基于機器學習方法的強對流天氣識別研究
2016-09-08 06:13:10修媛媛馮海磊
電子設計工程 2016年9期
修媛媛,韓 雷,馮海磊
(中國海洋大學 信息科學與工程學院,山東 青島 266100)
基于機器學習方法的強對流天氣識別研究
修媛媛,韓 雷,馮海磊
(中國海洋大學 信息科學與工程學院,山東 青島266100)
用機器學習中有監督學習模型支持向量機SVM來進行強對流天氣的識別和預報。強對流天氣的發生可以看作是小概率事件,因此強對流天氣的預警問題可以作為不平衡數據分類問題來處理。在SVM的應用上結合判別準則來對不平衡數據進行處理,更好的對強對流天氣進行預警。本文從數據的獲取、訓練算法的選擇、算法的應用、實驗結果的評估幾個方面進行了詳細的描述。通過采用丹佛地區的數據進行大量試驗,排除了不平衡數據對分類的干擾,提高了強對流天氣識別的準確度。
強對流天氣預警;SVM;不平衡數據分類;機器學習
強對流天氣[1]是常見的一種氣象災害,具有生命史短暫、發展移動速度快的特點,往往會給人民的工作生活帶來不便,對農業生產、國家財產等造成威脅。多普勒雷達資料以其較高的時空分辨率在臨近預報及天氣預警方面具有獨特的優勢,氣象業務上強對流天氣預警主要依賴于雷達的實時監測[2]。NCAR(National Center for Atmospheric Research國家大氣研究中心)研究出的多普勒雷達四維變分分析系統[3](The four-dimensional Variational Doppler Radar Analysis System,VDRAS)能夠給出反映低層大氣熱動力特征的實時分析場,是強對流行天氣臨近預報的有力工具。
目前的氣象臨近預報方法[4]主要有概念模型預報[5]、數值模式預報[6]、外推法預報[7]等。概念模型預報技術主要是通過綜合分析多種觀測資料,包括常規探測資料和遙感資料等在此基礎上建立雷暴發生、發展、消亡的概念模型,再結合數值模式預報和其他外推方法的結果,最終建立對流性天氣的臨近預報專家系統,如NCAR的ANC(Auto Nowcaster)預報系統[8]。精細化的數值天氣預報技術是未來強對流天氣短時臨近預報的重要發展方向[9]。利用多普勒雷達資料和其他常規觀測資料進行數值模式初始化進而預報中尺度對流系統的發生、發展和消亡已經取得了重要進展。
文中使用VDRAS模式實時反演的低層大氣分析場數據,結合機器學習中的基于統計學習理論的支持向量機方法[10],針對強對流天氣進行臨近預報。首先用VDRAS系統反演得到對流天氣的數值模式數據和雷達組合反射率,然后用SVM對不平衡數據[11]進行預報,最后通過評分準則來解決不平衡數據造成的預測結果不均衡。
1 算法設計與實現
文中使用美國國家大氣研究中心(NCAR)的VDRAS模式輸出的高時空分辨率的實時分析場數據,構建基于box的特征,以美國NEXRAD[12]多普勒雷達數據作為驗證的真值,然后利用SVM算法進行訓練和預測。
1.1數據的選擇
VDRAS系統反演得到的物理量有46個,根據其物理意義和多次實驗選出能有效強對流預警的特征(預報因子)。文中所用的預報因子有6個,分別為:rh(relative humidity相對濕度),w(wind垂直風速度),div(divergence輻合抬升),byc (bouyance距平溫度),sh(shear風切變),gsh(gshear梯度風切變)。
