基于節(jié)點聚集系數的分布式標簽傳播算法
2016-05-09 07:07:32張素智孫嘉彬
計算機應用與軟件 2016年4期
張素智 孫嘉彬 王 威
基于節(jié)點聚集系數的分布式標簽傳播算法
張素智 孫嘉彬 王 威
(鄭州輕工業(yè)學院計算機與通信工程學院 河南 鄭州 450002)
隨著互聯網的發(fā)展和普及,越來越多的用戶加入到社交網絡,逐漸形成了大規(guī)模、多樣化的社區(qū)。對于新浪微博等社交服務來說,這些社區(qū)的發(fā)現可以為用戶和商家提供有價值的信息。在社區(qū)發(fā)現算法中,標簽傳播算法(LPA算法)具有算法思想簡單、復雜度低、無需初始化社區(qū)數量等優(yōu)點,但準確率較低,同時在大數據環(huán)境下,效率還不夠高。將節(jié)點聚類系數引入LPA的標簽更新過程中,提出一種結合MapReduce分布式計算框架的社區(qū)發(fā)現算法——DisLPA算法。實驗表明,該算法不僅提高了準確率,同時有效改善了計算瓶頸問題。
社區(qū)發(fā)現 標簽傳播 聚集系數 MapReduce
0 引 言
近年來,隨著Web2.0的逐漸興起,社交網絡(SNS)的使用變得越來越普遍,越來越多的人利用SNS擴展個人交際圈,同時發(fā)布、查找和共享信息,吸引更多的人去關注熱點信息。新浪發(fā)布的2012年第三季度財報顯示,截止到2012年12月底,新浪微博注冊用戶數已超5億,平均每天活躍用戶達到4620萬。這些用戶發(fā)布文字、圖片、視頻,轉發(fā)微博,搜索信息,關注其他人等等都會產生大量的數據,這對數據分析帶來了巨大的挑戰(zhàn),這個挑戰(zhàn)[1]不僅是數據量膨脹的問題,而且涉及到數據深度分析需求的增長。
對SNS社區(qū)進行挖掘,可以發(fā)現網絡社區(qū)中的潛在的社區(qū)結構,從而對用戶角色進行評估,擴展社交圈,以實現高效準確的個性化推薦,同時能夠提供精準的商業(yè)定位,為商家?guī)砀蟮纳虣C。但是在線網絡社區(qū)數據具有龐大性、稀疏性、流動性,這些特性使得社交網絡尤為復雜。目前,不同領域的眾多研究者對復雜網絡的基本統計特性做了很多研究,如小世界效應[2](具有短路徑長度和高聚類系數特點),無標度特性[3](節(jié)點度服從冪函數分布),聚類特性[4](同社區(qū)內節(jié)點連接較為緊密)。
目前的社區(qū)挖掘大致分為基于優(yōu)化的方法和基于啟發(fā)式的方法[5]兩種。局部搜索方法和譜方法是基于優(yōu)化的方法中兩類最主要的方法。在基于優(yōu)化的方法中,典型的有譜平分算法,GA(Guimera-Amaral)算法,FN(Fast Newman)算法等,它們都是將復雜網絡的問題轉化為優(yōu)化目標函數來計算復雜網絡的社區(qū)結構。基于啟發(fā)式方法的共同特點是:在優(yōu)化目標不明確的前提下,設計和運用合理的啟發(fā)式規(guī)則來識別網絡社區(qū),如GN(Girvan-Newman)算法、MFC算法、HITS算法、CPM算法等。
