面向異構(gòu)并行架構(gòu)的大規(guī)模原型學(xué)習(xí)算法
2016-12-22 08:52:48蘇統(tǒng)華李松澤鄧勝春
哈爾濱工業(yè)大學(xué)學(xué)報 2016年11期
蘇統(tǒng)華, 李松澤, 鄧勝春, 于 洋, 白 薇
(1.哈爾濱工業(yè)大學(xué) 軟件學(xué)院, 哈爾濱 150001;2.中建八局大連公司, 遼寧 大連 116021;3.諾基亞通信系統(tǒng)技術(shù)(北京)有限公司浙江分公司, 杭州 310053)
?
面向異構(gòu)并行架構(gòu)的大規(guī)模原型學(xué)習(xí)算法
蘇統(tǒng)華1, 李松澤1, 鄧勝春1, 于 洋2, 白 薇3
(1.哈爾濱工業(yè)大學(xué) 軟件學(xué)院, 哈爾濱 150001;2.中建八局大連公司, 遼寧 大連 116021;3.諾基亞通信系統(tǒng)技術(shù)(北京)有限公司浙江分公司, 杭州 310053)
為解決當(dāng)前原型學(xué)習(xí)算法在大規(guī)模、大類別機(jī)器學(xué)習(xí)和模式識別領(lǐng)域的計(jì)算密集瓶頸問題,提出一種采用GPU和CPU異構(gòu)并行計(jì)算架構(gòu)的可擴(kuò)展原型學(xué)習(xí)算法框架. 一是通過分解和重組算法的計(jì)算任務(wù),將密集的計(jì)算負(fù)載轉(zhuǎn)移到GPU上,而CPU只需進(jìn)行少量的流程控制. 二是根據(jù)任務(wù)類型自適應(yīng)地決定是采用分塊策略還是并行歸約策略來實(shí)現(xiàn). 采用大規(guī)模手寫漢字樣本庫驗(yàn)證本框架,在消費(fèi)級顯卡GTX680上使用小批量處理模式進(jìn)行模型學(xué)習(xí)時,最高可得到194倍的加速比,升級到GTX980顯卡,加速比可提升到638倍;算法甚至在更難以加速的隨機(jī)梯度下降模式下,也至少能獲得30倍的加速比. 該算法框架在保證識別精度的前提下具有很高的可擴(kuò)展性,能夠有效解決原有原型學(xué)習(xí)的計(jì)算瓶頸問題.
原型學(xué)習(xí);學(xué)習(xí)矢量量化;手寫漢字識別;并行歸約;異構(gòu)并行計(jì)算
學(xué)習(xí)矢量量化LVQ (learning vector quantization)是一種適用于大規(guī)模、大類別分類任務(wù)的原型學(xué)習(xí)算法,具有低存儲、高識別吞吐率的優(yōu)點(diǎn). 已有的研究表明,當(dāng)采用判別學(xué)習(xí)準(zhǔn)則時,原型學(xué)習(xí)能在數(shù)字識別、漢字識別(含日本文字識別)問題上獲得較先進(jìn)的識別結(jié)果[1]. LVQ同樣在選取有限候選類方面具有非常好的效果. 例如,LVQ可以用來為復(fù)雜模型篩選小部分有潛力的類別集,從而有效緩解PL-MQDF模型[2]的高強(qiáng)度訓(xùn)練過程. 更重要的是,隨著移動設(shè)備的普及,LVQ以其模型精巧、速度快等特點(diǎn)能很好地適用于智能手機(jī)、平板電腦等嵌入式設(shè)備上的輸入法應(yīng)用[3-4].
學(xué)習(xí)一個魯棒的大規(guī)模LVQ模型,其計(jì)算復(fù)雜性令人望而生畏. 若使用單核CPU的傳統(tǒng)實(shí)現(xiàn)方法,將需要若干天的訓(xùn)練時間. 而對于判別學(xué)習(xí)準(zhǔn)則來說,數(shù)據(jù)越多識別效果則越好,當(dāng)然學(xué)習(xí)時間會相應(yīng)的加長. 部分研究者嘗試通過收集或人工合成的方式獲取更多的訓(xùn)練樣本. 最新的一些研究結(jié)果認(rèn)為,當(dāng)指數(shù)級增長樣本數(shù)量時,識別效果可以得到穩(wěn)步提升[5-6]. 然而,目前已進(jìn)入了多核計(jì)算時代. 英特爾公司的Pat Gelsinger曾表示,若芯片仍按照傳統(tǒng)方式設(shè)計(jì),到2015年芯片將如同太陽表面一樣熱[7]. GPU所使用的異構(gòu)并行計(jì)算架構(gòu)已開始逐漸補(bǔ)充甚至部分代替?zhèn)鹘y(tǒng)的串行計(jì)算架構(gòu). 因此,從單核處理器轉(zhuǎn)向大規(guī)模并行處理器是未來算法設(shè)計(jì)的必然趨勢.
GPU異構(gòu)計(jì)算架構(gòu)在機(jī)器學(xué)習(xí)以及模式識別任務(wù)領(lǐng)域具有突出的加速效果. Raina等人研究了深度信念網(wǎng)絡(luò)DBN (deep belief network)與稀疏編碼在GPU上的實(shí)現(xiàn)[8],他們的DBN實(shí)現(xiàn)方案達(dá)到了70倍的加速比,而稀疏編碼的并行算法則獲得了5到15倍的加速比. 一些學(xué)者也研究了大型多層神經(jīng)網(wǎng)絡(luò)在GPU上的實(shí)現(xiàn). Scherer與Behnke[9]在GPU上實(shí)現(xiàn)了加速比達(dá)100倍的卷積神經(jīng)網(wǎng)絡(luò)CNN (convolution neural network). Ciresan等人則在GPU上實(shí)現(xiàn)了深度多層感知機(jī),并且取得了當(dāng)前最好的識別性能[10]. 周明可等人則針對改進(jìn)二次判別函數(shù)MQDF (modified quadratic discriminative function)實(shí)現(xiàn)了基于GPU的判別訓(xùn)練方法,并將其成功應(yīng)用到了漢字識別上,其小批量處理實(shí)現(xiàn)方案獲得了15倍的加速比[6].
本文提出一種適用于大規(guī)模、大類別分類任務(wù)的異構(gòu)原型學(xué)習(xí)算法框架. 與已有的研究工作不同,本文提出的框架幾乎將所有的計(jì)算負(fù)載都調(diào)度到GPU上,CPU只負(fù)責(zé)協(xié)調(diào)部分計(jì)算邏輯. 為了充分利用GPU的計(jì)算資源,算法深入分析了計(jì)算負(fù)載的可并行度,大量使用了分塊平鋪以及并行歸約等并行計(jì)算模式. 算法在大類別手寫漢字識別任務(wù)下進(jìn)行驗(yàn)證,得到比較高的可擴(kuò)展性. 在小批量處理的模式下,使用消費(fèi)級顯卡GTX680,該算法最高可達(dá)194倍的加速比. 當(dāng)升級到新一代GTX980時,加速比提升到638倍. 最值得一提的是,該算法在隨機(jī)梯度模式下也可以獲得至少30倍的加速比.
