基于多尺度重采樣思想的類指數核函數構造
2016-10-14 01:29:21胡站偉焦立國徐勝金
電子與信息學報 2016年7期
胡站偉 焦立國 徐勝金 黃 勇
?
基于多尺度重采樣思想的類指數核函數構造
胡站偉①②焦立國③徐勝金*①黃 勇②
①(清華大學航空航天學院流體力學所 北京 100084),②(中國空氣動力研究與發展中心 綿陽 621000),③(大慶地區防洪工程管理處 大慶 163311)
該文按照多尺度重采樣思想,構造了一種類指數分布的核函數(ELK),并在核回歸分析和支持向量機分類中進行了應用,發現ELK對局部特征具有捕捉優勢。ELK分布僅由分析尺度決定,是單參數核函數。利用ELK對階躍信號和多普勒信號進行Nadaraya-Watson回歸分析,結果顯示ELK降噪和階躍捕捉效果均優于常規Gauss核,整體效果接近或優于局部加權回歸散點平滑法(LOWESS)。多個UCI數據集的SVM分析顯示,ELK與徑向基函數(RBF)分類效果相當,但比RBF具有更強的局域性,因此具有更細致的分類超平面,同時分類不理想時可能產生更多的支持向量。對比而言,ELK對調節參數敏感性低,這一性質有助于減少參數優選的計算量。單參數的ELK對局域特征的良好捕捉能力,有助于這類核函數在相關領域得到推廣。
多尺度重采樣;Nadaraya-Watson回歸;支持向量機;類指數核函數
1 引言
核方法(kernel method)自二十世紀90年代引入模式識別與機器學習后,取得了巨大的成功,在信號回歸、特征識別、聚類分析、運動檢測等非參數機器學習領域有廣泛的應用,其中支持向量機(Support Vector Machine, SVM)的發展尤為迅速。核方法的研究主要集中在兩方面:(1)核方法與常規的線性學習方法的結合,如基于核函數的主成分分析(KPCA)[5];(2)核方法中核函數的構造與核參數的優選。本文對(2)進行研究。
核函數的構造通常有3種途徑[6,7]:改造常用分布函數、構造核函數、組合核函數。一些應用通過構造核矩陣來代替一個顯式的核函數,來實現對具體問題核參數調整的要求[8]。常見核函數大多基于線性、多項式、高斯分布、樣條函數等分布,通過改造使其性質滿足Mercer定理要求。構造核函數針對字符、圖像、生物信息等特殊應用,以實現對信息的高效提取。組合核函數原則上可實現核函數程序化優化,組合形式包括不同適用范圍核函數的組合、不同局域性的核函數組合、不同尺度的同一核函數的多分辨組合等形式[9]。
