中文異構百科知識庫實體對齊
2016-07-19 19:39:43黃峻福李天瑞賈真景運革張濤
計算機應用 2016年7期
黃峻福 李天瑞 賈真 景運革 張濤

摘要:針對傳統實體對齊方法在中文異構網絡百科實體對齊任務中效果不夠顯著的問題,提出一種基于實體屬性與上下文主題特征相結合的實體對齊方法。首先,基于百度百科及互動百科數據構造中文異構百科知識庫,通過統計方法構造資源描述框架模式(RDFS)詞表,對實體屬性進行規范化;其次,抽取實體上下文信息,對其進行中文分詞后,利用主題模型對上下文建模并通過吉布斯采樣法求解模型參數,計算出主題單詞概率矩陣,提取特征詞集合及對應特征矩陣;然后,利用最長公共子序列(LCS)算法判定實體屬性相似度,當相似度位于下界與上界之間時,進一步結合百科類實體上下文主題特征進行判定;最后,依據標準方法構造了一個異構中文百科實體對齊數據集進行仿真實驗。實驗結果表明,與經典的屬性相似度算法、屬性加權算法、上下文詞頻特征模型及主題模型算法進行比較,所提出的實體對齊算法在人物領域和影視領域的準確率、召回率與綜合指標F值分別達到97.8%、88.0%、92.6%和98.6%、73.0%、83.9%,比其他方法均有較大的提高。實驗結果驗證了在構建中文異構百科知識庫場景中,所提算法可以有效提升中文百科實體對齊效果,可應用到具有上下文信息的實體對齊任務中。
關鍵詞:
知識庫;實體對齊;主題模型;資源描述框架模式;最長公共子序列算法
中圖分類號: TP391.1 文獻標志碼:A
0引言
語義網[1]提供一種在不同應用和個體間共享和重用數據的整體框架,是Web 3.0的重要特征。目前萬維網主要面向文檔,供人直接閱讀和理解;語義網則主要面向文檔所表示數據,使計算機能夠理解并通過推理引擎進行邏輯演算,是人工智能的重要目標。語義網的建立需要高質量的知識庫作為數據支撐。目前,國外具有代表性的知識庫有FreeBase[2]、DBpedia[3]、維基百科本體知識庫(Yet Another Great Ontology,YAGO[4])及Omega[5]等;國內的知識庫有百度知心、搜狗知立方及清華大學雙語知識庫XLore[6]。知識庫在知識圖譜、智能語義問答及信息融合等自然語言處理領域均有重要意義[7]。國外的知識庫如FreeBase等提供了公開的資源描述框架(Resource Description Framework, RDF)數據源,但所含中文數據量較少,如何構建高質量的中文RDF知識庫是目前的研究熱點。
實體(Entity)是指客觀存在并可相互區別的事物,包括具體的人、事、物、抽象的概念或聯系,知識庫中包含多種類別的實體。實體對齊(Entity Alignment)也被稱作實體匹配(Entity Matching),是指對于異構數據源知識庫中的各個實體,找出屬于現實世界中的同一實體。隨著中文網絡百科的不斷完善,可以從網絡百科頁面抽取出實體,并對不同來源的實體進行對齊,構建高質量的中文異構百科RDF知識庫[8]。百度百科與互動百科所包含的實體信息覆蓋面廣,更新及時,因此,如何從網絡百科數據中抽取出實體信息并進行實體對齊,是構建中文RDF知識庫的關鍵問題。實體對齊常用的方法是利用實體的屬性信息判定不同源實體是否可進行對齊,由于網絡百科數據屬于用戶原創內容(User Generated Content,UGC)類型[9],不同用戶編輯的數據質量參差不齊,僅通過用戶編輯的實體屬性信息難以準確判定是否為同一實體。本文根據網絡百科具有實體上下文的特性,提出一種基于主題模型的中文異構百科知識庫實體對齊方法,通過挖掘實體上下文潛在語義信息,對實體上下文進行主題建模,完成實體對齊任務。實驗驗證所提方法能夠有效提升實體對齊準確性,對具備上下文信息的實體對齊任務有良好通用性。
