一種基于虛擬處理區(qū)間劃分的負(fù)載均衡等值連接算法
2016-09-23 05:51:35胡忠奎屈波黃斌黎文陽(yáng)
現(xiàn)代計(jì)算機(jī) 2016年3期
胡忠奎,屈波,黃斌,黎文陽(yáng)
(1.四川大學(xué)計(jì)算機(jī)學(xué)院,成都 610065;2.中國(guó)人民解放軍78098部隊(duì),成都 611200)
一種基于虛擬處理區(qū)間劃分的負(fù)載均衡等值連接算法
胡忠奎1,屈波2,黃斌1,黎文陽(yáng)1
(1.四川大學(xué)計(jì)算機(jī)學(xué)院,成都610065;2.中國(guó)人民解放軍78098部隊(duì),成都611200)
0 引言
以 Spark為新興代表的內(nèi)存計(jì)算,在保持了MapReduce優(yōu)良傳統(tǒng)的同時(shí),大幅提升了其運(yùn)行效率,尤其在迭代式計(jì)算與交互式數(shù)據(jù)分析方面表現(xiàn)優(yōu)異,逐漸受到業(yè)界的青睞。Spark SQL是Spark生態(tài)系統(tǒng)的關(guān)鍵組成部分,它實(shí)現(xiàn)了在Spark系統(tǒng)上對(duì)關(guān)系型數(shù)據(jù)的查詢,是對(duì)Shark和Hive數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng)的升級(jí)。連接操作,特別是等值連接操作,是數(shù)據(jù)分析中常見且代價(jià)很高操作之一,Spark SQL由于采用了Hash劃分技術(shù)來(lái)處理等值連接操作:根據(jù)連接屬性上Key的Hash值確定Key對(duì)應(yīng)數(shù)據(jù)的所屬分區(qū),每個(gè)分區(qū)由一個(gè)Reduce處理單元執(zhí)行連接操作。由于現(xiàn)實(shí)中數(shù)據(jù)在分布上符合帕累托法則(80/20定律)即存在不均衡性,這就導(dǎo)致在數(shù)據(jù)等值連接查詢中,由于連接屬性數(shù)據(jù)分布的不均衡,造成不同Hash值對(duì)應(yīng)的數(shù)據(jù)量的不均衡,出現(xiàn)數(shù)據(jù)的聚集問題,從而導(dǎo)致某些計(jì)算節(jié)點(diǎn)的負(fù)載過(guò)重,極大地降低了大數(shù)據(jù)查詢分析的性能,成為當(dāng)前我們必須解決的新問題。
1 相關(guān)研究
基于Spark/MapReduce的大數(shù)據(jù)分析中,常用的連接算法有Simi-Join、Broadcast Join、Repartition Join等[1]。其中Simi-Join和Broadcast Join局限性較大,通常性能較差,Repartition Join適用性最好,在絕大多數(shù)情況下具有最好的性能。但Repartition Join在Spark上具有如下的缺點(diǎn)。①需要在查詢時(shí)對(duì)數(shù)據(jù)進(jìn)行動(dòng)態(tài)的重劃分,通信量較大,尤其在寬表的情況下;②通過(guò)Hash函數(shù)劃分到同一節(jié)點(diǎn)的很多事實(shí)表元組在外鍵上具有相同值,內(nèi)存和計(jì)算資源消耗較大,同時(shí)容易出現(xiàn)數(shù)據(jù)傾斜問題。關(guān)于連接中的數(shù)據(jù)傾斜問題,有很多學(xué)者進(jìn)行了深入的研究,并給出解決方案。卞昊穹等人[2]通過(guò)預(yù)等值連接得到Hash后的數(shù)值分布,并對(duì)其重新劃分得到負(fù)載均衡等值連接映射,最后根據(jù)映射關(guān)系組裝等值連接;翟紅敏等人[3]基于對(duì)等值連接鍵值的統(tǒng)計(jì)信息,進(jìn)行范圍分割數(shù)據(jù)量,從而達(dá)到總體負(fù)載均衡的目的;吳磊[4]基于分而治之的思想將傾斜數(shù)據(jù)和非傾斜數(shù)據(jù)區(qū)別對(duì)待,結(jié)合了傳統(tǒng)等值連接算法、廣播等值連接算法等算法思想,解決數(shù)據(jù)傾斜情況下任務(wù)負(fù)載分布不均勻的問題;Chen Qi等人[5]通過(guò)提出一種新的采樣方法較為準(zhǔn)確地估計(jì)連接屬性的數(shù)據(jù)分布情況,并基于等值連接代價(jià)模型計(jì)算代價(jià)最小的數(shù)據(jù)分配方案,實(shí)現(xiàn)等值連接計(jì)算的負(fù)載均衡。
