Git版本庫全文檢索系統的設計與實現
2016-09-20 08:14:28高毅任洪敏
現代計算機 2016年21期
高毅,任洪敏
(上海海事大學信息工程學院,上海 201306)
Git版本庫全文檢索系統的設計與實現
高毅,任洪敏
(上海海事大學信息工程學院,上海 201306)
隨著Git版本控制系統應用的日益廣泛,Git版本庫中的文檔資料也越來越多。基于Lucene的Git版本庫搜索引擎針對Git版本庫中的文件建立索引并進行搜索。該搜索系統通過Git的鉤子機制異步地建立索引,在檢索時使用了基于J2EE的架構。首先對Lucene、jGit等相關工具包進行研究,然后對索引模塊、檢索模塊等進行設計,最后編程實現和測試分析。系統實現的Git版本庫中文件的全文檢索,為Git版本庫提供Web化的檢索方式,同時也是對Lucene應用領域的探索。
Git;Lucene;全文檢索;搜索引擎
0 引言
Git是Linus開發的一個用于Linux內核代碼管理的分布式版本控制工具[1]。基于Git的客戶端管理工具如Git bash能用命令的形式對版本庫中文件進行查找,但這種方式使用不方便、也不直觀。為版本庫提供一種Web化的檢索方式,將提升用戶檢索的體驗。
針對版本庫中文件數據的特征,全文檢索技術是管理這些數據的有效方式,它能根據文件的內容進行處理和定位。Lucene是實現全文檢索的工具包,為實現Git版本庫的檢索提供了可能[2]。
本文通過研究Lucene在各個領域的應用,結合開源框架Spring和Spring MVC[3],設計了Java EE架構的全文檢索系統。改進了Lucene的分詞器,更好地支持中文分詞;使用開源的文本抽取工具Tika為文本內容抽取提供了統一的編程接口;將Git鉤子和Java異步編程結合,實現了異步索引;設計并實現了針對Git版本庫中的海量數據的全文檢索系統。
1 系統結構與功能分析
1.1 系統結構
全文檢索是一種將文件中的所有文本與檢索項匹配的文字資料檢索方法[4]。一般包括索引程序根據文件內容建立索引、檢索程序根據用戶的搜索關鍵字對已建立的索引進行查找并反饋查找結果等步驟。
本系統按照全文檢索理論針對Git版本庫為用戶提供全文檢索服務。在系統結構上有索引數據庫數據搜集、處理查詢及展示結果集等全文檢索核心功能。Git倉庫及訪問、索引引擎、查詢引擎、文本分析引擎及Web相關功能構成了整個系統。本系統結構如圖1所示。
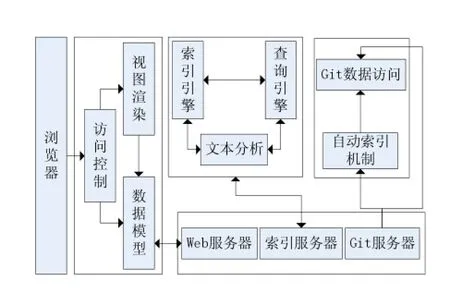
