基于大數(shù)據(jù)環(huán)境的NoSQL技術(shù)分析
2016-08-25 05:38:58呂冬雪
電子設(shè)計(jì)工程 2016年14期
關(guān)鍵詞:一致性數(shù)據(jù)庫(kù)
呂冬雪
(北京工業(yè)大學(xué) 北京 100124)
基于大數(shù)據(jù)環(huán)境的NoSQL技術(shù)分析
呂冬雪
(北京工業(yè)大學(xué) 北京100124)
傳統(tǒng)關(guān)系數(shù)據(jù)庫(kù)滿(mǎn)足不了當(dāng)前海量數(shù)據(jù)的高效存儲(chǔ)和管理、高并發(fā)訪(fǎng)問(wèn)、高可用性、高擴(kuò)展性、高容錯(cuò)性等特點(diǎn)的大數(shù)據(jù)環(huán)境,同時(shí),NoSQL技術(shù)在海量數(shù)據(jù)存儲(chǔ)方面展現(xiàn)了許多優(yōu)秀性能,因此,NoSQL技術(shù)越來(lái)越受到重視。本文總結(jié)了大數(shù)據(jù)環(huán)境對(duì)數(shù)據(jù)存儲(chǔ)的挑戰(zhàn),重點(diǎn)分析了NoSQL的理論基礎(chǔ)、系統(tǒng)架構(gòu)、數(shù)據(jù)模型、關(guān)鍵技術(shù)、安全問(wèn)題等,并分析了幾種典型的NoSQL數(shù)據(jù)庫(kù)。
大數(shù)據(jù);NoSQL;關(guān)系數(shù)據(jù)庫(kù);數(shù)據(jù)存儲(chǔ)
隨著云計(jì)算、物聯(lián)網(wǎng)、數(shù)據(jù)挖掘等新一代技術(shù)的發(fā)展,在移動(dòng)計(jì)算、社交網(wǎng)絡(luò)等業(yè)務(wù)的推動(dòng)下,大數(shù)據(jù)技術(shù)產(chǎn)生并迅速地建立起生態(tài)體系。然而,大數(shù)據(jù)在推動(dòng)技術(shù)變革的同時(shí),對(duì)海量數(shù)據(jù)的存儲(chǔ)、并發(fā)訪(fǎng)問(wèn)、擴(kuò)展等要求越來(lái)越高。例如,在Web2.0的社交網(wǎng)站中有龐大的用戶(hù)群,每時(shí)每刻都有大量的數(shù)據(jù)量訪(fǎng)問(wèn),因而會(huì)產(chǎn)生大量的日志和資料等,其數(shù)據(jù)量已經(jīng)達(dá)到PB級(jí)別。對(duì)于這些海量的數(shù)據(jù),不但包括結(jié)構(gòu)化數(shù)據(jù),更多的是包括非結(jié)構(gòu)化數(shù)據(jù),傳統(tǒng)關(guān)系數(shù)據(jù)庫(kù)不能很好、及時(shí)地處理這些數(shù)據(jù),其ACID(Atomicity、Consistency、Isolation、Durability)原則、結(jié)構(gòu)規(guī)整、表連接操作等特性成為制約海量數(shù)據(jù)存儲(chǔ)的瓶頸[1]。NoSQL就是為了解決海量數(shù)據(jù)的存儲(chǔ)而提出的,具有數(shù)據(jù)模型靈活、并發(fā)訪(fǎng)問(wèn)高、易于擴(kuò)展和伸縮、開(kāi)發(fā)效率高、開(kāi)發(fā)成本低等優(yōu)點(diǎn)。
本文先是分析了在大數(shù)據(jù)環(huán)境下對(duì)海量數(shù)據(jù)存儲(chǔ)的挑戰(zhàn),然后分析了NoSQL技術(shù),主要從理論基礎(chǔ)、系統(tǒng)架構(gòu)、數(shù)據(jù)模型、關(guān)鍵技術(shù)、安全問(wèn)題等幾個(gè)方面進(jìn)行分析,最后對(duì)當(dāng)前主流的NoSQL數(shù)據(jù)庫(kù)進(jìn)行總結(jié)分析。
1 大數(shù)據(jù)環(huán)境對(duì)數(shù)據(jù)存儲(chǔ)的挑戰(zhàn)
早在2012年,《紐約時(shí)報(bào)》就已經(jīng)刊稱(chēng)“大數(shù)據(jù)時(shí)代”已經(jīng)來(lái)臨,我們現(xiàn)在已經(jīng)處于大數(shù)據(jù)時(shí)代。大數(shù)據(jù)對(duì)當(dāng)前數(shù)據(jù)存儲(chǔ)、訪(fǎng)問(wèn)和管理帶來(lái)了前所未有的挑戰(zhàn)[2]:
1)高并發(fā)讀寫(xiě)需求。對(duì)于提供實(shí)時(shí)性、動(dòng)態(tài)性的社交網(wǎng)站、微博等,往往需要達(dá)到每秒上萬(wàn)次的讀寫(xiě)請(qǐng)求,這種很高的并發(fā)性對(duì)數(shù)據(jù)庫(kù)的并發(fā)負(fù)載相當(dāng)大,特別是對(duì)于傳統(tǒng)關(guān)系數(shù)據(jù)庫(kù)的硬盤(pán)I/0是個(gè)很大的負(fù)擔(dān)。
2)高效率存儲(chǔ)和訪(fǎng)問(wèn)需求。每天產(chǎn)生的數(shù)據(jù)量是巨大的,采用傳統(tǒng)的關(guān)系數(shù)據(jù)庫(kù)將海量數(shù)據(jù)放到具有結(jié)構(gòu)固定的二維表中,不管是查詢(xún)還是更新等操作效率都非常低。
3)高擴(kuò)展性。關(guān)系數(shù)據(jù)庫(kù)是很難水平擴(kuò)展的。當(dāng)數(shù)據(jù)量和訪(fǎng)問(wèn)量多到需要增加硬件和服務(wù)器節(jié)點(diǎn)來(lái)擴(kuò)大容量和負(fù)載量,關(guān)系數(shù)據(jù)庫(kù)必須停機(jī)維護(hù)和數(shù)據(jù)遷移,這對(duì)一個(gè)需要24小時(shí)不停服務(wù)的網(wǎng)站是非常不可取的。
大數(shù)據(jù)要求數(shù)據(jù)管理系統(tǒng)既能海量數(shù)據(jù)存儲(chǔ),又能高效率的并發(fā)讀寫(xiě)和訪(fǎng)問(wèn),同時(shí)必須支持?jǐn)U展性和可伸縮性。NoSQL數(shù)據(jù)庫(kù)作為關(guān)系數(shù)據(jù)庫(kù)的補(bǔ)充,彌補(bǔ)了關(guān)系數(shù)據(jù)庫(kù)在這些方面的不足,滿(mǎn)足了海量數(shù)據(jù)的存儲(chǔ)、訪(fǎng)問(wèn)和管理。
2 NoSQL技術(shù)
NoSQL(Not Only SQL)伴隨互聯(lián)網(wǎng)web2.0產(chǎn)生,是一種非關(guān)系型、分布式、不遵循ACID、不提供SQL的數(shù)據(jù)庫(kù)總稱(chēng)。它并不是單純地反對(duì)關(guān)系數(shù)據(jù)庫(kù),而是在靈活性、擴(kuò)展性、性能等方面對(duì)關(guān)系數(shù)據(jù)庫(kù)的補(bǔ)充[3]。NoSQL通過(guò)采用簡(jiǎn)單數(shù)據(jù)模型、元數(shù)據(jù)和應(yīng)用數(shù)據(jù)分離、弱一致性等技術(shù)能滿(mǎn)足海量數(shù)據(jù)的存儲(chǔ)要求。伴隨大數(shù)據(jù)、云計(jì)算、物聯(lián)網(wǎng)等新一代技術(shù)的迅速發(fā)展,NoSQL越來(lái)越成熟。
2.1理論基礎(chǔ)
CAP理論。CAP理論[3-4]是NoSQL的基石,分別代表一致性、可用性、分區(qū)容錯(cuò)性3個(gè)特性。根據(jù)CAP理論,數(shù)據(jù)共享系統(tǒng)只能滿(mǎn)足這3個(gè)特性中的兩個(gè),而不能同時(shí)滿(mǎn)足3個(gè)條件[3-4]。而由于當(dāng)前的網(wǎng)絡(luò)硬件條件限制肯定會(huì)出現(xiàn)延遲丟包等問(wèn)題,所以分區(qū)容錯(cuò)性是我們必須需要實(shí)現(xiàn)的[6]。因此,系統(tǒng)設(shè)計(jì)者需要在一致性和可用性之間進(jìn)行權(quán)衡和取舍。
