基于半監督DPMM的新聞話題檢測
2016-10-26 02:32:59姚冬冬
鄭州大學學報(理學版) 2016年3期
姚冬冬 , 袁 方 , 王 煜, 劉 宇
(1.河北大學 計算機科學與技術學院 河北 保定 071000; 2.河北大學 計算機教學部河北 保定 071000; 3.河北大學 數學與信息科學學院 河北 保定 071000)
?
基于半監督DPMM的新聞話題檢測
姚冬冬1,袁方2,3,王煜1,劉宇3
(1.河北大學 計算機科學與技術學院河北 保定 071000; 2.河北大學 計算機教學部河北 保定 071000; 3.河北大學 數學與信息科學學院河北 保定 071000)
基于狄利克雷過程混合模型(DPMM)這一非參數貝葉斯生成模型,從語義的角度入手,結合其自動確定聚類個數的特性進行話題檢測,運用了聚類個數K值由大到小變化的采樣策略,通過逐層遞進的形式獲取到較為準確的K值,并在此基礎上對語義聚類的詞頻特性加以分析,引入一組名詞實體作為“熱點特征詞”來引導聚類過程,從而給出了DPMM半監督模型.實驗結果表明,所給出的話題檢測方法在TDT4語料上取得了較好的檢測性能.
話題檢測; 狄利克雷過程; Gibbs采樣; 冪律特性; 名詞實體
0 引言
隨著互聯網的快速發展和移動媒體的廣泛普及,網絡成為人們獲取信息的重要途徑之一,如何有效地從雜亂的數據中獲取話題信息一直是文本挖掘領域的研究熱點.話題檢測與追蹤(topic detection and tracking, TDT)[1]最早由美國國防部高級研究計劃署在1996年提出,其目的在于利用當時的技術發現和追蹤新聞廣播流中的新事件.在多家機構的共同努力下,TDT的研究內容和評測體系被正式確立并取得長足發展.話題檢測是TDT中至關重要的環節,近些年的相關研究包括聚類算法的融合[2]、相似度的組合[3]、名詞實體的引入[4]、主題模型的使用[5]等,并擴展至其他相關領域[6].
狄利克雷過程混合模型(Dirichlet process mixture models, DPMM)[7]作為非參數貝葉斯領域的基礎模型,是一種定義在無限維參數空間上的貝葉斯模型.文獻[8]通過引入一定的先驗知識將DPMM應用于動詞語義聚類.文獻[9]綜述了DPMM、擴展模型及其在機器學習等領域的應用.文獻[10]將其引入到話題識別研究中,利用DPMM的特點解決話題識別任務中的參數設置問題.文獻[11]通過改進空間約束使得DPMM在圖像處理上更加簡單便捷.應用于TDT工作時,DPMM與潛在狄利克雷分配模型(latent Dirichlet allocation, LDA)[12]一樣,是一種具有文本主題表示能力的模型,在彌補VSM沒有考慮詞與詞之間語義聯系這一缺點的同時,也可以用來解決LDA模型存在的主題數目需要指定的問題,為聚類分析中K值確定這一基礎性問題提供了解決方案,減輕了人工實驗的負擔.
本文在研究分析DPMM模型的基礎上,對DPMM 模型進行了兩個方面的改進:一是借鑒深度學習的基本思想,獲取到較為準確的K值;二是分析語義聚類的詞頻特性,從詞性和名詞實體兩個角度改進模型初始狀態,引入的“熱點特征詞”給出了DPMM半監督模型.實驗結果表明,改進后的DPMM模型具有更好的話題檢測性能.
1 DPMM模型研究
伴隨著語義分析在話題研究中的應用,主題模型將主題的概念引入到了話題研究之中.對于LDA等主題模型而言,文檔是由若干隱性主題混合而成,而主題則需要借助詞匯來描述.本節首先著重研究了狄利克雷過程及其構造方法,其次是深入分析采樣公式,更加合理地將模型應用在話題檢測之中.
