某廣電單位大數(shù)據(jù)平臺(tái)架構(gòu)設(shè)計(jì)
2016-05-14 11:20:05孟蓮蓉
科技資訊 2016年7期
孟蓮蓉

摘 要:某局的大數(shù)據(jù)平臺(tái)架構(gòu)設(shè)計(jì)中,共有12個(gè)組件。計(jì)算框架采用Lambda架構(gòu),同時(shí)管理實(shí)時(shí)計(jì)算框架和離線計(jì)算框架,數(shù)據(jù)經(jīng)過數(shù)據(jù)采集服務(wù)初步驗(yàn)證過濾,記錄到消息隊(duì)列Kafka中,之后,同時(shí)進(jìn)入到Hadoop和storm中分別用于離線和實(shí)時(shí)計(jì)算。
關(guān)鍵詞:大數(shù)據(jù)平臺(tái) 離線計(jì)算 Hadoop 實(shí)時(shí)計(jì)算 Storm Kafka Mongodb
中圖分類號(hào):TP27 文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):1672-3791(2016)03(a)-0006-03
某局期望實(shí)現(xiàn)設(shè)備運(yùn)行數(shù)據(jù)、業(yè)務(wù)管理數(shù)據(jù)和各業(yè)務(wù)系統(tǒng)數(shù)據(jù)的規(guī)范傳送、標(biāo)準(zhǔn)化整理和存儲(chǔ),建立全局統(tǒng)一的數(shù)據(jù)關(guān)系明確的主題數(shù)據(jù)庫或數(shù)據(jù)倉庫,為全局各應(yīng)用系統(tǒng)提供規(guī)范的數(shù)據(jù)交換服務(wù)以及對(duì)基礎(chǔ)數(shù)據(jù)的管理。主要任務(wù)是:建立全局?jǐn)?shù)據(jù)中心,基于大數(shù)據(jù)云平臺(tái)和兩級(jí)數(shù)據(jù)交換中心,實(shí)現(xiàn)各級(jí)業(yè)務(wù)系統(tǒng)基礎(chǔ)數(shù)據(jù)的統(tǒng)一規(guī)范化管理;初步實(shí)現(xiàn)全局設(shè)備及其狀態(tài)以及運(yùn)行質(zhì)量、趨勢(shì)、故障等的可視化分析建模及展示。該文主要闡述平臺(tái)的架構(gòu)設(shè)計(jì)。
1 大數(shù)據(jù)平臺(tái)架構(gòu)
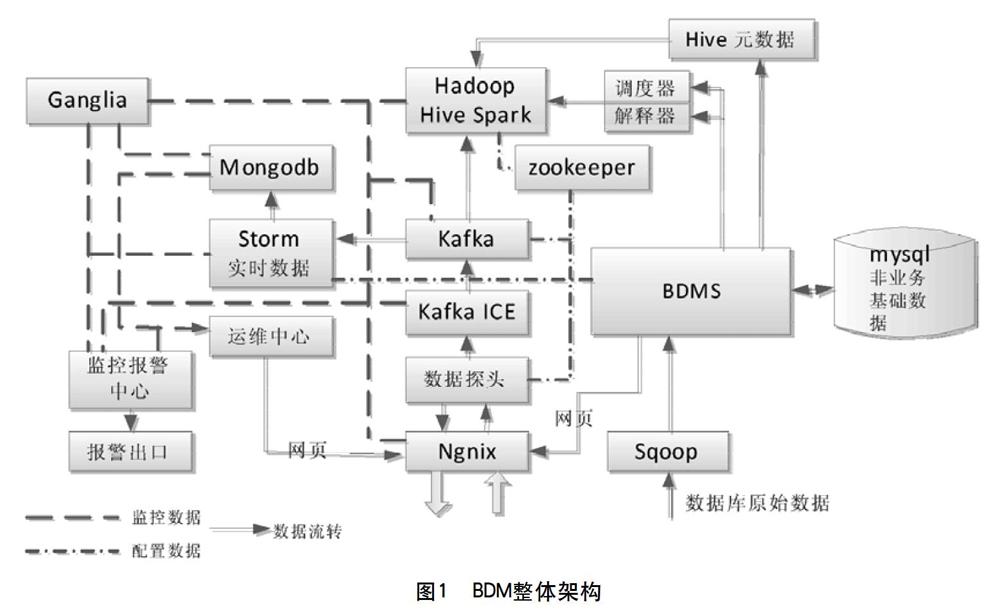
BDM(Big Data Management,大數(shù)據(jù)管理平臺(tái))整體架構(gòu)由下向上,從底層硬件逐步構(gòu)建。
(1)硬件設(shè)施層:提供最基礎(chǔ)的硬件系統(tǒng)。
(2)虛擬化層:在硬件設(shè)施層之上,將硬件資源虛擬化,將服務(wù)器集群資源統(tǒng)籌管理。
(3)數(shù)據(jù)存儲(chǔ)層:完成海量數(shù)據(jù)的分布式存儲(chǔ)。提供數(shù)據(jù)備份和容災(zāi),采用Hadoop框架的HDFS分布式存儲(chǔ)引擎、分布式消息隊(duì)列Kafka、分布式文檔型內(nèi)存數(shù)據(jù)庫和關(guān)系型數(shù)據(jù)庫。
(4)數(shù)據(jù)服務(wù)層:包括,數(shù)據(jù)裝載讀寫、數(shù)據(jù)分析處理編程框架和數(shù)據(jù)查詢等。數(shù)據(jù)處理工具完成服務(wù)層與數(shù)據(jù)存儲(chǔ)層間的數(shù)據(jù)交互,提供友好的數(shù)據(jù)操作界面。