多分辨組合的小波核函數,使用多尺度小波的非負線性組合,實現對某一空間上目標函數的高精度逼近[10]。借鑒這一思想,對空間上的目標函數直接進行多尺度重采樣,也可以獲得對目標函數的穩健估計;將這一過程使用單一核函數進行描述,可使多分辨組合核函數參數優化的計算量顯著降低。
以提升信號局部信噪比為分析樣本,通過對瞬態信號進行時域多尺度重采樣,本文構造了一種以分析尺度為唯一參量的類指數核函數(Exponential- Like Kernel, ELK),并通過數值仿真來討論該核函數在回歸分析和SVM中的適應性。
本文首先對局部回歸和SVM這兩種核方法簡單介紹;然后,通過引入時域多尺度重采樣的概念,導出了ELK。利用ELK對兩類典型非穩態信號進行了回歸處理,分析了ELK的降噪和瞬態信號捕捉性能。通過對比幾組UCI標準數據的SVM分類效果,討論了ELK的參數敏感特征;最后,對ELK的應用和局限進行了討論。
2 兩種核方法的介紹
2.1 局部回歸
信號回歸中一項重要內容就是對瞬態信號的提取[11]。在常見的樣條平滑、正交回歸等方法中,大多隱含了對數據分布形式的強制擬合(使用樣條函數、小波基函數等),容易引起信號畸變。局部回歸是一類易于保留信號局域特征的非參數回歸分析,主要包括:核回歸分析、局部多項式回歸分析、穩健回歸分析等方法[12]。N-W(Nadaraya-Watson)回歸在核回歸方法中發展歷史較早,形式簡單、便于分析[13],其核概率密度分布加權累加形式為
常見的核函數包括:均勻核函數、高斯(Gauss)核函數、三角核函數等[12]。核回歸分析的研究表明,相對于核函數的選擇,更為關鍵的是分析帶寬的選取[2,4]。
2.2 SVM
SVM是由文獻[14,15]在20世紀末提出的一種基于統計學習理論的新型機器學習方法。在SVM方法中,高效和具有良好擴展性的核函數的選擇,是模型復雜度和魯棒性的關鍵[14,16]。方法中核參數選擇算法包括:grid search 暴力搜索方法,啟發式GA, PSO方法等[17]。恰當選擇核函數及其參數,或者尋求對低參數敏感性的核函數以降低參數計算成本也是該類問題的研究熱點[16]。
SVM常見的核函數類型有:線性、多項式、徑向基函數(Radial Basis Function, RBF)和Sigmoid函數、樣條核函數等。其中,RBF具有高維數映射能力和參數相對簡單的特點,常被用作未知數據集處理的默認核函數。RBF的形式為
SVM算法在機器學習的幾大領域:模式識別、回歸估計、概率密度函數估計等都有應用。特別地用于分類的模式識別方面,對于手寫數字識別、語音識別、人臉圖像識別、文章分類等問題,SVM算法在精度上達到甚至優于其他傳統算法。