2 代價(jià)模型和相關(guān)分析
定義1連接數(shù)據(jù)與連接噪聲:在數(shù)據(jù)集的連接屬性中可能包含一些共有的連接鍵值,這些鍵值對(duì)應(yīng)的數(shù)據(jù)稱為連接數(shù)據(jù),而非共有部分的鍵值對(duì)應(yīng)的數(shù)據(jù)稱為連接噪聲。
定義2虛擬處理區(qū)間:在實(shí)際處理區(qū)間(reduce任務(wù))之上,虛擬劃分出更多的區(qū)間,以解決采樣估計(jì)誤差造成的不均衡問題,達(dá)到數(shù)據(jù)均衡分配的目的。
假設(shè)v表示虛擬處理區(qū)間的數(shù)量,H={H1,H2,…,Hv}表示虛擬處理區(qū)間集合。{(K1,C1),(K2,C2),…,(Kn,Cn)}表示采樣得到統(tǒng)計(jì)數(shù)據(jù),其中,Ki表示連接屬性上的鍵值,Ci表示與Ki對(duì)應(yīng)的元組數(shù)量,在沒有特別說(shuō)明時(shí),我們約定Ki<Ki+1成立。實(shí)際處理區(qū)間的數(shù)量為k,并由R={R1,R2,…,Rk}表示。虛擬處理區(qū)間到實(shí)際處理區(qū)間的交叉映射關(guān)系可以表示為MapPartition{(H1,Hk+1,…,H(α-1)k+1→R1),(H2,Hk+2,…,H(α-2)k+2→R2),…,(Hk,H2k,…,Hαk→Rk)}。其中,α=v/k。
定義3單個(gè)處理區(qū)間負(fù)載代價(jià):在RDD數(shù)據(jù)集轉(zhuǎn)換和連接操作中,單個(gè)處理區(qū)間完成連接操作的代價(jià),包括數(shù)據(jù)集合RD1和RD2從HDFS讀取數(shù)據(jù)和分區(qū)傳輸、處理區(qū)間的連接計(jì)算以及連接結(jié)果存儲(chǔ),表達(dá)式 Costsum=Costio(RD1+RD2)+Costnetwork[Join(RD1+RD2)+Noise(RD1+RD2)]+CostJoin[Join(RD1)×Join(RD2)]。其中,數(shù)據(jù)量定義為采樣得到的元組數(shù)量,代價(jià)定義為處理的數(shù)據(jù)量。Costio(RD1+RD2)表示RDD數(shù)據(jù)讀取及分區(qū)shuffle的代價(jià)。Costneteork表示網(wǎng)絡(luò)傳輸?shù)拇鷥r(jià),Join(RD1+RD2)表示處理區(qū)間中實(shí)際進(jìn)行連接的數(shù)據(jù)量,Noise(RD1+RD2)表示處理區(qū)間中與連接無(wú)關(guān)的數(shù)據(jù)量 (連接噪聲)。CostJoin[Join(RD1)×Join(RD2)]表示進(jìn)行連接計(jì)算以及結(jié)果數(shù)據(jù)輸出到HDFS的代價(jià)。Ri(Costsum)表示處理區(qū)間Ri對(duì)應(yīng)的連接代價(jià)。數(shù)據(jù)傾斜問題的解決取決于各個(gè)處理區(qū)間負(fù)載代價(jià)的均衡程度,即滿足R1(Costsum)≈R2(Costsum)≈…≈Rk(Costsum)。其中,各個(gè)處理區(qū)間關(guān)于Costnetwork和Costio的代價(jià),與分配給處理區(qū)間的實(shí)際數(shù)據(jù)量是成正比的。當(dāng)分配到各個(gè)處理區(qū)間的數(shù)據(jù)量達(dá)到均衡時(shí),處理區(qū)間Ri之間的Costio和Costnetwork是近似相等的,這時(shí)處理區(qū)間的負(fù)載均衡條件轉(zhuǎn)化為R (CostJoin)≈R2(CostJoin)≈…≈Rk(CostJoin),而Ri(CostJoin)取決于連接數(shù)據(jù)Join(RD1)×Join(RD2),因此,為了實(shí)現(xiàn)各個(gè)處理區(qū)間的負(fù)載均衡,除了實(shí)現(xiàn)數(shù)據(jù)量的均衡分配,同時(shí)也要保證連接數(shù)據(jù)或連接噪聲的均衡。
