基于MPI的GPU集群并行通信系統實現
2016-05-09 07:07:32侯景德陳慶奎趙海燕
計算機應用與軟件 2016年4期
關鍵詞:進程
侯景德 陳慶奎,2 趙海燕
基于MPI的GPU集群并行通信系統實現
侯景德1陳慶奎1,2趙海燕1
1(上海理工大學光電信息與計算機工程學院 上海 200093)
2(上海市現代光學系統重點實驗室 上海 200093)
針對GPU和MPI混合編程本身的復雜性問題,提出基于MPI的GPU并行通信系統:動態管道緩沖池體系(Pipe Dynamic Buffer Pool)。描述PDBP的主要部件、體系結構和實現過程,定義通信協議。該系統采用動態管道池和動態緩沖池技術,對MPI并行通信進行擴展,為CUDA程序員提供簡易高效的通信編程接口。實驗表明,PDBP具有較高的并行通信效率,特別是在多對多通信模式下,通信效率提高了近9倍。
MPI 動態管道池 動態緩沖池 通信協議 PDBP
0 引 言
近年來,3D、物聯網技術、移動互聯網技術、4G等應用逐步展開。這些新技術的廣泛應用帶來了海量信息處理問題以及如何提高大規模實時支持能力的新挑戰。
GPU集群具有大規模并行多核結構、多線程浮點運算的高吞吐量及使用大型片上緩存顯著減少大量數據移動的時間[1-3]。GPU集群比傳統CPU集群具有更好的成本效益[4-6],不僅在速度性能上有巨大飛躍,而且顯著降低空間、能源以及冷卻的要求[7-10]。總之,GPU集群為應對這些新挑戰帶來了新的曙光。
