一種基于RDF知識(shí)庫(kù)的二元組實(shí)體解析方法研究
2016-06-18 07:52:22伯為翰蘭雨晴
電子測(cè)試 2016年5期
伯為翰,蘭雨晴
(北京航空航天大學(xué)計(jì)算機(jī)學(xué)院,100191)
?
一種基于RDF知識(shí)庫(kù)的二元組實(shí)體解析方法研究
伯為翰,蘭雨晴
(北京航空航天大學(xué)計(jì)算機(jī)學(xué)院,100191)
摘要:實(shí)體解析是數(shù)據(jù)清理過程中的基本問題,隨著異構(gòu)數(shù)據(jù)源的大量涌現(xiàn),要求能夠?qū)Π卸喾N屬性類型的實(shí)體描述對(duì)象進(jìn)行解析。針對(duì)含有兩類屬性的實(shí)體解析問題,本文提出了一種基于RDF知識(shí)庫(kù)的二元組實(shí)體解析方法:通過知識(shí)庫(kù)檢索來(lái)確定二元組內(nèi)屬性的相互關(guān)系并獲取實(shí)體描述對(duì)象的具體類型,得到實(shí)體解析的分類結(jié)果。本文最后提出了基于該方法的算法框架及步驟,并通過實(shí)驗(yàn)進(jìn)行了驗(yàn)證。
關(guān)鍵詞:實(shí)體解析;RDF;知識(shí)庫(kù);數(shù)據(jù)清理
0 引言
實(shí)體解析(Entity Resolution,也稱為 Object Matching , Reference Reconciliation)是數(shù)據(jù)清理過程中的普遍問題,是數(shù)據(jù)集成的重要步驟。他的作用是分析、判別數(shù)據(jù)集中的哪些關(guān)于實(shí)體(entity)的描述(reference)是指向現(xiàn)實(shí)世界中的同一個(gè)實(shí)體。進(jìn)而對(duì)重復(fù)數(shù)據(jù)進(jìn)行刪除、合并、集成。
實(shí)體解析方法的種類很多,按其解析過程主要分為以下兩類:
(1)基于實(shí)體屬性的方法(character-based approaches),對(duì)每一對(duì)實(shí)體描述對(duì)象的屬性值計(jì)算其相似性,滿足設(shè)定的相似性閾值的實(shí)體表示為某一實(shí)體的共同引用(conference)。通常包括以下步驟:根據(jù)屬性的取值特點(diǎn),為每一屬性設(shè)計(jì)合適的相似度度量方法,并計(jì)算兩條記錄對(duì)應(yīng)屬性的相似度;然后選擇一個(gè)統(tǒng)計(jì)模型來(lái)判定兩個(gè)記錄的相似度或者匹配與否。簡(jiǎn)單的統(tǒng)計(jì)模型如線性回歸,涉及到學(xué)習(xí)每一個(gè)屬性的權(quán)重,從而對(duì)所有屬性的相似度進(jìn)行加權(quán)得到兩條記錄最終的相似度。通常會(huì)設(shè)定一個(gè)閾值,只有相似度不低于該閾值的記錄對(duì),才會(huì)被認(rèn)為是匹配的。傳統(tǒng)的統(tǒng)計(jì)模型根據(jù)有無(wú)訓(xùn)練集分為監(jiān)督模型和非監(jiān)督模型,比如樸素貝葉斯模型和層次聚類模型。無(wú)論使用哪一種模型,基于實(shí)體屬性匹配的方法都要涉及到計(jì)算屬性的相似度。根據(jù)屬性的取值特點(diǎn),人們提出了不同的相似度度量方法。這些相似度度量方法大致分為基于字符的相似度度量方法和基于詞的相似度度量方法。
