基于深度學習手寫字符的特征抽取方法研究
2017-02-27 03:11:05劉興旺
軟件 2017年1期
鄒 煜,劉興旺
(中南民族大學 計算機科學學院,武漢 430074)
基于深度學習手寫字符的特征抽取方法研究
鄒 煜,劉興旺
(中南民族大學 計算機科學學院,武漢 430074)
當前對深度學習單層訓練算法的研究工作較少,本文采用數據量、隱層節點和感受野大小,分析自動編碼器和K-means算法在訓練深度網絡抽取特征上的表現。發現自動編碼器對數據量,隱層節點敏感,且學習率與數據量和感受野呈負相關;數據量一定后,K-means對數據量不敏感,且感受野大小的選取對該算法發揮性能至關重要。在實際應用中給自動編碼器加入稀疏性控制是必要的。實驗結果表明,本文的研究工作,對用自動編碼器或K-means訓練深度網絡有一定的參考借鑒意義。
深度學習;K-means;自動編碼器;感受野;數據量;隱層節點
本文著錄格式:鄒 煜,劉興旺. 基于深度學習手寫字符的特征抽取方法研究[J]. 軟件,2017,38(1):23-28
0 引言
當下,人工智能已經是科技領域內研究的熱點,深度學習(Deep Learing,DL)更是人工智能技術中最具代表性的技術之一。引起了學術界與產業、工業界的廣泛關注。深度學習是由傳統的神經網絡發展而來的,但是又不僅僅是傳統網絡的簡單繼承。深度學習的概念最早由多倫多大學的GE.Hinton等人于2006年提出,指基于樣本數據通過一定的訓練方法得到包含多個層級的深度網絡結構的機器學習過程。傳統的神經網絡隨機初始化網絡中的權值,導致網絡很容易收斂到局部最小值,為解決這一問題,Hinton提出使用無監督預訓練方法優化網絡權值的初值,再進行權值微調的方法,拉開了深度學習的序幕[1]。
在圖像識別領域深度學習也有廣泛的應用,利用深度學習模型得到圖像標注信息,主要是利用了圖像間的視覺相似性,選用高層視覺特征作為深度神經網絡的輸入信息。可以對一些模糊的特征做分類,這是一個非常有前瞻意義的研究[2]。我國對深度學習的研究起步較晚,學習者批判性地學習新思想和新知識,將它們與原有的認知結構相融合,將眾多思想相互關聯,將已有的知識遷移到新的情境中去,做出決策并解決問題的學習。此后國內開展了一系列針對深度學習的相關學術研究[3]。深度學習的主要目的是訓練模型,使學習模型在滿足一定精度要求的前提下具有最簡單的網絡結構。并且在這一網絡結構的基礎上去測試樣本[4]。圖像領域的研究是深度學習最早進行嘗試的應用領域,面對一幅圖像,其像素級的特征幾乎沒什么實用價值,人體視覺系統對圖像信息的處理就是從低級的顏色、邊緣等特征到實體形狀或者再到更高層的人類理解層級,即將底層特征組合理解獲得圖像高級特征。而深度學習在圖像領域的應用過程就是模擬這個人類視覺系統對圖像內容進行理解建模的過程[5]。基于深度學習理論的神經網絡模型能夠很好的應用于中文命名實體識別任務。以該模型為核心建立的中文命名實體識別系統具有良好的健壯性和可維護性,能夠滿足大數據背景下中文命名實體識別的新需求[6]。深度學習模型己廣泛應用于計算機視覺、語音識別機器翻譯和語義挖掘等領域,而流數據變得越來越多,因此深度學習模型不得不對及時更新的流數據進行學習。如果把流數據放入原始的訓練數據集,重新對原始數據集進行學習,隨著流數據的加入越來越多,模型對數據學習所花費的時間將變得越來越長,就可能導致訓練模型所投入的成本大于模型對數據學習的收益的惡性循環。一種有效的解決方案是增量學習或在線學習[7]。由于深度學習在訓練過程后,它的結果是以一種模型文件顯示的,對于特定的分類需求中的特征提取能夠提升準確率[8[9]。
雖然深度學習方法在眾多方面取得了不少研究成果,但有關深度學習的單層訓練算法的研究工作較少,進展緩慢。本文在幾種規模的數據集上開展實驗,探討深度神經網絡的單層訓練中特征抽取方法。通過調整圖像塊的大小和隱層節點的數量,針對自動編碼器方法和K-means算法在不同訓練參數情況下,分析它們提取圖像樣本數據特征的表達性能。
1 自動編碼器算法
自動編碼器多用于堆疊構件深度網絡,一般是逐層預訓練,最后通過反向微調機制來微調整個網絡。
將高維的數據用低維信息予以表示,是自動編碼器的特點。它是一個三層的網絡結構,包含輸入層、隱藏層各輸出層。圖1所示為其網絡結構。其中輸入與輸出均有n個節點,圖中1為偏置項。

