基于聚焦爬蟲的農(nóng)業(yè)信息服務(wù)平臺設(shè)計與實現(xiàn)
2016-11-25 03:06:37李慧何永賢葉云
天津農(nóng)業(yè)科學(xué) 2016年10期
李慧+何永賢+葉云
摘 要:隨著信息技術(shù)的發(fā)展,農(nóng)業(yè)信息化成為現(xiàn)代農(nóng)業(yè)發(fā)展的必然需求。針對目前農(nóng)業(yè)信息化服務(wù)信息整合度低、實時性信息不夠等問題,提出了基于聚焦爬蟲的農(nóng)業(yè)信息服務(wù)平臺。聚焦爬蟲按照既定需求,實時提取各類相關(guān)網(wǎng)頁信息,通過信息服務(wù)平臺進(jìn)行整合,以友好的方式展示給用戶。平臺的建設(shè)使得用戶能夠在龐雜的信息中獲取全面、適用和及時的農(nóng)業(yè)信息,提高了農(nóng)業(yè)信息服務(wù)水平。
關(guān)鍵詞:聚焦爬蟲;信息提取;農(nóng)業(yè)信息
中圖分類號:TP311.5 文獻(xiàn)標(biāo)識碼:A DOI 編碼:10.3969/j.issn.1006-6500.2016.10.014
Abstract: With the development of information technology, agricultural informatization has become inevitable demand of modern agriculture. On the road of informationalization, the agricultural information is insufficient concentration and real-time poor. The paper describes the design and implement of the agricultural information service system based on focused crawler. With the need of user requirements, focused crawler access to the webpage and related links. The information obtained is presented to the user in a friendly manner through information service system. The platform which provide comprehensive, authoritative and reliable information for the users, promotes the development of agriculture information service.
