煤與瓦斯突出強度的FOA-SVM預測模型與應用*
2017-01-12 05:58:04謝國民單敏柱
傳感技術學報 2016年12期
關鍵詞:模型
謝國民,單敏柱,劉 明
(1.遼寧工程技術大學電氣與控制工程學院,遼寧葫蘆島125105 2.遼寧朝陽師范高等專科學校數計系,遼寧朝陽122000)
煤與瓦斯突出強度的FOA-SVM預測模型與應用*
謝國民1*,單敏柱1,劉 明2
(1.遼寧工程技術大學電氣與控制工程學院,遼寧葫蘆島125105 2.遼寧朝陽師范高等專科學校數計系,遼寧朝陽122000)
為了能夠對煤與瓦斯突出進行準確的辨識,本文提出將果蠅算法(FOA)與支持向量機(SVM)相結合的預測方法。首先通過Karhunen-Loève變換(K-L變換)進行特征提取,降低特征向量的維數,減小運算量;然后將經過K-L變換的樣本作為FOA-SVM模型輸入,通過果蠅算法全局尋優,自動搜索符合本預測模型最佳參數組合。通過對預測模型的訓練與仿真表明:本文提出的方法具有設計實現簡單,辨識精度高、推廣能力強的特點,為煤礦災害預測提供理論支持。
煤與瓦斯突出;Karhunen-Loève變換;支持向量機;特征提取;果蠅算法
煤與瓦斯突出是一種迅速而強烈的動力現象,常表現為在瞬間將大量的煤從煤體中拋向巷道或工作空間,并伴有大量瓦斯涌出[1],突出往往會給礦井生產帶來了極大威脅和經濟損失。在煤礦瓦斯災害中,煤與瓦斯突出是一種極其復雜的動力災害,危害性極大[2]。因此,對煤與瓦斯突出進行迅速地準確預測顯得尤為重要。近些年來,一些學者提出了預測方法,如DBC優化算法[3]、灰色關聯-遺傳神經網絡[4]、模糊神經網絡[5]等。盡管這些方法在工程實際中取得了一定效果,但是還存在一些不足,如神經網絡只有在大量訓練樣本的前提下,系統的預測精度才可以提高,而由于受作業環境的影響,煤與瓦斯突出的樣本量往往是有限的[6],使得神經網絡在煤與瓦斯突出預測方面受到制約;遺傳算法則比較費時,容易出現早熟收斂問題。同時,以上的研究方法的特征向量各參數間在具有一定的相關性,且研究方法較復雜,模型學習效率低,不利于對煤與瓦斯突出進行預測。