圖1 系統結構
1.2 功能分析
本系統主要實現了Git倉庫的異步索引和檢索兩大主要功能。其中,異步索引功能是針對用戶的提交操作觸發Git鉤子,由鉤子腳本調用索引模塊完成Git倉庫的索引的創建。在異步索引的過程中,要經過數據提取與轉換模塊、文本分析模塊才能建立索引。這是由于在Git倉庫中可能包含多種格式的文件,如txt、html、word、excel、pdf等,而Lucene的索引機制只能對文本文件建立索引[5],所以在做索引之前必須做數據轉換,即提取各種格式文件的文本信息,這一功能由數據提取與轉換模塊完成。在提取文本數據之后,要由分詞器對文本信息做分詞處理,該功能由文本分析模塊完成。
檢索功能是本系統的核心功能。用戶通過檢索頁面輸入檢索關鍵字提交檢索請求后,經過文本分析模塊、查詢模塊后將匹配結果集返回。各模塊流程如圖2所示。
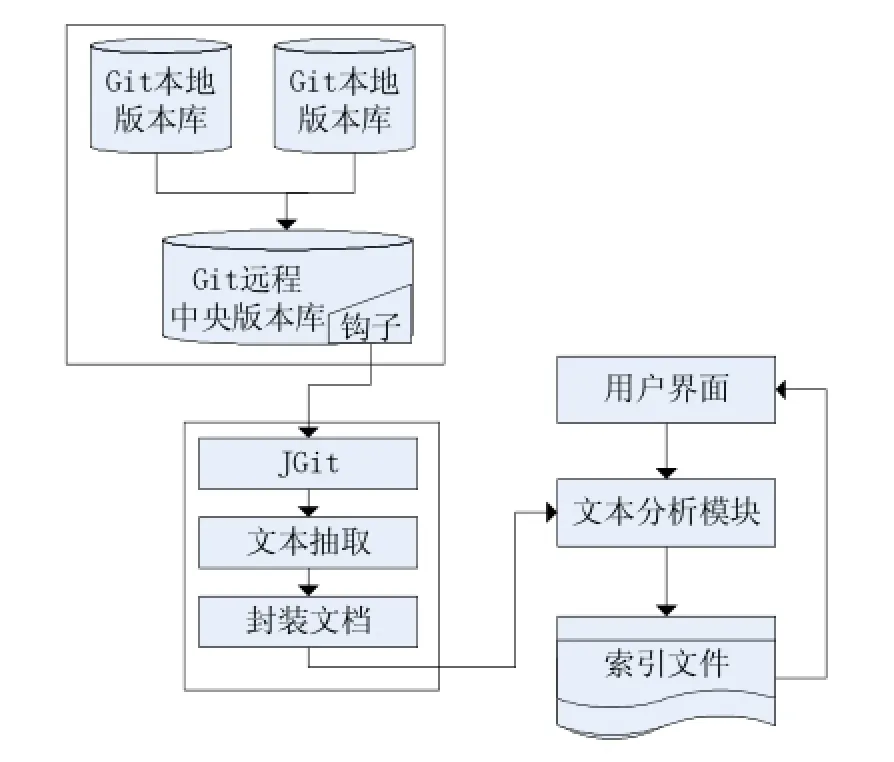
圖2 模塊流程圖
2 系統設計
2.1 Git鉤子和異步索引機制【6】
在Git版本庫的版本庫目錄下有一個hooks目錄,該目錄是Git版本庫的鉤子腳本目錄,也是實現所有與鉤子相關功能的關鍵。這些鉤子腳本能在特定的條件下被觸發,從而可以利用該機制設計基于鉤子的異步索引。在共享版本庫中我們使用的是“update”腳本,要使該腳本生效只要去掉其文件的擴展名.sample即可。
在本系統中在共享版本庫中設置該鉤子,在本地的版本庫向其推送時觸發腳本,執行索引程序。工作流程如圖3所示。
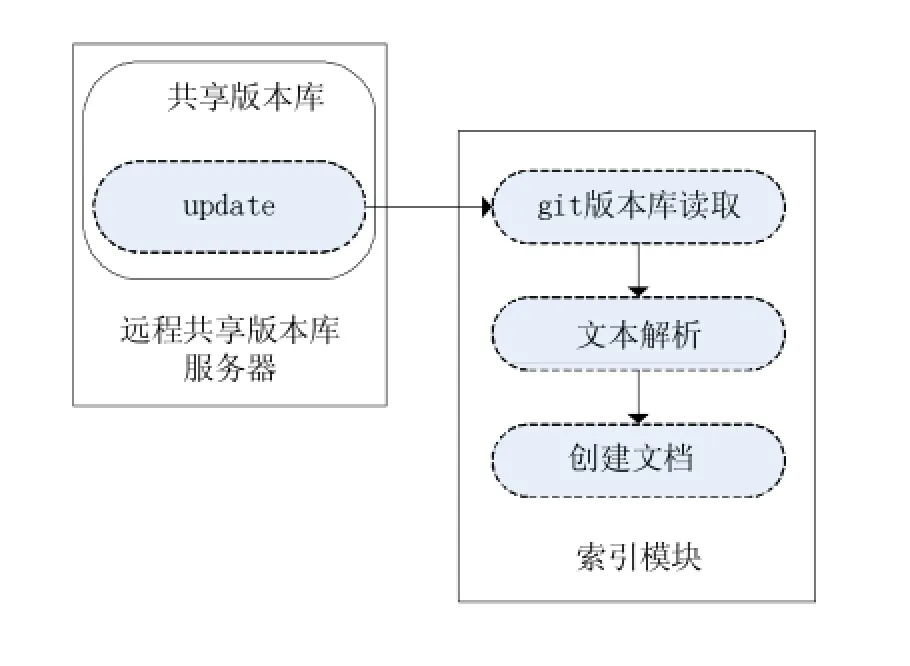
圖3 基于鉤子的異步索引機制
2.2 增量化索引
在Lucene中增量索引是指每次有新的數據源要索引時只對新增的數據做索引而不需改變原來的索引數據。根據Git版本庫的特點,本系統采用增量索引的方式做索引。在一次提交中可能包含若干發生變化的文件,采用增量索引,只對這些發生變化的文件做索引。這種索引方式不僅提高了索引的效率,對于檢索的查全率也有重要影響[7]。
做增量索引時,首先要獲取在一次提交中發生變化的文檔的集合,然后遍歷該集合,刪除與每一個文檔相關聯的對象塊。下一步又分為兩種情況,若發生變化的文檔的變化類型是被刪除的,則不做任何索引處理;若是其他變化類型,如修改,則對該文檔重新建立索引。總之索引數據庫中保存的總是文檔的最新修改狀態的數據形式。邏輯流程如圖4所示。
2.3 文檔解析模塊設計