BASE理論。由于對(duì)可用性及分區(qū)容錯(cuò)性的要求高于強(qiáng)一致性,并且很難滿(mǎn)足事務(wù)所要求的ACID特性,因此BASE理論[3,5]被提出。Base理論組成包括:基本可用、軟狀態(tài)和最終一致性。基本可用是指系統(tǒng)能夠保持基本可用的狀態(tài)一直為用戶(hù)提供服務(wù);軟狀態(tài)是指系統(tǒng)不要求強(qiáng)一致?tīng)顟B(tài),可以異步;最終一致性是指系統(tǒng)在一定時(shí)間內(nèi)保持?jǐn)?shù)據(jù)一致[3,5]。Base理論是CAP理論的演化,完全不同于關(guān)系數(shù)據(jù)庫(kù)的ACID特性,它通過(guò)犧牲強(qiáng)一致性獲得基本一致性和柔性可靠性,達(dá)到最終一致性來(lái)提高可用性和系統(tǒng)性能。NoSQL遵循Base理論。
2.2系統(tǒng)架構(gòu)
目前,NoSQL數(shù)據(jù)庫(kù)有許多解決方案,但其系統(tǒng)架構(gòu)主要分為兩類(lèi):Master-Slave架構(gòu)和P2P(Peer to Peer)環(huán)狀架構(gòu)。Master-Slave架構(gòu)[6]通常是由一個(gè)master節(jié)點(diǎn)(管理節(jié)點(diǎn))和多個(gè)slave節(jié)點(diǎn)(計(jì)算節(jié)點(diǎn))組成,master節(jié)點(diǎn)負(fù)責(zé)管理整個(gè)系統(tǒng),并監(jiān)控所有slave節(jié)點(diǎn)的狀態(tài)實(shí)現(xiàn)負(fù)載均衡;而slave節(jié)點(diǎn)是數(shù)據(jù)存儲(chǔ)節(jié)點(diǎn),每個(gè)salve節(jié)點(diǎn)需要維護(hù)一個(gè)本地?cái)?shù)據(jù)的索引表并定期向master節(jié)點(diǎn)匯報(bào)自己的運(yùn)行和負(fù)載情況。Master-Slave架構(gòu)系統(tǒng)設(shè)計(jì)的優(yōu)點(diǎn)是比較簡(jiǎn)單、可控性好、維護(hù)簡(jiǎn)便,缺點(diǎn)是master節(jié)點(diǎn)會(huì)成為制約性能的瓶頸[6]。Bigtable和HBase采用Master-Slave架構(gòu)。在P2P環(huán)狀架構(gòu)[6]中,系統(tǒng)節(jié)點(diǎn)通過(guò)“一致性哈希算法”連接一個(gè)環(huán),每個(gè)節(jié)點(diǎn)處于平等地位而沒(méi)有主次之分,每個(gè)節(jié)點(diǎn)存儲(chǔ)和管理數(shù)據(jù)。P2P架構(gòu)系統(tǒng)設(shè)計(jì)的優(yōu)點(diǎn)是負(fù)載均衡、協(xié)調(diào)性好、擴(kuò)展方便,缺點(diǎn)是系統(tǒng)較為復(fù)雜、可控性差。Cassandra和Dynamo采用P2P架構(gòu)。
2.3數(shù)據(jù)模型
從數(shù)據(jù)模型的角度,根據(jù)數(shù)據(jù)的存儲(chǔ)模型和特點(diǎn),NoSQL數(shù)據(jù)庫(kù)有很多分類(lèi),主要有以下四種典型的類(lèi)型[3]:鍵值存儲(chǔ)數(shù)據(jù)模型、列式存儲(chǔ)數(shù)據(jù)模型、文檔存儲(chǔ)數(shù)據(jù)模型、圖形存儲(chǔ)數(shù)據(jù)模型。
鍵值存儲(chǔ)數(shù)據(jù)模型。鍵值存儲(chǔ)數(shù)據(jù)模型的思想源自于哈希表中的key-value(鍵值對(duì)),是NoSQL數(shù)據(jù)庫(kù)經(jīng)常采用的存儲(chǔ)形式。key-value是一個(gè)映射,key是經(jīng)過(guò)計(jì)算得到關(guān)鍵字,value是存儲(chǔ)的內(nèi)容。在鍵值存儲(chǔ)數(shù)據(jù)模型中,數(shù)據(jù)按照key-value的形式進(jìn)行組織、存儲(chǔ)和索引。對(duì)于海量數(shù)據(jù)存儲(chǔ)系統(tǒng)來(lái)說(shuō),鍵值存儲(chǔ)模型弱化了數(shù)據(jù)結(jié)構(gòu),易于實(shí)現(xiàn),具有極高的并發(fā)讀寫(xiě)性能。但是,不適合批量數(shù)據(jù)的查詢(xún)、更新操作,也不支持特別復(fù)雜邏輯的數(shù)據(jù)操作[3]。采用此類(lèi)型存儲(chǔ)的數(shù)據(jù)庫(kù)系統(tǒng)有Redis、Dynamo等。