3 方法介紹
過采樣技術可以有效地增加信噪比,但在采樣樣本既定的情況下,充分并合理利用有限的采樣點,有效減小估計偏差,是信號識別的重要內容。借鑒微弱信號識別中采用的取樣積分方法的思想[21],可以對信號進行多尺度重采樣,并利用多個采樣樣本的組合來提高信噪比。
3.1多尺度重采樣
對于同一個弱的脈沖信號,相同背景噪音下多探測器同步測量,其累加結果會類似于取樣積分的效果。按照這一思路,可以將一個高頻采樣信號(),人工分為多組較低頻率的采樣信號x(t),構成重采樣信號組。
從采樣間隔的設定方法上區分,重采樣可分為定間隔的采樣法dTc、間隔遞增的采樣法dTn兩種。dTc方法與常規的降采樣過程類似,對信號總長度為的原始數據,從任意一點開始,以固定的間隔選取樣本點就可以獲得一組單尺度重采樣數據。記原始樣本間隔為, dTc方法可表述為
圖1展示了對含噪矩形階躍信號,不同重采樣方法的效果。原始信號總長度201,脈沖位于時間序列中部、寬度21,信噪比()設為5.6 dB。可以看到,dTc方法各樣本尺度相同,在階躍點附近失真顯著。dTn不同尺度樣本對階躍特征的捕捉效果存在差異,且數據樣本間的采樣點數不同,在樣本累加處理上需要進行樣本重構。以下重點討論dTn方法。
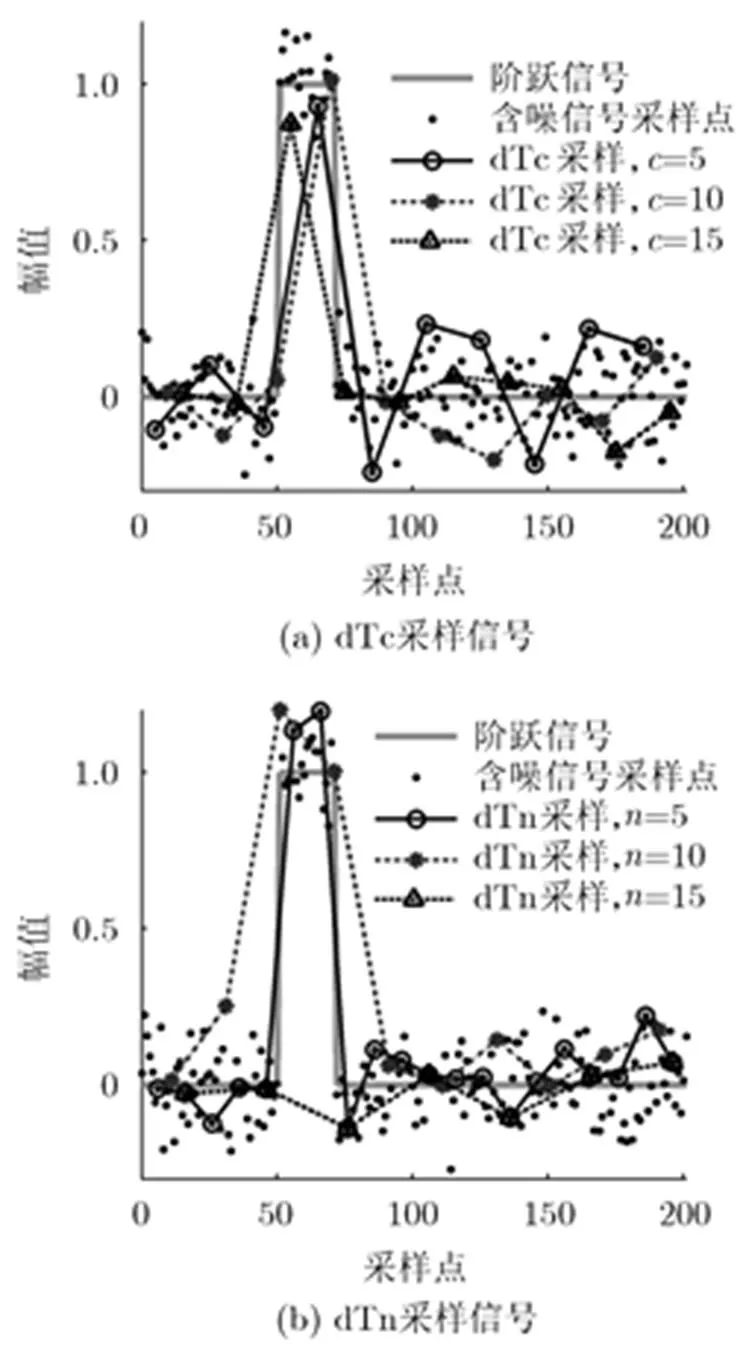
圖 1 多尺度重采樣點示意圖
3.2 時域多尺度重采樣構造的窗函數
多尺度重采樣數據重構時,需要充分利用瞬態信號在時域上影響范圍有限的特征。考慮局部長度為的一段信號進行采樣,按照dTn方法共取組多尺度重采樣樣本,即存在個有效數據點。某一時刻多尺度重采樣樣本累加結果可表示為
該權函數端點值非0,關于中心對稱,且自然滿足歸一化,如圖2(a)。由于該分布的形狀與指數分布相似,因此將該分布記作類指數(Exponential Like, EL)分布。EL分布在中心區具有局部極大,近似指數分布;在遠端迅速衰減,更接近高斯分布。
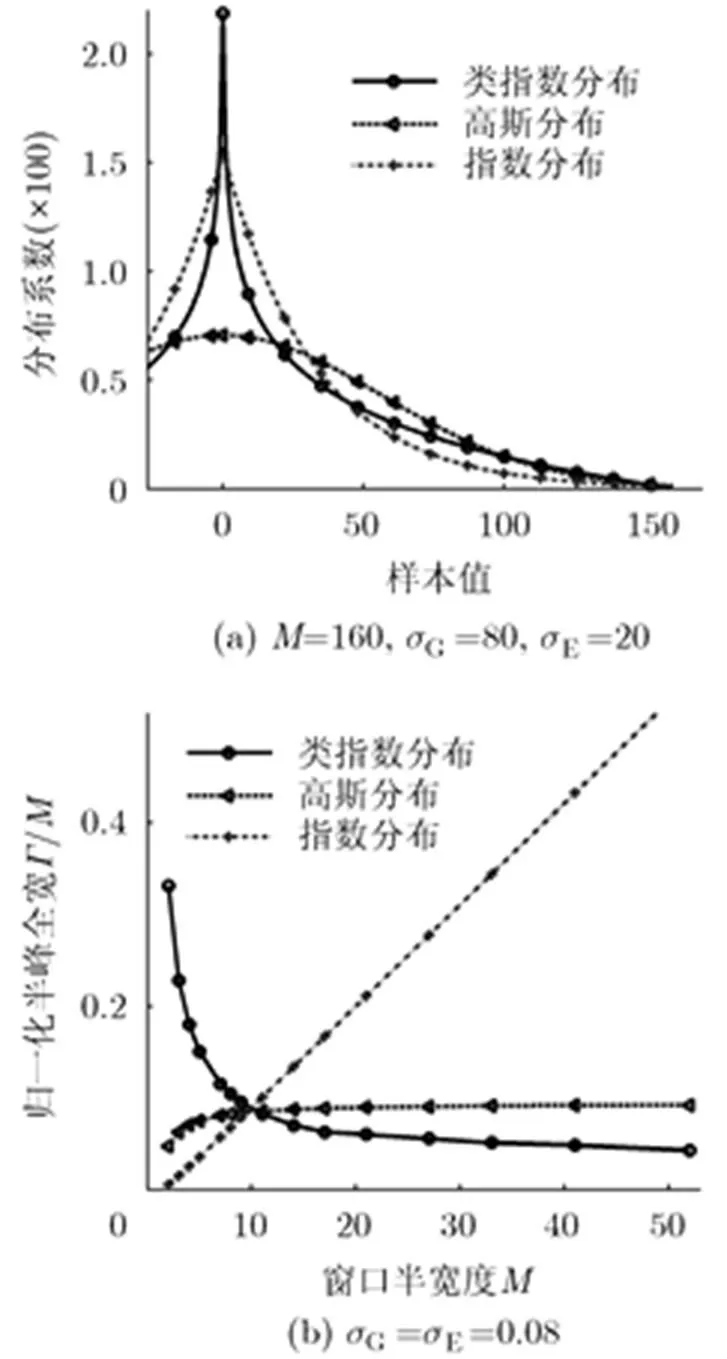
圖 2 ELK分布與高斯分布、指數分布之間的對比
以上分析中,分別提到基于dTc的采樣平均(記作dTc AVG)、基于dTn的線性插值(dTn LInter)和基于dTn的原始信號填充(dTn OSP)3種方法。可以從幅值跟蹤、階躍位置逼近和降噪效果3個方面對比這幾種方法的降噪處理效果。根據圖3,最大采樣樣本尺度越窄,降噪效果越差,但對于階躍捕捉越準確。具體而言,dTc AVG方法造成過度平滑,在幅值跟蹤和邊緣檢測方面較差;dTn LInter方法在幅值跟蹤、階躍位置逼近方面均不理想;dTn OSP方法各指標均最佳,但隨分析尺度增加,其階躍位置也會產生模糊。