(5)數(shù)據(jù)接口層:對(duì)外提供操作的相關(guān)接口。
2 BDM組件關(guān)系
圖1為該局BDM的整體架構(gòu),采用SOA(Service-Oriented Architecture)架構(gòu),其將具體功能以服務(wù)的形式部署在服務(wù)器集群上,每個(gè)服務(wù)以分布式方式部署,提供單獨(dú)的高可用的服務(wù),平臺(tái)中的各系統(tǒng)都可以任意訪問服務(wù)。BDM平臺(tái)支持結(jié)構(gòu)化數(shù)據(jù)(數(shù)據(jù)庫表、結(jié)構(gòu)化文本)、半結(jié)構(gòu)化數(shù)據(jù)和非結(jié)構(gòu)化數(shù)據(jù)。
數(shù)據(jù)經(jīng)由Kafka寫入到Hadoop HDFS,永久存儲(chǔ),進(jìn)行離線計(jì)算;經(jīng)由Kafka到達(dá)Storm流計(jì)算平臺(tái),進(jìn)行實(shí)時(shí)計(jì)算和處理。
2.1 Nginx
Nginx是一個(gè)高性能的HTTP和反向代理服務(wù)器,是BDM中統(tǒng)一的HTTP請(qǐng)求的轉(zhuǎn)發(fā)入口,需兩臺(tái)服務(wù)器集群互為備份和負(fù)載均衡。它接收用戶的HTTP接口調(diào)用瀏覽器訪問,將請(qǐng)求轉(zhuǎn)發(fā)到OMCenter網(wǎng)頁、BDMS網(wǎng)頁、數(shù)據(jù)查詢、REST接口和數(shù)據(jù)探頭等。
2.2 分布式集群協(xié)作管理Zookeeper
Zookeeper是集群協(xié)作管理中心,提供集群協(xié)調(diào)功能,保存集群運(yùn)行狀態(tài)和配置信息并同步到集群各個(gè)系統(tǒng),組件包括:數(shù)據(jù)采集服務(wù)、Storm、 Hadoop和Kafka等。Zookeeper作為集群的配置中心,在多臺(tái)zookeeper服務(wù)器之間,保證數(shù)據(jù)強(qiáng)一致性,實(shí)現(xiàn)了Paxos算法,完成數(shù)據(jù)在節(jié)點(diǎn)之間存儲(chǔ)一致的狀態(tài),在部署zookeeper集群的時(shí)候,一般使用3臺(tái)集群或5臺(tái)集群。 Zookeeper在部署完成后即擁有高容錯(cuò)功能,一個(gè)zookeeper節(jié)點(diǎn)故障,并不影響整體集群的服務(wù)功能,這個(gè)節(jié)點(diǎn)重啟就可以恢復(fù)數(shù)據(jù),并恢復(fù)正常狀態(tài)。集群協(xié)作管理的方式有如下幾種。
(1)在zookeeper中保存集群中每個(gè)服務(wù)器地址及其提供的對(duì)應(yīng)服務(wù)。
(2)客戶端從zookeeper中獲取集群中提供服務(wù)的具體實(shí)例地址和具體服務(wù)通信。
(3)集群狀態(tài)發(fā)生變化時(shí),更新zookeeper內(nèi)容,即時(shí)通知客戶端。
(4) zookeeper保存并分析服務(wù)的運(yùn)行狀態(tài),發(fā)送監(jiān)控信息和報(bào)警信息。
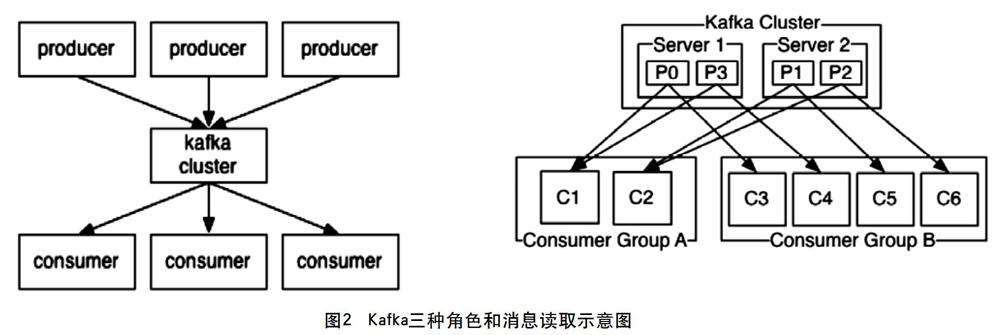
2.3 Kafka
Kafka集群有三種角色(如圖2):Producer是數(shù)據(jù)的發(fā)布者,向消息隊(duì)列推送數(shù)據(jù);Consumer是數(shù)據(jù)的訂閱者,從消息隊(duì)列訂閱數(shù)據(jù)并消費(fèi);Broker是消息隊(duì)列實(shí)體和集群中的Server。Kafka指定各個(gè)分區(qū)到對(duì)應(yīng)的讀取進(jìn)程,因此保證每個(gè)進(jìn)程讀取數(shù)據(jù)的順序性和負(fù)載均衡。