本論文中所用的VDRAS系統、數據資料均來自NCAR,研究區域為美國丹佛地區。由于風暴是運動的,所以沒有采用點對點的預報,而是采取劃分子塊的方式,以6km*6km大小的方塊為單位(1個box,即一個box中的所有特征為一個樣本),選取方塊中的最大值作為該子塊的值寫入數據。采取這種方式的原因有兩個,一是如果采取點對點的方式進行數據讀取,會造成數據資料過多,會產生許多冗余信息,最終會導致計算量過大,速度過慢;二是因為考慮到實際的強對流天氣并不會僅僅只是發生在某一個點上。因此,采用劃分子塊的方式選是可行的。
1.2數據的預處理
將上述6個預報因子作為樣本的屬性特征,并利用30 min后的雷達組合反射率(radar composite)作為樣本的標簽。設定標簽(label)的基本思想為:將雷達組合反射率的值大于等于35 dbz的樣本記為正類(label值為+1),小于35 dbz的樣本記為負類(label值為-1)。
樣本數據的預處理(不包括radar composite)主要分為兩步:差分和歸一化[13]。
差分:在天氣的變化過程中,相鄰時刻的數據在物理意義上是有關聯的。隨著時間的推移,數據的變化反映了天氣的變化。而相鄰時刻數據的差值能反映出天氣的變化趨勢,知道變化趨勢能更好的對CI預報,因此本文用向后差分來記錄下時間增量信息。具體差分公式如下:

歸一化:由于本實驗樣本數較多,且數據分布較為發散。通過歸一化讓權重變為統一,且歸一化后可以加快梯度下降求最優解的速度,也有可能提高精度。目前,主流的歸一化方法有兩種。通過實驗,發現線性函數歸一化能使預報更加準確。因此本文使用的是線性函數歸一化。具體公式如下:

1.3算法的設計
1.3.1算法的設計
不平衡數據問題,即在分類問題中正負樣本的比例相差很大。在強對流天氣預警問題中,強對流天氣是屬于個別天氣,是少數類。因此,可以作為不平衡數據分類問題來處理。目前不平衡數據分類的相關解決方法主要從數據層面(改變數據的分類)、算法層面(設計新的分類方法)和判別準則(設計新的分類器性能評價準則)3個不同層面進行研究。
分類問題中,基于統計學習理論的支持向量機(Support Vector Machine,SVM)方法逐漸成為機器學習的重要研究方向。與傳統的基于經驗風險最小化原則的學習方法不同,支持向量機基于結構風險最小化,能在訓練誤差和分類器容量之間達到一個較好的平衡,它具有全局最優、適應性強、推廣能力強等優點。文中選用機器學習中常用的SVM算法作為分類器。
強對流天氣的發生可以看作是小概率事件,因此強對流天氣預警問題可以作為不平衡分類問題來處理。而現在機器學習大部分的學習算法是基于一個平衡的訓練集而設計的(包括SVM)。為了解決此類問題,文中將SVM和不平衡數據分類方法中的判別準則結合,用來對強對流天氣預警。
1.3.2評估方法
評價一個分類器的性能的好壞的一個關鍵因素是評分標準,評分標準將指導分類器模型的建立。在兩分類問題中,混淆矩陣(見表1)中記錄的是每一個類的正確和錯誤識別的結果。

表1 二分類問題下的混淆矩陣
由于在氣象預報領域和機器學習領域中各自存在不同的評分標準,本論文通過結合兩類評分標準以及不平衡數據分類的特點挑選出了合理的評分標準[14],做如下定義:
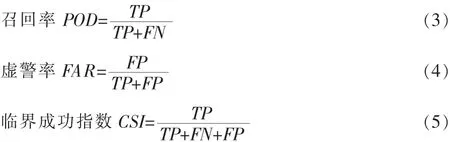
1.4算法的實現
文中通過用SVM分類器進行分類,然后對預測樣本輸出概率置信度,將其重新調整,從而獲得最優的分類結果。具體步驟如下:
1)從VDRAS中獲取實驗所需的數據;
