利用深度置信網絡的中文短信分類
2016-05-14 09:17:15王貴新鄭孝宗張浩然張小川
現代電子技術 2016年9期
關鍵詞:深度學習
王貴新 鄭孝宗 張浩然 張小川

摘 要: 為了提高垃圾短信的過濾效果,通過對中文短信內容和結構特點分析,提出了一種充分利用word2vec工具將短信內容轉化為固定長度向量的特征提取算法。同時設計了深度置信網絡進行學習和分類,實驗表明其推廣性能比已有報道結果提高了5%左右。
關鍵詞: 深度置信網絡; 深度學習; 受限波爾茲曼機; 短信
中圖分類號: TN911?34; TP391 文獻標識碼: A 文章編號: 1004?373X(2016)09?0037?04
Abstract: To improve the filtering effect of spam SMS, a feature extraction algorithm is proposed to convert SMS content into fixed length vector with word2vec tool by the analysis of Chinese SMS content and structure characteristics. The deep belief nets (DBN) were designed to learn and classify. The experimental results show that the generalization performance is increased by about 5% in comparison with the reported results.
Keywords: deep belief net; deep learning; restricted Boltzmann machine; SMS
0 引 言
每年移動運營商和國家都花費了大量的人力和物力進行垃圾短信治理,但公眾還是不滿意治理效果。目前移動運營商主要采用軟件過濾加人工干預的治理方式[1?3]。軟件過濾的算法原理主要有3類:有監督學習、無監督學習和半監督學習。單純的有監督學習[4?10]和無監督學習[11?12]在垃圾短信過濾過程中的效果還是值得肯定的[4?10],但這些學習和過濾算法目前已經不能適應于市場和機器學習環境,特別是深度學習算法理論的完善和應用發展為機器學習提供了廣闊空間[13]。
由于沒有公開的短信素材可以得到,利用以前所做項目收集的大約有300萬條短信作為實驗樣本,該樣本沒有主、被叫號碼、短信時間等涉及個人隱私的信息。本文首先提出充分利用word2vec工具,將短信內容轉化為固定長度向量的特征提取算法;然后設計了適合短信過濾的深度置信網絡對樣本進行學習和分類。實驗效果表明本文的方法是可行的,這為漢字內容分類提供了一種途徑。
1 短信內容向量化
