基于深度神經網絡的語音驅動發音器官的運動合成
2016-08-22 09:55:06唐郅侯進
自動化學報 2016年6期
唐郅 侯進
?
基于深度神經網絡的語音驅動發音器官的運動合成
唐郅1侯進1
實現一種基于深度神經網絡的語音驅動發音器官運動合成的方法,并應用于語音驅動虛擬說話人動畫合成.通過深度神經網絡(Deep neural networks,DNN)學習聲學特征與發音器官位置信息之間的映射關系,系統根據輸入的語音數據估計發音器官的運動軌跡,并將其體現在一個三維虛擬人上面.首先,在一系列參數下對比人工神經網絡(Artificial neural network,ANN)和DNN的實驗結果,得到最優網絡;其次,設置不同上下文聲學特征長度并調整隱層單元數,獲取最佳長度;最后,選取最優網絡結構,由DNN輸出的發音器官運動軌跡信息控制發音器官運動合成,實現虛擬人動畫.實驗證明,本文所實現的動畫合成方法高效逼真.
深度神經網絡,語音驅動,運動合成,虛擬說話人
引用格式唐郅,侯進.基于深度神經網絡的語音驅動發音器官的運動合成.自動化學報,2016,42(6):923-930
由于視覺與聽覺是人類最主要、最便捷的兩種溝通方式,因此虛擬人動畫結合聽視覺雙模態溝通方式的特點,將虛擬人的視覺信息作為其聲音的一種補充.例如,額外的舌頭和唇部等發音器官的運動,眉毛和眼瞼等面部特征,甚至是頭部和肢體的動作等,這些附加信息可以極大提高虛擬人動畫的真實感和可懂度.基于語音驅動虛擬人動畫的方法已經被證實在人機交互應用中十分有效[1-5].
語音的產生與聲道發音器官的運動直接相關,如唇部、舌頭和軟腭的位置與移動.因此,本文根據聲學特征參數估計發音器官的位置信息,并體現在一個虛擬說話人上面,實現語音驅動虛擬說話人動畫合成.其中,最重要的環節是聲視覺映射,即研究聲學特征與發音器官位置信息的映射問題.
在最近的十年里,人工神經網絡(Artificial neural network,ANN)[6]、隱馬爾科夫模型(Hidden Markov model,HMM)[7]、高斯混合模型(Gaussian mixture model,GMM)[8]和動態貝葉斯網絡(Dynamic Bayesian network,DBN)[9]等被應用于研究聲視覺映射問題.然而,聲學特征與發音器官位置信息之間的映射關系是一個非線性,多對多的映射問題.因此,使用這些算法研究聲視覺映射問題的預測精度較低.在Uria等[10]和Zhao等[11]的研究中,將聲學特征與發音器官位置信息之間的映射視為一個回歸問題,使用深度神經網絡(Deep neuralnetworks,DNN)尋找兩者之間的連續映射關系,并取得良好的實驗效果.
在虛擬人面部運動控制問題上,絕大多數研究者都將發音器官的運動合成作為一個重要的研究方向,主要體現在唇舌模型的運動控制,實現虛擬人動畫合成.目前主要有兩種主流方法,一種是基于參數控制的方法[12-13],另一種是基于數據驅動的方法[14-15].前者首先建立一個基于二維正面照片的三維人物面部模型,然后定義一些模型控制參數,通過計算每一幀動畫所需要的參數控制虛擬人面部動畫;后者則是先建立一個圖像樣本的表情數據庫,在合成階段根據算法將合適的嘴巴圖像從微表情數據庫中選出來,合成情感說話人面部動畫.
針對本文實際情況,采用實驗室前期工作,基于運動軌跡分析的3D唇舌肌肉控制模型[16].該模型的優點在于通過分析嘴部和舌部的運動軌跡,將其分解為一些機械運動的組合,只需要幾個控制參數便能夠很好地實現唇部和舌部的自然運動合成.
本文實現一種語音驅動虛擬說話人動畫合成方法.首先,本文比較基于ANN和DNN的方法研究聲學特征與發音器官位置信息之間映射關系的優劣.其中,ANN的網絡權值采用隨機初始化方式,而DNN采取預訓練的方式初始化網絡權值.然后,在得到較好的網絡結構的基礎上,我們進一步研究上下文(Context)長度對其重構誤差的影響,獲得最佳的Context長度.最后,在這兩個實驗結果的基礎上,選取最優網絡結構,由DNN輸出的發音器官位置信息控制發音器官運動合成,實現虛擬人動畫.實驗證明,本文所實現的動畫合成方法有效逼真.