3 虛擬區(qū)間劃分算法VPRP
3.1算法描述
本文在充分考慮連接噪聲對(duì)負(fù)載均衡影響的基礎(chǔ)上,根據(jù)區(qū)間劃分的思想[6],提出了基于虛擬處理區(qū)間劃分和交叉映射的連接算法,基本思想如下:首先通過(guò)文獻(xiàn)[4]提出的采樣方法,分別獲取數(shù)據(jù)集RD1和RD2在連接屬性Key的數(shù)據(jù)分布情況,數(shù)據(jù)格式為{(K1,C1),(K2,C2),…,(Kn,Cn)},通過(guò)對(duì)樣本集(RD1)sample和(RD2)sample的Key值排序和投影比較,估計(jì)出兩個(gè)樣本集連接數(shù)據(jù)集RDL和連接噪聲集RDV,根據(jù)虛擬分區(qū)數(shù)量v,分別將數(shù)據(jù)集RDL和RDV以鍵值數(shù)量Ci均勻分割v份,得到{L1,L2,…,Lv}和{V1,V2,…,Vv},合并組裝得到數(shù)據(jù)量和連接噪聲負(fù)載均衡的虛擬區(qū)間H={L1V1,L2V2,…,LvVv},采用輪轉(zhuǎn)法建立虛擬區(qū)間H到處理區(qū)間R的交叉映射關(guān)系MapPartition{(H1,Hk+1,…,H(α-1)k+1→R1),(H2,Hk+2,…,H(α-1)k+2→R2),…,(Hk,H2k,…,Hαk→Rk)},最后根據(jù)映射關(guān)系分配數(shù)據(jù),并完成連接操作。其中,虛擬區(qū)間數(shù)量v是處理區(qū)間數(shù)量k的整數(shù)倍(實(shí)驗(yàn)設(shè)定v=2×k=40)。
3.2算法詳細(xì)流程
虛擬處理區(qū)間劃分算法共分以下三個(gè)階段:
(1)采樣階段
輸入:連接數(shù)據(jù)集RD1和RD2
輸出:樣本集(RD1)sample和(RD2)sample,輸出數(shù)據(jù)表示為{(K1,C1),(K2,C2),…,(Kn,Cn)},其中Ki表示連接屬性上的鍵值,Ci表示與Ki對(duì)應(yīng)的元組數(shù)量。
①M(fèi)ap任務(wù)讀取數(shù)據(jù)的過(guò)程中,Master節(jié)點(diǎn)分別從RD1和RD2數(shù)據(jù)集對(duì)應(yīng)的集群中,隨機(jī)抽取50%比例的計(jì)算節(jié)點(diǎn),為選中的節(jié)點(diǎn)開啟獨(dú)立的統(tǒng)計(jì)進(jìn)程,從中讀取20%的數(shù)據(jù)集Ti。
②各個(gè)統(tǒng)計(jì)進(jìn)程對(duì)讀入的Ti按照Ki值排序,并統(tǒng)計(jì)相同Ki值的數(shù)量Ci,得到中間數(shù)據(jù) {(K1,C1),(K2,C2),…,(Ki,Ci)},按照Ci從大到小逆向排序,并從中抽取前p個(gè)最大的(Ki,Ci)集合Slargest,然后從剩余的數(shù)據(jù)中隨機(jī)抽取q個(gè)(Ki,Ci)集合Snormal,根據(jù)Ssample=Slargest∪Snor-mal組成節(jié)點(diǎn)的樣本集。
③Master節(jié)點(diǎn)開啟一個(gè)Reduce作業(yè)匯總各個(gè)統(tǒng)計(jì)進(jìn)程采集到的樣本集Ssample,按照Ki值升序排列,相同Ki值的Ci相加合并,最終得到輸出樣本集(RD1)sample和(RD2)sample。
(2)虛擬區(qū)間劃分階段
輸入:樣本集(RD1)sample和(RD2)sample
輸出:虛擬區(qū)間H={L1V1,L1V1,…,LvVv}
①對(duì)樣本集(RD1)sample和(RD2)sample的 Key值進(jìn)行投影比較,使用和,估計(jì)出連接數(shù)據(jù)集RDL和連接噪聲集RDV。為降低采樣誤差,造成個(gè)別共有Key值劃入RDV中的概率,將RDV中低于閾值θ(θ參考值為4~9)的數(shù)據(jù)區(qū)間和單Key值所對(duì)應(yīng)的(Ki,Ci)按序插入到RDL中。
