陣列眾核處理器上的高效歸并排序算法
2016-07-31 23:32:23李宏亮
計算機研究與發展 2016年2期
石 嵩 李宏亮 朱 巍
(江南計算技術研究所 江蘇無錫 214083)(shisong1990@163.com)
陣列眾核處理器上的高效歸并排序算法
石 嵩 李宏亮 朱 巍
(江南計算技術研究所 江蘇無錫 214083)
(shisong1990@163.com)
排序是計算機科學中最基本的問題之一,隨著眾核處理器結構的不斷發展,設計眾核結構上的高效排序算法具有重要意義.眾核處理器的一個重要方向是陣列眾核處理器,根據陣列眾核處理器的結構特點,提出了2種面向陣列眾核結構的高效歸并排序算法,通過利用DMA(direct memory access)多緩沖機制提高訪存效率、深度平衡歸并策略保持眾多核心之間的負載均衡、SIMD(single instruction multiple data)歸并方法提高歸并計算效率以及片上交換歸并策略提高片上數據重用率,大幅度提高了陣列眾核處理器的排序性能.在異構融合陣列眾核處理器DFMC(deeply-fused many-core)原型系統的實驗結果表明,算法排序速度達647MKeys?s(million keys per second),其排序效率(排序速度?峰值性能)是NVIDIA GPU上最快的歸并排序算法(GTX580平臺)的3.3倍,是Intel Xeon Phi上最快的歸并排序算法的2.7倍.最后,建立了陣列眾核處理器上歸并排序算法的性能分析模型,利用該模型分析了主要結構參數與算法性能的關系,對陣列眾核處理器的研究有一定的指導意義.
排序是計算機科學及算法研究中最基本、最重要的研究問題之一[1],是數據庫、圖運算、科學計算以及大數據等諸多重要應用的基礎,排序效率對這些應用程序的性能有重要的影響,在不同計算平臺和環境上不斷提高排序的性能,具有重要的現實意義.
近年來,眾核處理器在學術界和工業界得到了廣泛關注和蓬勃發展,已在多個領域得到了廣泛應用.當前主要的眾核處理器和眾核結構包括NVIDIA的GPU系列、AMD的GPU?APU系列、Intel的MIC(many integrated core)和SCC(single-chip cloud computer)構架,以及Tilera[2],PACS-G[3],epiphany[4],MPPA[5],Godson-T[6],DFMC[7]等.其中Tilera,PACS-G,epiphany,MPPA,Godson-T,DFMC等屬于陣列眾核處理器,它們的共同特點是以陣列方式組織眾多計算核心,具有可擴展性好、實現代價低的優點,是眾核處理器發展的重要方向.
隨著這些新型眾核處理器的不斷涌現,需要重新設計適應特定體系結構的排序算法,才能最大限度地發揮出處理器的運算潛力.國內外學者在GPU和Intel Xeon Phi(屬于MIC結構)上開展了大量研究工作,并取得了很好的效果[8-11],但陣列眾核結構上排序算法的研究尚較少.
盡管陣列眾核處理器提供了強大的計算能力,但是要發揮好性能需要用戶利用更多的底層硬件特征.針對排序算法,需要解決3個關鍵的問題:1)訪存問題,陣列眾核中核心數目多,單個核心所能分得的帶寬資源少,導致存儲墻問題嚴重;2)眾多核心之間的負載均衡問題;3)開發SIMD級并行性的問題,雖然陣列眾核的計算核心通常提供SIMD指令以增加并行性,但是以SIMD方式實現排序并不容易.
本文首先建立了陣列眾核處理器結構的共性抽象模型,然后設計了面向陣列眾核結構的高效歸并排序算法.算法通過利用DMA多緩沖機制提高訪存效率、深度平衡歸并策略保持核心間的負載均衡、SIMD歸并方法開發SIMD并行性以及片上交換歸并策略重用片上數據,有效提升了排序性能.算法在DFMC原型系統上的實驗結果優于NVIDIA眾核以及Intel Xeon Phi眾核上的基于比較的排序算法.最后,本文建立了算法性能分析模型,并用該模型討論和分析了陣列眾核結構與算法性能的關系,為陣列眾核結構的研究提供了參考.
1 相關工作
排序問題由來已久,經過半個多世紀的發展,串行排序算法的研究已經非常成熟且許多算法如快速排序、基數排序等已接近理論最優.近些年來,研究人員主要將精力集中在結構相關特別是新型體系結構如GPU和MIC等眾核結構上的排序算法的優化上,取得了許多進展.這些排序算法主要分為2類:基數排序和基于比較的排序.
基數排序是最為高效的排序之一,對于d位的鍵值,其時間復雜度是O(dN),文獻[8,12-14]分別提出和實現了GPU上的基數排序算法,其中Merrill等人[8]的基數排序被集成到了Thrust庫中,是當前最快的基數排序算法.Satish等人[10]實現了MIC結構上的基數排序算法,有很好的性能.然而,基數排序的時間開銷隨著鍵值長度的增加而增長,而且,基數排序不是基于比較的排序,通用性不足.
基于比較的排序是一類通用的排序方法,包括雙調排序、快速排序、采樣排序(sample sort)和歸并排序等,其時間復雜度的下界是O(Nlog N).
雙調排序是由Batcher[15]于20世紀60年代提出的一種排序網絡算法,采用分治法歸并序列,時間復雜度是O(Nlog2N),雖然不是漸進最優,但是由于其并行性好,且具有訪存連續、對界的優點,所以在GPU上有很好的運用.文獻[16-17]在GPU上實現了雙調排序,Greb等人[18]設計實現了GPU上自適應雙調排序(adaptive bitonic sort)算法,將時間復雜度從O(Nlog2N)降低到O(Nlog N).雙調排序較高的時間復雜度限制了其在數據量很大的排序中的應用.
Sengupta等人[12]首先實現了GPU上的快速排序算法,隨后Cederman等人[19-20]進一步做了改進.采樣排序是快速排序的一種推廣,它一次將輸入劃分成多個部分而非快速排序中的2部分,然后獨立地排序各個部分.Leischner等人[21]在GPU上實現了采樣排序.盡管快速排序的時間復雜度是O(Nlog N),但是其并行程序實現復雜,且性能表現不突出.