1.1狄利克雷過程
狄利克雷過程(Dirichlet process, DP)[13]是狄利克雷分布在連續空間上的擴展,和狄利克雷分布一樣具有共軛性[14].中國餐館過程[15]是指一個新的顧客坐在已有餐桌的概率與該餐桌上人數nc成正比,坐在新餐桌上的概率與參數α相關,當此過程趨于無窮時,類簇個數最終會趨于一個平穩值,具體表示如公式(1)所示.它是一種常見的直觀的DPMM描述方法,因此本文利用中國餐館過程對DP進行構造.
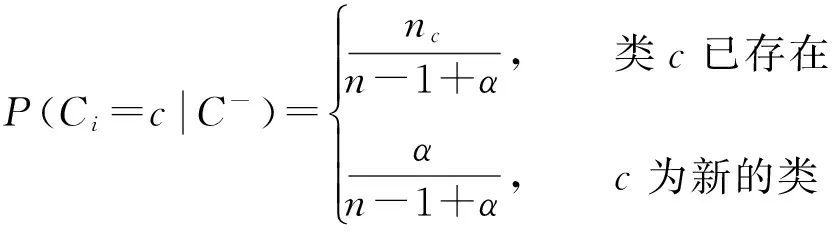
(1)
1.2DPMM模型
假設一組樣本服從某種分布,分布的參數服從狄利克雷過程先驗分布,參數的先驗和后驗分布采用狄利克雷過程構造方法推斷,則該模型稱為狄利克雷過程混合模型(DPMM)[10].鑒于狄利克雷過程的構造是概率和為1的離散分布,模型可以認為是可數的無限混合[16].
將DPMM引入到話題分析領域則可以構建如圖1所示的生成模型[11],其中α和β為模型的超參數,θ和φ分別代表主題分布和詞分布,z代表一個主題,w代表一個詞.生成一個詞的過程包括從一篇文檔的主題分布中生成一個主題,然后從這個主題的詞分布中生成一個詞的兩部分,m篇文檔對應于m個獨立的狄利克雷過程.這里的生成過程同LDA模型類似,區別在于生成主題的過程中,DPMM模型的主題數目K并不會預先指定,而會隨著迭代過程變化修正.

圖1 DPMM模型Fig.1 DPMM model
后驗計算方法一般采用積分的方式進行,考慮到模型的復雜程度,本文采用基于馬爾科夫鏈蒙特卡羅(Markov chain Monte Carlo, MCMC)的吉布斯采樣(Gibbs sampling)算法,根據貝葉斯理論可得采樣公式(2).

(2)
公式(2)的第一部分代表生成主題的概率,可以用中國餐館過程來構造.本文根據文獻[11,16-17]完善公式(1)得到公式(3),更加合理地將其應用在話題模型之中,

(3)
其中:nm,z代表文檔m中屬于主題z的詞的個數,nm代表文檔m中的詞的總個數,此處可以簡單理解為用主題將文檔進行了劃分,并且主題數目可變.
公式(2)的第二部分代表生成詞的概率,是從一個已知主題中生成一個詞,這其中的基本單位是該主題,包括該主題中的所有詞,不存在可變的因素,所以同LDA模型一樣,此處通常選取狄利克雷-多項式共軛過程,根據文獻[18]可得
(4)
綜合文獻[11]、公式(4)和文獻[17]給出的詞分布公式,可得

(5)
2 基于改進K值的半監督模型
依據DP的特性和TDT研究的前提,本文中將主題與話題的概念等同,K值并非是類似于LDA中的主題個數而是聚類個數,并在此基礎上從優化聚類個數K和改善聚類結果兩個角度進行了相應改進.
2.1DPMM模型的K值改進
DPMM模型為聚類個數K值確定這一基礎性問題提供了解決方案,但鑒于話題結構的復雜性,自動確定的K值也必然存在一定的準確性問題,因此如何獲取較為準確的K值是本文的研究重點.
由于語義分析的結果與類簇中語義信息量的大小有直接關系,因此,在采樣策略的選擇上,本文選取了聚類個數K值由大到小的變化方式,將初始K值設置為報道個數M,采樣過程中K值逐漸減小.變化的整體流程如算法1所示.具體過程是Gibbs采樣先將每篇報道中的各詞隨機分配到K個主題中,每次迭代依據采樣公式對各詞重新分配主題.在迭代過程中,如果某主題中詞數為0則去掉該主題,對應K值減1;如果某詞不屬于現有主題,則將其分配到新的主題,對應K值加1,收斂或達到迭代次數即終止采樣.