圖1 自動編碼器網絡結構示意圖Fig.1 AutoEncoder network structure
其中,網絡的輸入表示為x=(x1,x2,…,xn),輸出表示為y=(y1,y2,…,yn)。自動編碼器的全局代價函數如公式(1)所示,單次代價函數如公式(2)所示。其中,K為輸入樣本數,n為輸入維度,xi j,表示樣本i的第j個分量,yi j,表示樣本i對應輸出的第j個分量。

采用梯度下降算法訓練網絡,輸出層權值更新如公式(7)所示,隱藏層權值更新如公式(10)所示,算法迭代推導過程見公式(3)~(7)。

同理利用鏈式求導法則可得隱層權值更新算法,見公式(8)~(10)。


O表示輸出層,H表示隱層,hi表示隱藏層第i個節點的輸出,Io k表示輸出層第k個節點的累計輸出,IH i表示隱含層第i個節點的累計輸出,f為sigmod函數,δo k表示輸出層第k節點的殘差,δH i表示隱含層第i個節點的殘差。WO表示輸出層節點的權值,WH表示隱層節點的權值,η表示學習率。
經過迭代訓練得到隱層權值WH后,用樣本x與它做內積運算,便得到了樣本x的特征表示。這種特征映射的方法比K-means算法的特征映射要簡單,但訓練映射字典的復雜度和時間開銷超過K-means算法。
2 改進的K-means算法
K-mean聚類算法自誕生起就在人工智能領域受到青睞,它的算法思想通俗易懂,且算法計算速度也非常快,是一種無監督學習算法。該方法假定將某個數據集劃分成k個聚簇,簇中心用該簇中所有數據的均值計算得到,定義它的誤差函數如式(11)所示。當J的值最小或不再變化時,認為聚類過程完成,簇中心的迭代計算見公式(12)所示。算法的學習目標是使得J最小化。u=(u1,u2,…,uk,…),其中,當xn屬于uk簇時,tnk取值為1;否則,取值為0,uk為簇k的均值,即簇中心,M為第k個簇中樣本的數量,N為樣本數。
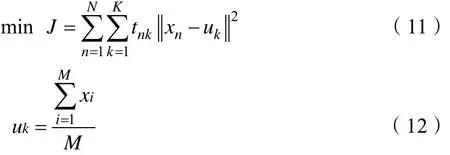
然后,由于K-means算法的初始化是隨機值,有可能造成空聚類的等問題。本文提出一種改進的K-means聚類方法,算法描述見算法1所示。其中,xi表示樣本i,T表示對向量或矩陣做轉置,X=(x1,x2,…,xn)表示所有樣本,s表示X在u下的一個映射,si k表示樣本i在u下映射的第k個分量。
算法1一種改進的K-means聚類算法


經過訓練得到字典u之后,進行特征映射。對字典u的一次映射,要求僅有少量類簇被激活。映射方式見公式(13)所示,其中Feature(x)k表示樣本x特征的第k個分量,md表示樣本x到各個類中心的平均距離,uk是K-means算法訓練得到的簇k的均值。這種映射保證了K-means算法抽取的特征的稀疏性,且綜合考慮了樣本以某概率屬于某個聚簇。K-means通過這種方式計算得到的特征的稀疏性,要比普通的自動編碼器得到的特征的稀疏性高。見下文的實驗分析。

3 實驗及結果分析
3.1 數據準備及預處理
本文實驗的數據集采用minist手寫數字數據庫,從60000個訓練樣本中,在隨機位置選取不同像素尺寸大小的圖塊,共生成6批數據,分別是:(1)4*4像素圖像,40000張;(2)4*4像素圖像,80000張;(3)8*8像素圖像,40000張;(4)8*8像素圖像,80000張;(5)16*16像素圖像,40000張(6)16*16像素圖像,80000張。
在開展實驗之前,分別將這些樣本數據進行歸一化處理,使得樣本的均值為0,方差為1。歸一化處理見公式(14)所示,std()表示求標準差,x為樣本,xmean為樣本均值。