Key words: focused crawler; information collection; agricultural information
隨著計算機和互聯(lián)網(wǎng)技術(shù)的飛速發(fā)展,信息技術(shù)廣泛應(yīng)用。信息化水平反映一個國家農(nóng)業(yè)的經(jīng)濟水平和整體實力,是實現(xiàn)農(nóng)業(yè)現(xiàn)代化的基礎(chǔ)與保障。加強農(nóng)業(yè)信息化建設(shè)是我國當(dāng)今社會經(jīng)濟發(fā)展的必然趨勢和客觀要求[1-4]。
當(dāng)前互聯(lián)網(wǎng)技術(shù)迅猛發(fā)展,萬維網(wǎng)成為大量信息的載體,廣泛分布著各類信息[5-6]。隨著各類農(nóng)業(yè)信息服務(wù)網(wǎng)站的建立,產(chǎn)生了大量的農(nóng)業(yè)信息,但農(nóng)業(yè)信息往往分布分散、信息更新不及時,導(dǎo)致信息質(zhì)量低,不能滿足農(nóng)民、農(nóng)村、農(nóng)業(yè)現(xiàn)實生產(chǎn)需要[7-11]。針對現(xiàn)代高效農(nóng)業(yè)發(fā)展對現(xiàn)代高新技術(shù)的發(fā)展的需求,本文基于聚焦爬蟲構(gòu)建農(nóng)業(yè)信息綜合服務(wù)平臺,根據(jù)用戶的既定需求,設(shè)定面向主題信息采集的聚焦爬蟲,在海量信息中實時、高效、準(zhǔn)確地提取所需農(nóng)業(yè)數(shù)據(jù),積極推動中國的農(nóng)業(yè)農(nóng)村信息化建設(shè)。
1 聚焦爬蟲網(wǎng)絡(luò)信息提取框架設(shè)計
1.1 農(nóng)業(yè)信息服務(wù)平臺
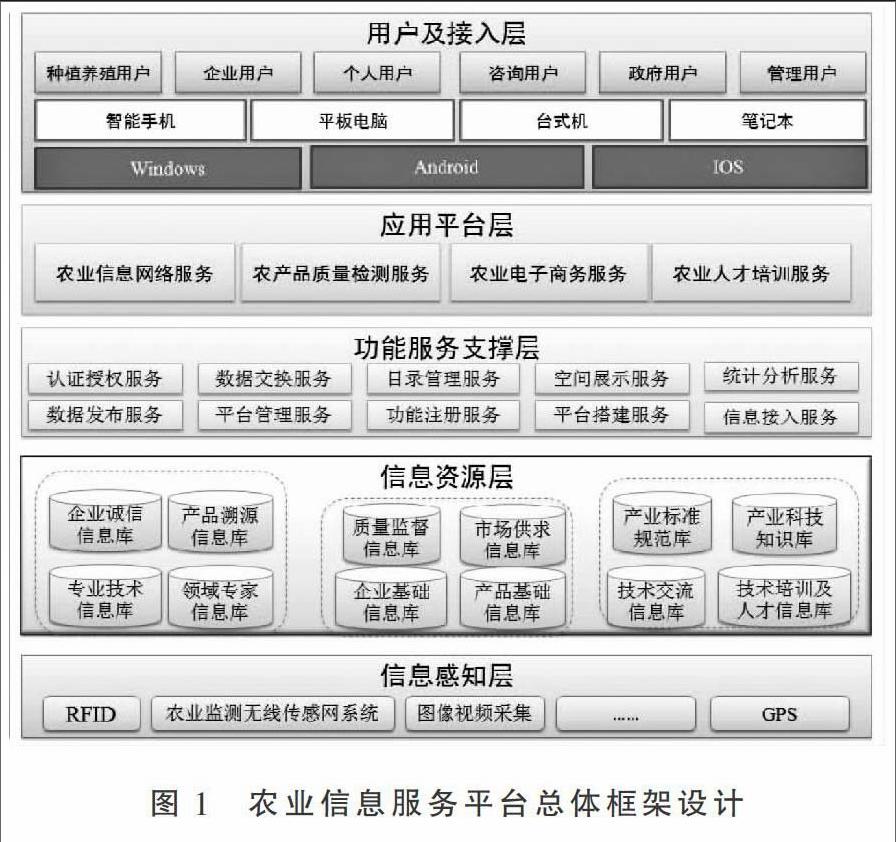
本系統(tǒng)是在建立農(nóng)業(yè)信息資源數(shù)據(jù)庫的基礎(chǔ)上,充分挖掘農(nóng)業(yè)信息服務(wù)功能,提供農(nóng)業(yè)綜合信息網(wǎng)絡(luò)服務(wù)的平臺。平臺包括基礎(chǔ)服務(wù)平臺和功能性平臺兩個層面,其中基礎(chǔ)服務(wù)平臺負(fù)責(zé)農(nóng)業(yè)信息資源數(shù)據(jù)庫的訪問與管理,以及提供相關(guān)服務(wù)功能的應(yīng)用接口;功能性平臺包括產(chǎn)品展示交易、電子溯源、技術(shù)交流與服務(wù)等平臺應(yīng)用接口。總體框架設(shè)計如圖1所示。
