基于樣本差異的多標(biāo)簽分類器評(píng)價(jià)標(biāo)準(zhǔn)預(yù)估
2016-11-09 01:20:12余圣波
計(jì)算機(jī)應(yīng)用與軟件 2016年9期
張 敏 余圣波
(重慶大學(xué)計(jì)算機(jī)學(xué)院軟件理論與技術(shù)重慶市重點(diǎn)實(shí)驗(yàn)室 重慶 400044)
?
基于樣本差異的多標(biāo)簽分類器評(píng)價(jià)標(biāo)準(zhǔn)預(yù)估
張敏余圣波
(重慶大學(xué)計(jì)算機(jī)學(xué)院軟件理論與技術(shù)重慶市重點(diǎn)實(shí)驗(yàn)室重慶 400044)
評(píng)價(jià)標(biāo)準(zhǔn)是分類器的重要指標(biāo)。對(duì)于多標(biāo)簽學(xué)習(xí),常用的評(píng)價(jià)標(biāo)準(zhǔn)有Hamming Loss、One-error、Coverage、Ranking loss和Average precision。多標(biāo)簽分類器給出分類結(jié)果的同時(shí)并未給出評(píng)價(jià)標(biāo)準(zhǔn)值,通常采用事后驗(yàn)算的方法評(píng)估評(píng)價(jià)標(biāo)準(zhǔn)。這樣往往不能及時(shí)有效地發(fā)現(xiàn)評(píng)價(jià)標(biāo)準(zhǔn)值變化之類的問題,同時(shí)評(píng)估評(píng)價(jià)標(biāo)準(zhǔn)值需對(duì)測(cè)試樣本進(jìn)行標(biāo)記。針對(duì)這一問題,分別從樣本分布差異和樣本實(shí)例間差異提出兩種評(píng)價(jià)標(biāo)準(zhǔn)預(yù)估方法。分析上述兩種方法的特點(diǎn),提出第三種評(píng)價(jià)標(biāo)準(zhǔn)預(yù)估方法。實(shí)驗(yàn)表明,這三種評(píng)價(jià)標(biāo)準(zhǔn)預(yù)估方法具有良好效果,可用于遷移學(xué)習(xí)等。
多標(biāo)簽學(xué)習(xí)評(píng)價(jià)標(biāo)準(zhǔn)樣本分布樣本實(shí)例線性擬合
0 引 言
多標(biāo)簽學(xué)習(xí)是機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘技術(shù)中的一個(gè)研究熱點(diǎn)。與單標(biāo)簽學(xué)習(xí)相比,多標(biāo)簽分類中的樣本可以同時(shí)歸屬多個(gè)類別。多標(biāo)簽學(xué)習(xí)是一種更符合真實(shí)世界客觀規(guī)律的方法,其廣泛地應(yīng)用于各種不同的領(lǐng)域,如圖像視頻的語(yǔ)義標(biāo)注[1-3]、功能基因組[4,5]、音樂情感分類[6]以及營(yíng)銷指導(dǎo)[7]等。多標(biāo)簽學(xué)習(xí)主要有兩個(gè)任務(wù):多標(biāo)簽分類和標(biāo)簽排序[8],前者的任務(wù)就是要為每一個(gè)樣本盡可能地標(biāo)注出所有與其相關(guān)的標(biāo)簽,從而達(dá)到一個(gè)多標(biāo)簽自動(dòng)分類的目的;后者則是對(duì)于待測(cè)樣本按標(biāo)簽與其相關(guān)程度由高至低輸出全部標(biāo)簽。
現(xiàn)有的多標(biāo)簽數(shù)據(jù)的學(xué)習(xí)方法主要分為兩大類:?jiǎn)栴}轉(zhuǎn)換法和算法適應(yīng)法[9]。問題轉(zhuǎn)換的方法就是通過改造數(shù)據(jù)將多標(biāo)簽學(xué)習(xí)問題轉(zhuǎn)化為其他已知的單標(biāo)簽學(xué)習(xí)問題進(jìn)行求解,該方法不受特定算法的限制,目前已成熟的單標(biāo)簽分類算法有支持向量機(jī)、k近鄰方法、貝葉斯方法和提升方法等。算法適應(yīng)方法是通過直接改造現(xiàn)存的單標(biāo)簽學(xué)習(xí)算法,使之能夠適應(yīng)多標(biāo)簽數(shù)據(jù)的處理,該類方法代表性的學(xué)習(xí)算法有ML-kNN(Multi-Label k-Nearest Neighbor)[10]、RankSVM(Ranking Support Vector Machine)[11]、AdaBoost.MH(multiclass,multi-label version of AdaBoost based on Hamming loss)[12]和BoosTexter (A Boosting-based System for Text Categorization)[13]等。在本文中,使用ML-kNN分類算法得到多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)值。ML-kNN是kNN算法的擴(kuò)展,其性能優(yōu)于BoosTexter、AdaBoost.MH和 RankSVM。
