融合底層和中層字典特征的行人重識別
2016-10-26 05:21:12王麗
中國光學 2016年5期
王 麗
(吉林省送變電工程公司 工程技術部, 吉林 長春 130033)
?
融合底層和中層字典特征的行人重識別
王麗
(吉林省送變電工程公司 工程技術部, 吉林 長春 130033)
針對當前行人重識別方法采用單一底層特征識別率較低的問題,提出一種融合底層和中層特征的識別方法,由粗到精對人體目標進行匹配識別。首先提取目標的顏色直方圖和紋理直方圖進行粗分類;然后將人體目標分為頭部、軀干和腿部3個部分。忽略包含信息量較少的頭部,對軀干和腿部,提出一種中層圖像塊字典提取方法,并對照該字典生成中層特征,進行精確分類。底層特征結合中層特征使算法既具有較好的區分度,又具有良好的泛化能力。實驗結果表明本文算法在VIPeR數據庫上的nAUC比已有方法提高6.3%,對遮擋和背景粘連的魯棒性更好。
行人重識別;顏色直方圖;紋理特征;中層特征;聚類
1 引 言
行人重識別是指給定一張行人圖片,從不同位置、時間和視場下拍攝的海量行人數據庫中,搜索同一行人的過程,可用于犯罪嫌疑人搜索、視頻監控、多目標跟蹤等領域[1]。行人重識別由于提出時間較短,目前尚不具備完整的理論和統一的框架,面臨著諸多問題,例如:由于成像距離較遠,傳統的人臉和步態識別技術難以應用;同一行人圖片受視角、光照、姿態、遮擋、背景變化等影響差異較大,單特征難以獲得較好的區分效果;不同行人衣著可能非常相似等。
近年來,學者們提出了眾多行人重識別算法。2007年,Wang等人[2]將行人進行分割,提取不同區域的Log-RGB梯度直方圖和顏色空間關系進行識別;2010年,Farenzena等人[3]根據對稱性將人體前景劃分為頭部、軀干、腿部3個部分,并提取各部分的HSV顏色直方圖、最大穩定顏色區域特征和高重復結構特征加權進行識別;2011年,Cheng等人[4]使用圖形算法定位人體的頭、胸、腰、腿4個區域位置,并提取顏色直方圖和最大穩定顏色區域特征;2012年,Kostinger等人[5]將HSV顏色直方圖、RGB顏色直方圖和圖像塊LBP特征進行組合,并使用PCA降維得到最后的特征;同年,Ma等人[6]提取圖像的亮度和梯度信息并使用Fisher向量編碼;2013年,Zheng等人[7]將圖像進行水平分塊,隨后提取每個小塊的HSV、RGB、YCbCr顏色直方圖和Schimidt、Gabor紋理特征進行識別。
現有算法都是通過利用不同的底層特征(例如SIFT[8]、SURF[9]、LBP[10]、Garbor特征[11]、局部紋理[12]等),達到識別行人的目的。底層特征構造的難點在于不同圖片中行人的表征隨視角、光照、遮擋、行人姿態等發生很大變化,很難設計出對所有圖片均適用的特征,而穩健的組合特征往往計算復雜度較高,在大數據庫中搜索效率較低。因此,現有算法往往難以適應不同的數據庫,識別效果也很難進一步提升。
