一種多路實時視頻拼接系統的設計與實現*
2016-06-30 07:06:48陳張新熊庭剛
艦船電子工程 2016年6期
陳張新 熊庭剛
(武漢數字工程研究所 武漢 430205)
一種多路實時視頻拼接系統的設計與實現*
陳張新熊庭剛
(武漢數字工程研究所武漢430205)
摘要針對當前多路視頻拼接系統實時性差、拼接效果不理想的問題,提出一種DSP+PC構架的視頻拼接系統。該視頻拼接系統由普通的PC機和硬件加速卡組成,硬件加速卡實現視頻采集和視頻拼接融合功能,PC端主要負責視頻顯示和人機交互,它們兩者之間通過PCIe高速協議進行數據傳輸。此外,論文通過改進基于SURF的特征點提取算法,提高了數據處理速度和配準精度。該設計實現了8路標清視頻的實時拼接與顯示,并顯著提升了視頻拼接效果。
關鍵詞全景視頻拼接; 圖像融合; SURF算法; DM8168
Class NumberTP391
1引言
為了解決單個攝像頭在獲取場景時存在的視野寬度不夠的問題,視頻拼接技術應用而生。這種技術可以將目標物體四周的場景進行無盲區顯示,進而填補特定場所大范圍、無盲區監控的市場空缺,可以預見,全景視頻拼接系統在車(艦)載監控、公共場所安全監控、智能交通、全景地圖繪制等軍用和民用領域必將有著廣泛的應用前景。例如,在軍事領域,全景視頻拼接系統能夠很好地把各個戰場獲得的畫面拼接起來,實時了解戰場的情況,進而根據畫面顯示的信息做出與之對應的決定,很大程度上杜絕了因為指揮不當而造成的損失。又例如,在醫學領域,如今的內科常規檢查都采用了醫學攝像診斷,而對于較大尺寸的目標,一個攝像頭不能照射到整個畫面,而兩個的話,不進行任何處理則會對醫生的診斷帶來一定的誤差和難度。而視頻拼接的引入能很好地解決這方面的難題。
目前,對于視頻拼接技術的研究,基本上都局限在功能實現的層面上,而且仍未出現一種能夠達到實時效果的拼接算法。隨著視頻拼接系統研究的不斷深入,對于一些比較基本的問題都得到了很好的解決,但實時性一直都是困擾著這套系統能夠取得突破的一個關鍵性問題。所以本文將著重對實時性這一問題進行分析和解決,同時,提出使用一種高效的構架。這種構架的結構是主控單元+硬件加速卡模式,它能夠最大限度的調用各個處理器的資源,加上算法方面的優化,進一步提升視頻數據的處理能力,從而達到實時性的效果。本系統在算法方面除了解決實時性的問題外,將對視頻顯示的效果也做進一步的優化,比如圖像配準精度問題等。
2系統設計與實現
本系統的組成主要由攝像機組、視頻拼接控制器、客戶終端等三個部分構成,其中視頻拼接控制器對來自攝像機組的多路視頻圖像進行實時采集、校正、拼接、融合,最終生成全景視頻圖像并予以實時顯示、壓縮、存儲和傳輸,從而實現對場景任意角度的無盲區監控。
2.1硬件整體構架
在硬件實現方面,本系統采用硬件加速卡的方式來提高系統的實時性和可擴展性。如圖1所示為全景拼接系統硬件組成框圖,采用主控單元+多個硬件插卡(視頻采集與硬件加速卡)的方案。其中,主控單元主要負責人機交互和資源調度,而采用硬件插卡的形式可以根據具體需求對系統功能進行擴展,例如:目前設計的系統采用兩塊卡完成對8路PAL視頻圖像的拼接,若需增加/減少視頻通道數、提高/減低系統分辨率可簡單通過增加/減少硬件插卡的形式實現。硬件插卡通過高速數據交換總線與主控單元相連,其主要功能如下。

