Hadoop平臺中作業調度算法分析與改進研究
2016-09-26 08:28:01陳新
網絡安全與數據管理 2016年11期
陳 新
(廣東省培英職業技術學校, 廣東 廣州 510630)
?
Hadoop平臺中作業調度算法分析與改進研究
陳新
(廣東省培英職業技術學校, 廣東 廣州 510630)
針對傳統云計算作業調度中簡單優先級設置的不足,首先對作業調度進行研究并提出了基于用戶服務等級協議(SLA)的作業分級機制。該設計基于QoS約束的多優先級作業調度算法,在算法中利用云用戶作業中的偏好程度來設計優先級值計算函數Priority,在作業調度時可以使較高等級的云用戶和具有較高優先級的作業優先得到任務的執行,通過上述方式可以較好地保證云計算環境下的服務質量。
云計算;作業分級機制;作業調度算法;SLA;QoS
引用格式:陳新. Hadoop平臺中作業調度算法分析與改進研究[J].微型機與應用,2016,35(11):80-82,86.
0 引言
Hadoop是目前比較流行的云計算實現平臺,通過Hadoop可以快速搭建和部署云計算的環境。在Hadoop中有兩個重要的功能組件,分別是分布式文件系統和MapReduce計算組件。通過上述功能組件可以實現云計算的分布式計算和應用的虛擬化[1]。開源云計算平臺Hadoop中的分布式文件系統是谷歌公司實現云計算的文件系統開源部分,而MapReduce是谷歌公司實現云計算中的并行計算和處理的實現部分[2]。
在云計算的環境下,目前的作業調度算法主要有三種,分別為先進先出作業調度算法、公平調度算法和計算能力調度算法。無論是哪種調度算法,在Hadoop中都需要通過主控節點進行分配和安排,通過作業調度器對云計算中的作業和任務進行調度,根據用戶的設置偏好來實現對任務的分配和作業的調度[3-4]。從這個角度上看,作業的調度和安排直接關系到云計算平臺性能的好壞,直接影響到云計算平臺的效率,同時也會對用戶的服務質量產生影響[5]。在云計算的環境下,需要對用戶提交的作業進行分級處理,并對每一個作業進行登記標注,這樣就可以對提交的作業設置不同的優先級別,在進行調度時可以按照作業調度的優先級別進行處理,優先安排服務質量高的作業進行資源的分配和處理,這樣可以有效地提高云用戶作業的服務質量以及云用戶的滿意程度[6]。
1 云體系架構

圖1 云計算作業調度的體系架構
云計算的服務包括多種類型,具體有私有云和公有云,對于不同的云計算環境其具體的劃分結構如圖1所示[7]。在云計算的體系結構中,對于私有云來說,用戶可以很好地實現對數據的控制,保證云計算中的用戶數據的安全。并且在私有云的計算環境下,用戶不僅可以通過其調度得到內部的計算資源,還可以通過云計算的作業調度獲取到公有云中的計算資源和服務,使得云計算的體系結構具有高可用性、易擴展的特點[8]。
2 算法設計
任務調度是集群系統的核心技術。本文中共劃分了五個主要的等級隊列,對作業進行服務質量(QoS)屬性偏好設置,就可以得到具有不同用戶屬性偏好的多優先級的作業,然后通過作業調度器來完成對作業的調度和安排,滿足用戶作業調度服務的需求,為此,本文提出了多優先級作業調度算法(QoS-Multi Priority Scheduler,QoS-MP Scheduler)。
2.1算法的設計思想
在QoS-MP Scheduler算法中,其設計的主要思路是,首先需要設計作業優先級計算函數 Priority,在這個函數中包括了基于 QoS 屬性約束的優先條件,對每一個作業的優先級的數值進行計算。接著,在云計算主控節點 JobTracker的作業調度器中對Priority建立隊列,然后,在進行作業調度任務分配時,選取隊列中具有最高優先級值的作業進行分配,并將相關數據調入到云計算本地文件系統區去執行,這樣就可以在最大程度上考慮用戶的服務質量需求,有效地提高用戶作業的服務質量,提升整個系統的質量和服務滿意度。
2.2服務質量設計
在云計算的環境下,云計算的服務質量是全部服務性能和程度的總和。對云服務的能力進行衡量和描述,具體如表1所示。