K-L變換在圖像識別中應用較為廣泛,通常應用在人臉識別系統中,本文將此方法應用到煤與瓦斯突出中進行研究。因為它不僅可以對特征量降維,而且考慮到了樣本類別信息,實現了可監督的特征提取。同時經過K-L變換各特征參數之間剔除了相關性,更有利于進行預測。支持向量機則是一種小樣本的學習方法,簡化了分類預測問題,適合分析學習樣本有限的問題。FOA算法是臺灣學者潘文超提出的一種參數尋優的算法,該算法在尋優過程中,不僅能夠全局尋優,同時算法運行速度快,能夠滿足煤與瓦斯突出在預測的實時性要求。
通過分析現有方法的不足,本文將K-L變換與FOA-SVM相結合,建立煤與瓦斯突出強度預測模型,并通過仿真驗證其可行性。
1 煤與瓦斯突出影響因素分析
煤與瓦斯突出是一種復雜的礦井動力現象,受多種因素影響[7],按照突出機理的各種學說,研究表明煤與瓦斯突出是在地應力、蘊含在煤體中的瓦斯、煤體本身力學特性以及煤礦采取的開采技術的相互作用下的產生的結果。通過對煤與瓦斯突出的相關因素研究,總結以往專家經驗和意見,確定以下5個導致煤與瓦斯突出的關鍵因素:
①地應力 地應力為煤與瓦斯突出的發生提供了動力,當地應力較高時,煤體自身的強度就會降低,與此同時,瓦斯壓力增大,煤層的通透性就會降低,在這種環境條件下,煤與瓦斯突出也是很容易發生的。
②瓦斯參數 一般包括瓦斯涌出量、瓦斯放散初速度等。前者是煤與瓦斯突出能夠發生的物質前提;后者則反映了瓦斯擴散的能力與滲透的規律,是對突出區域預測的一個重要指標。
③頂板和底板的巖性 如果頂板和底板的通透性好則瓦斯排放容易,發生煤與瓦斯突出的可能性較小;與之相反則瓦斯含量高且瓦斯壓力變大,極易發生煤與瓦斯突出。
④活動斷裂 斷裂帶周圍和多個斷裂帶相接的區域是煤與瓦斯突出發生的頻發地帶。并且斷裂的活動性影響著突出強度和突出的次數[8]。
⑤煤層厚度 煤層是瓦斯存在的介質,通過研究發現煤層的厚度與瓦斯含量的多少有一定的相關性,它體現了煤層在原始積淀上的不同,同時也表明了不同的瓦斯分布壓力。通常,在較厚的突出煤層,一般是在軟煤帶附近,最有可能有煤與瓦斯突出的發生。
2 K-L-FOA-SVM模型介紹
2.1 K-L變換原理
