基于自學習向量空間模型文本分類算法的研究與應用
2016-11-29 03:42:43張志強
軟件 2016年9期
張志強
(華北計算技術研究所,北京市 100083)
基于自學習向量空間模型文本分類算法的研究與應用
張志強
(華北計算技術研究所,北京市100083)
隨著網絡信息的迅猛發展,信息處理已經成為人們獲取有用信息不可缺少的工具。文本自動分類是信息處理的重要研究方向。它是指在給定的分類體系下,根據文本的內容自動判別文本類別的過程。本文對文本分類中所涉及的關鍵技術,包括向量空間模型,特征提取,機器學習方法等進行了研究和探討。最后,本文實現了一套基于自學習向量空間模型的文本分類系統,并基于kafka消息隊列和storm流計算框架,實時地為文本進行分類。
文本分類;向量空間模型;機器學習;kafka消息隊列;storm流計算
本文著錄格式:張志強. 基于自學習向量空間模型文本分類算法的研究與應用[J]. 軟件,2016,37(9):118-121
1 引言
隨著信息技術的不斷普及,人們對信息資源的依賴性越來越大,如何實現信息的自動分類,尤其是中文文本信息的有效分類是目前中文信息處理研究的一個重要分支領域。
中文文本分類已經不是一個新的課題,但隨著信息化帶來的信息量急劇增長,現有的中文文本分類技術面臨著新的挑戰,主要表現在:
1)動態性。當今社會日新月異,知識更新存在于每一領域,內容變化迅速,信息交換變得更為頻繁。分類模型如果缺乏適應性,分類質量將無法得到保障。
2)非結構化。網絡文本信息來源各異,往往具有不同的形式和語法。如何對這些非結構化的數據進行有效的處理,給文本分類技術提出了新的難題。
3)數據量大。因特網的發展帶來了信息海量式膨脹,信息出現的速度遠遠超出了人們接受的速度。這樣龐大的數據量對文本分類技術的時間效率和分類性能提出了新的挑戰。
本文研究的是一種基于自學習向量空間模型[1]文的本分類系統,這是在傳統的文本分類模型的基礎上的一種主動學習的文本分類方法。本文還增加了對非結構化的文本的處理,提供了把非結構化文本標準化成詞向量模型的方法。同時本文最后實現的文本分類系統使用kafka消息隊列發布訂閱文本數據,并運行在storm流計算框架上,增強了文本數據的處理數據量及實時處理的能力。
2 文本分類涉及的概念及文本分類算法的介紹
2.1文本分類涉及的概念
中文文本分類所涉及到的概念主要包括分詞技術、文本表示、特征抽取和分類算法的選擇。
1)分詞技術:相比于西方文本分類,中文文本分類的一個重要的區別在于預處理階段,中文文本的標準化需要分詞。分詞方法從簡單的查字典的方法,到后來的基于統計語言模型的分詞方法,中文分詞的技術已趨于成熟。比較有影響力的當屬于中科院計算所開發的漢語詞法分析系統ICTCLAS,現已發布供中文文本分類的研究使用。
2)文本表示:計算機不具有人類的智慧,不能讀懂文字,所以必須把文本轉換成計算機能夠理解的形式,即進行文本表示。目前文本表示模型主要是Gerard Salton和McGill于1969年提出的向量空間模型(VSM)。向量空間模型的基本思想是把文檔簡化為特征項的權重,并使用向量表示:(w1,w2, w3,…,wn),其中wi為第i個特征項的權重,一般選取詞作為特征項,權重用詞頻表示。
最初的向量表示完全是0、1的形式,即:如果文本中出現了該詞,那么文本向量的該維為1,否則為0。這種方法無法體現這個詞在文本中的作用程度,所以0,1逐漸被更精確地詞頻代替,詞頻分為絕對詞頻和相對詞頻。絕對詞頻使用詞在文本中出現的頻率表示文本;相對詞頻為歸一化的詞頻,其計算方法主要運用TF-IDF公式。本文采用的TF-IDF公式為:

3)特征抽取[2]:由于文本數據的半結構化至于無結構化的特點,當用特征向量對文檔進行表示時,特征向量通常會達到幾萬維甚至幾十萬維。因此我們需要進行維數壓縮的工作,這樣做的目的主要有兩個:第一,為了提高程序的效率,提高運行速度;第二,所有詞對文本分類的意義是不同的,一些通用的、各個類別都普遍存在的詞匯對分類的貢獻小;為了提高分類精度,對于每一類,我們應該去除那些表現力不強的詞匯,篩選出針對該類的特征項集合,存在多種篩選特征項的算法,如下所列:
a)根據詞和類別的互相信息量判斷
b)根據詞熵判斷
c)根據KL距離判斷
本文采用了詞和類別的互信息量進行特征抽取的判斷標準,其算法過程如下:
① 初始情況下,該特征項集合包含所有該類中出現的詞。
② 對于每個詞,計算詞和類別的互信息量。③ 對于該類中所有的詞,依據上面計算的互信息量排序。
④ 抽取一定數量的詞作為特征項。具體 需要抽取多少維的特征項,目前無很好的解決辦法,一般采用先定初始值,然后根據實驗測試和統計結果確定最佳值。一般初始值定義在幾千左右。
⑤ 將每類中所有的訓練文本,根據抽取的特征項進行向量維數壓縮,精簡向量表示。
4)分類算法:分類算法是研究文本分類的核心問題。目前基于統計和機器學習的方法已經成為文本分類的主流方法,并且還在不斷發展,比較常見的文本分類算法有:樸素貝葉斯,KNN分類算法[3-5],決策樹算法,神經網絡,支持向量機。本文在接下來的一小節重點介紹和比較KNN分類算法和樸素貝葉斯算法。
2.2文本分類算法的介紹
2.2.1KNN算法
K Nearest Neighbor算法,簡稱KNN算法,KNN算法是一個理論上比較成熟的方法,最初由Cover和Hart于1968年提出,其思路非常簡單直觀,易于快速實現,以及錯誤低的優點。KNN算法的基本思想為:根據距離函數計算待分類樣本x和每個訓練樣本的距離,選擇與待分類樣本距離最小的K個樣本作為x的K個最近鄰,最后根據x的K個最近鄰判斷x的類別。
它是一種比較簡單的機器學習算法,它的原理也比較簡單。下面用最經典的一張圖來說明,如下圖:

如圖所示,假設現在需要對中間綠色的圓進行分類,假設我們尋找距離這個綠色圓最近的3個樣本,即K=3,那么可以看出這個綠色圓屬于紅色三角形所在的類;如果K=5,因為藍色方框最多,所以此時綠色圓屬于藍色方框所在的類。從而得到當K值取值不同時,得到的分類結果也可能不一樣,所以很多時候K值得選取很關鍵,這就是KNN的核心思想。如果類別個數為偶數,那么K通常會設置為一個奇數;如果類別個數為奇數,K通常設置為偶數,這樣就能保證不會有平局的發生。
KNN算法是惰性學習法,學習程序直到對給定的測試集分類前的最后一刻對構造模型。在分類時,這種學習法的計算開銷在和需要大的存儲開銷。總結KNN方法不足之處主要有下幾點:①分類速度慢。②屬性等同權重影響了準確率。③樣本庫容量依懶性較強。④K值的確定。
2.2.2樸素貝葉斯算法
貝葉斯法則建立了P(h|d)、P(h)和P(d|h)三者之間的聯系如下:

其中:(1)P(h)是根據歷史數據或主觀判斷所確定的h 出現的概率,該概率沒有經過當前情況的證實,因此被稱為類先驗概率,或簡稱先驗概率(prior probability)。(2)P(d|h)是當某一輸出結果存在時,某輸入數據相應出現的可能性。對于離散數據而言,該值為概率,被稱為類條件概率(classconditional probability);對于連續數據而言,該值為概率密度,被稱為類條件概率密度(classconditional probability density),統計學中通常應使用P(d|h)表示,以示與概率區別。(3)P(h|d)的意義同前,它反映了當輸入數據d時,輸出結果h出現的概率,這是根據當前情況對先驗概率進行修正后得到的概率,因此被稱為后驗概率(posterior probability)。
顯然,當機器處理問題時,它關心的是P(h|d)。對于兩個不同的輸出結果h1和h2,如果P(h1|d)> P(h2|d),表示結果h1的可能性更大,從而最終結果應為h1。也就是說,應優先選擇后驗概率值大的結果,這一策略被稱為極大后驗估計(Maximum A Posteriori),簡稱MAP。設H表示結果集,則極大后驗估計為

在樸素貝葉斯分類器中,假設數據向量中各分量相互獨立,從而將高維數據分布轉化為若干一維數據分布進行處理。設d=(d1,d2,…,dn),其中n為數據維數,則根據各分量相互獨立的假設,類條件概率(或概率密度)可表示為:

于是樸素貝葉斯分類器的決策公式為

公式表明:只要獲得每個數據分量對應的P(d h)i,便獲得了類條件概率(或概率密度)。這一過程的計算量遠遠小于不做各分量獨立性假設而直接估計高維類條件概率(或類條件概率密度)的計算量。例如,設d=(d1,d2,…,dn)為離散數據向量,其中每個分量上的可能取值為m。如果假設各分量相互獨立,則只需學習mn個概率值;而如果假設各分量彼此相關,則需要考慮所有可能的分量組合,這便需要學習個概率,顯然這兩個數據量之間的差距是驚人的。
3 自學習的文本分類算法的研究
就目前研究情況來說,國內學者提出了很多文本分類算法,這些分類算法在封閉測試中表現良好,但是在開放測試中,尤其面對異常龐雜的網絡文本的測試中,往往不盡人意。究其原因,大多數的文本分類系統都采取“訓練-分類”模式,訓練和分類是兩個彼此獨立的過程,訓練過程一般只針對訓練語料進行學習,在這種模式下,分類系統的性能依賴于訓練預料的質量,缺乏適應性,不適宜海量、非結構化、動態的文本信息的處理要求。
本文研究的基于自學習向量空間模型文的本分類系統,該系統將訓練過程延伸到分類過程中,以訓練驅動分類,以分類結果反饋進行再訓練,使得訓練和分類兩個過程成為一個有機的整體,從而打破了訓練、分類相對獨立的傳統模式,同時在訓練過程中,克服了對訓練預料的完全依賴性,從而增強了分類系統的自適應能力。
本文介紹的自學習文本分類算法[6-7],首先得到分類后的結果,主觀的對結果進行評估,并反饋給訓練樣本,調整訓練樣本的向量空間模型。這是個不斷學習的過程,通過迭代反饋,逐漸提高分類的準確率。
4 標準化非結構化文本
本文為適應不同格式的非結構化文本,提供了文檔適配處理模塊[8]。利用Apache POI開源工具處理不同類型的電子文檔,包括Word、PDF、TXT等等,處理結果統一為文本分類系統能處理的純文本格式數據。然后把純文本格式數據標準化成向量空間模型。
5 kafka消息隊列及Storm流計算框架下的實時分類
Kafka是一種高吞吐量的分布式發布訂閱消息系統,它可以處理消費者規模的網站中所有動作流數據。由于采集數據的速度和數據處理的速度不一定同步,本文添加一個消息中間件kafka來作為緩沖。
Storm是一個免費開源、分布式、高容錯的實時流計算框架。Storm令持續不斷的流計算變得容易,彌補了Hadoop批處理所不能滿足的實時要求。本文為提供高實時性的文本分類系統,使用了storm實時流計算框架。
本文的文本分類系統,使用kafka消息隊列做緩沖中間件,并建立在Storm流計算框架的基礎之上。眾所周知,kafka負責高吞吐的讀取消息,并對消息保存到消息隊列中,保存時可以根據Topic進行歸類,消息發送者成為Producer,消息接收者成為Consumer。在本文中,kafka負責高吞吐地讀取消息成為消息生產者,kafka還負責緩沖消息到消息隊列中成為消息緩沖中間件,storm實時讀取緩沖區的消息并處理成為消息消費者。Storm的兩個核心組件spout和bolt,譯為中文為噴口和螺栓更加形象貼切。Spout是storm流處理中流的源頭,本文中的spout負責從緩沖隊列中讀取消息。Bolt是storm流處理中具體的處理單元,本文中的文本分類算法就是運行在bolt上的。
6 文本分類系統測試結果說明
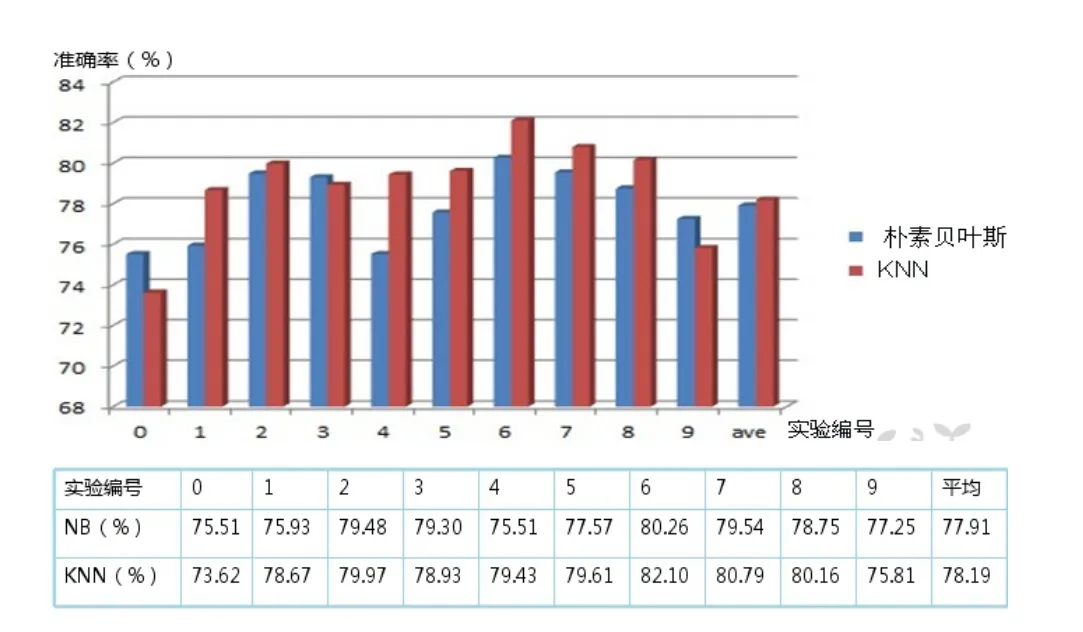
通過大量的不同格式的電子文檔的導入,進行文本分類,本文的文本分類系統能夠實時地處理并返回分類結果,分類的效果較好,分類準確率平均在80%。用戶可以通過對文本和分類結果進行比對,反饋給系統人為分類的結果,系統會根據反饋的結果,調整向量空間模型。通過這樣的不斷迭代反饋,逐步提高分類準確率。實驗結果圖如下:
7 結束語
本文所實現的文本分類系統,實現了對本文開始提出的文本分類目前存在的三個問題數據量大、非結構化、動態性的解決,為傳統的文本分類方式注入新鮮的血液。