考慮到構造底層特征的局限性,本文提出一種將底層特征與中層特征相結合的行人重識別方法。該方法提取人體的空間顏色直方圖、SIFT直方圖作為底層特征,建立粗略的外觀模型進行初步篩選,再通過訓練,提取不同部位的具有良好區分性和泛化能力的中層特征,用于精確分類。將兩個分類器級聯融合,能提高算法對于視角、遮擋和光照的穩健性。實驗證明本文算法能獲得更高的匹配率。
2 底層特征提取
行人重識別中,常用的底層特征包括顏色特征和紋理特征。由于其信息互補,考慮將二者進行融合。
2.1顏色空間特征
顏色特征由于能夠體現目標區域的整體統計信息,對形狀變化穩健性較好而被行人重識別算法廣泛采用。但是,傳統算法采用的顏色直方圖忽略了顏色的空間分布,分辨能力較差。因此本文使用二階空間直方圖以保留顏色特征的空間信息[13]。
圖像I的二階空間直方圖表示為:
(1)
式中,B為量化級數,nb為圖像的量化直方圖,μb和εb分別為均值矢量和協方差矩陣,計算公式為:
(2)
(3)
(4)
(5)
式中,N是圖像總像素個數;δkb標識像素k是否落在量化級數b內;xk是像素二維坐標。
兩個空間直方圖(SA,SB)的相似性可以計算如下:
(6)
式中,ρn(nb,A,nb,B)為兩個直方圖的Bhattacharyya距離,Ψb稱為空間-相似性,計算公式為:
(7)
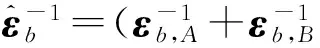
2.2紋理特征
不同行人衣著有可能相似,僅僅依靠顏色特征易造成誤匹配,因此需要提取能夠描述局部細節的紋理特征進行精確區分。由于SIFT特征在目標發生旋轉、縮放、仿射變換時具有良好的不變性,本文考慮采用SIFT提取目標的紋理特征,步驟如下:
(1)對匹配目標和待識別目標分別在H、S、V通道上提取SIFT特征;
(2)對于匹配目標每個通道的SIFT特征進行K-means聚類,生成kH、kS、kV個聚類中心,構成視覺詞典;
(3)將所有待識別目標的SIFT特征映射到對應關鍵詞上,統計每個關鍵詞出現的次數,歸一化生成kH+kS+kV維的紋理直方圖HT。
兩個紋理直方圖HTA和HTB用Bhattacharyya距離衡量相似度:
(8)
式中,HT(i)表示HT的第i個分量。
3 中層特征
中層特征提取方法是近年來提出的一種目標描述方法,已被用于場景分類、運動識別[14-15]等領域。為使提取的特征具備視角不變性,同時考慮到人體各個部位的區分,本文提出一種新的中層特征提取方法。
3.1圖像塊篩選