圖 3 不同降噪方法的效果對比
3.3 類指數分布核函數
式(9)所示加權函數,滿足式(2)的核函數條件,因此可以稱之為類指數分布核函數(ELK)。 用于SVM時,不關心歸一化,也可以表述為基于向量空間范數的ELK形式:
由于ELK是對稱正分布,ELK的Gram矩陣是正定的。使用數值仿真可以證明,ELK對于任意兩個維向量映射的核函數矩陣,都是對稱半正定的。按照Mercer定理[22],ELK是一個有效核函數。從分布上看,ELK與高斯核一樣,同屬于徑向對稱核函數,計算復雜程度一致。由于ELK具有強局域性,作用于核方法時可以獲得精細的局部特征。
4 類指數分布函數回歸分析
對于不同的信號類型,不同核函數在最優的帶寬選擇下會有近似的結果,但核函數對于帶寬的敏感性會有所不同。核回歸分析中常用Gauss核,以下即對ELK與Gauss核在N-W回歸中的效果進行對比。為增強對比的有效性,引入局部加權回歸散點平滑法(LOWESS)作為參照。
模擬分析信號采用Matlab軟件的Wnoise函數產生,主要討論包括階躍和多普勒兩種典型信號。為保證對瞬態細節顯示,信號的長度選擇為1024點。通過改變原始信號SNR、調整核函數的帶寬進行分析。模擬信號回歸估計效果的評估,采用均方誤差(Mean Squared Error, MSE)。考慮到N-W回歸的邊界效應,設計歸一化MSE并不引入邊界部分的影響:
此外,為了衡量算法對于階躍量的擬合效果,構造階躍平方誤差(Step Squared Error, SSE)函數。記,階躍平方誤差僅包含強階躍信號:
4.1 階躍信號回歸分析

圖4 含噪階躍信號不同回歸方法的參數影響對比
ELK的N-W回歸結果,整體上效果優于以上兩種方法。除了在局部小帶寬低SNR的情況下,ELK由于具有對局部的高加權因子的性質,得到了與LOWESS方法相似的高MSE。這一現象的成因在于低SNR信號回歸中,需要較大樣本才能取得相對較好的回歸效果,因此需要選擇較大的帶寬。
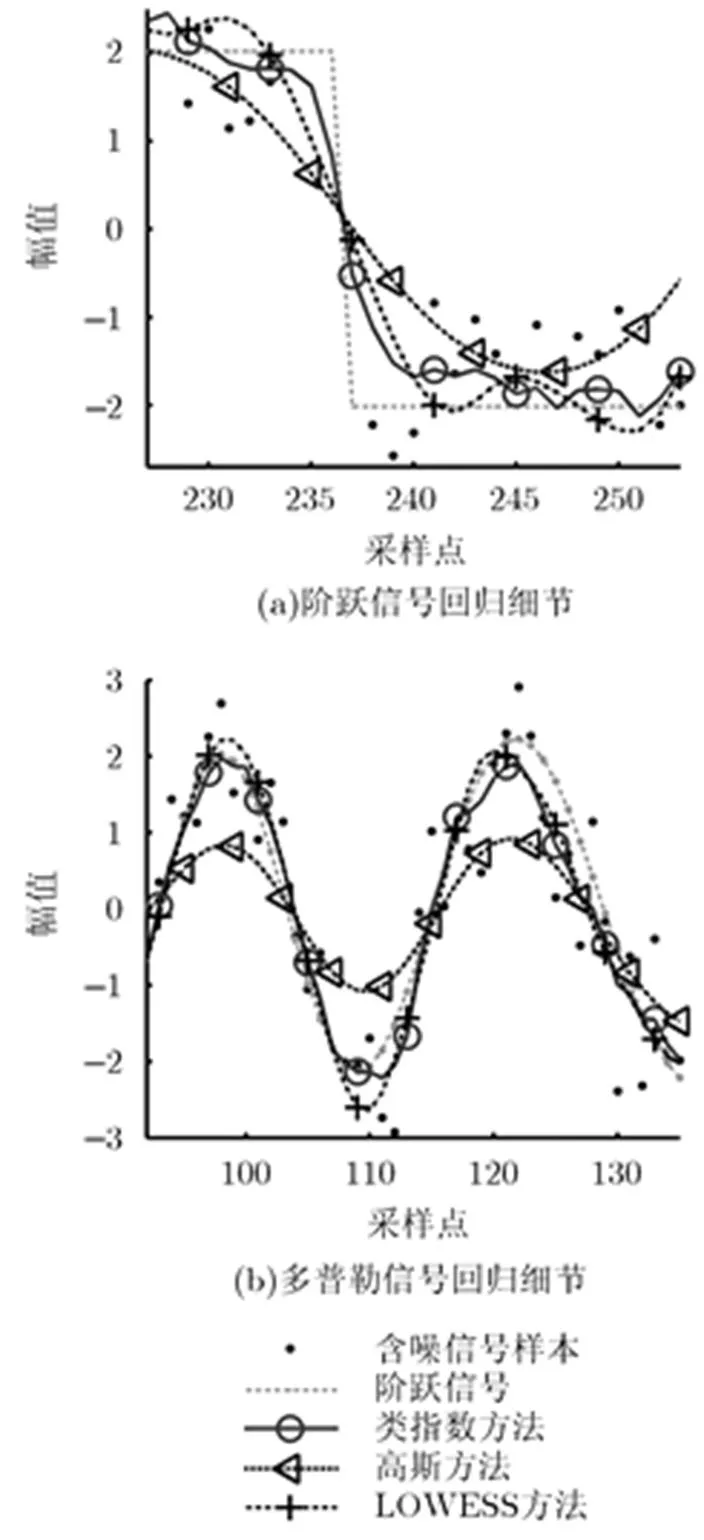
圖 5 含噪階躍信號不同回歸方法的效果對比
4.2 多普勒信號回歸分析
對于含噪多普勒信號,SNR和帶寬對回歸效果的整體影響與階躍信號類似(圖略)。同樣以各算法最優帶寬對含噪多普勒信號進行回歸,其效果對比參見圖5(b)。
5 類指數分布函數SVM性能分析