1 算 法
1.1 LVQ串行算法
假設(shè)有一個包含C個類別的分類任務(wù),原型學(xué)習(xí)即產(chǎn)生一個原型向量集Θ= {mi, i=1, 2,…,C}. 為便于討論,本文的形式化主要對每個類包含一個原型(類中心)的情況展開,所述框架同樣適用于每個類包含多個原型的情況. 預(yù)測未知標(biāo)號樣本x的標(biāo)記問題,可以轉(zhuǎn)化為查找最小距離問題. 計(jì)算x與每個原型向量的歐氏距離,通過查找C個距離的最小值,就可以把x的標(biāo)號設(shè)為擁有最小距離的原型向量所在類別,表示x與該類別的原型最相似. 該預(yù)測過程可形式化為把x賦予標(biāo)號j:
為了學(xué)習(xí)一個原型向量集,需要從大規(guī)模訓(xùn)練樣本中進(jìn)行有監(jiān)督的訓(xùn)練. 用{(xn,yn), n=1,2,…,N }表示訓(xùn)練樣本集,其中yn為樣本xn的真實(shí)標(biāo)號,整個訓(xùn)練過程的目標(biāo)就是針對訓(xùn)練集最小化經(jīng)驗(yàn)損失[11]:
(1)
其中φ(·)為針對評分函數(shù)f(x,Θ)的損失函數(shù).
為了求解式(1)中的最小化問題,通常采用隨機(jī)梯度下降SGD (stochastic gradient descent)的方法對參數(shù)進(jìn)行更新:
其中η表示學(xué)習(xí)步長.
為說明LVQ中的判別學(xué)習(xí)思想,此處以廣義學(xué)習(xí)矢量量化GLVQ (generalized learning vector quantization)為例. 首先需定義一個可以度量樣本x誤差的測量函數(shù):
(2)
這里dc與dr分別表示樣本x與真實(shí)類別c以及競爭類別r之間的距離. 分類損失函數(shù)可以通過sigmoid函數(shù)近似:
(3)
其中ξ用來調(diào)節(jié)sigmoid函數(shù)的平滑度.
若使用歐氏平方距離,則mc與mr的更新公式可以表示為x的下列函數(shù):
(4)
整個GLVQ學(xué)習(xí)算法可由算法1中的偽碼表示. 算法1主要重復(fù)執(zhí)行下列任務(wù):采樣一個樣本,計(jì)算出該樣本與所有原型之間的距離,獲得真實(shí)類別與競爭類別,計(jì)算損失函數(shù)以及梯度,最后更新原型向量.
算法1 GLVQ學(xué)習(xí)算法(串行版本)
Input:training set{xn,yn}n=1,…,N, initial prototypes {mi}i=1,…,C
Output: {mi}i=1,…,C
1: while not convergent do
2: for each {xn,yn}
3: find out (mc,dc) and (mr,dr) through compare- then-exchange distances
4: compute error measure f(x) using Eq.(2)
6: update mcand mrusing Eq.(4)
7: end for
8: end while
9: return {mi}i=1,…,C
1.2 并行原型學(xué)習(xí)框架
算法1的整體處理流程是一個串行過程. 為了將其擴(kuò)展到異構(gòu)并行計(jì)算框架,采用帶小批量處理(數(shù)量為mb)的梯度下降算法. 改進(jìn)的算法框架如算法2所示,其中的每個計(jì)算步驟(第3到6行)都可以并行執(zhí)行. 本框架不是一個接著一個的逐一計(jì)算每個樣本與每個原型的距離,而是一次性計(jì)算一個批次的樣本與全部原型的距離,保存為距離矩陣(見算法2第3行);與距離矩陣有關(guān)的計(jì)算涉及高密度的計(jì)算,具有較高的可擴(kuò)展性. 對于查找真實(shí)類別與競爭類別可以與計(jì)算分類損失函數(shù)合并進(jìn)行,需要考察不同的并行執(zhí)行備選方案(見算法2第4和5行). 最后執(zhí)行的參數(shù)更新操作,由于是針對一批樣本的計(jì)算,再加上每個樣本包含數(shù)百維特征,所以具有天然的并行性.
算法2 GLVQ學(xué)習(xí)算法(并行框架)
Input:training set{xn,yn}n=1,…,N, initial prototypes {mi}i=1,…,C
Output: {mi}i=1,…,C
1: while not convergent do
2: for each mini-batch Ti={(xi1,yi1),…,(xiM,yiM)}
3: compute all distances as a matrix in parallel
4: find out genuine/rival pair in parallel
5: derive loss functionin parallel
6: update prototypesin parallel
7: end for
8: end while
9: return {mi}i=1,…,C
本文中的GPU程序設(shè)計(jì)圍繞英偉達(dá)公司的計(jì)算統(tǒng)一設(shè)備架構(gòu)CUDA(compute unified device architecture)編程模型展開. GPU硬件從物理上提供了兩個層面的并行模式:一塊GPU上包含多個流多處理器SM (streaming multiprocessor),每個流多處理器上又包含若干個流處理器(或稱為CUDA核心). 代碼的最終物理執(zhí)行在SP上,CUDA核函數(shù)將計(jì)算封裝然后分配到GPU上執(zhí)行. 邏輯上,CUDA也包含兩個軟件抽象層與兩個物理層相對應(yīng),即線程塊與線程,一個線程塊由一組線程組成,線程塊調(diào)度到SM上執(zhí)行,線程塊中的每個線程再具體調(diào)度到SP上執(zhí)行.
同一線程塊上的所有線程可以對一小塊稱為共享內(nèi)存的存儲區(qū)(SM3.0的設(shè)備共享內(nèi)存大小為64KB)進(jìn)行訪問,并且在執(zhí)行的任一時刻都可以進(jìn)行同步. GPU上還有一塊叫做全局內(nèi)存的存儲區(qū),其容量較大,GTX680上的全局內(nèi)存達(dá)到2GB. GPU上所有的線程均可訪問全局內(nèi)存,但全局內(nèi)存的訪問速度卻比共享內(nèi)存慢兩個數(shù)量級. 因此,英偉達(dá)公司提供了一種叫存儲合并的技術(shù)為特定連續(xù)數(shù)據(jù)的存儲訪問提供優(yōu)化方案. 由于GPU的計(jì)算與存儲都是并行執(zhí)行的,因此,許多算法的主要瓶頸都出現(xiàn)在CPU與GPU全局內(nèi)存的數(shù)據(jù)傳輸上以及全局內(nèi)存的訪問,另外合理利用共享內(nèi)存也能對程序的加速做出很大貢獻(xiàn).
