 防 止 使 用Cookies 識別爬蟲軌跡的網站察覺,在settings.py 設置:COOKIES_ENABLES=False 。
(3)使用User Agent池:為了防止被服務器識別,可將 User Agent 池定義在 rotate_useragent.py文件中,每次訪問服務器時,從User Agent列表中隨機選擇一個作為Request中頭部信息的User Agent。
4 結束語
隨著互聯網信息的爆炸式增長,網絡爬蟲技術日漸成熟,通過網絡爬蟲來獲取特定需求的信息數據必然會是信息需求的趨勢。本文在各種成熟的爬蟲框架中選擇Scrapy定制實現了一個工業漏洞網絡爬蟲,該爬蟲能高效的抓取所需的漏洞信息,實現了自動化提取結構化的網絡資源信息。
總之,利用網絡爬蟲來高效獲取信息已經成為一個越來越受歡迎的手段。網絡爬蟲框架越來越多,便利越來越大,但是如何去提升爬蟲的效率仍將是爬蟲技術研究方向。
參考文獻
[1] 董日壯, 郭曙超.網絡爬蟲的設計與實現[J].電腦知識與技術, 2014(6X): 3986-3988.
[2] 周德懋,李舟軍.高性能網絡爬蟲: 研究綜述[J].計算機科學, 2009,36(8): 26-29.
[3] 孫立偉,何國輝,吳禮發.網絡爬蟲技術的研究[J].電腦知識與技術,2010(15): 4112-4115.
[4] 李盛韜,余智華,程學旗,等.Web 信息采集研究進展[J]. 計算機科學,2003,30(2): 151-157.
[5] Chakrabarti S,Van den Berg M,Dom B. Focused crawling: a new approach to topic-specific Web resource discovery[J]. Computer Networks,1999,31(11): 1623-1640.
[6] Cho J, Garcia-Molina H. The evolution of the web and implications for an incremental crawler[J]. 1999.
[7] Scrapy Document.Available at http://www.scrapy.org/.
[8] Twisted Document.Available at http://twistedmatrix.com/trac/.
作者簡介:
孫歆(1981-),男,漢族,浙江杭州人,畢業于浙江大學,碩士研究生,高級工程師;主要研究方向和關注領域:信息安全、工控安全。
戴樺(1985-),男,漢族,浙江杭州人,畢業于南京郵電大學,碩士研究生,工程師;主要研究方向和關注領域:工控安全、滲透測試。
孔曉昀(1969-),女,漢族,浙江杭州人,碩士研究生,高級工程師;主要研究方向和關注領域:信息技術、信息化建設。
趙明明(1984-),男,漢族,內蒙古赤峰人,畢業于北京科技學院,本科,工程師;主要研究方向和關注領域:信息安全攻防。