本文主要工作如下:
1)利用中文異構數據源百科類網站,構建中文百科知識庫,提出異構數據源百科知識庫進行實體對齊的方法,該方法能夠有效地對來自于異構數據源百科知識庫中的實體進行對齊。
2)結合實體結構化數據與非結構化數據,提出了適用于具備上下文信息的實體對齊方法。
3)構造了中文百科類實體對齊標準數據集,對數據集中需要對齊的實體進行了人工標注并進行了大量實驗。同標準的實體對齊方法進行對比,實驗結果表明本文提出的算法可以有效地對具有上下文信息的實體進行對齊。
1相關工作
目前實體對齊方法的研究主要分為以下3個方面。
1)基于OWL語義。
網絡本體語言(Web Ontology Language, OWL)用于對本體進行語義描述。文獻[10]中利用反函數及啟發式算法結合上層語義信息(如owl:sameAs等)對實體進行推理,判斷不同來源的實體是否可以進行對齊。文獻[11]中利用Freebase中實體分類信息對問句中的實體,通過迭代模型和判別模型與知識庫中的實體進行對齊。基于OWL語義的方法要求數據集本身具有完備的語義信息,而網絡百科類的實體由用戶定義,不同編輯者對同一事物的屬性定義并不嚴格,不具有完備的上層語義信息。
2)基于規則分析。
文獻[12]中通過在具體應用場景中制定特殊規則,通過規則及評價函數的方法對實體的含義進行消歧。此種方法在具體應用領域準確率較高,但由于換一個場景需要重新制定規則,存在一定局限性。百科類網站中覆蓋多領域實體,需要針對不同領域實體制定規則并對各領域規則進行驗證,因此此類方法不具有通用性。
3)基于相似度理論判定。
文獻[13]中基于屬性值的分布給屬性賦予權重,然后用加權后屬性的相似度來進行實體對齊,但是百科類網站實體的屬性類型眾多,單個實體屬性分布稀疏,屬性值較少的屬性權重很低,導致該方法對如中文名等通用屬性的依賴程度較高,難以滿足網絡百科類實體對齊任務。
綜上分析,中文網絡百科不具備完備本體信息,并且包含實體領域眾多,所以難以通過基于本體方法或制定領域規則的方法完成實體對齊。中文網絡百科中的屬性信息往往由用戶定義,不同編輯者編輯的數據質量參差不齊,僅利用基于屬性的方法其效果難以滿足構建中文異構百科知識庫的實際要求。由于百科知識庫中包含大量實體摘要信息及描述性文本,如何利用實體上下文非結構化數據,構造出有效的上下文特征,是目前急需解決的一個問題。由于傳統的文本建模方法如詞頻逆向文檔頻率(Term FrequencyInverse Document Frequency, TFIDF)方法僅考慮了詞頻的特征,而未考慮詞項之間的語義關聯,因此,為了有效地提取實體上下文文本信息,本文提出一種基于實體屬性與上下文主題特征相結合的實體對齊方法。首先利用屬性相似度的方法對實體進行第一步判別,當其難以準確判定時,進一步利用待對齊的實體上下文信息進行主題建模,再結合上下文特征與屬性相似度判定異構知識庫中的實體是否可以對齊。
