融合時間衰減與偏好波動的協同偏好獲取方法
2016-07-19 21:08:37楊立胡運紅邵桂榮
計算機應用 2016年7期
楊立 胡運紅 邵桂榮

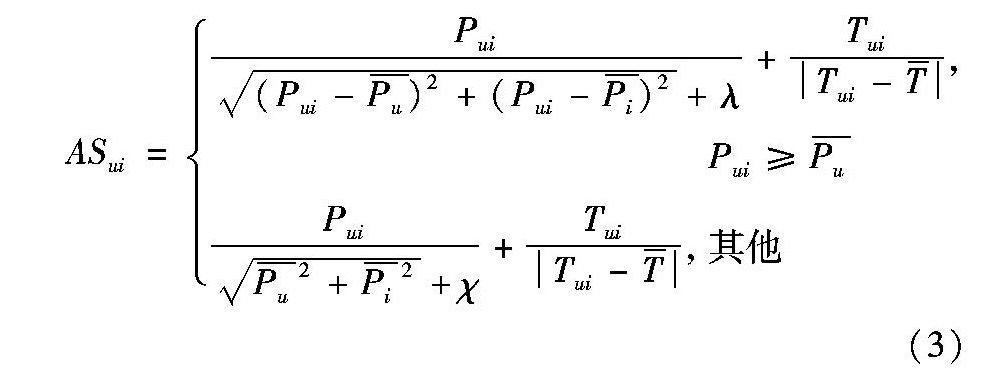

摘要:針對現有的推薦系統多采用近鄰用戶的偏好行為來預測當前用戶的偏好,而不考慮用戶的偏好會隨著時間的變化而改變,影響了推薦準確率的問題,提出了一種基于時間衰減與偏好波動的協同偏好獲取方法。首先,基于時間因素、用戶歷史偏好等獲取偏好衰減增量與衰減速度,并據此生成衰減函數,使用衰減函數對用戶歷史行為數據進行衰減修正;其次,基于用戶的歷史偏好分布獲取其偏好波動幅度;最后,將衰減函數與偏好波動幅度分別加入到最近鄰獲取與偏好獲取流程,協同為用戶生成推薦列表。在大規模真實數據集上的實驗結果表明,所提出的方法與基于屬性評分分布的協同過濾(RDCF)與最優TopN的協同過濾(OTCF)相比,平均絕對誤差(MAE)值分別降低了近6.42%和7.73%。實驗結果表明所提方法能夠提高推薦準確度,提升推薦質量。
關鍵詞:
推薦系統;時間衰減;衰減增量;衰減速度;偏好波動
中圖分類號: TP391.9; TP18 文獻標志碼:A
0引言
隨著大數據時代的到來,海量信息資源充斥整個信息服務領域,而其展示平臺或資源獲取途徑雖然在近年來有了較大的發展,資源檢索與篩選技術也趨于成熟,但仍不能為用戶提供符合其需求的個性化資源推薦服務。特別是隨著移動客戶端的普及,資源展示界面越來越小型化,用戶及服務提供商對于高質量的推薦系統的需求也越來越大。
推薦系統的主要思路就是基于用戶的歷史偏好信息,采用基于模型或基于內容的方法來建立用戶的興趣模型,將用戶可能感興趣的,且沒有過行為記錄的商品推薦給用戶[1-3]。目前,許多研究者都提出了不同的推薦系統實現方案,其中最著名與應用最廣的是基于協同過濾的推薦系統,協同過濾起源與生物理論中的“協同進化”,原意為生物鏈中某一個物種發生進化,而與其相關的其他物種也會隨之進化。在信息獲取領域,協同過濾基于這種思想,通過獲取與待預測偏好用戶的偏好最相似的其他用戶,并基于這些用戶的偏好行為為當前用戶生成推薦服務。例如,Chen等[4]提出了一種隨著時間變化并考慮用戶接受能力的推薦方法,在數據稀疏性的環境下,提高了推薦準確度;汪靜等[5]用共同評分和相似性權重來改進協同過濾推薦算法,增加了用戶間共同評分權重,在一定程度上提高了推薦準確度;郭晶晶等[6]采用李雅普諾夫模型與信任度相結合,將推薦系統應用于基于物聯網的信任推薦領域,提升了系統效益;孫光福等[7]提出了一種基于用戶間時序行為的推薦方法,并將最近鄰集合采用基于奇異值分解的協同過濾算法進行處理,提高了推薦準確度;王興茂等[8]從非共同評分項目集出發,基于歷史偏好記錄獲取近鄰用戶的貢獻程度,提高了推薦質量;Focuss等[9]基于圖模型相關理論提出了一種基于隨機游走的節點相似度計算方法,有效地緩解了協同過濾推薦系統中數據稀疏性問題對推薦準確度的影響。而由于用戶的偏好會隨著時間的變化而產生波動[10],上述方法并沒有考慮時間因素對于用戶偏好的影響,影響了推薦的準確度。針對這個問題本文提出了一種基于時間衰減與偏好波動的協同偏好獲取方法,首先基于時間因素、用戶歷史偏好等獲取偏好衰減增量、衰減速度,并生成衰減函數;其次,基于用戶的歷史偏好分布獲取其偏好波動幅度,并將衰減函數與偏好波動幅度分別加入到最近鄰獲取與偏好獲取流程,協同為用戶生成推薦列表。不但考慮了用戶自身的偏好波動,還同時加入了用戶偏好隨時間的衰減對其偏好的影響,能取得更好的推薦準確度。
1融合時間衰減與偏好波動的偏好預測方法
本文在經典協同過濾算法的基礎上提出了一種融合時間衰減與偏好波動的協同偏好獲取方法,在用戶真實歷史偏好行為數據的基礎上,基于衰減速度與衰減增量,獲取基于時間因素的用戶偏好衰減函數,并據此修正用戶的歷史偏好行為。基于此,通過偏好行為相似性度量算法度量用戶偏好間的相似關系,并結合基于歷史偏好合同類偏好所獲取的偏好波動幅度,為用戶生成推薦服務。總體流程如圖1所示。