3.2 樣本數量大小的影響分析
樣本數量的大小關系到特征抽取字典是否豐富,是獲得較好實驗結果的重要前提之一。在討論樣本數量大小對特征抽取字典的影響時,實驗選取2批數據,它們的圖像塊大小固定為8*8像素,樣本數量分為40000個和80000個。從實驗對比結果分析,發現當樣本數量增長一倍時,對K-means算法的影響較弱,而對自動編碼器方法影響較大,見圖2和圖3所示,標號8-40000-48表示8*8像素圖塊,樣本數量40000個,且隱層節點為48個,以下其他圖中標號含義類似。在圖3中,誤差值隨著樣本數量的增加而逐步減小,結果表明經過訓練得到的特征字典更加豐富。

圖2 自動編碼器的特征字典變化分析Fig.2 The Features dictionary changing analysis of AutoEncoder

圖3 K-means的特征字典變化分析Fig.3 The Features dictionary changing analysis of K-means
3.3 感受野大小的影響分析
感受野是人眼觀察一副圖像時,每次抓取多大的局部像素,不同大小的圖像的感受野不一樣。考察感受野對特征抽取字典的影響時,實驗選取3批數據,固定它們的樣本數量為80000個,感受野的大小依次從4*4像素到8*8像素,再到16*16像素。從模型訓練的復雜度角度來說,圖塊大小增加時,自動編碼器訓練的復雜度會大大增大,如圖4所示。但是圖塊太小,模型學習不能獲得特征。當圖塊大小為16*16像素時,實驗結果不理想,如圖5所示,一個重要原因是特征的稀疏性不高。對于K-means來說,圖塊訓練結果分析如下:當圖塊太小時,沒有學習到邊緣,見圖6所示;當圖塊太大時,已經學習到了具體數字,見圖7所示,這都不是理想的實驗結果。針對本文的實驗數據,圖塊大小保持在8*8像素,相差不到2個單位量是合適的,見圖8,學習獲得不同的邊緣,從而可以用學習得到的這些邊緣進行特征抽取。

圖4 自動編碼器感受野大小分析Fig.4 Patch size analysis of AutoEncoder

圖5 自動編碼器16*16圖塊學習結果Fig.5 AutoEncoder's learning result about 16*16 patch

圖6 K-means4*4圖塊學習結果Fig.6 K-means's learning result about 4*4

圖7 K-means16*16圖塊學習結果Fig.7 K-means's learning result about 16*16 patch

圖8 K-means 8*8圖塊學習結果Fig.8 K-means's learning result about 8*8 patch
3.4 隱層節點數量影響分析
隱層節點的數量多少決定了抽取特征的維度,隱層的節點數量是自動編碼器的隱層節點數和K-means的k的選擇。實驗固定樣本數據為圖塊8*8像素大小,樣本數量80000個。隱層節點數考慮40、48和56三種情況。實驗結果分析,見圖9和圖10所示,從這兩個結果圖中,可以看到兩種算法的相同之處,增大隱層節點數量可降低誤差,當考慮到數據抽象和降維要求時,應該在低維度表示和低誤差之間選取合理的平衡點。

圖9 自動編碼器的隱層節點數量分析Fig.9 AutoEncoder hidden layer node analysis

圖10 K-means算法的k值分析Fig.10 Analysis of the value of K about K-means
3.5 實驗結果
樣本特征抽取的表達效果直接與誤差或平均最小距離相關。實驗通過參數調節,討論分析特征抽取的成效,實驗結果見表1、表2所示,其中,第1列X-Y表示感受野為X*X大小、數據量為Y條。在表1中,第2與第4行表明數據量與學習率呈負相關,與誤差呈正相關。在表1,第3、第4和第5行,表明隱層節點與誤差呈負相關,且相關性較強。在表1中,第1與第4行表明當感受野快速變大,誤差快速變大,訓練難度增加,兩者相關性強。
在表2中,根據第2與第4行結果,可知當數據量到達一定數量時,再增加數據量對該算法影響波動較小;第3、4和5行結果數據可知K值與平均最小距離呈負相關,平均最小距離隨K值波動不大,表明該算法穩定性較好;第1與第4列數據表明感受野與平均最小距離呈正相關,且相關性強。
對比分析表1的第2和第4行與表2的第2和第4行的數據結果,可以發現自動編碼器方法對數據量的敏感度要高于K-means值算法;通過表1與表2的第3、4和5行對比分析可知,自動編碼器對隱層節點的數量的敏感度也要高于K-means;通過表1和表2的結果對比分析,可知二者對感受野都極為敏感。