2中文異構百科類實體對齊方法
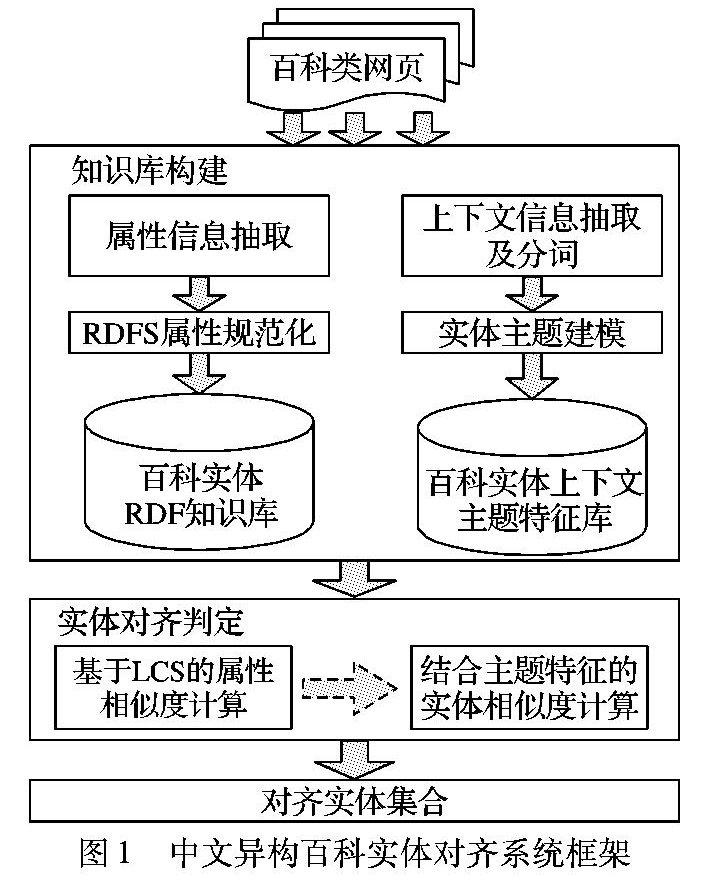
2.1框架概述
本文所述中文百科RDF知識庫主要基于百度百科與互動百科兩個數據源構建,本文設計的中文異構百科實體對齊系統框架如圖1所示,其中知識庫的構建及實體對齊判定模塊是實體對齊框架的核心部分。當系統獲取到一個新實體信息,依次抽取其屬性信息和上下文信息。由于不同百科網站存在異構數據,通過構建資源描述框架模式(Resource Description Framework Schema, RDFS)詞表對實體屬性進行規范化,將新的實體信息存儲到對應百科網站的RDF知識庫中;利用基于可擴展標記語言(eXtensible Markup Language, XML)及其路徑語言(XML Path Language, XPath)的抽取技術[14]將網頁中關于實體的描述性信息抽取出來,用西南交大分詞器(http://ics.swjtu.edu.cn/)分詞后,采用主題模型計算出實體潛在主題特征,將實體上下文主題特征進行存儲。另外為融合異構數據源的RDF知識庫,采用基于最長公共子序列(Longest Common Subsequence, LCS)屬性相似度結合主題特征的實體對齊方法。對于來自異構數據源待對齊實體對,利用基于LCS的屬性相似度計算方法判定兩個實體是否為同一實體,若相似度滿足閾值上界,說明可通過屬性信息進行實體對齊,將其輸出到對齊實體集合;當相似度位于下界與上界之間,說明實體屬性信息匱乏無法判定是否可以對齊,進一步采用結合上下文主題特征的實體對齊算法,綜合判定后決定是否將實體對輸出至對齊實體集合中。
2.2知識庫構建
RDF[15]是一種用于描述網絡資源的標記語言。RDF所描述的數據信息可通過共享及整合將不同源數據聯系起來構建知識庫,為知識圖譜及人工智能問答等領域提供數據支撐[16]。
構建的中文RDF知識庫主要存儲了實體相關信息,它將來自于不同源的網絡百科數據(如百度百科、互動百科及豆瓣網站等數據)進行對齊及整合。本文在知識庫構建及實體對齊過程中,主要抽取實體屬性信息及實體上下文信息。
實體屬性信息給出了實體的特征屬性及其取值,經過數據預處理及數據清洗后轉為結構化數據。由于中文網絡百科沒有根據本體語言指定統一的屬性標準,存在不同屬性名指代同一屬性的情況,如對于人物類別的屬性出生時間,百度百科常使用“出生日期”描述,互動百科常使用“出生年月”描述。屬性謂詞的不統一導致在異構數據源知識庫中進行實體對齊時準確程度很低,因此本文參考本體(Ontology)層次描述,通過統計高頻屬性謂詞,構建多個類別的RDFS[17]詞表,規范屬性名不一致的情況。部分人物類RDFS詞表示例如表1所示。
實體上下文信息由“摘要”及“實體描述”信息組成。摘要信息對實體進行簡要概括,實體描述信息從多方面對實體進行闡述。由于上下文信息是非結構化文本,在實體對齊任務中不能直接使用,所以需要對實體上下文信息進行主題建模。
2.3實體上下文建模