Kafka消息讀取的方式如圖2。它可以同時(shí)處理多個(gè)邏輯隊(duì)列,每個(gè)隊(duì)列用一個(gè)Topic名稱進(jìn)行唯一標(biāo)識(shí),即一個(gè)Topic確定一個(gè)邏輯隊(duì)列。每個(gè)邏輯隊(duì)列分成多個(gè)分區(qū)(Partition),圖中為Kafka Cluster的P0~P2,每個(gè)分區(qū)分散存儲(chǔ)于服務(wù)器上,數(shù)據(jù)寫入kafka時(shí),輪詢寫入每個(gè)分區(qū)。數(shù)據(jù)的消費(fèi)者,分多組(Consumer Group)同時(shí)讀取數(shù)據(jù),每組都可讀取到隊(duì)列中完整的數(shù)據(jù),兩組之間不會(huì)相互影響。
2.4 Kafka ICE服務(wù)
ICE(Internet Communications Engine),是一個(gè)分布式計(jì)算框架和RPC框架,方便各服務(wù)讀寫kafka數(shù)據(jù)。ICE Grid服務(wù)端包含Registry,Registry Replica,Node和服務(wù):
(1)Registry:ICE Grid的服務(wù)注冊(cè)中心、配置中心,其中保存了所有節(jié)點(diǎn)狀態(tài)、服務(wù)狀態(tài)、服務(wù)地址和端口及服務(wù)RPC API的元數(shù)據(jù)等。
(2)Registry Replica是Registry的熱備服務(wù)。
(3)Node:ICE Grid通過Node服務(wù)管理節(jié)點(diǎn)上運(yùn)行的服務(wù)的啟停,一個(gè)服務(wù)可注冊(cè)在一個(gè)或多個(gè)節(jié)點(diǎn)運(yùn)行,服務(wù)進(jìn)程通過Node進(jìn)程創(chuàng)建。
(4)服務(wù):通過ICE Grid框架定義。在BDM中,數(shù)據(jù)探頭和Kafka ICE都是通過ICE實(shí)現(xiàn)的。一個(gè)節(jié)點(diǎn)可啟動(dòng)多個(gè)服務(wù)進(jìn)程,每個(gè)服務(wù)進(jìn)程可以配置成多線程方式。
(5)客戶端:客戶端通過服務(wù)定義的slice文件,通過RPC的方式和服務(wù)端通信,完成API調(diào)用。Registry根據(jù)一定的規(guī)則,將服務(wù)地址分配給客戶端,分配策略有輪詢、隨機(jī)和根據(jù)負(fù)載分配的方式。
2.5 數(shù)據(jù)探頭
數(shù)據(jù)探頭服務(wù)采集和接收推送數(shù)據(jù),并發(fā)送到Kafka,數(shù)據(jù)經(jīng)過Nginx,uwsgi,Input ICE,Kafka ICE到達(dá)Kafka。Input ICE服務(wù)提供了動(dòng)態(tài)API配置的功能。
2.6 Mysql
Mysql作為BDMS的后臺(tái)數(shù)據(jù)庫,也作為基礎(chǔ)數(shù)據(jù)管理和關(guān)系型數(shù)據(jù)庫部分?jǐn)?shù)據(jù)的存儲(chǔ)。 BDM中Mysql集群,使用主備方式部署(Master-Slave),備機(jī)提供數(shù)據(jù)的只讀服務(wù),主機(jī)提供數(shù)據(jù)的讀寫服務(wù)。
