基于低秩矩陣恢復(fù)的目標(biāo)快速檢測方法研究
2016-06-02 11:28:26周薇娜上海海事大學(xué)信息工程學(xué)院上海201306
網(wǎng)絡(luò)安全與數(shù)據(jù)管理 2016年10期
李 俊,周薇娜(上海海事大學(xué)信息工程學(xué)院,上海201306)
?
基于低秩矩陣恢復(fù)的目標(biāo)快速檢測方法研究
李俊,周薇娜
(上海海事大學(xué)信息工程學(xué)院,上海201306)
摘 要:為了實現(xiàn)快速運(yùn)動目標(biāo)檢測,利用低秩矩陣恢復(fù)原理進(jìn)行視頻前景檢測,主要針對低秩矩陣恢復(fù)算法存在的耗費(fèi)大部分運(yùn)算時間且運(yùn)算較為復(fù)雜的奇異值分解問題,應(yīng)用統(tǒng)一計算結(jié)構(gòu)裝置(CUDA)第三方庫實現(xiàn)加速計算奇異值分解的低秩矩陣恢復(fù)算法優(yōu)化,得到快速且高效的前景檢測方法。基于開源視頻序列實驗,與原有的低秩矩陣恢復(fù)算法進(jìn)行各項參數(shù)的比較,其中加速倍數(shù)達(dá)一倍以上。實驗結(jié)果證明,經(jīng)過優(yōu)化的算法運(yùn)算時間變短,具有更高效率。
關(guān)鍵詞:低秩矩陣恢復(fù);前景檢測;統(tǒng)一計算結(jié)構(gòu)裝置
0 引言
目標(biāo)檢測是把視頻序列中感興趣的目標(biāo)分割出來,作為許多視覺應(yīng)用中最基礎(chǔ)的部分,深入探討其相關(guān)算法研究以提高其檢測性能與精度,顯得相當(dāng)重要。傳統(tǒng)目標(biāo)檢測算法計算較為復(fù)雜,檢測精度相對較低,性能也較低下。隨著計算機(jī)技術(shù)的高速發(fā)展,所拍攝的視頻序列圖像分辨率也越來越高,這使得視頻序列中圖像數(shù)據(jù)量過大和數(shù)據(jù)維數(shù)過高,增加目標(biāo)檢測計算難度。對高維數(shù)據(jù)降維,用降維得到的低維數(shù)據(jù)表征原有的高維數(shù)據(jù)從而降低數(shù)據(jù)計算復(fù)雜度成了視頻圖像數(shù)據(jù)處理的重要方法。主成分分析(Principal Component Analysis,PCA)是一種很有效的分析高維數(shù)據(jù)的工具,把高維數(shù)據(jù)投影到低維空間,奇異值分解(Singular Value Decomposition,SVD)使得PCA有了穩(wěn)定高效的計算能力,但當(dāng)矩陣元素受到嚴(yán)重破壞時,PCA則對矩陣估計不準(zhǔn)確。為了改善PCA對這種情況的處理,CANDES E J提出了魯棒主成分分析[1](Robust Principle Component Analysis,RPCA),也稱低秩矩陣恢復(fù)[2],指元素受到嚴(yán)重破壞的矩陣也得以恢復(fù)。