為了改善社區(qū)發(fā)現算法復雜度高的問題,Raghavan等人提出了一種啟發(fā)式的,基于標簽傳播的社區(qū)發(fā)現算法(LPA)[6],具有近似線性的時間復雜度,目前在眾多的社區(qū)發(fā)現算法中效率最高。
很多學者對標簽傳播算法進行了改進和優(yōu)化。利用特征空間嵌入實現數據點的稀疏重構能反映數據點與特征空間嵌入間的本質相似性結構的特點,陶劍文等人[7]提出了一種稀疏近似最近特征空間嵌入標簽傳播的方法,使得預測的數據標簽具有平滑性和魯棒性。王庚等人[8]提出了一種基于標簽傳播的穩(wěn)定重疊社區(qū)挖掘算法(soCLP),該方法引入平衡因子對算法的穩(wěn)定性進行控制,以解決重疊社區(qū)挖掘中效率與穩(wěn)定性的沖突。
但是由于現如今激增的SNS用戶和這些用戶產生的大數據,傳統的LPA算法來分析那些具有龐大節(jié)點數的社區(qū)效率較低,只靠單一的計算結點無法滿足這樣的計算需求,此時就需要多個并行的結點來進行處理。
為了解決因節(jié)點數增加等問題引起的挖掘算法效率低下的問題,趙雅端等人[9]將傳統Newman算法并行化,并應用在GPU并行計算中,使得傳統的社區(qū)挖掘算法在不失準確性的前提下運行效率有了提高。宋玨等人[10]提出了一種基于日志聚類的郵件網絡社區(qū)挖掘算法LENCM,該算法在維持執(zhí)行效率的基礎下提高了挖掘社區(qū)的質量。
本文提出了一種基于MapReduce的分布式LPA社區(qū)發(fā)現算法——DisLPA,在提高準確率的基礎上,有效改善了計算瓶頸問題。
1 相關工作
1.1 LPA算法
標簽傳播算法(LPA)的思想是根據已標記節(jié)點的標簽信息去預測未標記節(jié)點的標簽。它是由Zhu等人[11]率先提出的一種基于圖的半監(jiān)督學習方法。2007年Raghavan等人[6]根據標簽傳播的思想,提出了基于標簽傳播思想的社區(qū)發(fā)現算法。算法基本思想:一個節(jié)點x,它的k個鄰居節(jié)點分別為x1,x2,…,xk,每個鄰居節(jié)點對應的label為l1,l2,…,lk,這些鄰居節(jié)點共同決定了x所在的社區(qū)。該算法流程為:
(1) 首先初始化節(jié)點label,將每個節(jié)點賦予一個唯一的label,此label代表社區(qū)標識,即初始化之后每個節(jié)點自身為一個社區(qū)。
(2) 以迭代的方式更新圖中所有的節(jié)點。迭代規(guī)則為:節(jié)點x的所有鄰居節(jié)點x1,x2,…,xk中,對應的label為l1,l2,…,lk出現次數最多的那個label傳遞給節(jié)點x。當出現num[max(l1,l2,…,lk)]≥2的情況時,將任意一個節(jié)點的label作為x的label。