歸并排序的時間復雜度是O(Nlog N),由于并行性好且時間復雜度低,是GPU上廣泛使用的排序算法之一[9,14,22-23],這些工作主要針對GPU的結構特點在訪存、同步、通信上對算法做優化,使歸并排序算法更適合GPU結構.其中Davidson等人[9]的歸并排序是當前GPU上最快的歸并排序算法.Tian等人[11]設計了Intel Xeon Phi眾核上的歸并排序算法,是目前最快的歸并排序算法.
由于基數排序的通用性不夠,而基于比較的其他算法如雙調排序、快速排序等具有時間復雜度高或者并行化困難且并行程序效率不高的缺點,所以本文選取歸并排序進行研究.
2 陣列眾核處理器結構
陣列眾核結構最主要的特征是多個計算核心以陣列方式(mesh)組織,可以分為同構陣列眾核和異構陣列眾核2類,其中同構陣列眾核全部由計算核心陣列構成,異構陣列眾核在計算核心陣列外還有額外的管理核心,后者可視為前者的一般化情形,本文抽象的陣列眾核結構采用后者,但是所設計的算法對于2種結構均適用.
陣列眾核處理器的整體結構如圖1所示,包括管理核心MPE(management processing element)、計算核心陣列CPA(computing processing array)、存控和系統接口,通過片上網絡NoC互連.
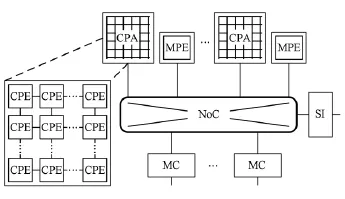
Fig.1 The array-based manycore architecture.圖1 陣列眾核結構
其中MPE是功能完整的通用核心,負責提供一些標準服務如IO代理和消息代理等,也適合運行程序的串行部分.CPA由若干計算核心CPE(computing processing elements)以陣列方式組織構成,陣列內的CPE可通過高速的顯式或者隱式的片上通信(如消息)交換數據.CPE是功能簡單的運算核心,支持SIMD指令以開發細粒度的并行性、提高峰值性能,用以加速大規模的并行任務.
陣列眾核處理器中CPA的數據存儲構架如圖2所示.CPE內具有片上存儲器SPM(scratched pad memory),或CPA中共享片上存儲器(本文敘述采用前者).SPM可配置為數據Cache結構,也可配置為由軟件顯式管理的局部存儲器,配置為Cache結構可以減輕軟件編程的負擔,但是由于需要保持眾多核心之間的Cache一致性,效率比作為局部存儲器低.本文將SPM視為局部存儲器,SPM與主存之間通過軟件顯式管理的DMA傳輸數據.
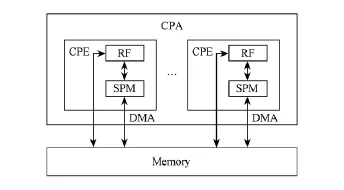
Fig.2 The data memory hierarchy of CPA.圖2 CPA的數據存儲構架
從陣列眾核結構可以看出,陣列眾核提供了2種粒度的并行性,核心或陣列之間的粗粒度線程級并行性SPMD(single program,multiple data)和核心內的細粒度并行性SIMD,因此設計陣列眾核上的并行算法要充分利用這2種并行性才能充分發揮處理器的性能.另外,陣列眾核結構提供的陣列內高速片上通信使算法可以通過交換核心間的數據而減少訪存操作.
3 陣列眾核處理器上的歸并排序算法
歸并是指將2個有序序列合并成1個新的有序序列.歸并排序是基于歸并操作的排序,它采用分治的策略先將待排序序列分成若干小的子序列,將各個子序列排序后,利用歸并操作將各子序列逐步歸并成有序序列.對于長度為N的序列,串行算法的時間復雜度是O(Nlog N),空間復雜度是O(N).
3.1 基本的并行歸并排序算法
歸并排序是一種自底向上的分治算法,并行歸并排序算法將數據劃分到各個CPE,各CPE用串行歸并排序算法對自己所持數據進行排序后,相互協作將各有序子序列歸并成整體有序的序列.基本并行歸并排序的流程如下:
步驟1.將N個數據均勻劃分到C個陣列;
步驟2.各陣列將數據均勻劃分給陣列內的P個核心;
步驟3.各核心使用歸并排序完成N?(C×P)個數據的排序;
步驟4.陣列內將各個有序子序列歸并成1個有序序列;
步驟5.C個陣列協作將C個有序子序列歸并成有序序列.
根據該流程本節首先實現一種基本的并行歸并排序算法作為參照,該算法不使用SIMD與片上通信,沒有顯式管理訪存,CPE內的排序使用一般的串行歸并排序算法,CPE間的歸并過程如算法1所示:
算法1.核間基本歸并算法.

基本并行歸并排序算法的優點是實現簡單,但是該算法沒有考慮陣列眾核的結構特點,存在以下3個問題:1)沒有使用SPM導致訪存延遲大且存儲帶寬效率低;2)雖然使用了SPMD,但是各核心間存在負載不均衡,分析算法1可知,隨著歸并級數遞增1級,參加歸并的CPE的數目減半;3)沒有使用處理器提供的SIMD和片上通信對算法進行加速.
根據陣列眾核的結構特點,本節接下來從不同層面解決和優化了這些問題和算法,在訪存管理上設計了DMA多緩沖機制提高訪存效率,在線程級并行層次設計了深度平衡歸并策略保持核心間的負載均衡,在SIMD層次設計了SIMD歸并方法提高歸并計算速度,以及利用片上通信提高片上數據重用率,獲得了很好的性能提升,最終實現了2種優化的歸并排序算法CPEB-MS(CPE-based merge sort)和CPAB-MS(CPA-based merge sort).其中CPEB-MS以CPE為單元,即各CPE先將自己所持數據排序,然后各CPE之間進行歸并.CPAB-MS則以CPA為單元,即CPA作為一個整體將自己所持數據排序,然后CPA間進行歸并.
3.2 CPEB-MS算法
CPEB-MS的整體流程與基本算法相似,先將數據分配給各CPE,CPE先用歸并排序將所持數據排序,然后CPE間協作完成歸并.該算法從3個層面——訪存管理、線程級并行和SIMD——進行了優化.
3.2.1 訪存管理——DMA多緩沖機制
基本歸并排序算法的訪存問題主要是由于CPE直接讀寫主存(使用LD?ST指令),一方面小數據量的訪存操作造成存儲帶寬的利用率低,另一方面計算過程和訪存過程不能實現并發執行,從而算法整體性能差.
