數據挖掘在選課推薦中的研究
2017-01-20 10:09:33胡健王理江
軟件 2016年4期
關鍵詞:數據挖掘
胡健 王理江
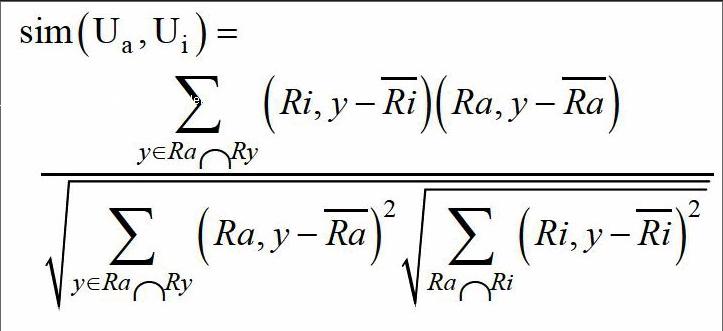

摘要:在當代大學教育中,學生選課系統中存在的缺乏個性化課程推薦、選課效率較低的問題,本文針對這個問題結合數據挖掘技術對選課建立了選課推薦系統模型,使得學生在選課中有更多的參考,在一定程度上減少了學生選課的盲目性。
關鍵詞:選課;數據挖掘;推薦系統
中圖分類號:TP391 文獻標識碼:A DOI:10.3969/j.issn.1003-6970.2016.04.028
0 引言
隨著教育改革的推進選課制度已在高校普及多年,為了滿足學生的個性化需求,根據上課時間、學習興趣、任課老師以及學習進程等各方面的需求選擇適合自己的課程,課程的自選使得學生的自由空間更大且學習效率明顯提升。選課制度作為高校教學管理制度改革內容的一部分同時也是學分制的重要內容,選課制度的設計及實施過程都需結合大學生教育理念。改革開放的到來更是為教育吹來了春風,教育體制也突破了傳統模式,開始實行選課制和學分制。然而多數高校在選課制度實施過程中普遍存在課程結構設置不合理、選課方式不完善、選課指導體系不健全等問題。學生不能結合自身的專業和興趣進行選課,選課缺乏目的性和針對性;選課制度不利于學生的個性發展,也不能為學生以后的工作帶來良好的指導,從而出現了專業與職位不對口的現象。有鑒于此,本文將數據挖掘中的個性化推薦技術應用于選課系統中,根據學生自身的狀況、學習需求以及興趣偏好等,為學生提供個性化課程推薦平臺,從而避免學生選課的盲目性和跟風現象,提高了課程資源的利用率和選課質量。
1 我國高校選課制度的現狀
隨著選課制在高校的普及,教育也逐漸走向網絡化和信息化,在這樣一個計算機網絡普及的時代自然選課過程也趨于網絡化。受到傳統觀念及學年制的影響,選課制度在運行過程中還存在一定的缺陷,另外在新教學觀念的實施和高素質人才的培養中選課制也沒有體現其優勢,具體原因有下幾個方面:
1.1 目前實施的選課制不利于學生的個性發展
隨著社會對人才專業需求的多樣化,傳統的人才培養模式已無法滿足社會發展需求,同時也抑制了學生的個性化發展。選課制的實行使得學生可根據自身的興趣愛好選擇合適的課程、任課教師以及學習時間,各種自由的選擇使得的個性特征得到滿足,從而提高了學生的學習積極性。
1.2 沒有實現真正的選課
盡管有部分學校允許學生選擇跨專業、跨年級的課程,但在教師資源、上課時間以及場地資源等影響下,學生仍無法選擇自己喜歡的課程,時間及資源上的沖突使得學生在自主選課上受到了一定的限制,對于比較熱門的課程,當選課人數較多資源有限時,課程就會被刪除,自主選課無法充分發揮其作用。隨著高校不斷擴招,教師資源越來越匱乏,學生的選擇范圍有限。
1.3 選課工作實施不到位
選課指導也是一個很重要的環節,特別是新生由于對課程了解不深,因此很容易出現盲目選課現象。部分學生了為了選擇簡單易學的知識而不顧自身發展,隨意性的選課對教學質量造成了很大的影響,同時也脫離了選課制實行的初衷。針對這個問題本文提出了利用數據挖掘技術篩選歷史選課數據中隱藏的、有用的知識,作為指導學生選課的依據,該課題的提出對高校教學管理改革有著重要的現實意義。
2 數據挖掘與個性化推薦系統
