基于局部敏感核稀疏表示的視頻跟蹤
2016-08-26 05:56:51黃宏圖畢篤彥查宇飛侯志強
電子與信息學報 2016年4期
黃宏圖 畢篤彥 高 山 查宇飛 侯志強
?
基于局部敏感核稀疏表示的視頻跟蹤
黃宏圖*①③畢篤彥①高 山①查宇飛①侯志強②
①(空軍工程大學航空航天工程學院 西安 710038)②(空軍工程大學信息與導航學院 西安 710077)③(中國人民解放軍95972部隊 酒泉 735018)
為了解決范數約束下的稀疏表示判別信息不足的問題,該文提出基于局部敏感核稀疏表示的視頻目標跟蹤算法。為了提高目標的線性可分性,首先將候選目標的SIFT特征通過高斯核函數映射到高維核空間,然后在高維核空間中求解局部敏感約束下的核稀疏表示,將核稀疏表示經過多尺度最大值池化得到候選目標的表示,最后將候選目標的表示代入在線的SVMs,選擇分類器得分最大的候選目標作為目標的跟蹤位置。實驗結果表明,由于利用了核稀疏表示下數據的局部性信息,使得算法的魯棒性得到一定程度的提高。
視頻跟蹤;核稀疏表示;局部敏感約束;支持向量機
1 引言
視頻目標跟蹤是計算機視覺領域的基礎問題之一[1],廣泛應用于視頻監控、機器人導航、人機交互和精確制導等領域,是各種后續高級處理,如目標識別、行為分析、視頻圖像壓縮編碼和應用理解等高層視頻處理和應用的基礎。跟蹤面臨的挑戰從內外兩個方面來說包括目標內部變化和外界變化,其中目標內部變化包括旋轉、尺度變化和形變等,外界變化包括光照變化、遮擋和噪聲等。由于目標自身和外界環境變化的復雜性和不可預知性,使得魯棒實時的視頻目標跟蹤仍然是亟待解決的問題。
SRC(Sparse Representation-based Classifier)模型已經廣泛應用于人臉識別、圖像分類、圖像去噪、圖像分割、超分辨率重建、目標檢測和特征提取等計算機視覺領域[2]。得益于SRC模型在人臉識別上的成功應用,以及視頻本身幀與幀之間存在的冗余性,2009年ICCV上,文獻[3]首次將其應用到視頻目標跟蹤中,后續出現了大量基于稀疏表示的視頻目標跟蹤算法,并且取得了較好的跟蹤性能。文獻[4]在稀疏表示模型中引入了微模板系數的范數約束,并將加速最近梯度算法引入到模型求解中,提高了算法的魯棒性和速度,但是由于其模型更新方式導致一旦跟蹤失敗后續將不可能跟蹤上目標。文獻[5]將基于稀疏表示的判別式模型和生成式模型結合提出了基于稀疏表示的混合式跟蹤算法,在生成式模型中引入了基于重構誤差的遮擋檢測。文獻[6]將深度學習引入到視頻目標跟蹤。文獻[7]是基于高斯過程回歸的遷移學習跟蹤算法。其中文獻[5]和文獻[7]在現有的公開數據庫上取得了較好的跟蹤效果。