DMA多緩沖機制在SPM中開辟2個讀緩沖bufA,bufB和1個寫緩沖bufC,每個緩沖分為2份,構成雙緩沖.以bufA為例,分為bufA0和bufA1,初始時使用DMA將數據裝填到bufA0中,之后CPE使用bufA0中的數據進行計算,同時利用DMA將數據裝填到bufA1中;當CPE計算完bufA0的數據后等待bufA1的裝填結果,若已裝填好,則CPE使用bufA1中的數據同時裝填bufA0,持續這個過程直到完成所有數據的歸并.
DMA多緩沖的運用一方面使得主存的訪問次數大為減少,提高了存儲帶寬的實際效率,CPE的數據訪問延遲大為減小;另一方面,多緩沖使得歸并的訪存時間和計算時間重疊,最大限度掩蓋了訪存延遲.
3.2.2 核心負載均衡——深度平衡歸并策略
使用多線程主要需要考慮的2個問題是負載均衡和通信,歸并算法需要的核間通信很少,因此主要要解決負載均衡的問題.基本歸并排序算法中的核間歸并過程會造成CPE間負載不均衡的問題,即在步驟3中,歸并級數每增加1級,參與歸并的CPE就減少一半(如圖3(a)所示).針對這一問題,設計了一種基于采樣劃分的深度平衡歸并策略,保證在歸并過程中,所有CPE都始終參與歸并.
采樣劃分通過采樣的方法將2個有序序列A和B各劃分成p個不相交的塊A0,A1,…,Ap-1和B0,B1,…,Bp-1,當i≠j時,Ai和Bj不相交.其中劃分元的選取過程如算法2所示,根據p-1個劃分元,分別將A和B劃分成p塊(長度可能為0),下標相同的塊屬于同一組,完成劃分.
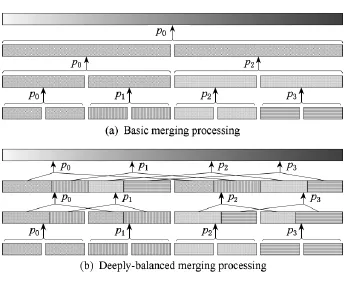
Fig.3 The basic merging processing and the deeplybalanced merging processing(different textures are merging by different CPE).圖3 基本歸并與深度平衡歸并示意圖
算法2.采樣選取劃分元算法.

可以證明采樣劃分后各個組的數據量是均勻分布(除第1組和最后1組有偏斜).深度平衡歸并策略如圖3(b)所示,在第k級(最底層為第0級),用采樣劃分將2個子序列劃分成2k組,分別分給2k個CPE,然后各CPE對分給自己的數據進行歸并.從圖3(b)可以看出,每一級歸并的CPE數目不變且各CPE的任務量相當,保持了負載均衡.
3.2.3 使用SIMD——SIMD并行歸并方法
傳統歸并過程中的循環體1次寫回1個數據,SIMD并行歸并的目標是1次寫回K(SIMD寬度)個數據,從而減少每個數據的時間攤銷.
20世紀60年代,Batcher等人[15]提出了基于Batcher比較器的歸并網絡,如奇偶歸并網絡、雙調歸并網絡,可在O(log N)的時間內完成歸并.圖4顯示了一個長度為8的雙調歸并網絡,垂直線表示比較器,上(下)端輸出較小(大)值,網絡通過lb(8)=3級比較操作,可以將2個長度為4的有序序列A[0,1,2,3]和B[0,1,2,3]歸并成1個有序序列.
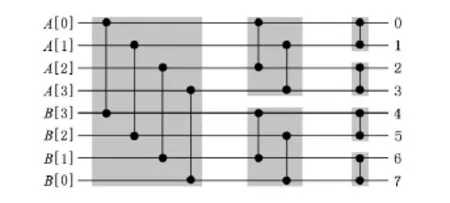
Fig.4 Bitonic merge network.圖4 雙調歸并網絡
利用歸并網絡,可以實現1次輸出多個數據的目標,長度為2 K的雙調歸并網絡,每次可輸出K個結果(較小的K個數據),另外的K個數據則繼續和接下來讀入的K個數據進行歸并,重復該過程直到歸并完所有數據.歸并網絡可映射成SIMD指令實現,如圖4中,A和B分別放置在2個向量寄存器中,則每一級的4個比較器可以用CPE中SIMD指令集中的1條vmax(取較大值)指令和1條vmin(取較小值)指令實現,而在1次比較之后,2個寄存器的值可通過混洗指令vshuffle混洗,以滿足下一級比較的輸入位置要求.
為了運用SIMD歸并網絡,需要先將輸入序列排成長K有序的子序列.該過程可通過基于排序網絡和混洗操作的寄存器排序完成,如圖5所示,將K2個元素放置在K個寄存器中,首先用長度為K的奇偶歸并排序網絡將它們(如A[0,1,2,3])排序成K個長K有序的序列(如a0,a1,a2,a3),如圖5(a)所示,然后通過Klb(K)次vshuffle操作將各有序序列混洗到單個寄存器中(圖5(b)).
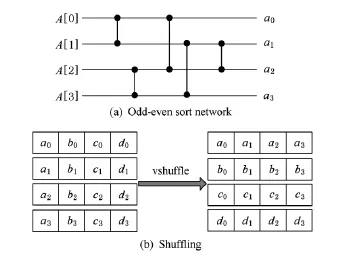
Fig.5 In-register sort with SIMD.圖5 SIMD寄存器排序
3.2.4 CPEB-MS算法流程
結合上述3.2.1~3.2.3小節的內容,總結出CPEB-MS算法整體流程如下:
步驟1.將N個數據均勻劃分給各CPE(C個CPA,每個CPA中P個CPE,共C×P個CPE),每個核心有N?(C×P)個數據;
步驟2.各CPE使用步驟2.1~2.2完成N?(C×P)個數據的排序:
2.1)將所持數據分為N?(C×P)?M個組,每組M個數據(可以存放于SPM緩沖中),使用步驟2.1.1~2.1.2對每一組進行排序:
2.1.1)用寄存器排序將序列排序成長K(SIMD寬度)有序的序列;
2.1.2)使用lb(M?K)次SIMD歸并,逐步將長K有序的子序列歸并成1條有序序列;
2.2)各CPE使用lb(N?(C×P)?M)次SIMD歸并將自己所有的長為M的有序子序列歸并成1個有序序列(讀寫數據使用DMA多緩沖技術);
步驟3.CPA內各CPE利用lb(P)次深度平衡歸并策略將P個有序子序列歸并成1個有序序列(讀寫數據使用DMA多緩沖技術);
步驟4.C個CPA繼續應用lb(C)次深度平衡歸并策略將C個有序子序列歸并成整體有序序列(讀寫數據使用DMA多緩沖技術).