1.2 聚焦爬蟲工作流程
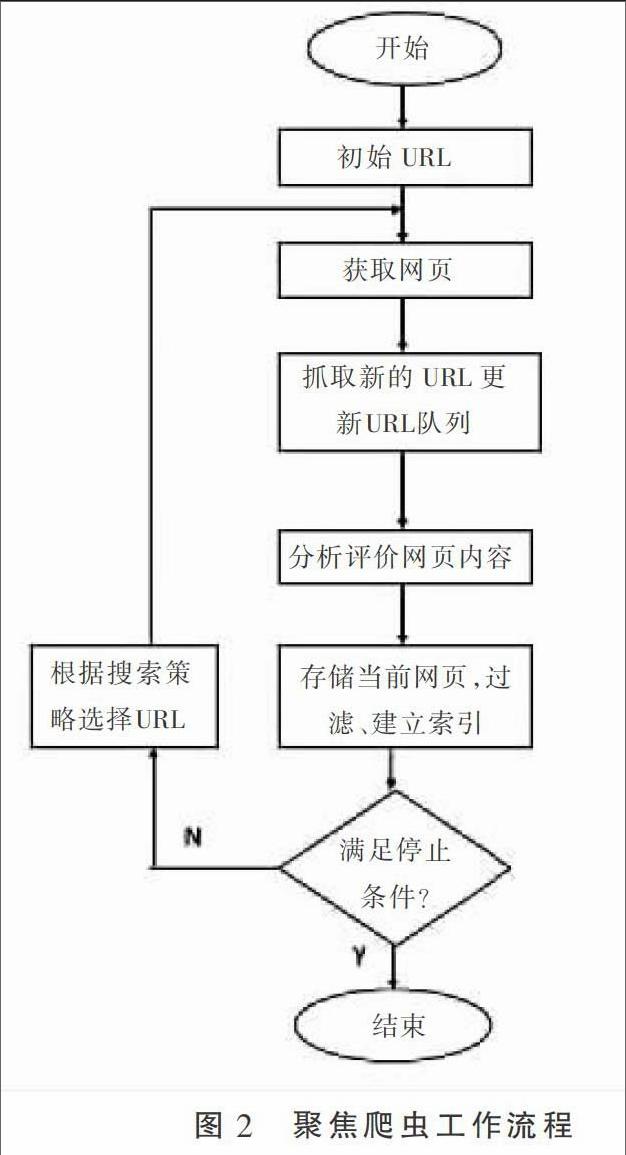
為了可以實現(xiàn)全面、實時的農(nóng)業(yè)信息服務(wù),系統(tǒng)基于聚焦爬蟲,設(shè)定需求,有選擇性地訪問萬維網(wǎng)上的網(wǎng)頁和相關(guān)鏈接,獲得目標(biāo)農(nóng)業(yè)信息數(shù)據(jù)。聚焦爬蟲根據(jù)網(wǎng)頁分析策略過濾與目標(biāo)內(nèi)容無關(guān)的鏈接,保留有效的鏈接并將其放入等待抓取的容器中。它將根據(jù)一定的搜索策略從容器中選擇下一步要抓取分析的網(wǎng)頁的URL,并重復(fù)上述過程,直到達(dá)到系統(tǒng)的某一條件時停止。所有被爬蟲抓取的網(wǎng)頁數(shù)據(jù)將會被系統(tǒng)存貯,進(jìn)行一定的分析、過濾,以便之后的查詢和檢索;對于聚焦爬蟲來說,這一過程所得到的分析結(jié)果可以對以后的抓取過程給出反饋和指導(dǎo)。聚焦爬蟲工作流程圖如圖2所示。
1.3 聚焦爬蟲網(wǎng)絡(luò)信息提取步驟設(shè)計
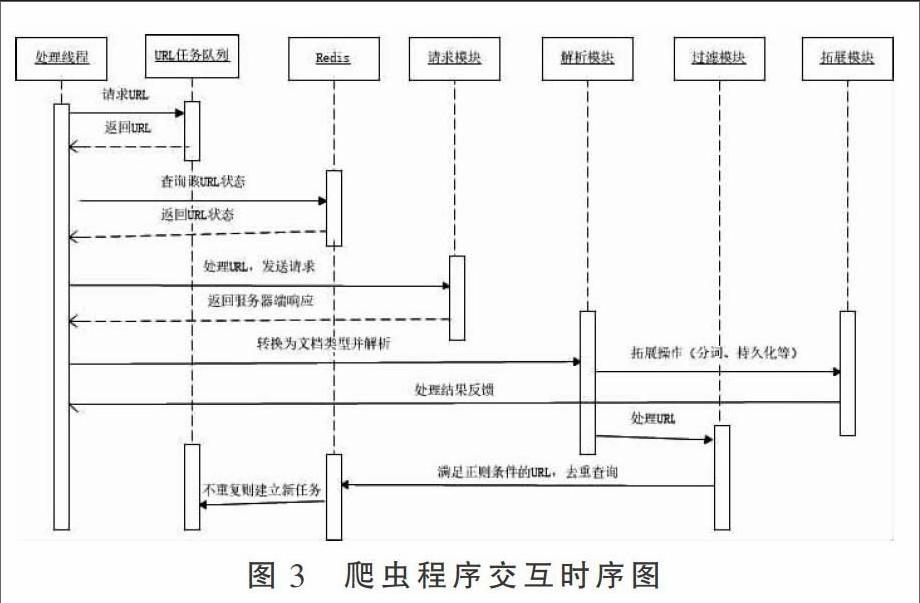
根據(jù)爬蟲程序的工作流程,得到爬蟲各個模塊之間的交互時序圖,如圖3所示。聚焦爬蟲的工作步驟如下。
(1)處理線程向URL任務(wù)隊列請求一個新的URL,如果該任務(wù)隊列不為空,那么任務(wù)隊列會給處理線程返回處于隊頭的URL。
(2)處理線程拿到URL后,與Redis中保存的已進(jìn)入任務(wù)隊列的URL庫做對比,同時更新URL庫中該URL的狀態(tài)(程序中設(shè)定URL有等待爬取、已爬取2個狀態(tài))。
(3)處理線程把URL傳遞給請求模塊,HttpClient構(gòu)造HTTP請求發(fā)給服務(wù)器端,并獲得來自服務(wù)器端的響應(yīng)。
(4)在拿到服務(wù)器端的響應(yīng)后,處理線程將之交予解析模塊,解析模塊會先將響應(yīng)轉(zhuǎn)化為方便解析的文檔類型。
(5)用戶根據(jù)各個網(wǎng)站特有的頁面規(guī)則,可以抽取出網(wǎng)頁目標(biāo)區(qū)域的數(shù)據(jù),然后將這些數(shù)據(jù)交給拓展模塊,拓展模塊可以是數(shù)據(jù)持久化模塊、漢語分詞處理模塊等。
(6)解析模塊解析出頁面的所有URL后,會將之傳給過濾模塊,如果某個URL滿足過濾條件且尚未添加進(jìn)任務(wù)隊列,則將該URL添加至任務(wù)隊列的隊尾;否則拋棄該URL。endprint
