基于MPI的最小費用流網絡單純形并行算法設計與實驗
2016-05-25 00:37:04吳立新,劉紀平,江錦成
地理與地理信息科學 2016年1期
關鍵詞:進程
吳 立 新,劉 紀 平,江 錦 成
(1.東北大學測繪遙感與數字礦山研究所,遼寧 沈陽 110819;2.中國礦業大學環境與測繪學院,江蘇 徐州 221116;3.中國測繪科學研究院,北京 100830;4.北京師范大學減災與應急管理研究院,北京 100875)
基于MPI的最小費用流網絡單純形并行算法設計與實驗
吳 立 新1,2,劉 紀 平3,江 錦 成4
(1.東北大學測繪遙感與數字礦山研究所,遼寧 沈陽 110819;2.中國礦業大學環境與測繪學院,江蘇 徐州 221116;3.中國測繪科學研究院,北京 100830;4.北京師范大學減災與應急管理研究院,北京 100875)
網絡最小費用流算法常用來解決資源流最優分配問題,傳統的串行算法因時間復雜度高而不能滿足大規模網絡對計算效率的要求。該文用時間復雜度低的網絡單純形算法(NSA)的并行化求解大規模網絡的最小費用流問題。通過分析NSA的可并行性,使用MPI分布式并行技術,設計了NSA并行算法;分析了3種常用流網絡的拓撲結構特征及其與地理網絡的關系;在并行環境下對計算效率進行實驗測試,結果表明該算法具有顯著的加速效果,峰值可達5.4。NSA并行算法應用面寬,可為區域及全國性大規模網絡流資源分配方案的快速制定與政務決策提供有力支持。
網絡最小費用流;并行計算;資源分配;網絡單純形算法(NSA); MPI
0 引言
網絡最小費用流問題旨在將交通網絡上的資源以最小的總代價從供應點運輸至需求點,已被廣泛應用于工業生產、通訊及GIS網絡分析領域,在全國性物流規劃與資源調配中有著重要意義。目前,針對該問題國內外已提出了大量算法,包括消圈算法[1]、連續最短路徑算法[2]、原始單純形算法[3]等,其中,網絡單純形算法(Network Simplex Algorithm,NSA)已發展成為一種求解網絡最小費用流問題的高效算法[4]。盡管NSA的時間效率不錯,但因最小費用流問題本身的復雜性,串行NSA的時間復雜度依然較高。
利用高性能計算環境的硬件資源,并行技術可有效提升計算效率。通常,并行計算分為共享內存和分布內存兩種模式,兩者各有優缺點。目前,已有研究提出多種相關并行算法,如原始-對偶并行算法[5]、ε-松弛并行算法[6]、最小費用整型流并行算法[7]等。單純形并行算法包括:為解決大規模線性規劃問題,Yarmish等提出了基于矩陣列計算的分布式單純形法[8];Ploskas等在共享內存平臺下實現了改進的單純形法并行[9];其他學者則在CPU-GPUs上實現了單純形法并行[10,11]。通常,共享內存并行受限于單機CPU數量,可擴展性差;而在分布內存并行方面,現有并行算法難以在實用中取得滿意的加速效果。
為此,本文分析NSA的粗粒度可并行性,采用MPI (Message Passing Interface) 分布式并行技術對其可并行部分進行并行計算,并避免由消息傳遞引起并行效率低下的缺陷。旨在面向大規模計算機集群,使基于MPI的并行NSA具備高效性和強可擴展性,確保NSA并行算法適用于大規模網絡最小費用流的求解。
1 網絡最小費用流問題
將交通網絡表達為有向圖G(N,A),包含n=|N|個節點和m=|A|條路段。任意路段(i,j)∈A包含代價cij、最大容量uij、最小容量lij和流量fij。對于節點j∈N,賦予屬性bj,表示節點的供需量:bj>0表示供應量,bj<0表示需求量,bj=0表示傳輸節點。最小費用流問題描述如下:
最小化:
z=∑(i,j)∈Acij×fij
(1)
約束條件:
∑(i,j)∈Afij-∑(j,k)∈Afij=bj,for?j∈N
(2)
lij≤fij≤uij,for?(i,j)∈A
(3)
2 網絡單純形算法(NSA)
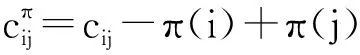
(4)
(5)
若非基態弧不滿足式(4)或式(5),則為不合格弧段。NSA包括兩個階段:1)初始解求解階段:利用網絡最大流算法[12]求得初始可行解;2)優化階段:迭代搜索不合格弧段,并通過消圈計算,將其調整為合格弧段,操作如下:
開始
求解初始最小生成樹T及B(T,L,U);
設定T上所有節點的矢量代價π(i);
若存在不合格弧段,則
選擇不合格弧段(i,j);
添加(i,j)至T,計算舍棄弧段(p,q);
更新T、f和π(i);
結束
3 分布式并行NSA
3.1 可并行性分析
本文根據并行粒度將網絡進行兩個層次分解,并分別并行化,實現兩層次的并行計算。