3.3 CPAB-MS算法
CPEB-MS中各CPE首先將所持數據排序成有序序列然后CPE間進行歸并的流程沒能利用陣列眾核結構提供的片上通信支持來減少訪存次數.因此本文繼續設計了CPAB-MS算法,它將CPA視為一個整體,算法將數據分給各CPA,各CPA先將所持數據排序,然后CPA之間進行歸并.
3.3.1 使用片上通信——片上交換歸并策略
在CPEB-MS算法流程中的步驟2.1中,各CPE排序M個元素后即將其寫回主存,接著處理后M個元素.與此不同,片上交換歸并的策略是,各CPE排序完M個元素后不直接寫回主存,而是由陣列選出P-1個劃分元,各CPE根據劃分元劃分所持的M個元素,將各分塊發送到其他對應的CPE(數據交換),數據交換后,歸并所接收的各分塊,然后CPA內利用前綴和計算出各CPE所持數據的偏移位置,將其寫回主存,得到長為P×M的有序序列.
其中,劃分元的選取和深度平衡歸并中的方法類似,不同的是,這里為了降低空間復雜度采用2級采樣劃分策略:行劃分和列劃分.首先是行劃分,每個CPE選取P-1個代表元發送到本行第1列的核心Px0(x=0,1,…,P-1),Px0對這些數據進行排序后選取P-1個代表元發送給P00,P00對其排序后選出P-1個劃分元廣播給所有CPE,完成劃分元的選取.與直接采樣劃分策略相比,這里的2級劃分策略的空間復雜度從P2降低到了P3?2.
數據交換過程是一個全局通信操作,由于各CPE待交換的數據長度可能不一致,通信過程非常復雜.為了解決該問題,本文設計了基于握手的點對點通信策略來完成全局通信:共P-1次點對點通信,每次通信在數據傳輸之前源節點先將子序列長度發送給目的節點(握手).第i 槡P+j次通信中(如圖6所示),節點Pm,n發送第(mi)槡P+(nj)塊數據Ami,nj①給Pmi,nj,而從Pmi,nj那里接收數據,如果這2個節點不同行且不同列,則Pm,n與Pmi,nj(Pmi,nj)之間的通信需要1個轉發節點Pmi,n(Pm,nj)轉發,源節點先把數據發送到轉發節點上,然后由轉發節點發送至目的節點.該通信模式可以保證所有CPE能并發進行點對點通信,不會出現空閑或者死鎖的狀態.
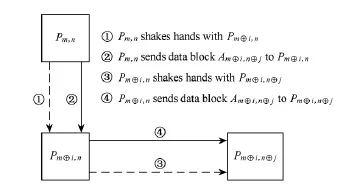
Fig.6 Data communication processing.圖6 數據發送過程示意圖
3.3.2 CPAB-MS算法流程
綜合3.2節和3.3.1節所設計的4項優化技術,總結出CPAB-MS算法整體流程如下:
步驟1.將N個數據均勻劃分到C個CPA,每個陣列有N?C個數據;
步驟2.各CPA將所持數據分為(N?C)?(P× M)個組,每組P×M個數據(可以存放于CPA內各CPE的SPM中),使用步驟2.1~2.2對每一組數據進行排序:
2.1)每個CPE讀取M個數據到SPM,使用步驟2.1.1~2.1.2完成M個數據的排序:
2.1.1)用寄存器排序將序列排序成長K(SIMD寬度)有序的序列;
2.1.2)使用lb(M?K)次SIMD歸并,逐步將長K有序的子序列歸并成1條有序序列;
2.2)CPA內各CPE通過片上交換歸并策略將P×M個數據排成有序序列;
步驟3.CPA內各CPE利用lb(N?(C×P× M))次深度平衡歸并策略將N?(C×P×M)個有序子序列歸并成1個有序序列(讀寫數據使用DMA多緩沖技術);
步驟4.C個CPA繼續應用lb(C)次深度平衡歸并策略將C個有序子序列歸并成整體有序序列(讀寫數據使用DMA多緩沖技術).
4 實驗結果與分析
4.1 實驗環境
異構融合陣列眾核處理器DFMC的結構包括4個MPE,4個CPA共256個CPE,主頻1.0GHz,支持128b(2個64b整數或浮點運算)的SIMD指令,每個CPE擁有32KB局存,局存訪問延遲3周期,局存與主存間支持多種DMA模式傳輸,CPA內支持片上通信,單次主存訪問延遲約100周期,主存帶寬102.4GBps,芯片32位整數運算峰值性能512GOps(giga operations per second).軟件配置是,MPE運行在內核為2.6.28版本的Linux系統上,CPE的系統是一個輕量級的定制系統,編程環境是定制的提供并行編程的C語言.
目前DFMC原型系統采用FPGA構建,時鐘頻率2.6MHz,如圖7所示.實驗在該原型系統上進行,所得的實驗結果根據真實的時鐘頻率進行校準.
4.2 優化效果
實驗中待排序的數據是均勻分布的32位整數序列,數據量從220增長到256×220,實驗算法包括基本并行歸并、CPEB-MS和CPAB-MS三種.圖8顯示了3種算法的排序速率(序列長度與排序時間的比值),結果表明,與基本算法相比,CPEB-MS和CPAB-MS的排序速度得到了巨大的提升,平均分別提升了158倍和194倍.CPAB-MS的排序速度相對CPEB-MS平均提升了23%,這是因為CPABMS通過片上通信重用片上數據減少了訪存次數.然而,CPAB-MS中片上通信是有代價的,將在第5,6節進一步分析.

