新浪微博數據爬取研究
2017-01-21 22:11:09陳智梁娟謝兵傅籬
物聯網技術 2016年12期
陳智++梁娟++謝兵++傅籬


摘 要:新浪微博的快速發展促進了基于微博數據的研究發展,如何獲取微博數據是開展相關研究的首要問題。文中就分析爬取新浪微博數據的方法,提出了一種基于Python的語言,直接設置已登錄用戶Cookie信息,模擬瀏覽器訪問的新浪微博數據爬取方案,解決了不使用新浪微博開放平臺API爬取微博數據的主要問題,所實現的爬蟲程序編程簡單、性能穩定,能有效獲取微博數據。
關鍵詞:新浪微博;數據爬取;微博爬蟲;Python
中圖分類號:TP391;TP311 文獻標識碼:A 文章編號:2095-1302(2016)12-00-04
0 引 言
隨著互聯網的不斷普及,人們越來越多地參與到互聯網的社交活動中,微博作為典型的互聯網社交活動,得到了迅速發展。新浪微博是國內出現最早,也是規模最大的微博社區,新浪微博數據中心發布的“2015微博用戶發展報告”指出:“截止2015年9月,微博月活躍人數已達到2.22億,較2014年同期相比增長33%;日活躍用戶達到1億,較去年同期增長30%。隨著微博平臺功能的不斷完善,微博用戶群逐漸穩定并保持持續增長。”[1]
微博用戶群的增長使得基于微博數據的社交網絡分析[2]、用戶行為分析[3, 4]和網絡數據挖掘[5]等相關研究越來越受到人們的重視,而如何從微博爬取感興趣的數據則成為研究者要解決的首要問題。本文分析微博數據的爬取方式,提出一種基于Python模擬瀏覽器登錄的微博數據爬取方案,并討論針對微博反爬機制的相關處理。
1 微博數據的爬取方式
微博數據的爬取通常有兩種方式,一種是調用新浪微博開放平臺提供的微博開放接口,另一種是開發爬蟲程序,模擬微博登錄,分析獲得的HTML頁面,提取所需信息。
1.1 調用微博開放接口
新浪微博開放平臺[6]提供了二十余類接口,覆蓋了微博內容、評論、用戶及關系的各種操作,理論上該方法是最直接、方便的方式。但新版的微博開放接口存在一些限制,對于小型研究團隊或個人而言不是很方便,突出表現在以下幾點:
(1)微博開放接口使用Oauth2.0認證授權,如果希望得到另外一個用戶的個人信息和微博內容,則必須由該用戶授權;
(2)微博開放接口存在訪問頻次限制,對于測試用戶的每個應用,每小時最多只能訪問150次;
(3)很多研究所需要的數據只能通過高級接口才能訪問,需要專門申請和付費。
正是因為這些限制的存在,自己設計開發網絡爬蟲程序獲取微博數據就成了必不可少的備選或替代方案。
1.2 開發微博爬蟲程序
設計開發微博爬蟲程序需要分析新浪微博的特點、明確爬取數據的目的及用途,選擇合理的開發語言,保證高效、穩定地獲取微博數據。
1.2.1 新浪微博的特點
與一般網站相比,新浪微博具有以下特點:
(1)新浪微博面向登錄用戶,在訪問微博數據前,用戶必須先登錄;
(2)微博博文的顯示采用了延遲加載機制,一次只顯示一個微博頁面的部分博文,當用戶瀏覽博文滾動到底部時,才繼續加載當頁的其他博文;
(3)新浪微博有較完備的反爬蟲機制,一旦微博服務器認定爬蟲程序,就會拒絕訪問。
基于新浪微博的上述特點,在設計微博爬蟲時,需要對以上特點進行針對性處理。
1.2.2 開發語言選擇
從快速獲取微博數據的角度看,Python是開發微博爬蟲的首選語言,其具有如下特點:
(1)Python是一種解釋型高級語言,具有文字簡約、容易學習、開發速度快等特點;
(2)Python具有較豐富的庫及第三方庫,在開發爬蟲方面比其他語言方便。考慮新浪微博在一段時間后就會微調其數據格式,因此使用Python開發微博爬蟲程序具有較高的易維護性。
2 微博爬蟲的實現
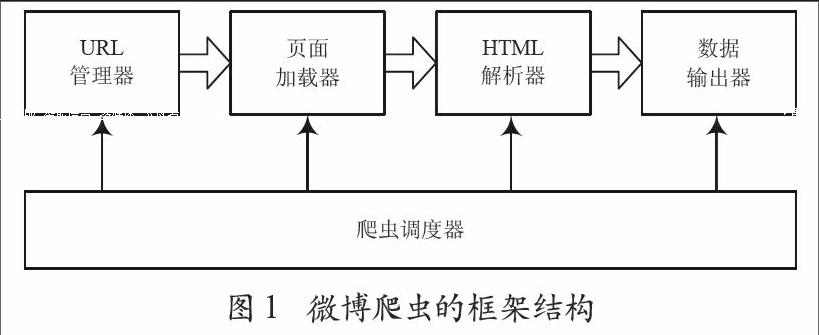
2.1 微博爬蟲的框架結構
本文討論的微博爬蟲程序包括爬蟲調度器、URL管理器、頁面加載器、HTML解析器和數據輸出器五個功能模塊,其框架結構如圖1所示。
圖1 微博爬蟲的框架結構
2.1.1 爬蟲調度器