為了區分人體的不同部位,將行人圖像按水平方向分成頭部、軀干和腿部,三部分的高度分別占人體總高度的16%、29%和55%,如圖1所示。從圖中可以看出,用這種簡單的方式能夠較為準確地將行人身體部位劃分出來。由于傳感器分辨率限制,頭部不包含足夠有效的信息,將其忽略。
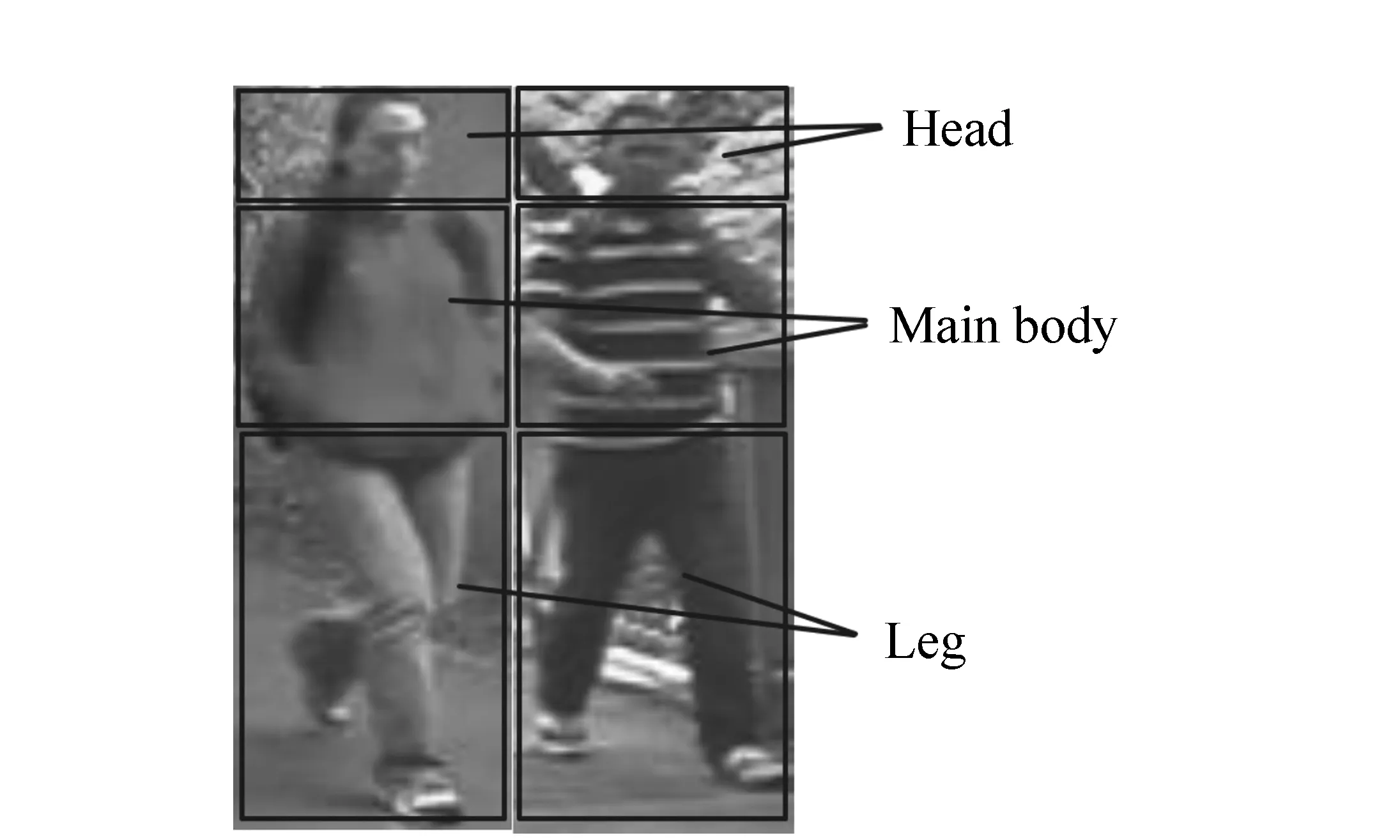
圖1 行人不同部位劃分 Fig.1 Segmentation of different body parts
下面討論如何提取軀干部分的圖像塊,腿部的圖像塊同理可得。
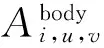
(9)
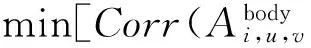
(10)
實驗中取Nr=0.5 V,Cmin=0.5,Cmax=0.8。這樣從一個攝像機中篩選出來的圖像塊在另一個攝像機中出現的概率既不會太大也不會太小,既有一定的泛化能力,又有一定的區分性。
3.2圖像塊聚類
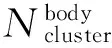
3.3生成中層特征向量
(11)
式中,bi、lj分別為對應軀干、腿部中層特征關鍵詞出現的頻次。將fmid進行歸一化,得:
(12)
中層特征之間的相似性可由歐氏距離計算。
4 特征組合
首先使用空間顏色直方圖和紋理直方圖對行人目標進行粗識別,隨后使用中層特征對其進行精確分類,最后將識別結果融合,目標Ai和Bj之間的相似性為:
(13)
式中,ρcolor、ρtexture、ρmid分別為兩個目標的空間顏色混合高斯模型、紋理直方圖、中層特征的相似性,ω1、ω2、ω3是特征權重,ω1+ω2+ω3=1。實驗中取ω1=ω2=0.3,ω3=0.4。
5 實 驗
為驗證算法有效性,采用VIPeR和ETHZ兩類數據庫進行實驗。采用累計匹配特性曲線[8](CMC,Cumulative Matching Curve)來評價重識別算法的性能,CMC曲線下的歸一化累計面積nAUC(normalized Area Under CMC)能描繪CMC曲線的整體走勢和性能。
5.1VIPeR數據庫實驗結果
VIPeR中包含不同場景下的632對行人圖片,圖片大小都被歸整為48 pixel×128 pixel。對比算法選擇目前效果較好的SDALF[3]、ELF[17]和SCEAF[18]算法,采用與ELF算法相同的五輪二折驗證法,即總共進行5次實驗,每次將632對目標隨機均分,并在測試時交換匹配圖像和待識別圖像,一共得到10組識別結果,最后取其平均值作為最終的評判依據,統計得到的識別結果如圖2所示。
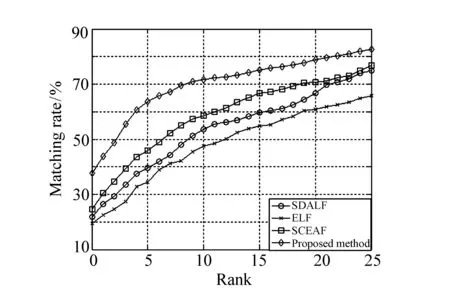