在百科類網站所覆蓋的實體中,通常具有關于實體多方面的描述信息,這些描述信息大多以文本的形式呈現。主題模型在文獻[18]中被顯式提出來,是對文本中隱含主題的一種建模方法。主題是語料集合上語義的高度抽象、壓縮表示,每個主題對應著比較一致的語義。對于網絡百科實體,如果實體屬性信息匱乏,難以判斷實體是否可以對齊,則利用上下文信息進行建模并提取主題特征,根據主題特征分布來判別是否可進行對齊。基于主題模型對上下文建模的實現主要包括利用潛在狄利克雷分布(Latent Dirichlet Allocation, LDA)產生上下文過程及主題特征生成過程兩部分。
2.3.1LDA產生上下文過程
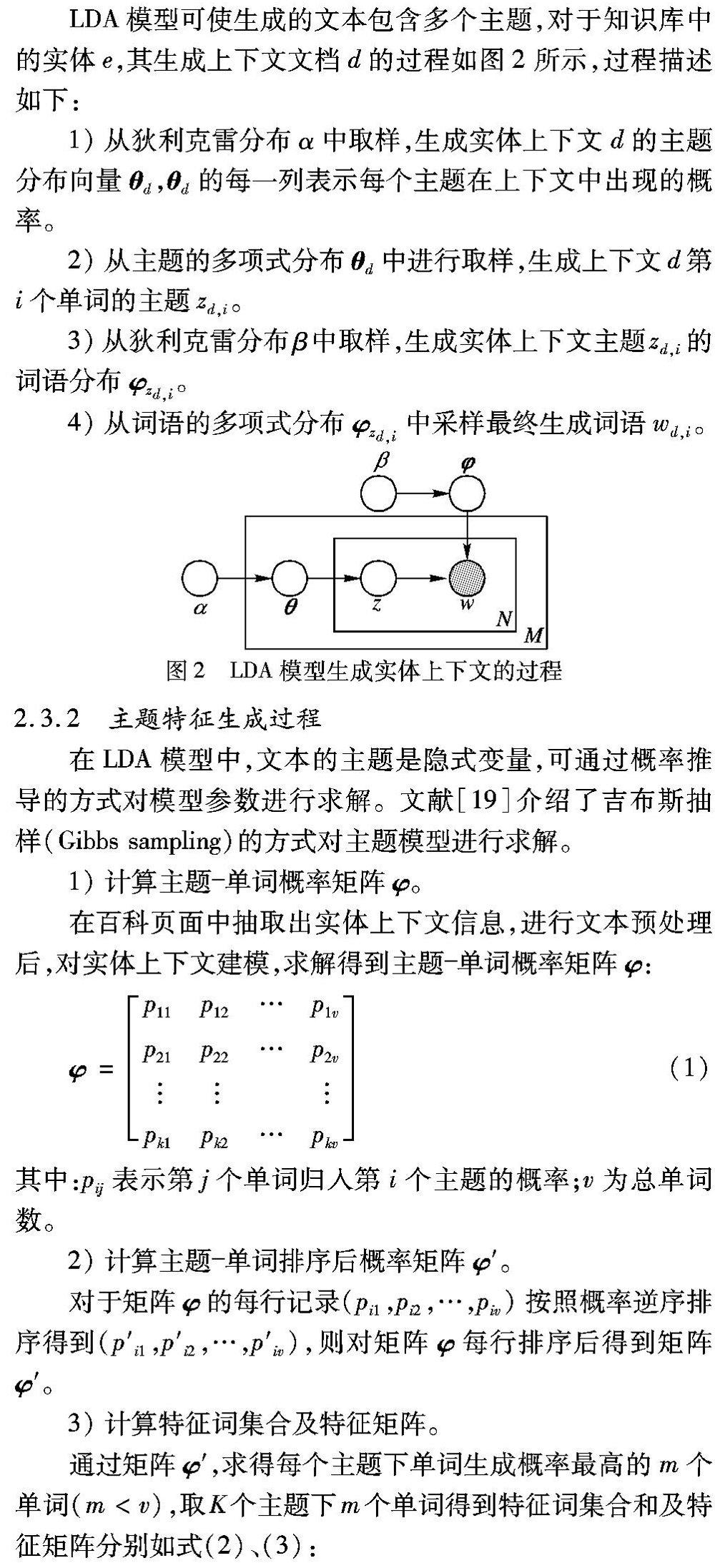
LDA模型可使生成的文本包含多個主題,對于知識庫中的實體e,其生成上下文文檔d的過程如圖2所示,過程描述如下:
1)從狄利克雷分布α中取樣,生成實體上下文d的主題分布向量θd,θd的每一列表示每個主題在上下文中出現的概率。
2)從主題的多項式分布θd中進行取樣,生成上下文d第i個單詞的主題zd,i。
3)從狄利克雷分布β中取樣,生成實體上下文主題zd,i的詞語分布φzd,i。
4)從詞語的多項式分布φzd,i中采樣最終生成詞語wd,i。
2.3.2主題特征生成過程
在LDA模型中,文本的主題是隱式變量,可通過概率推導的方式對模型參數進行求解。文獻[19]介紹了吉布斯抽樣(Gibbs sampling)的方式對主題模型進行求解。
2.4基于LCS的屬性相似度計算
實體屬性相似度計算可對網絡百科中屬性定義較準確的實體進行判別,本文基于文獻[20]中所述LCS算法,提出適用于網絡百科的屬性相似度計算方法。
2.4.1網絡百科實體的屬性信息的相關定義
定義1設實體ea經過RDFS屬性規范化后屬性名集合Propertya={pa1,pa2,…,pam},對應屬性值集合Valuea={va1,va2,…,vam};實體eb對應屬性名集合Propertyb={pb1,pb2,…,pbn},其對應屬性值集合Valueb={vb1,vb2,…,vbn},其中m,n分別為實體的屬性個數。
定義2設實體ea的規范化屬性pai,其對應屬性值vai=(sa1sa2…sap);實體eb“實體..”,此處書寫是否有誤?請作相應調整。的規范化屬性pbj,其屬性值vbj=(sb1sb2…sbq)。其中:i表示實體ea的第i個屬性; j表示實體eb的第j個屬性;sap為屬性值vai的第p個字符;sbq表示屬性值vbj的第q個字符;p與q分別表示對應屬性值的長度。
2.4.2屬性相似度計算
1)實體ea及eb共有屬性的計算式為:
InterProperty(ea,eb)=Propertya∩Propertyb(5)
對于共有屬性pi∈InterProperty(ea,eb),其中pax=pi且pby=pi,其中,實體ea的屬性pax對應的屬性值為vax,實體eb的屬性pby對應的屬性值為vby。
2)屬性pi的相似度計算式為:
sim(pi)=lcs(vax,vby)max(len(vax),len(vby))(6)
其中lcs(vax,vby)為實體屬性值的最長公共子序列。
3)實體ea及eb的相似度計算式為:
property_sim(ea,eb)=[∑Ti=1sim(pi)]/T(7)
其中:
T=Propertya∩Propertyb(8)
2.5基于主題特征的相似度計算方法
1)實體..實體ea此處的書寫是否符合規范?表示什么含義?請明確。及eb的實體上下文相似度計算式為:
context_sim(ea,eb)=Vea·Veb|Vea||Veb|(9)
其中Vea及Veb是每個實體的主題特征向量。
在實體對齊時,如果僅考慮實體上下文特征,結果并不準確。為了提高結果的準確性,結合實體屬性相似度及實體主題相似度得到實體的相似度計算公式。
2)實體的相似度計算式為:
sim(ea,eb)=[property_sim(ea,eb)+context_sim(ea,eb)]/2.0(10)
其中property_sim(ea,eb)為實體的屬性相似度。
2.6基于主題特征的實體對齊算法
根據上面的定義和公式,提出了基于主題特征的中文異構百科知識庫實體對齊算法描述如下。
算法1基于主題特征的實體對齊算法。
有序號的程序——————————Shift+Alt+Y
程序前
輸入:異構數據源實體集合EA及EB,實體屬性相似度閾值上界ν及下界μ,實體相似度參數ω,主題參數K。
輸出:對齊后的實體集合AE。
1)
for each entity e∈(EA∪EB) do
2)
compute topicword matrix φ/*利用LDA算法對實體e上下文主題建模,計算主題單詞概率矩陣φ*/
3)
compute topicfeature vector Ve/*通過主題特征生成過程,計算主題特征向量Ve*/
4)
for i ← 1 to size(EA) do
5)
for j ← 1 to size(EB) do
6)
compute ps = property _sim(ei ,ej )
7)
if ps 8) continue; 9) else if ps> threshold ν do 10) AE ← AE∪{ (ei,ej)} 11) else do 12) compute cs=context_sim(ei,ej)/*利用主題特征向量Vei及Vej計算主題相似度*/ 13) compute s=sim(ei,ej)/*結合屬性相似度ps和主題相似度cs,計算實體相似度s*/ 14) if s≥ω do 15) AE ← AE∪{ (ei,ej)} 程序后 3實驗與結果分析 3.1實驗數據集描述 為了檢驗中文異構知識庫實體對齊算法的有效性,本文從互動百科及百度百科分別隨機抽取了包含人物類及影視類的實體,抽取出的實體具有屬性信息及上下文信息。關于百科網站中人物類別的實體,熱門詞條編輯次數較多,實體屬性描述較為完整;普通詞條編輯次數較少,某些屬性存在缺失的情況。影視類實體的屬性描述較為統一,屬性對單個實體的描述較為完整。人物類實體的上下文描述從“人物生平”“主要成就”“人物影響及評價”等方面實體進行描述,影視類實體的上下文主題分布對同一實體的描述在不同數據源下可能存在較大差異。本文通過人工審核的方法對抽取的實體數據集進行了校驗。實體對齊數據集統計信息如表2所示。 3.2實驗結果分析 3.2.1評價指標 本文的主要工作是將來自中文異構數據源知識庫中的實體進行對齊,評價指標選取準確率(Precision,P)、召回率(Recall,R)及綜合指標F值(FScore,F)作為評價標準[21]。 1)準確率計算公式為: P=Nr/No(11) 2)召回率計算公式為: R=Nr/Na(12) 3)綜合指標F值計算公式為: F=2·P·R/(P+R)(13) 其中:Na為數據集中所有可準確對齊的實體個數;No為所有對齊實體數;Nr為正確對齊實體數。 準確率表示通過實體對齊算法后得到正確對齊后的實體的準確程度;召回率表示通過算法得到的準確對齊的實體數占數據集中所有可準確對齊實體的比率;F值為衡量準確率與召回率的綜合指標。