(2)基于實(shí)體關(guān)系的方法(relation-based approaches),根據(jù)實(shí)體描述,通過找出實(shí)體間相互關(guān)系的方法來(lái)進(jìn)行解析。舉例來(lái)說(shuō),在學(xué)術(shù)網(wǎng)絡(luò)中,研究者們通常會(huì)和特定的一些研究者合作比較頻繁。這種朋友關(guān)系或者合作關(guān)系可以通過觀察實(shí)體在記錄中的共現(xiàn)情況得到。利用這些關(guān)系可以進(jìn)行深層次的分析。這些方法包括:Ananthakrishna等人利用鏈接之間存在的維度層次結(jié)構(gòu)等信息來(lái)解決數(shù)據(jù)倉(cāng)庫(kù)應(yīng)用領(lǐng)域中存在的重復(fù)問題;Bhattacharta等人提出了將基于屬性的實(shí)體解析方法直接進(jìn)行改進(jìn)的關(guān)系型實(shí)體解析方法,將實(shí)體之間的相似性定義為二者基于關(guān)系的實(shí)體相似性和基于邊(鏈接)的實(shí)體相似性的線性組合;將實(shí)體解析轉(zhuǎn)換為聚類問題的方法。無(wú)論用什么樣的關(guān)系表示,這種基于實(shí)體關(guān)系的方法本質(zhì)上都是基于實(shí)體值的的相似度測(cè)量值基礎(chǔ)上的改進(jìn)。
以上的這些方法首先都要對(duì)每個(gè)實(shí)體描述對(duì)象對(duì)進(jìn)行相似度測(cè)量,特別是對(duì)較大規(guī)模的數(shù)據(jù)集即便設(shè)計(jì)高效的算法其比對(duì)量也很大;其次大多數(shù)解析場(chǎng)景是針對(duì)具有相同類型的這一類實(shí)體描述對(duì)象進(jìn)行比較,例如包含有文章名稱和作者描述的文字的這一類實(shí)體描述對(duì)象。
而現(xiàn)實(shí)中情況更為復(fù)雜,實(shí)體的描述信息可能來(lái)自于不同類型的數(shù)據(jù)集,可能是關(guān)系型數(shù)據(jù)庫(kù)、文本字段等。即便是在關(guān)系型數(shù)據(jù)庫(kù)中,由于字段名屬性不同,同一實(shí)體在不同數(shù)據(jù)源中可能有多個(gè)不同的表達(dá)方式;即使是相同字段名屬性的描述可能表示多個(gè)不同的實(shí)體。例如最普遍的情況:對(duì)于同一部電影,一條文字是包含有電影名字、電影演員的實(shí)體描述,而另一條文字是包含有電影名字、導(dǎo)演的實(shí)體描述;而對(duì)于包含有電影名字、導(dǎo)演這兩種屬性的實(shí)體描述又表示不同的電影實(shí)體;此外,具有相同描述主體的文字可能指向不同類型的實(shí)體。
考慮現(xiàn)實(shí)中經(jīng)常出現(xiàn)的以下場(chǎng)景:以包含有某個(gè)實(shí)體名稱屬性值和其他屬性值的實(shí)體描述為例,可能存在的實(shí)體描述文字為:(表1)
由表1可知7種實(shí)體描述中,共得到4個(gè)不同的實(shí)體,其中4個(gè)描述是關(guān)于電影“臥虎藏龍”的實(shí)體,1個(gè)描述關(guān)于小說(shuō)“臥虎藏龍”的實(shí)體,1個(gè)描述關(guān)于電影“少年派”的實(shí)體和1個(gè)描述關(guān)于小說(shuō)“少年派”的實(shí)體。表中關(guān)于電影“臥虎藏龍”的描述有4個(gè),其導(dǎo)演李安還執(zhí)導(dǎo)了“少年派”這部電影。如果用傳統(tǒng)的相似度方法或者聚類方法解析,即使描述文字的相似度很高,得到的結(jié)果也不盡如人意。考慮到每一條實(shí)體描述語(yǔ)言都是對(duì)現(xiàn)實(shí)世界中的實(shí)體的某種表示,即具有語(yǔ)義性,我們尋求一種通過RDF類型知識(shí)庫(kù)來(lái)建立實(shí)體描述中屬性值的某種關(guān)系,進(jìn)而對(duì)該實(shí)體描述進(jìn)行類型匹配的方法來(lái)進(jìn)行實(shí)體解析。