列式存儲(chǔ)數(shù)據(jù)模型。列式存儲(chǔ)數(shù)據(jù)模型也采用類(lèi)似“表”的傳統(tǒng)數(shù)據(jù)模型,相對(duì)于關(guān)系數(shù)據(jù)庫(kù)用“行”來(lái)存儲(chǔ)數(shù)據(jù),它主要采取了“列”存儲(chǔ)。列式存儲(chǔ)通過(guò)將同一列的數(shù)據(jù)盡可能地存儲(chǔ)在硬盤(pán)同一個(gè)頁(yè)中,同時(shí)支持“列族”(多個(gè)列并為一個(gè)組,即列族)特性,能提高存儲(chǔ)空間利用率和查詢(xún)效率,節(jié)省大量的I/O操作[3]。由于列式存儲(chǔ)是面向大數(shù)據(jù)環(huán)境下的數(shù)據(jù)分析和數(shù)據(jù)倉(cāng)庫(kù)而生,會(huì)有寫(xiě)入效率低、數(shù)據(jù)完整性稍差等缺點(diǎn)。采用此類(lèi)型存儲(chǔ)的數(shù)據(jù)庫(kù)系統(tǒng)有 Bigtable、Cassandra、Hbase、HyperTable等。
文檔存儲(chǔ)數(shù)據(jù)模型。文檔存儲(chǔ)數(shù)據(jù)模型沒(méi)有關(guān)系數(shù)據(jù)庫(kù)的存儲(chǔ)模式,存儲(chǔ)格式多樣,其數(shù)據(jù)通常以JSON或者類(lèi)似JSON格式(例如XML、BSON等)的文檔進(jìn)行存儲(chǔ)。它可以通過(guò)復(fù)雜的查詢(xún)條件來(lái)獲取數(shù)據(jù),在部分應(yīng)用中,文檔型數(shù)據(jù)庫(kù)比鍵值型數(shù)據(jù)庫(kù)的查詢(xún)效率更高,比較容易使用,支持嵌套結(jié)構(gòu),擴(kuò)展性強(qiáng);缺點(diǎn)是存儲(chǔ)的是非結(jié)構(gòu)化數(shù)據(jù),不具備關(guān)系數(shù)據(jù)的事務(wù)處理和JSON處理能力[3]。采用此類(lèi)型存儲(chǔ)的數(shù)據(jù)庫(kù)系統(tǒng)有MongoDB、CouchDB等。
圖形存儲(chǔ)數(shù)據(jù)模型。圖形存儲(chǔ)數(shù)據(jù)模型[2]以網(wǎng)格結(jié)構(gòu)的圖理論為基礎(chǔ),由節(jié)點(diǎn)、關(guān)系和屬性組成,用節(jié)點(diǎn)表示實(shí)體對(duì)象,用邊表示實(shí)體對(duì)象之間關(guān)系。采用圖結(jié)構(gòu)存儲(chǔ)數(shù)據(jù)應(yīng)用圖算法進(jìn)行各種復(fù)雜的運(yùn)算,如最短路徑計(jì)算、集中度測(cè)量等[3]。采用此類(lèi)型存儲(chǔ)的數(shù)據(jù)庫(kù)系統(tǒng)有Neo4j、GraphDB等。
2.4關(guān)鍵技術(shù)
為了適應(yīng)高并發(fā)的讀寫(xiě)、高效率的存儲(chǔ)和訪(fǎng)問(wèn)以及高擴(kuò)展性和可用性等需求的大數(shù)據(jù)環(huán)境,NoSQL數(shù)據(jù)庫(kù)迅速發(fā)展,其關(guān)鍵技術(shù)主要集中在數(shù)據(jù)的分區(qū)、放置、處理、復(fù)制、容錯(cuò)、壓縮、緩存等方面。
數(shù)據(jù)分區(qū)和放置。在不斷地解決數(shù)據(jù)存儲(chǔ)空間和數(shù)據(jù)庫(kù)性能問(wèn)題的過(guò)程中,為了有效地存儲(chǔ)、處理大量的數(shù)據(jù),采用“分而治之”思想的數(shù)據(jù)分區(qū)技術(shù)出現(xiàn)。分區(qū)能夠減少管理操作的時(shí)間,縮小查詢(xún)操作的范圍,提高了數(shù)據(jù)的可用性、系統(tǒng)的性能和維護(hù)的效率。根據(jù)數(shù)據(jù)的特點(diǎn)和用戶(hù)的需求,分區(qū)技術(shù)主要有范圍分區(qū)、列表分區(qū)、哈希分區(qū)等。