目前大多數基于稀疏表示的跟蹤算法是基于范數約束下的SRC模型,然而SRC模型存在以下局限性[8]:(1)模型必須是線性的,即各類樣本可以用線性子空間建模,同類的樣本屬于同一子空間;(2)SRC是通過選擇部分訓練樣本來實現的,需要找到能很好表示各類子空間的字典原子,使得測試樣本可用該類的原子有效表示或逼近;(3)約束項中僅含有表示系數的稀疏性先驗,沒有考慮字典中原子之間的相似性,無法獲取數據的局部結構信息,導致獲得的稀疏表示判別信息不足;(4)模型算法復雜度高。
文獻[9]根據實驗結果指出稀疏編碼的結果傾向于局部性,即非零系數通常分配給與待編碼數據較近的基,稀疏編碼是在由待編碼數據的最近鄰形成的局部坐標系下進行。理論上指出在一些特定的條件下,局部性是比稀疏性更加本質的東西,并且局部性可以通過控制最近鄰的數量產生稀疏解,反之稀疏性卻不一定能夠產生局部性表示。
因此本文針對復雜場景下的視頻目標跟蹤問題,將SIFT特征與核稀疏表示相結合,利用核函數將線性稀疏表示擴展到核空間,在核空間中求解目標基于局部敏感約束的核稀疏表示,使得稀疏表示系數中同時集成了數據的稀疏性和局部性信息,從而增強字典和稀疏表示系數在特征層的類判別能力,實驗結果表明提高了基于稀疏表示的判別式跟蹤算法的魯棒性。
2 基于稀疏表示的視覺先驗字典學習
大量實驗表明,相比直接使用預先指定的字典,使用從訓練數據中學習得到的字典將會得到更為緊湊的表示,從而便于后續的壓縮編碼和分類識別。視覺先驗字典學習旨在獲取大量同類目標的相似特征信息,所以字典的學習過程需要大量的訓練圖像。而一般在視頻目標跟蹤中除了第1幀中的目標信息可以利用外,并無其它可利用的有關目標的準確信息。因此如圖1所示,選用Caltech101數據庫[10]中的圖像進行字典學習。

圖1 用于學習視覺先驗字典的圖像
首先在101類目標和1類背景的灰度圖像上使用固定大小的滑動窗(16×16),以步長8個像素來提取部分重疊圖像塊的SIFT特征,其中為SIFT特征的維數,為提取的SIFT特征數量。為要學習得到的字典,字典學習的過程為無監督的離線學習過程,目標函數為[11]
3 基于局部敏感約束的核稀疏表示
3.1 核稀疏表示
核方法能夠捕獲非線性特征的相似性,有助于尋找非線性特征的稀疏表示。核函數將樣本映射到高維特征空間后可以改變樣本的分布,在合適的核函數投影下,數據在高維特征空間將具有更好的線性可分性,樣本將可能更準確地由同類的訓練樣本線性表示,即樣本的稀疏表示系數中的非零值將更多地對應于同類訓練樣本,所以樣本的稀疏表示系數中包含更強的判別信息[13]。核稀疏表示本質上是在高維核空間中求解投影特征在投影基下的稀疏表示。給定特征,。假定由特征投影函數定義的核,其中。投影函數將特征和基投影到高維核空間[13]:
然后將投影后的特征和基替換稀疏編碼中相應的變量,可以得到核稀疏表示的目標函數:
3.2 局部敏感約束的核稀疏表示

表1 算法時間復雜度比較
得到目標基于局部敏感約束的核稀疏表示后,沿著圖像的不同位置和不同空間尺度對每個單元內的核稀疏表示進行最大值池化,使得池化后的特征對于局部空間轉換具有魯棒性[14]。假定單元區域有個圖像塊特征,經過最大值池化后,單元區域由維向量表示:
為了保存空間信息,使用3層空間金字塔匹配,將每個候選目標圖像分成1×1, 2×2, 4×4個子區域,然后對于每個子區域內的核稀疏表示系數使用最大值池化,最后將每層經過最大值池化后的表示系數等權重串聯得到目標最終表示。則有候選目標中所有個單元區域內的核稀疏表示經過最大值池化后連接起來得到目標的最終表示:
4 分類器的初始化和更新
4.1 分類器的初始化
在當前幀跟蹤位置基礎上,在目標周圍按照高斯分布提取一定數量的正負樣本,其中正樣本中心坐標滿足,負樣本中心坐標滿足,其中和為高斯分布的標準差且,為當前幀的跟蹤位置。
4.2 基于分類器響應的模型在線更新
考慮到跟蹤中目標的變化,模型的在線更新主要是分類器的在線更新,同時為了降低模型更新中由于誤差累積導致的漂移,將候選目標在第1幀中獲得的分類器響應和重新訓練得到的分類器響應進行線性加權作為候選目標最終的分類器響應:
5 跟蹤算法
算法是在粒子濾波框架[17]下完成。粒子濾波原理實質是用所有已知信息來構造系統狀態變量的后驗概率密度,即用系統狀態轉移模型預測狀態的先驗概率密度,再使用最近的觀測值進行修正,得到后驗概率密度。這樣通過觀測數據來遞推計算狀態取不同值時的置信度,由此獲得狀態的最優估計。給定目標的觀察變量集合,目標的狀態變量可以通過最大后驗估計得到:
因此,本文跟蹤算法如表2所示。

表2 基于局部敏感核稀疏表示的視頻目標跟蹤算法
6 實驗結果及分析
6.1 跟蹤結果及分析
測試視頻來自文獻[1],視頻數據及目標特征描述如表3所示,8個視頻共5579幀。實驗在Dual- Core 3.20 GHz,內存3 GB的臺式計算機上通過Matlab(R2013a)軟件實現。Shaking仿射變換參數的標準差為,粒子個數為100個,David仿射變換參數的標準差為,粒子個數為600個,Walking仿射變換參數的標準差為,粒子個數為300個,Suv仿射變換參數的標準差為,粒子個數為600個,Dudek仿射變換參數的標準差為,粒子個數為400個,FleetFace仿射變換參數的標準差為,粒子個數為600個,BlurCar1仿射變換參數的標準差為,粒子個數為400個。BlurFace仿射變換參數的標準差為,粒子個數為600個。經過仿射變換后目標區域大小為32×32。
實驗的部分跟蹤結果如圖2所示,其中白色實線為本文算法跟蹤結果,其它算法跟蹤結果如圖例