在一輪Gibbs采樣收斂之后,數據顯示最終的聚類個數K距離樣本中話題個數有一定差距,聚類個數大于話題個數意味著將較大話題進行了拆分.由于不同話題的報道數量并不均勻,數據往往具有較大的不平衡性,因此需要優先考慮大話題即熱點話題的聚類性能,適當增加初始類簇的語義信息量,減少初始K值的個數.本文采用了逐層遞進的形式來獲取較為理想的K值,即重復進行多輪采樣,下一輪采樣的初始K值設置為上一輪采樣結束后得到的K值,具體描述見算法1.當K值上下浮動在2以內時,則認為其近似穩定.實驗結果表明,K值在幾輪采樣后會趨于穩定.

算法1 改進K值的采樣算法輸入:報道集合D,初始類數M,分布參數α、β.輸出:主題數目K,主題集合Φ.步驟:1WHILEK值不穩定DO2隨機初始化:為每篇文檔中的每個詞w,隨機賦一個topic編號z∈(0,K-1).3掃描語料庫,按照公式(2)、(3)和(5)重新采樣每個詞w的topic編號z,K值變化.4重復步驟3,直到采樣收斂,得到新主題數目K,新主題集合Φ.5ENDWHILE6RETURNK,Φ.
2.2DPMM半監督模型構建
由于采樣時初始的詞語分配是隨機分配到各個主題,在相同條件下進行DPMM聚類實驗得到的實驗結果不盡相同.由于動詞和名詞對新聞話題的表達貢獻程度較大,本文考慮首先去掉語料中除動詞、名詞以外的其他詞語,用較少更具代表性的詞語來代表報道.
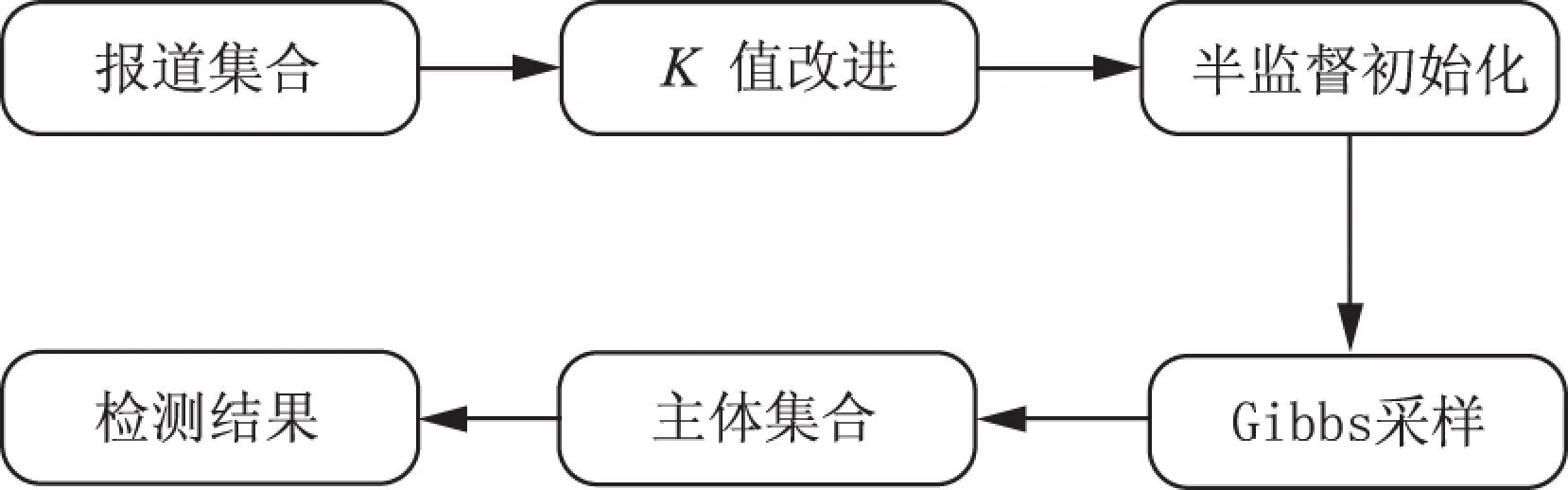
圖2 半監督模型過程Fig.2 Process of semi-supervised model
根據Zipf定律,文檔的詞頻分布符合冪律分布,在語義分析中這種冪律分布將導致大量的低頻詞受少量高頻詞的主題分布的影響[19].本文參考文獻[8]的Cannot-link思想和文獻[20]中成對約束信息的融入操作,在聚類的基礎上加上少量先驗知識,通過統計詞頻和人工分析的方式篩選出一組由人名、地名和組織名構成的名詞實體作為“熱點特征詞”.組內各詞在采樣初始分配時不出現在同一個類中,而相同名詞則聚集在一起,構建了DPMM半監督模型,所作改進并沒有破壞DPMM模型的聚類特性.半監督模型的過程如圖2所示,具體描述見算法2.