多標(biāo)簽學(xué)習(xí)的評(píng)價(jià)指標(biāo)不同于傳統(tǒng)的單標(biāo)簽學(xué)習(xí),單標(biāo)簽學(xué)習(xí)常用的評(píng)價(jià)標(biāo)準(zhǔn)有準(zhǔn)確度、精度、召回率和F值[14]。對(duì)于多標(biāo)簽學(xué)習(xí),常用的評(píng)價(jià)標(biāo)準(zhǔn)有Hamming loss、One-error、Coverage、Ranking loss和Average precision。其中,Hamming loss主要衡量預(yù)測(cè)所得標(biāo)簽和樣本實(shí)際標(biāo)簽不一致的程度,結(jié)果越小越好;One-error描述樣本預(yù)測(cè)隸屬度最高的標(biāo)簽不在實(shí)際標(biāo)簽的概率,結(jié)果越小越好;Coverage描述了在標(biāo)簽排序函數(shù)中,從隸屬度最高的標(biāo)簽開始,平均需要跨越多少個(gè)標(biāo)簽才能覆蓋樣本所擁有的全部標(biāo)簽,結(jié)果越小越好;Ranking loss衡量樣本所屬標(biāo)簽隸屬度低于非其所屬標(biāo)簽隸屬度的概率,結(jié)果越小越好;Average precision描述了對(duì)樣本預(yù)測(cè)標(biāo)簽的平均準(zhǔn)確率,結(jié)果越大越好。
目前要得到多標(biāo)簽學(xué)習(xí)評(píng)價(jià)標(biāo)準(zhǔn)有兩個(gè)常用方法。一個(gè)常用的方法是觀察訓(xùn)練樣本集中的評(píng)價(jià)標(biāo)準(zhǔn)值,訓(xùn)練樣本集中的評(píng)價(jià)標(biāo)準(zhǔn)值與測(cè)試樣本集中的評(píng)價(jià)標(biāo)準(zhǔn)值無明確關(guān)系,但是通過對(duì)訓(xùn)練樣本集中的評(píng)價(jià)標(biāo)準(zhǔn)值的觀察,估計(jì)測(cè)試樣本集中的評(píng)價(jià)標(biāo)準(zhǔn)值有一定意義。對(duì)于Hamming loss、One-error、Coverage和Ranking loss,這些評(píng)價(jià)標(biāo)準(zhǔn)關(guān)于測(cè)試樣本集的值往往高于或等于這些評(píng)價(jià)標(biāo)準(zhǔn)在訓(xùn)練樣本集中的估計(jì)值,那么關(guān)于訓(xùn)練樣本集的這些評(píng)價(jià)標(biāo)準(zhǔn)值過高,其在測(cè)試樣本集中的評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)值也不會(huì)低。對(duì)于Average precision評(píng)價(jià)標(biāo)準(zhǔn),其關(guān)于測(cè)試樣本集的估計(jì)值往往低于或等于其在訓(xùn)練樣本集中的估計(jì)值,那么Average precision在訓(xùn)練樣本集中的估計(jì)值太低,其在測(cè)試樣本集中的估計(jì)值也不會(huì)高。另一個(gè)常用的方法是標(biāo)記測(cè)試樣本,與分類結(jié)果對(duì)比,得到測(cè)試樣本的評(píng)價(jià)指標(biāo)值,然后利用統(tǒng)計(jì)學(xué)的知識(shí),將計(jì)算出來的評(píng)價(jià)指標(biāo)值推廣到一般情況。這種方法需要標(biāo)記測(cè)試樣本,標(biāo)記樣本有時(shí)候會(huì)比較昂貴,但其得到的評(píng)價(jià)指標(biāo)估計(jì)值比較客觀。可以看出,想得到關(guān)于測(cè)試樣本集的確切評(píng)價(jià)指標(biāo)值,往往需要對(duì)測(cè)試樣本進(jìn)行標(biāo)記,那么是否可以不對(duì)測(cè)試樣本進(jìn)行額外的標(biāo)記就估計(jì)出關(guān)于測(cè)試樣本的評(píng)價(jià)指標(biāo)值呢?
本文提出基于測(cè)試樣本與訓(xùn)練樣本差異來估計(jì)關(guān)于測(cè)試樣本的評(píng)價(jià)指標(biāo)的方法。樣本差異可以從宏觀和微觀兩個(gè)角度來考慮,樣本分布差異是樣本差異的宏觀體現(xiàn),樣本實(shí)例間差異是樣本差異的微觀體現(xiàn)。這樣可以通過收集到的測(cè)試樣本與訓(xùn)練樣本的對(duì)比估計(jì)出評(píng)價(jià)指標(biāo)值,從而避免標(biāo)記樣本的昂貴成本,使得多標(biāo)簽分類器可以在給出分類結(jié)果的同時(shí)給出評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)值,可以應(yīng)用于遷移學(xué)習(xí)等領(lǐng)域。
1 基于樣本分布差異的多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)預(yù)估
1.1MMD統(tǒng)計(jì)量
通常情況下,分類器都假設(shè)樣本分布在整個(gè)分類過程中不會(huì)發(fā)生變化。當(dāng)訓(xùn)練樣本集和測(cè)試樣本集的分布有差異時(shí),由訓(xùn)練樣本集得到的分類器不再適用于測(cè)試樣本集。如單標(biāo)簽貝葉斯分類器,當(dāng)訓(xùn)練樣本集和測(cè)試樣本集的分布有差異時(shí),先驗(yàn)概率發(fā)生變化,此時(shí)由訓(xùn)練樣本集得到的貝葉斯分類器不適用于測(cè)試樣本集。那么如何衡量?jī)山M樣本的分布差異呢?