1 基于深度神經網絡的聲視覺映射
1.1深度置信網絡
深層次網絡訓練中的高度非凸性(Highly nonconvex property)和梯度擴散(Gradient diffusion)等問題導致直接訓練一個DNN是一件很困難的事情.Hinton等提出一種構建深層次結構神經網絡的切實可行的方案[17].該方法的關鍵在于使用若干個受限的玻爾茲曼機(Restricted Boltzmann machine,RBM)無監督生成預訓練,并將這些RBM逐層依次向上堆砌成一個DBN.生成預訓練階段使每一個RBM接近全局最優,從而確保DBN可以獲得一個更優的網絡權值初值.
1.1.1受限的玻爾茲曼機
RBM是一種可以用無向圖模型表述的概率模型.該無向圖模型擁有兩層結構,且每一層由若干個概率單元組成.一個用于描述輸入數據特征的可見層和一個隱藏層.所有的可見層單元通過一個無向權值與隨機二值的隱藏層單元全連接,而在可見層和隱藏層的層內單元間無連接.
RBM是一個基于能量的模型,在模型參數θ下,記其可見層和隱藏層的聯合組態為,其能量函數為.則可見層與隱藏層的聯合概率分布為
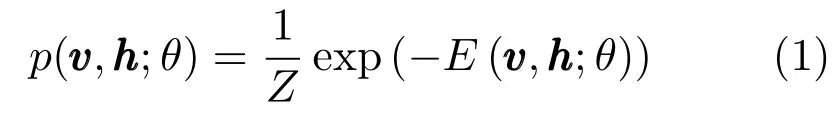
當RBM的可見層和隱藏層單元都是隨機二值類型時,我們采用Bernoulli-Bernoulli RBM(二值RBM).其聯合概率分布的能量函數被定義為
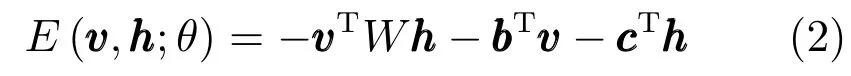
當可見層輸入是實際的特征值時,如語音參數梅爾倒譜系數(Mel-scale frequency cepstral coefficients,MFCC),而隱藏層是隨機二值類型時,我們采用Gaussian-Bernoulli RBM(GRBM)[18].
通常,我們將GRBM輸入端的實際的特征數據進行歸一化處理,使其具有0均值且標準差為1.則其聯合概率分布的能量函數被定義為
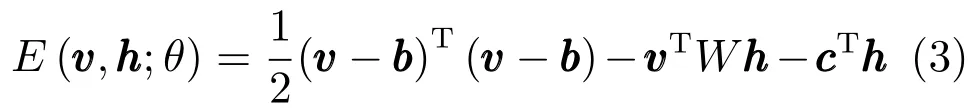
在RBM的生成訓練階段,我們使用對比散度(Contrastive divergence,CD)[19]算法.
1.1.2堆砌RBM成DBN
我們將若干個RBM自下而上一層一層地堆砌成DBN,堆砌規則可參見文獻[20].因為本文中輸入的數據為聲學特征,故最低層RBM本文采用GRBM,其他層為二值RBM.將GRBM隱藏層單元的狀態作為新數據,用于訓練更高一層的二值RBM;而在兩個二值RBM之間使用低層的輸出值作為更高一層的輸入數據.采用這種重復的方法,我們可以獲得期望的隱藏層層數的網絡結構.
1.2搭建并微調DNN結構
本文在DBN的最頂層增加一個線性輸出層形成DNN[21],用于研究聲學特征與發音器官位置信息之間的映射問題.輸入為語音特征參數,輸出為發音器官的位置信息.使用預訓練DBN獲得的各層參數依次初始化與DNN對應的每一層,這樣我們便可以獲得一個接近最優參數的深層網絡結構.最后,我們便可以將DNN當作傳統的ANN,使用誤差反向傳播(Error back propagation,BP)算法進行微調網絡參數.
2 語料庫
本文使用MNGU0數據庫[22]研究聲學特征與發音器官位置信息之間的映射問題.該數據庫采用電磁關節造影技術(Electromagnetic articulography,EMA)并行記錄一個說話者說話時發音器官的位置信息,同時記錄說話者的語音數據資料.如圖1所示,分別記錄上唇(UL)、下唇(LL)、下頜切牙(LI)、舌尖(T1)、舌片(T2)和舌背(T3)上觀測點的位置信息.EMA以200Hz的采樣頻率記錄這6個觀測點的x和y軸坐標值,共計12維數據.至于音頻數據,首先將記錄的語音數據降低采樣頻率至16kHz,然后使用STRAIGHT[23]提取40維頻率扭曲線譜頻率(Frequency-warped line spectral frequencies,LSFs),并加一個增益值.在所有的EMA 和LSFs參數向量的每一個維度上,先減去其平均值,然后除以4倍的標準差,進行歸一化處理.