(7)從全局來看,聚焦爬蟲的所有處理線程都必須接受線程池的管理。線程池所有線程均執(zhí)行完畢時代表爬蟲程序完成了當(dāng)前層級的所有爬取操作。
2 聚焦爬蟲網(wǎng)絡(luò)信息提取的實現(xiàn)
采用JAVA語言,實現(xiàn)基于目標(biāo)網(wǎng)頁特征和廣度優(yōu)先搜索策略的多線程聚焦爬蟲程序框架。通過使用此框架可以簡單、高效地完成具備個性化需求的爬蟲程序的開發(fā)定制。
2.1 URL過濾規(guī)則
爬蟲程序爬取的網(wǎng)頁中,往往存在著許多與主題毫無關(guān)系的鏈接,比如廣告鏈接和無關(guān)外鏈等。正規(guī)的網(wǎng)站網(wǎng)頁上URL的命名和主題會有一定的相關(guān)性,因此爬蟲程序抽取的URL做正則篩選,篩選出所需網(wǎng)頁的URL。程序中定義了URL的抽取規(guī)則類RegexRule,要求抽取的URL必須至少滿足一條正正則,不能滿足任何一條負(fù)正則。
2.2 URL抽取方法
網(wǎng)頁解析時,程序?qū)⒔邮盏腍TML轉(zhuǎn)換為org.jsoup.nodes.Document類。對URL的抽取,以整頁Document、正則規(guī)則RegexRule和網(wǎng)頁CSS布局為篩選條件,提供功能函數(shù)進(jìn)行抽取。
2.3 線程池的使用
線程池中的FixedThreadPool模式使用一個優(yōu)先固定數(shù)目的線程池來處理多線程任務(wù)。開啟一定數(shù)目的線程來處理所有任務(wù),一旦有線程處理完了當(dāng)前任務(wù),會被用來處理新的任務(wù)。
2.4 分層數(shù)據(jù)爬取
根據(jù)用戶需要的數(shù)據(jù)層次深度,分層爬取數(shù)據(jù)。在抓取線程FetcherThread中,程序每次從任務(wù)隊列FetchQueue的隊頭取出一個URL,并對該URL所在網(wǎng)頁進(jìn)行爬取,然后將從該網(wǎng)頁抽取的URL存到臨時任務(wù)隊列TempQueue。即當(dāng)前層級新抽取的URL都會放到臨時任務(wù)隊列中,完成當(dāng)前層級的爬取任務(wù)后,任務(wù)隊列為空。最后,將臨時隊列中的數(shù)據(jù)移至任務(wù)隊列中。
2.5 隨機代理IP
有些網(wǎng)站為了防止爬蟲程序?qū)W(wǎng)站的關(guān)顧,會統(tǒng)計來源IP,當(dāng)來源IP對該網(wǎng)站的訪問頻率超過一定閥值,將其識別為爬蟲程序,并禁止通過該IP對其網(wǎng)站進(jìn)行訪問。為了應(yīng)對這種情況,通過代理IP來訪問具備反爬蟲功能的網(wǎng)站。
