公安警務領(lǐng)域視頻圖像偵查關(guān)鍵技術(shù)綜述
2016-12-07 03:39:49唐文杰
中國公共安全 2016年15期
□ 文/唐文杰
公安警務領(lǐng)域視頻圖像偵查關(guān)鍵技術(shù)綜述
□文/唐文杰
引言
隨著視頻聯(lián)網(wǎng)監(jiān)控系統(tǒng)在公安警務領(lǐng)域的應用,實時視頻監(jiān)控和歷史視頻調(diào)閱等基本功能為公安人員巡查治安、辦案取證等工作帶來了很大幫助,同時,視頻監(jiān)控系統(tǒng)的普及也為公安行業(yè)積累了海量的視頻圖像數(shù)據(jù),如果對這些重要數(shù)據(jù)進行智能分析和處理,快速高效的獲得精確警報或線索,能夠充分發(fā)揮視頻圖像資源的作用,使得公安日常工作和刑事偵查更加快捷高效。然而,視頻圖像數(shù)據(jù)以指數(shù)速度增長,成為具有數(shù)據(jù)容量大(Volume)、數(shù)據(jù)類型繁多(Variety)、數(shù)據(jù)價值高(Value)、處理速度快(Velocity)4V特性的非結(jié)構(gòu)化大數(shù)據(jù),導致以人工方式從海量視頻圖像中發(fā)現(xiàn)線索非常耗時耗力,海量視頻資源的高效能應用正在成為公安警務領(lǐng)域案件偵破和治安管控的新要求。
視頻圖像偵查技術(shù)通過運動目標檢測、目標跟蹤、目標分類與識別、濃縮摘要、行為分析等技術(shù)手段對視頻圖像數(shù)據(jù)進行分析處理,得到結(jié)構(gòu)化的簡短視頻和語義描述,轉(zhuǎn)化為公安實戰(zhàn)的重要情報。通過對實時視頻進行智能行為分析,并與提前設定好的規(guī)則進行比對,比如入侵、絆線、人群聚集等等,及時獲得異常事件的報警信息,使得視頻監(jiān)控工作變得高效、準確及全面;通過對涉案視頻進行濃縮摘要,自動去除視頻中的靜止畫面,留下有價值的活動目標視頻,可以大大縮短辦案人員調(diào)閱歷史視頻的時間,比如一個120分鐘的視頻,在濃縮處理后,可能只需要1分鐘就可以快速瀏覽到視頻中所有的活動目標,大大提高了辦案效率,并解決了視頻的海量存儲問題,節(jié)約了存儲成本;通過對視頻圖像數(shù)據(jù)進行結(jié)構(gòu)化,對檢測到的活動目標進行分類,檢測出涉案的行人、車輛及物品,與重點人員庫、車輛庫、物品庫等進行專業(yè)的識別比對,幫助辦案人員迅速發(fā)現(xiàn)重要線索,追捕嫌疑人。總之,視頻圖像偵查技術(shù)已成為智能視頻監(jiān)控技術(shù)創(chuàng)新發(fā)展的一個重要方向,也是公安警務領(lǐng)域智能信息化的必由之路。
公安警務中視頻圖像偵查技術(shù)架構(gòu)
視頻圖像偵查技術(shù)源自于計算機視覺技術(shù)和人工智能技術(shù),目標是對視頻圖像數(shù)據(jù)進行多維度的特征提取,進而讓計算機讀懂視頻圖像的含義,定位跟蹤感興趣的運動目標,實時分析目標行為,并根據(jù)預定的規(guī)則進行處理,實現(xiàn)異常事件的前期預防和快速反應;也可以對目標進行分類識別,將視頻圖像按照人、車、物等線索進行關(guān)聯(lián),實現(xiàn)案事件的后期偵破和高效處理。