文檔解析是指通過相關的工具對各種格式的文檔進行轉換并解析出文本內容。文檔解析模塊的意義在于為索引文檔提供統一的數據格式。在Git版本庫中可能存在有各種格式的文檔如word、excel、pdf及普通的txt文檔,使用jGit工具讀取Git版本庫中的數據后,可以得到字節數組形式的數據。Lucene內部只能對純文本格式的數據建立文檔,而對于其他類型的文檔,不能建立索引,這也是做文檔解析的必要性所在。故在做索引前必須將各種類型的文檔轉換成文本文檔。通過分析Lucene的API發現其提供了文檔類型的描述類Document類和關于域信息的描述類 Field類,其中Document代表被索引的一個文檔,Field代表文檔的一個域信息,如文檔內容等。也就是說在實際使用時我們不必將各種格式的文檔轉換為文本文檔,只需提取出各類型文檔的文本內容即可。文檔解析模塊是索引的前提和基礎,如果不能順利提取文本內容索引也將無法建立。
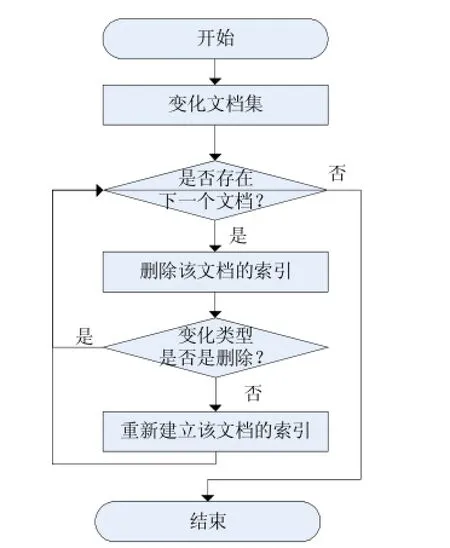
圖4 增量索引邏輯流程圖
文檔解析的實現邏輯[8]:
文檔解析模塊使用解析框架Tika,Tika是使用Java語言實現的并且是Apache下的開源項目。它能探測并從各種常見的文件中提取包括文本和元信息在內的數據。多文檔解析的示意圖如圖5所示。
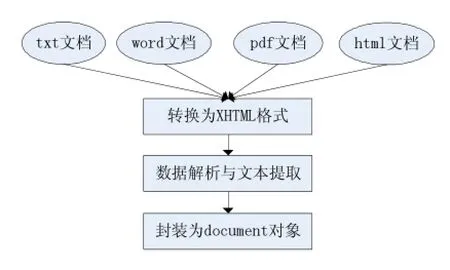
圖5 文檔解析流程
3 系統實現
3.1 異步索引的實現
“update”腳本在整個推送過程完成后運行。修改該腳本后大致內容如下:
#!/bin/sh
refname="$1"
cd$GIT_DIR/tool
uname=$(git config--get user.name)
java-Duser=$uname -Dbranch=$refname -Dfile. encoding=utf-8-jar index.jar
該腳本能在本地倉庫向遠程倉庫推送完成后執行,執行過程中首先接收參數refname,其代表推送的分支。然后調用索引模塊index.jar完成索引的構建。
在索引時使用了Java線程池和FutureTask類:
ExecutorService executorService = Executors.new-FixedThreadPool(5);
Task task=new Task();
FutureTask<Integer>futureTask=new FutureTask<>(task);