2)對數據進行預處理;
本文中的預處理包括對原始數據進行差分和歸一化,并將所有的樣本數據分為訓練集和測試集兩部分。
3)用SVM對訓練集進行訓練,得到模型;
4)用3)所得的模型,對測試集進行預測,獲得每個樣本的置信度;
置信度(confidence)是一個概率值,下面的步驟會根據置信度將樣本預測為正類或者預測為負類。將此樣本劃分為正類的概率值稱為正例置信度。
5)通過調整閾值解決本實驗中所用的數據不均衡的問題。
文中的閾值亦為臨界值。由于SVM主要是應用于平衡數據集的分類,其默認的概率閾值為0.5,即當預測概率結果中正例置信度大于等于0.5的時候,分類為正樣本,小于0.5的時候分類為負樣本。由于本實驗的數據為非平衡數據,因此進行分類時,為獲得最優的分類結果,對概率閾值進行了調整,分別采用不同的閾值進行分類,并計算相應的評價指標,最后選取最優的評價指標。
文中主要應用的評價指標為POD、FAR、CSI。不同的閾值下評價指標結果不同,考慮到CI預警具有的實際意義,POD達到0.6的時候才具有實際應用價值,所以在選取評價指標結果的時候按照以下標準進行:因CSI指標綜合考慮召回率(POD)和虛警率(FAR),故首先觀察該指標,即不同置信度下,若CSI的指達到最大且POD的值大于等于0.6,則選擇該置信度下的評級指標結果;若CSI達到最大時POD的值小于0.6,則重新觀察不同置信度下POD的值,選擇POD達到0.6時,對應的置信度下的評價指標結果。
6)用feature selection分析預報因子的重要性
前面經過分析選取了6個預報因子,這6個預報因子連同其差分(12個特征)又進行了特征選擇實驗,主要用來獲取最重要的特征。具體實驗描述如下:依次去掉每個特征值和其對應的差分,用剩下的10個特征值進行訓練和預測,然后觀察每次的結果表現。實驗結果如圖1所示。
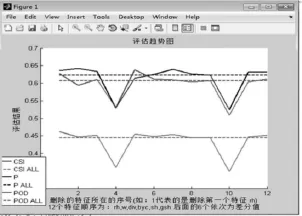
圖1 feature-selection實驗結果
圖1表明,當去掉byc及其差分dbyc的時候,CSI、P(這里的P為精確度,值的大小為1-FAR)和POD值都下降很多,由此可得出結論byc在整個預報過程中起重要作用。則,預報因子的貢獻率由高到低依次為:byc、w、gsh、div、sh、rh。
針對feature selection結果和在實際中特征值的物理意義,最終選取如下特征組合進行實驗:1)byc+dbyc 2)w+dw+ byc+dbyc 3)所有12個特征值。
2 實驗結果與分析
2.1實驗結果
下面是所做各種組合的實驗結果:(注:文中所用的POD 和CSI值是越大越好,而FAR越小越好 )
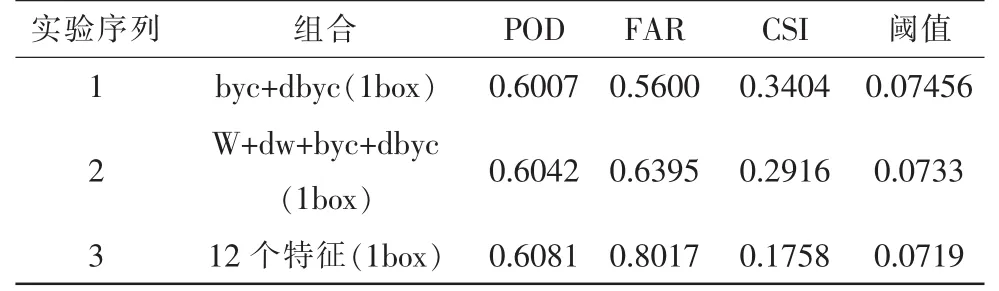
表2 SVM各種特征組合實驗結果表
由表2的實驗1、2、3結果可以看出在1個box試驗中byc+dbyc組合的實驗結果是最好的,它的CSI值為0.3404,而w+dw+byc+dbyc組合的CSI值為0.2916,12個特征的效果更差CSI為0.1758。
下面的結果顯示就是將實驗效果最好的組合 (實驗1:1box byc+dbyc組合和實驗2:9box w+dw+byc+dbyc組合)用CIDD[15]顯示出來,可以進一步觀察分類器的好壞。
2.2分析