1.1相似度度量方法
由于用戶的偏好會隨著時間的變化而產生波動,在多數情況下,用戶對某類項目的喜好程度會隨著時間的變化而逐漸衰減,衰減的程度與策略與具體用戶相關。例如用戶在一定的時期內喜歡某個歌曲,隨著時間的變化和用戶聽歌次數的增加,該用戶對這個歌曲的喜好程度會逐漸減少。據此本文提出了一種用戶偏好隨時間衰減策略,基于時間與用戶的歷史偏好,通過定義衰減函數、衰減速度、衰減增量,將時間因素與用戶偏好變化關聯起來,具體算法描述與相關定義如下。
1.2偏好波動
偏好波動(Preference Fluctuation)指的是在用戶自身因素的影響下,用戶的偏好所產生波動的情況。即是在排除外界影響因素的前提下,用戶偏好不會恒定不變,而是會有一定幅度波動的現象。通過度量用戶歷史偏好間的差異程度,獲取用戶的偏好波動幅度(Preference Fluctuation Range),基于此去修正預測的用戶偏好。具體表示如下:
Puw=Puw·(1+PFR)(9)
其中:Pui為采用偏好預測算法為用戶u生成的對于項目w的預測評分,PFR為偏好波動幅度。
PFR=∑ISISL∑j,l∈Is, j≠lPuj-PulCard(ISL)·Card(IS)·(Card(IS)-1),ND≥NX
-∑ISISL∑j,l∈Is, j≠lPuj-PulCard(ISL)·Card(IS)·(Card(IS)-1),其他 (10)
其中:Is表示任一同類商品集合;ISL為IS的集合,即所有同類商品的集合;Pul與Puj分別表示用戶u對于同類項目l與j的歷史偏好值;Card(IS)與Card(ISL)分別表示商品集合IS與ISL中的項目數量;ND表示在集合ISL中用戶u的偏好值大于等于其均值(用戶u對其他所有項目的評分均值)的歷史偏好行為數量;NX則為其中小于其均值的歷史偏好行為數量。即是根據用戶歷史偏好的分布情況,提出了增強與懲罰兩種修正策略,并基于修正后的偏好值,將值最大的TOPN個項目推薦給用戶u。
1.3方法實施步驟
基于用戶的歷史行為數據,方法的實施步驟如下:
1)基于時間因素、用戶歷史偏好等獲取偏好衰減增量;
2)計算用戶偏好衰減速度;
3)根據衰減增量與衰減速度生成衰減函數;
4)根據衰減函數獲取衰減后的用戶行為,并獲取修正后的行為最近鄰;
5)根據歷史偏好行為與同類偏好行為生成偏好波動幅度;
6)基于修正后的行為最近鄰和偏好波動幅度,獲取用戶偏好。
2實驗設計及結果分析
2.1實驗數據集
本文采用Netflix數據集作為本文提出方法進行仿真實驗的基礎數據,Netflix是最常用的推薦領域真實數據集之一,它采用評分值來度量用戶對電影的喜好程度。每個電影采用五分制,分值越高則表明電影越符合用戶的興趣。Netflix共涉及48萬個用戶對1.7萬個電影的近一億條偏好行為數據(評分制,最高為5分),以及相應的偏好行為發生的時間信息(1998年10月到2005年12月),精確到“天”。本文實驗數據是Netflix的子集,共選取了3000個用戶對近2200個電影的數據子集,并將該數據集分為訓練集與測試集兩部分,分別進行實驗檢驗。
2.2算法評價標準
目前評價推薦算法優劣的標準主要可分為統計精度度量和決策支持精度度量兩種策略。本文所采用的平均絕對誤差(Mean Absolute Error,MAE)是統計精度度量策略中比較常用和受到廣泛認可的評價策略。MAE通過度量所提出的推薦算法預測出的用戶偏好與實際用戶偏好間的差異程度,來評價所提出推薦算法的優劣,其值越小則說明提出的推薦算法所作出的預測與用戶實際偏好間的偏差越小,推薦準確度越好。假設根據推薦算法預測出用戶評分為{p1,p2,…,pN},而其對應的真實用戶評分為{q1,q2,…,qN},則MAE可表示為:
MAE=(∑Ni=1pi-qi)/N(11)
2.3實驗設計及結論
本文實驗主要包括兩部分:第1部分是參數檢驗實驗,主要檢驗衰減速度中的λ與χ參數,即獲取不同偏好值對于衰減速度的不同影響情況;第2部分是對比實驗,將提出的基于波動序列的推薦算法與現有算法進行對比。
實驗1參數λ與χ檢驗實驗。
針對實驗所用數據集Netflix,分別提取20%、30%、50%、70%的數據作為訓練集,其余作為測試集進行實驗,由于參數λ與χ影響的是不同偏好值下的偏好衰減速度,兩參數之間沒有交互影響關系,在進行實驗時,兩個參數所對應的偏好值分離開,并分別進行實驗檢驗。分別以兩種情況下所獲取的修正后的用戶歷史偏好作為預測評分的基礎數據,以分別判定兩種參數對于推薦準確度的影響。經過反復對比實驗選取出幾組有代表性的λ與χ取值,如表1,通過對比所提出算法的MAE值來選取針對當前數據集最優的參數λ與χ的取值。實驗結果見圖2~3所示(其中R表示最近鄰個數)。
分別對比不同數據集比例下,參數λ與χ的取值對推薦結果MAE值的影響可以發現,隨著訓練集比例的增加,所提出推薦算法的MAE值呈現出遞減的趨勢,即推薦的準確度越來越高。分別對比參數λ與χ,可以發現在4種數據集模式下,當λ=0.46, χ=1.56時算法能夠取得整體最佳的推薦準確度,所以在以下的實驗中,選取λ=0.46, χ=1.56。
實驗2與其他算法對比實驗。
針對當前數據集,經過多次實驗對比,選取30%與50%兩種數據集模式將本文算法與現有的推薦算法進行對比。經過反復測試與篩選,本文選取了基于屬性評分分布的協同過濾(Collaborative Filtering based on Rating Distribution,RDCF)算法[11]和最優TopN的協同過濾(Optimizing TopN Collaborative Filtering,OTCF)算法[12]作為算法的對比算法。其中:RDCF將用戶歷史偏好轉化成用戶對項目的屬性偏好分布,并改進了偏好行為相似性度量方法;OTCF算法采用動態的負項目抽樣來獲取TopN推薦項目集。本文采用MAE作為對比實驗的評價標準,分別對3種算法進行仿真實驗,實驗結果如圖10~114所示。
從實驗結果可以看出,在Netflix數據集上以MAE為評價標準,本文提出時間衰減與偏好波動的推薦算法,在兩種不同數據集比例下,能夠取得更小的MAE值,即推薦準確度要優于RDCF和OTCF。也即說明在使用用戶的歷史偏好信息建立用戶的興趣模型時,考慮用戶偏好隨時間衰減與用戶自身的偏好波動,相比于現有的推薦方法,能夠取得更好的推薦準確度。
3結語
針對現有的推薦方法多采用近鄰用戶的偏好行為來預測當前用戶的偏好,而不考慮用戶的偏好會隨著時間的變化而改變,影響了推薦準確率。針對這個問題提出了一種基于時間衰減與偏好波動的協同偏好獲取方法,首先基于時間因素、用戶歷史偏好等獲取偏好衰減增量、衰減速度,并生成衰減函數;其次,基于用戶的歷史偏好分布獲取其偏好波動幅度,并將衰減函數與偏好波動幅度分別加入到最近鄰獲取與偏好獲取流程,協同為用戶生成推薦列表,并且在大規模真實數據集的仿真實驗結果表明,所提出的推薦方法相比現有的推薦方法,能夠取得更好的推薦準確度。未來的研究工作將會致力于研究考慮時間因素的情景感知推薦方法,以期進一步地提高推薦質量。
參考文獻:
[1]
吳月萍,杜奕.基于人工魚群算法的協同過濾推薦算法[J].計算機工程與設計,2012,33(5):1852-1856.(WU Y P, DU Y. Collaboration filtering recommendation algorithm based on artificial fish swarm algorithm [J]. Computer Engineering & Design, 2012, 33(5): 1852-1856.)