(1)第一層并行。最小費用流問題是一種特殊形式的網絡最大流,而最小割是最大流問題的對偶問題。根據最大流-最小割原理[12],最小費用流的解決方案中存在一個或多個s-t割,其中s-t割C={S,T}是對節點集合N的剖分,供應點s∈S,需求點t∈T,最小割集合為{(u,v)∈A|u∈S,v∈T}。由于NSA是消圈算法的一種變種形式,最小割集上的弧段都處于飽和狀態,包含割集弧段的所有回路上的最大可增廣量為0,故所有穿越s-t的負值回路都是無效回路。因此,NSA能對S和T消圈計算進行并行化,且無需任何通訊代價。每個s-t割可將網絡分割成兩個獨立子網絡。因各子網絡的解是完全獨立的,所有子網絡最優解的直接組合即為整體網絡的全局最優解,無需合并后重新優化。第一層次的可并行性取決于兩個因素:1)s-t割的數量:數量越多,則分割的子網絡越多,可并行性越高;2)負載均衡度:S和T間的負載越均衡,并行效率越高。
(2)第二層并行。盡管NSA是一個全局優化過程,分治法[13]可將全局優化轉換成局部優化。因NSA最小生成樹T的根節點r的選擇無特定要求,故可在第一層分割的子網絡上分別進一步劃分若干子區;并行構建最小生成樹,對子區進行局部優化;待獲得各子區的局部最優最小生成樹之后,再將其合并,對合并結果執行串行NSA,得到子網絡的全局最優解。理論上,假如某子網絡被分割成多個大小近似的子區,則第二層并行求解的效率會很高。
3.2 基于MPI技術的并行NSA設計
(1)第一層分布式并行。首先,根據最大流-最小割原理將網絡分割成多個子網絡,并在這些子網絡上并行執行NSA,實現第一層分布式并行,步驟如下:1)主進程根據最大流-最小割原理將網絡分割成為多個子網絡,表示為R0,R1,…,Ri,…;2)主進程將子網絡Ri分發至從進程i;3)各從進程i執行NSA,無通訊代價地并行優化子網絡Ri的局部解。
(2)第二層分布式并行化。第二層并行化是采用分治法實現子網絡Ri的局部解的優化,步驟如下:1)進程i將子網絡Ri進一步分割成多個子區Rij,并將子區分發給空閑從進程;2)空閑從進程j在子區Rij上執行串行NSA,獲得Rij的局部最優解;3)進程i回收所有子區Rij及其局部最優解,并將所有子區合并為子網絡Ri,所有子區局部最優解合并為Ri的解;4)進程i在Ri上執行串行NSA,將Ri的解優化為全局最優解。
圖1為基于MPI技術的NSA并行主流程,主要包括3部分:1)網絡預處理:將整個網絡進行兩個層次的分割,第一層根據最大流-最小割原理,將網絡分割成為多個子網絡,第二層遵循負載均衡原理將得到的子網絡進一步分割成多個子區,并將子區數據分發至各從進程;2)子區并行求解:各從進程獨立、并行地對各子區執行串行NSA,得到所有子區的局部最優解;3)子區解合并再優化:主進程收集所有從進程的子區及其局部最優解結果,合并后執行串行NSA進行再優化,得到子網絡及其全局最優解,然后將各子網絡的最優解寫入同一結果文件,即為整體網絡的全局最優解。
4 并行NSA實驗測試
4.1 實驗設計
本實驗采用3種廣泛應用于網絡流算法測試的經典拓撲網絡[14]:Goto網絡包含2 000個節點和317 000條邊;Gridgen網絡包含10 000個節點和1 240 000條邊;Netgen網絡包含5 000個節點以及40 000條邊。這些網絡是1991年在Rutgers大學舉辦的第一次DIMACS會議上公布的[14]。其中,Gridgen隨機網絡生成器由Lee[15]用C語言編寫,該生成器產生格網狀的網絡和一個超級節點,其拓撲結構與城市交通網絡相近(如北京市交通網絡),生成器參數如圖2所示。
Netgen網絡生成器用以產生網絡最小費用流問題實例[16],可用于研究任務指派等交通網絡問題[17],其生成器參數如圖3。Goto(Grid on Torus)網絡有意產生特殊而困難的實例[18],如其名所言,其基本網絡結構為網狀多環,與城市道路網絡相匹配。每個Goto網絡供應點和需求點間的供需量取決于弧段容量[19],參數描述如圖4。
實驗測試環境為兩臺圖形工作站(2.00 GHz的CPU,32核,48 GB內存)、64位Windows 7操作系統。代碼設計采用C語言,使用GCC編譯器編譯,使用O2優化。串行算法和并行算法同在此環境下進行測試對比。相對于串行算法,并行算法的加速比speedup=ts/tp,其中ts和tp分別為串行和并行算法的計算耗時。
4.2 實驗結果與討論
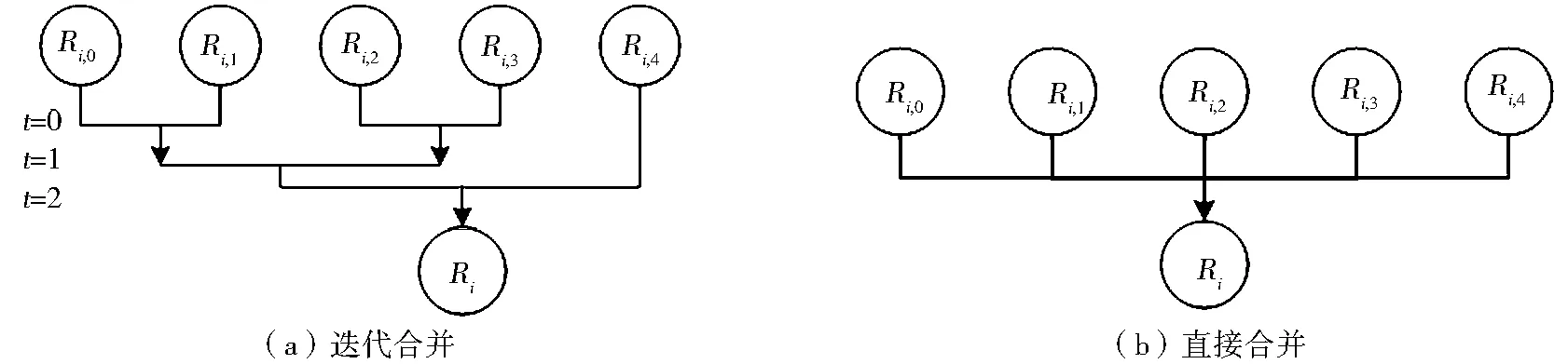
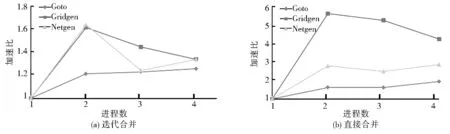
為更好地測試本文并行算法的適應性,針對第二層分布式并行中第三步的子區合并問題,本實驗采用兩種合并策略進行比較:迭代合并策略和直接合并策略(圖5)。迭代合并策略為:在任意迭代次數t時,第2j 圖1 基于MPI的并行NSA流程 圖4 Goto隨機網絡生成器參數 Fig.1 The flowchart of MPI-based parallel NSA Fig.4 Input parameters of Goto network generator(https://lemon.cs.elte.hu/trac/lemon/wiki/MinCostFlowData) 圖5 子區合并策略 Fig.5 Two strategies of merging sub-regions 不同合并策略得到不同的并行效率(圖6)。