視頻圖像偵查技術(shù)在公安警務場景中的基本應用有視頻濃縮摘要和檢索和行為分析預警,視頻濃縮摘要和檢索包括行人檢測、車輛檢測、人臉識別、車牌識別、特征檢索等,行為分析預警包括入侵檢測、絆線檢測、人群聚集檢測、物品丟失檢測、遺留物檢測等。公安警務領(lǐng)域的視頻圖像偵查技術(shù)架構(gòu)如圖1所示,分為三個階段:
首先,采用圖像增強、背景建模等技術(shù)將實時視頻流或歷史視頻中的目標與背景分離,并對目標進行跟蹤。
然后,對成功跟蹤的目標進行分類,便于進行識別。目標分類將視頻檢測的運動目標分類為事先定義好的類別,實質(zhì)上是提取目標的結(jié)構(gòu)和語義特征,與類別特征進行映射,類別為從語義意義上選取的典型物體,目前在公安警務領(lǐng)域典型物體一般分為行人、車輛、人騎車三類,然后對這三類物體形態(tài)進行識別。
最后,在目標檢測跟蹤、分類識別的基礎上,對目標進行進一步的應用,可以進行壓縮拼接,形成摘要視頻,便于后續(xù)檢索,或者對目標的行為進行判定,如果有符合預先設定規(guī)則的行為,則觸發(fā)報警或進一步處理。
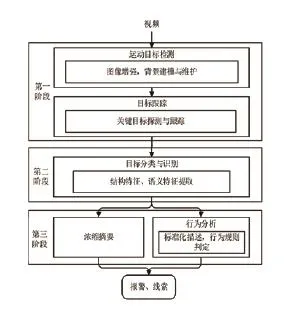
▲圖1 公安警務中圖像視頻偵查技術(shù)架構(gòu)
公安警務中圖像視頻偵查關(guān)鍵技術(shù)
本文研究公安警務領(lǐng)域涉及到的視頻偵查關(guān)鍵技術(shù),包括運動目標檢測、目標跟蹤、目標分類和識別、濃縮摘要和行為分析。
運動目標檢測
公安警務領(lǐng)域的運動目標檢測通過預處理、背景建模、目標分割等流程從視頻或圖像中提取出感興趣的目標,比如人、車、物等,并確定當前目標所在畫面的位置、大小,為后續(xù)的行人識別、車輛識別等做準備。運動目標檢測是后續(xù)跟蹤識別等算法的基礎,其準確率和性能直接影響了后續(xù)算法的效果,根據(jù)處理的對象不同,運動目標檢測算法分為基于背景建模的檢測算法和基于目標建模的檢測算法。
(1)基于背景建模的運動目標檢測
基于背景建模的運動目標檢測具有簡單、速度快、受遮擋影響小等優(yōu)勢,但是背景建模要求背景固定、目標運動,因此在要求實時性強、攝像機固定的場景中應用廣泛。
基于背景建模的運動目標檢測首先進行背景建模,然后通過當前畫面與背景圖像的相減即可得到運動目標。但是模型建立后,可能對場景的變化比如陽光、云影、樹葉、波浪等比較敏感,而良好的背景模型能消除或減少背景動態(tài)變化對于運動目標檢測帶來的影響。目前有很多研究致力于背景建模與維護,如卡爾曼濾波建模、均值濾波、中值濾波、最大值最小值濾波、線性濾波、非參數(shù)化模型、近似中值濾波、基于高斯假設的迭代方法、基于聚類的方法、基于隱馬爾科夫的方法、基于自回歸模型的方法、基于在線學習的方法以及基于時空背景隨機更新的VIBE方法.其中,混合多高斯背景建模方法是目前普遍應用的一種前景提取方法.