算法2 半監督模型構建算法
3 實驗
為了驗證所給方法的有效性,本節采用TDT4語料庫中的中文新聞語料進行實驗,對同一篇報道歸屬于兩個話題的情況進行了去重操作,并根據實際需要,去掉了包含報道少于10篇的話題,采用具有較高普遍性的F值評測方法,進行了第2節中提到的K值改進和半監督兩個方面的實驗,并就實驗結果進行了相關分析和比較.
3.1評測標準
F-measure評測方法[21]綜合了信息檢索中查準率(precision)與查全率(recall)的思想來進行聚類評價.一個分類i與相關聚類j的查準率P、查全率R和F值的定義為
P=preciseon(i,j)=(Nij/Nj);R=recall(i,j)=Nij/Ni;F(i)=2PR/(P+R),
(6)
其中:Ni表示分類i中的樣例個數,Nj表示聚類j中的樣例個數,Nij表示分類i與聚類j共有的樣例個數.對分類i而言,取具有最大F值的聚類j作為其最終的關聯聚類.因此對聚類結果來說,其總F值可由每個分類i的F值加權平均得到,

(7)
3.2K值改進實驗
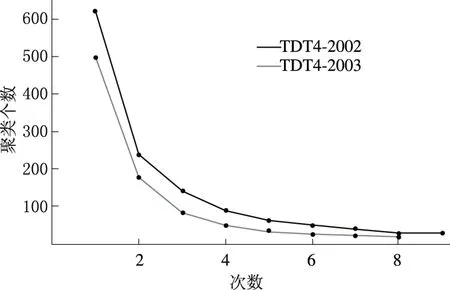
圖3 聚類個數與遞進次數的關系Fig.3 Relationship between cluster numbers and progressive times
為了充分發揮DPMM模型自主確定聚類個數K值的優勢,本實驗采用第2.1節中提到的遞進方式來獲得較為準確的K值,在DPMM無監督模式下進行,每輪采用的K值為多次實驗的均值.具體如圖3所示,聚類個數K隨遞進次數的增加呈下降趨勢,對應于TDT4-2002和TDT4-2003的最終K值分別穩定在30和20左右,與已標注的話題個數較為接近.
3.3DPMM半監督實驗
本實驗首先去掉了語料中除動名詞以外的其他詞匯,適當弱化了不同報道之間的相似性;其次在先驗知識的選擇方面,本文以詞頻統計結果為依據,選擇以地名為主、人名為輔的部分名詞實體作為“熱點特征詞”來實現2.2節中所描述的操作,如表1所示,進而采用改進K值后的DPMM半監督模型來進行實驗,并在相同語料上與DPMM基本模型、改進K值后的基本模型進行對比.