不同核函數對SVM的分類性能會有影響,同時核函數參數也對分類問題的效果影響顯著[23]。在考察在分類問題中不同核函數的性質時,均選擇C-SVC(C-Support Vector Classification)算法,并采用SMO求解;核函數效果檢驗使用多組UCI 數據集。
5.1 ELK用于SVM時的分類超平面對比
以fisheriris的部分數據為例[24],以花萼寬度和花萼長度對兩類(Verg., Vers.)鳶尾花進行分類,直觀考察不同核函數的分類特征。選擇默認罰函數,對參數的影響進行了分析(圖略)。兩個核函數在各自的最優參數下最大失誤率相當,參數變化范圍內ELK分類效果整體上更接近最優。圖6給出了最優時支持向量分布,可以看出ELK相對于RBK,對于同樣的參數,其分類超平面更為細致,表明具有顯著的局域性。
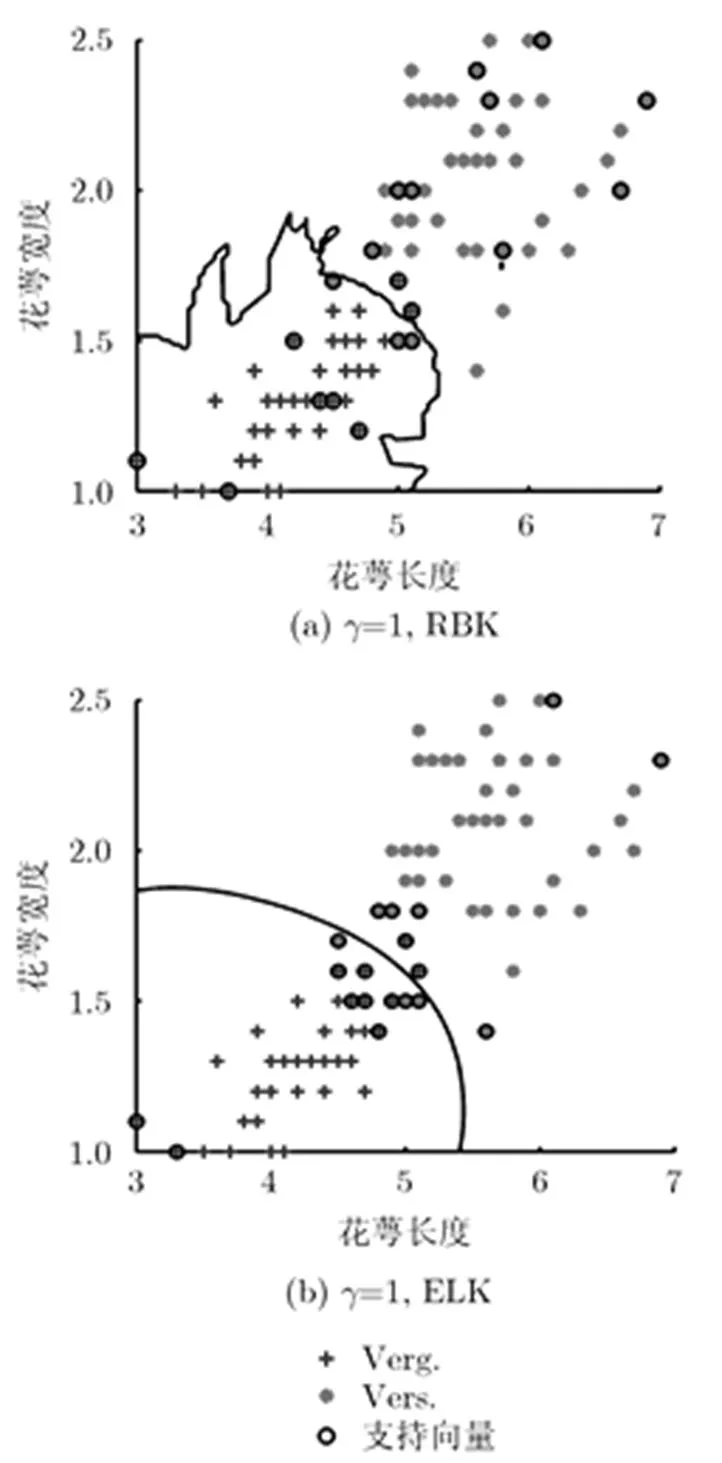
圖 6 RBK與ELK用于fisheriris數據分類
5.2 ELK在SVM中的性能對比
在核函數效果的對比驗證中,使用UCI數據庫的fisheriris, glass, heart, wine數據集[24],進行分類效果檢驗。數據集的參數描述見表1。分類計算使用LibSVM工具箱。為了考察核函數的性能,罰函數和部分參數的使用網格搜索法對最優核參數進行選擇,并使用5-折交叉驗證正確率(5-Cross Validation Accuracy, 5-CVA)、使用支持向量數(number of Support Vector, nSVs)來估計LOO (Leave-One-Out) 誤差上限等方法對最優參數下不同核函數的效果進行對比。仿真過程中,首先對各參變量進行歸一化預處理,防止出現參數特征對分類效果的影響。
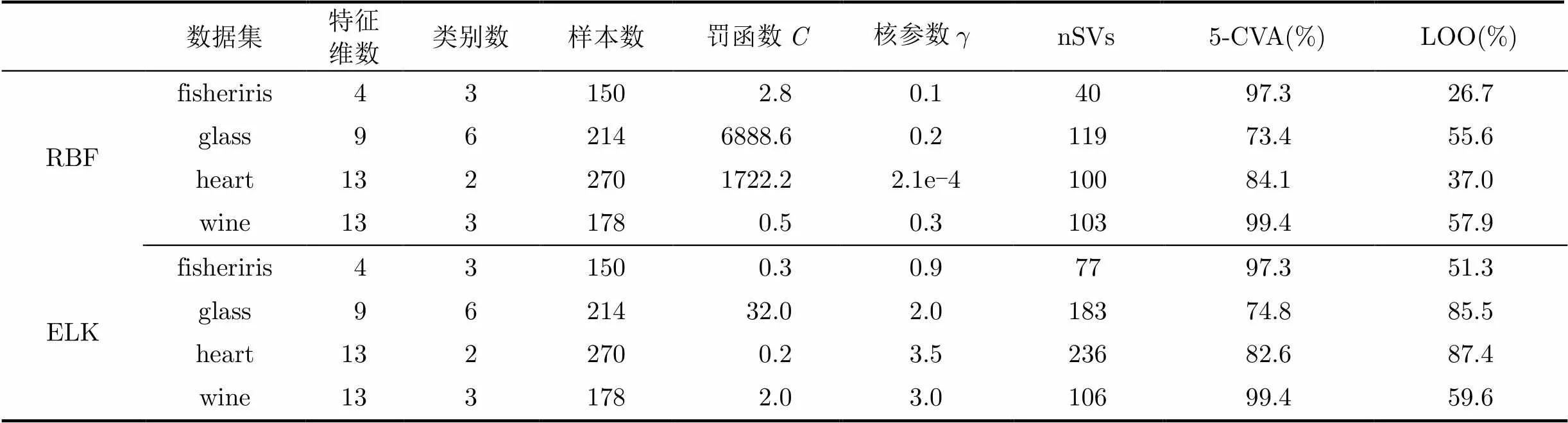
表1 各UCI數據集使用不同核函數的最優分類效果
各數據集最佳分類正確率下,不同核函數的參數值及支持向量數見表1。不同數據集下,ELK參數整體上量級更為接近,因此在參數選擇上可以以較小的代價進行參數優選。從5-CVA效果看, ELK比RBF具有相當或者更優的結果。這一結果與ELK對于局部特征的顯著捕捉能力有關,這一點也體現在ELK在分類效果不良時所需要的支持向量數量遠大于RBF的支持向量數量。支持向量增加會引起LOO誤差上限增大,也增加過擬合的風險。
圖7給出了不同參數組合下兩種核函數的對Iris分類準確率分布。ELK最優參數的分布區間相對集中,且在優選區域內罰函數的變化對分類準度的影響相對較小,更多的影響到支持向量的數目。這一性質有助于大大減少參數選擇所需的計算量。