Fig.7 DFMC FPGA prototype system.圖7 FPGA搭建的DFMC原型系統
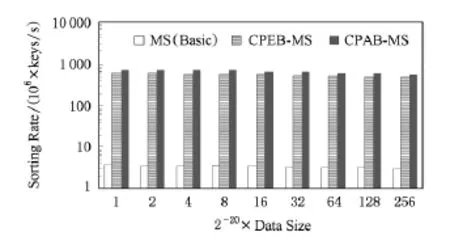
Fig.8 Sorting rates of the three merge sort algorithms for varying sequence sizes.圖8 3種歸并排序算法的排序速率
其中各項優化技術所提供的加速比如表1所示.從表1可以看出,多緩沖和深度平衡歸并所提供的加速比非常大,說明基本算法中由于訪存低效和負載不均衡導致的性能問題非常嚴重.與之相比,SIMD歸并和片上交換歸并策略所提供的性能增益相對較小,這是因為通過前2項技術后,存儲帶寬的利用率已接近極限,此時,SIMD計算所帶來的性能提升受限于訪存瓶頸,而片上交換歸并所減少的訪存次數受限于CPA內各CPE的SPM大小之和.

Table1 Speedups of All Optimization Techniques表1 各優化技術加速比
4.3 與其他平臺排序算法的比較
實驗選取了近幾年來眾核處理器上效率最高的幾種比較型排序算法進行對比.在GPU方面,選取了NVIDIA GTX580上的歸并排序(GPU Merge)[9]、NVIDIA Tesla C1060上的采樣排序(GPU Sample)[21]、CPU-GPU(Intel i7 980+GTX580)混合結構上的采樣排序(Hybrid Sample)[24];在Intel Xeon Phi眾核上,選取了歸并排序(Xeon Phi Merge)[11]進行比較,實驗數據均來源于公開發表的文獻.表2顯示了這些處理器的性能參數.
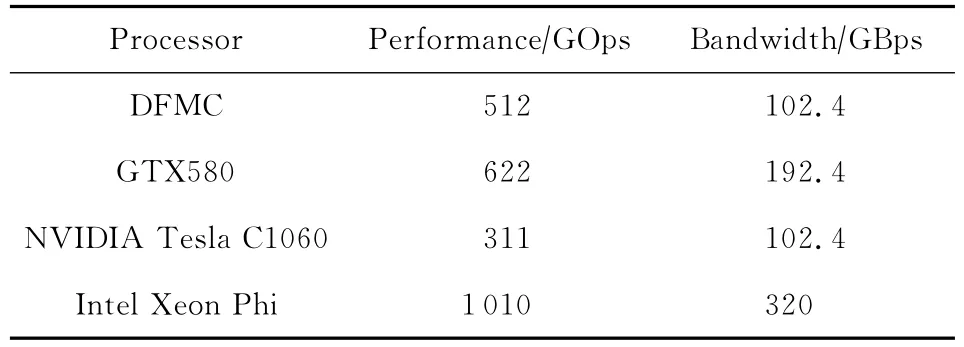
Table 2 The Parameters of Referred Processors表2 處理器參數
實驗結果如圖9所示,可以看出,在所有這些比較型排序中,DFMC上的實驗結果是最好的,如數據量為16×220時,DFMC Merge的排序速度達到647MKeys?s,是GPU Merge的2.7倍,是GPU Sample的5.5倍,是CPU-GPU混合結構上Hybrid Sample的2.4倍;比Xeon Phi上歸并排序排序快36%.折算成同等峰值性能,DFMC上的歸并排序的排序效率(排序速率與峰值性能的比值)是GTX580歸并排序的3.3倍,是Xeon Phi上歸并排序的2.7倍.CPAB-MS算法比其他處理器上比較型排序算法效率高的主要原因是CPAB-MS充分利用了陣列眾核結構的硬件特征,最大限度地發揮了處理器的性能.
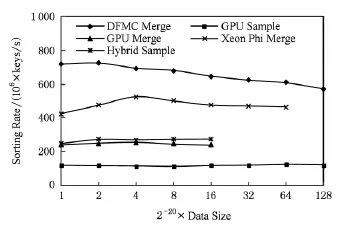
Fig.9 Sorting performance of different methods on different platforms.圖9 不同平臺排序算法性能比較
5 算法性能模型
本節建立算法性能的分析模型,用以指導算法的優化以及分析陣列眾核結構與算法性能之間的關系.
5.1 模型建立
陣列眾核上并行歸并程序的執行時間主要包括訪存時間、計算時間和片上通信時間(針對CPABMS).設τm是歸并過程中單次單個元素的平均訪存時間,τc是歸并過程中單次單個元素的平均計算時間,τs是單個元素的平均寄存器排序時間,τi是單個元素的平均片上通信時間.則CPEB-MS算法框架中步驟2的時間是
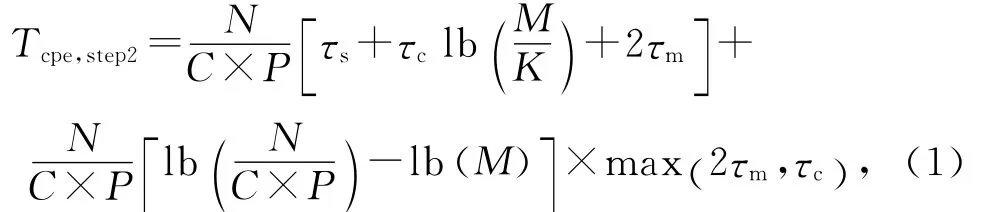
其中N,M,K分別表示數據量、SPM緩沖中可容納的元素數目和SIMD寬度,C表示陣列數,P表示每個陣列中的核心數.max(2τm,τc)是由于多緩沖使得計算時間和訪存時間重疊,總的執行時間是這二者的最大值,τm前的系數2說明讀寫2次操作.步驟3和步驟4的時間之和是