K-L變換是一種應用統計的方法對特征進行提取的變換[9],K-L變換可以在正交變換的情況下實現失真真最小,這樣不但能去除數據之間的相關性,還能保證在均方誤差的準則下總體熵最小。將它應用于煤與瓦斯突出的致突因素的特征提取,不僅簡化了致突特征的提取過程,也減少了在訓練過程中的計算量。其具體計算步驟如下:
步驟1 計算訓練樣本集X={x1,x2,…,xM}的二階矩陣,以此為K-L變換的產生矩陣,即:
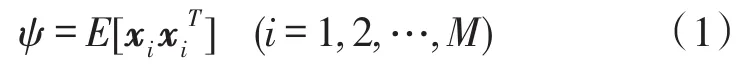
其中xi=[xi1,xi2,…,xij,…,xiN]T,N是訓練樣本的維數,xij是第i個訓練樣本的第j個特征,M是訓練樣本的總數。
步驟2 計算產生矩陣的本征值λi(i=i,2,…,N),并將其按照從大到小的順序進行排序。
步驟3 從本征值選擇前n個本征值使得信息量e盡可能的大,同時n又要盡可能的小,即用較少的主成分來表示數據的全部,不僅絕大部分的數據得以保留,而且樣本的特征的維數趨于最小。
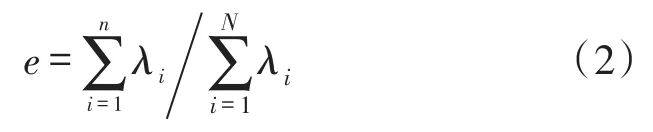
步驟4 將要包含的信息量e和特征維數n進行綜合考慮,確定n的大小。
步驟5 計算前n個本征值對應的本征向量μi(i=1,2,…,n)構成的變換矩陣W=(μ1,μ2,…,μn),然后再將訓練樣本集投影到W空間中去,則經過K-L變換后所提取到的特征空間為

2.2 支持向量機算法
SVM是一種新的機器學習方法,是在統計學習理論SLT的基礎上,能夠同時最小化經驗誤差與最大化幾何邊緣區,提高泛化能力,保證全局最優解,能夠較好地解決小樣本、非線性的問題[10-12]。
SVM是按照結構風險最小化的原則進行分類,它的基礎是解決兩類的分類問題,最終產生一個超平面將兩類分開,與此同時,還要求兩類距離此超平面距離最大,保證了分類的準確性與精確性。
假定訓練的樣本為:
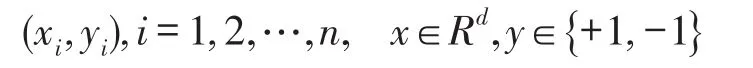
是分類標號。SVM實現的就是一個有限定條件下的問題最優化,設最優分類函數和限定條件分別為:
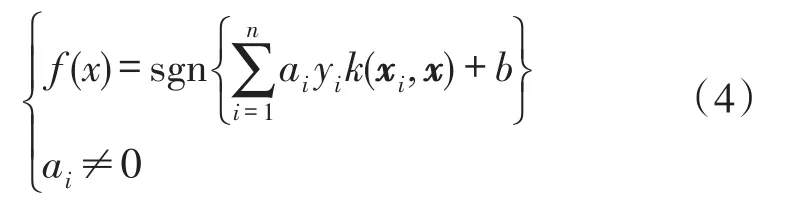
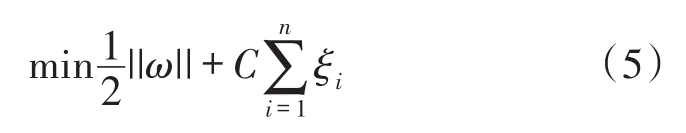