圖 7 UCI數據集使用RBF和ELK的參數選擇效果對比
6 結論
通過對多尺度重采樣過程建模,從理論上導出了時域瞬態信號的局部加權函數,并將這種具有顯著中心權重的正對稱分布函數發展為一種類指數分布核函數(ELK)。ELK既具有穩定的強局域性,也在一定程度上可以感受大尺度范圍的影響。
ELK用于核回歸分析,在分析尺度樣本的規模,比Gauss核函數具有更好的信號降噪和局部階躍捕捉能力,綜合效果甚至優于LOWESS方法。ELK用于SVM分析時,比使用RBF時更為細致的分類超平面,整體上具有更佳的分類效果,但數據集分類不良時需要更多的支持向量。此外,ELK在一定區域內對于罰函數的變化不敏感,有助于減少參數選擇所需的計算量。ELK對局域信號的捕捉能力,以及其形狀僅由分析尺度單參數決定的性質,使得該函數的尺度選擇上物理意義明確。這一性質有助于這類核函數在其他諸如模式識別、聚類分析等領域的應用中得到推廣。
[1] SMOLA A J and SCHLKOPF B. On a kernel-based method for pattern recognition, regression, approximation, and operator inversion[J]., 1998, 22(1): 211-231. doi: 10.1007/PL00013831.
[2] KOHLER M, SCHINDLER A, and SPERLICH S. A review and comparison of bandwidth selection methods for kernel regression [J]., 2014, 82(2): 243-274. doi: 10.1111/insr.12039.
[3] DAS D, DEVI R, PRASANNA S,Performance comparison of online handwriting recognition system for assamese language based on HMM and SVM modelling[J].&, 2014, 6(5): 87-95. doi: 10.5121/csit.2014.4717.
[4] HASTIE T and LOADER C. Local regression: Automatic kernel carpentry[J]., 1993, 8(2): 120-143. doi: 10.1214/ss/1177011002.