(3) 反復執(zhí)行步驟(2),直到每個節(jié)點的label都不再變化或者達到最大迭代次數為止。
(4) 若兩個節(jié)點具有相同的label,那么認為這兩個節(jié)點在同一個社區(qū)。
節(jié)點標簽值更新步驟如圖1所示。
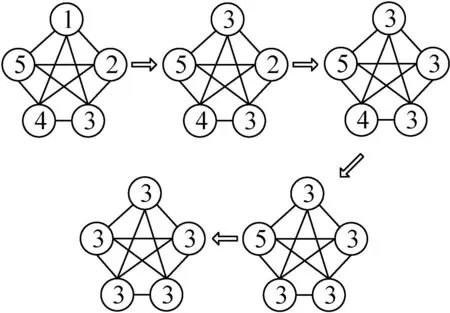
圖1 節(jié)點label更新步驟
如圖1所示,節(jié)點label的傳遞是一個迭代的過程,每一次迭代,節(jié)點的label就會根據其鄰居節(jié)點的label進行更新。這個更新的過程分為同步更新和異步更新兩種。
在同步更新中,節(jié)點x在第t次迭代的label值lx取決于其鄰居節(jié)點在第t-1次迭代使所得的label,即:
lx(t)=f(lx1(t-1),…,lxk(t-1))
其中,lx(t)表示節(jié)點x在第t次迭代時label,f函數的返回值是在x的鄰居節(jié)點的label里出現次數最高的那個label。然而在同步更新過程中可能會出現圖2中的無限迭代的情形,從而無法得到社區(qū)結構。
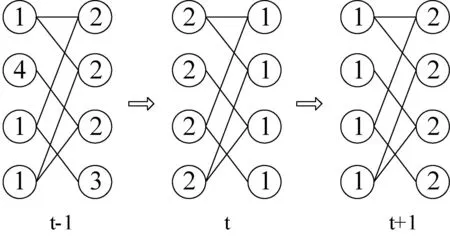
圖2 同步更新震蕩情況
在異步更新中,節(jié)點在第t次迭代時的label不僅僅取決于第t次迭代更新過的label,同時和剩下未進入t次迭代的鄰居節(jié)點在t-1次迭代的label有關,即lx(t)=f(lxi1(t),…,lxin(t),lxi(n+1)(t-1),…,lxk(t-1))其中xi1,…,xin表示在t次(本次)迭代中更新過label的節(jié)點,xi(n+1),…,xik表示在本次迭代中還沒有更新的節(jié)點,f同上。
近年來,有研究人員不斷地對LPA社區(qū)挖掘算法進行了改進和優(yōu)化。Leung等人[12]使用LPA算法來分析大規(guī)模在線網絡,其實驗預示了標簽傳播算法是一種快速有效的社區(qū)發(fā)現算法,在處理超大規(guī)模復雜網絡方面潛力巨大。Barber等人[13]為了避免所有的節(jié)點都分配到一個社區(qū),設計了一個帶約束條件的標簽傳播算法LPAm,將社區(qū)發(fā)現算法轉化為目標函數優(yōu)化的問題,但是該算法會有陷入局部最大值的趨勢,這會導致社區(qū)發(fā)現不準確。針對這個問題,Liu等人[14]將LPAm與多步層次貪婪算法MSG(Multi-step Greedy Agglomerative Algorithm)相結合,提出了一個模塊化,分層化的標簽傳播算法LPAm+,使LPA類算法的性能得到進一步改善。
1.2 MapReduce計算模型