MNGU0數據庫包含1354個語音片段文件和對應的EMA數據文件.其中,校驗和測試數據集各具有63個音頻和對應的EMA數據文件,則剩余的1228個音頻和對應的EMA數據文件作為訓練數據集.
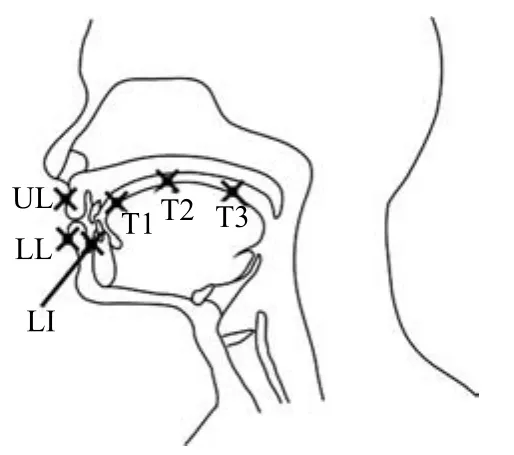
圖1 MNGU0數據庫中EMA記錄發音器官的6個觀測點[22]Fig.1 Positioning of the six electromagnetic coils in the MNGU0 dataset[22]
3 發音器官模型
本文主要驅動的發音器官為嘴部和舌部,我們采用實驗室前期工作基于運動軌跡分析的3D唇舌肌肉控制模型[16].圖2和圖3分別代表三維虛擬人唇部模型和舌部模型.該模型的優點在于通過分析嘴部和舌部的運動軌跡,將其分解為一些機械運動的組合,只需通過計算口輪匝肌外圈肌、舌縱肌等的肌肉收縮量oos、zt和下頜的旋轉角度jaw,便可以很好地實現唇部和舌部的自然運動合成.
根據文獻[16],推出口輪匝肌外圈肌的肌肉收縮量的計算公式如下:
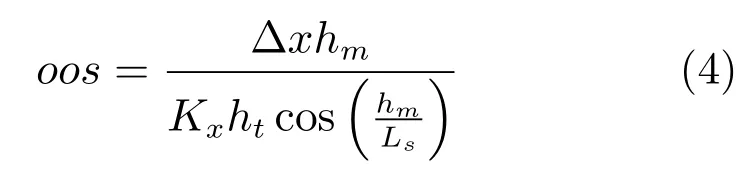
其中,Δx為預測出上唇的x坐標相對其初始狀態的相對變化量;hm為初始狀態下唇舌模型的上下嘴唇高度差;ht為初始狀態下測量的上唇與下唇的y坐標的相對差值;Kx為伸縮系數,通過實驗獲得Kx=0.2;Ls為唇舌模型中唇部長度.
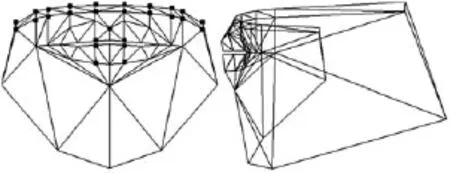
圖2 嘴部網格模型Fig.2 Mouth mesh model
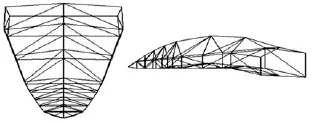
圖3 舌部網格模型Fig.3 Tongue mesh model
計算下頜的旋轉角度jaw的方法如圖4所示.其中,點U和L分別表示上唇和下唇的測量點位置;O′為線段的中點;點J為初始狀態時下頜切牙測量點位置;J′為說話時下頜切牙的一個位置.則計算下頜的旋轉角度公式為

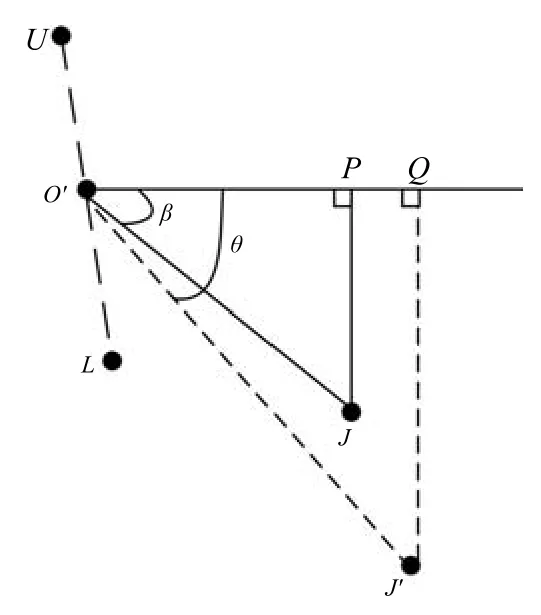
圖4 下頜的旋轉角度分析Fig.4 The rotation of the mandible angle analysis
根據文獻[16],推出舌縱肌的肌肉收縮量的計算公式如下:
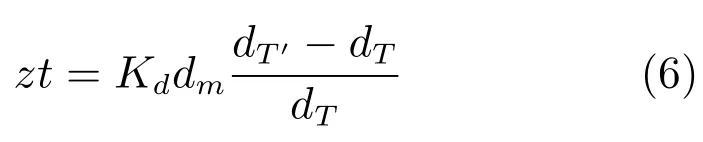
其中,dT為初始狀態下舌片T2與舌尖T1之間的距離;dT′為說話時舌片T2與舌尖T1之間的距離;Kd為伸縮系數,通過實驗獲得Kd=0.05;dm為唇舌模型中舌片與舌尖之間的距離.