本文所提出的文本分類系統,仍然存在一些問題,具體體現在:
1)半監督的學習模式。這種學習模式需要人為地干預,這樣會一定程度上把分類的準確性寄托在人為分類的基礎之上。
2)文本分類結果的準確率上。本文實驗的文本分類準確率在80%,除了通過自學習這種“后天學習”方式來提高準確率,還需提高“先天”的向量空間模型的建立以及分類算法的選擇上。
[1] 龐劍鋒, 卜東波, 白碩. 基于向量空間模型的文本自動分類系統的研究與實現[J]. 計算機應用研究, 2001, 09: 23-26.
[2] 張東禮, 汪東升, 鄭緯民. 基于VSM的中文文本分類系統的設計與實現[J]. 清華大學學報(自然科學版), 2003, 09: 1288-1291.
[3] 黃萱菁, 夏迎炬, 吳立德. 基于向量空間模型的文本過濾系統[J]. 軟件學報, 2003, 03: 435-442.
[4] 周炎濤, 唐劍波, 吳正國. 基于向量空間模型的多主題Web文本分類方法[J]. 計算機應用研究, 2008, 01: 142-144.
[5] 李文波, 孫樂, 張大鯤. 基于Labeled-LDA模型的文本分類新算法[J]. 計算機學報, 2008, 04: 620-627.
[6] 馬凱航, 高永明, 吳止鍰, 等. 大數據時代數據管理技術研究綜述[J]. 軟件, 2015, 36(10): 46-49.
[7] 謝子超. 非結構化文本的自動分類檢索平臺的研究與實現[J]. 軟件, 2015, 36(11): 112-114.
[8] 路同強. 基于半監督學習的微博謠言檢測方法[J]. 軟件, 2014, 35(9): 104-108.
[9] 申超波, 王志海, 孫艷歌. 基于標簽聚類的多標簽分類算法[J]. 軟件, 2014, 35(8): 16-21.
Research and Implementation of Text Categorization System Based on VSM and ML
ZHANG Zhi-qiang
(CETC 15 Institute, Beijing 100083, China)
In recent years, information processing turns more and more important for us to get useful information. Text categorization, the automated assigning of natural language texts to predefined categories based on their contents, is a task of increasing importance. This paper gives a research to several key techniques about text categorization, including vector space model, feature extraction, machine learning. At the last of this paper, a text categorization system based on VSM and ML is implemented, and it also can dispose text categorization at real time through kafka and storm, which is a flow calculation framework.
Text categorization; Vector space model; Machine learning; Kafka; Storm flow calculation
TP391.1
A
10.3969/j.issn.1003-6970.2016.09.028
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