對(duì)于海量數(shù)據(jù)的放置策略,有許多的研究算法,其中“一致性哈希”算法公認(rèn)度最高。具體思想是[3,7]:第一步,在一個(gè)虛擬的環(huán)形哈希空間,組織方式是順時(shí)針,哈希函數(shù)H的值空間是0~(232-1),0和232-1在時(shí)針零點(diǎn)鐘重合(圖1);第二步,按照服務(wù)器的主機(jī)名或者IP地址對(duì)每臺(tái)服務(wù)器進(jìn)行哈希尋址,例如3臺(tái)服務(wù)器節(jié)點(diǎn)ServerA、ServerB、ServerC使用IP尋址后在環(huán)上的位置 (圖2),Key值分別是KeyA、KeyB、KeyC;第三步,通過(guò)哈希算法得出數(shù)據(jù)對(duì)象在環(huán)的空間位置,順時(shí)針判斷數(shù)據(jù)存儲(chǔ)的服務(wù)器節(jié)點(diǎn),比如4個(gè)數(shù)據(jù)對(duì)象Object1、Object2、Object3、Object4的 Key值分別是 Key1、Key2、Key3、Key4,則Object1存儲(chǔ)在ServerA、Object4存儲(chǔ)在ServerC、Object2和Object3存儲(chǔ)在ServerB(圖3)。

圖1 一般哈希空間
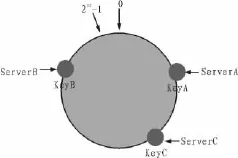
圖2 有3臺(tái)服務(wù)器節(jié)點(diǎn)分布的哈希空間
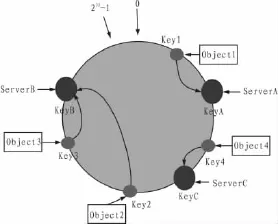
圖3 數(shù)據(jù)對(duì)象分布的哈希空間
在容錯(cuò)性方面[3,7],例如ServerC突然停機(jī),根據(jù)一致性哈希算法,原來(lái)存儲(chǔ)在ServerC的數(shù)據(jù)對(duì)象Object4將順時(shí)針存儲(chǔ)在下一個(gè)服務(wù)器ServerB(圖4)。在擴(kuò)展性方面[3,7],如果需要新加一個(gè)ServerD,首先根據(jù)IP進(jìn)行尋址得出ServerD在空間位置 (例如在ServerD地址空間在數(shù)據(jù)對(duì)象Obejct2和Object3之間),則Object2將存儲(chǔ)在ServerD,其他不變(圖5)。
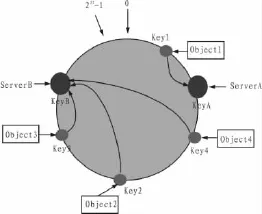
圖4 減少服務(wù)器節(jié)點(diǎn)后的哈希空間(容錯(cuò)性)
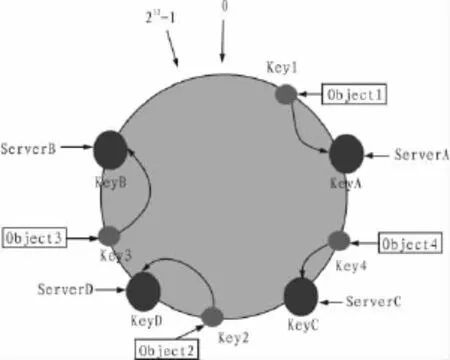
圖5 增加服務(wù)器節(jié)點(diǎn)后的哈希空間(擴(kuò)展性)
在負(fù)載均衡方面[3,7],一致性哈希算法引入了“虛擬節(jié)點(diǎn)”的概念,即將每臺(tái)服務(wù)器都在環(huán)形哈希空間上映射多個(gè)虛擬節(jié)點(diǎn)。在沒(méi)有虛擬節(jié)點(diǎn)之前,系統(tǒng)中ServerB的訪(fǎng)問(wèn)和存儲(chǔ)量遠(yuǎn)遠(yuǎn)小于ServerA的訪(fǎng)問(wèn)和存儲(chǔ)量,造成負(fù)載不均衡(圖6)。引入虛擬節(jié)點(diǎn)后,計(jì)算出數(shù)據(jù)的哈希空間值后按照順時(shí)針?lè)较蛘业椒?wù)器節(jié)點(diǎn),這個(gè)節(jié)點(diǎn)是虛擬的,實(shí)際上數(shù)據(jù)是存儲(chǔ)在這個(gè)虛擬節(jié)點(diǎn)對(duì)應(yīng)的實(shí)際服務(wù)器上。例如,ServerA和ServerB都映射了兩個(gè)虛擬節(jié)點(diǎn) ServerA#1、ServerA#2和ServerB#1、ServerB#2(圖7),數(shù)據(jù)可以均勻分布這4個(gè)節(jié)點(diǎn)上,解決了負(fù)載不均衡的問(wèn)題。
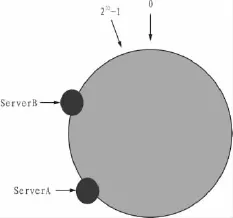
圖6 負(fù)載不平衡的哈希空間
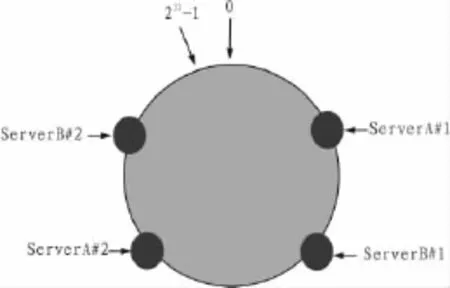
圖7 增加虛擬節(jié)點(diǎn)后的哈希空間(負(fù)載均衡)