②根據(jù)虛擬分區(qū)數(shù)量v,分別將數(shù)據(jù)集RDL和RDV以鍵值數(shù)量Ci均勻分割v份,得到連接數(shù)據(jù)分割區(qū)間{L1,L2,…,Lv}和連接噪聲分割區(qū)間{V1,V2,…,Vv}。
分割算法:
輸入:數(shù)據(jù)集RDL和RDV,用U={U[0],U[1],…,U [n-1]}表示
輸出:區(qū)間{L1,L2,…,Lvv}和{V1,V2,…,Vv},用P={P [0],P[1],…,P[v-1]}表示
1.Cur_key←U[0].K Cur_size←U[0].CP[0]←U [0]i←0 j←0
2.Avg_size←Sum(U[0].C+U[1].C+…+U[n-1]. C)/v
3.while i<v do
4.while U[j+1].C/2<=Avg_size-Cur_size do
5.Cur_size←Cur_size+U[j+1].C
6.P[i]←P[i]U.[j+1]
7.j++
8.end while
9.i++
10.end while
(3)映射關(guān)系建立和執(zhí)行連接階段
輸入:分割區(qū)間{L1,L2,…,Lvv}和{V1,V2,…,Vv}
輸出:映射 MapPartition{(H1,Hk+1,…,H(α-1)k+1→R1),(H2,Hk+2,…,H(α-2)k+2→R2),…,(Hk,H2k,…,Hαk→Rk)}
①合并區(qū)間{L1,L2,…,Lv}∩{V1,V2,…,Vv},得到虛擬區(qū)間H={L1V1,L2V2,…,LvVv}
②采用輪轉(zhuǎn)法建立虛擬區(qū)間H到處理區(qū)間R的交叉映射關(guān)系MapPartition{(H1,Hk+1,…,H(α-1)k+1→R1),(H2,Hk+2,…,H(α-1)k+2→R2),…,(Hk,H2k,…,Hαk→Rk)},其中Hαk=Lv∪Vv。
③把映射關(guān)系MapPartition用分布式緩存機(jī)制發(fā)送到各個(gè)mapper節(jié)點(diǎn)上。
④每個(gè)mapper根據(jù)射關(guān)系MapPartition判斷數(shù)據(jù)的劃分,將其對(duì)應(yīng)的劃分編號(hào)關(guān)聯(lián)到(Ki,Ci)對(duì)上,然后劃分器會(huì)將其解碼得到劃分編號(hào),最后根據(jù)劃分編號(hào)把(Ki,Ci)對(duì)發(fā)送給對(duì)應(yīng)的reducer。
⑤執(zhí)行等值連接,得到結(jié)果。由于使用了相同映射關(guān)系,所以每個(gè)reducer上的RD1和RD1分區(qū)的K值是相同的,reduce任務(wù)作Hash連接,將RD1和RD1分區(qū)中Hash值相同的所對(duì)應(yīng)的value進(jìn)行連接。
4 實(shí)驗(yàn)及結(jié)果分析
實(shí)驗(yàn)在4臺(tái)計(jì)算機(jī)虛擬出的Spark集群上進(jìn)行,其中一個(gè)NameNode節(jié)點(diǎn),一個(gè)SecondaryNameNode和20個(gè)worker節(jié)點(diǎn),其中CPU為Intel四核i5-3470@ 3.2GHz,內(nèi)存8GB,硬盤1TB 7500RPM,網(wǎng)絡(luò)100Mbps。軟件平臺(tái):操作系統(tǒng)Ubuntu 14.04 LTS 64,Spark 1.1.0使用yarn模式,Hadoop 2.4.1,Scala 2.10.4。文中使用Pavlo等人的基準(zhǔn)測(cè)試程序[19],來(lái)對(duì)比分析有傾斜數(shù)據(jù)的連接優(yōu)化算法。具體查詢語(yǔ)句如下:
SELECT sourceIP,AVG(pageRank),SUM(adRevenue)as totRevenue
FROM rankings AS RK JOIN uservisits AS UV ON RK.pageURL=UV.destURL