表1 熱點特征詞列表Tab.1 Hot key words list
表2列出了50次實驗的平均值和最高值,DPMM表示基礎模型,DPMM-K表示改進K值的模型,DPMM-S表示半監督模型.由于這3種方法在初始化時都存在較大的隨機成分,因此其性能都不能簡單地用平均F值來表示,而最大F值能夠體現出模型的最佳潛能.從表2中不難看出單純依靠DPMM模型無法實現較好的聚類效果,改進K值后的模型實驗效果有所提升,而半監督模型在自動確定聚類個數的同時顯著提高了模型的性能,有效保證了熱點話題的檢測結果.結合語料的構成對比TDT4-2002和TDT4-2003可知,基于語義分析的DPMM模型性能受語義信息量的影響,TDT4-2002中包含的話題和報道個數都要大于TDT4-2003,因此在性能上略有下降.
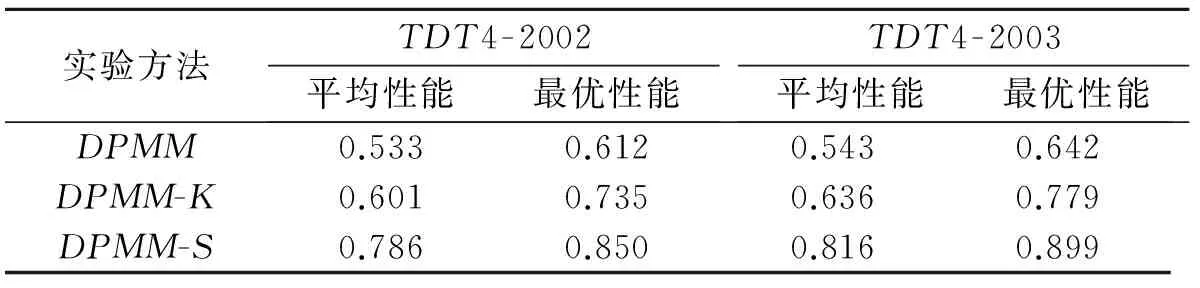
表2 不同方法的F值比較Tab.2 F value comparison of different methods
4 結束語
本文在DPMM模型的基礎上,完善了中國餐館過程在模型中的運用,采用了K值由大到小變化的采樣策略,并結合深度學習的思想使模型自動確定的K值更為準確.通過分析聚類結果,得出了聚類結果在一定程度上受初始語料的影響,并做了相應的研究和改進.本文提出的半監督模型,通過加入一定的先驗知識,使得模型的話題檢測性能有了顯著的提高.在接下來的工作中,應繼續優化模型,進一步研究增加報道間區分度的方法和識別小話題的方法,使得模型更為可行.同時,增大實驗的數據量,豐富語料庫,在TDT標準語料的基礎上,結合各大權威新聞網站的新聞報道,使理論算法更具有實際意義.
[1]洪宇, 張宇, 劉挺, 等. 話題檢測與跟蹤的評測及研究綜述[J]. 中文信息學報, 2007, 21(6): 71-87.
[2]李勝東, 呂學強, 施水才, 等. 基于話題檢測的自適應增量K-means算法[J]. 中文信息學報, 2014, 28(6): 190-193.
[3]周剛, 鄒鴻程, 熊小兵, 等.MB-SinglePass:基于組合相似度的微博話題檢測[J]. 計算機科學, 2012, 39(10): 198-202.[4]張曉艷. 新聞話題表示模型和關聯追蹤技術研究[D]. 長沙: 國防科學技術大學, 2010.
[5]GUOX,XIANGY,CHENQ,etal.LDA-basedonlinetopicdetectionusingtensorfactorization[J].Journalofinformationscience, 2013, 39(4): 459-469.
[6]潘云仙, 袁方. 基于JST模型的新聞文本的情感分類研究[J]. 鄭州大學學報(理學版), 2015, 47(1): 64-68.
[7]ANTONIAKCE.MixtureofDirichletprocesseswithapplicationstoBayesiannonparametricproblems[J].Annalsofstatistics, 1974, 2(6): 1152-1174.
[8]VLACHOSA,GHAHRAMANIZ,KORHONENA.Dirichletprocessmixturemodelsforverbclustering[C]//Icmlworkshoponpriorknowledgefortext&languageprocessing.Helsinki, 2008: 74-82.
[9]梅素玉, 王飛, 周水庚. 狄利克雷過程混合模型、擴展模型及應用[J]. 科學通報, 2012, 57(34): 3243-3257.