論文主要是利用30 min后雷達組合反射率來標記標簽,對30 min后的天氣進行CI預報。本文實驗所用的是2012年前的5個案例做訓練集,2012年的2個案例做測試集,具體的預測結果可通過氣象中的VDRAS系統中的CIDD以圖像的方式顯示出來。下面對所用的結果預報圖和結果顯示圖進行分別說明:
1)結果預報圖:即,所用的背景雷達圖像是當前時刻的雷達圖像,而所用的預報結果是30 min之后的。圖中的白框表示當前時刻此處有強對流天氣的現象;黑框表示當前時刻存在強對流天氣,30 min后也存在強對流天氣;灰框表示的是本算法所預測出30 min后會出現強對流天氣,能很好的描述出強對流天氣的運動趨勢和發展方向。
2)結果顯示圖:即,所用的雷達圖像是30 min之后的,預報結果也是30 min之后的。圖像中的3種不同的框與結果預報圖中的表示有所不同:白色表示漏報,黑色表示預報正確,灰色表示的是誤報。此圖用來說明預報的是否準確。
結果分析:本實驗中用1個box byc+dbyc組合的樣本來訓練。在此實驗中,選取最優的閾值為0.074 56,評分結果如下:
POD為0.600 7;FAR為0.560 0;CSI為0.340 4;
1)圖2為2012年6月6日20時55分的預測結果的CIDD顯示圖(當前時刻為20時55分,預報為30分鐘之后的),圖(a)是結果預報圖,圖(b)是結果顯示圖。
由圖(a)看灰色框可以看出該天氣的運動趨勢,向圖所示的右上方發展。而在圖(b)的整個顯示區域中,黑框很好的展現出了預報結果,還是挺準確的。
2)圖3為2012年6月6日22時10分的預測結果的CIDD顯示圖,圖(a)是結果預報圖,圖(b)是結果顯示圖。
圖(a)中可以看出,此強對流天氣處于產生、發展、消亡中的發展階段。從整個3-2來看,研究區域中給出的預報結果基本上都覆蓋了出現強對流天氣的地方,雖然會出現少量誤報,但是整個區域的基本形狀還原程度還是比較高的。給出的預報結果與實際情況非常吻合。
3)圖4為2012年7月7日21時10分的預測結果的CIDD顯示圖,本圖為結果顯示圖。
這個是預測失敗的個例,由圖可以看出,本次的預測結果有些偏離強對流天氣發生的位置。圖的右下角區域還是可以預報出整個強對流天氣的大體位置,但周圍會出現一些的漏報和誤報;在圖的左上角區域不是漏報就是誤報,而左下角更是出現大片的誤報。出現這種預報結果,說明本文提出的預警算法還是有待于進一步完善。

圖2 2012年6月6日20時55分結果圖

圖3 2012年6月6日22時10分結果圖

圖4 2012年7月7日結果顯示圖3
3 結 論
文中主要用VDRAS的數值模式數據,結合機器學習中的SVM,針對強對流天氣進行臨近預報。首先用VDRAS系統反演得到實驗所需的數據并將數據做預處理;然后用SVM對不平衡數據進行訓練和預報;最后通過調整閾值(即修改評分準則)來解決不平衡數據造成的預測結果不均衡。為了直觀的觀察實驗結果的好壞,本文通過CIDD將預報結果直觀的展示出來。分析實驗結果,發現本文提供的算法在一定程度上提高了識別的精度,降低了虛假警報發生的概率。表明,該方法能很好地實現強對流天氣的臨近預報,但是本算法還有些缺陷需要改進,這也將是我們下一步的工作目標。例如:只能人工選取預報因子,這就增加了實驗的不確定性;劃分子塊上,文中用每個子塊區域中6*6格子中的最大值作為該子塊的值,雖然有效減少了計算量,但是也丟棄了一部分信息,因此應該由更加完善的做法在減少計算量的同時也保留信息。
[1]韓雷,俞小鼎,鄭永光,等.京津及鄰近地區暖季強對流風暴的氣候分布特征[J].科學通報,2009,54(11):1585-1590.