一般說來由視頻數(shù)據(jù)構(gòu)造成的觀測矩陣可以分解為稀疏和低秩兩個矩陣,矩陣恢復(fù)時可以用凸優(yōu)化的方法,視頻前景檢測擬合這種分解特性。前景檢測是從拍攝的視頻中分離出背景和前景,由于視頻的背景基本是不變的,因此如果把每幀當(dāng)做矩陣的各列,那么此矩陣將是低秩的,低秩矩陣恢復(fù)可以同時完成背景和前景分離,得到的前景即為需要檢測的目標(biāo)。
低秩矩陣恢復(fù)算法運(yùn)行在MATLAB平臺上,MATLAB雖易用性強(qiáng),但是有著計算慢、效率低等缺點。經(jīng)過對算法和CUDA[3]深入分析,使用MATLAB和C++的MEX混合編程,進(jìn)行了在MATLAB內(nèi)調(diào)用CUDA第三方庫加速原有算法的運(yùn)算,經(jīng)加速優(yōu)化后,低秩矩陣恢復(fù)前景檢測方法效率更高。最后基于真實數(shù)據(jù)實驗,進(jìn)行經(jīng)過優(yōu)化后的算法與原算法各項參數(shù)的比較。
1 低秩矩陣恢復(fù)
觀測得到的數(shù)據(jù)組成的數(shù)據(jù)矩陣D秩一般很低,為了恢復(fù)它的低秩結(jié)構(gòu),把矩陣D分解成一個低秩矩陣和一個稀疏矩陣的和,即D=A+E,A未知是低秩的,E也未知是稀疏的。當(dāng)矩陣E的元素服從獨(dú)立同分布的高斯分布時,PCA可解SVD得到最優(yōu)的矩陣A,即求解下面的最優(yōu)化問題:
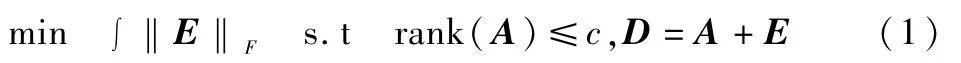
其中,‖.‖F(xiàn)為F范數(shù),c為子空間維數(shù)。當(dāng)E不理想時,經(jīng)典PCA對A的估計就相當(dāng)不準(zhǔn),WRIGHT J等人提出的RPCA很好地解決了上述問題。
同PCA一樣,RPCA的問題可描述為:觀察數(shù)據(jù)矩陣D為已知,D=A+E,A、E未知,A為低秩的,但是E稀疏且非零元素E可能無限大,要從中恢復(fù)出A,需得到觀察數(shù)據(jù)D的最小的秩,且干擾誤差是稀疏的。通過以下優(yōu)化問題來描述:
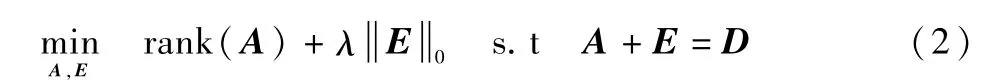
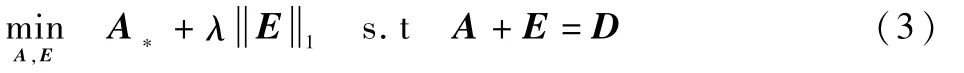
該問題也被稱之為主成分追蹤(Principal Component Pursuit,PCP),在一定條件下,求解式(3)可以得到理想且唯一的A和E。將以上的凸優(yōu)化問題稱為RPCA,該方程式在實際應(yīng)用中性能良好,能從高達(dá)1 /3嚴(yán)重腐蝕的觀測值中恢復(fù)真實的低秩矩陣,并且具有優(yōu)秀的理論保證。例如,對一般的矩陣A,它可以顯示成功糾正錯誤恒比,甚至當(dāng)A的秩是近似地正比于環(huán)境度:rank(A)=Cm/log (m)。參考文獻(xiàn)[1]也給出了結(jié)論定理:如果A0為n×n矩陣,其秩rank(A0)≤ρrnμ-1·(log n)-2,E0是隨機(jī)稀疏的n×n矩陣,基數(shù)m≤ρsn2ρrρs,其中ρr為低秩率,ρs為稀疏率,當(dāng)時,PCP能夠準(zhǔn)確恢復(fù)出的概率為1 -O(n-10)。對于任意矩形矩陣,對λ=1 /有與上相同的結(jié)論。