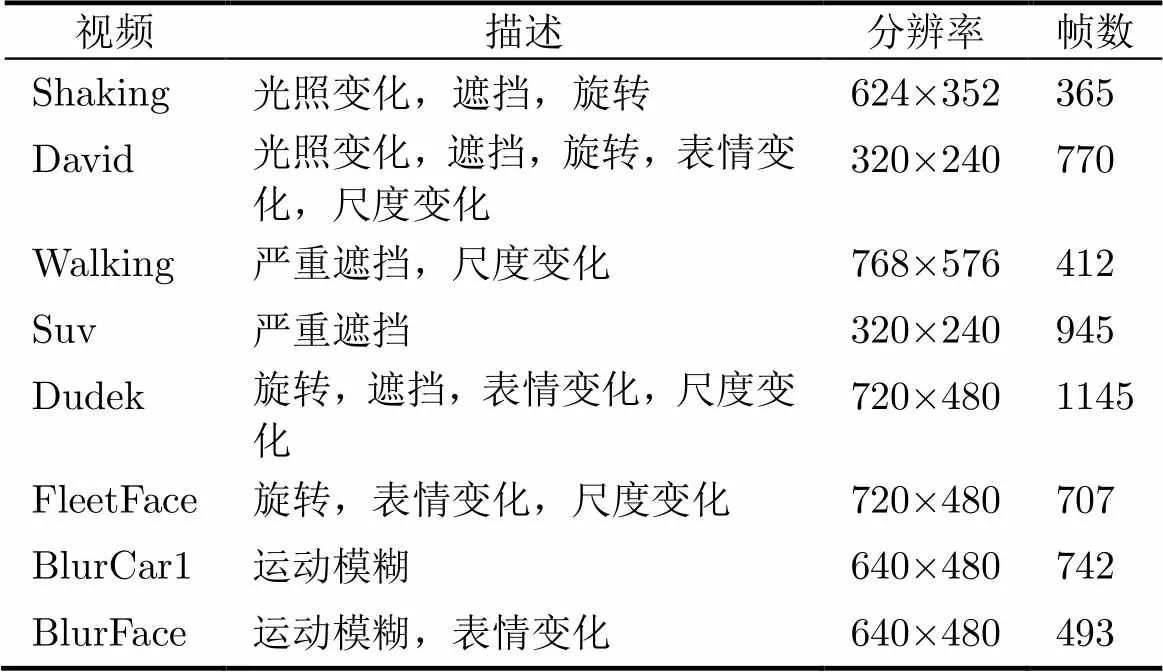
表3 視頻數據及目標特征描述

圖2 部分實驗跟蹤結果
基于深度學習的跟蹤算法(Deep Learning Tracking, DLT)[6],基于高斯過程回歸的遷移學習跟蹤算法(Transfer learning with Gaussian Process Regression, TGPR)[7]。由于上述算法都是在粒子濾波框架下利用仿射變換模型完成,因此所有算法均采用相同的初始位置、相同的粒子個數和相同的仿射變換參數標準差,其余參數采用代碼中的默認參數。
光照變化(Shaking#59, #60; David#158, #371):由于SIFT特征對梯度幅值直方圖進行了歸一化因而能夠對光照變化具有一定的不變性,加之目標的表示中同時集成了數據的局部性和稀疏性信息,使得在高維的特征表示下目標和背景更加線性可分。
遮擋(Shaking#360; Walking#87; Suv; Dudek #208):由于算法提取的局部圖像塊的SIFT特征對于部分遮擋具有一定的魯棒性,并且在分類器的在線更新中通過設定響應閾值避免了將遮擋物信息引入到模型更新中,所以能夠較好地處理跟蹤中的遮擋問題。
共面旋轉(Dudek#771):算法每次生成不同旋轉角度的候選框,并且SIFT特征本身對于共面旋轉具有不變性,因此能夠解決跟蹤中的共面旋轉問題。
異面旋轉(Shaking#158; Dudek#1139; FleetFace#274, #452, #541):對于異面旋轉由于目標的視覺特征發生改變,因此主要是通過分類器的在線更新對目標的變化作出自適應響應。
尺度變化(David, Walking, Dudek, FleetFace, BlurCar1):在粒子濾波框架下按照設定的仿射變換的標準差每次生成不同尺度的候選框,所以能夠較好地處理跟蹤中目標的尺度變化。
運動模糊(BlurCar1; BlurFace):圖像模糊等效于模糊核與清晰圖像的卷積,顯然模糊前后目標的SIFT特征是不同的,經過高斯核映射后提高了目標的線性可分性,并且目標的稀疏表示中集成了數據的局部性信息,因而能夠將模糊后的目標圖像與背景分開。
表情變化(David#158; Dudek#461; BlurFace 209; BlurFace#476):由于人臉的表情變化導致人臉面部的非線性運動,導致目標的SIFT特征發生改變。在高維的特征表示下SVMs具有較好的泛化能力,所以能夠將表情變化后的人臉與背景分開。
6.2 跟蹤精度