為了充分挖掘GPU的性能,有兩點(diǎn)必須注意. 首先,CPU與GPU全局內(nèi)存的數(shù)據(jù)傳輸次數(shù)應(yīng)盡量少. 對于機(jī)器學(xué)習(xí)和模式識別問題,可以通過將原型模型數(shù)據(jù)一直保存在GPU全局內(nèi)存的方式來減少數(shù)據(jù)的傳輸次數(shù). 然而,有時全局內(nèi)存并不能保存所有的訓(xùn)練數(shù)據(jù),此時可以只在使用時傳輸相應(yīng)的數(shù)據(jù),每次傳輸?shù)臄?shù)據(jù)量盡量多,以此保證總體的傳輸次數(shù)最少. 由于原型參數(shù)數(shù)據(jù)以及訓(xùn)練數(shù)據(jù)均保存在GPU的全局內(nèi)存中,參數(shù)的更新操作也可以直接在GPU上完成.
另外需要注意的一點(diǎn)是學(xué)習(xí)算法的設(shè)計(jì)和實(shí)現(xiàn)需考慮線程塊與線程這兩個層面,這樣才能高效使用共享內(nèi)存,實(shí)現(xiàn)全局內(nèi)存合并訪問. 通常,線程塊的選取控制著整體數(shù)據(jù)并行策略,而線程塊內(nèi)的線程通過使用共享內(nèi)存和同步操作,控制著最底層的并行效果. 此外,已調(diào)度到SM上準(zhǔn)備執(zhí)行的線程塊在等待全局內(nèi)存訪問時,圖形硬件能很好地隱藏存儲延遲. 為了充分利用這些延遲時間,線程塊的數(shù)量可以盡量多,且相互之間獨(dú)立執(zhí)行.
根據(jù)以上兩點(diǎn)并行設(shè)計(jì)原則,本文提出一種可以把密集型計(jì)算分發(fā)到GPU上的計(jì)算框架,其流程圖如圖1所示. 圖中GPU與CPU控制權(quán)的更迭用虛線箭頭表示. 由圖1可知:原型向量只在程序啟動時傳輸?shù)紾PU上,并在程序結(jié)束時從GPU傳輸回CPU;若全局內(nèi)存無法一次性容納整個訓(xùn)練集,則通過小批量處理的方式分批將訓(xùn)練樣本傳輸?shù)紾PU全局內(nèi)存(CPU和GPU端的數(shù)據(jù)傳輸采用曲線箭頭表示),否則,只需一次性將所有數(shù)據(jù)拷貝到GPU. 整個執(zhí)行過程中,僅在流程控制和準(zhǔn)備數(shù)據(jù)上,需要少量的CPU干預(yù).
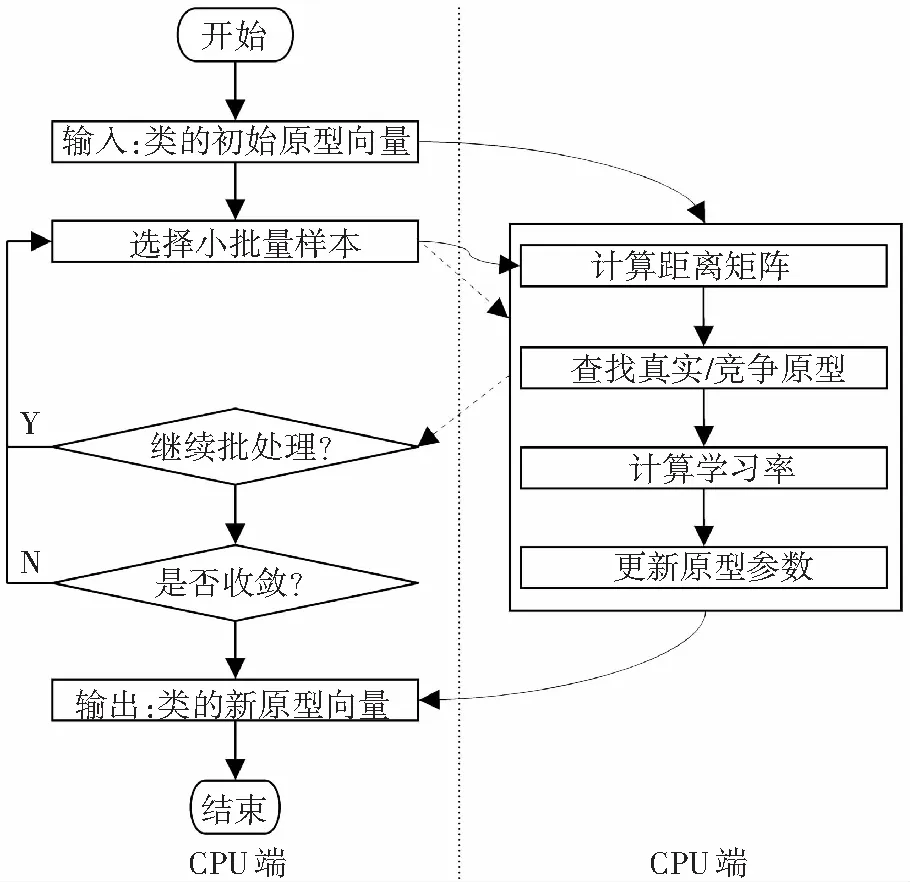
圖1 原型學(xué)習(xí)的異構(gòu)計(jì)算模型
2 算法實(shí)現(xiàn)
本文的算法實(shí)現(xiàn)采用CUDA并行編程架構(gòu). 在每輪的訓(xùn)練過程中主要調(diào)用了3個CUDA核函數(shù). 算法2中的第3到6步分別在3個獨(dú)立的核函數(shù)中執(zhí)行,其中第4步和第5步在同一核函數(shù)內(nèi)執(zhí)行. 在這3個核函數(shù)中,前2個最消耗時間,是所謂的“熱點(diǎn)”. 針對這2個核函數(shù),本文分別提供了兩種不同的并行計(jì)算算法,并對其效率進(jìn)行分析.
2.1 基于并行歸約的距離計(jì)算
歸約操作可以在K個輸入元素上執(zhí)行操作,轉(zhuǎn)化得到1個輸出元素. 它可以用來并行執(zhí)行可交換的二元操作. 標(biāo)準(zhǔn)的歸約算法可以在文獻(xiàn)[12]中找到. 此處采用歸約算法來計(jì)算兩個向量之間的歐氏平方距離. 在計(jì)算過程中,需定義操作符:
圖2顯示了16個線程時的歸約結(jié)構(gòu)(每個線程處理一個元素). 第一輪計(jì)算時,前8個元素依序與后8個元素進(jìn)行操作符為的運(yùn)算. 第二輪則是前8個元素中的前4個元素與后4個元素對應(yīng)運(yùn)算. 以此類推. 假設(shè)K是2的冪次倍,對于一個K維的向量則只需要計(jì)算log2(K)+1輪就能得到平方距離.