在Gridgen和Netgen網絡中,兩種合并策略均在兩個進程時取得最大加速比。顯然,對比于串行算法,多個進程的計算效率始終大于單進程,迭代合并策略的最大加速比為1.6;直接合并策略的最大加速比可達5.4。然而,進程數越多,由此引發的通訊代價也越高。與Gridgen和Netgen網絡不同的是,并行NSA在Goto網絡中,兩個進程取得較好加速比之后,隨進程增加,時間效率并未立即下降,而是保持平穩或者持續輕微地增加。總之,針對以上3種網絡,并行NSA的加速比都比較明顯。通常,網絡流算法為全局優化過程,各操作之間的關聯較大,并行難度較高;但是,本文算法的并行效果明顯,可達到預期目標。 圖6b中出現了超線性加速比。當進程數為2時,理論上最大加速比不應超過2,實際上卻達到了5.4。這是因為,串行算法最小生成樹T中的弧段及節點集合的總數比并行算法最小生成樹子集中的多得多,若并行算法迭代次數總和并未遠超串行算法的迭代次數,就可能出現超線性加速比。 圖6 并行NSA加速比 Fig.6 The speedups of parallel NSA 本文基于MPI分布式并行技術,提出了網絡并行NSA。在3種經典流網絡上的測試結果表明,并行NSA相比于串行NSA的加速效果明顯,峰值可達5.4。并行NSA中的迭代合并與直接合并策略具有不同的加速效果,在Gridgen和Netgen網絡中兩者均在兩個進程時取得最佳加速比;而在Goto網絡中,4個進程的加速效果較兩個進程還有少量增加。總體而言,直接合并策略的加速效果比迭代合并策略明顯,且出現了“超線性”加速比現象。 本文提出的并行NSA有效解決了大規模網絡最小費用流的高效求解問題,可為國家政務、交通、軍事及應急GIS大規模網絡中的最優流資源分配方案制定提供關鍵技術與決策支持;提出的兩種并行策略及其加速效果,也可為其他網絡流算法的并行化設計提供參考。 [1] GOLDBERG A V,TARJAN R E.Finding minimum-cost circulations by canceling negative cycles[J].Journal of the ACM,1989,36(4):873-886. [2] GOLDBERG A V,TARJAN R E.Solving minimum cost flow problem by successive approximation[A].Proceedings of the Nineteenth Annual ACM Symposium on Theory of Computing[C].ACM,1987(7)-18. [3] GOLDFARB D,HAO J X.A primal simplex algorithm that solves the maximum flow problem in at mostnmpivots and O(n2m) time[J].Mathematical Programming,1990,47(1-3):353-365. [4] ORLIN J B.A polynomial time primal network simplex algorithm for minimum cost flows[J].Mathematical Programming,1997,78(2):109-129. [5] BERTSEKAS D P,CASTANON D A.Parallel primal-dual methods for the minimum cost flow problem[J]. Computational Optimization and Applications,1993,2(4):317-336. [6] BERALDI P,GUERRIERO F.A parallel asynchronous implementation of the ε-relaxation method for the linear minimum cost flow problem[J].Parallel Computing,1997,23(8):1021-1044. [7] ANDRZEJ L,MIA P.A fast parallel algorithm for minimum-cost small integral flows[A].Euro-Par Parallel Processing[C].Springer Berlin Heidelberg,2012.688-699. [8] YARMISH G,SLYKE R.A distributed,scaleable simplex method[J].The Journal of Supercomputing,2009,49(3):373-381. [9] PLOSKAS N,SAMARAS N,MARGARITIS K.A parallel implementation of the revised simplex algorithm using