2 算法
前景檢測是把目標(biāo)由視頻里提取出來。因為視頻的背景基本是不變的,假設(shè)視頻有n幀圖像,把每幀當(dāng)做矩陣D每一列,由每幀圖像的像素構(gòu)成的m維列向量作為矩陣D每一行,得到大小為m×n低秩矩陣D,因此可用低秩矩陣恢復(fù)來恢復(fù)出背景。低秩矩陣A可作為視頻中有很大相關(guān)性的背景部分,稀疏矩陣E則可作為分布稀疏的前景部分也即感興趣的目標(biāo)。
有許多方法可求解RPCA問題[4-7],本文對非精確增廣拉格朗日乘子法(IALM)中的奇異值分解計算進(jìn)行加速優(yōu)化,使得能夠加速計算奇異值分解,算法運(yùn)算效率提升,運(yùn)行時間縮減。
構(gòu)造增廣拉格朗日函數(shù):
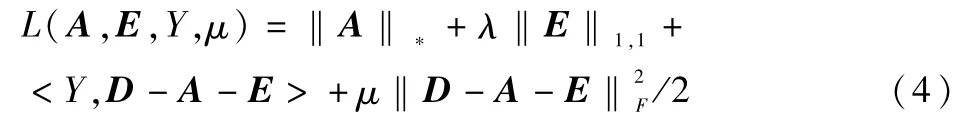
其中,Y∈Rm×n為約束乘子,μ>0為懲罰參數(shù),[·]表示計算內(nèi)積,‖·‖F(xiàn)表示F范數(shù)。每一步最小化式(4)時使用輪流更新的方法,先保持Y與E不變,求得使L最小的A,然后保持Y與A不變,求使L最小的E,這樣迭代次數(shù)就可收斂到這個子問題的最優(yōu)解。更新A時:
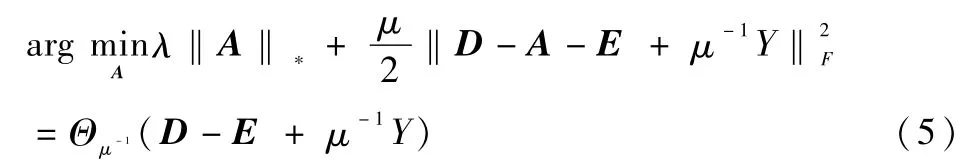
更新E時:
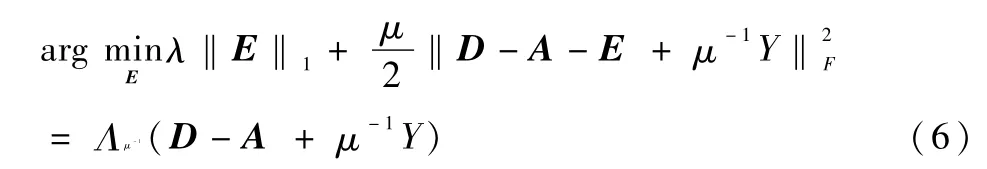
輪流更新,直到對子問題求解收斂時為止,該算法被稱為精確增廣拉格朗日乘子法(EALM),見算法1[4,8]。
算法1
(2)while not converged do
(4)while not converged do
(8)j=j+1
(9)end while
(11)k=k+1
(12)end while
稱算法1為精確增廣拉格朗日乘子法,原因在于最外層的循環(huán)并不需要求出子問題的精確解,事實上,只要將A和E都更新一次得子問題的一個近似解,這樣得到的最優(yōu)解就可使算法收斂到原問題,因此可以得到簡潔且收斂更快的算法——IALM,見算法2[4,8]。
算法2
(1)初始化Y0,E0,μ0,k=0
(2)while not converged do
(7)更新μk
(8)k=k+1
(9)end while
以上算法會耗費(fèi)大量時間計算奇異值分解,所以找到快速處理奇異值分解計算的方法,對于整個算法的執(zhí)行效率將會大有改善。本文基于CUDA架構(gòu)第三方CULA[9 -10]庫在MATLAB中實現(xiàn)加速優(yōu)化算法中奇異值分解的計算。MATLAB中CUDA加速的原理為:CPU執(zhí)行流程控制的操作代碼,一些需要并行運(yùn)算的操作代碼放在GPU中處理,這樣算法運(yùn)算時間將大幅度減少。CUDA計算的流程如圖1所示。