然而,GPU集群并行編程并未出現一個標準通信模型,絕大多數集群應用采取CUDA與MPI混合編程的方法[11,12]。CUDA具有獨立編譯系統,無法和MPI編譯系統融合[13,14],因而開發二者混合系統為CUDA程序員帶來了困難。需要了解GPU硬件架構和MPI消息傳遞機制,顯式控制內存與顯存、節點與節點間的數據傳輸[15]。因此,對CUDA編程人員來說,GPU集群并行編程仍是一個復雜問題。
為了解決上述問題,本文提出基于MPI的GPU集群并行通信系統PDBP的實現。該系統構建動態管道池和動態緩沖池來實現各類進程、線程之間的通信通道,定義PDBP內各個模塊間交互的通信協議,以實現消息的高效傳輸,并且向外提供統一的通信函數接口。CUDA程序員在進行GPU和MPI混合編程時,無需了解MPI通信細節,只需調用相應通信函數,便可以進行并行GPU程序開發。使CUDA程序員從MPI編程的繁瑣細節中解放出來,更加關注于上層業務算法的設計,顯著改善GPU和MPI混合編程的效率。同時,由于動態緩沖池機制對MPI的擴展,極大地提高了MPI并發多數據流通信的效率。
1 GPU集群并行通信系統框架
集群通信環境CCE(Cluster Communication Environment)為四元組CCE
廣義進程為四元組GP