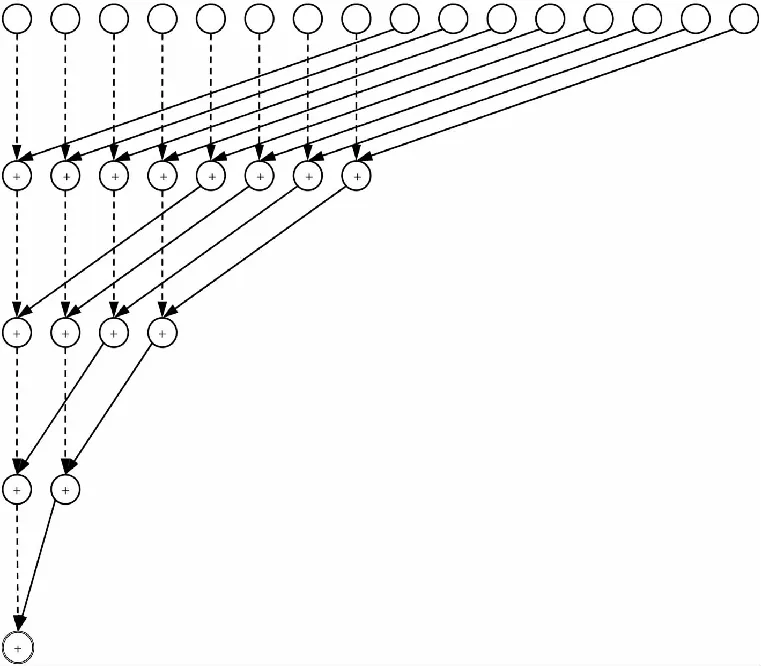
圖2 歸約過程示意(以16元素為例)
初始時,每個線程塊從全局內(nèi)存加載一個樣本向量和原型向量,負(fù)責(zé)一個平方距離的計(jì)算. 因此,一共需要(C,mb)個線程計(jì)算Cmb個平方距離.
然而,在具體實(shí)現(xiàn)的時候,仍有許多細(xì)節(jié)問題需要注意. 例如有時樣本特征向量的維度(用dim表示)并不是2的冪次倍,如160. 此時,線程塊的線程數(shù)目仍可以開啟為2的冪次倍,但其大小必須是小于特征向量的維度和物理硬件允許的線程塊線程數(shù)目的最大2的冪次值. 對于超出線程塊大小的數(shù)據(jù),可以在進(jìn)行對數(shù)步(log-step)歸約之前,通過額外一次運(yùn)算累加到線程塊前部線程的部分和上. 另外,程序應(yīng)盡可能復(fù)用共享內(nèi)存. 相較于一個線程塊計(jì)算一個平方距離,也可以讓每個線程塊計(jì)算一個樣本與TILE_LEN個原型之間的歐氏距離,以提高樣本數(shù)據(jù)的利用率.
2.2 基于分塊加和的距離計(jì)算
與歸約算法不同,該算法的思想是一個線程獨(dú)立計(jì)算一個歐氏距離,每個線程首先從全局內(nèi)存中獲取2個維度為dim的向量,然后執(zhí)行一個序列化的歸約操作. 但這樣讀取全局內(nèi)存的效率并不高,容易造成阻塞. 為了解決矩陣乘法任務(wù)中全局內(nèi)存的訪問阻塞問題,文獻(xiàn)[13]采用基于數(shù)據(jù)分塊思想進(jìn)行改善. 這種思想進(jìn)行適當(dāng)改進(jìn),也能很好地用來解決這里的平方距離的計(jì)算問題.
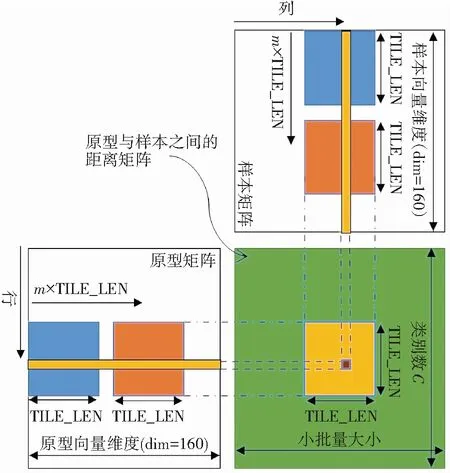
圖3 通過分塊思想實(shí)現(xiàn)平方距離的計(jì)算
2.3 基于并行歸約的最小距離搜索
當(dāng)計(jì)算出樣本(xn,yn)與C個原型的距離后,接下來的任務(wù)就是找出該類的真實(shí)類別(含額外的距離信息)(dc,c)與競爭類別(含額外的距離信息) (dr,r). 從而可以通過梯度下降方法更新mc與mr. 這里提出一種并行歸約的方式來尋找與該樣本最近的距離以及與其對應(yīng)的原型索引,并通過一些技巧來避免程序的條件判斷代碼. 例如,既然dr是除了dc之外的最小距離,在程序執(zhí)行時,可先通過yn獲取到dc,然后將其設(shè)為一個無限大的值,以防止尋找最小距離時需要對dc進(jìn)行特別的判斷操作. 若每個類使用多個原型中心,則需要提前通過一遍歸約操作來計(jì)算出最近的原型索引.
算法的內(nèi)核函數(shù)啟動了mb個線程塊,每個線程塊包含1024(或512)個線程. 同一個線程塊內(nèi)的所有線程將在共享內(nèi)存中做歸約操作,找出與該樣本距離最近的競爭類別. 同樣,若類別數(shù)C不為2的冪次倍,也可采用3.1節(jié)中相同的技巧. 另外,C可能比一個線程塊包含的線程數(shù)還要大,此時需要在進(jìn)行對數(shù)步歸約之前先對那些相距線程塊大小的數(shù)據(jù)進(jìn)行迭代加和.
2.4 基于比較交換的最小距離搜索
該算法只需調(diào)用mb個線程,每個線程通過比較交換操作找出一個樣本的真實(shí)類別(含額外的距離信息)(dc,c)與競爭類別(含額外的距離信息) (dr,r). 若mb比線程塊理論最大線程數(shù)還大,則需要分配多個線程塊.
該算法是對串行搜索算法進(jìn)行的最粗粒度的并行化. 一個線程將要執(zhí)行時間復(fù)雜度為O(C)的操作才能得到輸出,因此這是一種線程密集型的處理策略. 若mb的值很小,則無法充分利用GPU的資源.
2.5 參數(shù)更新
若使用隨機(jī)梯度下降(即mb=1),則每次更新時只需對兩個原型向量進(jìn)行更新,即真實(shí)類別原型向量和競爭類別原型向量. 參數(shù)更新的內(nèi)核函數(shù)只需調(diào)用dim個線程,每個線程按式(2)對向量的一個元素進(jìn)行更新. 當(dāng)mb>1時,每個線程需要迭代mb次,每輪迭代都考慮來自一個樣本的貢獻(xiàn),對兩個原型向量進(jìn)行更新.