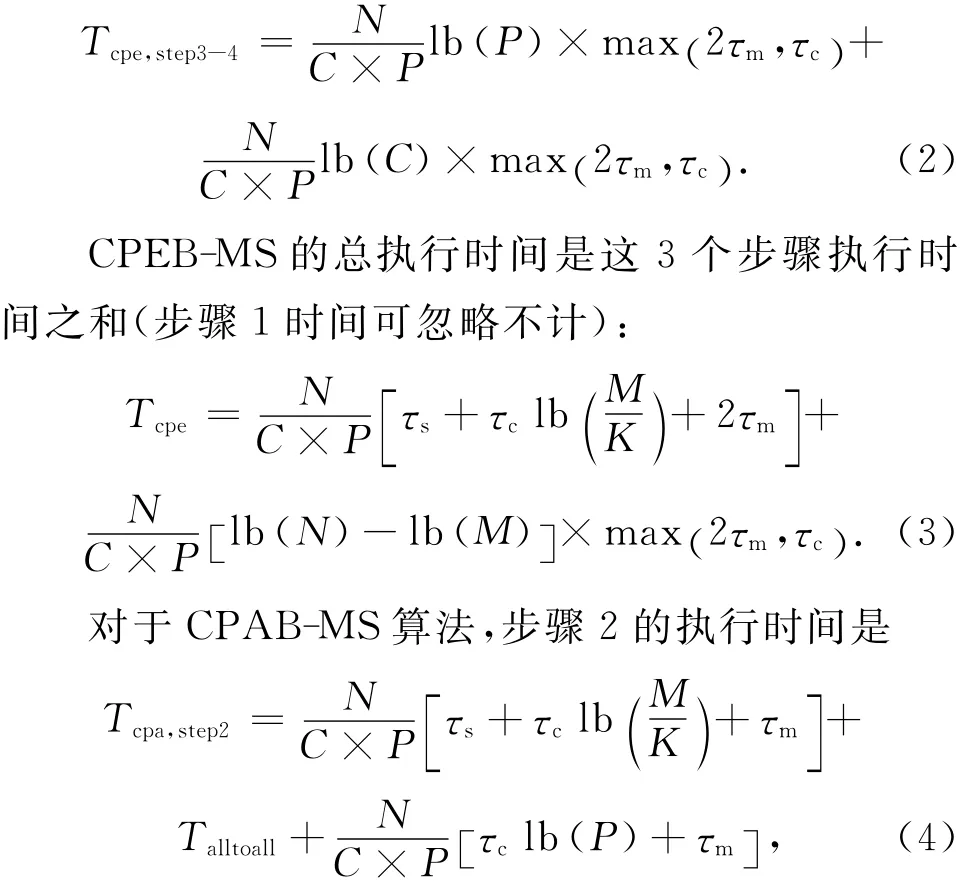
其中Talltoall是片上通信時間,片上通信時間與數據分布有關,最好的情形,即已經完全有序,無需通信,Talltoall=O(1);最壞的情形,每次點對點通信的傳輸數據量達到N?(C×P),Talltoall=P×N?(C×P)×2τi;一般情形,平均時間是Talltoall,ave=N?(C×P)×2τi.

CPAB-MS算法的總執行時間是這3個步驟執行時間之和:

式(3)、式(6)~(8)可以作為陣列眾核上歸并排序算法的性能模型,通過調整系數,可以表示不同結構上的性能模型.例如,若眾核不支持SIMD指令,則K=1;若眾核具有共享片上存儲,則Talltoall=0.
5.2 性能模型誤差
我們在DFMC原型系統上檢驗了算法性能模型的準確度.性能模型中的τm,τc,τs,τi可通過程序代碼、存儲帶寬和時鐘頻率計算出來,其他系數可由結構參數得到,從而算出執行時間的估計值.估計值和實驗值的結果如圖10所示.其中CPEB-MS算法性能模型的平均誤差在5%以內,CPAB-MS算法性能模型的平均誤差會達到11%,這是因為CPABMS中片上通信過程里有大量的同步操作,帶來一些額外的不確定性時間.
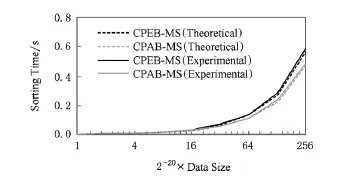
Fig.10 Comparison between estimated values and experimental values.圖10 實驗值與理論值比較
從實驗結果可以看出,算法性能模型的準確度高,可以用來分析不同結構參數下的算法性能.
6 進一步討論
本節利用第5節建立的算法性能模型,對算法優化以及算法性能與眾核結構之間的關系進行一些分析和探索.
在算法優化方面,可以分析出如下結論:
1)陣列眾核上歸并排序算法的時間復雜度是O(Nlb(N)?(C×P)),降低并行歸并排序時間的主要途徑是降低τm和τc.本文設計的多緩沖策略和SIMD歸并方法即是降低了τm和τc.
2)從式(8)可以看出τm和τc的系數之和是與算法無關的恒定值.對于核數較多的眾核結構,通常τm比τc大,因此提高排序性能的一種策略是減少a而增加b來降低整個執行時間,即以增加計算來減少訪存時間,本文中CPAB-MS與CPEB-MS相比就是通過重用片上數據減小訪存次數來提高性能.
3)CPAB-MS的執行時間中Talltoall受待排序序列數據分布的影響,最壞情形的通信開銷大,性能將比CPEB-MS差,而一般情形時,其性能比CPEBMS好.
陣列眾核結構中的核心數目、存儲帶寬、SPM大小以及SIMD寬度,與算法性能密切相關,可以依據算法性能模型進行定量分析.
6.1 核心數目與存儲帶寬
核心數目對排序性能的影響有2方面,一方面核心數目越多,計算能力越強,單位時間可完成的比較操作越多;另一方面,核心數目的增加會導致單個核心所分得的存儲帶寬減小,從而排序容易陷入訪存瓶頸.
在第4節的陣列眾核歸并排序性能模型中,式(3)和式(6)中的τm是和存儲帶寬以及核心數目有關的變量,設帶寬為B(單位為Bps),CPE數目為P,存儲帶寬利用率為ρ,鍵值大小為w(單位為B),則

以式(3)為例,當N很大時,執行時間主要是由式中第2項決定,記為Tcpe,second.而當2τm>τc時,將式(9)代入,有
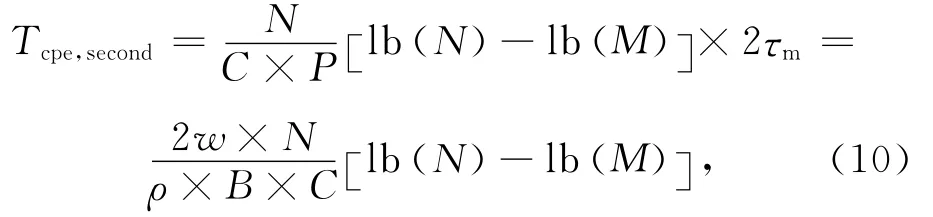
由式(10)可看出Tcpe,second與P無關,即使增加P也無法再減少Tcpe,second,繼而對Tcpe的影響非常有限.因此,2τm=τc是一個臨界條件,即

若2τm<τc說明排序是計算受限的,而2τm>τc則是訪存受限.當未來陣列眾核處理器核心數目和存儲帶寬的擴展關系滿足式(11)時,算法有很好的可擴展性.