圖2 VIPeR圖庫上匹配結果 Fig.2 Matching result in VIPeR database
從圖2可以看出,本文算法相比SDALF、ELF和SCEAF具有更高的匹配率。圖2中第1列表示第1匹配率CMC(1),SDALF、ELF和SCEAF分別為21.8%、19.4%、24.6%,而本文算法達到37.8%,這是因為本文算法融合了底層顏色特征、底層紋理特征和中層特征,由粗到精地進行分類,包含了目標圖像的更多信息。而SDALF算法使用了HSV顏色直方圖、最大穩定顏色區域和高重復結構,ELF使用一組簡單特征組合構建分類模型,SCEAF融合結構信息和多個紋理特征,這3種算法本質上都使用的是局部特征,泛化能力不強。隨著排名等級的增加,4種算法的識別率均呈上升趨勢,本文算法始終高于其余3種算法。統計算法的rank-1、rank-10、rank-20、rank-30(即在待搜索目標庫中相似度為前1、10、20和30的目標中找到正確目標的概率)和nAUC,如表1所示,也證明了圖2趨勢的正確性。在VIPeR數據庫中,算法的nAUC高達91.7%,遠高于其余3種算法。

表1 算法排名等級和nAUC對比
5.2ETHZ數據庫實驗結果
ETHZ為多幀數據庫,各幀之間存在較嚴重的光照和遮擋,但是姿態變化較小,更接近于實際應用中的相機連續曝光情況。
對比算法采用SDALF與PLS[13]。比較待識別目標為1幀,而候選目標分別為2、5、10幀的結果,如圖3所示。
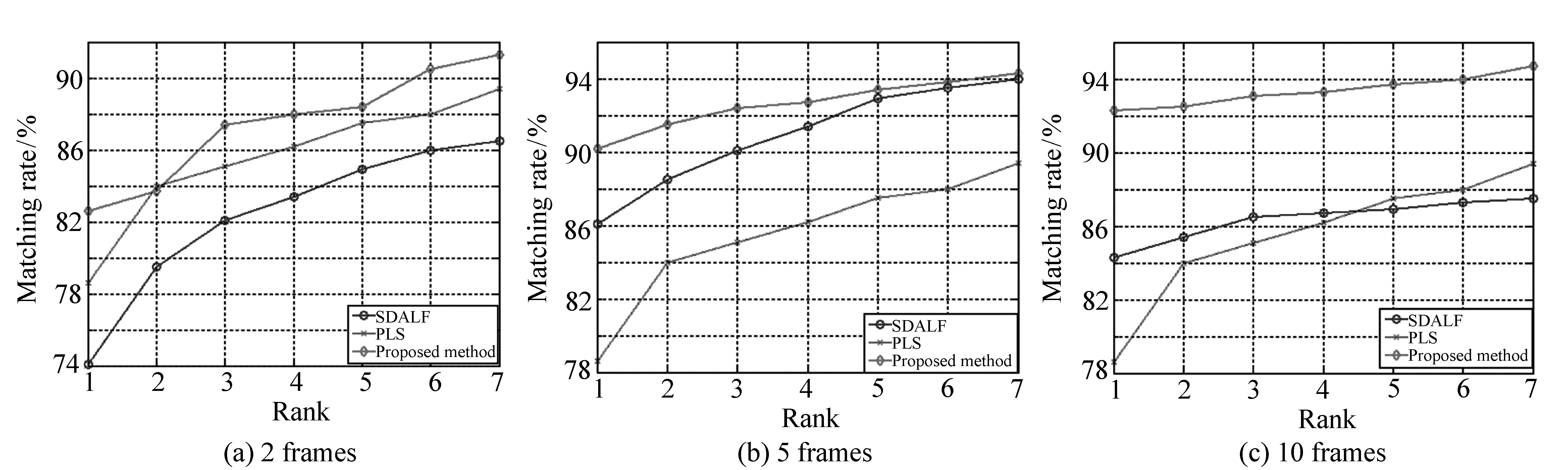
圖3 ETHZ數據庫上多幀匹配結果 Fig.3 Multi-frame matching rate in ETHZ database
比較圖3(a)、3(b)、3(c)內部的3條曲線,當候選目標分別為2、5、10幀時,本文算法識別率均優于其余3種算法,并且曲線趨勢與單幀數據庫相同。通過圖3(a)、3(b)、3(c)之間橫向對比,隨著候選目標的增加,PLS算法的識別率無變化,SDALF算法在候選目標5幀時識別率最高,在10幀的識別率反而低于5幀,而本文算法的識別率隨著候選目標的增加而提升較大。這是因為本文算法融合了不同尺度下的特征,具有較好的穩定性。因此,本文算法不僅適用于單幀目標圖像庫,更適用于多幀圖像庫。
6 結 論
考慮到底層特征的構造難度和局限性較大,難以滿足行人重識別的需求,本文提出了融合底層特征和中層特征的行人重識別方法。首先引入空間顏色直方圖,對目標的顏色空間信息建模,并提取目標的SIFT紋理特征進行粗識別。隨后提出一種區分不同人體部位圖像塊的中層特征訓練和提取方法。融合上述底層特征和中層特征,對行人圖像進行識別。實驗表明本文算法在單幀和多幀數據庫中均能取得良好的識別性能,低位匹配率遠高于現有算法,具有較好的應用前景。下一步工作將研究如何更加精確地劃分人體不同部位,以及將中層特征與距離度量算法相結合,使其具有更好的區分度。