其中,xi是支持向量,x是需要分類的向量,k(·)是核函數,a、b是確定最優超平面的系數,C>0是懲罰系數,ξi是松弛系數。通過Lagrange泛函算法,將此問題轉化成一個二次優化問題:
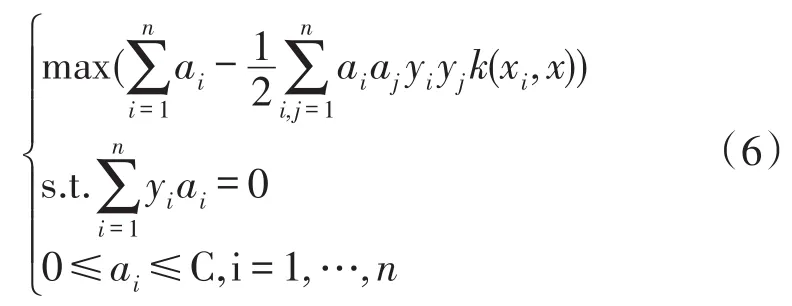
b值通過式(7)求得。
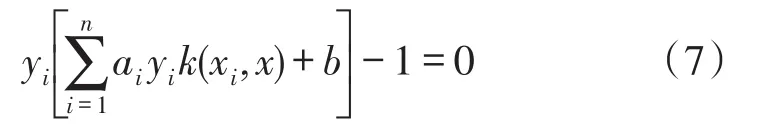
可以看出,選擇不同的k(·),支持向量機的形式就會不同,因此就會產生不同的超平面進行分類,常用的核函數類型有線性核函數、多項式核函數、高斯核函數等。線性核函數用在線性可分的情況中,本文中研究的煤與瓦斯突出的預測本身為非線性狀態,不適合用此核函數;多項式核函數需要的參數較多,當其階數較高時,核矩陣會趨于無窮大或無窮小,亦不適合本文的研究;而高斯核函數所需參數較少,而且分類辨識效果較好,因此本文選取高斯函數作為SVM的核函數,其表達式為:
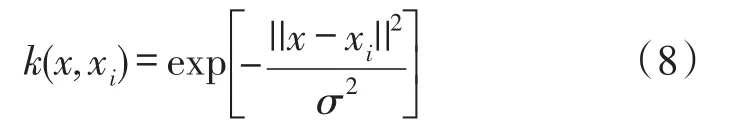
2.3 FOA算法原理
果蠅算法為由果蠅覓食行為推演的尋求全局優化方法[13-15]。果蠅的感官較其他生物更加靈敏,其嗅覺可以嗅到周圍的氣體分子,甚至是與之相距40 km遠的氣味,在接近食物時可以感知到食物和其他果蠅的集中分布,迭代具體過程如下:
步驟1 設果蠅群體具有初始的隨機坐標:
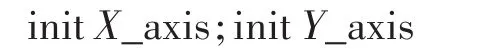
步驟2 加載單個果蠅靠嗅覺查找目標的隨機距離和方向。
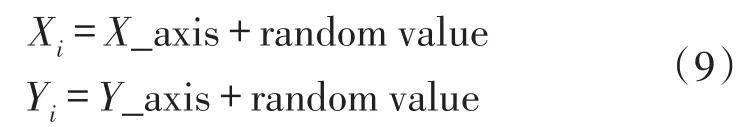
步驟3 由于食物具體位置未知,需要先假定與原點的距離(dist),然后計算氣味濃度確定值S,S與距離成反比,即
步驟4 將S代入氣味濃度判定函數(fitness function)解出此單個果蠅所處位置處的氣味濃度值(smelli),將smelli輸入網絡得到預估值Pred,此處選用均方根誤差作為氣味濃度的適應度函數。
步驟5 尋找整個群體中smelli最大的果蠅個體,即求取極大值的過程。
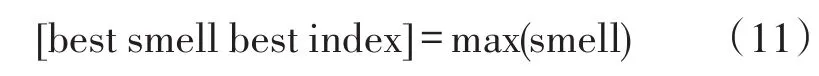