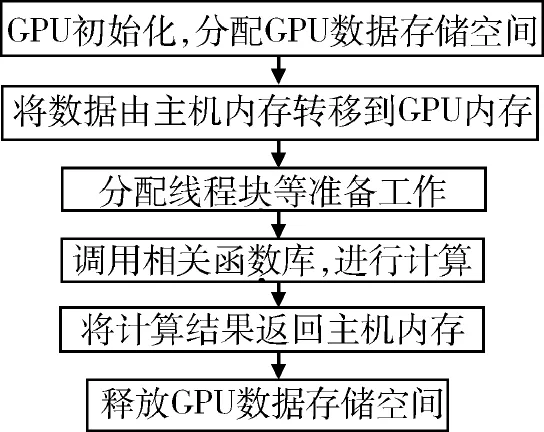
圖1 CUDA計算流程圖
經(jīng)過仔細(xì)閱讀CULA參考手冊和CULA編程指南,分析低秩矩陣恢復(fù)算法,編寫可以在MATLAB里面通過一些接口使用CULA庫加速的culaSvd mex源文件。首先,需要在MATLAB里面處理多種CULA的數(shù)據(jù)類型,MATLAB和CULA支持的4個主要的數(shù)據(jù)類型為:單精度實數(shù)、雙精度實數(shù)、單精度復(fù)數(shù)和雙精度復(fù)數(shù)。由于MATLAB MEX編譯器與CULA支持C++語言,可以通過代碼來實現(xiàn)數(shù)據(jù)類型的處理,用C++模板來處理所有的4個MATLAB數(shù)據(jù)類型,使用MATLAB函數(shù)mxGetClassID()和mxIsComplex()確定輸入矩陣的精度和復(fù)雜度。上述代碼主要包括3個部分,SVD函數(shù)的CULA頭文件和MATLAB數(shù)據(jù)類型和接口的頭文件、支持4種MATLAB數(shù)據(jù)類型的模板函數(shù)、在MATLAB中調(diào)用的C++模板所需要的網(wǎng)關(guān)函數(shù)。其次,因為CULA和MATLAB以不同的類型存儲復(fù)雜的數(shù)據(jù),創(chuàng)建helper函數(shù),實現(xiàn)兩個類型之間的轉(zhuǎn)換。創(chuàng)建好helper函數(shù)后,通過查閱CULA的xGESVD函數(shù)的文檔可以發(fā)現(xiàn),MATLAB中對角陣返回奇異值,而CULA返回一個向量,MATLAB返回V,而CULA返回V的轉(zhuǎn)置,為了對接MATLAB的接口,必須從奇異值向量轉(zhuǎn)換成一個對角矩陣并轉(zhuǎn)置。至此完成了culaSvd程序,在MATLAB中用MEX命令編譯culaSvd.cpp源文件生成二進(jìn)制mex文件,完成MATLAB中實現(xiàn)在底層調(diào)用經(jīng)CULA加速優(yōu)化后的奇異值分解。
3 實驗結(jié)果及分析
本節(jié)將原有算法與基于CUDA優(yōu)化后的算法進(jìn)行運(yùn)行效果比較,測試是基于拍攝的真實數(shù)據(jù)進(jìn)行的,試驗運(yùn)行環(huán)境配置為:Intel Core i5 M 520 2.40 GHz CPU,4 GB內(nèi)存,Nvidia公司的GT218 GPU,編程環(huán)境為MATLAB R2010a+Visual Studio 2010 +CUDA Toolkit Version 4.0 + CULA R12,選取的視頻是拍攝的學(xué)校路口某個時刻的場景。視頻序列總共為200幀,每幀大小為576 768,由此組成的觀測矩陣為M(27 648×200)。