[1]GONG S,CRISTANI M,YAN S,etal..PersonRe-identification[M]. London:Springer,2014.
[2]WANG X,DORETTO G,SEBASTIAN T B,etal.. Shape and appearance context modeling[J].IEEE,2007,1(1):1-8.
[3]ARENZENA M,BAZZANI L,PERINA A,etal.. Person re-identification by symmetry-driven accumulation of local features[C]. IEEE Conference on Computer Vision and Pattern Recognition,San Francisco,USA,2010:2360-2367.
[4]CHENG D,CRISTANI M,STOPPA M,etal.. Custom pictorial structures for re-identification[C]. British Machine Vision Conference,Dundee,UK,2011:749-760.
[5]KOSTINGER M,HIRZER M,WOHLHART P,etal.. Large scale metric learning from equivalence constraints[C]. IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2012:2288-2295.
[6]MA B,SU Y,JURIE F. Local descriptors encoded by fisher vectors for person re-identification[C]. European Conference on Computer Vision,Florence,Italy,2012:413-422.
[7]ZHENG W,GONG S,XIANG T. Re-identification by Relative Distance Comparison[J].IEEE,2013,35(3):653-668.
[8]王睿,朱正丹.融合全局-顏色信息的尺度不變特征變換[J].光學 精密工程,2015,23(1): 295-301.