OpenMP:Some preliminary results[A].Optimization Theory,Decision Making,and Operational Research Applications[C].Springer Proceedings in Mathematics & Statistics,2013,31:163-175. [10] LALAMI M E,BOYER V,EL-BAZ D.Efficient implementation of the simplex method on a CPU-GPU system[A].Proc.of the 2011 IEEE Int.Symposium on Parallel and Distributed Processing Workshops and PhD Forum[C].Washington DC,2011.1999-2006. [11] BIELING J,PESCHLOW P,MARTINI P.An efficient GPU implementation of the revised simplex method[A].Proc.of the 24th IEEE Int.Parallel and Distributed Processing Symposium[C].2010.1-8. [12] GOLDBERG A V,TARJAN R E.A new approach to the maximum flow problem[J].Journal of the ACM,1988,35(4):921-940. [13] CORMEN T H,et al.Introduction to Algorithms[M].Cambridge:MIT Press,2001. [14] BADICS T,BOROS E,CEPEK O.Implementing a new maximum flow algorithm[A].JOHNSON D S,MCGEOCH C C.Network Flows and Matching:1st DIMACS Implementation Challenge,DIMACS Series in Discrete Mathematics and Theoretical Computer Science[C].American Math.Society,1993. [15] LEE Y.Computational Analysis of Network Optimization Algorithms[D].M.I.T,1993. [16] KLINGMAN D,NAPIER A,STUTZ J.NETGEN:A program for generating large scale capacitated assignment,transportation,and minimum cost flow networks[J].Management Science,1974,20(5):814-821. [17] GEORGIOS G.A Dual Network Exterior Point Simplex-Type Algorithm for the Minimum Cost Network Flow Problem[D].Geranis,Georgios,2012. [18] GOLDBERG A V,KHARITONOV M.On implementing scaling push-relabel algorithms for the minimum-cost flow problem[A].DIMACS Series in Discrete Mathematics and Theoretical Computer Science[C].1993,12:157-198. [19] KOVCS P.Minimum-cost flow algorithms:An experimental evaluation[J].Optimization Methods and Software,2015,30(1):94-127. Design and Experiment on MPI-Based Parallel Network Simplex Algorithm for Network Minimum-Cost Flow WU Li-xin1,2,LIU Ji-ping3,JIANG Jin-cheng4 (1.Institute of Geo-informatics & Digital Mine,Northeastern University,Shenyang 110819;2.School of Environment Science & Spatial Information,China University of Mining and Technology,Xuzhou 221116;3.Chinese