MapReduce是由Google公司最早提出的,它是一種用于海量數據計算(大于1T)的并行運算模型,最初被Google應用于Google搜索引擎的服務器集群中[15],實時進行龐大的搜索數據計算。Map和Reduce兩個程序構成了MapReduce的整體架構,其中Map程序將input的數據切分成各類型的小塊,并分配給大量的服務器處理;Reduce程序將Map處理后的結果匯總整理后輸出給客戶端[16]。MapReduce的執(zhí)行流程如圖3所示。
在編程的時候,需要編寫Map和Reduce這兩個主要函數[17]。
Map:
Reduce:
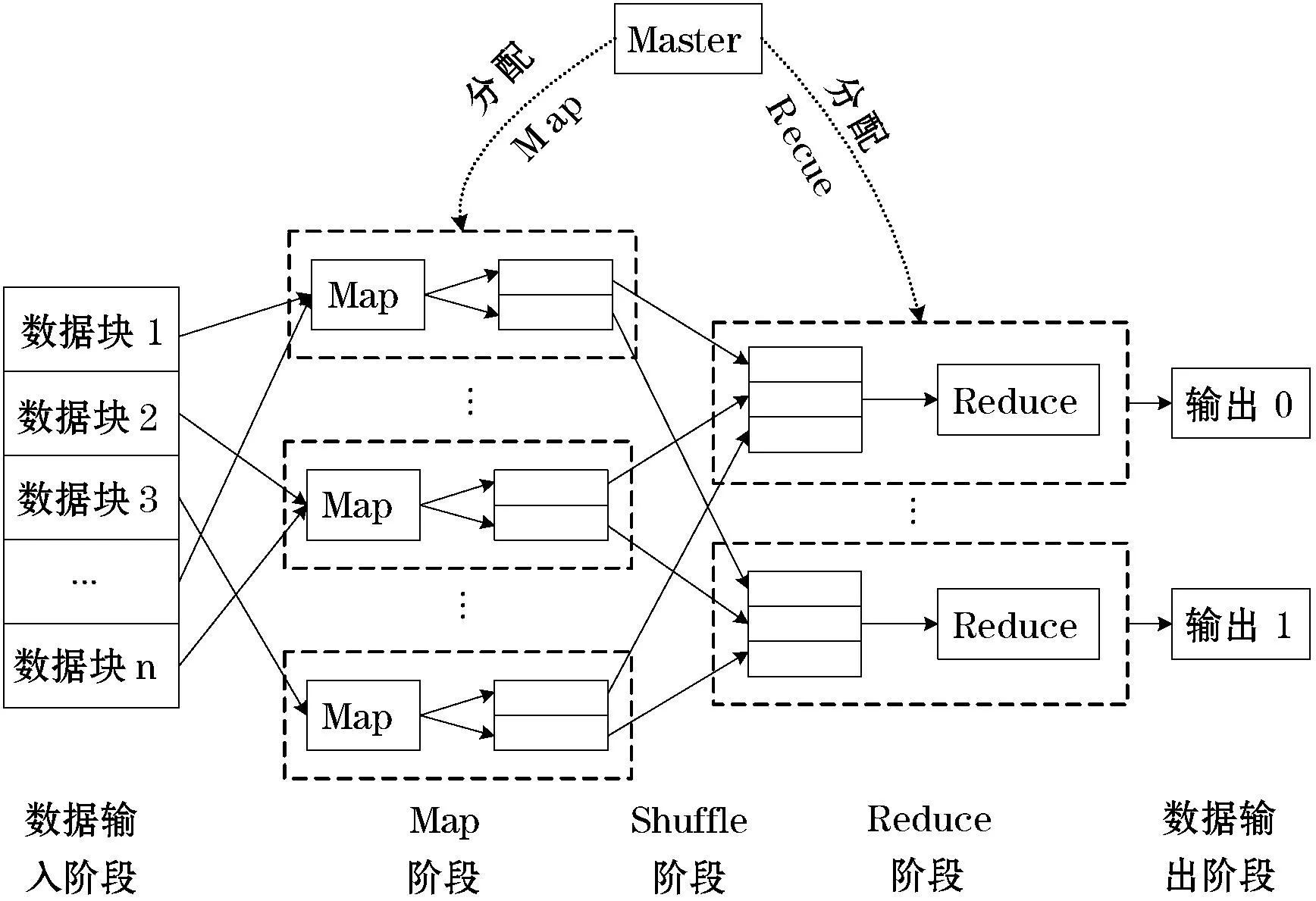
圖3 MapReduce執(zhí)行流程
MapReduce可以充分發(fā)揮普通計算機集群的計算能力,以解決單一普通計算機由于處理器以及存儲資源的限制而無法高效處理海量數據計算的問題。
2 基于LPA的分布式社區(qū)發(fā)現算法
2.1 基本思想
本文采用MapReduce分布式編程模型來設計分布式LPA算法——DisLPA,從而解決計算的瓶頸問題。
該算法編程模型分為三個階段[18]:
(1) 從輸入文件讀取的元數據轉化成
(2) 所有輸入數據的
(3) 其中每個key和他所有關聯的value值[u1,…,us]傳遞給reduce函數(某一Hadoop節(jié)點上的)調用,用來創(chuàng)建一個輸出的key-value鍵值對[(m1,x1),…,(mt,xt)](reduce階段,見(2))。整個過程中,輸出的key值不需要匹配輸入的key,它們不必是相同的。
2.2 算法步驟
在標簽傳播算法中,通常將網絡抽象為一個簡單的無向圖G(V,E),其中V表示節(jié)點(或頂點Vertex)的集合,E表示邊(Edge)的集合,同時,集合中的每一條邊都與集合V中的一對節(jié)點相對應。|V|表示圖的階,即節(jié)點集合中節(jié)點的個數,|E|表示圖的邊數,即邊集合中邊的條數。節(jié)點的鄰居節(jié)點集合Ni(j)可以表示為:
Ni(j)={j:j∈V,(i,j)∈E}
第一次更新節(jié)點label時,每個label都是唯一的,更新的原則是在鄰居節(jié)點中隨機選擇一個節(jié)點進行更新,在第一次更新后,大約90%的節(jié)點會劃分到最終所屬的社區(qū)。因此,第一次節(jié)點label更新時的選擇會直接影響最終的社區(qū)劃分結果。這極大地降低了算法的魯棒性,同時影響了社區(qū)劃分的準確性。
為了解決這一問題,本文對每個label增加權值,用節(jié)點聚集系數:
(1)
來衡量節(jié)點的影響力,n表示在節(jié)點i的所有k個鄰居間的邊數。將加入了節(jié)點聚集系數的標簽傳播算法記為CLPA算法。
LPA算法的每一次迭代,要執(zhí)行更新頂點label的操作。對于每個分區(qū),我們需要運行幾個帶來大開銷的map-reduce進程,因此我們將所有的分區(qū)并行計算,來取代將整體進行計算的方式。
算法DisLPA的具體步驟如下:
(1) 首先,初始化。DisLPA為每個頂點i分配一個唯一的label,將label初始化為頂點的id,即初始化不同的label,即li=i,此處,i表示節(jié)點i的id。將迭代次數初始化為p=1。
(2) Map進程:將節(jié)點id賦值給map進程的key,將二元組(lj,j)傳遞給map進程的value,其中l(wèi)j表示節(jié)點j的標簽值,j表示對應id節(jié)點的鄰居節(jié)點和其標簽值。輸出list(l,n),n是對應標簽值l的所有鄰居的數量。
(3) Reduce進程:輸入list(l,n),得到n值最大對應的label,根據(1)中節(jié)點聚集系數Ci,由式(2)更新每個頂點i的label,并賦給節(jié)點i:
(2)
其中,δ是克羅內克符號,滿足:
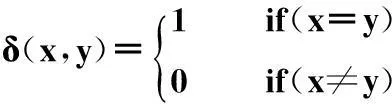
(4) 上一步Reduce輸出的結果作為下一個Map的輸入。重復步驟(2)-(3),直到所有的節(jié)點不再發(fā)生變化為止。
DisLPA算法的偽代碼如下:
Input:G(V,E),p=1,Ci=1,li=i;
If all vertex not change do
{ p=p+1;
Map(key1,value1)
{
key1←all vertex id;
value1←(lj,j);
//j∈Ni(j),l∈L;
for(each nerghborID in N of i)do
(lj,1);
key2←lj;
value2←Cj·l;
Output(key2,value2);
}
Reduce(key2,value2)
{
key3←nerghborID m of vertex I;
value3←(lm,m);
Output(key3,value3);
}
else
end
}
該算法不僅改進了傳統LPA算法不穩(wěn)定的特點,同時極大地提高了算法執(zhí)行的效率。
3 實驗及分析
該實驗分別選取基準數據和實際數據進行對比分析。基準數據采用單機模式進行實驗分析算法的準確性,實際數據采用集群模式分析算法的高效性。
3.1 實驗環(huán)境
在Linux下建立Hadoop集群環(huán)境,該集群中配備了4個節(jié)點,每個節(jié)點的處理器為Alienware Auroa ALX(ALWAD-02)、6 GB、硬盤1500 GB。其中1個節(jié)點作為Namenode和Jobtracker,其余3個節(jié)點負責具體的計算任務。
3.2 基準網絡
實驗選取兩個經典的基準數據,分別為Zachary’s karate club數據集[19]和Dolphin社會關系網[20],使用基于節(jié)點聚集系數的LPA算法(CLPA)來分析。
對比表1結果可以看出,CLPA準確率高于LPA,證明了其可行性。

表1 LPA和CLPA準確率對比
3.3 實際網絡
本文通過調用新浪微博官方的API來獲取微博數據,用來比較DisPLA算法和單機分析的CLPA算法以及傳統LPA算法的性能。