我們通過DNN預測輸出的發音器官位置信息可以計算出口輪匝肌外圈肌、舌縱肌等的肌肉收縮量oos、zt和下頜的旋轉角度jaw,從而實現發音器官的運動合成.
4 實驗結果與分析
本文的實驗環境為 Intel Xeon E3-1231 v3 3.4GHz,16GB內存,Window 7,Matlab 2012b,VS2010,OpenGL.
采用均方根誤差(Root mean-squared error,RMSE)評價基于神經網絡的方法實現聲學特征與發音器官位置信息之間映射關系的實驗效果,其定義如下:
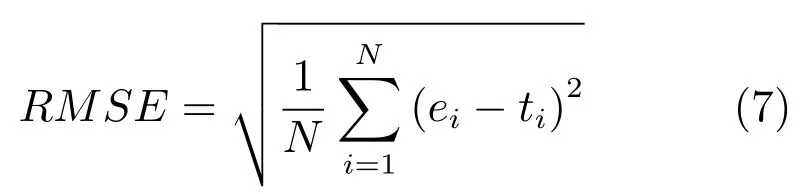
其中,ei為發音器官位置信息的估計值;ti為發音器官位置信息的真實測量值.
本文分別計算發音器官位置信息的每一維RMSE,然后取12維RMSE的平均值作為最終的重構誤差RMSE.
采用文獻[24]的客觀評價方法評價唇部動畫合成的真實度.本文考查實際唇部的歸一化高度與動畫合成唇部的歸一化高度的差值其中,分別是在發音階段實際唇部和動畫合成唇部的高度;分別是在唇部自然閉合狀態下實際唇部和動畫合成唇部的高度.
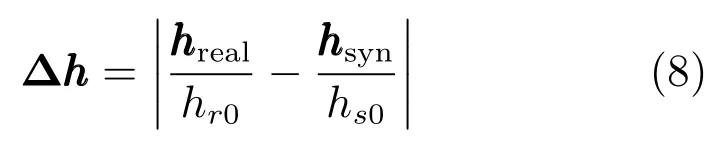
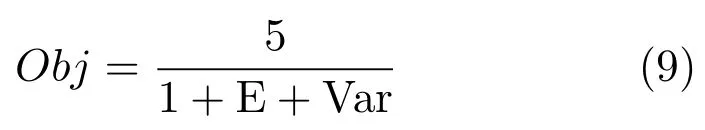
本文分別計算每個測試數據的客觀評測值Obj,并取其均值,作為最終的動畫合成評測結果.
4.1實驗條件
本文使用N個語音幀組成的上下文窗(Context window)作為DNN的輸入數據,調整N獲得最優的實驗結果.因為本文使用41維語音參數(40 維LSFs加1個增益值),因此DNN的輸入層單元數為41×N.至于輸出端,本文不僅選擇與當前上下文窗的中間時刻對應的12維EMA數據,而且還考慮EMA數據的一階和二階差分.所以,DNN輸出層含有36個單元.
在本文中,輸入層為GRBM,其他層為二值RBM.在預訓練階段,本文設置所有RBM的小批量(Mini-batch)為128,動量因子為0.9,未使用權值衰減.設置GRBM的學習速率為0.001,迭代50次;而二值RBM的學習速率為0.01,迭代10次.