1 RDF類型知識(shí)庫(kù)研究
1.1RDF數(shù)據(jù)模型
RDF是一種數(shù)據(jù)模型,全稱是資源描述框架(resource description framework),由萬(wàn)維網(wǎng)聯(lián)盟(World Wide Web Consortium,W3C)組織的資源描述框架工作組于1999年提出的一個(gè)解決方案,并于2004年2月正式成為萬(wàn)維網(wǎng)聯(lián)盟推薦標(biāo)準(zhǔn)。目標(biāo)是構(gòu)建一個(gè)綜合性的框架來(lái)整合不同領(lǐng)域的元數(shù)據(jù)。RDF的基本數(shù)據(jù)模型包括資源(resource)、屬性(property)及陳述(statements)。RDF模型中一條標(biāo)準(zhǔn)的陳述(statement)由一個(gè)三元組構(gòu)成:主體(<subject>)、謂詞(<predicate>)、客體(<o(jì)bject>),表示對(duì)主體的某種描述。
基于信息抽取技術(shù),可以自動(dòng)地從大規(guī)模的非結(jié)構(gòu)化數(shù)據(jù)中抽取并構(gòu)造開放領(lǐng)域的RDF數(shù)據(jù)集,如Freebase、IMDB、Wikipedia等等。

表1 包含有“臥虎藏龍(Crouching Tiger Hidden Dragon)”和“Life Of Pie(少年派)”實(shí)體的可能描述
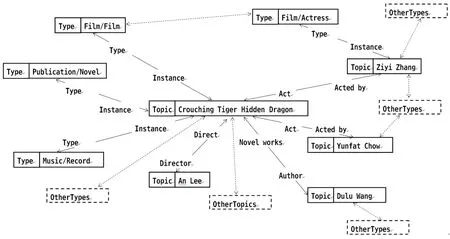
圖1 Freebase 知識(shí)庫(kù)中關(guān)于“臥虎藏龍(Crouching Tiger Hidden Dragon)”名稱圖的結(jié)構(gòu)
1.2Freebase知識(shí)庫(kù)結(jié)構(gòu)
以Freebase知識(shí)庫(kù)為例,按照類型分類它的結(jié)構(gòu)可分為三層:域(Domain)->類型(Type)->實(shí)體(Topic)。
(1) 在Freebase中,每個(gè)Topic,即為主體(<subject>),每個(gè)Topic中的固定字段,叫做“屬性”(Property)即謂詞(<predicate>);對(duì)應(yīng)某種屬性的值即為客體(<o(jì)bject>),這樣建立了主體與客體之間的雙向關(guān)系;
(2) 所有同類的Topic組成一個(gè)Type,比如所有電影Topic就屬于同一個(gè)Type,每個(gè)Type都有一套固定的Property,因此同類信息可以直接比較和關(guān)聯(lián);
(3) 所有相關(guān)的Type組成一個(gè)“域”(Domain),比如電影和音樂都屬于“藝術(shù)和娛樂”域,可將域看做一個(gè)大的類型(Type)。
同時(shí)對(duì)每一個(gè)主體它的某個(gè)屬性值可能為另一個(gè)主體, 這樣所有的主體通過屬性的關(guān)系構(gòu)建成了一張圖(Graph),圖中的頂點(diǎn)表示主體(Topic)和類型(Type),邊表示頂點(diǎn)之間的對(duì)應(yīng)屬性,考慮從表1中抽取的實(shí)例在Freebase庫(kù)中的結(jié)構(gòu)(圖1):