設(shè)有一組訓(xùn)練樣本集記為A(x1,x2,…,xm),其服從分布p;一組測(cè)試樣本記為B(y1,y2,…,yn),其服從分布q。如何判斷p和q是否相同,過去主要采用參數(shù)統(tǒng)計(jì)的方法,首先需要確定它們的分布模型,之后通過參數(shù)假設(shè)的方法推斷它們是否包含相同的參數(shù)。文獻(xiàn)[15]提出了將分布嵌入再生核希爾伯特空間的方法。文獻(xiàn)[16]提出了衡量?jī)山M樣本差異的核方法,即最大均值差異MMD(Maximum Mean Discrepancy)的度量方法。其中:
(1)
式中,F(xiàn)為將測(cè)量空間映射到實(shí)數(shù)域的一類函數(shù),k(·)為核函數(shù)。
(2)
式中,K為一常數(shù),且|k(x,y)|≤K,x∈A,y∈B。
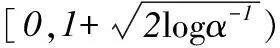
1.2MMD與評(píng)價(jià)標(biāo)準(zhǔn)的關(guān)系
為了確定MMD統(tǒng)計(jì)量與多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)Hamming loss、One-error、Coverage、Ranking loss和Average precision 的關(guān)系,使用參數(shù)估計(jì)的方法估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)。從評(píng)價(jià)標(biāo)準(zhǔn)和MMD統(tǒng)計(jì)量的實(shí)驗(yàn)數(shù)據(jù)可以看出,MMD與Hamming loss、One-error、Coverage、Ranking loss和Average precision有良好的線性關(guān)系。然而,針對(duì)不同的評(píng)價(jià)標(biāo)準(zhǔn),相關(guān)性程度也不相同。可將使用MMD估計(jì)多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)值問題假設(shè)為:
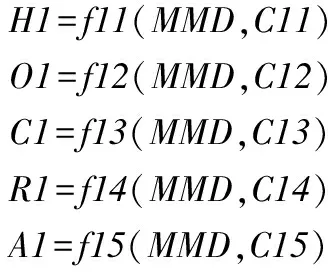
(3)
其中H1、O1、C1、R1和A1分別為Hamming loss、One-error、Coverage、Ranking loss和Average precision的估計(jì)值。C11、C12、C13、C14和C15為參數(shù)列表;f11、f12、f13、f14和f15為線性函數(shù)。為了確定參數(shù)估計(jì)中的相關(guān)參數(shù)和使得評(píng)價(jià)標(biāo)準(zhǔn)與評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)值的誤差最小,使用最小二乘法。下面以評(píng)價(jià)指標(biāo)Hamming loss為例進(jìn)行求解,其他指標(biāo)的求解過程與Hamming loss相似。設(shè)有z1組實(shí)驗(yàn)數(shù)據(jù)(mmdi,hlossi),i=1,…,z1,它們相互獨(dú)立,其中mmdi和hlossi分別為第i次實(shí)驗(yàn)得到的MMD統(tǒng)計(jì)值和Hamming loss值。記:
則殘差平方和為:
Q1=‖Y-X×C11‖2=(Y-X×C11)′(Y-X×C11)

2 基于樣本實(shí)例間差異的多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)預(yù)估
2.1MMR統(tǒng)計(jì)量
MMD關(guān)注的是訓(xùn)練樣本集和測(cè)試樣本集的分布差異,是一個(gè)宏觀的統(tǒng)計(jì)量。樣本差異可以從宏觀和微觀兩個(gè)角度進(jìn)行考慮。樣本實(shí)例間差異是樣本差異的微觀體現(xiàn)。為此,提出基于樣本實(shí)例間差異的多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)。
k近鄰算法kNN(k-nearest neighbor)是一種基于樣本實(shí)例的單標(biāo)簽分類器。k近鄰算法意味著每個(gè)樣本都可以用與它最近的k個(gè)鄰居來表示,其基本思想是:找到離該樣本最近的k個(gè)鄰居,如果這k個(gè)鄰居大多數(shù)屬于某一個(gè)類別,那么這個(gè)樣本也應(yīng)該屬于這個(gè)類別。k近鄰分類算法的數(shù)學(xué)模型如下:設(shè)一組訓(xùn)練樣本集記為A(x1,x2,…,xm),一組測(cè)試樣本集記為B(y1,y2,…,yn),為了求得B中每個(gè)樣本yi的標(biāo)簽,對(duì)每個(gè)測(cè)試樣本做如下處理:求得訓(xùn)練樣本集A中與yi最接近的k個(gè)樣本,然后由這k個(gè)樣本投票得到y(tǒng)i的標(biāo)簽。對(duì)k近鄰算法的一個(gè)明顯改進(jìn)是對(duì)k個(gè)近鄰進(jìn)行距離加權(quán)。離測(cè)試樣本越近的訓(xùn)練樣本,其權(quán)值越大。可以看出,在k近鄰算法中,若近鄰與測(cè)試樣本的平均距離越小,則分類結(jié)果的可信度越高。使用kNN算法得到一個(gè)分類結(jié)果,該分類結(jié)果的可信度可以由k近鄰組成的鄰域大小做出估計(jì)。此處,選擇k=1的特殊情況。如果對(duì)測(cè)試樣本B中的每一個(gè)樣本yi,與其在A中的最近鄰樣本xj的距離d(yi,xj)足夠小,那么以xj的標(biāo)簽作為yi的標(biāo)簽有較高的可信度;反之,與其在A中的最近鄰樣本xj的距離d(yi,xj)比較大,那么以xj的標(biāo)簽作為yi的標(biāo)簽具有較低的可信度。