廣義進程類似于通常意義上的進程,不同之處主要是,每個GP都配備有兩個管道和兩個線程。一個管道用于向其他GP發送數據,另一個管道用于接收其它GP發來的數據,與兩個管道相對應的有寫管道線程(WRPThread)和讀管道的線程(RDPThread)。按照是否與流處理器相關來劃分,廣義進程又被分為正常廣義進程NGP(Normal Generalized Process)和流處理計算廣義進程SGP(Stream Generalized Process)。流處理計算廣義進程是涉及到流處理計算設備和開發環境(如CUDA、CTM)的進程,而NGP則為只涉及CPU環境運行的進程。
2 PDBP模型
管道動態緩沖池模型為五元組PDBP
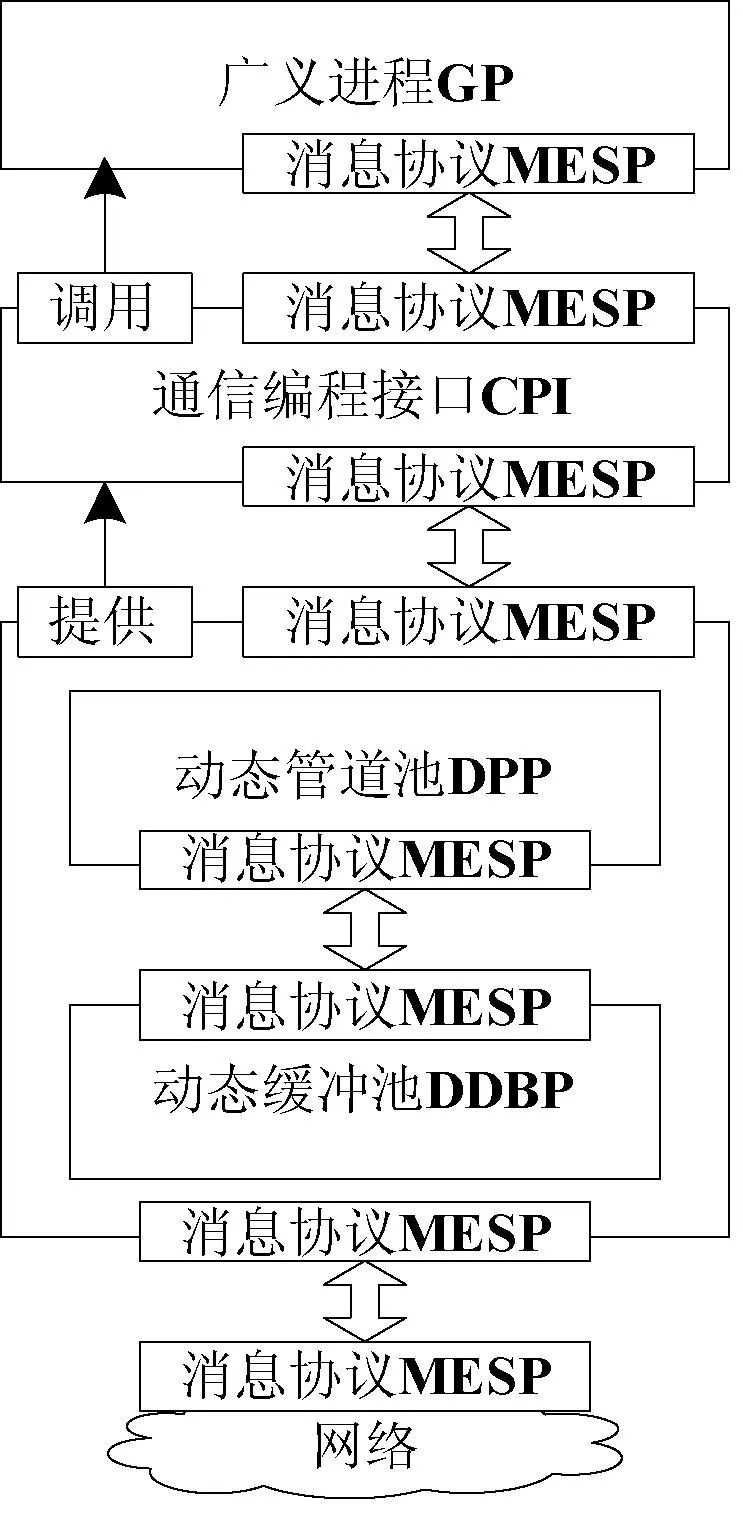
圖1 PDBP總體結構圖
2.1 動態管道池模型
這里所說的管道是一個單項流動的數據流通道,類似于UNIX操作系統中的管道。
動態管道池DPP是進程NGP之間、進程SGP之間以及進程NGP與進程SGP之間的通信的通道。它隱藏了進程NGP和SGP的差異性,對收發的消息分別進行統一封裝。
動態管道池模型為五元組DPP
如果為每個GP都分配一個PriPipe,并且在其生命周期內一直獨占此管道,顯然會增大系統資源的開銷和降低資源的利用率。因此GP與PriPipe采用動態綁定的方式。