爬蟲調度器是爬蟲的控制程序,主要負責協調和調度微博爬蟲的各個模塊,其核心功能包括以下幾項:
(1)實現爬取微博數據的流程;
(2)控制其他模塊的執行;
(3)模擬瀏覽器登錄,為頁面請求添加Headers信息;
(4)控制微博訪問頻率,避免反爬蟲機制拒絕訪問。
2.1.2 URL管理器
微博爬蟲采用廣度優先遍歷策略提取需要的數據,URL管理器需維護已經爬取的URL列表和等待爬取的URL列表。在得到新URL之后,首先檢查已經爬取的URL列表,如果該URL不在列表中,則將其添加到等待爬取的URL列表。
2.1.3 頁面加載器
頁面加載器根據爬蟲調度器提供的Headers信息以及URL管理器提供的URL,向微博服務器發出請求,獲得所請求的HTML頁面。為了避免爬取過于頻繁,導致微博服務器無法及時響應,或被服務器反爬蟲機制拒絕訪問,頁面加載器采用定時機制限制加載頁面的頻率。
2.1.4 HTML解析器
HTML解析器對頁面加載器提供的HTML頁面進行解析,獲取需要的數據。如某位微博用戶發表的博文內容、轉發數、點贊數、評論數等。同時HTML解析器會根據需要將新得到的URL反饋給爬蟲調度器。
2.1.5 數據輸出器
數據輸出器輸出HTML解析器解析后的數據。輸出的數據采用JSON格式,其格式與使用新浪微博開放平臺API獲取的數據格式基本一致,保證不同爬取方式得到的數據能夠被統一分析和處理。
2.2 模擬瀏覽器登錄
要訪問微博數據,必須要先登錄。可以用爬蟲程序模擬微博用戶登錄[7, 8]。爬蟲程序首先向微博用戶服務器發送登錄請求,然后接收服務器返回的密鑰,再結合用戶名、密碼、服務器返回的密鑰生成驗證信息,登錄服務器。只要保持與服務器的Session會話,就可以從服務器獲取微博數據,從而進一步分析。
這種做法實現比較復雜,并且需要了解服務器驗證信息的細節。因此采用另一種相對簡單的做法,即本文微博爬蟲的做法。首先在瀏覽器中登錄微博,然后使用瀏覽器提供的開發者工具查看請求頁面的請求頭信息。例如使用Firefox登錄微博后,利用Firefox提供的開發者工具可以看到如圖2所示的請求頭信息。
從圖2可以看出,“Referer”的內容是訪問微博的URL,其中“<用戶Uid>”是當前用戶在微博的唯一標識id;“Connection”的值為“keep-alive”,標識Cookie永不過期;“Cookie”的內容是成功連接微博服務器后保存在本地的Cookie,利用它可以簡單、快速地訪問新浪微博。首先需復制“<連接需要的Cookie>”的內容,然后在Python中定義headers對象,設置Cookie和Connection,最后在每次訪問微博頁面時,都將headers作為參數添加到Request對象中,得到微博頁面。這樣在Cookie的有效期內就可以直接訪問微博,并提取自己需要的數據。采用這種做法,只需以下代碼就可以實現微博的登錄并簡單獲取頁面數據:
headers = {'Cookie': ‘<連接需要的Cookie>,Connnection:keep-alive}
url = u'http://weibo.com/u/<用戶Uid>/home?wvr=5&lf=reg'
request = urllib.request.Request(url, headers=headers)
rsponse = urllib.request.urlopen(request)
page = response.read()
2.3 微博頁面解析
爬蟲程序成功登錄到微博,獲取微博頁面后,就可以對得到的HTML腳本進行解析,提取需要的數據。一條博文的數據主要包括發表博文的用戶昵稱、用戶Uid、主頁鏈接、博文內容、發表時間、轉發數、評論數、點贊數等。除此以外,轉發其他用戶的微博是非常常見的現象,因此在提取博文數據時,也需要考慮被轉發的微博用戶的相關數據信息。
進一步分析微博頁面可以發現,每一條博文均是以
開始,內部以
標簽形成樹結構,其主結構如表1所列。


2016年12期
- 資訊博覽