數(shù)據(jù)處理。并行計(jì)算是解決大規(guī)模數(shù)據(jù)處理的方法之一,其計(jì)算模型主要分為三大類(lèi):MPI技術(shù)、Map/Reduce計(jì)算、Dryad并行計(jì)算模型。MPI是并行計(jì)算的編程接口標(biāo)準(zhǔn);Dryad是微軟為并行處理海量數(shù)據(jù)而設(shè)計(jì)的分布式架構(gòu)。Map/Reduce[8]是Google提出的大規(guī)模數(shù)據(jù)的并行計(jì)算模型,數(shù)據(jù)處理過(guò)程主要分成兩個(gè)階段:Map階段、Reduce階段。具體過(guò)程是:首先Map/Reduce框架將輸入的數(shù)據(jù)集分成若干個(gè)獨(dú)立的數(shù)據(jù)塊,由Map任務(wù)以并行的方式執(zhí)行;其次,Map/ Reduce框架先對(duì)Map的輸出進(jìn)行排序,然后把結(jié)果輸入給Reduce任務(wù);同時(shí),整個(gè)Map/Reduce框架會(huì)負(fù)責(zé)任務(wù)的調(diào)度和監(jiān)控,以及重新執(zhí)行已經(jīng)失敗的任務(wù)。
數(shù)據(jù)復(fù)制和容錯(cuò)。在處理數(shù)據(jù)時(shí)候,為了避免因一些差錯(cuò)和失誤而刪除、改錯(cuò)某些數(shù)據(jù)等情況,數(shù)據(jù)復(fù)制(備份)技術(shù)隨之產(chǎn)生,通過(guò)對(duì)數(shù)據(jù)進(jìn)行備份,在出錯(cuò)情況下能夠及時(shí)找到或者恢復(fù)原來(lái)的數(shù)據(jù)。現(xiàn)在,NoSQL數(shù)據(jù)庫(kù)種類(lèi)繁多,出現(xiàn)了很多不同的數(shù)據(jù)復(fù)制策略以及相應(yīng)的數(shù)據(jù)故障檢測(cè)與處理技術(shù)。主要有Dynamo為代表的基于key-value模式的數(shù)據(jù)庫(kù)復(fù)制策略、以CouchDB為代表的文檔數(shù)據(jù)庫(kù)代表的復(fù)制的策略、以PNUTS為代表的其他數(shù)據(jù)庫(kù)的復(fù)制策略[3]。
數(shù)據(jù)壓縮。由于數(shù)據(jù)中存在著大量的冗余信息,在不丟失信息的前提下,將重復(fù)的數(shù)據(jù)按照一定算法進(jìn)行重新組織,以達(dá)到最大程度的壓縮提高數(shù)據(jù)傳輸、存儲(chǔ)和處理的效率,這就是數(shù)據(jù)壓縮。傳統(tǒng)的數(shù)據(jù)壓縮方法如霍夫曼編碼、LZ77算法等不能滿(mǎn)足海量數(shù)據(jù)的對(duì)于數(shù)量、速度、多樣的壓縮要求,因此出現(xiàn)了針對(duì)大數(shù)據(jù)的數(shù)據(jù)壓縮方法,主要包括Oracle的混合列壓縮、Google的兩趟壓縮、Hadoop的LZO壓縮算法等[3]。
數(shù)據(jù)緩存。在多服務(wù)器的大數(shù)據(jù)環(huán)境下,數(shù)據(jù)庫(kù)的高訪(fǎng)問(wèn)量制約數(shù)據(jù)庫(kù)和服務(wù)器的性能,因此,數(shù)據(jù)緩存是NoSQL技術(shù)非常重要的部分。分布式緩存技術(shù)迅速發(fā)展,其經(jīng)歷從本地緩存、分布式緩存系統(tǒng)、彈性緩存平臺(tái)到彈性應(yīng)用平臺(tái)的發(fā)展。數(shù)據(jù)庫(kù)將數(shù)據(jù)直接放入緩存中,應(yīng)用程序從緩存中獲取所需數(shù)據(jù),提高了系統(tǒng)可用性和性能。分布式緩存機(jī)制具有高性能、動(dòng)態(tài)可擴(kuò)展、高可用、易可用等特點(diǎn)。
2.5安全問(wèn)題