在DNN調整網絡權值階段,本文采用BP算法的隨機梯度下降法微調網絡權值,且小批量同為128.設置網絡的學習速率為0.01,動量因子為0.9,迭代500次.在每次迭代時,網絡學習速率的衰減因子為0.99.
4.2ANN和DNN實驗結果的對比
本文進行一系列實驗,比較ANN和DNN的實驗結果優劣.在此次實驗中,本文采用10個語音幀組成的上下文窗作為DNN的輸入層,故輸入層有410個節點單元.ANN和DNN網絡分別含有1至4個隱藏層,且每個隱藏層分別有100、200、300和400個單元,均采用測試數據集進行測試,共得到32組實驗結果,如圖5所示.
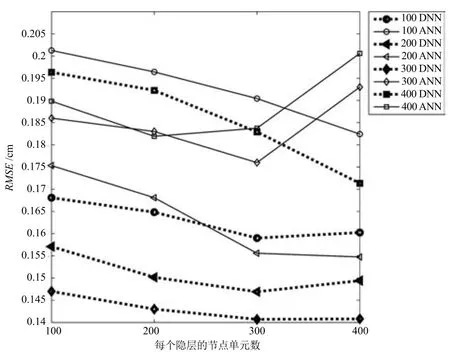
圖5 對比ANN和DNN的實驗結果Fig.5 Comparison on the experimental results of ANN and DNN
從圖5中可知,基于DNN方法的重構誤差明顯小于ANN.因此,使用基于DNN的方法研究聲學特征與發音器官位置信息之間映射關系的效果更優.另外,當DNN含有3個隱藏層,且每個隱藏層層內具有300個單元時,在10個語音幀組成的上下文窗的條件下,其重構誤差最小.
文獻[11]中也選擇MNGU0數據庫作為訓練與測試,其DNN含有4個隱藏層,且每個隱藏層均含有1000個單元的網絡結構.從文獻[11]的結果圖中可以看出,其最優結果大于0.145cm,而本文所得到的最小重構誤差小于文獻[11]中的結果,效果更優.
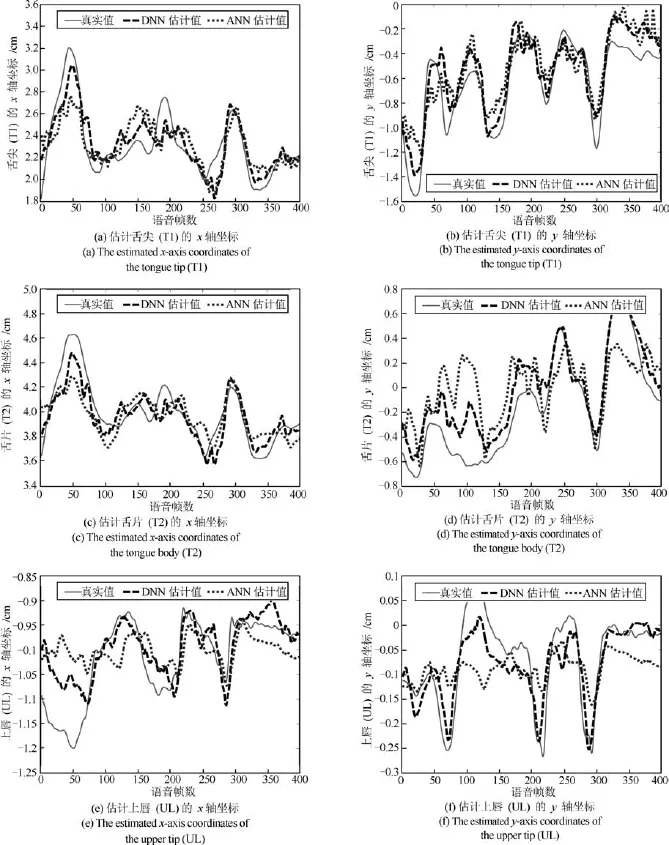
圖6 比較ANN和DNN估計的發音器官運動軌跡Fig.6 Comparison on the estimated articulatory motion trajectories between ANN and DNN
圖6為由400幀語音參數估計出的舌尖(T1)、舌片(T2)和上唇(UL)運動軌跡.圖中實線為真實值,點虛線為ANN估計值,短線虛線為DNN估計值.從圖6中可以看出,采用基于DNN的方法擬合出特征點的運動軌跡更接近真實的運動軌跡,故DNN的擬合效果優于ANN.通過對比重構誤差和擬合T2的運動軌跡這兩個方面,均可以發現DNN優于ANN.