社區(qū)質量的評價采用量化指標模塊化度量,是由Newman和Girvan提出[21]的,至今為止比較權威的衡量指標。定義為:
其中,M為網絡社區(qū)數目;表示邊兩端都在社區(qū)s中的邊數;Os表示邊一端在社區(qū)s中的邊數;E表示網絡中邊總數。
算法由于牽涉到多次迭代,在處理小規(guī)模數據的時候,其運行時間是可以接受的,但是面對較大規(guī)模的數據,算法的處理能力明顯下降,幸運地是,算法的并行化版本減緩了這一下降趨勢,使得算法能夠在有限的時間內處理大規(guī)模數據。
LPA,CLPA,DisLPA算法模塊度和運行時間對比結果如表2所示。
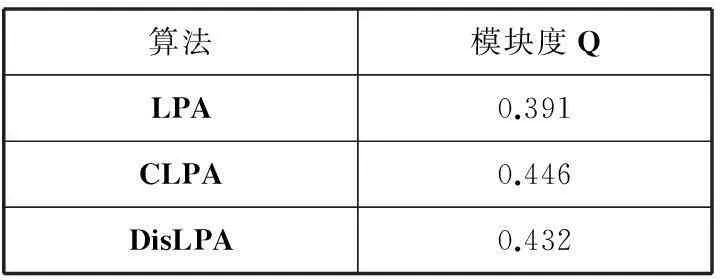
表2 微博數據實驗結果
從表1、表2和圖4的對比結果可以看出,與傳統的LPA算法相比,CLPA算法能夠較準確地發(fā)現社區(qū)結構,同時,隨著網絡節(jié)點數的增加,CLPA算法的擴展——DisLPA算法減少了時間上的開銷,提高了發(fā)現社區(qū)的效率。
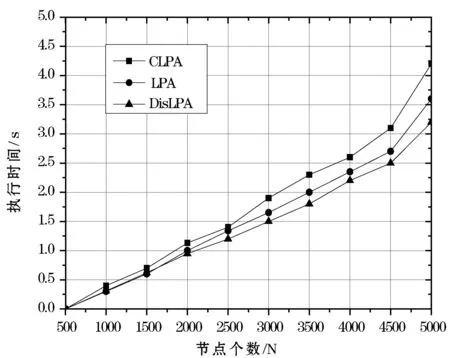
圖4 執(zhí)行時間隨節(jié)點數的變化情況
4 結 語
本文在節(jié)點聚集系數的概念基礎上,提出了一種改進的標簽傳播算法CLPA,同時對CLPA算法并行化處理得到了DisLPA算法,并在Hadoop集群中運行,實驗結果證明了,CLPA算法不僅繼承了LPA算法優(yōu)點,而且提高了LPA算法的精度,但時間消耗上略大于傳統LPA算法。而DisLPA算法不僅提高了準確率,同時有效地減少了運行時間,提高了效率。
但是我們提出的CLPA和DisLPA算法未考慮社區(qū)重疊的問題,在未來的研究中將考慮社區(qū)的重疊性,并對現有算法進行相應的改進和應用。
[1] 覃雄派,王會舉,杜小勇,等. 大數據分析——RDBMS與MapReduce的競爭與共生[J]. 軟件學報,2012,23(1):32-45.
[2] Watts D J,Strogatz S H. Collective dynamics of ‘small-world’networks[J]. nature,1998,393(6684):440-442.
[3] Adamic L A,Huberman B A. Power-law distribution of the world wide web[J]. Science,2000,287(5461):2115-2115.
[4] Girvan M,Newman M E J. Community structure in social and biological networks[J]. Proceedings of the National Academy of Sciences of the United States of America,2002,99(12):7821-7826.