步驟6 記錄最大氣味濃度值和x、y的坐標,那么果蠅群體根據視覺判斷飛向此處。

步驟7 進行迭代運算搜索最優。循環步驟2~步驟5,同時與上一次迭代氣味濃度進行比較,如果比上一次優,則執行步驟6。
雖然FOA在進行迭代后可以尋找到最優氣味濃度,但是FOA有時會陷入局部的最優解,于是本文中將Si加上一個跳脫參數Δ,即可找到全局極值,Δ如下:
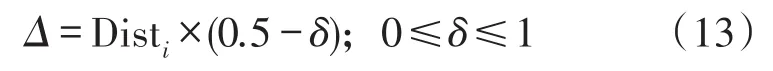
2.4 FOA優化SVM模型
SVM中的每一個參數在很大程度上是由經驗確定,造成網絡誤差加大,運行速度變慢等,為此引入FOA算法來于優化SVM參數,不僅能夠提高預測精度,而且可以加快計算的速度。SVM對非線性問題分類取決于結合因素[16],本文中選取高斯參數σ2將特征向量映射到高維特征空間中,在此特征空間中搜索最佳的懲罰因子C,使得SVM的置信區間與經驗風險達到最優,具體步驟如下:
步驟1 初始化果蠅群體坐標、相關系數,設置其置信區間,種群規模,迭代最大次數。
步驟2 果蠅搜索最佳參數,在線尋找氣味濃度最佳的果蠅位置,通過不斷更新參數C與g。
步驟3 根據適應度函數計算氣味濃度。
步驟4 記錄氣味濃度最大值,及其對應的最佳位置。
步驟5 是否滿足結束條件;若此解符合要求則停止,否則轉到步驟2。判斷依據為是否已經達到迭代次數以及此次氣味濃度是否優于上一次的最優值。
步驟6 將果蠅優化算法尋找到的最優值賦值給式(5)和式(8)。
3 仿真
3.1 特征提取與預測模型訓練仿真
步驟1 樣本數據處理 通過參考相關研究文獻[17-18]選取以下9個因素作為煤與瓦斯突出的特征:瓦斯壓力(x1,MPa)、煤層瓦斯含量(x2,m3/t)、垂深(x3,m)、煤層開采深度(x4,km)、軟煤層煤體厚度(x5,m)、頂板滲透率(x6,%)、最大主應力(x7,MPa)、絕對瓦斯涌出量(x8,m3/d)、相對瓦斯涌出量(x9,m3/d)。在K-L變換前先使用MATLAB 2014b歸一化函數mapminmax,對樣本數據進行歸一化處理。然后對處理過的數據進行KL變換,得到特征提取后的特征向量樣本組。得到特征向量在選擇不同數量主成分時特征提取所含原始數據的信息量,如表1所示。通過分析可以看出,當選擇4個主成分的時候,已經包含了原始數據的絕大部分信息量,表2為前4個主成分的得分系數矩陣。