當一個GP需要進行與其他GP進行通信時,GP向“管道管理器”PM申請綁定一個PriPipe,PM查看“管道資源表”Pipe-Tab,將“管道池”PP中的某個處于“空閑”的管道分配給GP,并更新“管道進程綁定表” GP-Pipe-Bind-Tab;當GP通信結束后需釋放其分配的PriPipe,歸還到PP中。DPP結構如圖2所示。
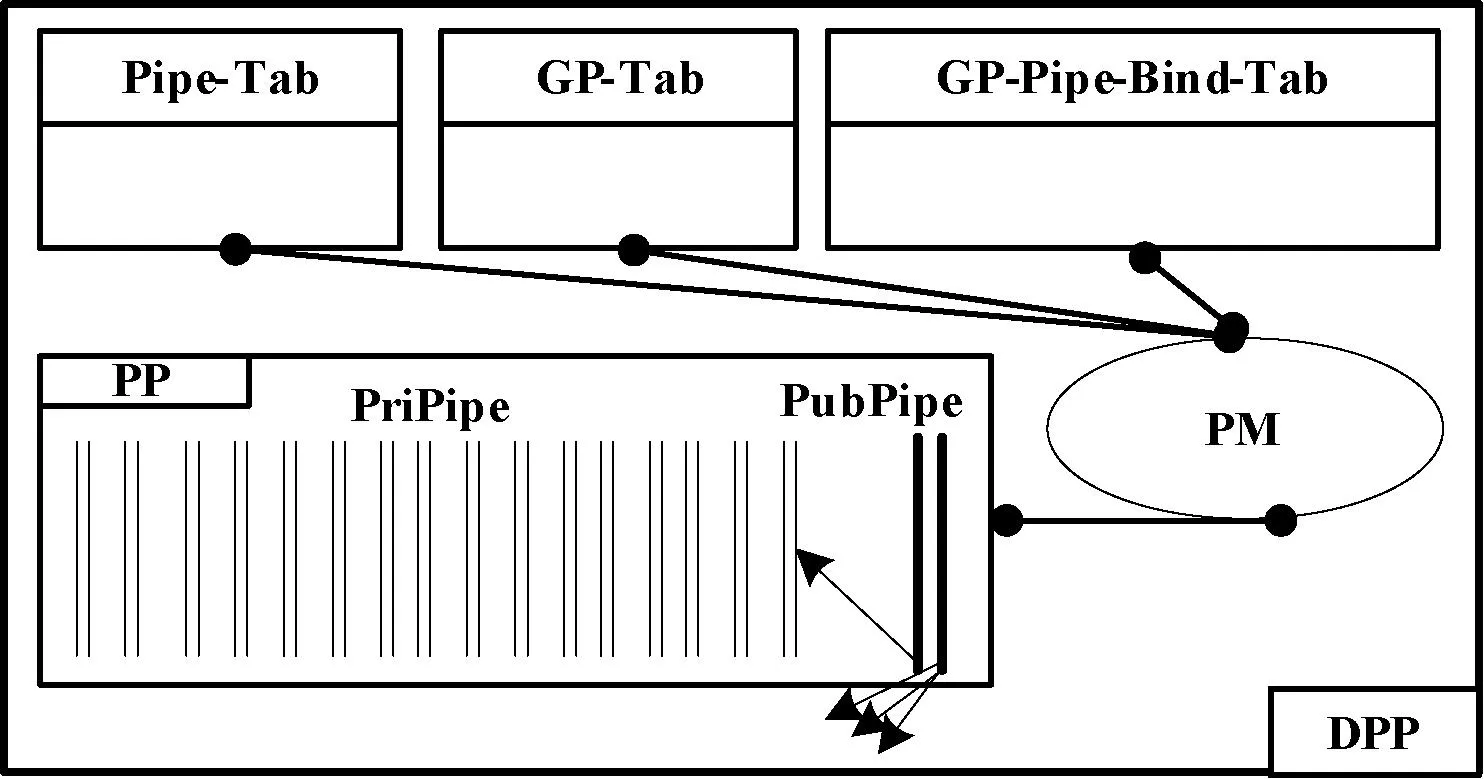
圖2 DPP結構圖
2.2 動態雙緩沖池模型
為對MPI并行通信進行擴展以提高并發多數據流的通信效率,在通信的每臺主機內都設置一個發送緩沖池和一個接受緩沖池,并且緩沖池配有線程池,以提高收發消息的高度并行性。
動態雙緩沖池模型為九元組DDBP
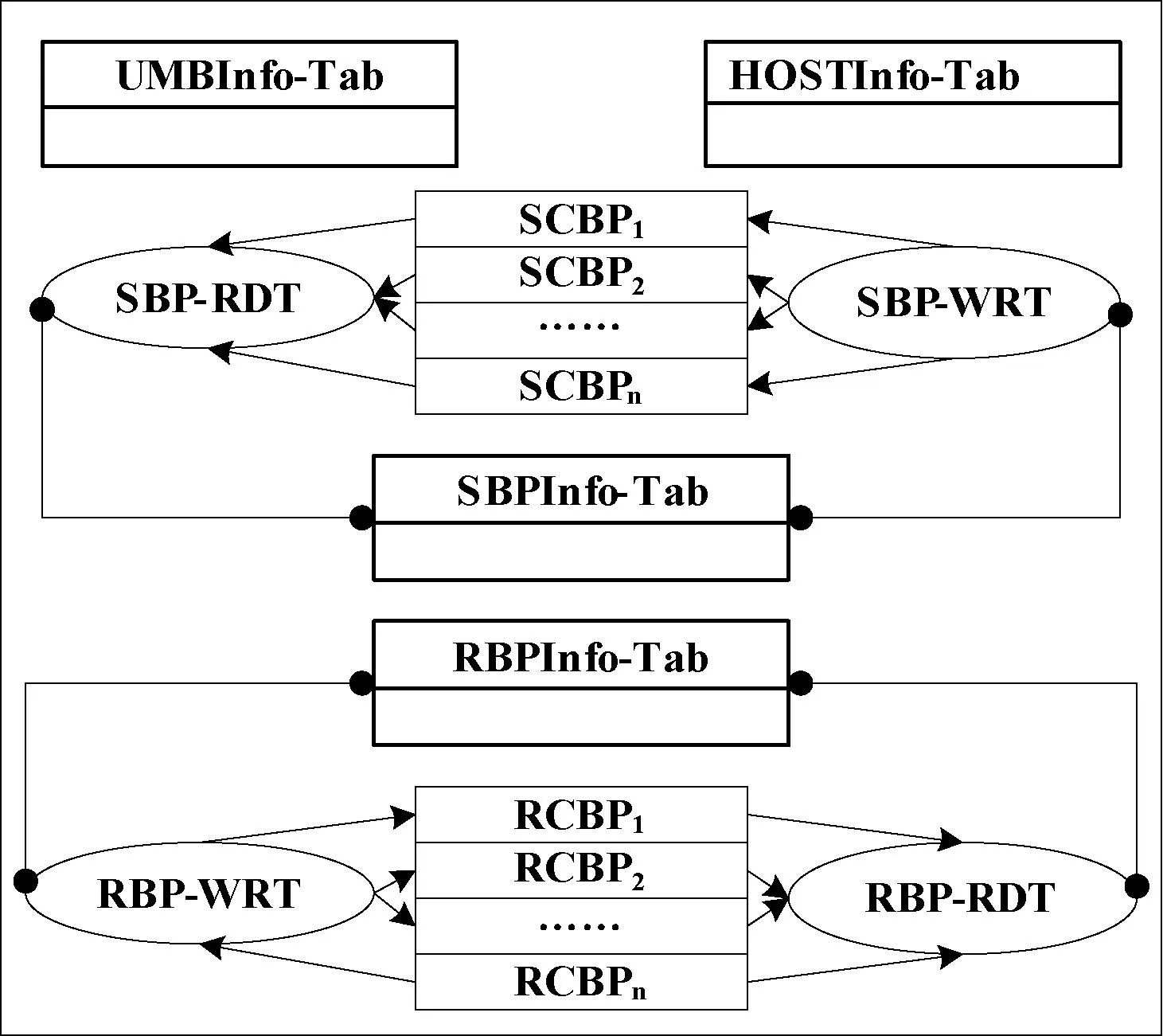
圖3 DDBP結構圖
2.3 發送/接收緩沖池
SBP
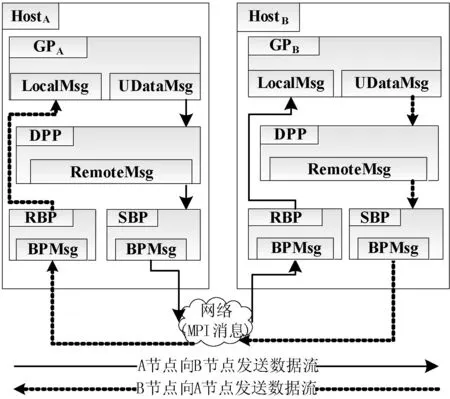
SM/RM都是一個M(N矩陣,其中M代表當前通信域中主機的個數,分別稱SM、RM的第i行為發送子緩沖池SCBPi、接收子緩沖池RCBPi。其中0≤i≤M-1,N代表每個子緩沖池的最大容量,可以根據通信數據流的特點來調整N的大小。當前主機的SCBPi是用于向遠端主機i發送數據的緩沖池,當前主機的RCBPj是用于存儲從遠端主機j接收到的數據的緩沖池。假設HostA、HostB為當前通信域中任意兩臺主機,若主機HostA要向主機HostB發送數據,則只需將HostA的SCBPB中的數據發往主機HostB,HostB將接收的數據存儲在本機的RCBPA中。