圖2為選取的第150幀3種算法運(yùn)行效果對比圖。表1為取150幀進(jìn)行前景檢測,兩種算法及其加速改進(jìn)后算法

圖2 第180幀3種算法仿真對比圖
的運(yùn)算時間、迭代次數(shù)、SVD時間及SVD次數(shù)的比較。
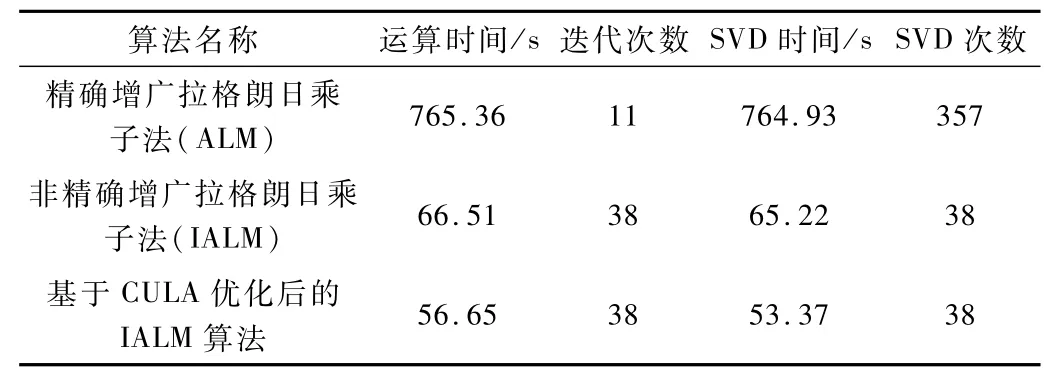
表1 三種算法150幀仿真數(shù)據(jù)的比較
表2為分別取180幀、160幀、140幀、120幀、100幀和80幀進(jìn)行前景檢測,為了得到精確運(yùn)行時間,分別進(jìn)行100次運(yùn)算,然后取平均運(yùn)行時間,計算算法的運(yùn)行時間、平均加速倍數(shù)。對視頻進(jìn)行處理,將其裁剪為不同分辨率的視頻,對其進(jìn)行測試,表3為分別采用不同分辨率進(jìn)行視頻測試時兩種算法的運(yùn)行時間及其加速倍數(shù)。
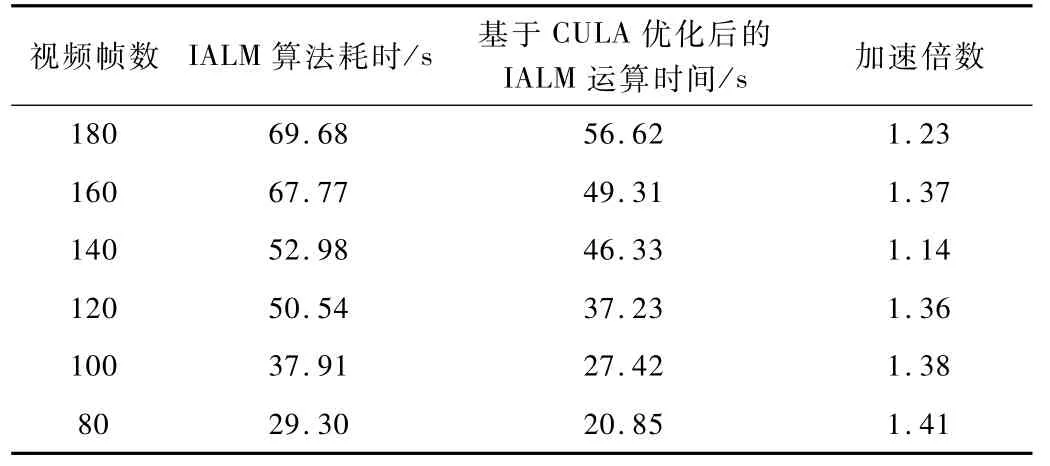
表2 IALM算法與基于CULA優(yōu)化后算法不同視頻幀數(shù)仿真數(shù)據(jù)比較
從仿真效果可以看出,經(jīng)CULA優(yōu)化后的算法分離出的背景A3比其他兩種原有的算法得到的背景A1和背景A2相比,前景目標(biāo)更加分明,前景目標(biāo)檢測效果更好。
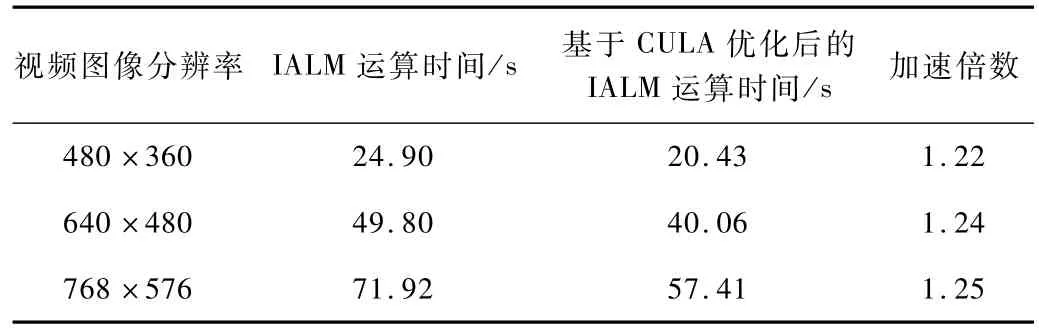
表3 IALM算法與基于CULA優(yōu)化后算法不同分辨率視頻仿真數(shù)據(jù)比較
表1表明,優(yōu)化改進(jìn)后的算法運(yùn)行效率有所提升。表2取不同的視頻幀數(shù)進(jìn)行前景目標(biāo)檢測,表明實現(xiàn)了至少1倍以上加速比。最后表3給出了不同測試視頻的運(yùn)行結(jié)果,表明隨著圖像尺寸的加大,加速比增大。綜合得知,本文的優(yōu)化改進(jìn)算法效率更高。
4 結(jié)論
本文應(yīng)用CULA加速優(yōu)化后的低秩矩陣恢復(fù)算法實現(xiàn)前景目標(biāo)檢測,加速優(yōu)化后的算法與原有算法相比,奇異值分解次數(shù)減少,表明算法里的奇異值分解計算得到加速改進(jìn),因此算法的運(yùn)行時間得以較大幅度縮短。仿真結(jié)果表明,本文加速優(yōu)化后的算法有更好的前景目標(biāo)檢測效率。本文的前景目標(biāo)檢測算法在計算效率上得到改善,發(fā)揮了軟硬件結(jié)合的效果,這種學(xué)習(xí)成本低廉、使用代價較小、運(yùn)行效率較高的優(yōu)點彌補(bǔ)了MATLAB計算速度上的缺點,也使得視覺應(yīng)用的研究有了良好的開端。
參考文獻(xiàn)
[1]CANDES E J,Li Xiaodong,Ma Yi,et al.Robust principalcomponent analysis[J].Journal of the ACM,2009,58(3):233-279.