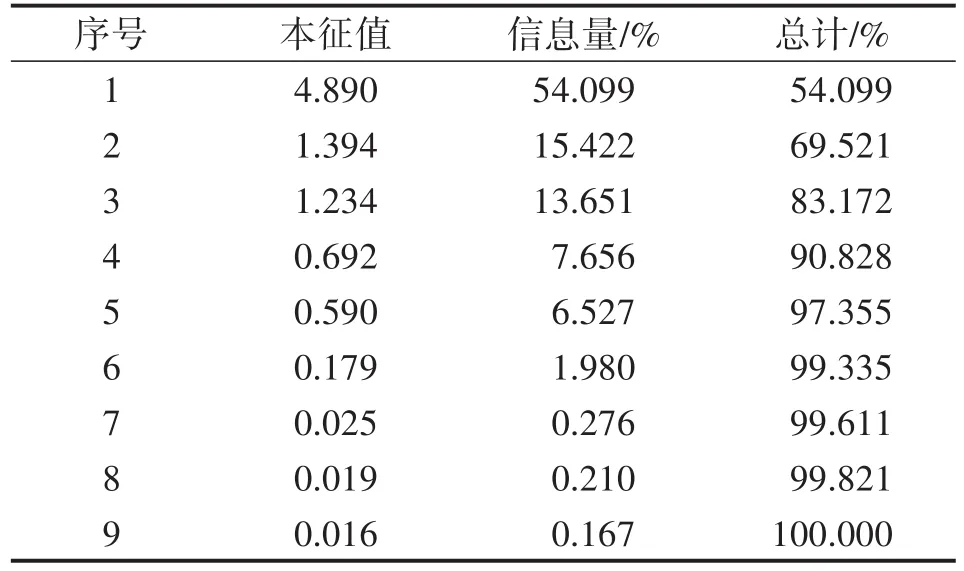
表1 主成分與信息量的關系
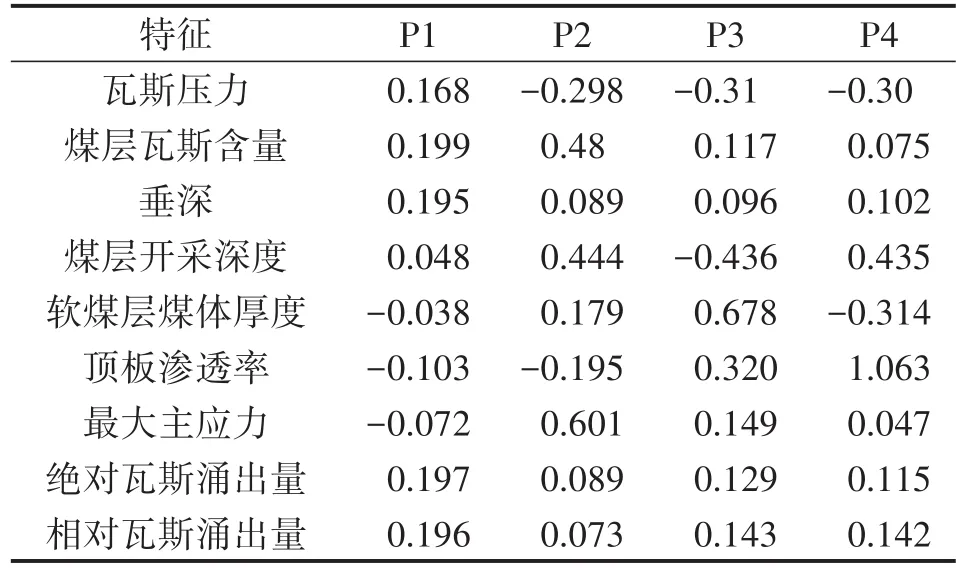
表2 前4個主成分得分系數
步驟2 種群位置范圍設置為[1,2],種群規模為30,迭代的最大次數為100次,SVM懲罰系數C的區間為[10-1,102],高斯核函數的參數的區間為[10-1,102]。本文研究中將煤與瓦斯突出的強度級別分為安全、較危險、危險3個級別,在用SVM進行預測時分別用1、2、3表示這3種級別。利用果蠅優化算法對支持向量機尋優,搜索最佳參數組合。在果蠅算法優化支持向量機進行訓練學習時,選擇經過K-L變換前后的120組樣本數據對SVM訓練,訓練誤差如圖1所示。
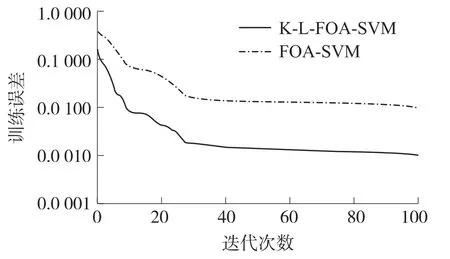
圖1 訓練誤差分析
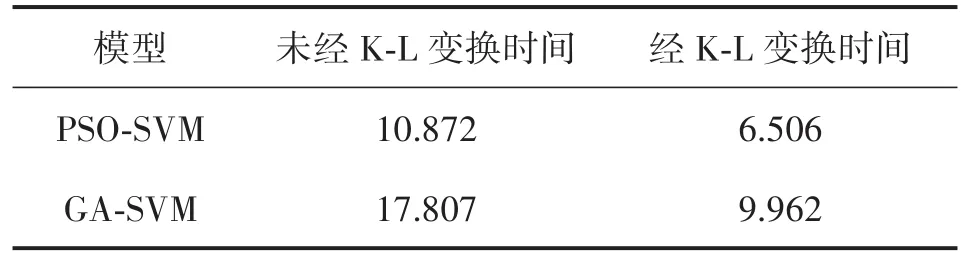
表3 3種預測模型參數搜索時間 單位:s
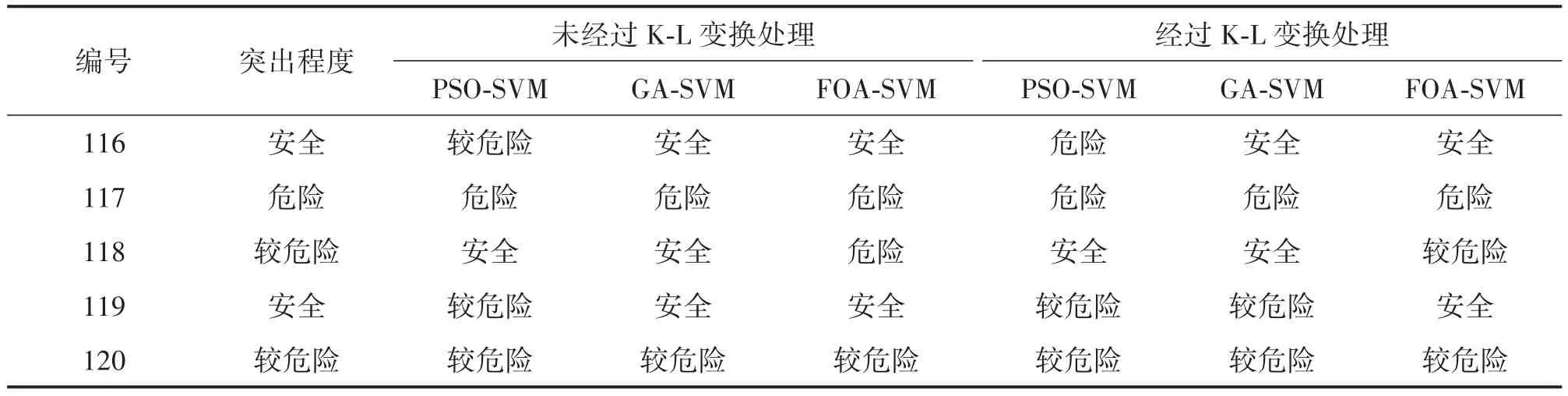
表4 預測模型部分訓練結果對比
從圖1可以看出,預測模型無論經過K-L變換與否隨著迭代次數的增加,兩者訓練的誤差都趨于平緩,表明預測的模型穩定性較好。通過對比預測模型的訓練誤差,可以直觀地發現:加入K-L變換后的訓練誤差遠遠小于未經過K-L變換的訓練誤差,這是因為在經過K-L變換后的樣本特征之間去除了相關性,同時抑制干擾噪聲對采集數據的影響,提高了模型預測的準確性。
將FOA-SVM模型與常用的PSO-SVM、GASVM預測模型在加入K-L變換前后尋優時間做了對比,如表3所示,表4為在訓練過程中的部分訓練結果。
3種預測模型在經過K-L變換處理后,對煤與瓦斯突出預測的性能得以提升,可見采用K-L變換對預測模型進行特征提取很有必要,同時果蠅算法本身的尋優時間也較短,有利于實時預測的要求。
3.2 預測仿真