2.4 用戶內存塊UMB
UMB是DDBP向操作系統申請的內存塊的集合,每個內存塊都有一個唯一的標示符blockId且大小都相同。UMB為SMB和RMB所共享,UMBInfo-Tab是維護UMB信息的數據結構。
SM和RM中的元素并不是實際存儲數據的物理內存塊,而是UMB中的內存塊的標志blockId。因此稱SM和RM的地址空間為邏輯地址空間LAS(Logical Address Space)。邏輯地址空間保證了SM和RM并行發送/接收數據時結構上的整齊性,為實現消息整列的并行發送/接收提供了結構支持。
稱UMB的地址空間為物理地址空間PAS(Physical Address Space)。如果邏輯地址空間中某元素已經分配了物理地址空間中某內存塊的blockId,則稱此元素為“實元素”RE(Real Elements),否則稱為“虛元素”VE(Virtual Elements)。邏輯地址與物理地址的映射關系及相應的UMBInfo-Tab如圖4所示。
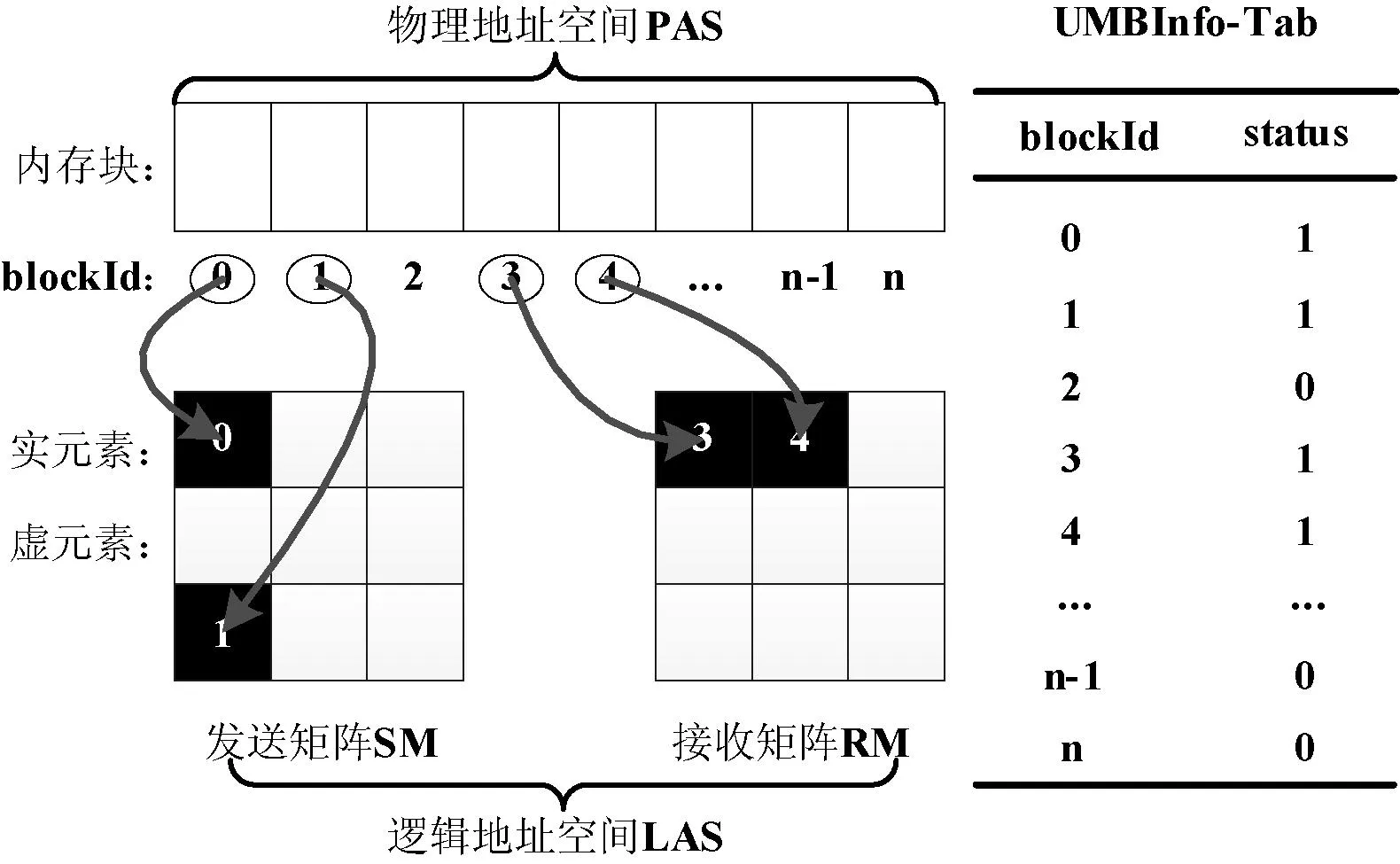
圖4 邏輯地址LAS與物理地址PAS映射關系