[2]趙暢.多普勒雷達及多源資料在局地短臨預報中的應用[D].南京:南京信息工程大學,2014.
[3]Sun J,Crook N A.Dynamical and microphysical retrieval from Doppler radar observations using a cloud model and its adjoint[J].Model development and simulated data experiments. J.Atmos.Sci.,1997(54):1642-1661.
[4]程叢蘭,陳明軒,王建捷,等.基于雷達外推臨近預報和中尺度數值預報融合技術的短時定量降水預報試驗 [J].氣象學報,2013,71(3):397-415.
[5]劉國忠,黃開剛,羅建英,等.基于概念模型及配料法的持續性暴雨短期預報技術探究[J].氣象,2013,39(1):20~27.
[6]王啟光,丑紀范,封國林.數值模式延伸期可預報分量提取及預報技術研究[J].中國科學,2014,44(2):343-354.
[7]陳雷,戴建華,徐強君.基于雷達回波外推技術的閃電臨近預報方法研究[C]//第九屆長三角氣象科技論壇論文集,2012.
[8]Wilson JW,Crook N A,Muller C K,et al.Nowcasting thunderstorms:a status report[J].Bull Amer Meteor Soc,1998,79 (10):2079-2099.
[9]鄭永光,張小玲,周慶亮,等.強對流天氣短時臨近預報業務技術進展與挑戰[J].氣象,2010,36(7):33-42.
[10]鄧乃揚,田英杰.數據挖掘中的新方法-支持向量機[M].北京:科學出版社,2004.
[11]葉志飛,文益民,呂寶糧.不平衡分類問題研究綜述[J].智能系統學報,2009,4(2):148-156.
[12]Bieringer P,P S Ray.A Compari son of tornado warning lead timeswithandwithoutNEXRADDopplerRadar[J]. WeaForecasting,1996(11):47-52.
[13]XIAO Han-guang,CAI Cong-zhong.Comparison study of normalization of feature vector[J].Computer Engineering and Applications,2009,45(22):117-119.
[14]石璐.基于數值模式和雷達數據的對流初生預警技術研究[D].青島:中國海洋大學,2015.
[15]陳明軒,俞小鼎,譚曉光,等.對流天氣臨近預報技術的發展與研究進展[J].應用氣象學報,2004,15(6):754-766.
The identification of strong convective weather based on machine learning methods
XIU Yuan-yuan,HAN Lei,FENG Hai-lei
(School of Information Science and Engineering,Ocean University of China,Qingdao 266100,China)
The present study was designed to use a supervised learning method-support vector machines SVM of machine learning to recognize and forecast the strong convective weather.The occurrence of strong convective weather can be seen as a small probability event,so this problems can be handled as imbalanced data classification.To make better forecast,on the application of SVM we proposed a new criterion for processing data on imbalances.This paper described the algorithm in several aspects:the data obtained,the training algorithm,the application of the algorithm,the assessment results.This paper used Denver area data,eliminated the interference of imbalanced data classification,and improved the accuracy of recognition of severe convective weather.
strong convective weather warning;SVM;unbalanced data classification;machine learning
TN957.52
A
1674-6236(2016)09-0004-04
2015-11-19稿件編號:201511181
國家自然科學基金(41005024)
修媛媛(1991—),女,山東聊城人,碩士研究生。研究方向:人工智能。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