- 物聯網產業(2016年11月)
- 陜西物聯網產業聯盟出席2017“物聯中國”年度盛典啟動儀式
- 秦鷺話物聯,合作共發展
- 五種技術趨勢重塑制造業
- 2016智能家居產業年度解析:安全仍是最大難題
- 斑點貓:以安全為核心,定義物聯網智能指紋鎖
- 綠茵舞者
- 天使的守護
- 智能藥箱
- 陜西物聯網產業聯盟(ASII)
- 學術研究
- 基于ZigBee的人體健康數據采集系統的設計
- 氣壓高度計的測量誤差分析及修正方法
- 基于ZigBee養老院室內外定位系統的實現
- 動態心電心阻抗監測系統的研究
- 基于ZigBee+云服務器的橋梁基質穩定性監測系統
- 基于ODAC的權限管理機制
- MDCF壓接式微矩形型電連接器的研制
- 老齡化社區智能服務平臺及其數據分析
- 仿微信掃碼登錄系統的實現與改進
- 監獄安全防范綜合管理系統效能評估指標體系分析
- 一種基于微信平臺的智能家居系統
- 一種應用于低功耗植入式醫療芯片的無線能量管理單元
- 基于云計算的智能充電樁管理系統的研究
- B/S架構下的學生信息管理系統的設計
- 基于物聯網的小區天氣反饋調節智能窗戶系統設計
- 新浪微博數據爬取研究
- 基于物聯網的晉陜豫黃河金三角地區智慧旅游研究
- 淺談基于物聯網技術的能源管理系統
- 基于ZigBee技術的智能家居系統設計
- 基于物聯網的智能檢測飛行器設計
- 基于渦旋諧振環的人工磁導體的設計與應用
- 智能穿戴設備監測數據的分析及研究
- 基于視頻的帶電作業中組合間隙的智能檢測
- 快遞物品遠程自動接收系統設計與開發
- 基于Netty+WebSocket的社區增值服務平臺的推送設計
- 有刷式航空直流電機裝配試驗中的關鍵工藝分析
- 語音業務多系統融合技術研究與實現
- 基于改進演化算法的自適應醫學圖像多模態校準
- 基于WiFi和移動終端的智能照明控制系統設計
- 軍工企業集中式信息化平臺方案研究
- 一種基于微信的智能燈光控制系統的設計
- 去除印制板三防涂覆材料的工藝研究
- 基于開源平臺Arduino的大學創客實踐探索
- 高職課程信息化教學設計實踐與研究
- 大數據背景下高職計算機網絡專業課程體系改革研究
- 移動教育App的研究現狀分析
公司地址: 北京市西城區德外大街83號德勝國際中心B-11
客服熱線:400-656-5456??客服專線:010-56265043??電子郵箱:longyuankf@126.com
電信與信息服務業務經營許可證:京icp證060024號
Dragonsource.com Inc. All Rights Reserved
一種處理辦法是多次發送模擬HTTP請求的GET方法,構建響應的URL,完成整頁加載[8];另一種處理辦法是使用selenium模擬瀏覽器滾動條操作,在Ajax加載后再獲取頁面數據,這種方法的參考代碼如下:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Firefox()
driver.set_page_load_timeout(30)
def scroll(driver):
driver.execute_script("""
( function () {
var y = document.body.scrollTop;
var step = 100;
window.scroll(0, y);
function f() {
if (y < document.body.scrollHeight) {
y += step;
window.scroll(0, y);
setTimeout(f, 50);
} else {
window.scroll(0, y);
document.title += "scroll-done";
}
}
setTimeout(f, 1000);
""")
3 反爬蟲機制及對策
如果爬蟲爬取過“猛”,就會為微博服務器帶來不小的壓力。新浪微博有比較完備的反爬蟲機制,用以識別和拒絕爬蟲訪問。雖然新浪官方并沒有提供具體的反爬蟲機制說明,但是通過分析常用的反爬蟲策略[9],可以發現主要的爬蟲識別方法有以下幾種:
(1)通過識別爬蟲的User-Agent信息來拒絕爬蟲;
(2)通過網站流量統計系統和日志分析來識別爬蟲;
(3)通過實時反爬蟲防火墻過濾爬蟲。
為了避免微博反爬蟲機制拒絕訪問,本文的微博爬蟲采取了偽裝User-Agent與降低請求訪問頻率來反爬蟲對策。
3.1 偽裝User-Agent
User-Agent用于描述發出HTTP請求的終端信息。瀏覽器及經過企業授權的知名爬蟲如百度爬蟲等都有固定的User-Agent信息,本文討論的微博爬蟲偽裝瀏覽器通過微博登錄來爬取特定數據。在請求頭headers中,采用交替偽裝User-Agent的方法來避免爬蟲User-Agent的識別和訪問流量統計異常。
例如以下四個User-Agent信息,分別從使用Windows Edge、Firefox、Chrome和360瀏覽器訪問微博時的請求頭中提取。
Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2486.0 Safari/537.36 Edge/13.10586
Mozilla/5.0 (Windows NT 10.0; rv:47.0) Gecko/20100101 Firefox/47.0"
Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.94 Safari/537.36
Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
在Python中定義headers對象時,交替隨機選擇其中的一條添加到headers對象中,將爬蟲的HTTP請求偽裝成某個瀏覽器的訪問。
3.2 降低請求訪問頻率
如果爬蟲程序爬取過于頻繁,則會降低微博服務器的響應效率,影響一般用戶的正常使用。反爬蟲防火墻往往會根據請求的訪問頻率來判斷客戶端是一般用戶的人工操作還是爬蟲程序的自動運行。因此適當降低爬蟲程序的請求訪問頻率既可以避免連接超時錯誤的發生,還可有效應對反爬蟲機制。
4 結 語
綜上,本文實現的微博爬蟲能夠有效爬取新浪微博數據,實現簡單、性能穩定,并能較好的避免反爬蟲機制的檢測。其具有如下主要特點:
(1)直接獲取已登錄用戶的Cookie,避免了模擬登錄的繁瑣;
(2)基于lxml解析微博數據,簡化了數據篩選的操作;
(3)使用selenium模擬滾動條滾動,解決了Ajax延遲加載頁面的問題;
(4)使用偽裝User-Agnet以及延遲訪問來避免反爬蟲機制的過濾。
但該設計的主要缺陷是沒有使用多線程導致爬取效率不高,不適用于海量數據爬取,用戶可根據需要進行適當改動。
參考文獻
[1]新浪微博數據中心.2015微博用戶發展報告[R].2015.
[2]曹玖新,吳江林,石偉,等.新浪微博網信息傳播分析與預測[J].計算機學報,2014(4):779-790.
[3]葉勇豪,許燕,朱一杰,等.網民對“人禍”事件的道德情緒特點——基于微博大數據研究[J].心理學報,2016,48(3):290-304.
[4]王晰巍,邢云菲,趙丹,等.基于社會網絡分析的移動環境下網絡輿情信息傳播研究——以新浪微博“霧霾”話題為例[J].圖書情報工作,2015,59(7):14-22.
[5]丁兆云,賈焰,周斌.微博數據挖掘研究綜述[J].計算機研究與發展,2014,51(4):691-706.
[6]微博開放平臺API文檔[EB/OL].http://open.weibo.com/
[7]周中華,張惠然,謝江.基于Python的新浪微博數據爬蟲[J].計算機應用,2014,34(11):3131-3134.
[8]吳劍蘭.基于Python的新浪微博爬蟲研究[J].無線互聯科技,2015(6):94-96.
[9]鄒科文,李達,鄧婷敏,等.網絡爬蟲針對“反爬”網站的爬取策略研究[J].電腦知識與技術,2016,12(7):61-63.