如圖1所示,該圖是與“臥虎藏龍(Crouching Tiger Hidden Dragon)”這個(gè)名字的主體(topic)所對(duì)應(yīng)的所有關(guān)系圖,由圖中可知,“臥虎藏龍”對(duì)應(yīng)屬于3個(gè)不同類型,同時(shí)它也繼承了這3類的所有屬性,它同時(shí)與n個(gè)不同的主體之間存在某種關(guān)系,不同的主體又屬于不同的其它類型。
2 基于RDF結(jié)構(gòu)知識(shí)庫(kù)的二元組實(shí)體解析算法(RDF-Tow-Tuple Entity Resolution, RDF-TER)
2.1概念定義
(1)實(shí)體描述對(duì)象
假設(shè)實(shí)體數(shù)據(jù)集中的每一個(gè)實(shí)體描述對(duì)象由兩種屬性值表示成一個(gè)二元組,R=(S,Oi),S,Oi為該二元組的元素:其中S表示實(shí)體描述對(duì)象的名稱,Oi表示實(shí)體描述對(duì)象的某種屬性的值。
(2)實(shí)體描述對(duì)象類型定義
由于不同種類的實(shí)體屬性不同,會(huì)導(dǎo)致其屬性值也不同,則在實(shí)體解析過程中所起的作用也不同,因而用比較的方法將將二元組中的元素分為決定元素和輔助元素。
定義1 決定元素 (dominant element, DE)把實(shí)體描述對(duì)象中較為穩(wěn)定的、不具有較多歧義參考表示的元素稱為決定元素。決定元素在實(shí)體分類過程中起到?jīng)Q定性的作用。
定義2 輔助元素 (assistant element, AE)把實(shí)體描述對(duì)象中屬性較為繁多并可能有較多歧義的元素稱為輔助元素。輔助元素在實(shí)體解析過程中起到輔助的作用。
根據(jù)定義,實(shí)體描述對(duì)象R中S為決定元素(DE), Oi為輔助元素(AE)。例如表1中所描述的,“Crouching Tiger Hidden Dragon”為決定元素,表中的其他屬性值為輔助元素。為簡(jiǎn)化討論,本文中暫時(shí)先假設(shè)輔助元素為1個(gè)的情況。
2.2算法原理
基于RDF結(jié)構(gòu)的知識(shí)庫(kù),將實(shí)體描述對(duì)象的二元組的值分別在知識(shí)庫(kù)圖中進(jìn)行檢索,找出二元組中屬性值之間的絕對(duì)屬性關(guān)系,再通過對(duì)這兩類屬性值的類型的遍歷與篩選,得到一個(gè)包含決定元素(DE)的屬性類型(Type)的基本回路,回路的結(jié)點(diǎn)包含元素值和類型,邊由他們之間的相互關(guān)系組成。即確定了該實(shí)體描述對(duì)象的類型,最終得到具體的實(shí)體。
綜上,本文提出的基于RDF結(jié)構(gòu)知識(shí)庫(kù)的二元組實(shí)體解析算法(RDF-TER)的框架(圖2),包括兩個(gè)階段:第一階段檢索二元組值之間的關(guān)系,第二階段通過遍歷匹配二元組之間的類型關(guān)系,最后得到?jīng)Q定元素的類型。
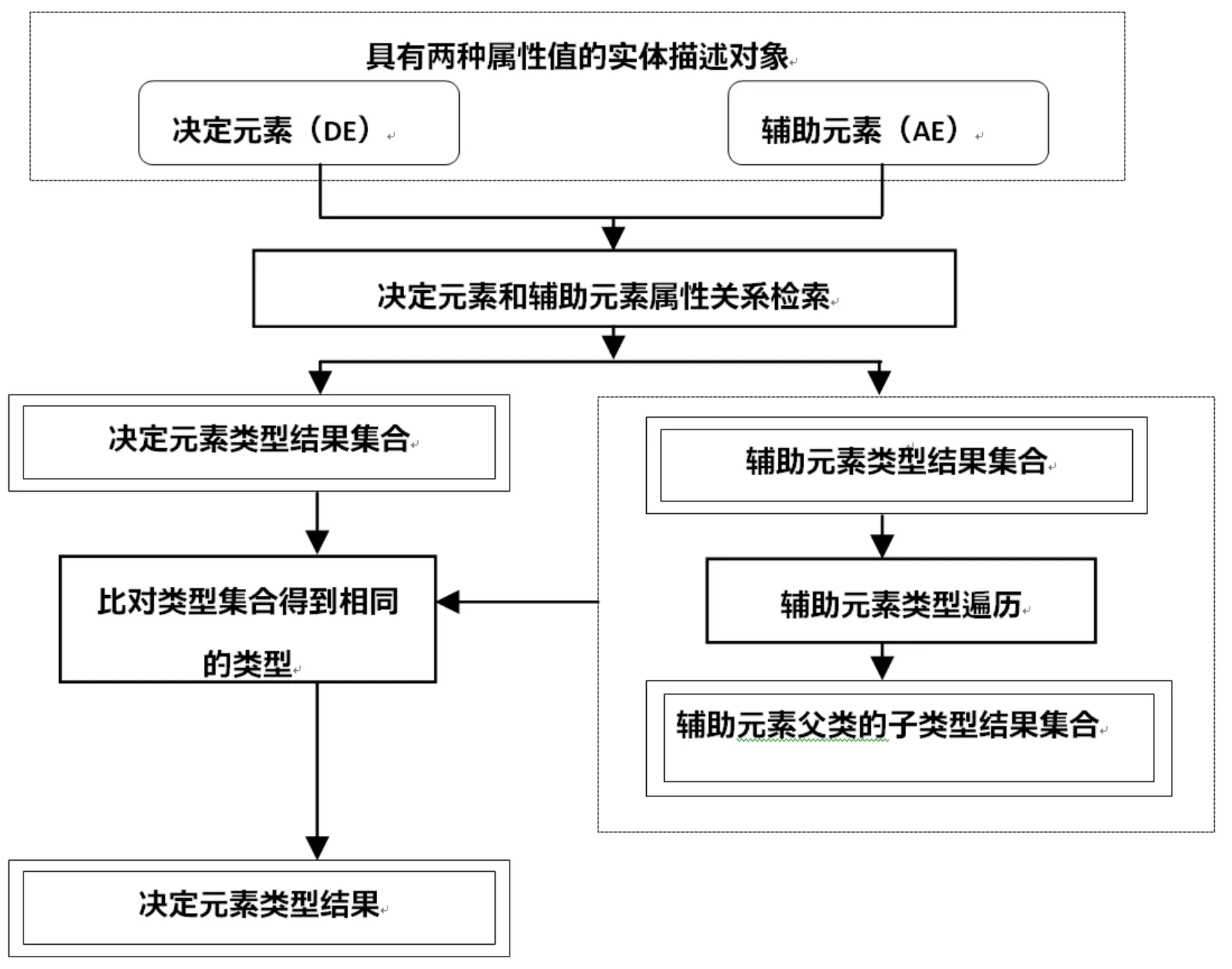
圖2 基于RDF結(jié)構(gòu)知識(shí)庫(kù)的二元組實(shí)體解析算法(RDF-TER)的框架
2.3算法步驟
輸入 規(guī)模為n的,包含兩種元素的數(shù)據(jù)集D;
輸出 決定元素類型結(jié)果。
基于RDF結(jié)構(gòu)知識(shí)庫(kù)的二元組實(shí)體解析算法(RDF-TER)主要步驟(圖3):