WANG R,ZHU ZH D. SIFT matching with color invariant characteristics and global context[J].Opt.PrecisionEng.,2015,23(1):295-301.(in Chinese)
[9]王飛宇,邸男,賈平.結合尺度空間FAST角點檢測器和SURF描繪器的圖像特征[J].液晶與顯示,2014,29(4):598-604.
WANG F Y,DI N,JIA P. Image features using scale-space FAST corner detector and SURF descriptor[J].ChineseJ.LiquidCrystalsandDisplays,2014,29(4):598-604.(in Chinese)
[10]王曉華,孫小姣.聯合Gabor降維特征與奇異值特征的人臉識別[J].光學 精密工程,2015,23(10):553-558.
WANG X H,SUN X J. Face recognition based on Gabor reduction dimensionality features and singular value decomposition features[J].Opt.PrecisionEng.,2015,23(10):553-558.(in Chinese)
[11]鄧丹,吳謹,朱磊,等.基于紋理抑制和連續分布估計的顯著性目標檢測方法[J].液晶與顯示,2015,30(1):120-125.
DENG D,WU J,ZHU L,etal. Significant target detection method based on texture inhibition and continuous distribution estimation[J].ChineseJ.LiquidCrystalsandDisplays,2015,30(1):120-125.(in Chinese)
[12]BIRCHFIELD S T,RANGARAJAN S. Spatiograms versus histograms for region-based tracking[J].IEEE,2005(2):1158-1163.
[13]SINGH S,GUPTA A,EFROS A A. Unsupervised discovery of mid-level discriminative patches[C]. European Conference on Computer Vision,Florence,Italy,2012:73-86.
[14]JAIN A,GUPTA A,RODRIGUEZ M,etal.. Representing videos using mid-level discriminative patches[C]. IEEE Conference on Computer Vision and Pattern Recognition,IEEE,2013:571-2578.
[15]陳瑩,朱明,劉劍,等.高斯混合模型自適應微光圖像增強[J].液晶與顯示,2015,30(2):300-309.
CHEN Y,ZHU M,LIU J,etal.. Automatic low light level image enhancement using Gaussian mixture modeling[J].ChineseJ.LiquidCrystalsandDisplays,2015,30(2):300-309.(in Chinese)
[16]GRAY D,TAO H. Viewpoint invariant pedestrian recognition with an ensemble of localized features[C]. European Conference on Computer Vision,Florence,Marseille,Italy,2008:262-275.
[17]HU Y,LIAO S,LEI Z,etal.. Exploring structural information and fusing multiple features for person re-identification[C]. IEEE Computer Society Conference on Computer Vision and Pattern Recognition,Portland,USA,2013:794-799.
[18]SCHWARTZ W,DAVIS L. Learning discriminative appearance based models using partial least squares[C]. Computer Graphics and Image Processing,Rio de Janeiro,Brazil,2009:322-329.
Pedestrian re-identification based on fusing low-level and mid-level features
WANG Li
(Engineering and Technology Department,Jilin Transmission and TransformationEngineeringCompany,Changchun130033,China)*Correspondingauthor,E-mail:44417020@qq.com
Aiming at the problem of low recognition rate in the existing pedestrian re-identification algorithm using single low-level feature, a new method by fusing low-level and mid-level features is proposed, which identifies person in a coarse to fine strategy. First, the pedestrian is recognized roughly by color and texture features. Then, the human body is divided into three parts, including head, main body and leg. Head is ignored for its few useful information. A mid-level dictionary method is proposed and the dictionary is trained using patches from main body and leg, and then mid-level feature is computed for fine recognition. Fusing mid-level and low-level features can be not only discriminative but also representative. The experimental results indicate that the proposed method can increase nAUC by 6.3% compared with the existing methods, which is more robust to occlusion and background adhesion.
pedestrian re-identification;color histogram;texture features;mid-level features;clustering
2016-04-05;
2016-05-26
2095-1531(2016)05-0540-07
TP394.1
Adoi:10.3788/CO.20160905.0540

王麗(1979—),女,吉林長春人,學士,工程師,主要從事信息通信技術方面的研究。E-mail:44417020@qq.com