(2)基于目標建模的運動目標檢測
相比于基于背景建模的方法,基于目標建模的運動目標檢測能良好的適應背景的運動,對目標的運動狀態(tài)也沒有要求,但是由于要對大量訓練目標進行統(tǒng)計學習,所以速度相對較慢,一般適用于對實時性要求不強的應用場景。基于目標建模的運動目標檢測一般采用滑動窗口的策略,掃描每個滑動窗口的圖像,根據(jù)模型判定圖像是目標還是背景,目標檢測的效果取決于模型的魯棒性。根據(jù)建模的方法不同,基于滑動窗口的目標檢測主要分為剛性全局模板檢測模型、基于視覺詞典的檢測模型、基于部件的檢測模型和深度學習模型,其他模型中有語法模型以及生物啟發(fā)特征模型等。其中剛性全局模板檢測模型中的梯度方向直方圖特征,成為近年以來最有影響力和最為成功的特征之一,而基于深度學習的目標檢測模型正在成為研究的熱點。

目標跟蹤
公安警務領(lǐng)域的目標跟蹤主要是跟蹤感興趣的行人、車輛、物品等目標,獲得目標的前景動態(tài)信息,如時間、位置、運動軌跡、方向等等,本質(zhì)上是在連續(xù)視頻之間建立基于位置、速度、形狀等特征的對應匹配,目的是在連續(xù)視頻圖像的幀之間建立目標的對應關(guān)系,便于后續(xù)對目標進行辨認。目標跟蹤是視頻圖像偵查中最關(guān)鍵的過程,是后續(xù)分類、識別、壓縮及分析的重要前提。公安警務領(lǐng)域目標跟蹤多為單場景單目標或單場景多目標跟蹤,單場景單目標跟蹤是指對同一個攝像機拍攝的單一視頻場景中指定的某一個目標進行連續(xù)跟蹤,單場景多目標跟蹤相對復雜,是指對同一個攝像機拍攝的單一視頻場景中多個目標進行跟蹤。
單目標跟蹤主要有基于點的跟蹤、基于核或面的跟蹤、基于主動輪廓的跟蹤以及基于模型的跟蹤,其中比較常用的方法是預測運動體下一幀可能出現(xiàn)的位置,在其相關(guān)區(qū)域內(nèi)尋找最優(yōu)點。諸多研究成果集中在均值漂移算法,卡爾曼濾波,粒子濾波,粒子濾波改進算法。另外也有研究提出基于檢測的跟蹤,代表性方法有基于在線特征提升的跟蹤算法,基于多示例學習的跟蹤方法,利用在線的空時上下文結(jié)構(gòu)信息來輔助跟蹤等。
多目標跟蹤問題更加復雜,有研究將其描述為一個候選區(qū)域和已有目標軌跡之間的數(shù)據(jù)關(guān)聯(lián)問題,代表性方法如多假設跟蹤器和聯(lián)合概率數(shù)據(jù)關(guān)聯(lián)濾波,也有一些研究將跟蹤問題看成是貝葉斯狀態(tài)空間推斷問題,如貝葉斯多目標跟蹤器。目前的多目標跟蹤算法普遍計算效率不高,如何考慮目標間的交互,并且提高多目標跟蹤的效率是一個值得研究的問題。
目標分類與識別
公安警務領(lǐng)域的目標分類與識別目的是對跟蹤到的目標進行辨識,比如識別到車輛的顏色、車牌號、車型車款、車飾物等特征,便于車輛布控、車輛違規(guī)檢測等工作的進一步執(zhí)行。目標分類與識別技術(shù)首先利用大量的目標樣本對系統(tǒng)進行模型訓練,學習出不同目標的特征,然后在這些模型上驗證新的樣本是否匹配。
一般將視頻圖像中的目標特征分為底層特征和高層語義特征,底層特征包括全局特征、局部特征、結(jié)構(gòu)特征等,其中全局特征又細分為顏色特征、形狀特征、紋理特征等,局部特征包括SIFT特征、SURF特征等;高層語義特征是指以底層特征為基礎,在語義模型上識別出的更高層次的特征,比如行為特征即為語義特征。本節(jié)重點闡述面向目標底層特征的分類與識別,在公安警務領(lǐng)域,目標底層特征包括行人衣著顏色、頭發(fā)顏色、車輛顏色、車牌號等等。