圖3 RDF-TER算法偽代碼
3 實(shí)驗(yàn)及結(jié)果分析
3.1實(shí)驗(yàn)數(shù)據(jù)
為驗(yàn)證本方法的有效性,我們對(duì)一個(gè)真實(shí)的數(shù)據(jù)集進(jìn)行測(cè)試,該數(shù)據(jù)集是從關(guān)系數(shù)據(jù)庫(kù)和網(wǎng)頁(yè)中抽取的包含電影、小說(shuō)、音樂等類型數(shù)據(jù)集作為比對(duì)數(shù)據(jù),其中每一條記錄由實(shí)體名稱描述和實(shí)體某一類屬性描述構(gòu)成,截取數(shù)據(jù)部分參考如下(表2)。
實(shí)驗(yàn)測(cè)試環(huán)境為:操作系統(tǒng)為WIN7,CPU為Intel Core 3.40GHz、內(nèi)存為4GB。
3.2結(jié)果分析
對(duì)實(shí)體描述中的所有對(duì)象分別抽取為決定元素和輔助元素的二元組對(duì),再通過RDF-TER算法在知識(shí)庫(kù)中檢索后得到的分類實(shí)體解析結(jié)果,對(duì)照表2的實(shí)例部分,得到的解析結(jié)果集
合如下(圖4):由解析得到的結(jié)果可知,表2中的包含有3個(gè)相同實(shí)體描述名稱(決定元素)的12條實(shí)體描述最終得到了6個(gè)不同的實(shí)體,數(shù)據(jù)子集中的1,4, 8,11為同一個(gè)實(shí)體,6為另一個(gè)實(shí)體,盡管他們都有相同的實(shí)體描述名稱,而1,9,10即便都是同一類型的描述,但是實(shí)體描述名稱不同,其實(shí)體也不同,最特殊的,1,9的中屬性描述(輔助元素)即便相同,其得到的實(shí)體也不一樣。
最終在1000條、5000條數(shù)據(jù)上得到的解析結(jié)果與數(shù)據(jù)集標(biāo)準(zhǔn)值比較,準(zhǔn)確率分別為
88.32%、81.47%。其檢索比對(duì)時(shí)間包括二元組詞檢索和結(jié)果類型比對(duì),分別為40.572秒、320.915秒。考慮到數(shù)據(jù)的規(guī)模,該算法能夠在較短時(shí)間內(nèi)處理大規(guī)模的實(shí)體解析數(shù)據(jù)集。
4 結(jié)論
本文針對(duì)具有二元屬性因素的實(shí)體解析問題,采用了與以往基于相似度測(cè)量和基于相似度關(guān)系等途徑不同的思路,提出了通過RDF類型知識(shí)庫(kù)來(lái)建立實(shí)體描述中屬性值之間的確定關(guān)系,進(jìn)而對(duì)該實(shí)體描述進(jìn)行類型匹配的方法來(lái)進(jìn)行實(shí)體解析。通過實(shí)驗(yàn)得出的準(zhǔn)確率分析,能較好地解決具有相似屬性和不同屬性的實(shí)體描述對(duì)象的解析問題,并根據(jù)運(yùn)行時(shí)間,認(rèn)為該算法能能夠在較短時(shí)間內(nèi)處理大規(guī)模的實(shí)體解析數(shù)據(jù)集。作為一種探索性的思路與算法,下一步將繼續(xù)研究其與傳統(tǒng)解析方法的性能比較與分析,擴(kuò)展解析場(chǎng)景,進(jìn)一步提高算法運(yùn)行效率與準(zhǔn)確率。
參考文獻(xiàn)
[1] Hanna K?pcke,Andreas Thor,Erhard Rahm,Evaluation of entity resolution approaches on real-world match problems,2010 VLDB.