[5] Sch?lkopf B, Smola A, and Müller K R. Nonlinear component analysis as a kernel eigenvalue problem[J]., 1998, 10(5): 1299-1319. doi: 10.1162/ 089976698300017467.
[6] BUCAK S S, JIN R, and JAIN A K. Multiple kernel learning for visual object recognition: A review [J]., 2014, 36(7): 1354-1369. doi: 10.1109/TPAMI.2013.212.
[7] BACH F R, LANCKRIET G R, and JORDAN M I. Multiple kernel learning, conic duality, and the SMO algorithm[C]. Proceedings of the Twenty-first International Conference on Machine Learning, Banff, Canada, 2004: 1-6. doi: 10.1145/1015330.1015424.
[8] 吳濤, 賀漢根, 賀明科. 基于插值的核函數構造[J]. 計算機學報, 2003, 26(8): 990-996.
WU Tao, HE Hangen, and HE Mingke. Interpolation based kernel function’s construction[J]., 2003, 26(8): 990-996.
[9] JAIN P, KULIS B, and DHILLON I S. Inductive regularized learning of kernel functions[C]. Proceedings of the Advances in Neural Information Processing Systems, Vancouver, Canada, 2010: 946-954.
[10] ZHANG L, ZHOU W, and JIAO L. Wavelet support vector machine[J].,,,:, 2004, 34(1): 34-39. doi: 10.1109/TSMCB.2003.811113.