executorService.submit(futureTask);executorService.shutdown();
3.2 增量索引的實現
通過分析增量索引的邏輯流程,可知要實現增量索引首先要獲取在一次提交中發生變化的文檔集,獲取文檔集的核心代碼如下:
//the list of files changed in a commit
List<PathChangeModel>list=new ArrayList<PathChange-Model>();
......
List<DiffEntry>diffs=df.scan(parent.getTree(),commit. getTree();
for(DiffEntry diff:diffs){
//create the path change model
PathChangeModel pcm=PathChangeModel.from(diff,commit.getName();
if(calculateDiffStat){
//update file diffstats
df.format(diff);
PathChangeModel pathStat=df.getDiffStat(). getPath(pcm.path);if(pathStat!=null){
pcm.insertions=pathStat.insertions;pcm.deletions=pathStat.deletions;}
}
list.add(pcm);
}
然后遍歷該文檔集,刪除每個文檔對應的索引:
//delete the indexed blob
deleteBlob(repositoryName,branch,path.name){
......
}
接下來判斷變化文件的變化類型,若是刪除則什么也不做;若不是則重建索引。
//re-index the blob
if(!ChangeType.DELETE.equals(path.changeType){
//the file deleted is not indexed
result.blobCount++;
Document doc=new Document();
doc.add(new Field(FIELD_OBJECT_TYPE,SearchObjectType.blob.name(),StringField.TYPE_STORED);
......