3 驗(yàn) 證
將本文中的異構(gòu)原型學(xué)習(xí)算法在大規(guī)模、大類別手寫漢字識別任務(wù)上進(jìn)行測試,驗(yàn)證過程中主要對每類單個原型和每類8個原型的情況進(jìn)行測試,TILE_LEN的大小設(shè)置為16. 算法測試的硬件平臺采用統(tǒng)一的GPU服務(wù)器. 計(jì)算機(jī)配置有Xeon X3440服務(wù)器級CPU,主頻為2.53 GHZ. 消費(fèi)級顯卡GTX680插在服務(wù)器的PCI-E插槽上. 當(dāng)考慮算法在未來硬件上的適應(yīng)性時,使用了更新的顯卡GTX980.
3.1 漢字樣本庫描述
本文使用的漢字?jǐn)?shù)據(jù)庫為CASIA-HWDB1.0 (DB1.0)與CASIA-HWDB1.1 (DB1.1)[15],這是文獻(xiàn)[2]中使用的數(shù)據(jù)庫的子集,其包含3 755個類別(來自國標(biāo)GB1字符集),每個類約有570個訓(xùn)練樣本. 這樣共有2 144 749個訓(xùn)練樣本,533 675個測試樣本. 在收集樣本時,每一套字符集按照6種不同的排列次序預(yù)先打印在版面上,為的是抵消每個書寫者在書寫過程中的書寫質(zhì)量變化.
為了描述每個樣本,提取512維的梯度特征作為特征向量. 隨后使用線性判別分析(LDA)將特征向量從512維降到160維. 因此,本文中使用的變量dim大小為160.
3.2 算法正確性驗(yàn)證
同時運(yùn)行CPU版本的GLVQ算法與異構(gòu)計(jì)算架構(gòu)版本的GLVQ算法進(jìn)行背對背測試,且均在訓(xùn)練數(shù)據(jù)上運(yùn)行40輪. 每輪測試都計(jì)算出訓(xùn)練樣本上的識別錯誤率以及測試樣本的識別錯誤率. 實(shí)驗(yàn)中也對不同大小的mb進(jìn)行了測試,圖4與圖5分別顯示了整個學(xué)習(xí)過程以及對應(yīng)的性能. 鑒于基于CPU的串行算法的訓(xùn)練過程過于耗時,圖5中僅訓(xùn)練了24輪. 由圖可知, 串行版本的GLVQ算法與異構(gòu)計(jì)算架構(gòu)版本的GLVQ算法的運(yùn)行結(jié)果并無明顯差異,這說明本文提出的適用于異構(gòu)計(jì)算架構(gòu)的大規(guī)模GLVQ算法具備正確性.
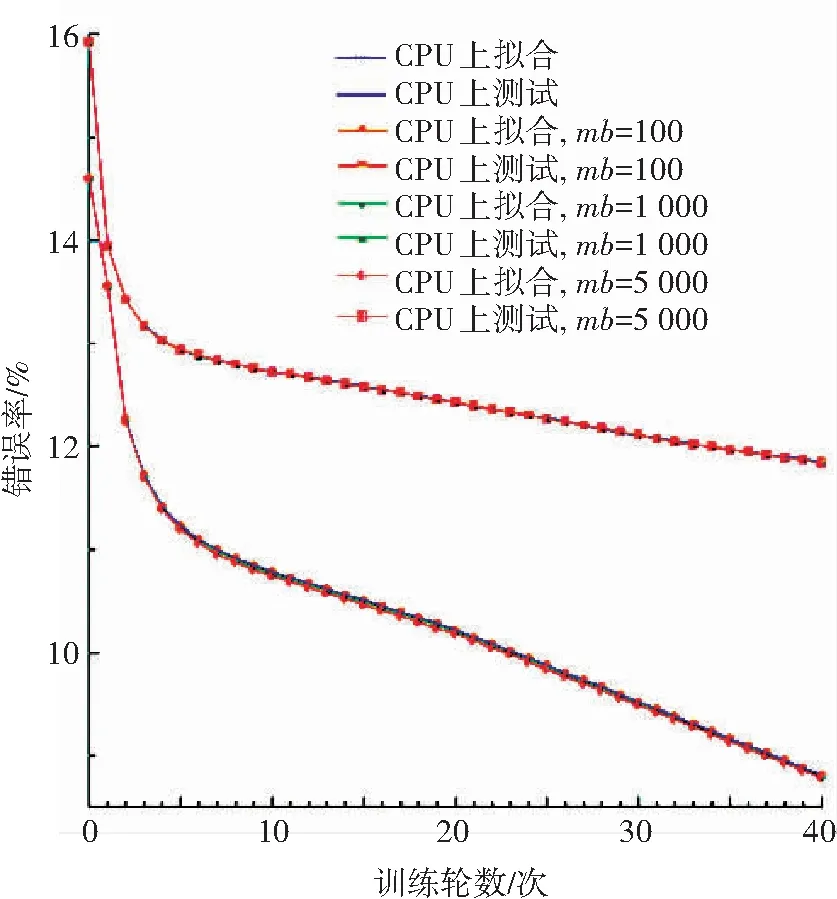
圖4 比較CPU版本和GPU異構(gòu)版本的學(xué)習(xí)過程(每類單個原型)
Fig.4 Learning process comparison between CPU and GPU (single prototype/class)
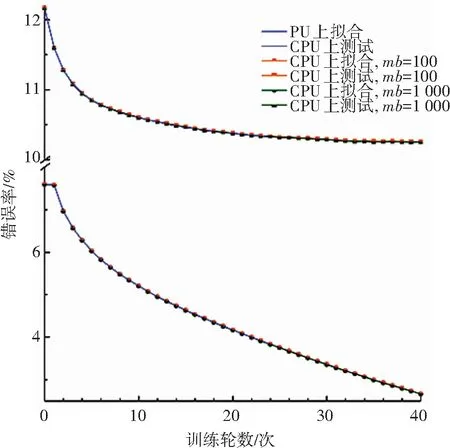
圖5 比較CPU和GPU的學(xué)習(xí)過程(每類八個原型)
Fig.5 Learning process comparison between CPU and GPU (eight prototypes/class)
3.3 算法中間過程評估
算法1中距離計(jì)算與最短距離搜索這兩步的計(jì)算量最大. 首先對距離計(jì)算的效率進(jìn)行評估. 實(shí)驗(yàn)中主要使用了歸約和分塊加和兩種算法,并比較了不同mb大小時的運(yùn)算效率. mb的大小分別取{20, 21, …, 213}. 實(shí)驗(yàn)結(jié)果如圖6與圖7所示,實(shí)驗(yàn)只對訓(xùn)練數(shù)據(jù)進(jìn)行了一輪測試. 由圖可知,并行歸約算法的執(zhí)行時間比較穩(wěn)定,在小批量的規(guī)模較小時,應(yīng)優(yōu)先使用并行歸約算法. 而當(dāng)mb的值大于或等于TILE_LEN時,分塊加和算法則效率更高.