2.6 使用cookie模擬登錄
有些網(wǎng)站需要用戶登錄后才能看到完整的網(wǎng)站內(nèi)容。因此,在發(fā)送請求時,同時發(fā)送賬戶登錄后的cookie信息,讓爬蟲模擬登錄。
2.7 定時任務(wù)增量爬取
增量爬取,是在爬蟲程序運行時,判斷抽取的URL所對應(yīng)的網(wǎng)頁是否已經(jīng)被解析過,如果已經(jīng)解析過則將該URL拋棄,沒有解析過才進(jìn)行解析,即爬蟲程序每次運行時只爬取新更新的內(nèi)容。
2.8 關(guān)鍵詞提取
關(guān)鍵詞提取模塊是調(diào)用漢語分詞系統(tǒng)ICTCLAS的接口來實現(xiàn)。為了適應(yīng)不同用戶的需求和業(yè)務(wù)場景,提供了漢語分詞系統(tǒng)ICTCLAS的本地調(diào)用和遠(yuǎn)程調(diào)用兩種模式。
2.9 聚焦爬蟲實時提取農(nóng)業(yè)信息
根據(jù)農(nóng)業(yè)信息服務(wù)系統(tǒng)所實現(xiàn)的信息服務(wù)功能,聚焦爬蟲通用框架被設(shè)計用來抓取指定網(wǎng)站特定主題的網(wǎng)頁內(nèi)容。以農(nóng)業(yè)資訊要聞信息服務(wù)為例,系統(tǒng)中主要是提供國家和廣東省的最新、最全的農(nóng)業(yè)資訊要聞。通過人工篩選主題網(wǎng)站,廣東省農(nóng)業(yè)資訊選擇具備農(nóng)業(yè)信息權(quán)威性的廣東農(nóng)業(yè)廳網(wǎng)(http://www.gdagri.gov.cn/)作為采集對象網(wǎng)站。使用聚焦爬蟲通用框架來定制農(nóng)業(yè)要聞爬蟲,目錄頁設(shè)置為聚焦爬蟲的啟動種子,并且根據(jù)網(wǎng)頁內(nèi)容特征和URL正則特征確定目標(biāo)URL的篩選條件,最后依據(jù)網(wǎng)頁特征(圖4)完成目標(biāo)數(shù)據(jù)抽取,抽取的數(shù)據(jù)存入相應(yīng)的資源庫(圖5),抽取結(jié)果如圖6所示。
3 結(jié) 論
隨著互聯(lián)網(wǎng)技術(shù)、信息技術(shù)等高新技術(shù)在農(nóng)業(yè)領(lǐng)域的廣泛應(yīng)用,對農(nóng)業(yè)農(nóng)村信息服務(wù)的迫切需求。為了讓用戶能夠在信息海洋中獲取全面、及時、適用和精煉的農(nóng)業(yè)信息,構(gòu)建基于聚焦爬蟲的農(nóng)業(yè)信息服務(wù)平臺。本研究著重研究了聚焦爬蟲的網(wǎng)頁信息提取框架的設(shè)計與實現(xiàn),將聚集爬蟲實時獲取的農(nóng)業(yè)相關(guān)信息依托農(nóng)業(yè)信息服務(wù)平臺呈現(xiàn)給各類用戶,對農(nóng)業(yè)農(nóng)村信息服務(wù)的推廣有重要的實踐意義和推動意義。