2.7 Storm
Storm是BDM中的實(shí)時(shí)處理平臺(tái),完成實(shí)時(shí)統(tǒng)計(jì)、計(jì)算和數(shù)據(jù)處理等。Storm集群分為主控節(jié)點(diǎn)Nimbus和工作節(jié)點(diǎn)Supervisor,Nimbus負(fù)責(zé)任務(wù)的總控,管理所有工作節(jié)點(diǎn)的狀態(tài);Supervisor負(fù)責(zé)接受并執(zhí)行任務(wù)。
Storm會(huì)保證數(shù)據(jù)在計(jì)算任務(wù)中都被處理過一次(至少一次),如果處理發(fā)生異常,這條數(shù)據(jù)會(huì)被重新發(fā)送,保證每條數(shù)據(jù)都會(huì)被正確處理。Storm在記錄消息處理情況的時(shí)候,只有數(shù)據(jù)完全經(jīng)過所有節(jié)點(diǎn)的時(shí)候,數(shù)據(jù)才會(huì)被認(rèn)為正常處理完成。該項(xiàng)目中,可使用Storm完成實(shí)時(shí)指標(biāo)計(jì)算,如,全局設(shè)備實(shí)時(shí)運(yùn)行時(shí)長(zhǎng)統(tǒng)計(jì)、設(shè)備實(shí)時(shí)狀態(tài)分析等。
2.8 分布式文檔型數(shù)據(jù)庫Mongodb
Mongodb是文檔對(duì)象數(shù)據(jù)庫,是一種NoSQL數(shù)據(jù)庫,每一條數(shù)據(jù)是一個(gè)“文檔”,一個(gè)文檔是一個(gè)json格式的數(shù)據(jù),由于json格式數(shù)據(jù)的特點(diǎn),Mongodb沒有關(guān)系型數(shù)據(jù)庫的外鍵和關(guān)聯(lián)等概念,對(duì)于有嵌套關(guān)系的數(shù)據(jù),可以直接存儲(chǔ)到一條記錄中。Mongodb支持集群部署方式和自動(dòng)故障恢復(fù)。Mongodb高可用部署方式為Replica Set(副本集),其中Primary為主節(jié)點(diǎn),數(shù)據(jù)的讀寫操作都在Primary上執(zhí)行,兩個(gè)Secondary服務(wù)器從Primary同步數(shù)據(jù)并作為熱備,這3個(gè)節(jié)點(diǎn)之間通過心跳信號(hào)通信,確認(rèn)彼此服務(wù)處于存活狀態(tài)。
當(dāng)Primary出現(xiàn)故障時(shí),主的心跳信號(hào)丟失,此時(shí),兩個(gè)Secondary節(jié)點(diǎn)中的一個(gè)節(jié)點(diǎn)作為Primary,客戶端和新的Primary節(jié)點(diǎn)進(jìn)行操作。故障節(jié)點(diǎn)恢復(fù)后,重新加入集群,并作為新的備節(jié)點(diǎn),開始數(shù)據(jù)同步。
在BDM中,Storm從Kafka讀取實(shí)時(shí)采集的數(shù)據(jù),完成計(jì)算后,將計(jì)算結(jié)果輸出到Mongodb存儲(chǔ),使用方讀取Mongodb結(jié)果獲取實(shí)時(shí)計(jì)算報(bào)表。
2.9 BDMS大數(shù)據(jù)建模平臺(tái)