WHERE UV.visitDate BETWEEN date(xxx)AND date(xxx),GROUP BY UV.sourceIP
實(shí)驗(yàn)一,該基準(zhǔn)測(cè)試用于計(jì)算每個(gè)IP在某段時(shí)間訪問該網(wǎng)站的總廣告收入,數(shù)據(jù)集包含rankings表10GB和uservisits表200GB,為分析不同傾斜數(shù)據(jù)對(duì)性能的影響,從給定的數(shù)據(jù)集中分別抽取四個(gè)不同時(shí)間段的數(shù)據(jù),每段時(shí)間的數(shù)據(jù)傾斜度不同。每個(gè)時(shí)段執(zhí)行時(shí)間為6次查詢的平均數(shù)。
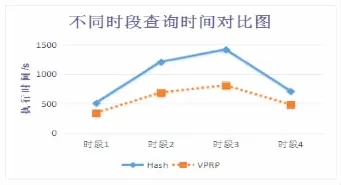
圖1 不同傾斜度下查詢時(shí)間對(duì)比圖
如圖1所示,橫坐標(biāo)表示分別取查詢中的不同時(shí)間段,縱坐標(biāo)表示查詢優(yōu)化前后的運(yùn)行時(shí)間。由于時(shí)間段1與時(shí)間段4的區(qū)間數(shù)據(jù)傾斜不太嚴(yán)重,所以系統(tǒng)性能不太明顯;而時(shí)間段2與時(shí)間段3的數(shù)據(jù)傾斜嚴(yán)重,所以性能提升顯著。
實(shí)驗(yàn)二,為考慮連接噪聲是否均衡對(duì)整體性能的影響,選取時(shí)段3的數(shù)據(jù),分別按照比例15%、35%、55%、75%、95%隨機(jī)采樣,對(duì)各個(gè)樣本集添加無(wú)用的噪聲數(shù)據(jù)達(dá)到與源數(shù)據(jù)相同的規(guī)模,使得各個(gè)樣本集的數(shù)據(jù)傾斜度近似相同,而連接噪音逐步遞減。給出不考慮連接噪聲影響的算法VPRP-T(即將虛擬區(qū)間劃分階段的輸入改為樣本集(RD1)sample(RD2)sample,且略過(guò)Step1)與VPRP進(jìn)行對(duì)比實(shí)驗(yàn)。
如圖2所示,橫坐標(biāo)表示參與連接數(shù)據(jù)占總數(shù)據(jù)量的比值,縱坐標(biāo)表示查詢優(yōu)化前后的運(yùn)行時(shí)間。數(shù)據(jù)傾斜度和數(shù)據(jù)規(guī)模不變的情況下,連接數(shù)據(jù)所占比例與查詢時(shí)間成正比。連接數(shù)據(jù)所占比值太大或太小(低于15%或高于95%),其分配的均衡程度對(duì)整體性能的影響較小,反之,連接計(jì)算量分配的不均衡,對(duì)整體的性能影響相對(duì)較大。綜上可知:當(dāng)數(shù)據(jù)傾斜嚴(yán)重時(shí),本文提出的基于虛擬處理區(qū)間劃分算法VPRP,由于考慮了節(jié)點(diǎn)間的數(shù)據(jù)量和實(shí)際連接數(shù)據(jù)的均衡分配,性能提升明顯。
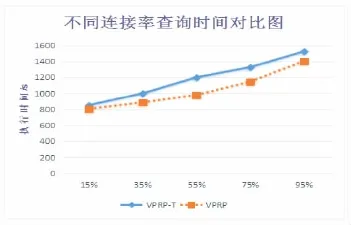
圖2 相同規(guī)模數(shù)據(jù)不同連接率查詢時(shí)間對(duì)比圖
5 結(jié)語(yǔ)
本文給出了一種基于虛擬處理區(qū)間劃分和交叉映射的連接算法VPRP,該算法通過(guò)虛擬處理區(qū)間劃分和交叉映射,保證了shuffle階段數(shù)據(jù)量和連接噪聲的均勻分配,實(shí)現(xiàn)了各個(gè)處理區(qū)間的負(fù)載均衡。該算法與Hash連接算法在Spark集群上進(jìn)行對(duì)比實(shí)驗(yàn),結(jié)果表明該算法能有效解決連接中的數(shù)據(jù)傾斜問題。但是該算法并沒有考慮如何優(yōu)化分配Reduce任務(wù),提高數(shù)據(jù)本地化程度,這將成為下步研究的重點(diǎn)方向。
[1]Blanas S,Patel J M,Ercegovac V,et al.A Comparison of Join Algorithms for Log Processing in MapReduce[C].Proceedings of the 2010 ACM SIGMOD International Conference on Management of data.ACM,2010.