[2]WRIGHT J,GANESH A,RAO S,et al.Robust principal component analysis:exact recovery of corrupted low-rank matrices via convex optim ization[C].Proceedings of Neural Information Processing Systems(NIPS),2009,87(4):20:3-20:56.
[3]NVIDIA Corporation.NVIDIA CUDA programming guide[Z]. 2009.
[4]Lin Zhouchen,Chen Minming,Ma Yi.The augmented Lagrange multip liermethod for exact recovery of a corrupted low-rank matrix[R].Eprint Arxiv,2010.
[5]GANESH A,Lin Zhouchen,WRIGHT J,et al.Fast algorithms for recovering a corrupted low-rank matrix[C].International Workshop on Computational Advances in Multi-Sensor Adaptive Processing,2009:213-216.
[6]Lin Zhouchen,GANESH A,WRIGHT J,et al.Fast convex optim ization algorithms for exact recovery of a corrupted low-rank matrix[C].Proceedings of Computational Advances in Multi-Sensor Adaptive Processing(CAMSAP),2009.
[7]YUAN X,YANG J.Sparse and low-rank matrix decomposition via alternating direction methods[R].Hong Kong:Hong Kong Baptist University,2009.
[8]Chen M inm ing.Algorithms and implementations ofmatrix reconstruction[D].Beijing:Graduate School Chinese Academy of Science,2010.
[9]EM Photonics Corporation.CULA reference guide[Z].2014.
[10]EM Photonics Corporation.CULA programmers guide[Z]. 2014.
李俊(1992 -),男,碩士研究生,主要研究方向:圖像處理與模式識別。
周薇娜(1982 -),通信作者,女,博士,講師,主要研究方向:圖像處理,集成電路設(shè)計。E-mail:wnzhou@shm tu.edu.cn。
引用格式:李俊,周薇.娜基于低秩矩陣恢復(fù)的目標(biāo)快速檢測方法研究[J].微型機(jī)與應(yīng)用,2016,35(10):75-78.
Fast object detection based on low-rank matrix recovery theory
Li Jun,Zhou Weina
(College of Information Engineering,Shanghai Maritime University,Shanghai201306,China)
Abstract:In order to implement fastmoving object detection,foreground detection is completed by using low-rank matrix recovery algorithm. As the main computation of low-rank matrix recovery algorithm is the singular value decomposition,most of which is time-consuming and complex,a fast and efficient foreground detection method is obtained by applying the compute unified device architecture(CUDA)and its thirdparty library to realize the low-rank matrix recovery optimized algorithm which implements the faster computing of singular value decomposition. We test our algorithm on open source video and compare itwith original low-rank matrix algorithm on various parameters,and the acceleration ratio achievesmore than one times.The experiment result indicates that the optimized algorithm obtains less running time and ismore efficient.
Key w ords:low-rank matrix recovery;foreground detection;compute unified device architecture
作者簡介:
收稿日期:(2016-01-23)
中圖分類號:TP312
文獻(xiàn)標(biāo)識碼:A
DOI:10.19358 /j.issn.1674-7720.2016.09.026