NoSQL數(shù)據(jù)存儲(chǔ)具有海量存儲(chǔ)、高并發(fā)性、高可用性、可擴(kuò)展性等優(yōu)勢(shì),但由于NoSQL發(fā)展比較新,其數(shù)據(jù)存儲(chǔ)遵從最終一致性,也面臨一些安全威脅[9-10]:1)模式成熟度不夠。NoSQL無(wú)法沿用關(guān)系數(shù)據(jù)庫(kù)的模式,沒(méi)有嚴(yán)格的訪(fǎng)問(wèn)控制和隱私工具。2)系統(tǒng)成熟度不夠。相比關(guān)系數(shù)據(jù)庫(kù)比較成熟的安全機(jī)制,NoSQL系統(tǒng)仍然會(huì)有各種漏洞。3)客戶(hù)端問(wèn)題。NoSQL需對(duì)訪(fǎng)問(wèn)的客戶(hù)端應(yīng)用程序提供安全措施,例如身份驗(yàn)證和授權(quán)功能、SQL注入問(wèn)題、代碼漏洞等。4)數(shù)據(jù)冗余和分散性問(wèn)題。在分布式環(huán)境,數(shù)據(jù)分在不同位置不同服務(wù)器上,對(duì)數(shù)據(jù)的冗余性和分散性需要考慮。同時(shí),也要注意數(shù)據(jù)查詢(xún)、處理、備份、容錯(cuò)等問(wèn)題。
3 幾種典型的NoSQL數(shù)據(jù)庫(kù)對(duì)比分析

表1 幾種典型的NoSQL數(shù)據(jù)庫(kù)對(duì)比分析
Redis是一個(gè)鍵值模型的內(nèi)存數(shù)據(jù)庫(kù),整個(gè)數(shù)據(jù)庫(kù)在內(nèi)存中加載并進(jìn)行數(shù)據(jù)操作,并周期性地把更新的數(shù)據(jù)寫(xiě)回硬盤(pán)中進(jìn)行保存。Cassandra借鑒于Google的Bigtable的列族,是Facebook在2008年提出的,同時(shí)引入了“超級(jí)列”的概念,實(shí)現(xiàn)更高層級(jí)的數(shù)據(jù)組織、索引。MongoDB是存儲(chǔ)結(jié)構(gòu)松散、可擴(kuò)展、高性能、易部署、易使用的文檔存儲(chǔ)數(shù)據(jù)庫(kù),介于關(guān)系數(shù)據(jù)庫(kù)和NoSQL數(shù)據(jù)庫(kù)之間。Neo4j是一個(gè)嵌入式、基于磁盤(pán)的、支持完整事務(wù)的java持久化引擎,它將結(jié)構(gòu)化數(shù)據(jù)采用圖結(jié)構(gòu)的方式存儲(chǔ),是面向圖形的數(shù)據(jù)庫(kù)。
表1展示的是4種NoSQL數(shù)據(jù)庫(kù)在數(shù)據(jù)模型、功能特性、使用許可、編寫(xiě)語(yǔ)言、協(xié)議類(lèi)型、應(yīng)用案例和場(chǎng)景、缺陷方面等方面的對(duì)比[10]。
4 結(jié)束語(yǔ)
面對(duì)具有海量化、多樣化、快速化、價(jià)值化特點(diǎn)的大數(shù)據(jù)環(huán)境,傳統(tǒng)關(guān)系數(shù)據(jù)庫(kù)已經(jīng)不能滿(mǎn)足海量數(shù)據(jù)的存儲(chǔ)和管理要求。NoSQL數(shù)據(jù)庫(kù)具有簡(jiǎn)單和靈活的數(shù)據(jù)模型、高并發(fā)訪(fǎng)問(wèn)、很好的擴(kuò)展性和可用性等優(yōu)點(diǎn),彌補(bǔ)了關(guān)系數(shù)據(jù)庫(kù)的不足。但是,NoSQL數(shù)據(jù)庫(kù)不是對(duì)關(guān)系數(shù)據(jù)庫(kù)的否定,而是對(duì)關(guān)系數(shù)據(jù)的補(bǔ)充,兩者在各種領(lǐng)域各自發(fā)揮著重要的作用。作為解決大數(shù)據(jù)存儲(chǔ)和管理的先進(jìn)方法,NoSQL技術(shù)有著關(guān)系數(shù)據(jù)庫(kù)無(wú)法比擬的優(yōu)勢(shì),越來(lái)越受到大多人的關(guān)注和重視,發(fā)展前景廣闊。
[1]呂美英,郭顯娥.NOSQL和可擴(kuò)展的SQL[J].山西大同大學(xué)學(xué)報(bào)(自然科學(xué)版),2012,28(5):15-18.
[2]阮夢(mèng)黎.大數(shù)據(jù)挑戰(zhàn)下的NoSQL系統(tǒng)研究 [J].聊城大學(xué)學(xué)報(bào):自然科學(xué)版,2015,28(1):88-93
[3]陸嘉恒.大數(shù)據(jù)挑戰(zhàn)與NoSQL數(shù)據(jù)庫(kù)技術(shù)[M].北京:電子工業(yè)出版社,2014.