數據挖掘是從大量的、不完全的、有噪聲的、模糊的、隨機的數據中,提取隱含在其中的、人們事先不知道的、但又是潛在有用的信息和知識的過程。它是一門交叉學科,集成了許多學科中成熟的工具和技術,包括統計學、數據庫技術、機器學習、模型識別、人工智能等。數據挖掘技術已經有了很好的應用,例如銷售、銀行、電信、保險、交通等領域。數據挖掘所能解決的典型商業問題包括:數據庫營銷、客戶群體劃分、背景分析、交叉銷售等市場分析行為,以及客戶流失性分析、客戶信用記分、欺詐發現等。將數據挖掘技術應用于教育中,也是這些技術發展的必然。個性化推薦是數據挖掘中一項非常有用的技術,它是20世紀90年代被作為一個獨立的概念提出來,近些年有了迅速的發展,得益于Web2.0技術的成熟。有了這個技術,用戶不再是被動的獲取信息,而是成為獲取信息這個過程中的主動參與者。它在商業領域大獲成功,在一個實際的推薦系統中需要推薦的產品可能會有上萬種,甚至更多,例如Amazon,eBay,YouTube等,用戶的數目也會非常巨大。準確、高效的推薦系統可以挖掘用戶潛在的消費傾向,為眾多的用戶提供個性化服務。協同過濾系統是目前應用最為廣泛,也是效果最好的個性化推薦系統。協同過濾(Colaborative Filtering)這個概念由Goldberg等在1992年提出,并應用于Tapestry系統。目前主要有兩類協同過濾推薦算法:基于用戶的協同過濾推薦算法和基于項目的協同過濾推薦算法。
3 學生個性化選課推薦系統的研究
本文采用的是基于用戶的協同過濾算法,在高校選課系統中融入該算法可幫助學生根據自身的興趣愛好選擇與自身發展最為貼近的課程、學習量及任課教師,個性化選課推薦系統的運用使得高校選課機制更為完善。在推薦系統內建立評價矩陣,對學生在選課過程中的主要因素進行描述,如興趣愛好、專業、學習程度、選課記錄和老師評價等,算法根據學生這些信息對其行為進行分析,并建立相應的學生項,通過與評價矩陣中的項進行對比找出相似度最高的選課記錄,并向該學生進行課程推薦。由此可見,個性化高校選課推薦系統模型主要分為評價矩陣、搜索最近鄰居和課程推薦三個部分。
3.1 建立評價矩陣
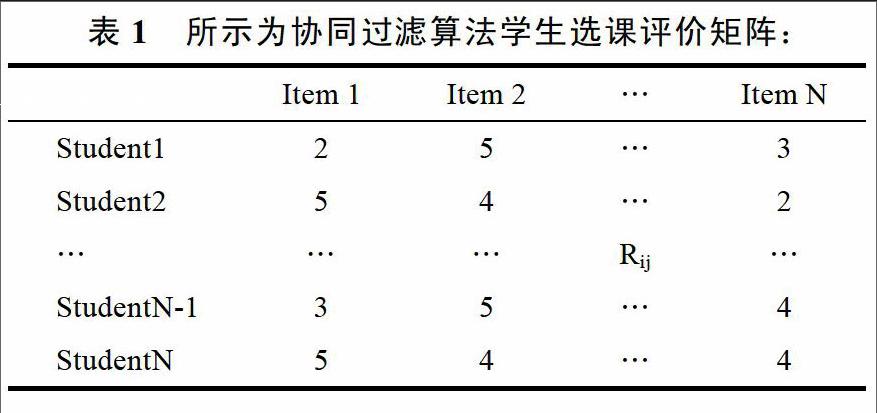
根據專業、愛好、選課記錄、學習程度等信息收集歷史選課數據,若直接從教務系統中選取,則需對數據進行清洗和轉化,從而形成協同過濾算法學生選課評價矩陣。
在上述矩陣中Rij的中的i代表的是學生,j代表的是項目,R代表的是評價。Rij的取值范圍通常在[0,5]這個區間范圍內,分值的大小與評價的高低成正比。
3.2 搜索最近鄰居
將目標學生與評價舉證中所有學生的相似度進行對比,找出相似度最高的一組并建立相應的最近鄰居集合,在基于用戶的寫通過率算法中這步是很難關鍵的,相似度的具體算法如下所示:
在上述公式中sim(Um,Ui),代表目標學生與矩陣學生的相似度,y代表兩者共同評價過的項目,Ra,y,和Ri,y表示a學生和i學生對y項目的評價,Ra和Ri表示項目評價平均值。
3.3 產生推薦
根據評價結果和推薦算法產生推薦,具體推薦算法如下所示:
sim(a,n)表示相似度,Rn,i表示項目評分Ra和Rn表示項目評價平均值。該算法主要是針對用戶評價項目較多的情況,對于個別評價,結果可能就沒那么準確。
4 結束語
本文基于協同過濾算法的個性化高校選課推薦系統是根據學生的興趣愛好、學習程度和專業等信息進行相似度計算,然后再根據相似度的高低推薦相應的課程。但是該算法存在“冷啟動”問題,即在沒有學生的歷史數據作為參考和分析的基礎下是無法實現選課推薦的。高校個性化選課推薦系統的使用可有效提高學生的學習興趣以及學校的教學質量,幫助學生科學合理的選擇合適的課程,為學生的個性化發展提供有效的學習方式。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