表1 云計算服務質量 QoS 的屬性說明表
2.3優先級計算函數設計

圖2 作業中的兩個重要的QoS 屬性
云服務中的作業包括了兩個重要的屬性,即Time和Cost屬性,對于每一個作業,其Time和Cost的需求是不盡相同的,根據具體的實際情況才能確定。在云計算的環境下,其計算數值相差都較大,具有比較大的波動性,但是這兩個屬性是衡量云計算服務質量的最重要的屬性,如何對其進行定義和配置關系到云服務質量的好壞,需要在這兩個作業屬性之間找到平衡,來保證云服務的質量。為此,本文提出了使用基于 QoS 約束的優先級計算函數 Priority來完成上述各個屬性的約束與控制,實現用戶作業服務質量的滿足。Time和Cost屬性具體如圖2所示。
2.4算法的實現
通過對用戶作業的分級可以在開源云計算框架中的主控節點JobTracker中得到5個具有不同級別的隊列,表示為VERY_HIGH、HIGH、NORMAL、LOW、VERY_LOW。上述作業隊列的優先級別為從高到低。在節點中對作業客戶端所提交的作業信息進行提取,可以得到作業等級的數據信息,將其提交到主控節點中進行作業隊列的安排,通過映射就可以使得每一個作業隊列都具有優先級別。同樣地,在主控節點中,對于作業隊列通過計算其優先權值的數據,并對每一個優先級別VERY_HIGH、HIGH、NORMAL、LOW、VERY_LOW分別設置ω1、ω2、ω3、ω4、ω5的權重數值,云用戶就可以對上述的權值進行配置,實現對云計算中的作業優先級別的計算。對于其權重的計算,如圖3所示。
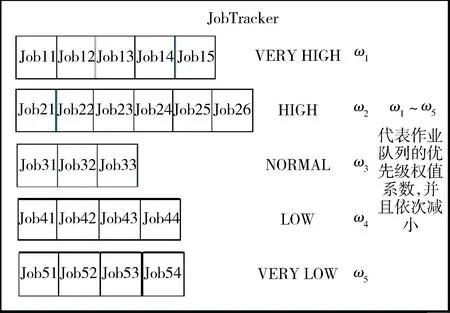
圖3 JobTracker 中作業隊列的優先級權值系數的設計
在云計算環境下,對每一個作業,其用戶都有其QoS屬性的偏好,對于不同的偏好可以通過基于 QoS 約束的優先級計算函數 Priority來描述和實現,這樣就可以使得在云用戶進行作業提交時實現偏好程度的選擇,在云計算的作業提交之后通過參數的方式將其數據信息傳遞到云計算中的主控節點進行處理。本文對于優先級別函數的計算中,主要是對服務質量屬性中的Time 和 Cost進行設計和計算。下面介紹Time 和 Cost 的偏好程度級別的設計,其級別的設置如表2所示。

表2 Time和Cost的偏好程度級別表
對于偏好程度共設置了1~10之間的多個級別,其中1的級別最低,10的級別最高。不同屬性按照用戶需求選擇,如果對實時性要求較高,則在偏好程度數值的選擇上選擇較大的Time 屬性值,在云計算進行作業調度時,則是選擇優先級別較高的作業進行調度實現;此外,對于用戶對云計算中的花費較低的需求,則在作業中屬性選擇時選擇較低的 Cost 屬性值。通過上述設置完成選擇,將作業Time 和 Cost 信息傳遞到主控節點。對于上述過程,具體如圖4所示。

圖4用戶對作業 QoS 屬性偏好值的傳遞過程

圖6 改進后的云計算系統的作業處理流程
通過上述過程,作業自身的Time 和 Cost屬性消息傳遞到云計算中的主控節點,并在主控節點對此消息進行計算和分析,對所提交的作業進行分級,根據用戶所提交的作業等級進行調度,將處于優先級別較高的作業優先安排到作業隊列中進行處理。因此,在云計算的作業調度中,對于作業的處理是通過對作業隊列的優先級系數值和用戶對 QoS 屬性的偏好程度進行計算,從而得到優先級計算函數 Priority,最終通過云計算中的主控節點進行作業的調度,完成作業的執行。
對于任務的分配其具體實施策略如圖5所示。分配步驟如下:

圖5 JobTracker分配任務給 TaskTracker 的分配策略圖
(1)任務跟蹤節點通過心跳協議的內容,一旦出現處于空閑的map 任務槽和空閑的 reduce 任務槽,就進行統計和分析,并將其統計到主控節點JobTracker進行安排。
(2)主控節點對目前調度的map 任務數與處于空閑的map 任務數進行比較;判斷是否mapslots> req_mapno,如果是,則將作業的map任務全分配給主控節點,執行步驟(3);否則,mapslots 個 map 任務進行調度,并將其分配到主控節點中,直到空閑的任務數分配完畢。
(3)如果mapslots = req_mapno,則跳轉到(4);否則,結束分配過程。
(4)比較目前調度作業的reduce 任務數與空閑的 reduce 任務槽數,如果reduceslots>= req_reduceno,則進行任務的分配,并將其分配到任務跟蹤節點中進行調度;否則結束分配。對作業分級機制和調度算法改進后的云計算系統的作業處理流程具體如圖6所示。
3 實驗與分析
3.1實驗環境搭建
硬件環境:Inter Pentium Dual E2200@2.20 GHz,1 GB內存,160 GB硬盤; 軟件環境 :操作系統為Linux Ubuntu 8.04,編程環境為Hadoop 0.20.2、jdk-6u24-linux-i586。
3.2實驗設計
仿真實驗中對作業的完成時間進行比較。在Hadoop集群環境下,仿真20個不同用戶的工作和業務流,并且對每一組的工作流都執行20次,對這些重復執行的工作任務進行計算取其平均值,計算作業的完成時間,按照上述方式,對不同級別的文件進行作業調度,計算不同作業調度算法和策略下其總的作業運行時間和平均作業運行時間。
3.3實驗結果分析
在本次實驗中,將作業的隊列等級權重設置為不同的級別,權重分別為VERY_HIGH=4、HIGH=2、NORMAL=1、LOW=0.5、VERY_LOW=0.25,對于優
先級別中的屬性參數Time和Cost均設置為 0.5。
在本次實驗中,對于不同算法(靜態調度算法表示為Static,遺傳算法表示為GA,本文算法表示為QOS)下的作業完成時間,其結果如圖7所示。

圖7 云作業的平均完成時間對比
從上述的作業完成時間比較示意圖可以看到,本文算法的作業完成時間最小。
4 結束語
針對傳統作業調度算法中的不足,通過對作業進行QoS 屬性的偏好標記,調度中進行優先級函數計算保證用戶的服務質量。通過仿真實驗,驗證了算法的平均完成時間相對較少,有效地提高了作業調度成功率,表明算法具有較好性能。
[1] 柳少鋒,董劍.一種基于優先級隊列的集群動態反饋調度算法[J].智能計算機與應用,2014,12(4):45-49.
[2] 廖大強.面向多目標的云計算資源調度算法[J]. 計算機系統應用,2016,25(2):180-189.
[3] 鐘浩濤.基于遺傳算法的動態調度分組算法[J].計算機學報,2013,45(8):11-12.
[4] 涂剛陽,富民.基于動態優先級策略的最優軟非周期任務調度算法[J].計算機研究與發展,2014,42(11):23-24.
[5] 廖大強,鄒杜,印鑒. 一種基于優先級的網格調度算法[J]. 計算機工程, 2014, 40(10): 11-16.
[6] AGUILERA M K, CHEN W,TOUEG S. On quiescent reliable communication[J]. Computing,2014,39(6):2040-2073.
[7] VAQUERO L,RODERO-MERINO L,CACERES J,et al.A break in the clouds:towards a cloud definition[J].ACM SIGCOMM Computer Communication Review,2014,39(1):50-55.
[8] 廖大強,印鑒,鄔依林,等.基于興趣傳播的用戶相似性計算方法研究[J].計算機應用與軟件,2015,32(10):95-100,104.
Analysis and improvement of job scheduling algorithm in Hadoop platform
Chen Xin
(Guangdong Province Pei Ying Occupation Technical School, Guangzhou 510630, China)
In view of the shortcoming of simple priority setting in the traditional cloud computing job scheduling, this paper studies the job grading mechanism firstly and puts forward the job grading mechanism based on user’s service level agreement (SLA). The priority job scheduling algorithm is designed based on QoS constraints. In the algorithm the cloud users’ preference can be used to design the priority value to calculate function priority. When scheduling jobs, tasks from higher lever of could users and higher priority jobs can be performed finstly. This mentioned methods can better guarantee the quality of service in cloud computing environment.
cloud computing; job grading mechanism; job scheduling algorithm; SLA; QoS
TP393
A
10.19358/j.issn.1674- 7720.2016.11.024
2016-02-02)
陳新(1974-),男,碩士,講師,主要研究方向:計算機系統架構、軟件工程。
猜你喜歡
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
學生天地(2020年17期)2020-08-25 09:28:54
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
商用汽車(2016年11期)2016-12-19 01:20:16
故事大王(2016年7期)2016-09-22 17:30:08
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