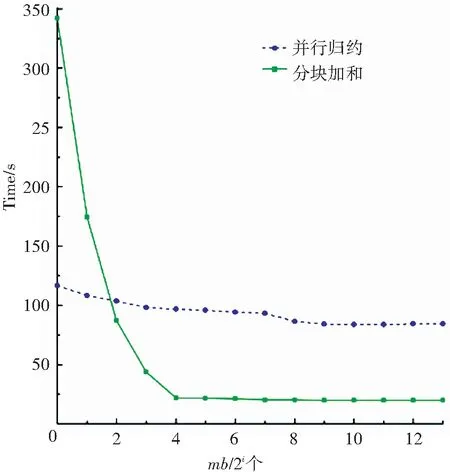
圖6 分別基于并行歸約和分塊加和計(jì)算距離的比較(每類單個原型)Fig.6 Distance computation comparison between parallel reduction and tiling sum (single prototype/class)
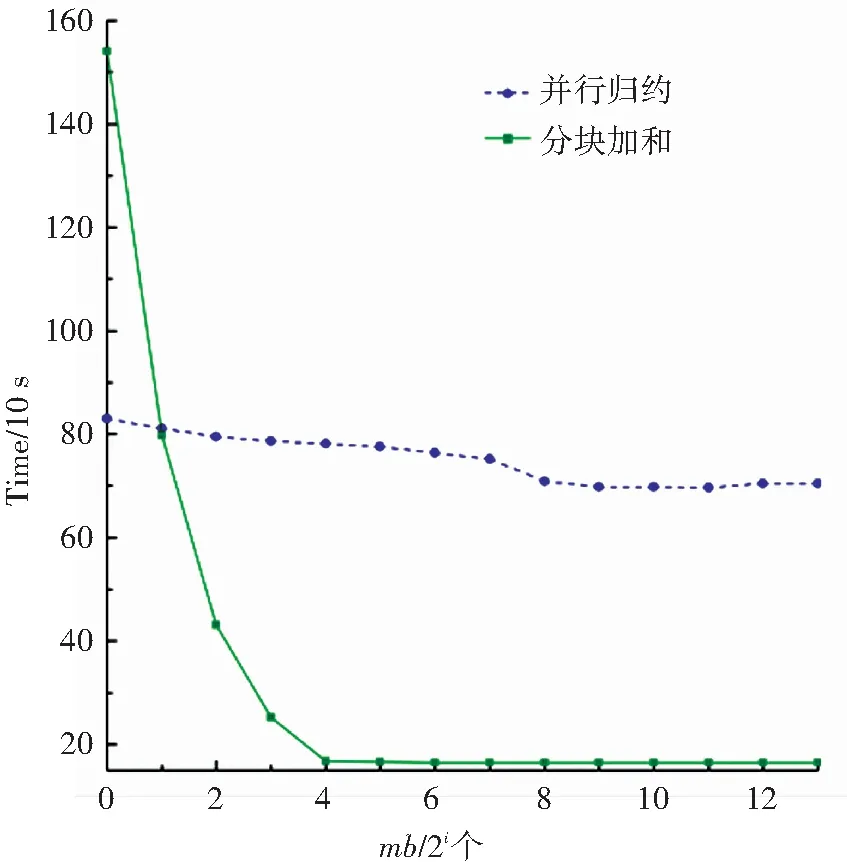
圖7 分別基于并行歸約和分塊加和計(jì)算距離的比較(每類八個原型)Fig.7 Distance computation comparison between parallel reduction and tiling sum (eight prototypes/class)
對于最短距離搜索的實(shí)現(xiàn),采用了并行歸約和比較交換兩種方案. 對這兩種方案進(jìn)行一輪學(xué)習(xí)測試,測試結(jié)果如圖8與圖9所示. 從圖中可以看出,并行歸約算法的可擴(kuò)展性更強(qiáng),針對不同的mb值算法的執(zhí)行時間都比較穩(wěn)定,即使當(dāng)mb很大時,比較交換算法仍比并行歸約慢很多. 另外,當(dāng)一個類使用多個原型向量時,比較交換算法的效率就變得更差. 圖中同樣顯示,當(dāng)使用過大的mb時,會帶來少量的額外消耗. 很重要的原因在于mb取值很大時,可能損害GPU系統(tǒng)緩存的效率.
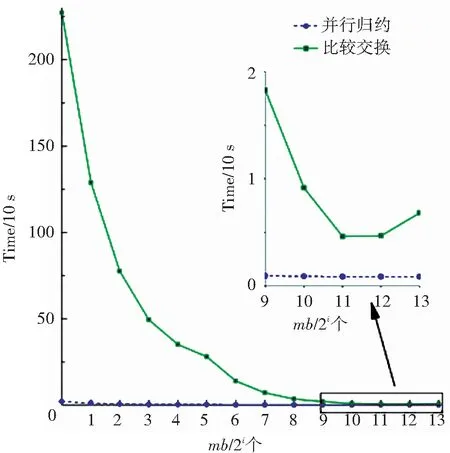
圖8 分別基于并行歸約和比較交換策略求最小值的比較(每類單個原型)
Fig.8 Minima searching comparison between parallel reduction and compare-and-exchange (single prototype /class)
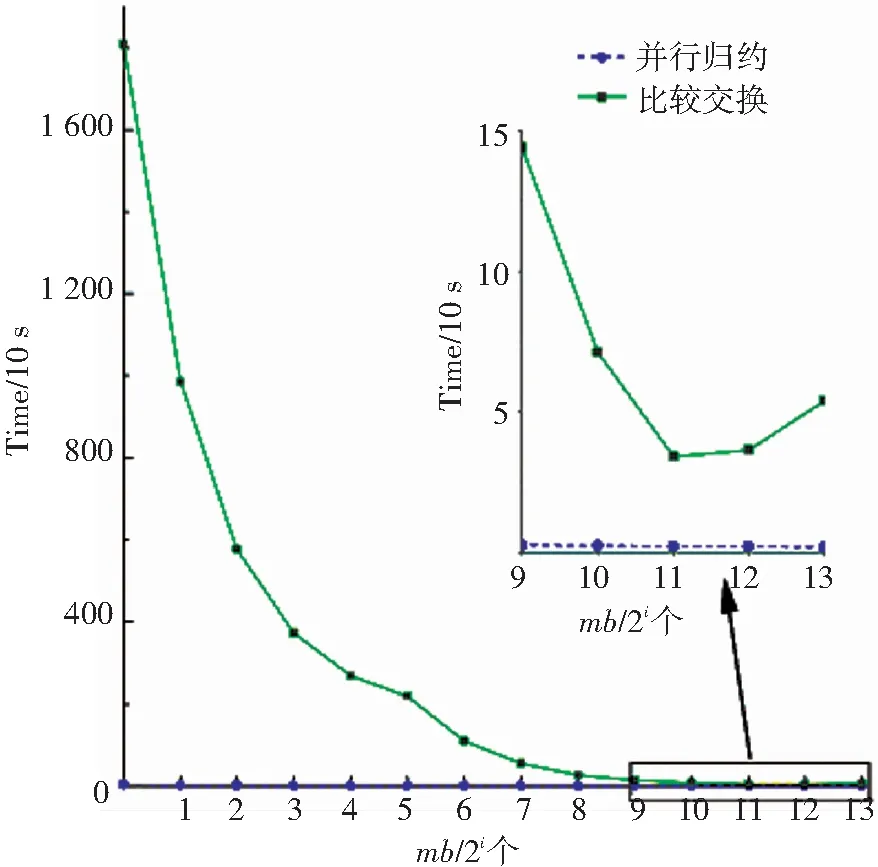
圖9 分別基于并行歸約和比較交換策略求最小值的比較(每類八個原型)
Fig.9 Minima searching comparison between parallel reduction and compare-and-exchange (eight prototypes/class)
3.4 算法加速比評估
訓(xùn)練GLVQ模型的串行學(xué)習(xí)過程比較耗時。若使用單核CPU進(jìn)行一輪學(xué)習(xí),當(dāng)每個類使用單個原型時需要花費(fèi)4 332 s,而每類使用8個原型則需要消耗32 843 s. 若對GLVQ算法循環(huán)訓(xùn)練40輪,則需要花費(fèi)數(shù)天時間.