目標分類與識別是視頻圖像偵查技術(shù)應用的重要環(huán)節(jié),也是最具有挑戰(zhàn)性的環(huán)節(jié)。好的目標分類與識別算法對模型的要求非常高,目前研究和應用較多的是相似度模型和深度學習模型。
(1)相似度模型
相似度模型首先將目標對象進行特征表示,即特征編碼,然后根據(jù)一定的相似度計算方法計算特征集合之間的相似關(guān)系。其中,特征編碼密集提取的底層特征中包含了大量的冗余與噪聲,為提高特征表達的魯棒性,需要使用一種特征變換算法對底層特征進行編碼,從而獲得更具區(qū)分性、更加魯棒的特征表達,這一步對目標識別的性能具有至關(guān)重要的作用。因而,大量的研究工作都集中在尋找更加強大的特征編碼方法上,重要的特征編碼算法包括向量量化編碼、核詞典編碼、稀疏編碼、局部線性約束編碼、顯著性編碼、Fisher向量編碼、超向量編碼等;相似度度計算主要包括向量空間模型、基于哈希的相似度計算以及基于主題的相似度計算。
(2)深度學習模型
經(jīng)研究,人腦之所以能迅速看懂輸入的視頻圖像,是視網(wǎng)膜上的圖像映射經(jīng)過層層神經(jīng)元的提取和計算,每個層次都降低前一個層次處理的數(shù)據(jù)量,并且保留物體有用的結(jié)構(gòu)信息。為了讓計算機也具有類似人類感知系統(tǒng)能夠更深入理解視頻圖像的能力,需要構(gòu)建多層非線性處理組成的模型,即深度結(jié)構(gòu)。從最早提出的含多個隱藏層的多層神經(jīng)網(wǎng)絡以及向后傳播訓練算法,對深度學習模型的研究從未間斷,應用較好的有卷積神經(jīng)網(wǎng)絡,Sigmoid信度網(wǎng),深度信度網(wǎng),以及深度信度網(wǎng)的變種,比如深度玻爾茲曼機、深度自動編碼機以及深度神經(jīng)網(wǎng)絡等等。其中,深度卷積神經(jīng)網(wǎng)絡在圖像識別應用上取得了較好的效果,盡管用監(jiān)督學習的方式直接訓練深度神經(jīng)網(wǎng)絡非常困難,但是卷積神經(jīng)網(wǎng)絡卻成為了一個例外,相比傳統(tǒng)的多層神經(jīng)網(wǎng)絡和相應的向后傳播學習算法,卷積神經(jīng)網(wǎng)絡可以更容易的從非線性空間找到最優(yōu)點。深度學習模型是目前目標分類與識別中最準確的方法。
濃縮摘要
公安人員在辦案過程中往往需要觀看與案發(fā)時間、地點等相關(guān)的所有視頻,傳統(tǒng)方式下,24小時的視頻要花費同樣24小時才能查閱完畢,而且可能發(fā)生遺漏,視頻濃縮摘要大大改善了這種工作模式,提高了視頻查證的效率和全面性。視頻濃縮摘要是指從原始視頻中提取有用的前景目標的活動信息,然后和背景視頻合成剪輯而成較短的視頻片斷,其中包含了原始視頻中所有重要的活動目標和快照,視頻濃縮摘要通常分為基于靜態(tài)關(guān)鍵幀的方法和動態(tài)的視頻縮略方法。
(1)基于靜態(tài)關(guān)鍵幀的方法
關(guān)鍵幀是能夠反映視頻主要信息的圖像幀,關(guān)鍵幀序列可組成故事板,它以簡潔的形式反映了視頻的主要內(nèi)容。目前視頻關(guān)鍵幀的提取方法主要有基于顏色直方圖的方法,基于顏色熵的方法,基于運動活動性的方法,基于宏塊統(tǒng)計特性的方法等等。由于視頻圖像序列的相似性很強,存在很多冗余,因此現(xiàn)有的關(guān)鍵幀算法大多是基于鏡頭來進行的。