[2]卞昊穹,陳躍國(guó),杜小勇,等.Spark上的等值等值連接優(yōu)化[J].華東師范大學(xué)學(xué)報(bào):自然科學(xué)版,2014.
[3]翟紅敏,劉國(guó)華,趙威,等.MapReduce中等值連接負(fù)載均衡優(yōu)化研究[J].計(jì)算機(jī)工程與科學(xué),2014.
[4]吳磊.基于hadoop的等值連接算法中數(shù)據(jù)傾斜問題的研究[D].中國(guó)科學(xué)技術(shù)大學(xué),2014.
[5]Chen Q,Yao J,Xiao Z.LIBRA:Lightweight Data Skew Mitigation in MapReduce[J].IEEE Transactions on Parallel&Distributed Systems,2015.
[6]Atta F,Viglas S D,Niazi S.SAND Join—A Skew Handling Join Algorithm for Google's MapReduce Framework[C].Multitopic Conference(INMIC),2011 IEEE 14th International.IEEE,2011.
Equi-Join;Load Balancing;Data Skew;Range Partition
A Load Balanced Equi-Join Algorithm Based on Virtual Processor Range Partition
HU Zhong-kui1,QU Bo2,HUANG Bin1,LI Wen-yang1
(1.College of Computer Science,Sichuan University,Chengdu 610065)2.78098 PLA Troops,Chengdu 611200)
1007-1423(2016)03-0003-05
10.3969/j.issn.1007-1423.2016.03.001
胡忠奎(1981-),男,遼寧海城人,碩士研究生,研究方向?yàn)榇髷?shù)據(jù)分析
屈波(1976-),男,成都崇州人,講師,研究方向?yàn)榉植际胶透咝阅苡?jì)算
黃斌(1986-),男,云南曲靖人,碩士研究生,研究方向?yàn)樾畔踩?/p>
黎文陽(yáng)(1990-),男,河南信陽(yáng)人,碩士研究生,研究方向?yàn)榉植际脚c數(shù)據(jù)庫(kù)
2015-12-18
2016-01-15
數(shù)據(jù)分析和處理是大數(shù)據(jù)處理中最重要的任務(wù),而等值連接又是數(shù)據(jù)分析中最常用、代價(jià)最高的操作之一。在實(shí)際的等值連接操作中,存在一個(gè)重要的問題就是數(shù)據(jù)傾斜:分配到每個(gè)任務(wù)的數(shù)據(jù)量不均衡,造成部分任務(wù)的完成時(shí)間更長(zhǎng),致使連接性能受到嚴(yán)重影響。為解決這個(gè)問題,提出一種負(fù)載均衡的等值連接算法(VPRP),通過(guò)采樣估計(jì)數(shù)據(jù)集在連接屬性上的數(shù)據(jù)分布情況,并采用虛擬分區(qū)和交叉映射的方法,在傾斜嚴(yán)重的數(shù)據(jù)周圍劃分出更多的區(qū)間,以增加數(shù)據(jù)分配的均衡性,同時(shí)消減連接噪聲對(duì)整體性能的消極影響,最后實(shí)驗(yàn)驗(yàn)證該算法的有效性。
等值連接;負(fù)載均衡;數(shù)據(jù)傾斜;范圍分割
Data analysis and processing is one of the most important tasks in large-scale distributed data processing applications.Join operations is one of the most common and costly in data analysis.One significant issue in practical Join operations is data skew:the imbalance in the amount of data assigned to each task.This causes some tasks to take much longer to finish than others and can impact performance.To solve data skew,presents a load balancing Join algorithm.It uses sampling method which can achieve a highly accurate approximation to the data distribution of connection properties.It can detect the data which is useless for the join operations to reduce Negative influence so as to realize load balancing.It uses the method of the virtual processor range partition and cross mapping to control the data skew which can improve the efficiency of equl-Join obviously.The simulation and experimental results show the algorithm proposed efficient.