基于本文提出的異構(gòu)并行學(xué)習(xí)框架,開發(fā)了一個可根據(jù)計(jì)算負(fù)載規(guī)模自適應(yīng)切換最優(yōu)內(nèi)核函數(shù)的GLVQ原型學(xué)習(xí)算法. 分別針對每類單個原型和每類8個原型的情況,收集數(shù)據(jù)并計(jì)算算法的加速比,如圖10所示. 加速比的計(jì)算是采用串行執(zhí)行時間除以并行執(zhí)行時間. 可從圖10看出,當(dāng)使用本文所提出的異構(gòu)原型學(xué)習(xí)算法時, 每類使用單個原型時運(yùn)行速度最高可加速184倍,而每類使用8原型則最高可加速194倍.
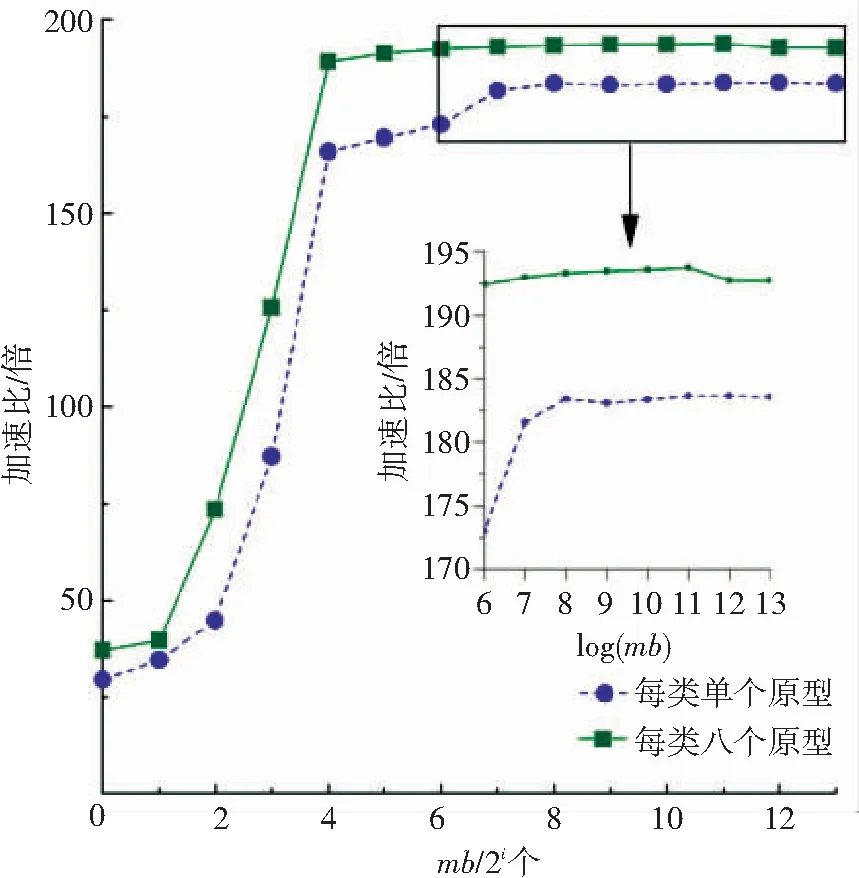
圖10 異構(gòu)大規(guī)模原型學(xué)習(xí)相對CPU的加速比(分別考慮每類單個原型和每類八個原型)
Fig.10 Prototype learning speedup (with both single prototype/class and eight prototypes/class)
這里需要強(qiáng)調(diào),并不是小批量規(guī)模越大,加速越高. 加速峰值均出現(xiàn)在小批量mb=2 048個樣本時,說明此時GPU的計(jì)算部件的利用率和訪存效率之間經(jīng)折衷后達(dá)到最優(yōu). 一旦繼續(xù)加大小批量的規(guī)模,雖然可以加大GPU的占用率,但會對參加運(yùn)算數(shù)據(jù)的局部性有所損害,從而導(dǎo)致GPU硬件二級緩存的命中率降低. 以每類單個原型為例,從mb=2 048增加小批量的規(guī)模到mb=8 196,GPU的占用率從98.08%增加為98.13%,但卻導(dǎo)致二級緩存的命中率從91.0%惡化到87.1%. 緩存命中率的下降,意味著訪存效率的惡化,由于占用率的增加無法抵消訪存惡化的負(fù)面效應(yīng),最終影響了每秒可以執(zhí)行的浮點(diǎn)以及整型運(yùn)算數(shù)量. 在本文的實(shí)驗(yàn)中,隨著mb的進(jìn)一步增大,加速比的下降幅度一般較小.
隨機(jī)梯度下降模式(mb=20)通常很難達(dá)到較高的加速比,這是由于受到可并行化的計(jì)算負(fù)載的局限. 當(dāng)采用隨機(jī)梯度下降時,本文中距離計(jì)算與最短距離搜索均采用并行歸約的算法,以此實(shí)現(xiàn)細(xì)粒度并行. 最終,本文的方法在隨機(jī)梯度下降模式下實(shí)現(xiàn)了最少30倍的加速比(每類單個原型時30倍,每類8個原型時37倍),這一成績在文獻(xiàn)上比較少見.
最后,討論所提出框架在未來新GPU硬件上的擴(kuò)展性和適應(yīng)性. 當(dāng)前,在消費(fèi)級顯卡行業(yè)出現(xiàn)了計(jì)算能力高于GTX680的GPU硬件,GTX980是典型代表. 本文的原型學(xué)習(xí)算法未做任何修改,重新運(yùn)行在GTX980上并考察在新硬件上的性能表現(xiàn). 當(dāng)采用隨機(jī)梯度下降模式時,兩種原型分配方案下獲得的加速比分別為30倍(每類單個原型)和38倍(每類8個原型),跟GTX680的加速比例相當(dāng). 但當(dāng)采用小批量處理模式時,可以看到更優(yōu)異的性能提升:每類分配單個原型時獲得加速比為493倍,每類8個原型時的加速比為638倍. 這表明本文的異構(gòu)并行學(xué)習(xí)框架對于未來的新硬件具有較強(qiáng)的自動擴(kuò)展能力.