由此假設(shè),B中樣本與A中樣本的最小距離影響kNN算法分類結(jié)果可信度。通過觀察B中每個(gè)樣本到A中樣本的最小距離,可以得到B中樣本的kNN分類結(jié)果可信度。由這個(gè)估計(jì)得到對(duì)多標(biāo)簽分類器評(píng)價(jià)標(biāo)準(zhǔn)的估計(jì)。本文提出了MMR(Mean Maximum Resemblance)統(tǒng)計(jì)量,MMR為B中樣本到A中樣本最小距離的均值。
MMR(A,B)=mean(minx∈Ad(x,y))
(4)
MMR的計(jì)算方法如下:
Step1對(duì)yi∈B,i=1,2,…,n,計(jì)算其與訓(xùn)練樣本集的最小距離:
md(yi)=minxj∈Ad(xj,yi)
=minxj∈A(xj-yi)×(xj-yi)′j=1,2,…,m
(5)
Step2求均值:
(6)
Step3標(biāo)準(zhǔn)化:
(7)
在Step3中使用最大跨度作為標(biāo)準(zhǔn)化分母,使得MMR盡量不受訓(xùn)練樣本集的影響。MMR越大,表示測(cè)試樣本集與訓(xùn)練樣本集實(shí)例間的差異越大,隨之關(guān)于測(cè)試樣本集的Hamming loss值、One-error值、Coverage值和Ranking loss值越大,Average precision值越小;MMR越小,表示測(cè)試樣本集與訓(xùn)練樣本集實(shí)例間的差異越小,隨之關(guān)于測(cè)試樣本集的Hamming loss值、One-error值、Coverage值和Ranking loss值越小,Average precision值越大。
MMR性質(zhì):MMR(A,B)=0,當(dāng)且僅當(dāng)對(duì)于測(cè)試樣本集中的每一個(gè)實(shí)例,在訓(xùn)練樣本集中都可以找到與之相同的實(shí)例,使得它們的距離為0,即MMR(A,B)=0。MMR(A,B)不是一個(gè)對(duì)稱的統(tǒng)計(jì)量,即MMR(A,B)≠M(fèi)MR(B,A)。一個(gè)特例是A真包含B時(shí),有MMR(A,B)=0,MMR(B,A)≠0。MMR的計(jì)算時(shí)間復(fù)雜度為O(mn+m2)。
2.2MMR與評(píng)價(jià)標(biāo)準(zhǔn)的關(guān)系
為了確定MMR和多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)的關(guān)系,使用參數(shù)估計(jì)的方法估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)。從多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)和MMR統(tǒng)計(jì)量的實(shí)驗(yàn)數(shù)據(jù)可以看出,Hamming loss、One-error、Coverage、Ranking loss、Average precision和MMR統(tǒng)計(jì)量也有良好的線性關(guān)系。然而,對(duì)于不同的評(píng)價(jià)標(biāo)準(zhǔn),相關(guān)性程度也不同。因此,跟利用MMD統(tǒng)計(jì)量估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)類似,可將評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)問題假設(shè)為:

(8)
其中H2、O2、C2、R2和A2分別為Hamming loss、One-error、Coverage、Ranking loss和Average precision的估計(jì)值;C21、C22、C23、C24和C25為參數(shù)列表;f21、f22、f23、f24和f25為線性函數(shù)。為了確定參數(shù)估計(jì)中的相關(guān)參數(shù)和使得評(píng)價(jià)標(biāo)準(zhǔn)與評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)值的誤差最小,亦使用最小二乘法。下面以Hamming loss為例進(jìn)行求解,其他評(píng)價(jià)指標(biāo)的求解過程與Hamming loss相似。設(shè)有z2組實(shí)驗(yàn)數(shù)據(jù)(mmrj,hlossj),j=1,2,…,z2,它們相互獨(dú)立,其中mmrj和hlossj分別為第j次實(shí)驗(yàn)得到的MMR統(tǒng)計(jì)值和Hamming loss值。記:
則殘差平方和為:
Q2=‖Y-X×C21‖2=(Y-X×C21)′(Y-X×C21)

3 基于MMD和MMR的多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)預(yù)估
MMD關(guān)注的是訓(xùn)練樣本集和測(cè)試樣本集的分布差異,是一個(gè)宏觀的統(tǒng)計(jì)量;MMR關(guān)注的是訓(xùn)練樣本集中的實(shí)例和測(cè)試樣本集中的實(shí)例之間的差異,是一個(gè)微觀的統(tǒng)計(jì)量。它們可以相互補(bǔ)充,共同估算出關(guān)于測(cè)試樣本集的評(píng)價(jià)標(biāo)準(zhǔn)值。
由利用MMD線性擬合評(píng)價(jià)標(biāo)準(zhǔn)和MMR線性擬合評(píng)價(jià)標(biāo)準(zhǔn),可以得出Hamming loss、One-Error、Coverage、Ranking loss和Average precision分別與MMD和MMR的相關(guān)方程及參數(shù)。利用這些參數(shù),可以得出這些評(píng)價(jià)標(biāo)準(zhǔn)與MMD和MMR的相關(guān)方程。由于MMD和MMR都與這些評(píng)價(jià)標(biāo)準(zhǔn)有良好的線性關(guān)系,故將使用MMD和MMR預(yù)估多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)問題假設(shè)為:

(9)
其中H3、O3、C3、R3和A3分別為Hamming loss、One-error、Coverage、Ranking loss和Average precision的估計(jì)值。c311、c312、c313、c321、c322、c323、c331、c332、c333、c341、c342、c343、c351、c352和c353為參數(shù)列表;f31、f32、f33、f34和f35為線性函數(shù)。下面以Hamming loss為例進(jìn)行參數(shù)求解,其他評(píng)價(jià)標(biāo)準(zhǔn)的參數(shù)求解過程與Hamming loss相似。
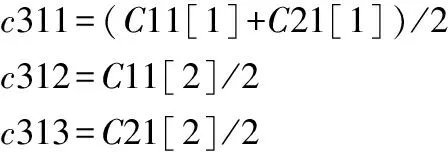
(10)
線性方程f31的詳細(xì)表達(dá)式如下:
H3=c311+c312×MMD+c313×MMR
(11)
4 實(shí)驗(yàn)及分析
4.1實(shí)驗(yàn)說明
在實(shí)驗(yàn)中共使用兩組數(shù)據(jù)集,分別描述如下:
UJIndoorLoc數(shù)據(jù)集是一個(gè)基于WLAN/WiFi指紋的多建筑多層室內(nèi)定位數(shù)據(jù)集。 該數(shù)據(jù)集有兩組數(shù)據(jù),分別叫做UJI_training和UJI_test。UJI_training含有19 937個(gè)訓(xùn)練樣本,UJI_test含有1111個(gè)測(cè)試樣本。
Turkiye學(xué)生評(píng)價(jià)數(shù)據(jù)集由 Gazi University提供。該數(shù)據(jù)集有兩組數(shù)據(jù),分別叫做Tu_training和Tu_test。Tu_training收集于2013年,有5820個(gè)學(xué)生評(píng)價(jià)數(shù)據(jù);Tu_test收集于2014年,有5820個(gè)學(xué)生評(píng)價(jià)數(shù)據(jù)。這兩組數(shù)據(jù)有差異。
共進(jìn)行16次試驗(yàn),分別記為Task1,Task2,…,Task16。采用ML-kNN多標(biāo)簽分類器得出關(guān)于測(cè)試樣本集的評(píng)價(jià)標(biāo)準(zhǔn)值。
4.2樣本差異與MMD、MMR的關(guān)系
Task1~Task6使用相同的訓(xùn)練樣本集,得到相同的分類器。從UJI_training set中隨機(jī)抽取1200個(gè)樣本作為Task1至Task6的訓(xùn)練樣本集。從UJI_test set中進(jìn)行兩次隨機(jī)抽取200個(gè)樣本分別作為Task1和Task2的測(cè)試樣本集。從UJI_training set中(除Task1的訓(xùn)練樣本集)進(jìn)行兩次隨機(jī)抽取200個(gè)樣本分別作為Task3和Task4的測(cè)試樣本集。從Task1和Task3的測(cè)試樣本集中各隨機(jī)抽取100個(gè)樣本,再將它們合并,作為Task5的測(cè)試樣本集;從Task2和Task4的測(cè)試樣本集中各隨機(jī)抽取100個(gè)樣本,再將它們合并,作為Task6的測(cè)試樣本集。然后,得到MMD值和MMR值,使用ML-kNN得到Hamming loss、One-error、Coverage、Ranking loss和Average precision的值。實(shí)驗(yàn)結(jié)果如表1所示。從表1可以看出,UJI_training set和UJI_test set存在差異。不同地點(diǎn)采取的數(shù)據(jù)可能存在差異。
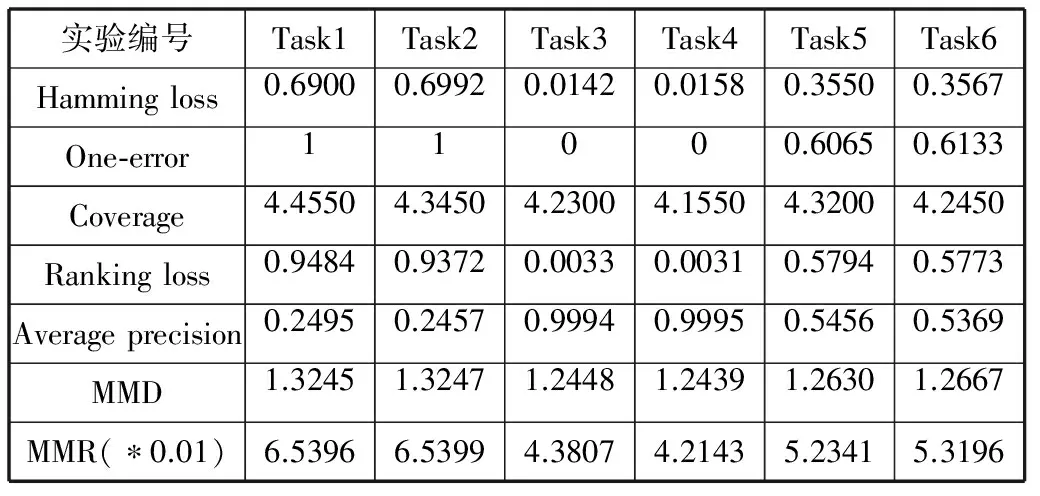
表1 Task1~Task6實(shí)驗(yàn)結(jié)果
Task7-Task12使用相同的訓(xùn)練樣本集,得到相同的分類器。從Tu_training set中隨機(jī)抽取1200個(gè)樣本作為Task7至Task12的訓(xùn)練樣本集,從Tu_test set中進(jìn)行兩次隨機(jī)抽取200個(gè)樣本分別作為Task7和Task8的測(cè)試樣本集。從Tu_training set(除Task7的訓(xùn)練樣本集)中進(jìn)行兩次隨機(jī)抽取200個(gè)樣本分別作為Task9和Task10的測(cè)試樣本集。從Task7和Task9的測(cè)試樣本集中分別隨機(jī)抽取100個(gè)樣本,再將它們合并,作為Task11的測(cè)試樣本集。從Task8和Task10的測(cè)試樣本集中分別隨機(jī)抽取100個(gè)樣本,再將它們合并,作為Task12的測(cè)試樣本集。然后,得到它們的MMD值、MMR值和多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)值,實(shí)驗(yàn)結(jié)果如表2所示。從表2可以看出,Tu_training set和Tu_test set兩組數(shù)據(jù)存在差異。Tu_training set采集于2013年,Tu_test set采集于2014年。

表2 Task7~Task12實(shí)驗(yàn)結(jié)果