4.3上下文的長度對實驗結果的影響
在基于深度學習的語音識別領域,研究人員發現將長的上下文聲學特征作為輸入端,可以獲得更好的識別效果[25].因此,本文嘗試尋找最佳的上下文窗作為DNN的輸入數據,使估計出發音器官的位置信息的重構誤差最小.本文試驗6~30個語音幀組成的上下文窗,且每次增加4幀.我們采用含有3個隱藏層的預訓練網絡,且在訓練階段均迭代500次,調整隱藏層層內單元數使網絡最優.
實驗結果如表1所示,從中我們發現適當地增加上下文窗的長度可以降低重構誤差,但過長的上下文窗并不能取得更好效果.因此,使用適當長度的上下文聲學特征作為DNN的輸入端,可以有效地降低重構誤差.本文上下文長度為22幀,且DNN每層含有500隱藏單元時,RMSE最小,為0.134cm.
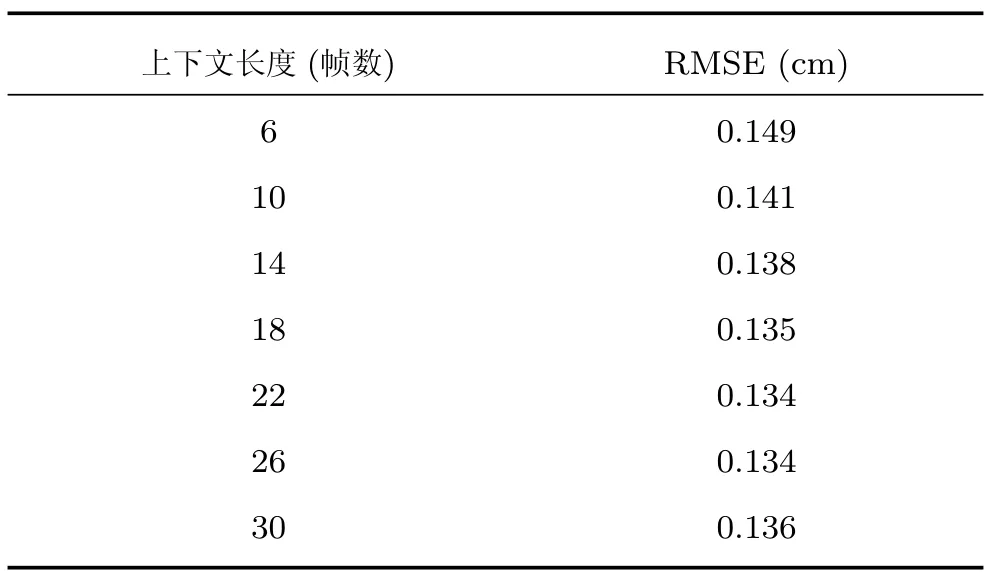
表1 上下文窗的長度對RMSE的影響Table 1 Effect of the length of the context window on the RMSE
4.4唇部動畫評價結果
本文在前兩個實驗結果的基礎上,選取含有3個隱藏層,每層含有500個單元的深度神經網絡,其DNN輸入端為22幀語音參數的最優網絡.我們使用得到的12維發音器官位置信息控制虛擬人動畫合成.
通過本文使用的方法合成測試集中的一段House shook的三維人臉口型動畫.為了方便而直觀地驗證人臉口型動畫的逼真度,錄制真實人臉視頻與基于本文方法合成的動畫進行對比,如圖7所示.
圖7中第1行為真實人臉在說話時的口型截圖,第2行為本文方法合成的三維人臉口型動畫截圖.通過主觀對比評價可以發現,基于本文方法合成的動畫與真實說話人發音口型變化規律相同.
采用客觀評價方法對本文合成的63個測試動畫進行客觀評測,得到評測結果如表2所示.結果表明基于本文方法實現的動畫效果比傳統方法較優,并且動畫合成更加簡易.

表2 客觀評價結果Table 2 Objective assessment results
通過主客觀評價分析,得出本文所實現的方法接近真實說話人的口型動畫變化趨勢,并且合成的口型動畫的綜合客觀評價結果較好.因此,實驗結果證明本文所實現的動畫合成方法簡易有效且逼真.