4 結(jié) 語
本文提出的適用于異構(gòu)計(jì)算架構(gòu)的大規(guī)模原型學(xué)習(xí)算法框架通過重組串行原型學(xué)習(xí)算法的計(jì)算任務(wù),將串行學(xué)習(xí)算法轉(zhuǎn)化為高度并行化的形式,可以將密集型計(jì)算負(fù)載轉(zhuǎn)移到GPU上,而CPU只需進(jìn)行少量的流程協(xié)調(diào)和數(shù)據(jù)傳遞. 為了充分利用GPU的資源,該算法框架可自動選擇分塊策略與并行歸約策略. 算法的正確性和有效性均在大規(guī)模手寫漢字識別任務(wù)上進(jìn)行了驗(yàn)證. 在消費(fèi)級顯卡GTX680上使用小批量處理模式進(jìn)行模型學(xué)習(xí)時,最高可得到194倍的加速比,即使是隨機(jī)梯度下降模式下,也可實(shí)現(xiàn)30倍的加速比. 當(dāng)升級顯卡到GTX980,在小批量下的加速比可提升到638倍,表明本文提出的框架和算法具有很好的可擴(kuò)展性和適應(yīng)性,能夠有效解決原有原型學(xué)習(xí)的計(jì)算瓶頸問題.
[1] LIU C, NAKAGAWA M. Evaluation of prototype learning algorithms for nearest-neighbor classifier in application to handwritten character recognition[J]. Pattern Recognition, 2001,34: 601-615.
[2] SU T, LIU C, ZHANG X. Perceptron learning of modified quadratic discriminant function[C]//International Conference on Document Analysis and Recognition. 2011:1007-1011.
[3] LV Y, HUANG L, et al. Learning-based candidate segmentation scoring for real-time recognition of online overlaid Chinese handwriting[C]//International Conference on Document Analysis and Recognition. 2013: 74-78.
[4]蘇統(tǒng)華,戴洪良,張健,等. 面向連續(xù)疊寫的高精簡中文手寫識別方法研究[J],計(jì)算機(jī)科學(xué), 2015, 42(7):300-304.
SU T, DAI H, et al. Study on High Compact Recognition Method for Continuously Overlaid Chinese Handwriting[J]. Computer Science, 2015, 42(7):300-304.
[5] SU T, MA P, et al. Exploring MPE/MWE training for Chinese handwriting recognition[C]//International Conference on Document Analysis and Recognition. 2013:1275-1279.
[6] ZHOU M, YIN F, LIU C. GPU-based fast training of discriminative learning quadratic discriminant function for handwritten Chinese character recognition[C]//International Conference on Document Analysis and Recognition, 2013:842-846.
[7] GELSINGER P. Microprocessors for the new millennium: Challenges, opportunities and new frontiers[C]//ISSCC Tech. Digest, 2001: 22-25.
[8] RAINA R, MADHAVAN A, NG A Y. Large-scale deep unsupervised learning using graphics processors[C]//International Conference on Machine Learning. 2009. 873-880.
[9] SCHERER D, SCHULZ H, BEHNKE S, Accelerating large-scale convolutional neural networks with parallel graphics multiprocessors[C]//International conference on Artificial neural networks. 2010:82-91.
[10]CIRESAN DC, MEIER U, et al. Deep, big, simple neural nets for handwritten digit recognition[J]. Neural computation. 2010, 22: 3207-3220.
[11]JIN X, LIU C , HOU X. Regularized margin-based conditional log-likelihood loss for prototype learning[J]. Pattern Recognition, 2010, 43(7): 2428-2438.
[12]SATO A, YAMADA K. Generalized learning vector quantization[C]//Advances in Neural Information Processing Systems. 1996: 423-429.
[13]WILT N. CUDA專家手冊: GPU編程權(quán)威指南[M]. 蘇統(tǒng)華等, 譯. 北京: 機(jī)械工業(yè)出版社, 2014.
WILT N. The CUDA Handbook: A Comprehensive Guide to GPU Programming[M]. Addison-Wesley, 2013.
[14]KIRK DB, WENMEI WH.大規(guī)模并行處理器編程實(shí)戰(zhàn)[M]. 趙開勇等,譯. 第二版. 北京: 清華大學(xué)出版社, 2013.
KIRK DB, WENMEI WH. Programming massively parallel processors: a hands-on approach (Second Edition)[M]. Morgan Kaufmann, 2012.
[15]LIU C, YIN F, et al. Online and offline handwritten Chinese character recognition: Benchmarking on new databases[J]. Pattern Recognition, 2013,46(1): 155-162.
(編輯 王小唯 苗秀芝)
Massively scalable prototype learning for heterogeneous parallel computing architecture
SU Tonghua1, LI Songze1, DENG Shengchun1, YU Yang2, BAI Wei3
(1. School of Software, Harbin Institute of Technology, Harbin 150001, China; 2. Dalian Branch China Construction Eighth Engineering Division Corp. Ltd, Dalian 116021, Liaoning, China; 3.Nokia Solutions and Networks, Hangzhou 310053, China)
Current learning algorithms for prototype learning require intensive computation burden for large category machine learning and pattern recognition fields. To solve this bottleneck problem, a principled scalable prototype learning method is proposed based on heterogeneous parallel computing architecture of GPUs and CPUs. The method can transfer the intense workload to the GPU side instead of CPU side through splitting and rearranging the computing task, so that only a few control process is needed to be managed by the CPU. Meanwhile, the method has the ability to adaptively choose the strategies between tiling and reduction depending on its workload. Our evaluations on a large Chinese character database show that up to 194X speedup can be achieved in the case of mini-batch when evaluated on a consumer-level card of GTX 680. When a new GTX980 card is used, it can scale up to 638X. Even to the more difficult SGD occasion, a more than 30-fold speedup is observed. The proposed framework possess a high scalability while preserving its performance precision, and can effectively solve the bottleneck problems in prototype learning.
prototype learning; learning vector quantization; Chinese character recognition; parallel reduction; heterogeneous parallel computing
10.11918/j.issn.0367-6234.2016.11.009
2015-05-11
國家自然科學(xué)基金(61203260);黑龍江省自然科學(xué)基金重點(diǎn)項(xiàng)目(ZD2015017);哈爾濱工業(yè)大學(xué)科研創(chuàng)新基金 (HIT.NSRIF.2015083)
蘇統(tǒng)華(1979—),男, 博士, 副教授; 鄧勝春(1971—),男, 博士,教授,博士生導(dǎo)師
蘇統(tǒng)華, thsu@hit.edu.cn
TP181
A
0367-6234(2016)11-0053-08