按照有關規定,需要把短信內容分為: 敏感政治信息、黃色信息、商業廣告信息、違法犯罪信息、詐騙信息、正常信息等6大類(本文分別用zp,ss,sy,sh,sp,qt字母組合表示類名)。分類結果除了正常信息外,其余信息需要過濾和提交不同部門處理。將短信表示成為向量的過程主要需要三個步驟:短信預處理,短信分詞,向量化。
1.1 預處理
預處理主要包括非正規字詞替換(不妨稱為短信內容的正規化過程)。比如:“公$$司*開發@PIAO,酒折優惠,歡迎撥打:I39XXXXXXXX”。短信需要根據系統的諧音庫、拼音庫、繁體庫等標準進行內容轉換。同時剔除內容里面不相關的符號。結果這條短信就是“公司開發票,9折優惠,歡迎撥打:139XXXXXXXX”。
假設所有的短信集合記為[S,]記正規化過程對應的函數為[f1,]經過正規化處理的短信集合記為[G,]上面的過程可表達為:[?s∈S,f1(s)∈G。]
1.2 分詞
本文采用中國科學院計算技術研究所ICTCLAS系統(網址:ictclas.nlpir.org)分詞。在分詞后,如果內容包含有數字,需要按照下面要求處理:
價格數字、電話或聯系號碼數字、商品數字、日期時間數字、其他數字等數字內容分別用AA,BB,CC,DD,NN替換。比如:“公司開發票,9折優惠,歡迎撥打:139XXXXXXXX”,分詞的結果應該是:“公司 開 發票 AA折 優惠 歡迎 撥打 BB”。
1.3 向量化
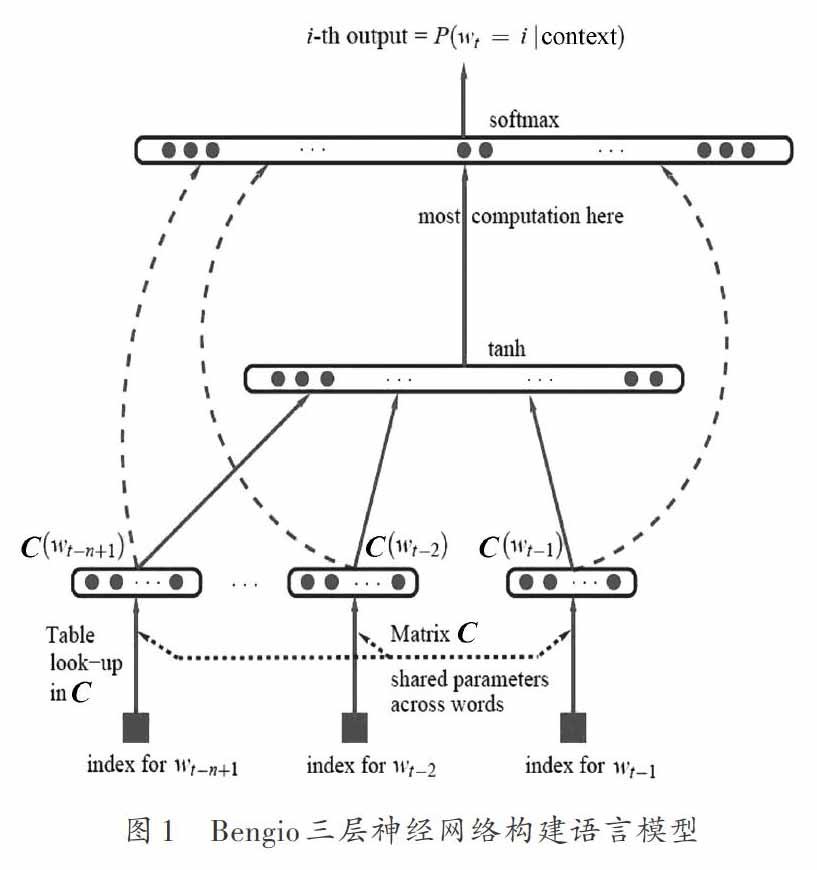
谷歌推出了將詞語轉換成詞向量的工具word2vec (https://code.google.com/p/word2vec/)。工具的主要原理是Bengio模型[14]的一個改進和應用,Bengio模型主要理論是:設句子[S]依次由一系列關鍵詞[w1,w2,…,wt]組成, [wi]向量化的過程如圖1所示。
短信內容向量化算法過程描述如下:
(1) 每類按照一定比例取出大約21 280個訓練樣本。然后將每個短信正規化。
(2) 按照1.2節中的方法把正規化的短信進行分詞(每個詞語之間空格分隔),并形成如下的7個文本文件:rubbish.txt,所有樣本的分詞文件;zp.txt,ss.txt,sy.txt,sh.txt,sp.txt,qt.txt分別是敏感政治信息、黃色信息、商業廣告信息、違法犯罪信息、詐騙信息、正常信息等6大類訓練樣本對應的分詞文件。
(3) 對rubbish.txt,zp.txt,ss.txt,sy.txt,sh.txt,sp.txt,qt.txt,分別執行word2vec指令(格式:word2vec ?train 分詞文件名 ?output 向量化結果文件名 ?cbow 0 ?size 5 ?window 10 ?negative 0 ?hs 1 ?sample 1e?3 ?threads 2 ?binary 0),分別得到向量化結果文件rubbish.out,zp.out,ss.out,sy.out,sh.out,sp.out,qt.out。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