從表1和表2可以看出,MMD能正確反映兩組樣本分布的差異, MMD值越小,表示訓(xùn)練樣本集和測(cè)試樣本集的分布差異越小,從而Hamming loss、One-error、Coverage、Ranking loss的值越小,Average precision的值越大。MMD值越大,表示訓(xùn)練樣本集和測(cè)試樣本集的分布差異越大,從而Hamming loss、One-error、Coverage、Ranking loss的值越大,Average precision的值越小。MMR能正確地反映兩組樣本實(shí)例間的差異,MMR越大,表示訓(xùn)練樣本集實(shí)例和測(cè)試樣本集實(shí)例之間的差異越大,從而Hamming loss、One-error、Coverage、Ranking loss的值越大,Average precision的值越小。MMR越小,表示訓(xùn)練樣本集實(shí)例和測(cè)試樣本集實(shí)例之間的差異越小,從而Hamming loss、One-error、Coverage、Ranking loss的值越小,Average precision的值越大。
4.3評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)
Task13采用UJIndoorLoc數(shù)據(jù)庫(kù)。從UJI_training set中隨機(jī)抽取801個(gè)樣本作為Task13的訓(xùn)練樣本集。為保證數(shù)據(jù)的平衡性,從UJI_training set(除Task13的訓(xùn)練樣本集)中隨機(jī)抽取1111個(gè)樣本和UJI_test set作為一個(gè)新的測(cè)試樣本集,記為Test samples1。從Test samples1中隨機(jī)抽取90個(gè)樣本作為Task13的測(cè)試樣本集。重復(fù)20次,然后得到MMD值、MMR值和多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)值。利用4-折交叉驗(yàn)證得到評(píng)價(jià)標(biāo)準(zhǔn)的估計(jì)值。
Task14采用UJIndoorLoc數(shù)據(jù)庫(kù)。從UJI_training set中隨機(jī)抽取1200個(gè)樣本作為Task14的訓(xùn)練樣本集。為保證數(shù)據(jù)的平衡性,從UJI_training set(除Task14的訓(xùn)練樣本集)中隨機(jī)抽取1111個(gè)樣本和UJI_test set作為一個(gè)新的測(cè)試樣本集,記為Test samples2。從Test samples2中隨機(jī)抽取250個(gè)樣本作為Task14的測(cè)試樣本集。重復(fù)20次,然后得到MMD值、MMR值和多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)值。利用4-折交叉驗(yàn)證得到評(píng)價(jià)標(biāo)準(zhǔn)的估計(jì)值。
評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)的實(shí)驗(yàn)結(jié)果如表3所示,其中EM(D)為使用MMD估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的誤差均值,EM(R)為使用MMR估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的誤差均值,EM(D,R)為使用MMD和MMR估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的誤差均值。
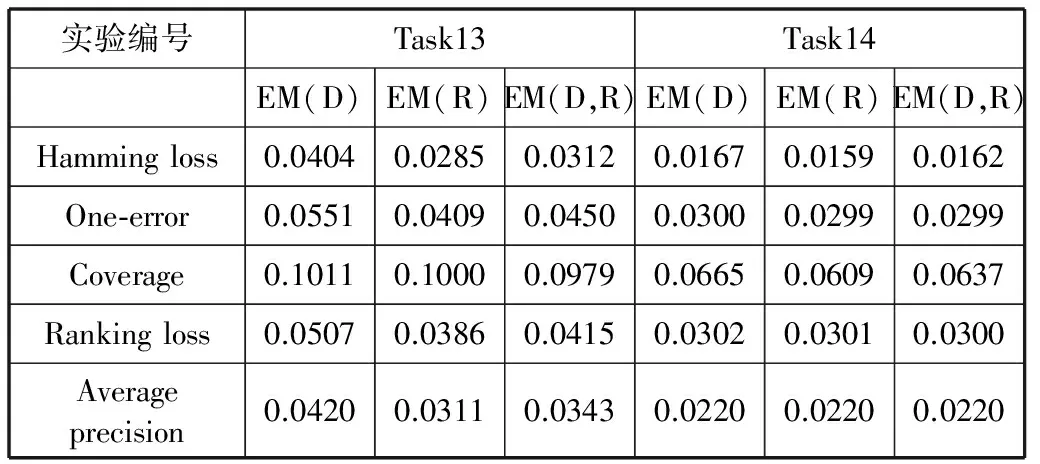
表3 Task13~Task14實(shí)驗(yàn)結(jié)果
從表3和表4可以看出,針對(duì)不同的評(píng)價(jià)標(biāo)準(zhǔn),MMD的表現(xiàn)不同。其中,對(duì)于Hamming loss、One-error、Ranking loss和Average precision,MMD的表現(xiàn)良好。對(duì)于Coverage,MMD的表現(xiàn)要比其他評(píng)價(jià)標(biāo)準(zhǔn)差。針對(duì)不同的評(píng)價(jià)標(biāo)準(zhǔn),MMR的表現(xiàn)也不同。對(duì)于Hamming loss、One-error、Ranking loss和Average precision,MMR的表現(xiàn)良好。對(duì)于Coverage,MMR的表現(xiàn)要比其他評(píng)價(jià)標(biāo)準(zhǔn)差。綜合使用MMD和MMR估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的誤差均值一般在單獨(dú)使用MMD和MMR估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的誤差均值之間。對(duì)比表3和表4可以看出,訓(xùn)練樣本集和測(cè)試樣本集中的樣本數(shù)目越多,估計(jì)評(píng)價(jià)指標(biāo)的誤差均值越小。
Task15采用Turkiye Student Evaluation Data Set。從Tu_training set中隨機(jī)抽取801個(gè)樣本作為Task15的訓(xùn)練樣本集。將Tu_training set(除Task15的訓(xùn)練樣本集)和Tu_test set作為一個(gè)新的測(cè)試樣本集,記為Test samples3。從Test samples3中隨機(jī)抽取90個(gè)樣本作為Task15的測(cè)試樣本集。重復(fù)20次,然后得到MMD值、MMR值和多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)值。利用4-折交叉驗(yàn)證得到評(píng)價(jià)標(biāo)準(zhǔn)的估計(jì)值。