[10]王嬋. 基于Dirichlet過程混合模型的話題識別與追蹤[D]. 北京: 北京郵電大學, 2013.
[11]ZHANGH,JONATHANWQM,NGUYENTM.ImagesegmentationbyDirichletprocessmixturemodelwithgeneralisedmean[J].Ietimageprocessing, 2014, 8(8):103-111.
[12]BLEIDM,NGAY,JORDANMI.LatentDirichletallocation[J].Journalofmachinelearningresearch, 2003, (3): 993-1022.[13]FERGUSONTS.ABayesiananalysisofsomenonparametricproblems[J].Annalsofstatistics, 1973, 1(2): 209-230.
[14]徐謙, 周俊生, 陳家俊.Dirichlet過程及其在自然語言處理中的應用[J]. 中文信息學報, 2009, 23(5): 25-32.
[15]PITMANJ.Combinatorialstochasticprocesses[M].Springer,Berlin, 2006: 75-92.
[16]NEALRM.MarkovchainsamplingmethodsforDirichletprocessmixturemodels[J].JournalofcomputationalandgraphicalStatistics, 2000, 9(2): 249-265.
[17]SATOI,NAKAGAWAH.Topicmodelswithpower-lawusingPitman-Yorprocess[C]//Proceedingsofthe16thACMSIGKDDinternationalconferenceonknowledgediscoveryanddatamining.WashingtonDC, 2010: 673-681.
[18]HEINRICHG.Parameterestimationfortextanalysis[R].Germany:FraunhoferIGD, 2005.
[19]張小平, 周雪忠, 黃厚寬, 等. 一種改進的LDA主題模型[J]. 北京交通大學學報(自然科學版), 2010, 34(2): 111-114.[20]蔣文, 齊林. 一種基于深度玻爾茲曼機的半監督典型相關分析算法[J]. 河南科技大學學報(自然科學版), 2016,37(2): 47-51.
[21]STEINBACHM,KARYPISG,KUMARV.Acomparisonofdocumentclusteringtechniques[C]//Proceedingsofthe6thACM-SIGKDDinternationalconferenceontextmining.Boston, 2000: 103-122.
(責任編輯:王浩毅)
NewsTopicDetectionBasedonSemi-supervisedDPMM
YAODongdong1,YUANFang2, 3,WANGYu1,LIUYu3
(1. School of Computer Science and Technology, Hebei University, Baoding 071000, China;2. Department of Computer Teaching, Hebei University, Baoding 071000, China;3. College of Mathematics and Information Science, Hebei University, Baoding 071000, China)
BasedontheDirichletprocessmixturemodel(DPMM),combiningwiththemodel’sbasiccharacteristicofautomaticallylearningtheclusternumber,thelatenttopicinformationdetectionwasheldfromtheperspectiveofsemantics.AmoreaccurateK-valuewasobtainedwiththesamplingstrategyofK-value’schangingfrombigtosmallstepbystep.Afteranalyzingthetermfrequencycharacteristicsofsemanticclustering,agroupofnounentitieswereintroducedas“hotterms”toguidetheclusteringprocess,whichcouldbeconsideredastheDPMMsemi-supervisedmodel.TheresultsonTDT4corpusshowedthattheproposedtopicdetectionmethodwaseffective.
topicdetection;Dirichletprocess;Gibbssampling;powerlaw;nounentity
2016-04-07
河北省軟科學研究計劃項目(12457206D-11, 13455317D).
姚冬冬(1990—),男,河北邢臺人,碩士研究生,主要從事數據挖掘研究,E-mail:ydd625@qq.com;通訊作者:袁方(1965—),男,河北安新人,教授,主要從事數據挖掘、社會計算研究,E-mail:yuanfang@hbu.edu.cn.
TP391.1
A
1671-6841(2016)03-0063-06
10.13705/j.issn.1671-6841.2016070
引用本文:姚冬冬,袁方,王煜,等.基于半監督DPMM的新聞話題檢測[J].鄭州大學學報(理學版),2016,48(3):63-68.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
人大建設(2020年4期)2020-09-21 03:39:12
開放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