//file name
doc.add(new Field(FIELD_NAME,path.name,TextField. TYPE_STORED);
//determine extension to compare to the extension //blacklist
String ext=null;
String name=path.name.toLowerCase();if(name.indexOf('.')>-1){
ext=name.substring(name.lastIndexOf('.')+1);}
if(StringUtils.isEmpty(ext)||!excludedExtensions.contains(ext){
//read the blob content
Stringstr= JGitUtils.getStringContent(repository,commit.getTree(),path.path,encodings);
if(str!=null){doc.add (new Field (FIELD_CONTENT,str,TextField.TYPE_STORED);writer.addDocument(doc);}
}
}
3.3 文檔解析的實現
通過在設計章節對文檔解析模塊的分析,本系統使用開源的文本提取工具Tika提取各種格式文檔的文本數據,它為文本抽取提供了統一的編程接口。實現文本抽取的核心代碼如下:
①ByteArrayInputStream in=new ByteArrayInput-Stream(content);
②ContentHandler contentHandler=new BodyContentHandler();
③Metadata metadata=new Metadata();
④Parser parser=new AutoDetectParser();
①中是讀取被解析的文件保存在字節數組content中,這時在程序內部會建立XHTML形式的數據結構,然后②中創建一個ContentHandler的子類的實例,本系統使用的是BodyContentHandler類,它能讀取<body></ body>標簽之間的文本內容并保存在 contentHandler中。③中是創建了一個默認設置的元信息對象。④中創建了一個自動探測解析類型的解析器,它會探測文檔的類型然后調用相應的解析器。
3.4 索引的實現
在實現時具體的過程如下:
(1)搜集用戶輸入的查詢關鍵詞及過濾條件,并作初步的客戶端驗證。
(2)創建查詢解析器QueryParser對象以解析用戶輸入,在創建對象時傳入解析器作為構造的參數。
(3)創建BooleanQuery對象以封裝多個子查詢。(4)創建IndexSearcher對象和TopScoreDocCollector容器對象,并執行查詢方法,將結果集寫入容器。
(5)以分頁顯示的方式從容器中取得本頁數據,并放入ScoreDoc類型的數組中。
(6)遍歷數組,返回結果集。
檢索功能的核心代碼如下:
//result set
Set<SearchResult> results= new LinkedHashSet<SearchResult>();
IKAnalyzer analyzer=new IKAnalyzer();try{
BooleanQuery query=new BooleanQuery();
QueryParser qp;
if(StringUtils.isEmpty(fname){
//search by content
//default search checks content qp=new QueryParser(LUCENE_VERSION,FIELD_CONTENT,analyzer);
qp.setAllowLeadingWildcard(true);
query.add(qp.parse(text),Occur.SHOULD);}else if(StringUtils.isEmpty(text){
//search by filename…………}else{
//search by filename and content…………}
//searcher
IndexSearcher searcher=getIndexSearcher(repositories[0]);
Query rewrittenQuery=searcher.rewrite(query);
TopScoreDocCollector collector=TopScoreDocCol lector. create(5000,true);
searcher.search(rewrittenQuery,collector);
int offset=Math.max(0,(page-1)*pageSize);
ScoreDoc[]hits=collector.topDocs(offset,pageSize).score-Docs;
int totalHits=collector.getTotalHits();for(int i=0;i<hits.length;i++){
int docId=hits[i].doc;
Document doc=searcher.doc(docId);
//search result
SearchResult result=createSearchResult(doc,hits[i]. score,docId,offset+i+1,totalHits);
result.repository=repositories[0];
String content=doc.get(FIELD_CONTENT);if(content.length()>50){