Task16采用Turkiye Student Evaluation Data Set。從Tu_training set中隨機(jī)抽取1200個(gè)樣本作為Task16的訓(xùn)練樣本集。 將Tu_training set(除Task16的訓(xùn)練樣本集)和Tu_test set作為一個(gè)新的測(cè)試樣本集,記為Test samples4。從Test samples4中隨機(jī)抽取250個(gè)樣本作為Task16的測(cè)試樣本集。重復(fù)20次,然后得到MMD值、MMR值和多標(biāo)簽評(píng)價(jià)標(biāo)準(zhǔn)值。利用4-折交叉驗(yàn)證得到評(píng)價(jià)標(biāo)準(zhǔn)的估計(jì)值。評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)的實(shí)驗(yàn)結(jié)果如表4所示。
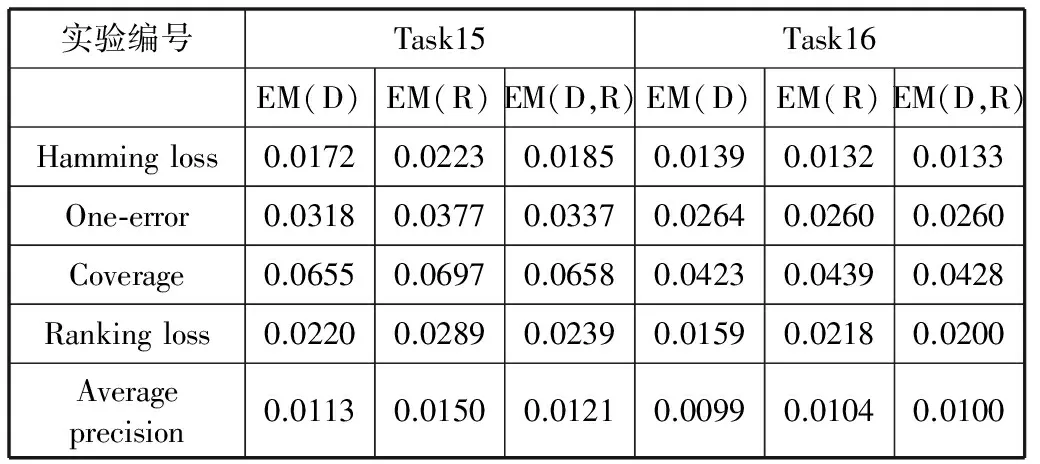
表4 Task15-Task16實(shí)驗(yàn)結(jié)果
表4得出的信息與表3得出的信息相同。針對(duì)不同的評(píng)價(jià)標(biāo)準(zhǔn),MMD和MMR的表現(xiàn)不同。其中,對(duì)于Hamming loss、One-error、Ranking loss和Average precision,MMD和MMR的表現(xiàn)良好;對(duì)于Coverage,MMD和MMR的表現(xiàn)要比其他評(píng)價(jià)標(biāo)準(zhǔn)差。綜合使用MMD和MMR估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的誤差均值一般在單獨(dú)使用MMD和MMR估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的誤差均值之間。訓(xùn)練樣本集和測(cè)試樣本集中的樣本數(shù)目越多,估計(jì)評(píng)價(jià)指標(biāo)的誤差均值越小。
通過上述實(shí)驗(yàn)結(jié)果可以看出,使用MMD線性估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)和使用MMR線性估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的效果良好。綜合使用MMD和MMR線性估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的效果良好。因此,使用這三種方法估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)是有一定意義的。MMD度量訓(xùn)練樣本集和測(cè)試樣本集之間的分布差異,MMR度量訓(xùn)練樣本集實(shí)例和測(cè)試樣本集實(shí)例之間的差異,與分類器無關(guān),因此適用于所有的分類器。但由于分類器的性能不同,評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)誤差會(huì)有一定的波動(dòng)。
5 結(jié) 語(yǔ)
目前并沒有專門針對(duì)多標(biāo)簽分類器評(píng)價(jià)標(biāo)準(zhǔn)進(jìn)行良好估計(jì)的方法。本文針對(duì)這一問題,提出多標(biāo)簽學(xué)習(xí)評(píng)價(jià)標(biāo)準(zhǔn)估計(jì)方法。從樣本分布差異得出MMD線性估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的方法,從樣本實(shí)例間差異得出MMR線性估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的方法。MMD著眼于兩組樣本的分布差異,是一個(gè)宏觀的統(tǒng)計(jì)量;MMR著眼于兩組樣本實(shí)例間的差異,是一個(gè)微觀的統(tǒng)計(jì)量。接著綜合使用MMD和MMR線性估計(jì)多標(biāo)簽分類器的評(píng)價(jià)標(biāo)準(zhǔn),其誤差均值在單獨(dú)使用MMD線性估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)和MMR線性估計(jì)評(píng)價(jià)標(biāo)準(zhǔn)的誤差均值之間。實(shí)驗(yàn)表明,這三種估計(jì)方法具有良好的效果,可用于遷移學(xué)習(xí)等。
[1] Zhang M L, Zhou Z H. ML-kNN:A lazy learning approach to multi-label learning [J]. Pattern Recognition, 2007,40(7):2038-2048.
[2] Xu X S, Jiang Y, Peng L, et al. Ensemble approach based on conditional random field for multi-label image and video annotation[C] // Proceedings of the 19th ACM International Conference on Multimedia, Scottsdale, USA, 2011:1377-1380.
[3] Wang J D, Zhao Y H, Wu X Q, et al. A transductive multi-label learning approach for video concept detection [J]. Pattern Recogintion,2011, 44(10-11):2274-2286.