根據當前DFMC的配置情況,可以算出P=42是臨界點,即當前DFMC結構為訪存受限.單個CPA上使用不同CPE數目的CPEB-MS算法的實驗結果如圖11所示(數據量為16×220).從圖11可以看出臨界CPE數在32~64之間,之后,執行時間隨CPE數目增加的下降速度變緩慢.根據式(11),DFMC單個CPA的帶寬應當提高約50%,才能最大限度發揮64個CPE的計算性能,此時,算法的排序速度將提高25%.
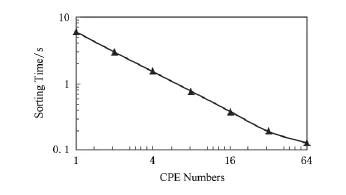
Fig.11 Sorting time for varying number of CPEs.圖11 排序時間與CPE數目關系
6.2 片上存儲大小
根據算法性能模型式(6),可算出DFMC結構上排序時間與片上存儲開辟的緩沖區大小的關系,如圖12所示(數據量為16×220).從圖12可以看出,排序時間隨緩沖區大小增長呈對數級下降,可見,通過增大SPM大小可以提升排序性能,但空間有限.
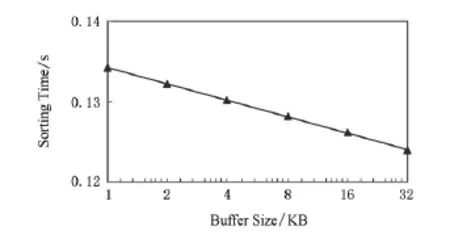
Fig.12 Sorting time for varying buffer sizes.圖12 排序時間隨緩沖大小關系
6.3 SIMD寬度
SIMD歸并算法中,對于寬度為K的SIMD指令,歸并K個元素需要1個lb(2 K)級的歸并網絡,每級網絡需要2次比較操作和2次混洗操作,所以前面性能模型中的τc可表示成
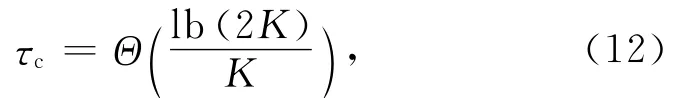
其中Θ表示緊致界[25],由式(12)結合式(3)、式(6)可以看出,訪存理想的情況下,排序時間會隨著K的增加而呈式(12)下降.但實際的情況是,當隨著K的增加,算法會達到訪存受限,之后執行時間的下降空間有限.圖13顯示了DFMC結構上排序時間與SIMD寬度的關系,當前DFMC的SIMD寬度為2,由于存儲帶寬的限制,SIMD寬度的進一步加大所帶來的性能提升有限.但是,如果存儲帶寬增加1倍,同時SIMD寬度增加1倍,將使得排序速度提升71%.
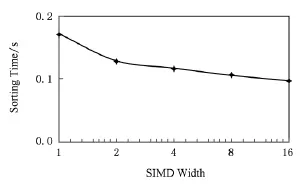
Fig.13 Sorting time for varying SIMD width.圖13 排序時間隨SIMD寬度關系
7 總 結
陣列眾核處理器是眾核處理器發展的重要方向,能夠提供很高的峰值性能,但如何利用其多級并行性(SPMD和SIMD)和SPM的結構特點、充分發揮其峰值性能,對并行算法的設計提出了較高的要求.
本文通過分析陣列眾核處理器的結構特點,設計了多種相應的優化策略,大幅度提高了陣列眾核結構上的歸并排序算法性能,實驗結果優于其他眾核處理器上基于比較的排序算法.本文的優化過程說明了,并行算法的設計要和特定的處理器結構緊密結合起來才能最大限度地發揮處理器的性能.本文所展示的陣列眾核結構上歸并排序算法的優化過程對于其他處理器上并行算法的設計和優化也有很好的借鑒意義.
本文最后分析了陣列眾核結構與代表數據密集型應用的歸并排序算法的性能之間的關系,相信這些分析對陣列眾核結構的研究是一個有益的參考.
[1]Zhong Cheng,Chen Guoliang.An optimal parallel sorting algorithm for multisets[J].Journal of Computer Research and Development,2003,40(2):336 341(in Chinese)(鐘誠,陳國良.Multisets排序的最優并行算法[J].計算機研究與發展,2003,40(2):336 341)
[2]Ramey C.Tile-gx100manycore processor:Acceleration interfaces and architecture[OL].San Jose,CA:Tilera Corporation,2011[2014-10-25].http:??www.hotchips.org? wp-content?uploads?hc_archives?hc23?HC23.18.2-security? HC23.18.220-TILE-GX100-Ramey-Tilera-e.pdf
[3]Mitsuhisa S.Feasibility study on future HPC infrastructure[OL].Tsukuba,Janpan:University of Tsukuba,2014[2014-10-25].http:??www.ccs.tsukuba.ac.jp?files?exreview?FS-ccs-eval-2014.pdf
[4]Gwennup L.Adapteva:More flops,less watts[OL].Mountain View,CA:The Linley Group,2011[2014-10-25].http:??www.adapteva.com?wp-content?uploads?2011? 06?adapteva_mpr.pdf
[5]Dinechin B D,Ayrignac R,Beaucamps P E,et al.A clustered manycore processor architecture for embedded and accelerated applications[C]??Proc of the 17th IEEE Conf on High Performance Extreme Computing.Piscataway,NJ:IEEE,2013:1 6
[6]Fan D R,Yuan N,Zhang J C,et al.Godson-T:An efficient many-core architecture for parallel program executions[J].Journal of Computer Science and Technology,2009,24(6):1061 1073
[7]Zheng Fang,Zhang Kun,Wu Guiming,et al.Architecture techniques of many-core processor for energy-efficient in high performance computing[J].Chinese Journal of Computers,2014,37(10):2176 2186(in Chinese)(鄭方,張昆,鄔貴明,等.面向高性能計算的眾核處理器結構級高能效技術[J].計算機學報,2014,37(10):2176 2186)
[8]Merrill D G,Grimshaw A S.Revisiting sorting for GPGPU stream architectures[C]??Proc of the 19th Int Conf on Parallel Architectures and Compilation Techniques.New York:ACM,2010:545 546
[9]Davidson A,Tarjan D,Garland M,et al.Efficient parallel merge sort for fixed and variable length keys[C]??Proc of Innovative Parallel Computing.Piscataway,NJ:IEEE,2012:1 9
[10]Satish N,Kim C,Chhugani J,et al.Fast sort on CPUs,GPUs and Intel MIC architectures[OL].Santa Clara,CA:Intel Labs,2010[2014-10-25].http:??www.intel.com? content?www?us?en?research?intel-labs-radix-sort-mic-report.html
[11]Tian X,Kamil R,Reiji S.Register level sort algorithm on multi-core SIMD processors[C]??Proc of the 3rd Workshop on Irregular Applications:Architecture and Algorithms.New York:ACM,2013:No 9
[12]Sengupta S,Harris M,Zhang Yao,et al.Scan primitives for GPU computing[C]??Proc of the 22nd ACM SIGGRAPH? EUROGRAPHICS Symp on Graphics hardware.Aire-la-Ville,Switzerland:Eurographics Association,2007:97 106
[13]Satish N,Harris M,Garland M.Designing efficient sorting algorithms for manycore GPUs,NVR-2008-001[R].Santa Clara,CA:NVIDIA Corporation,2008
[14]Satish N,Harris M,Garland M.Designing efficient sorting algorithms for manycore GPUs[C]??Proc of the 23rd IEEE Int Symp on Parallel &Distributed Processing.Piscataway,NJ:IEEE,2009:1 10
[15]Batcher K E.Sorting networks and their applications[C]?? Proc of the Spring Joint Computer Conf.New York:ACM,1968:307 314