圖1 全景拼接系統硬件組成框架
1) 對來自攝像機組的4路PAL模擬視頻進行實時采集;
2) 利用拼接參數完成4路視頻圖像的實時拼接,并將拼接好的圖像通過高速數據交換總線實時傳遞給主控單元;
3) 根據主控單元發來的指令,接收來自主控單元的拼接參數或將采集到的4路原始視頻圖像通過高速數據交換總線傳遞給主控單元;
4) 對采集到的四路原始視頻進行壓縮,并通過高速存儲總線存儲到本地存儲單元。
主控單元的主要功能包括:
1) 人機交互;
2) 對硬件插卡進行控制和調度;
3) 在全景拼接系統啟動階段計算拼接參數并通過高速數據交換總線傳遞給硬件插卡;
4) 在全景拼接系統穩定運行階段,每隔一段時間通過高速數據交換總線從硬件插卡接收原始視頻圖像,重新計算拼接參數,并將新的拼接參數通過高速數據交換總線傳遞給硬件插卡;
5) 實時接收來自硬件插卡的拼接圖像,并實時將來自各硬件插卡的拼接圖像拼接起來形成全景圖像;
6) 控制云臺攝像機,跟蹤目標或對局部區域進行放大。
2.2系統實現
本文所設計的硬件加速卡主要由DM8168及一些外設組成,TMS320DM8168是TI最新推出的一款高性能DMSoC,其中包含一個C674x DSP 主頻為1GHz,1 個Cotex-A8 主頻為1.2GHz,三個HDVICP 頻率為600MHz。CPU 具有強大的數據處理能力并包含大量的外設資源。其采用ARM+DSP的達芬奇構架,可以廣泛應用于視頻編解碼、視頻會議、媒體服務器、視頻監控等領域。評估板內部所包含的模塊以及外設主要包括以下幾點:
· 基于Cortex-A8的ARM微處理器;
· 基于C674x的定/浮點DSP;
· 一個高清視頻處理子系統(HDVPSS);
· 三個高清視頻圖像協處理器(HDVICP);
· 3D圖形引擎;
· 豐富的外設接口,主要包括UART接口、SATA接口、視頻接口(4片視頻采集芯片TVP5158)、音頻接口、以太網接口等。
根據以上設計的硬件框架,本文搭建了一個主控單元 + 硬件加速卡的實驗架構。DM8168的工作是多核之間協同作用,共同完成的,之所以能夠最大限度利用各個芯片之間的資源,主要得益于ARM中運行了一個Linux操作系統來協調各個微處理器之間的工作。
DM8168是DSP和ARM雙架構的SOC芯片。對芯片與外界的交互通過ARM端的Linux操作系統和相關的應用程序來管理,DSP端只處理相關的算法。DSP和ARM之間的通信和交互式通過引擎(Engine)和服務器(Server)來完成的[5]。
在ARM 端,對視頻類程序來說,應用程序首先把采集到的原始圖像信號,通過VISA 接口調用相關的Codec 存根函數,由存根函數調用相關的Engine API函數,也就是SPI (service provider interface)接口,但由于實際的Codec算法在遠端(DSP端),所以必須由引擎把信號進行封裝,通過OS抽象層與DSP Link 通訊把打包后的數據發送出去。這種數據處理方式有效地利用了各個環節的分工,提升了整個系統的開發效率。對于雙核的達芬奇構架,兩核之間的資源分配很大程度上決定了系統能否最大限度地各盡其能。ARM獨享(DSP不可用)的外設有:UART/0/1/2,I2C,看門狗時器,PWM/0/1/2,ARM 中斷控制器,USB2.0,ATA/CF,SPI,GPIO,VPSS,EMAC/MDIO,EMIF A CONTROL,VLYNQ,MMC/SD。DSP獨享(ARM不可用)的外設有:DSP 中斷控制器,VICP。ARM和DSP 共享的外設有:EDMA,Timer/0/1,Power & Sleep Controller,ASP 和EMIFA Data。也就是說,DM8168首次給DSP分配了內存管理單元(MMU),其可以將內存訪問的權限授予DSP,使得DSP與ARM擁有平等訪問內存的權利。DSP通過指向內存單元的指針尋址就可獲取數據,無需對數據進行拷貝。這種多核之間數據共享的機制大大提高了ARM和DSP協同工作的效率。
將上面已經優化過得算法移植到DSP上之后,可以在PC端發送視頻采集命令,通過PCIe傳送到硬件加速卡,進行視頻采集。硬件加速卡端將采集到的視頻進行一系列預處理后,進行拼接融合,將視頻數據傳輸到PC端進行實時顯示。其具體軟件實現流程圖如下所示。
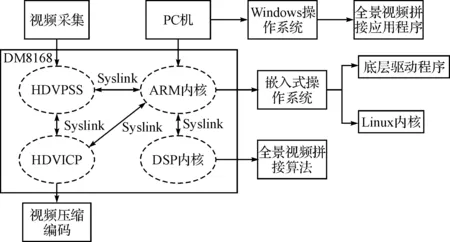
圖2 系統構架
2.3軟件算法優化
在算法設計方面,經過長期的研究發現,在視頻圖像拼接過程中,拼接參數計算階段耗時最長,但拼接參數的計算僅需在系統啟動時計算一次,而后續拼接過程中可以每隔幾分鐘甚至更長時間計算一次,不需要實時計算;另外,由軟件算法得到的拼接參數與實際情況存在一定誤差,如果每一幀視頻圖像都重新計算拼接參數,反而會影響場景的視覺一致性,這也是靜止圖像拼接算法不能直接用于視頻拼接的一個主要原因[1]。經上述分析后,本文將視頻拼接算法模塊劃分為兩個子模塊,即拼接參數計算模塊和圖像拼接模塊,來進一步提高算法的實時性。
拼接參數計算模塊主要完成曝光系數、拼接掩膜、后相映射圖等拼接參數的計算。如圖2所示為拼接參數計算模塊的工作流程。首先利用SURF(Speeded Up Robust Feature)算法提取圖像特征,并完成特征匹配對的搜索,然后根據特征匹配對估計相機焦距和相機運動參數。為了消除相鄰圖像間的亮度差異還需要進行曝光系數的計算。最后,為了進一步分擔圖像拼接模塊的負擔,此模塊還需完成后相映射圖(用以圖像彎曲)的計算以及權重圖(用以圖像融合)的計算。
圖像拼接模塊從拼接參數計算模塊得到相關參數,并完成視頻圖像的拼接,此過程需要實時處理。如圖3所示為圖像拼接模塊的工作流程,該模塊需要利用拼接參數計算模塊輸出的后相映射圖、曝光系數、權重圖等依次完成圖像彎曲、曝光補償和圖像融合。