用后30組數據用作驗證樣本,采用MATLAB 2014b與LIBSVM工具箱進行編程仿真,驗證此模型的精確度,各算法的預測識別結果見表5。圖2為經過K-L變換的的三種預測模型的識別結果。

表5 模型預測性能比較
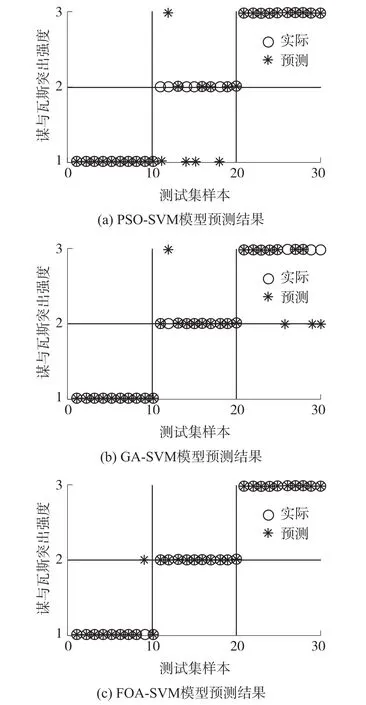
圖2 3種預測模型預測對比圖
從表5與圖2中分析知:對比三種預測模型的預測精度,可以看出本文中采用的果蠅尋優算法體現了其優越性,同時也表明FOA-SVM模型在煤與瓦斯突出預測方面的可行性。通過上述的分析可知,將K-L與FOA-SVM有機結合的方法在對研究煤與瓦斯突出強度辨識中可行性較高。
4 結論
本文將K-L變換、FOA算法和SVM三者有機結合,提出基于K-L變換和FOA-SVM相結合的煤與瓦斯突出預測模型。對特征向量采用K-L變換處理有效去噪降維,降低預測模型的運算量;將FOA用于SVM的參數尋優,提高了模型的全局搜索能力和泛化能力。通過仿真表明本文提出的預測模型在對煤與瓦斯出強度辨識的準確度與運行時間均優于常用預測模型。總體分析知,K-L-FOASVM辨識模型具有可行性,同時為其他相關研究領域提供一定的理論指導。
[1]Liu Xianglan,Hu Qianting,Zhao Xusheng,etc.Study on Early Warning System of Coal and Gas Outburst[C]//Conference Anthology,IEEE,2013:1-4.
[2]程東全,顧鋒.基于可拓模式識別的煤、與瓦斯突出危險性分析[J].安全與環境學報,2012,12(1):241-243.
[3]彭繼慎,聶苓.DBC優化算法在瓦斯突出預測中的應用[J].計算機系統應用,2014,23(2):119-122.
[4]胡廣青,姜波,吳胡.基于灰色關聯-遺傳神經網絡的煤與瓦斯突出預測模型[J].中國煤炭地質,2011,23(9):22-26.
[5]孫霞.基于模糊神經網絡的煤礦瓦斯預測[J].安徽工業大學學報(自然科學版),2012,29(3):229-232.
[6]曲方,安文超,李迎業,等.基于GRA-SVM方法的煤與瓦斯突出預測模型研究[J].中國煤炭,2012,38(11):102-106.