3.2.2模型參數選取
本文的模型參數主要有屬性相似度下界μ,屬性相似度上界ν,實體對齊閾值ω及主題模型中的主題數K。參數選取方法如下。
1)參數μ、ν選取。
經過大量實驗,實體在進行對齊時,如果屬性相似度小于μ,則判定為不可對齊實體, μ取經驗值0.5;如果屬性相似度高于上界ν,則判定為同一實體,ν取經驗值0.95。
2)參數ω選取。
實體相似度是屬性相似度與實體上下文相似度的均值,對于基于主題模型的實體對齊算法效果有重要影響。實體相似度參數ω越高,則實體對齊的準確率越高,但召回率下降;否則,參數ω降低,召回率提升,但準確率下降。實體相似度參數ω的選取主要依賴最優F值,若F值相近的情況下,選擇準確率更高的參數ω。通過圖3(a)看出,人物類實體對齊閾值ω選取為0.5~0.6時,綜合指標F值較高;通過圖3(b)看出,影視類實體對齊閾值選取為0.4時附近,綜合指標F值較高。
3)參數K選取。
本文的LCSLDA算法對不同主題數目情況進行了對比實驗。實驗中ω參數選取0.4,依次選取不同K值進行實體對齊實驗。從圖4實驗結果可以看出,主題個數K設定為2~3時實體對齊算法的F值最優,準確率及召回率的整體性能較好。
3.2.3與其他實體對齊算法比較
為了進一步驗證所提中文異構知識庫實體對齊算法(LCSLDA)的有效性,利用實體對齊數據統計信息進行實驗,在實驗過程中,分別用LCSLDA算法、LCS算法、LCS屬性加權(WeightedLCS)算法、LCSTFIDF算法、LDA算法運行表2中的實體對齊數據,各算法通過大量實驗取最優結果,實驗結果如表3所示。對各標準方法評價如下。
1)LCS算法。
文獻[22]中利用實體屬性,通過實體屬性值計算實體的相似度判定實體是否可以進行對齊。由于百科類屬于UGC數據,屬性值存在不規范情況,因此基于文獻[20]中所述算法,采用LCS算法比較實體屬性值。通過表3可以看出,僅僅利用實體屬性來對實體進行對齊,準確率、召回率及綜合評價指標F值均較低。
2)WeightedLCS算法。
WeightedLCS算法為文獻[13]中對屬性進行加權后進行實體對齊的方法,按照統計信息對屬性進行加權,實驗結果如表3所示,其對齊的準確程度較LCS算法下降,是由于該方法對通用屬性如人物類的“中文姓名”“出生日期”等,影視類如“影片名”“imdb編碼”等屬性依賴較重,導致百科數據集中分布較稀疏的屬性對實體對齊的重要性降低,而這些信息對于百科類實體對齊非常關鍵,因此對屬性進行加權并不能有效提高中文異構百科實體對齊的效果。
3)LCSTFIDF算法。
LCSTFIDF算法為結合了上下文信息的實體對齊方法,為每個實體上下文中出現的詞計算TFIDF值[23],將所有詞項的TFIDF值作為特征向量,在實體對齊問題中取得了較好表現,但由于TFIDF方法僅考慮詞項的詞頻特征,沒有考慮詞項的語義信息,因此效果次于LCSLDA算法。
4)LDA算法。