[2] Bhattacharya I, Getoor L. Collective entity resolution in relational data [J] . ACM Transactions on Knowledge Discovery from Data, 2007, 1(1): 1-36.
[3] Yu P S, Han J W, Faloutsos C. Link mining: Models, algorithms, and applications[M] . New York: Springer-Verlag, 2010: 118-119.
[4] David Menestrina, Steven Euijong Whang, and Hector GarciaMolina. Evaluating Entity Resolution Results . 2010 VLDB .
[5] Kalashnikov D V, Mehrotra S, Chen Z Q. Exploiting relationships for domain-independent data cleaning[C] // Proceedings of the Fifth SIAM International Conference on Data Mining, Philadelphia: Society for Industrialand Applied Mathematics, 2005: 262-273.
[6] W. Winkler, Overview of record linkage and current research directions, Statistical Research Division, U.S. Bureau of the Census, Washington, DC, Tech. Rep., 2006.
[7] David Menestrina, Steven Euijong Whang, and Hector GarciaMolina. Evaluating Entity Resolution Results.2010 VLDB .
[8] Ananthakrishna R, Chaudhuri S, Ganti V. Eliminating fuzzy duplicates in data warehouses[C] // Proceedings of the 28th International Conference on Very Large Databases, Massachusetts: Morgan Kaufmann Publishers, 2002: 586-597.
[9] Hannah Bast, Florian B?urle, Bj?rn Buchhold, Elmar Haussmann. A Case for Semantic Full-Text Search. JIWES ’12 August 12 2012, Portland, OR, USA
[10] RDF Current Status. http://www.w3.org/standards/ techs/rdf#w3c_all
[11] Thanh Tran, Haofen Wang, Sebastian Rudolph, Philipp Cimiano. Top-k Exploration of Query Candidates for Efficient Keyword Search on Graph-Shaped (RDF) Data. In Proceedings of ICDE'2009. 405~416
[12] Shady Elbassuoni, Maya Ramanath, Ralf Schenkel,Gerhard Weikum: Searching RDF Graphs with SPARQL and Keywords. IEEE Data Eng. Bull. (2010), 33(1):16~24
[13] Freebase API reference. https://developers.google.com/ freebase/v1/
[14] https://freebase.com/
[15] http://freebase-easy.cs.uni-freiburg.de/dump/

表2 包含實(shí)體名稱描述和實(shí)體某類屬性的數(shù)據(jù)子集
A method for two-tuple entity resolution based on RDF knowledge base
Bo Weihan,Lan Yuqing
(School of Computer Science and Engineering,Beihang University,Beijing,100191,China)
Abstract:Entity resolution is a fundamental issue in the process of data cleaning.With the advent of heterogeneous data source,it is necessary to identify entities with different properties simultaneously.We propose a method for two-tuple entity resolution based on RDF knowledge base.By retrieving knowledge base we can identify the relationship between two tuples and obtain a specific type of the entity resolution object in each. We also present an algorithm framework and experiment results.
Keywords:Entity parsing;RDF;knowledge base;data cleaning
通訊作者:伯為翰