稱邏輯地址空間中連續的RE形成的空間為實空間RS(Real Space),稱邏輯地址空間中連續的VE形成的空間為虛空間VS(Virtual Space)。稱實空間與虛空間臨界處的實元素為臨界實元素CRE(Critical Real Elements),稱實空間與虛空間臨界處的虛元素為臨界虛元素CVE(Critical Virtual Elements),如圖5所示。

圖5 實空間RS與虛空間VS
2.5 基于閾值的UMB分配算法
稱SCBPi或RCBPi中實元素數目(‖REi‖)與元素總數目的比值,為該SCBPi或RCBPi的密度因子DFi(Density Factor),如下式:
(1)
稱SCBPi或RCBPi中已用實空間大小與當前子緩沖池實際可用實空間大小的比值,為該SCBPi或RCBPi實空間利用率SUi(Space utilization),如下式:
(2)
其中recv、send分別為當前子緩沖池的接收、發送位置指針(下同)。
稱SCBPi或RCBPi中已用實空間大小與未用實空間的比值,為該SCBPi或RCBPi收發速度比RSRi(Receive Send Ratio,簡稱RSR),如下式:
(3)
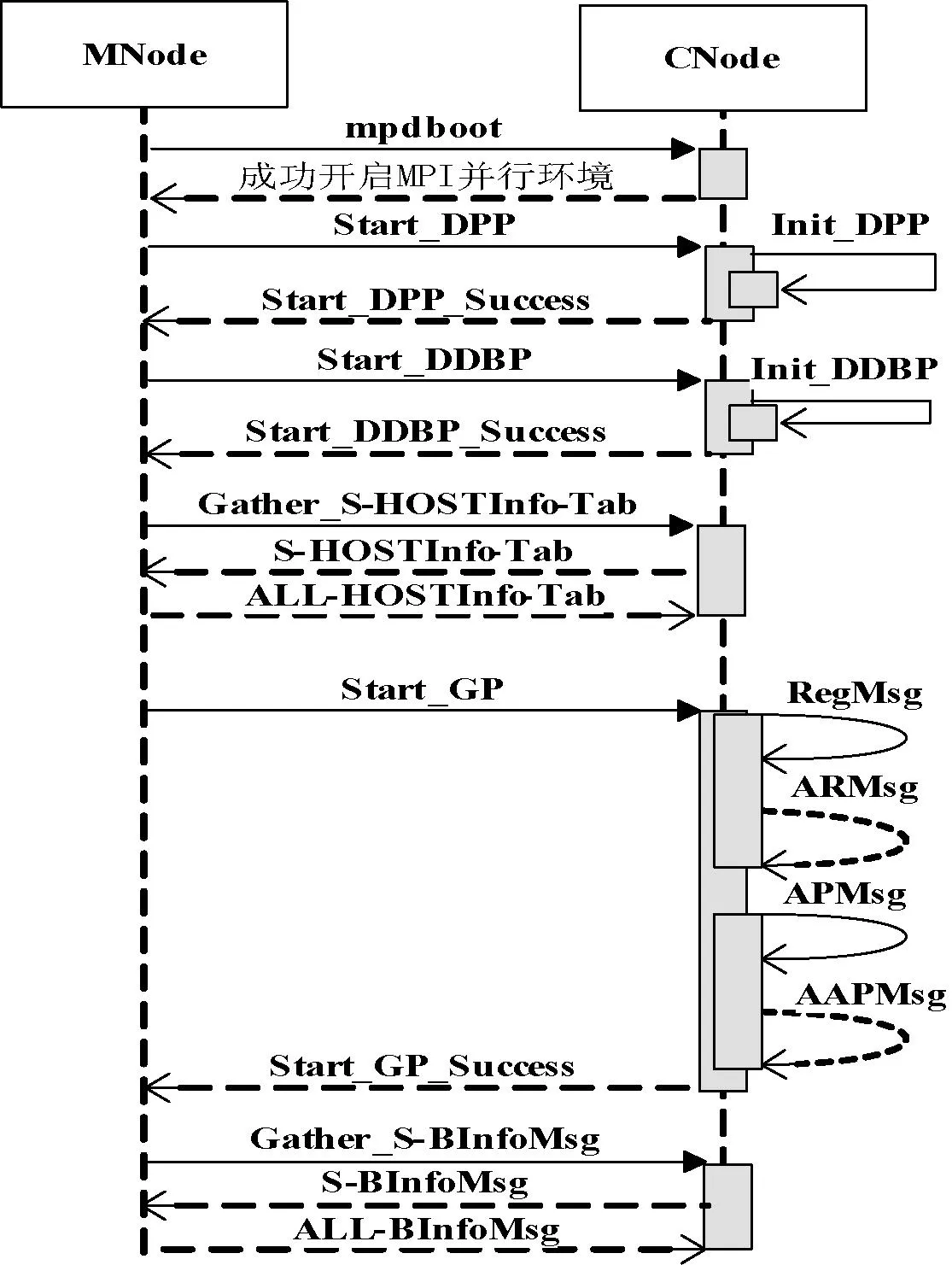
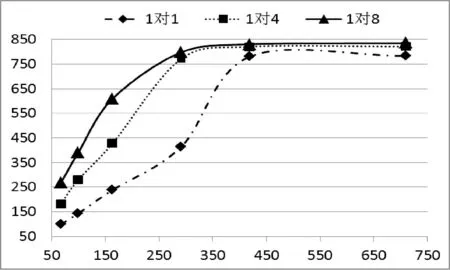
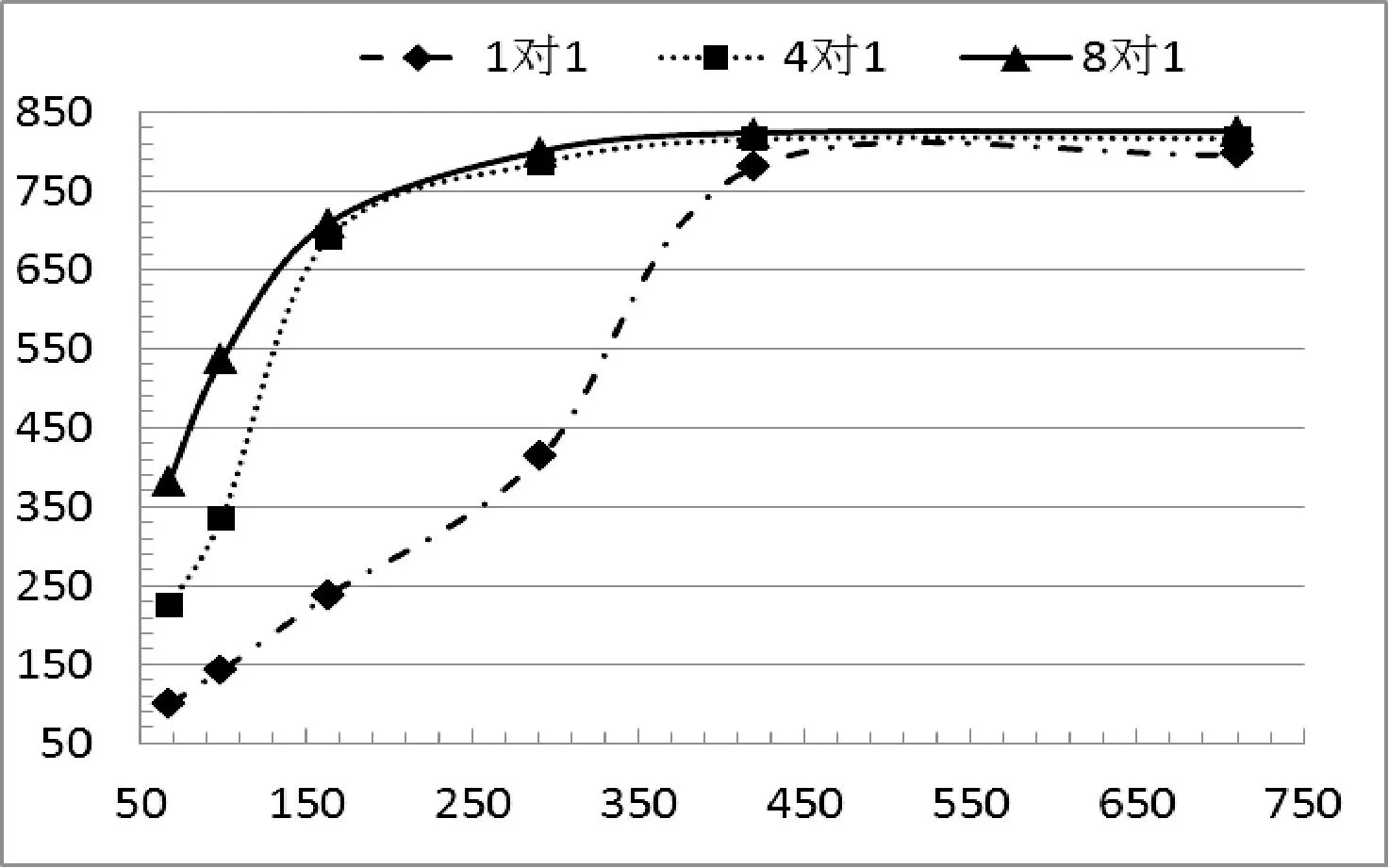
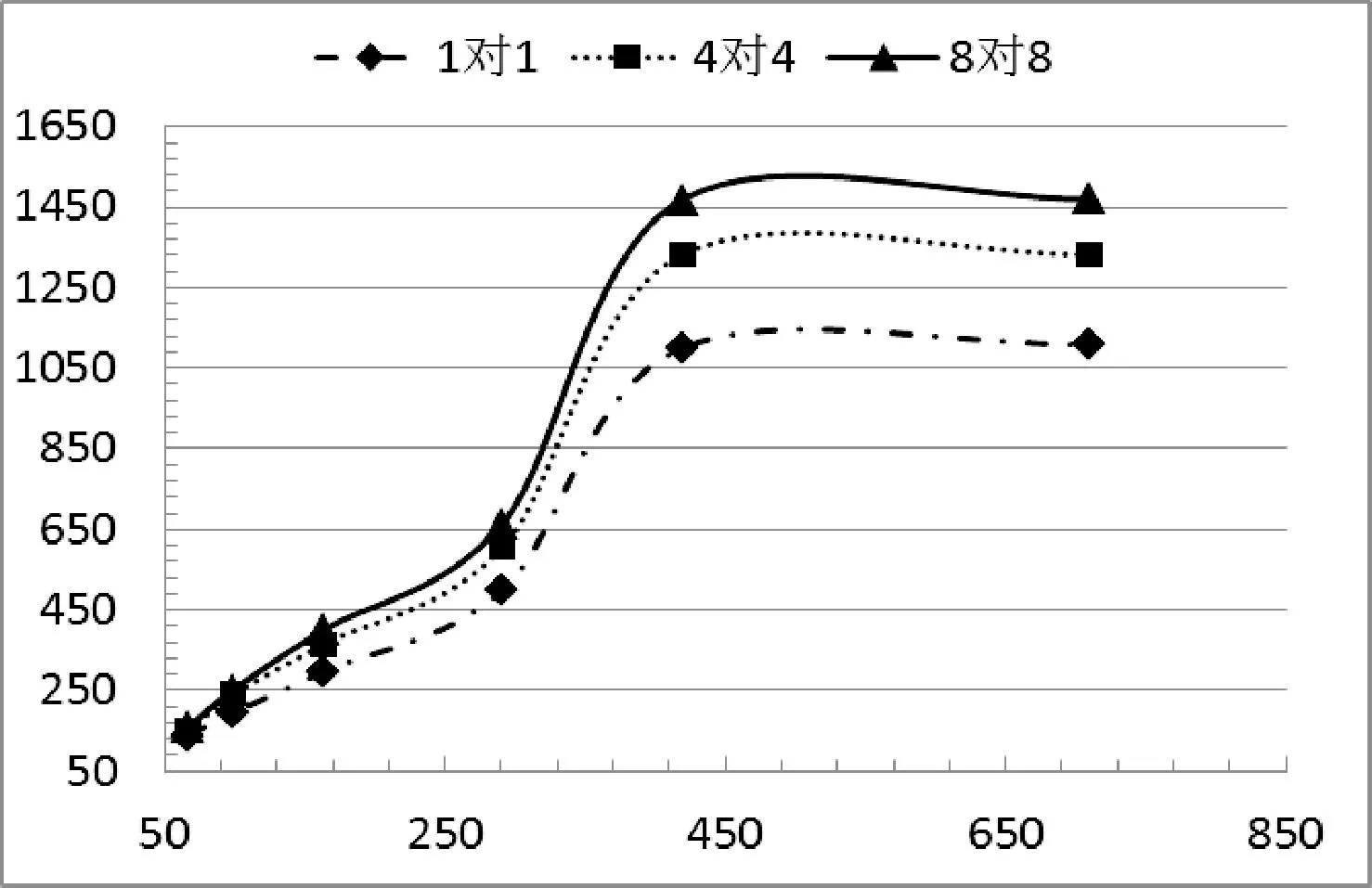