[11] NADARAYA E A. On estimating regression[J].&, 1964, 9(1): 141-142. doi: 10.1137/1109020.
[12] Wasserman L著, 吳喜之譯. 現代非參數統計[M]. 北京: 科學出版社, 2008: 163-179.
[13] WATSON G S. Smooth regression analysis[J].:,, 1964, 26(4): 359-372.
[14] CRISTIANINI N and SHAWE-TAYLOR J. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods[M]. Cambridge: Cambridge University Press, 2000: 93-112.
[15] VLADIMIR V N and VAPNIK V. Statistical Learning Theory[M]. New York: Wiley, 1998: 293-394.
[16] CHANG C C and LIN C J. LIBSVM: A library for support vector machines[J]., 2011, 2(3): 27. doi: 10.1145 /1961189.1961199.
[17] REN Y and BAI G. Determination of optimal SVM parameters by using GA/PSO[J]., 2010, 5(8): 1160-1168. doi: 10.4304/jcp.5.8.1160-1168.
[18] SARAFIS I, DIOU C, and TSIKRIKA T. Weighted SVM from click through data for image retrieval[C]. 2014 IEEE International Conference on Image Processing (ICIP 2014), Paris, 2014: 3013-3017. doi: 10.1109/ICIP.2014.7025609.
[19] SONKA M, HLAVAC V, and BOYLE R. Image Processing, Analysis, and Machine Vision[M]. Kentucky: Cengage Learning, 2014: 257-749. doi: 10.1007/978-1-4899-3216-7.
[20] SELLAM V and JAGADEESAN J. Classification of normal and pathological voice using SVM and RBFNN[J]., 2014, 5(1): 1-7. doi: 10. 4236/jsip.2014.51001.
[21] 高晉占. 微弱信號檢測[M]. 北京: 清華大學出版社有限公司, 2004: 154-299.
GAO Jinzhan. Weak Signal Detection[M]. Beijing: Tsinghua University Press Ltd., 2004: 154-299.
[22] MERCER J. Functions of positive and negative type, and their connection with the theory of integral equations[J].,, 1909, 209(456): 415-446. doi: 10.1098/rsta.1909. 0016.
[23] MARRON J and CHUNG S. Presentation of smoothers: The family approach[J]., 2001, 16(1): 195-207. doi: 10.1007/s001800100059.
[24] LICHMAN M. UCI machine learning repository[OL]. http://archive.ics.uci.edu/ml. 2013.
Design of An Exponential-like Kernel Function Based on Multi-scale Resampling
Hu Zhanwei①②Jiao Liguo③Xu Shengjin①Huang Yong②
①(,,,100084,),②(&,621000,),③(,163311,)
Based on multi-scale resampling, an Exponential-Like Kernel (ELK) function is designed, and evaluated with local feature extraction in kernel regression and Support Vector Machine (SVM) classification. The ELK is a one-parameter kernel, whose distribution is controlled only by the resolution of analysis. With block and Doppler noisy signals, Nadaraya-Watson regression with ELK mainly shows more noise and step error than with Gaussian kernel, it also has better precision and is more robust than LOcally WEighted Scatterplot Smoothing (LOWESS). Data sets from the UCI Machine Learning Repository used in SVM test demonstrate that, ELK has nearly equal classification accuracy as RBF does, and its locality results in more detailed margin hyperplanes, in consequence, a big number of support vectors in low classification accuracy situation. Moreover, the insensitivity of ELK to the adjustive coefficient in kernel methods shows the potential to facilitate the parameter optimization progress. ELK, as a single parameter kernel with significant locality, is hopefully to be extensively used in relative kernel methods.
Multi-scale resampling; Nadaraya-Watson regression; Support Vector Machine (SVM); Exponential- Like Kernel (ELK) function
TN911.7
A
1009-5896(2016)07-1689-07
10.11999/JEIT151101
2015-09-25;改回日期:2016-05-03;網絡出版:2016-06-03
徐勝金 xu_shengjin@tsinghua.edu.cn
國家自然科學基金(11472158)
The National Natural Science Foundation of China (11472158)
胡站偉: 男,1984年生,工程師,博士生,研究方向為實驗流體力學、信號處理.
焦立國: 男,1970年生,高級工程師,研究方向為信號處理、防洪工程.
徐勝金: 男,1969年生,副教授,博士生導師,研究方向為實驗流體力學、流固耦合.
黃 勇: 男,1973年生,副研究員,研究方向為流動控制和動力模擬.
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
電子制作(2018年11期)2018-08-04 03:25:42
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
中華詩詞(2018年11期)2018-03-26 06:41:34
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