6.2.2 中心誤差 中心誤差定義為算法跟蹤框的中心與人工標定的真實的中心之間的歐氏距離(像素)[1],中心誤差的統計特征如表4所示,其中每個視頻對應的第1行為中心誤差的均值,第2行為中心誤差的標準差,中心誤差的均值表示算法的平均性能,中心誤差的標準差表示算法的穩定性,在均值相同的情況下,標準差越小表示算法的穩定性越好。從表4中可以看出本文算法整體上優于其它4種算法。
6.3 跟蹤魯棒性
6.4 算法處理速度比較
算法處理速度比較如表6所示。可以看出Matlab環境下基于稀疏表示的跟蹤算法(L1APG,
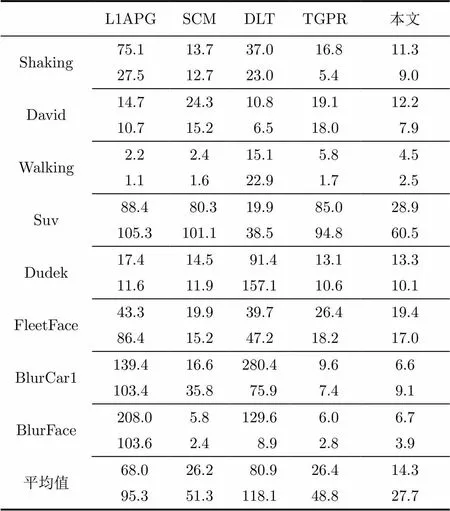
表4 不同算法下各視頻中心誤差的均值和標準差(像素)
SCM,本文算法)目前還很難達到實時處理(0.04 s/幀)的要求。由于本文算法需要對每個候選目標提取9個局部圖像塊的SIFT特征,所以特征提取過程是影響算法速度的主要因素
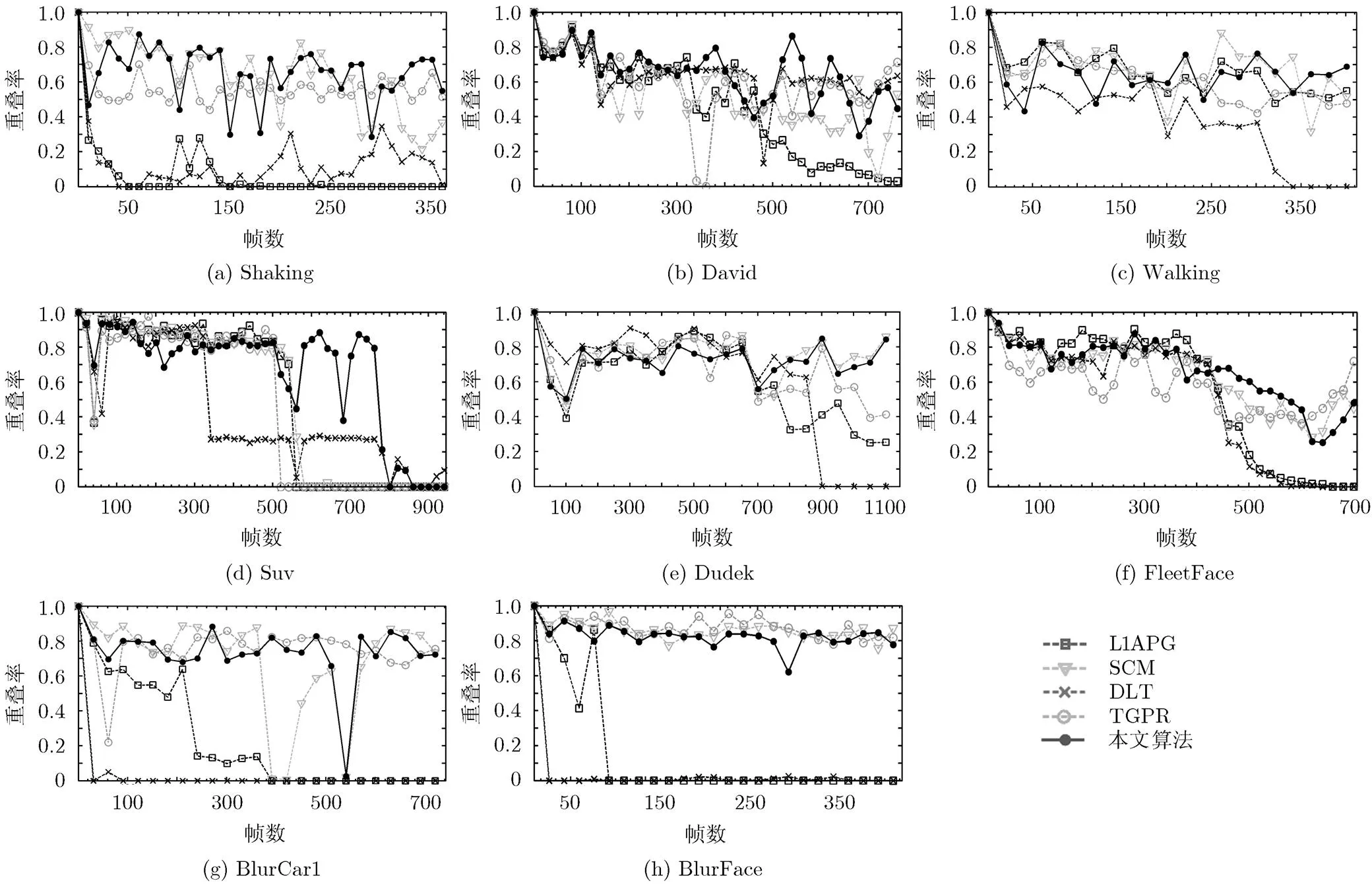
圖3 各視頻重疊率隨幀數的變化曲線
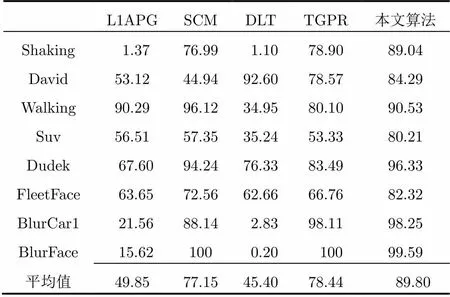
表5 不同算法下各視頻跟蹤成功率(%)
7 結束語
[1] WU Yi, LIM J, and YANG Minghsuan. Object tracking Benchmark[J]., 2015, 37(6): 1442-1456.
[2] WRIGHT J, MA Yi, MAIRAL J,. Sparse representation for computer vision and pattern recognition[J]., 2010, 98(6): 1031-1044.
[3] MEI X and LING H. Robust visual tracking using1minimization[C]. 2009 IEEE 12th International Conference on Computer Vision, Kyoto, 2009: 1436-1443.
[4] BAO Chenglong, WU Yi, LING Haibin,. Real time robust1tracker using accelerated proximal gradient approach[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 2012: 1830-1837.
[5] ZHONG Wei, LU Huchuan, and YANG Minghsuan. Robust object tracking via sparse collaborative appearance model[J]., 2014, 23(5): 2356-2368.