(2)動態(tài)視頻縮略方法
動態(tài)的視頻縮略可以看作是原始視頻的一種特殊編輯,它保留了視頻的主要內(nèi)容和時間推進線索。目前研究者提出了很多視頻縮略算法,有基于聚類的方法,比如基于鏡頭序列或圖像色彩的相似性分析,光流法,擬合法等等;還有基于模型的方法,比如EDU模型,CPR模型,時空運動模型,馬爾科夫模型等等;基于語義的方法是根據(jù)高層語義概念特征對視頻進行切分和提取。
行為識別
行為分析技術(shù)可以實時發(fā)現(xiàn)視頻流中的異常行為,比如闖入電子圍欄、打架斗毆、闖紅燈等等,并及時處置,極大的改善了公安監(jiān)控人員的日常監(jiān)控工作,將公安監(jiān)控人員從“死盯屏幕”的工作狀態(tài)中解脫出來。行為分析技術(shù)分為模板匹配法和狀態(tài)空間法。
(1)模板匹配法
模板匹配法將從輸入視頻圖像序列提取的特征與在訓練階段預先保存好的模板進行相似度對比,行為分析的結(jié)果即為與測試序列距離最小的已知模板的類別。常用描述行為的模板有運動能量圖像,運動歷史圖像等,后續(xù)的相似度匹配常采用最近鄰方法、馬氏距離計算法等等,另外,也有研究提出基于動態(tài)時間規(guī)整的模板匹配法。模板匹配法計算復雜度低、實現(xiàn)簡單,但對噪聲和運動時間間隔的變化比較敏感。
(2)狀態(tài)空間法
狀態(tài)空間法,又叫概率轉(zhuǎn)移法,該方法將行為的每一個姿態(tài)或運動狀態(tài)作為狀態(tài)圖的一個節(jié)點,通過某種概率將對應于各個姿勢或狀態(tài)節(jié)點之間的依存關(guān)系聯(lián)系起來,這樣任何人體行為運動序列可以看作在圖中若干節(jié)點或狀態(tài)之間的一次遍歷過程。應用較為廣泛的狀態(tài)空間模型為隱馬爾可夫模型和動態(tài)貝葉斯網(wǎng)絡,多為這兩類模型的改進版,比如耦合隱馬爾可夫模型,可變長馬爾可夫模型;抽象隱馬爾可夫模型;基于典型樣本的隱馬爾可夫模型;此外,熵隱馬爾可夫模型、分層隱馬爾可夫模型、最大熵馬爾可夫模型等也被用于復雜行為識別。貝葉斯網(wǎng)絡模型有基元動態(tài)貝葉斯網(wǎng)絡,分級貝葉斯網(wǎng)絡,含有多層狀態(tài)的分層且?guī)яv留時間狀態(tài)的動態(tài)貝葉斯網(wǎng)絡,此外還用神經(jīng)網(wǎng)絡、條件隨機場、有限狀態(tài)機、置信網(wǎng)絡等方法來識別人體行為。
總結(jié)與展望
隨著視頻圖像分析在公安警務領(lǐng)域的普遍應用,視頻圖像偵查已成為繼刑偵、技偵、網(wǎng)偵之后的第四大偵查技術(shù),所以提高視頻圖像偵查技術(shù)的準確度和速度已成為公安部門的迫切需求。本文總結(jié)描述了公安警務領(lǐng)域視頻圖像偵查關(guān)鍵技術(shù)的架構(gòu)以及具體技術(shù)的相關(guān)算法,如運動目標檢測、目標跟蹤、目標分類和識別、濃縮摘要和行為分析。值得一提的是,深度學習模型在視頻圖像偵查中的應用非常值得期待,如何在大數(shù)據(jù)等高新技術(shù)的幫助下,使得深度復雜模型在保證準確率的前提下,提高計算效率成為新的研究方向。
作者單位:中國電子進出口總公司
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