BDMS大數(shù)據(jù)建模平臺(tái)是基于Hadoop、Hive、sqoop等hadoop生態(tài)系統(tǒng)中的工具整合開發(fā)的可視化大數(shù)據(jù)離線計(jì)算、數(shù)據(jù)分析和建模平臺(tái)。基礎(chǔ)的Hadoop平臺(tái)提供HDFS分布式數(shù)據(jù)存儲(chǔ)和MapReduce計(jì)算框架,使得大量數(shù)據(jù)的分布式計(jì)算成為可能。存儲(chǔ)文件分成多個(gè)Block(塊),默認(rèn)大小是64M。通過塊的Replica的方式,保證數(shù)據(jù)可靠性,讀取速度和吞吐量。一般每個(gè)塊至少分布到3個(gè)DataNode節(jié)點(diǎn)上。如圖3,NameNode負(fù)責(zé)維護(hù)集群的元數(shù)據(jù),DataNode用來存放數(shù)據(jù)塊,每個(gè)數(shù)據(jù)塊都有3個(gè)備份,分散存儲(chǔ)于各個(gè)DataNode上,任意一個(gè)DataNode故障,數(shù)據(jù)塊的副本不會(huì)丟失;同時(shí),為防止NameNode單點(diǎn)故障,引入了Secondary NameNode的備份節(jié)點(diǎn)。Hadoop HDFS上的數(shù)據(jù)讀寫,始終都采用就近原則,優(yōu)先使用本地的數(shù)據(jù)塊,以提升數(shù)據(jù)讀取的速度。
Hadoop平臺(tái)為BDMS提供基礎(chǔ)的數(shù)據(jù)存儲(chǔ)和計(jì)算框架,單純MapReduce框架應(yīng)用復(fù)雜,因此Hive平臺(tái)提供了結(jié)構(gòu)化數(shù)據(jù)的管理和查詢功能。Hive使用類SQL語言,完成對(duì)Hadoop上存儲(chǔ)的數(shù)據(jù)進(jìn)行查詢。Hive將SQL語言解析成為MapReduce任務(wù)在Hadoop平臺(tái)上執(zhí)行,更適合于海量數(shù)據(jù)的SQL查詢。BDMS還提供了Hadoop平臺(tái)上的其它功能,如,SparkMLL機(jī)器學(xué)習(xí)庫,sqoop數(shù)據(jù)裝載工具等,為數(shù)據(jù)的采集、清洗、格式化、查詢、建模、計(jì)算、分析、報(bào)表產(chǎn)出等一系列流程提供可視化工作界面。
2.10 集群監(jiān)控中心ganglia
Ganglia是BDM的服務(wù)器集群監(jiān)控中心,它收集每個(gè)節(jié)點(diǎn)的服務(wù)器運(yùn)行狀態(tài)和服務(wù)運(yùn)行狀態(tài),完成運(yùn)行狀態(tài)的實(shí)時(shí)監(jiān)控圖標(biāo)繪制,圖標(biāo)的數(shù)據(jù)保存為rrd格式,可在使用較小磁盤容量的情況下,記錄多年的歷史數(shù)據(jù)。
3 結(jié)語
除了上述的各個(gè)組件,大數(shù)據(jù)平臺(tái)還配備報(bào)警中心和運(yùn)維管理中心,報(bào)警中心完成對(duì)BDM中關(guān)鍵服務(wù)組件運(yùn)行狀態(tài)的監(jiān)控報(bào)警和對(duì)數(shù)據(jù)處理任務(wù)的監(jiān)控報(bào)警;運(yùn)維中心OMCenter為BDM提供一站式私有云管理軟件、集成設(shè)備管理、服務(wù)管理、監(jiān)控、實(shí)時(shí)報(bào)表和配置中心等。目前,BDM已經(jīng)運(yùn)行了一年左右,體現(xiàn)了其應(yīng)有的作用。
參考文獻(xiàn)
[1] 張戈.淺談廣電網(wǎng)絡(luò)的信息化建設(shè)[J].科技致富向?qū)В?014(26):80,172.
[2] 任磊,杜一,馬帥,等.大數(shù)據(jù)可視分析綜述[J].軟件學(xué)報(bào),2014(9):1909-1936.