Academy of Surveying & Mapping,Beijing 100830;4.Academy of Disaster Reduction and Emergency Management,Beijing Normal University,Beijing 100875,China) Network minimum-cost flow algorithms are usually used to solve optimal flow resource allocation problems.However,the traditional sequential algorithm is not efficient enough to satisfy the requirement of computing performance in large-scale network due to its high time-complexity.With the rapid development of computer technology,parallel computing is becoming an effective way of solving the computational bottleneck.This paper utilizes the relatively low time-complexity network simplex algorithm (NSA) to solve the network minimum-cost flow problem,and designs the parallel computing process of NSA.Analyzing to the parallelizability of NSA,distributed parallel NSA using MPI (Message Passing Interface) technology is designed for high-performance computing platform.The topological structures of three types of classical flow networks are discussed and referred to that of geographical networks.Experimental tests on the three classical flow networks demonstrate that the proposed parallel NSA displays notable acceleration effect,and the maximum speedup reaches 5.4.The proposed parallel NSA provides powerful support for rapid solution of large network resource allocation and decision making on national affairs at regional or national scale. network minimum-cost flow;parallel computing;resource allocation;network simplex algorithm(NSA);MPI 2015-09-25 國家863計劃項目(2011AA20302);測繪地理信息公益性行業科研專項經費項目(201512032) 吳立新(1966-),男,教授,博導,長江學者特聘教授,國家杰出青年基金獲得者,主要研究方向為:空間信息理論與算法、災害遙感與協同觀測。E-mail:awulixin@263.net 10.3969/j.issn.1672-0504.2016.01.001 P208;TP301.6 A 1672-0504(2016)01-0001-05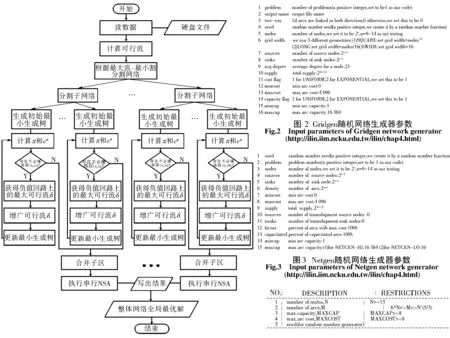
5 結論
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58
中國外匯(2019年8期)2019-07-13 06:01:06
電腦愛好者(2018年15期)2018-08-23 17:24:06
民主與科學(2014年3期)2014-02-28 11:23:03
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
電腦迷(2012年24期)2012-04-29 00:44:03
中華女子學院學報(2012年6期)2012-03-25 13:52:27
俄羅斯問題研究(2012年1期)2012-03-25 09:54:45
杭州師范大學學報(社會科學版)(2011年3期)2011-04-04 08:58:20