[6] WANG N and YEUNG D Y. Learning a deep compact image representation for visual tracking[C]. Advances in Neural Information Processing Systems, Nevada, 2013: 809-817.
[7] GAO Jin, LING Haibin, HU Weiming,. Transfer Learning Based Visual Tracking with Gaussian Processes Regression[M]. Computer Vision-ECCV 2014, Zurich: Springer International Publishing, 2014: 188-203.
[8] 王瑞, 杜林峰, 孫督, 等. 復雜場景下結合SIFT與核稀疏表示的交通目標分類識別[J]. 電子學報, 2014, 42(11): 2129-2134.
WANG Rui, DU Linfeng, SUN Du,. Traffic object recognition in complex scenes based on SIFT and kernel sparse representation[J]., 2014, 42(11): 2129-2134.
[9] YU K, ZHANG T, and GONG Y. Nonlinear learning using local coordinate coding[C]. Advances in Neural Information Processing Systems. Vancouver, 2009: 2223-2231.
[10] LI Feifei, FERGUS R, and PERONA P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories[J]., 2007, 106(1): 59-70.
[11] WANG Qing, FENG Chen, YANG Jimei,. Transferring visual prior for online object tracking[J]., 2012, 21(7): 3296-3305.
[12] LEE H, BATTLE A, RAINA R,. Efficient sparse coding algorithms[C]. Advances in Neural Information Processing Systems, Vancouver, 2006: 801-808.
[13] GAO Shenghua, TSANG I W, and CHIA Liangtien. Sparse representation with kernels[J]., 2013, 22(2): 423-434.
[14] WANG Jinjun, YANG Jianchao, YU Kai,. Locality-constrained linear coding for image classification[C]. 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA. 2010: 3360-3367.
[15] CHANG Chihchung and LIN Chihjen. LIBSVM: A library for support vector machines[J]., 2011, 2(3): 1-27.
[16] SMOLA A J and SCHOLKOPF B. A tutorial on support vector regression[J]., 2004, 14(3): 199-222.
[17] ROSS M A, LIM Jongwoo, LIN Ruei-Sung,. Incremental learning for robust visual tracking[J]., 2008, 77(1/3): 125-141.
黃宏圖: 男,1986年生,博士生,研究方向為視頻目標跟蹤.
畢篤彥: 男,1962年生,博士,教授,研究方向為圖像處理和模式識別.
高 山: 女,1983年生,博士,講師,研究方向為圖像處理.
查宇飛: 男,1979年生,博士,副教授,研究方向為計算機視覺和機器學習.
Foundation Items: The National Natural Science Foundation of China (61175029, 61379104, 61372167), The Young Scientists Fund of the National Natural Science Foundation of China (61203268, 61202339)
Visual Tracking via Locality-sensitive Kernel Sparse Representation
HUANG Hongtu①③BI Duyan①GAO Shan①ZHA Yufei①HOU Zhiqiang②
①(Aeronautics and Astronautics Engineering College, Air Force Engineering University, Xi’an 710038, China)②(Information and Navigation Institute, Air Force Engineering University, Xi’an 710077, China)③(95972 Troops of PLA, Jiuquan 735018, China)
In order to solve the problem of lack of discriminability in the-norm constraint sparse representation, visual tracking via locality-sensitive kernel sparse representation is proposed. To improve the linear discriminable power, the candidates’ Scale-Invariant Feature Transform (SIFT) is mapped into high dimension kernel space using the Gaussian kernel function. The locality-sensitive kernel sparse representation is acquired in the kernel space. The candidates’ representation are obtained after multi-scale maximum pooling. Finally, the candidates’ representation is put into the classifier and the candidate with the biggest Support Vector Machines (SVMs) score is recognized as the target. And the experiments demonstrate that the robustness of the proposed algorithm is improved due to the use of the data locality under the kernel sparse representation.
Visual tracking; Kernel sparse representation; Locality-sensitive constraint; Support Vector Machine (SVM)
TP391
A
1009-5896(2016)04-0993-07
10.11999/JEIT150785
2015-06-29;改回日期:2015-11-27;網絡出版:2016-01-14
黃宏圖 huanghongtu@sina.cn
國家自然科學基金(61175029, 61379104, 61372167),國家自然科學基金青年科學基金(61203268, 61202339)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