[2]
PARK S T, CHU W. Pairwise preference regression for coldstart recommendation [C]// Proceedings of the Third ACM Conference on Recommender Systems. New York, ACM, 2009: 21-28.
[3]
DAI Y, DANIELS A, WU J. Demo: recommendation system for dynamic spectrum access through spectrum mining and prediction [J]. Spectrum, 2014, 43(5): 415-416.
[4]
CHEN W, HSU W, LEE M L. Modeling users receptiveness over time for recommendation [C]// Proceeding of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, ACM, 2013: 373-382.
[5]
汪靜,印鑒,鄭利榮,等.基于共同評分和相似性權重的協同過濾推薦算法[J].計算機科學,2010,37(2):99-104.(WANG J, YIN J, ZHENG L R, et al. Collaborative filtering recommendation algorithm based on coratings and similarity weight [J]. Computer Science, 2010, 37(2): 99-104.)
[6]
郭晶晶,馬建峰.面向虛擬社區物聯網的信任推薦算法[J].西安電子科技大學學報(自然科學版),2015,42(2):59-65.(GUO J J, MA J F. Trust recommendation algorithm for virtual community based interest of things [J]. Journal of Xidian University (Natural Science), 2015, 42(2): 59-65.)
[7]
孫光福,吳樂,劉淇,等.基于時序行為的協同過濾推薦算法[J].軟件學報,2013,24(11):2711-2733.(SUN G F, WU L, LIU Q, et al. Recommendations based on collaborative filtering by exploiting sequential behaviors [J]. Journal of Software, 2013, 24(11): 2711-2733.)
[8]
王興茂,張興明.基于貢獻因子的協同過濾推薦算法[J].計算機應用研究,2015,32(12):132-136.(WANG X M, ZHANG X M. Collaborative recommendation algorithm based on contributor factor [J]. Application Research of Computers, 2015, 32(12): 132-136.)
[9]
FOUSS F, PIROTTE A, RENDERS M, et al. Randomwalk computation of similarities between nodes of a graph with application to collaborative recommendation [J]. Knowledge and Data Engineering, 2007, 19(3): 355-369.
[10]
李源鑫,肖如良,陳洪濤,等.時間衰減制導的協同過濾相似性計算[J].計算機系統應用,2013,22(11):129-134.(LI Y X, XIAO R L, CHEN H T. Time decay guided similarity calculation in collaborative filtering [J]. Computer Systems & Applications, 2013, 22(11): 129-134.)
[11]
王茜,楊莉云,楊德禮.面向用戶偏好的屬性值評分分布協同過濾算法[J].系統工程學報,2010,25(4):561-568.(WANG Q, YANG L Y, YANG D L. Collaborative filtering algorithm based on rating distribution of attributions faced user preference [J]. Journal of Systems Engineering, 2010, 25(4): 561-568.)
[12]
ZHANG W, CHEN T, WANG J, et al. Optimizing topN collaborative filtering via dynamic negative item sampling [C]// Proceeding of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, ACM, 2013: 785-788.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
全體育(2016年4期)2016-11-02 18:57:28
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
科普童話·百科探秘(2015年6期)2015-10-13 07:21:18
科普童話·百科探秘(2015年8期)2015-08-14 07:13:06