[5] 劉大有,金弟,何東曉,等. 復雜網絡社區(qū)挖掘綜述[J]. 計算機研究與發(fā)展,2013,50(10):2140-2154.
[6] Raghavan U N,Albert R,Kumara S. Near linear time algorithm to detect community structures in large-scale networks[J]. Physical Review E,2007,76(3):036106.
[7] 陶劍文,FLC,王士同,等. 稀疏近似最近特征空間嵌入標簽傳播[J]. 軟件學報,2014,25(6):1239-1254.
[8] 王庚,宋傳超,盛玉曉,等. 基于標簽傳播的穩(wěn)定重疊社區(qū)挖掘算法研究[J]. 山東科學,2013,26(5):61-68.
[9] 趙雅端,盧罡,趙瑩,等. 基于GPU的復雜網絡社區(qū)挖掘算法并行計算[J]. 計算機應用研究,2013,30(8):2426-2428.
[10] 宋鈺,何小利. 一種基于日志聚類郵件網絡社區(qū)劃分挖掘算法[J]. 科技通報,2014,30(2):96-98.
[11] Zhu X,Ghahramani Z. Learning from labeled and unlabeled data with label propagation[R]. Technical Report CMU-CALD-02-107,Carnegie Mellon University,2002.
[12] Leung I X,Hui P,Lio P,et al. Towards real-time community detection in large networks[J]. Physical Review E,2009,79(6):066107.
[13] Barber M J,Clark J W. Detecting network communities by propagating labels under constraints[J]. Physical Review E,2009,80(2):026129.
[14] Liu X,Murata T. Advanced modularity-specialized label propagation algorithm for detecting communities in networks[J]. Physica A: Statistical Mechanics and its Applications,2010,389(7):1493-1500.
[15] Dean J,Ghemawat S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM,2008,51(1):107-113.
[16] 楊文志. 云計算技術指南: 應用,平臺與架構[M]. 北京: 化學工業(yè)出版社,2010.
[17] 劉鵬. 云計算[M].2版. 北京:電子工業(yè)出版社,2011.
[18] 曾大聃,周傲英. Hadoop 權威指南中文版[M]. 北京: 清華大學出版社,2010.
[19] Zachary W. An Information Flow Modelfor Conflict and Fission in Small Groups1[J]. Journal of anthropological research,1977,33(4):452-473.
[20] Lusseau D,Schneider K,Boisseau O J,et al. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations[J]. Behavioral Ecology and Sociobiology,2003,54(4):396-405.
[21] Newman M E J,Girvan M. Finding and evaluating community structure in networks[J]. Physical Review E,2004,69(2):026113.
DISTRIBUTED LABEL PROPAGATION ALGORITHM BASED ON NODES CLUSTERING COEFFICIENT
Zhang Suzhi Sun Jiabin Wang Wei
(SchoolofComputerandCommunicationEngineering,ZhengzhouUniversityofLightMdustry,Zhengzhou450002,Henan,China)
Along with the development and popularity of Internet,more and more users join in social networks,and this gradually forms the large-scale and diverse communities. For social networking services such as Sina microblogging,the detection of these communicates can offer valuable information to users and merchants. Among numerous community detection algorithms,the label propagation algorithm (LPA) has the advantages of simple algorithm idea,low complexity,and no need in initialising the numbers of community,etc. However,its accuracy is rather lower,and meanwhile its efficiency is not high enough in the environment of big data. We proposed a community detection algorithm,which combines MapReduce distributed computation framework,by introducing nodes clustering coefficient into the process of LPA label update,we call it DisLPA. Experiment showed that the algorithm not only improved the accuracy,but also effectively solved the bottleneck problem of calculation.
Community detection Label propagation Clustering coefficient MapReduce
2014-09-10。國家自然科學基金項目(61201447)。張素智,教授,主研領域:Web數據庫,分布式計算和異構系統集成。孫嘉彬,碩士生。王威,碩士生。
TP301.6
A
10.3969/j.issn.1000-386x.2016.04.030