圖3 拼接參數計算工作流程
關于圖像配準的算法有很多種,比如說比較經典的基于尺度不變特征(SIFT)的圖像拼接技術,該算法完全自動完成,而且采用了多分辨率對圖像進行融合,具有尺度不變性和旋轉不變性,是目前視頻拼接領域最為流行的算法。但是,當待匹配圖像含有大量的相似結構或者有高速運動的物體時,由于SIFT特征描述符僅僅利用了特征點的局部領域信息,因此對散落在這些相似區域中的點極易發生錯誤匹配。此次,利用了SURF特征[2]和RANSAC(Random Sample Consensus)[3]方法來實現多路視頻圖像精確配準。配準流程圖[4]如圖4所示,這種配準算法主要分為兩大步驟:第一步是特征提取——提取待匹配的兩幅圖像的SURF特征,并對每個特征點生成一個多維的描述子,所有特征點的描述子構成每一幅圖像的特征集;第二步是特征點匹配——以特征點集為考察對象,選擇一組特征集為參考集,另一組為目標集,在目標特征集中找出與參考特征集中一個特征描述子最相近的一個,對應特征點組成匹配對,再對匹配對進行提純,剔除錯誤匹配結果。

圖4圖像拼接模塊工作流程
SURF算子是一種具有局部特性的算子,該算子只對圖像中某一局部的極值點進行提取[5],這種局部特性很穩定,它不會因為圖像存在尺度縮放、旋轉、光照強度不同等情況而出現較大的變化,因此SUEF特征是一種局部不變形特征[6]。SUEF特征提取算法流程圖5所示。

圖5 配準流程圖

圖6 SURF特征提取流程圖
一般而言,同一個場景的不同視角的圖像之間具有一定的對應關系[6],在齊次坐標系下,圖像之間一般滿足式(1)所示的透視關系,其中M為圖像變換矩陣[7]。
(1)
對于較為豐富的圖像,得到的匹配對數往往數以百計,而圖像間變換關系只需四個匹配對便可完成[8]。如果只選擇其中四個匹配對計算出來的變換矩陣難免具有片面性,這就需要找出大部分匹配對都滿足的變換矩陣,至于那些不滿足的匹配對就作為錯誤匹配對而被剔除掉[9]。本項目擬采用RANSAC算法實來提純匹配對并估計變換參數。在實際操作中,具體實現形式可按照下列步驟進行[10]:
1)每次隨機取出四個匹配對,并以此計算出變換矩陣中的八個參數。
2)將匹配對中的其中一個點坐標經過計算出來的變換矩陣變換成一個新的坐標值,并計算這個坐標值與匹配對中的另一個點的坐標的距離。
3)考察上一步計算出來的距離,如果它小于某一個閾值,則將它作為一個內點,否則作為外點。
4)對所有的匹配對都按照第三步的做法,并記錄在上述變換矩陣下的內點數。然后從第一步開始重復進行上述步驟,直到找到擁有最多內點的變換模型,最大重復次數為N。對于N的確定,先令ω為數據是真實數據模型內點的概率,n為確定模型參數的最小點數,取4。這樣一來,一次估計所有n個點都為內點的概率就為ωn。如果要保證經過N次至少有一次估計中的所有點都是內點的概率為p,那么N應該滿足以下關系式:

(2)
3實驗結果與分析
相對于全景視頻的拼接,本文選取了三路視頻拼接作為實驗的結果進行分析。這樣做的理由是三路視頻的拼接與八路的原理是一致的,但取景相對來說會方便很多,而實際達到的效果卻一樣。
實驗采用本文所介紹的拼接算法,在搭建完開發環境和硬件系統后,把算法移植到DSP上運行,最后顯示出來的視頻圖像如圖7所示。經過與實時的視頻進行對比發現,我們所拼接顯示后的圖像的延時可以嚴格控制在15ms以內,這個參數已經可以滿足現如今大部分的監控需求。而且拼接后的視頻流的幀率平均可達25f/s。

圖7 全景視頻幀截圖
4結語
通過對視頻拼接系統硬件方面和軟件方面長期的研究,本文提出一種優化的硬件構架,并輔以改進的視頻拼接算法,很大程度上改善了視頻拼接實時性差、拼接效果不理想等瓶頸。本系統的主要設計思路是通過DM8168的8個視頻采集口對8個攝像頭的視頻數據進行采集,利用ARM調度板間資源,通過DSP上已經移植的視頻拼接算法處理同步的幀視頻信號,處理后的數據通過PCIe協議傳輸到上位機進行顯示。實驗結果表明,本系統能將8路D1視頻源的拼接延時控制在15ms以內,基本滿足了實時性要求,而且通過對配準算法的優化,很好地改善了拼接效果。
參 考 文 獻
[1] W Pan, K Qin, Y Chen. An Adaptable Multilayer Fractional FourierTransform Approach for Image Registration[J]. IEEETrans. on PAMI (S0162-8828),2009,31(3):400-414.
[2] Ishibuchi H,Tsukamoto N,Nojima Y.Diversity Improvementby Non—geometric Binary Crossover in EvolutionaryMultiobjective Optimization[J]. IEEE Transactions onEvolutionary Computation,2010,14(6):985-998.
[3] 杜威,李華.一種用于動態場景的全景表示方法[J].計算機學報,2014,26(6):968-956.
[4] 陳虎.基于特征點匹配的圖像拼接算法研究[J].海軍工程大學學報,2007,19(4):94-97.
[5] 陳玲,李昊然,谷源濤,等.基于DM8168的視頻會議服務器的設計與實現[J].計算機仿真,2013(11):206-208.
[6] Tuytlaars T. and Van Gool L., Matching widely separated views based on affine invariant region. International Journal of Computer Vision,2004,59(1):61-85.
[7] 方賢勇.圖像拼接技術研究[D].杭州:浙江大學,2005.
[8] M. Brown. D. Glowe. Recognising Panoramas[C]//Proceedings of the 9th International Conference on Computer Vision (ICCV2003),2003:1218-1225.
[9] R. Szeliski and H.-Y.Shum.Creating full view panoramic image mosaics and texture-mapped models[C]//Computer Graphics (SIGGRAPH'97) Proceedings,1997:251-258.
[10] Giorda.F, Racciu.A. Bandwidth Reduction of Video Signals via Shift Vector Transmission [J]. IEEE Transactions on Communications,1975,23(9):1002-1004.
Design and Implementation of A Multi-channel Fast Video Stiching System Based on DM8168
CHEN ZhangxinXIONG Tinggang
(Wuhan Digital Engineering Institute, Wuhan430205)
AbstractIn order to deal with the problem that multichannel video mosaicing system has worse real-time performance and unsatisfactory stitching effect, a video mosaics system of DSP + PC architecture is presented. The video mosaicing system is composed of ordinary PC and the hardware acceleration card.The hardware acceleration card is really to realize the function of video capture and video fusion splicing, and PC is responsible for video display and human-computer interaction. The data transmission between PC and hardware acceleration card relies on the PCIe high-speed protocols. In addition, through improving the feature points extraction algorithm based on SURF (Speeded Up Robust Feature), the data processing speed and matching accuracy is improved. The design has realized the 8 sign clear video stitching and display in real time, and significantly increased the video stitching effect.
Key Wordspanoramic video stitching, video fusion, SURF algorithm, DM8168
*收稿日期:2015年12月17日,修回日期:2016年1月23日
作者簡介:陳張新,男,碩士研究生,研究方向:視頻信息處理、DSP驅動開發等。熊庭剛,男,博士,研究員,研究方向:計算機體系結構。
中圖分類號TP391
DOI:10.3969/j.issn.1672-9730.2016.06.022