表1 自動編碼器結果Table 1 The result of AutoEncoder

表2 K-means結果Table 2 The result of K-means
4 結語
本文通過分析樣本數量、感受野大小和隱層節點數等3種因素對自動編碼器方法和K-means算法在特征學習方面的性能影響,發現K-means算法比自動編碼器更容易訓練。同時,通過本實驗數據評估了兩種算法各自的適用性。實驗結果表明,對于自動編碼器,樣數量和感受野大小均與學習率成負相關,且較好好的特征抽取與較低的錯誤率相關,在實際應用中,給自動編碼器加入稀疏性控制,往往能取得更好的結果。
[1] 尹寶才, 王文通, 王立春. 深度學習研究綜述[J]. 北京工業大學學報, 2015, 01∶ 48-59.
[2] 楊陽, 張文生. 基于深度學習的圖像自動標注算法[J]. 數據采集與處理, 2015, 01∶ 88-98.
[3] 樊雅琴,王炳皓,王偉,唐燁偉. 深度學習國內研究綜述[J].中國遠程教育, 2015, 06∶ 27-33+79.
[4] 陳珍, 夏靖波, 柏駿, 徐敏. 基于進化深度學習的特征提取算法[J]. 計算機科學, 2015, 11∶ 288-292.
[5] 楊宇. 基于深度學習特征的圖像推薦系統[D]. 電子科技大學, 2015.
[6] 王國昱. 基于深度學習的中文命名實體識別研究[D]. 北京工業大學, 2015.
[7] 岳永鵬. 深度無監督學習算法研究[D]. 西南石油大學, 2015.
[8] 萬維. 基于深度學習的目標檢測算法研究及應用[D]. 電子科技大學, 2015.
[9] 王茜, 張海仙. 深度學習框架Caffe在圖像分類中的應用[J].現代計算機(專業版), 2016, 05∶ 72-75+80.
[10] 趙鵬, 王斐, 劉慧婷, 姚晟. 基于深度學習的手繪草圖識別[J]. 四川大學學報(工程科學版), 2016, 03∶ 94-99.
[11] 金連文, 鐘卓耀, 楊釗, 楊維信, 謝澤澄, 孫俊. 深度學習在手寫漢字識別中的應用綜述[J]. 自動化學報, 2016, 08∶1125-1141.
[12] Mahmood Yousefi-Azar, Len Hamey, Text summarization using unsupervised deep learning, Expert Systems with Applications, Volume 68, February 2017, Pages 93-105, ISSN 0957-4174, Keywords∶ Deep Learning; Query-oriented Summarization; Extractive Summarization; Ensemble Noisy Auto-Encoder.
[13] Zhong Yin, Jianhua Zhang, Cross-session classification of mental workload levels using EEG and an adaptive deep learning model, Biomedical Signal Processing and Control, Volume 33, March 2017, Pages 30-47, ISSN 1746-8094.
Research of Feature Extraction Method for Offline Handwritten Character Based on Deep Learning
ZOU Yu, LIU Xing-wang
(College of Computer Science, South-Central University for Nationalities, Wuhan 430074)
In currently, there are few studies of monolayer training algorithms about deep learning. In this paper, We analyze the performance of the AutoEncoder and K-means in training deep network and feature extraction on three points∶data volume, hidden layer nodes and receptive field. We find that automatic encoder is sensitive to data volume and hidden layer nodes,and learning rate has a negative correlation with data volume and receptive field. After a certain amount of data, K-means is not sensitive to data volume, so select receptive field size plays a crucial performance for the algorithm. In practice, added sparsity control into AutoEncoder is necessary. Experimental results shows that studies of this paper has reference value for training deep network with AutoEncoder or K-means.
Deep learning; K-means; AutoEncoder; Receptive field; Data volume; Hidden layer nodes
TP391.43
A
10.3969/j.issn.1003-6970.2017.01.006
國家自然科學基金資助項目(60975021,女書規范化及識別技術研究)
鄒煜(1985-),男(通信作者),碩士研究生,研究方向為人工智能與模式識別;劉興旺(1991-),男,碩士研究生,研究方向為文字圖像處理。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