該方法采用LDA模型對實體提取主題特征,上下文僅考慮信息,可以看出在人物類百科實體對齊中可以取得不錯表現,然而由于人物類實體描述往往從“人物生平”“所獲成就”等方面描述,影視類實體在異構百科數據源中存在描述差異較大的現象,因此對于某些類別的百科實體僅通過上下文信息進行對齊時效果并不理想。
5)LCSLDA算法。
LCSLDA算法在人物類實體對齊數據集上實體相似度閾值ω取0.6,主題參數K取3時實體對齊的準確率及F值效果最好,召回率略低于LCSTFIDF算法及LDA算法;在影視類數據集上,實體相似度閾值取0.4,主題參數K取2時準確率、召回率及綜合評價指標F值均為第一,可見采用該算法對解決中文異構百科類實體對齊問題具有良好效果。
4結語
為解決中文異構百科類實體對齊問題,本文提出一種基于實體屬性與上下文主題特征相結合的實體對齊LCSLDA方法。該方法基于百度百科及互動百科構造中文RDF知識庫,通過RDFS對屬性進行規范化,抽取實體上下文信息并利用主題模型構造主題特征,結合了實體屬性特征與上下文語義信息解決實體對齊問題。為驗證所提算法的有效性,依照標準方法構造了中文百科類實體對齊數據集。通過與經典的屬性相似度算法、屬性加權算法、上下文詞頻特征模型及主題模型算法方法比較,實驗結果表明本文所提LCSLDA方法對于解決中文異構百科類實體對齊問題具有良好效果,對具有上下文信息的實體對齊問題具有一定通用性。
后續的研究將進一步優化實體對齊模型,并考慮大規模數據處理情況和基于云計算平臺解決異構百科實體數據融合問題,這對于百科知識庫的構建及問答系統的性能提升具有重要意義。
參考文獻:
[1]
BERNERSLEE T, HENDLER J, LASSILA O. The semantic Web [J]. Scientific American, 2001, 284(5): 28-37.
[2]
BOLLACKER K, EVANS C, PARITOSH P, et al. Freebase: a collaboratively created graph database for structuring human knowledge [C]// ACM SIGMOD 2008: Proceedings of the 2008 Association for Computing Machinerys Special Interest Group on Management of Data. New York: ACM, 2008: 1247-1250.
[3]
LEHMANN J, ISELE R, JAKOB M, et al. DBpedia—a largescale, multilingual knowledge base extracted from wikipedia [J]. Semantic Web, 2015(2): 167-195.
[4]
BIEGA J, KUZEY E, SUCHANEK F M. Inside YAGO2s: a transparent information extraction architecture [C]// Proceedings of the 22nd International Conference on World Wide Web Conference. New York: ACM, 2013: 325-328.