[16]Purcell T J,Donner C,Cammarano M,et al.Photon mapping on programmable graphics hardware[C]??Proc of the ACM SIGGRAPH?EUROGRAPHICS Conf on Graphics hardware.Aire-la-Ville,Switzerland:Eurographics Association,2003:41 50
[17]Peters H,Schulz-Hildebrandt O,Luttenberger N.Fast inplace,comparison-based sorting with CUDA:A study with bitonic sort[J].Concurrency and Computation:Practice and Experience,2011,23(7):681 693
[18]Greb A,Zachmann G.GPU-ABiSort:Optimal parallel sorting on stream architectures[C]??Proc of the 20th Int Conf on Parallel and Distributed Processing.Piscataway,NJ:IEEE,2006:45 54
[19]Cederman D,Tsigas P.A practical quicksort algorithm for graphics processors[G]??LNCS 5193:Proc of the 16th Annual European Symp on Algorithms.Berlin:Springer,2008:246 258
[20]Cederman D,Tsigas P.GPU-quicksort:A practical quicksort algorithm for graphics processors[J].Journal of Experimental Algorithmics(JEA),2009,14(4):1 22
[21]Leischner N,Osipov V,Sanders P.GPU sample sort[C]?? Proc of the 24th IEEE Int Symp on Parallel Distributed Processing.Piscataway,NJ:IEEE,2010:1 10
[22]Sintorn E,Assarsson U.Fast parallel GPU-sorting using a hybrid algorithm[J].Journal of Parallel and Distributed Computing,2008,68(10):1381 1388
[23]Ye X,Fan D,Lin W,et al.High performance comparisonbased sorting algorithm on many-core GPUs[C]??Proc of the 24th IEEE Int Symp on Parallel Distributed Processing.Piscataway,NJ:IEEE,2010:1 10
[24]Banerjee D S,Sakurikar P,Kothapalli K.Fast,scalable parallel comparison sort on hybrid multicore architectures[C]??Proc of the 27th IEEE Int Symp on Parallel and Distributed Processing Workshops &PhD Forum.Piscataway,NJ:IEEE,2013:1060 1069
[25]Cormen T H,Leiserson C E,Rivest R L,et al.Introduction to Algorithms[M].Cambridge,MA:MIT Press,2001

Shi Song,born in 1990.MSc.Member of China Computer Federation.His research interests include computer architecture,microprocessor design and high-performance computing.

Li Hongliang,born in 1975.PhD,associate professor.Member of China Computer Federation.His main research interests include computer architecture,microprocessor design and high-performance computing(hongliangli@263.net).

Zhu Wei,born in 1976.MSc,senior engineer.His main research interests include microprocessor design and integrated circuit verification(zw84611@sina.com).
Efficient Merge Sort Algorithms on Array-Based Manycore Architectures
Shi Song,Li Hongliang,and Zhu Wei
(Jiangnan Institute of Computing Technology,Wuxi,Jiangsu214083)
Sorting is one of the most fundamental problems in the field of computer science.With the rapid development of manycore processors,it shows great importance to design efficient sort algorithms on manycore architecture.An important trend of manycore processors is array-based manycore architecture.This paper presents two efficient merge sort algorithms on array-based manycore architectures.Our algorithms achieve high performance by using DMA(direct memory access)multi-buffering strategy to improve the memory accessing efficiency,deeply balanced merging strategy to keep load-balancing between cores,SIMD(single instruction multiple data)merging method to exploit fine-grained parallelism and on-chip swap merging strategy to reuse on-chip data.Experimental results on DFMC(deeply-fused many-core)prototype system achieve a sorting rate of 647MKeys?s(million keys per second),and the sorting efficiency(sorting rate?peak performance)is 3.3xhigher than state-of-the-art GPU merge sort on GTX580,and 2.7xhigher than the fastest merge sort on Intel Xeon Phi.Additionally,this paper establishes an analytical model to characterize the performance of our algorithms.Based on the analytical model,we analyze the influence of the main structural parameters to the performance of the algorithms,which will contribute to the study of many-core architecture.
array-based manycore;merge sort;sort network;SIMD;SPMD;on-chip communication
TP302
2014-11-14;
2015-07-21
國家“八六三”高技術研究發展計劃基金項目(2014AA01A301);“核高基”國家科技重大專項基金項目(2013zx0102-8001-001-001)
This work was supported by the National High Technology Research and Development Program of China(863Program)(2014AA01A301)and the National Science and Technology Major Projects of Hegaoji(2013zx0102-8001-001-001).
關鍵詞 陣列眾核;歸并排序;排序網絡;單指令多數據流;單程序多數據流;片上通信