[4] Nicolo C B, Claudio G, Luca Z. Hierarchical classification:combining Bayes with SVM [C] //Proceedings of the 23rd International Conference on Machine learning, Pittsburgh, USA, 2006:177-184.
[5] Li G Z, You M Y, Ge L, et al. Feature selection for semi-supervised multi-label learning with application to gene function analysis [C] //Proceedings of the 1st ACM International Conference on Bioinformatics and Computational Biology, Niagara Falls, USA, 2010:354-357.
[6] Sanden C, Zhang J Z. Enhancing multi-label music genre classification through ensemble techniques [C] //Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’ 11), Beijing,China, 2011:705-714.
[7] Zhang Y, Burner S, Street W N. Ensemble pruning via semi-definite programming [J]. Journal of Machine Learning Research, 2006,7(7):1315-1338.
[8] Tsoumakas G, Katakis I, Vlahavas I. Mining multi-label data[M]2nd ed. Data Mining and Knowledge Discovery Handbook, Springer, 2010:667-685.
[9] Grigorios T, Ioannis K. Multi-label classification:an overview [J]. International Journal of Data Warehousing and Mining, 2009,3(3):1-13.
[10] Zhang M L, Zhou Z H. A k-nearest neighbor based algorithm for multi-label classification [C] //Proceedings of the 2005 IEEE International Conference on Granular Computing. Beijing:IEEE, 2005,2:718-721.
[11] Elisseeff A, Weston J. A kernel method for multi-labelled classification [C] //Proceedings of the Advances in Neural Information Processing Systems. Cambridge:MIT Press,2002:681-687.
[12] Schapire R E, Singer Y. Improved boosting algorithm using confidence-rated predictions [J]. Machine Learning,1999,37(3):297-336.
[13] Schapire R E, Singer Y,Carbonell J,et al. BoosTexter:a boosting based system for text categorization [J]. Machine Learning,2000,39(2-3):135-168.
[14] Sebastiani F. Machine learning in automated text categorization[J]. ACM Computer Surveys, 2002,34 (1) :1-47.
[15] Alex S, Arthur G, Le S, et al. A hilbert space embedding for distributions[C] //Proceedings of the 18th International Conference on Algorithmic Learning Theory, 2007:13-31.
[16] Arthur G, Karsten M B, Malte R, et al. A kernel method for the two-sample-problem[C] //Proceedings of the Advances in Neural Information Processing Systems 19, 2007:513-520.
[17] 陳昊. 加權(quán)K-NN及其應(yīng)用[D].保定:河北大學(xué),2005.
ESTIMATING EVALUATION METRICS OF MULTI-LABEL CLASSIFIERS BASED ON SAMPLES DIFFERENCE
Zhang MinYu Shengbo
(Software Theory and Technology Chongqing Key Lab,College of Computer Science,Chongqing University,Chongqing 400044,China)
Evaluation metrics play an important role in classifiers.Popular evaluation metrics used in multi-label learning include Hamming loss,One-error,Coverage,Ranking loss and Average precision.While the classification results are obtained from multi-label classifier,the values of evaluation metrics will be derived later,usually the evaluation metrics are assessed in the way of checking afterwards.However this sometimes cannot find the problem of the variation in values of evaluation metrics timely and effectively,meanwhile it is necessary to mark the test samples when estimating the values of evaluation metrics.To solve this problem,this paper put forward two methods of estimating the evaluation metrics based on the difference in sample sets distribution and on the difference between instances in sample sets respectively.After analysing the characteristics of above two methods,we propose the third estimating method for evaluation metrics.Experiments show that the proposed three methods all have good effects.They can be used in transfer learning and others.
Multi-label learning Evaluation metricsSamples distributionSamples instancesLinear fitting
2015-04-22。中央高校基本科研業(yè)務(wù)費(fèi)專項(xiàng)資金項(xiàng)目(CDJZR12180005);重慶自然科學(xué)基金項(xiàng)目(CSTC2011BB2063)。張敏,講師,主研領(lǐng)域:機(jī)器學(xué)習(xí)。余圣波,碩士。
TP3
A
10.3969/j.issn.1000-386x.2016.09.064
猜你喜歡
城市道橋與防洪(2022年4期)2022-07-01 06:04:12
音樂探索(2022年2期)2022-05-30 21:01:37
石油瀝青(2021年4期)2021-10-14 08:50:44
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2019年8期)2019-08-27 02:23:00
當(dāng)代陜西(2019年8期)2019-05-09 02:22:48
動(dòng)漫星空(興趣百科)(2019年3期)2019-03-07 07:23:10
小學(xué)科學(xué)(學(xué)生版)(2018年7期)2018-08-13 09:33:04
專用汽車(2016年4期)2016-03-01 04:13:43
中國(guó)教育技術(shù)裝備(2015年19期)2015-03-01 02:43:07
鄭州大學(xué)學(xué)報(bào)(醫(yī)學(xué)版)(2015年2期)2015-02-27 14:50:46

- 計(jì)算機(jī)應(yīng)用與軟件的其它文章
- 基于權(quán)限組合的Android竊取隱私惡意應(yīng)用檢測(cè)方法
- 基于測(cè)試代價(jià)敏感的不完備決策系統(tǒng)屬性約簡(jiǎn)算法
- 面向以太網(wǎng)的網(wǎng)絡(luò)故障自動(dòng)實(shí)時(shí)發(fā)現(xiàn)與定位方法
- 臺(tái)站級(jí)地面氣象觀測(cè)數(shù)據(jù)綜合質(zhì)控系統(tǒng)設(shè)計(jì)
- B2C電子商務(wù)信息系統(tǒng)操作風(fēng)險(xiǎn)評(píng)估方法研究
- 一種新的基于混沌的彩色圖像加密算法