[5]
PHILPOT A, HOVY E, PANTEL P. The Omega ontology [C]// OntoLex05: Proceedings of the 2nd International Joint Conference on Natural Language Processing Workshop on Ontologies and Lexical Resources. Cambridge, UK: Cambridge University Press, 2005: 59-66.
[6]
LI M, SHI Y, WANG Z, et al. Building a largescale crosslingual knowledge base from heterogeneous online wikis [M]// Natural Language Processing and Chinese Computing. Berlin: Springer, 2015: 413-420.
[7]
MADHU G, GOVARDHAN A, RAJINIKANTH T V. Intelligent semantic Web search engines: a brief survey [J]. International Journal of Web & Semantic Technology, 2011, 2(1): 34-42.
[8]
HAN X, SUN L. A generative entitymention model for linking entities with knowledge base [C]// ACLHLT 2011: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language TechnologiesVolume 1. Stroudsburg, PA: Association for Computational Linguistics, 2011: 945-954.
[9]
NOV O. What motivates wikipedians [J]. Communications of the ACM, 2007, 50(11): 60-64.
[10]
SLEEMAN J, FININ T. Computing FOAF coreference relations with rules and machine learning [C]// SDoW2010: Proceedings of the 3rd International Workshop on Social Data on the Web. Berlin: Springer, 2010: 1-11.
[11]
ZHENG Z, SI X, LI F, et al. Entity disambiguation with freebase [C]// Proceedings of the 2012 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technology. Washington, DC: IEEE Computer Society, 2012: 82-89.
[12]
鄭杰,茅于杭.基于語境的語義排歧方法[J].中文信息學報,2000,14(5):1-7.(ZHENG J, MAO Y H. Word sense tagging method based on context [J]. Journal of Chinese Information Processing, 2000, 14(5): 1-7.)
[13]
張曉輝,蔣海華,邸瑞華.基于屬性權重的鏈接數據共指關系構建[J].計算機科學,2013,40(2):40-43.(ZHANG X H, JIANG H H, DI R H. Property weight based coreference resolution for linked data [J]. Computer Science, 2013, 40(2): 40-43.)
[14]
GOZUDELI Y, KARACAN H, YILDIZ O, et al. A new method based on tree simplification and schema matching for automatic Web result extraction and matching [C]// IMECS 2015: Proceedings of the International MultiConference of Engineers and Computer Scientists. Hong Kong: Newswood Limited, 2015, 1:369-373.
[15]
MILLER E. An introduction to the resource description framework [J]. Bulletin of the American Society for Information Science and Technology, 1998, 25(1): 15-19.
[16]
DONG L, WEI F, ZHOU M, et al. Question answering over freebase with multicolumn convolutional neural networks [C]// ACLIJCNLP 2015: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015, 1: 260-269.
[17]
MCBRIDE B. The Resource Description Framework (RDF) and its vocabulary description language RDFS [M]// Handbook on Ontologies. Berlin: Springer, 2004: 51-65.
[18]
BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation [J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
[19]
GRIFFITHS T. Gibbs sampling in the generative model of latent Dirichlet allocation [R]. Stanford: Stanford University, 2002.
[20]
BERGROTH L, HAKONEN H, RAITA T. A survey of longest common subsequence algorithms [C]// SPIRE 2000: Proceedings of the Seventh International Symposium on String Processing and Information Retrieval. Piscataway, NJ: IEEE, 2000: 39-48.
[21]
朱敏,賈真,左玲.中文微博實體鏈接研究[J].北京大學學報(自然科學版),2014,50(1):73-78.(ZHU M, JIA Z, ZUO L. Research on entity linking of Chinese micro blog [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2014, 50(1): 73-78.)
[22]
RAIMOND Y, SUTTON C, SANDLER M B. Automatic interlinking of music datasets on the semantic Web [C]// LDOW 2008: Proceedings of the 1st Workshop about Linked Data on the Web. New York: ACM, 2008, 369: 1-8.
[23]
MORI J, TSUJISHITA T, MATSUO Y, et al. Extracting relations in social networks from the Web using similarity between collective contexts [C]// ISWC 2006: Proceedings of the 5th International Semantic Web Conference. Berlin: Springer, 2006, 4273: 487-500.
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