[7]付華,王馨蕊,王志軍,等.基于PCA和PSO-ELM的煤與瓦斯突出軟測量研究[J].傳感技術學報,2014,27(12):1710-1715.
[8]朱志潔,張宏偉,韓軍,等.基于PCA-BP神經網絡的煤與瓦斯突出預測研究[J].中國安全科學學報,2013,23(4):45-50.
[9]Cappelli R,Maio D,Maltoni D.Multispace KL for Pattern Representation and Classification[J].2001,23(9):977-996.
[10]陳果.基于遺傳算法的支持向量機時間序列預測優化[J].儀器儀表學報,2006,27(9):1080-1084.
[11]Krishna Satya Varma M,Rao Dr N K K,Raju K K,et al.Pixelbased Classification Using Support Vector Machine Classifier[C]//IEEE 6th International Conference on Advanced Computing,2016:51-55.
[12]Guangyi Chen,Tien D Bui,AdamKrzyz?ak.Sparse Support Vector Machine for Pattern Recognition[J].Concurrency and Computation:Practice and Experience,2015,28(7):2261-2273.
[13]Pan W T.A New Fruit Fly Optimization Algorithm:Taking Thefinancial Distress Model as an Example[J].Knowledge-Based-Systems,2012,26:69-74.
[14]Jia Dongqin,Shi Buhua.Based on the FOA Algorithm Research of Ocean-Going Vessels Economy Speed[J].International Conference on Electrical&Electronics Engineering,2013(8):472-476.
[15]Yin Lüjiang,Li Xinyu,Gao Liang,et al.A New Improved Fruit Fly Optimization Algorithm for Traveling Salesman Problem[C]//8th International Conference on Advanced Computational Intelligence Chiang Mai,Thailand;February 14-16,2016:55-60.
[16]石志標,苗瑩.基于FOA-SVM的汽輪機振動故障診斷[J].振動與沖擊,2014,33(22):111-114.
[17]王雨虹,付華,張洋.基于KPCA和CIPSO-PNN的煤與瓦斯突出強度辨識模型[J].傳感技術學報,2015,28(2):271-276.
[18]謝國民,丁會巧,付華,等.基于FRA與GA-ELM的煤與瓦斯突出預測研究[J].傳感技術學報,2015,28(11):1670-1674.

謝國民(1969-),男,遼寧阜新人,博士,副教授,研究生導師。主要從事工業自動化和智能檢測及控制方面的研究工作,Lngdxgm@163.com;

單敏柱(1989-),男,河北張家口人,碩士研究生。主要研究控制理論與控制工程,shanminzhushr@163.com。
Coal and Gas Outburst Intensity Prediction of FOA-SVM Model and Application*
XIE Guomin1*,SHAN Minzhu1,LIU Ming2
(1.College of Electrical and Control Engineering,Liaoning Technical University,Huludao Liaoning125105,China2.Count Department of Liaoning Chaoyang Teachers College,Chaoyang Liaoning122000,China)
In order to accurately identify the coal and gas outburst,this paper proposes a prediction method based on the combination of the fruit fly optimization algorithm(FOA)and the support vector machine(SVM).Firstly,through Karhunen-Loève transform(K-L transform)to extract features,this can reduce the dimension of feature vectors and the amount of computation;the samples through K-L transform are the FOA-SVM model’s input,by FOA globally searching the best parameter combination for the prediction model.The training and simulation results show that the proposed method has the characteristics of simple design,high accuracy and strong generalization ability,which provides theoretical support for the coal mine disaster prediction.
coal and gas outburst;Karhunen-Loève transform;support vector machine;feature extraction;fruit fly optimization algorithm
TP183;TP212
A
1004-1699(2016)12-1941-06
??7230
10.3969/j.issn.1004-1699.2016.12.027
項目來源:國家自然科學基金項目(51274118);遼寧省教育廳基金項目(UPRP20140464)
2016-03-29修改日期:2016-08-30
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