[4]Julian Browne.Brewer’s CAP Theorem[EB/OL].2009-01-11,http://www.julianbrowne.com/article/viewer/brewers-captheorem.
[5]王珊,薩師煊.數(shù)據(jù)庫(kù)系統(tǒng)概論[M].北京:高等教育出版社,2007.
[6]申德榮,于戈,王習(xí)特,等.支持大數(shù)據(jù)管理的 NoSQL系統(tǒng)研究綜述[J].軟件學(xué)報(bào),2013,24(8):1786-1803.
[7]趙飛,蘇忠.一致性哈希算法在數(shù)據(jù)庫(kù)集群上的拓展應(yīng)用[J].成都信息工程學(xué)院學(xué)報(bào),2015,30(1):52-58.
[8]萬(wàn)川梅,謝正蘭.深入云計(jì)算:Hadoop應(yīng)用開(kāi)發(fā)實(shí)戰(zhàn)詳解[M].北京:中國(guó)鐵道出版社,2014.
[9]張尼,張?jiān)朴拢ぃ?大數(shù)據(jù)安全技術(shù)與應(yīng)用[M].北京:人民郵電出版社,2014.
[10]張俊,周新,于素華,等.NoSQL數(shù)據(jù)管理技術(shù)[J].科研信息化技術(shù)及應(yīng)用,2013,4(1):3-11.
Analysis of NoSQL technology based on big data environment
LV Dong-xue
(Beijing University of Technology,Beijing 100124,China)
The traditional relational database can not meet the current environment of big data,that contains the features of efficient storage and management,high concurrent access,high availability,high scalability,high fault tolerance.At the same time,NoSQL technology shows a lot of excellent properties in mass data storage.Therefore,many people pay attention to NoSQL technology.This article summarizes the challenges of big data environment for data storage,and focuses on the theoretical basis,system architecture,data model,key technologies,security issues in NoSQL,then analyzes several typical NoSQL databases.
big data;NoSQL;relational databases;data storage
TP311
A
1674-6236(2016)14-0033-04
2015-07-14稿件編號(hào):201507096
呂冬雪(1990—),女,山東煙臺(tái)人,碩士研究生。研究方向:軟件工程。
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
教學(xué)考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學(xué)問(wèn)題(2021年4期)2021-11-05 07:02:34
中醫(yī)眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
財(cái)經(jīng)(2017年15期)2017-07-03 22:40:49
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
中國(guó)公共安全(2017年11期)2017-02-06 05:28:08
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