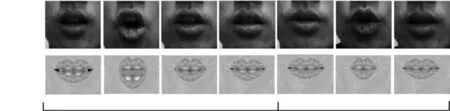
圖7 口型動畫部分截圖Fig.7 Snapshots from the lip animation
5 結論
本文實現一種基于深度神經網絡的語音驅動發音器官運動合成的方法,將其用于語音驅動虛擬說話人系統.通過DNN學習語音特征與發音器官位置信息之間的映射關系,從而根據輸入的語音數據估計出發音器官的運動軌跡,并將其體現在一個三維虛擬人上面.首先,本文在一系列參數下對比ANN 和DNN的實驗結果,得到最優網絡;其次,設置不同上下文聲學特征長度并調整隱層單元數,獲取最佳長度;最后,本文在這兩個結論的基礎上,選取最優網絡結構,由DNN輸出的發音器官位置信息控制發音器官運動合成,實現虛擬人動畫.實驗證明,本文所實現的動畫合成方法高效且逼真,優點在于合成動畫的控制參數少,簡單方便.但是,也存在一些問題,如本文只使用了舌縱肌控制舌部動畫合成,實現舌頭卷起動作,而未考慮控制舌頭厚度變化.因此,在未來工作中會對其進行改善,生成更加逼真的舌部動畫.
References
1 Liu J,You M Y,Chen C,Song M L.Real-time speech-driven animation of expressive talking faces.International Journal of General Systems,2011,40(4):439-455
2 Le B H,Ma X H,Deng Z G.Live speech driven head-andeye motion generators.IEEE Transactions on Visualization and Computer Graphics,2012,18(11):1902-1914
3 Han W,Wang L J,Soong F,Yuan B.Improved minimum converted trajectory error training for real-time speech-tolips conversion.In:Proceedings of the 2012 IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP).Kyoto,Japan:IEEE,2012.4513-4516
4 Ben-Youssef A,Shimodaira H,Braude D A.Speech driven talking head from estimated articulatory features.In:Proceedings of the 2014 IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP).Florence,Italy:IEEE,2014.4573-4577
5 Ding C,Zhu P C,Xie L,Jiang D M,Fu Z H.Speechdriven head motion synthesis using neural networks.In:Proceedings of the 2014 Annual Conference of the International Speech Communication Association(INTERSPEECH).Singapore,Singapore:ISCA,2014.2303-2307
6 Richmond K,King S,Taylor P.Modelling the uncertainty in recovering articulation from acoustics.Computer Speech and Language,2003,17(2-3):153-172
7 Zhang L,Renals S.Acoustic-articulatory modeling with the trajectory HMM.IEEE Signal Processing Letters,2008,15:245-248
8 Toda T,Black A W,Tokuda K.Statistical mapping between articulatory movements and acoustic spectrum using a Gaussian mixture model.Speech Communication,2008,50(3):215-227
9 Xie L,Liu Z Q.Realistic mouth-synching for speech-driven talking face using articulatory modelling.IEEE Transactions on Multimedia,2007,9(3):500-510
10 Uria B,Renals S,Richmond K.A deep neural network for acoustic-articulatory speech inversion.In:Proceedings of the 2011 NIPSWorkshop on Deep Learning and Unsupervised Feature Learning.Granada,Spain:NIPS,2011.1-9
11 Zhao K,Wu Z Y,Cai L H.A real-time speech driven talking avatar based on deep neural network.In:Proceedings of the 2013 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference(APSIPA).Kaohsiung,China:IEEE,2013.1-4
12 Tang H,Fu Y,Tu J L,Hasegawa J M,Huang T S.Humanoid audio-visual avatar with emotive text-to-speech synthesis. IEEE Transactions on Multimedia,2008,10(6):969-981
13 Fu Y,Li R X,Huang T S,Danielsen M.Real-time multimodal human-avatar interaction.IEEE Transactions on Circuits and Systems for Video Technology,2008,18(4):467-477
14 Schreer O,Englert R,Eisert P,Tanger R.Real-time vision and speech driven avatars for multimedia applications.IEEE Transactions on Multimedia,2008,10(3):352-360
15 Liu K,Ostermann J.Realistic facial expression synthesis for an image-based talking head.In:Proceedings of the 2011 IEEE International Conference on Multimedia and Expo (ICME).Barcelona,Spain:IEEE,2011.1-6
16 Yang Yi,Hou Jin,Wang Xian.Mouth and tongue model controlled by muscles based on motion trail analyzing.Application Research of Computers,2013,30(7):2236-2240(楊逸,侯進,王獻.基于運動軌跡分析的3D唇舌肌肉控制模型.計算機應用研究,2013,30(7):2236-2240)
17 Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data with neural networks.Science,2006,313(5786):504-507
18 Hinton G E.A practical guide to training restricted Boltzmann machines.Neural Networks:Tricks of the Trade(2nd Edition).Berlin:Springer-Verlag,2012.599-619
19 Tieleman T.Training restricted Boltzmann machines using approximations to the likelihood gradient.In:Proceedings of the 25th International Conference on Machine Learning (ICML).New York,USA:ACM,2008.1064-1071
20 Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets.Neural Computation,2006,18(7):1527 -1554