參考文獻(xiàn):
[1]岳廣飛,何明祥.村鎮(zhèn)農(nóng)業(yè)個性化信息服務(wù)體系的研究[J].現(xiàn)代情報,2009,29(6):34-37.
[2]鄧秀新.現(xiàn)代農(nóng)業(yè)與農(nóng)業(yè)發(fā)展[J].華中農(nóng)業(yè)大學(xué)學(xué)報:社會科學(xué)版,2014,33(1):1-4.
[3]李林杰,王紅濤.加快農(nóng)業(yè)科技進(jìn)步推進(jìn)現(xiàn)代農(nóng)業(yè)發(fā)展——基于我國“十五”時期農(nóng)業(yè)科技進(jìn)步貢獻(xiàn)率的實證分析[J].農(nóng)業(yè)現(xiàn)代化研究,2008,29(2):163-167.
[4]張海峰.基于Android智能手機的農(nóng)業(yè)信息服務(wù)平臺應(yīng)用展望[J].黑龍江農(nóng)業(yè)科學(xué),2014(8):126-128.
[5]羅長壽,孫素芬,張峻峰,等.基于查準(zhǔn)率的網(wǎng)頁信息搜索技術(shù)研究分析[J].情報雜志,2007,26(3):115-117.
[6]劉建生,周志輝.個性化搜索引擎綜述[J].計算機與數(shù)字工程,2010,38(10):80-81, 94.
[7]韋金河,袁易之,周秋萍,等.江蘇省農(nóng)業(yè)科技服務(wù)超市信息化網(wǎng)絡(luò)設(shè)計[J].江西農(nóng)業(yè)學(xué)報,2013,25(5):123-126, 131.
[8]陳誠,廖桂平,史曉慧,等.農(nóng)業(yè)農(nóng)村信息服務(wù)個性化推送技術(shù)[J].中國農(nóng)學(xué)通報,2011,27(29):151-156.
[9]韓炳華.關(guān)于農(nóng)業(yè)信息化服務(wù)現(xiàn)代農(nóng)業(yè)的思考[J].黑龍江科技信息,2013(16):290.
[10]方鈺,黃亮,陳詩平.基于Android系統(tǒng)的農(nóng)業(yè)信息服務(wù)平臺運行模式及發(fā)展前景[J].現(xiàn)代農(nóng)業(yè)科技,2014 (19):340-341, 345.
[11]任鈺,郭芳芳.農(nóng)業(yè)信息服務(wù)需求與影響因素分析[J].山西農(nóng)業(yè)科學(xué),2015,43(8):1018-1020.endprint