//the number of display
content=content.substring(0,50);
}
result.fragment=getHighlightedFragment(analyzer,query,content,result);
results.add(result);
}
系統實現的檢索結果頁面如圖6所示。
圖6 檢索界面
4 系統測試分析
系統測試環境中CPU為Intel Core i3-3110M CPU @2.40GHz,內存為4GB。以txt、docx、pdf三種文檔格式作測試,數據大小級別分別為10KB、100KB、1000KB。測試結果如表1所示。測試結果表明,文件類型和大小對索引的建立速度有直接的影響,而對檢索速度影響不大。由于在實際環境中,更頻繁的操作是檢索,故能基本滿足用戶對Git倉庫的檢索需求。
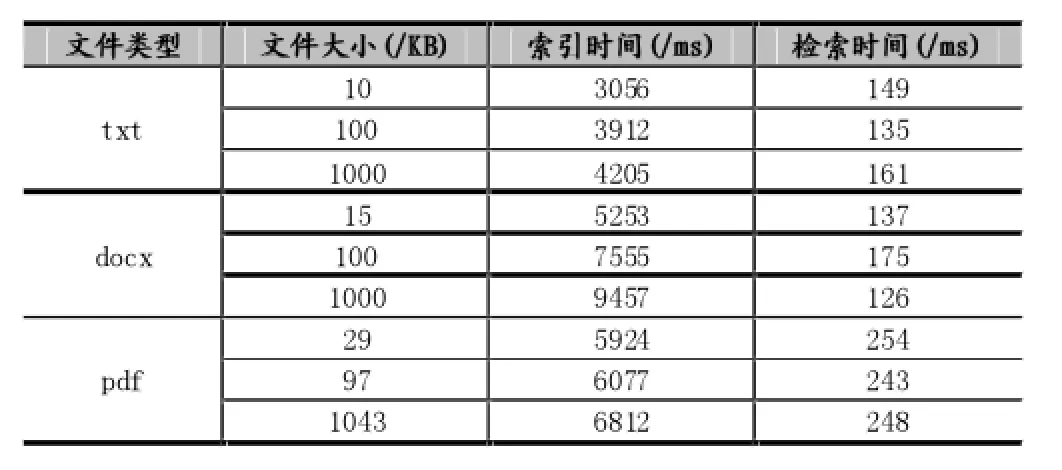
表1 系統測試結果
5 結語
本文在研究了Git的工作原理和開源檢索框架Lucene的基礎上,對多格式文檔內容進行提取,設計并實現了一個基于Git倉庫的全文檢索系統。 系統能根據用戶輸入的關鍵字和文件名定位索引庫中的文件。系統主要在兩方面需要改進,其一對中文分詞的進一步優化,提高分詞精度;其二在面對海量數據檢索時,檢索的準確性和效率。
[1]蔣鑫.Git權威指南[M].北京:機械工業出版社,2011.
[2]Apache Software Foundation.Lucene Java Documentation[DB/OL].http://lucene.apache.org/core/3_0_3/index.html,2013-06-21.
[3]王福強.Spring揭秘[M].北京:人民郵電出版社,2009.438-580.
[4]周敬才.基于Lucene全文檢索系統的設計與實現[J].計算機工程與科學,2015,37(2):2-3.
[5]牛長流.Lucene實戰[M].北京:人民郵電出版社,2011.32-73.
[6]王文龍.分布式軟件開發平臺的設計與實施[D].北京郵電大學,2011.
[7]江毅銘.專業搜索引擎技術的研究與實現[D].北京化工大學,2005.
[8]Apache Software Foundation.Apache Tika Document[DB/OL].http://tika.apache.org/1.12/parser.html,2016.
[9]O'Reilly Taiwan公司譯.Shell腳本學習指南[M].北京:機械工業出版社,2009.
Design and Implement of Git Repository Search Engine
GAO Yi,REN Hong-min
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
With Git version control system applications increasingly widespread,Git repository documentation is also increasing.Lucene-based Git repository search engine indexing for Git repository file and search.The search system indexed by the hook mechanism Git asynchronously,when used in the retrieval based on J2EE architecture.First,Lucene,jGit kits and other related research,and then indexing module,searching module design,programming and final test analysis.System to achieve full-text search Git repository file with a Git repository provides a Web-based retrieval methods,but also the exploration of Lucene applications.
1007-1423(2016)21-0071-06
10.3969/j.issn.1007-1423.2016.21.017
高毅(1987-),男,山東青島人,碩士研究生,研究方向為信息系統與電子商務任紅敏(1969-),男,上海人,博士,副教授,研究方向為軟件體系結構、構件技術、軟件復用、過程工程、軟件項目管理,基于社會計算、群體智能、人本計算、社會網絡、輿情分析等技術的軟件資產管理、船舶協同設計知識管理等
2016-05-06
2016-07-15
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
甘肅教育(2020年8期)2020-06-11 06:10:02
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:48:08
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
電子制作(2018年18期)2018-11-14 01:48:06
家庭影院技術(2017年9期)2017-09-26 03:41:45
小學教學參考(2015年20期)2016-01-15 08:44:38