21 Hinton G,Deng L,Yu D,Dahl G E,Mohamed A R,Jaitly N,Senior A,Vanhoucke V,Nguyen P,Sainath T N,KingsburyB.Deep neural networks for acoustic modeling in speech recognition:the shared views of four research groups.IEEE Signal Processing Magazine,2012,29(6):82-97
22 Richmond K,Hoole P,King S.Announcing the electromagnetic articulography(day 1)subset of the mngu0 articulatory.In:Proceedings of the 2001 Annual Conference of the International Speech Communication Association(INTERSPEECH).Florence,Italy:ISCA,2011.1505-1508
23 Kawahara H,Estill J,Fujimura O.Aperiodicity extraction and control using mixed mode excitation and group delay manipulation for a high quality speech analysis,modification and synthesis system STRAIGHT.In:Proceedings of the 2nd International Workshop Models and Analysis of Vocal Emissions for Biomedical Application(MAVEBA). Firenze,Italy,2001.59-64
24 Li Hao,Chen Yan-Yan,Tang Chao-Jing.Dynamic Chinese visemes implemented by lip sub-movements and weighting function.Signal Processing,2012,28(3):322-328(李皓,陳艷艷,唐朝京.唇部子運動與權重函數表征的漢語動態視位.信號處理,2012,28(3):322-328)
25 Deng L,Li J Y,Huang J T,Yao K S,Yu D,Seide F,Seltzer M,Zweig G,He X D,Williams J,Gong Y F,Acero A.Recent advances in deep learning for speech research at Microsoft. In:Proceedings of the 2013 IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP). Vancouver,Canada:IEEE,2013.8604-8608

唐 郅西南交通大學信息科學與技術學院碩士研究生.主要研究方向為虛擬說話人動畫與模式識別.
E-mail:tang_zhi@126.com
(TANG ZhiMaster student at the SchoolofInformationScienceand Technology,Southwest Jiaotong University.His research interest covers talking avatar animation and pattern recognition.)

侯 進西南交通大學信息科學與技術學院副教授.主要研究方向為計算機動畫,數字藝術和自動駕駛.本文通信作者.
E-mail:jhou@swjtu.edu.cn
(HOU JinAssociate professor at the School of Information Science and Technology,Southwest Jiaotong University.Her research interest covers computer animation,digital art,and automatic driving. Corresponding author of this paper.)
Speech-driven Articulator Motion Synthesis with Deep Neural Networks
TANG Zhi1HOU Jin1
This paper implements a deep neural networks(DNN)approach for speech-driven articulator motion synthesis,which is applied to speech-driven talking avatar animation synthesis.We realize acoustic-articulatory mapping by DNN. The input of the system is acoustic speech and the output is the estimated articulatory movements on a three-dimensional avatar.First,through comparison on the performance between ANN and DNN under a series of parameters,the optimal network is obtained.Second,for different context acoustic length configurations,the number of hidden layer units is tuned for best performance.So we get the best context length.Finally,we select the optimal network structure and realize the avatar animation by using the articulatory motion trajectory information output from the DNN to control the articulator motion synthesis.The experiment proves that the method can vividly and efficiently realize talking avatar animation synthesis.
Deep neural networks(DNN),speech-driven,motion synthesis,talking avatar
10.16383/j.aas.2016.c150726
Tang Zhi,Hou Jin.Speech-driven articulator motion synthesis with deep neural networks.Acta Automatica Sinica,2016,42(6):923-930
2015-10-31錄用日期2016-05-03
Manuscript received October 31,2015;accepted May 3,2016
成都市科技項目(科技惠民技術研發項目)(2015-HM01-00050-SF),四川省動漫研究中心2015年度科研項目(DM201504),西南交通大學2015年研究生創新實驗實踐項目(YC201504109)資助
Supported by Science and Technology Program of Chengdu (Science and Technology Benefit Project)(2015-HM01-00050-SF),2015 Annual Research Programs of Sichuan Animation Research Center(DM201504),and 2015 Graduate Innovative Experimental Programs of Southwest Jiaotong University(YC2015 04109)
本文責任編委柯登峰
Recommended by Associate Editor KE Deng-Feng
1.西南交通大學信息科學與技術學院成都611756
1.School of Information Science and Technology,Southwest Jiaotong University,Chengdu 611756
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學)(2021年12期)2021-03-16 05:40:38
小學科學(學生版)(2020年10期)2020-10-28 07:52:18
文苑(2019年22期)2019-12-07 05:28:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
學生天地(2016年9期)2016-05-17 05:45:06
中外會展(2014年4期)2014-11-27 07:46:46