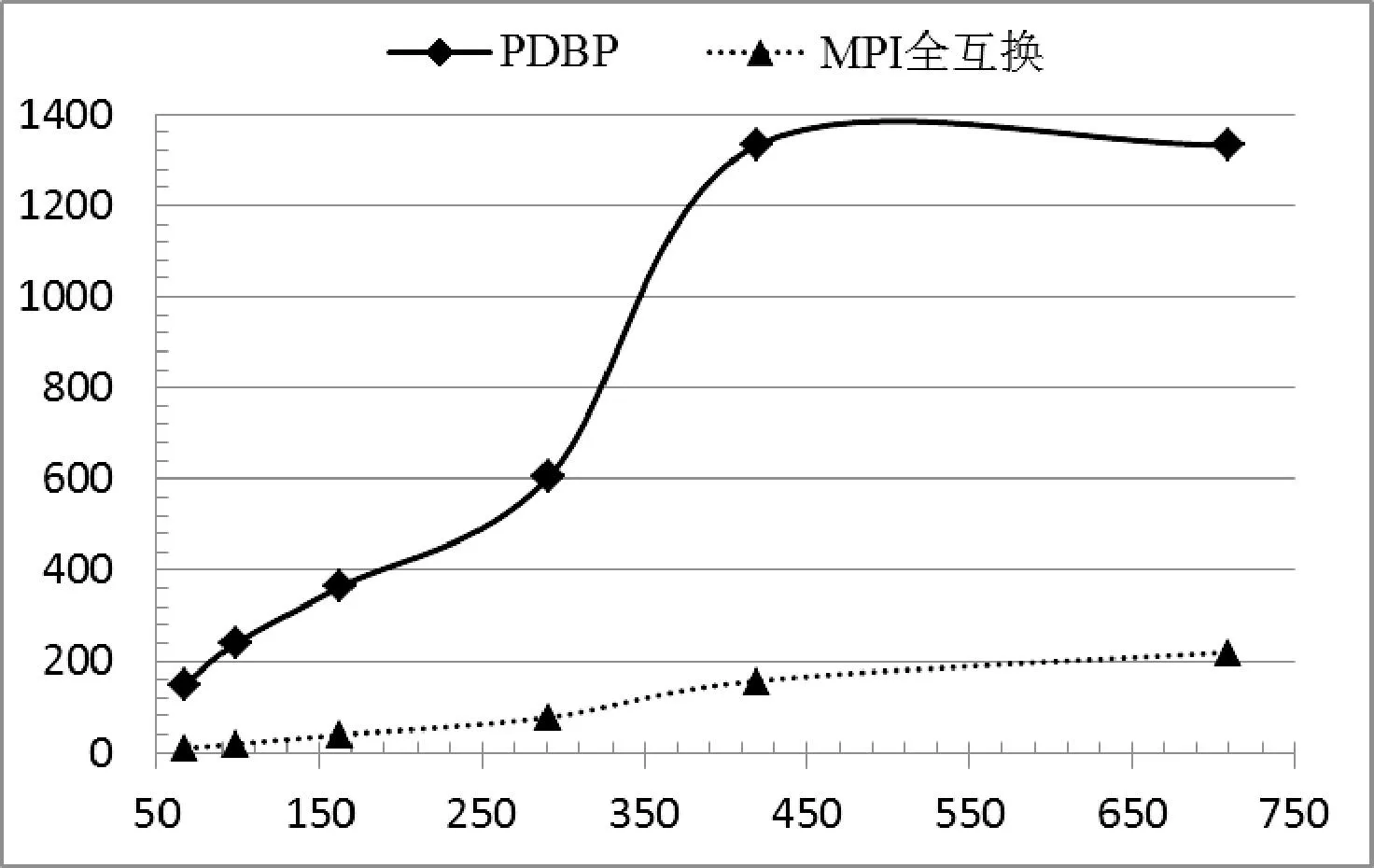
閾值Threshold是基于實空間利用率SU的值,一般有0 基于閾值的UMB分配算法的基本思想:(1) 為當前通信域中的每臺主機的SCBP和RCBP分配相同的實空間。(2) 對當前SCBP/RCBP,每當recv指針到達臨界實元素CRE時,計算其SU。如果SU大于閾值Threshold,則說明當前SCBP/RCBP通信較為密集,那么就從位置臨界虛元素CVE開始為其增加實空間。(3) 實空間的增加量根據收發速度比RSR來確定,以使每個子緩沖池的收發速率與其可用空間達到平衡,避免因接收迅速而發送遲緩造成子緩沖池“滿”,導致數據溢出。 算法1 基于閾值的UMB分配算法 輸入:Threshold,UMBInfo-Tab,SCBPi/RCBPi 輸出:增加實空間后的SCBPi/RCBPi /* 初始分配實空間 */ 1. for i = 1 to n do 2. if(UMBInfo-Tab 尚有可用內存塊) 3. Allocation_RS(SCBPi/RCBPi, m) //為子緩沖池分配實空間,大小為m 4. else 輸出提示信息 5. end if 6. end for /* 根據閾值Threshold動態調整實空間 */ 7. for i = 1 to n do 8. if(SCBPi.recv或RCBPi.recv位于CRE) 9. 計算SCBPi/RCBPi的SUi 10. if((SUi> Threshold) && (DFi< 1) ) 11. if(UMBInfo-Tab 尚有可用內存塊) 12. 計算RSRi 13. m = (RSRi- 1)* curSize 14. Allocation_RS(SCBPi/RCBPi, m) 15. else 輸出提示信息 16. end if 17. end if 18. end if 19. end for 2.6 線程池ThreadPool 線程池為ThreadPool DDP和DDBP對GP來說是消息收發的服務者,GP若要收發消息只需調用DDP和DDBP提供的通信編程口CPI即可,主要接口有以下幾個: 進程注冊prcsReg(…); 進程申請管道prcsApplyPipe(…); 發送數據sendData(…); 接收數據recvData(…); 進程釋放管道prcsReleasePipe(…); 進程注銷prcsFree(…)。 在PDBP內傳輸的消息,主要有兩類:控制消息和數據消息。控制消息主要有請求/應答消息,初始化消息和任務調度消息等,它們相對于數據消息具有實時性高、數據量小、發送和接收的進程是隨機的等特點,因此PDBP消息系統也分為兩部分,控制消息傳輸系統和數據消息傳輸系統。PDBP中的消息協議為MESP 設計消息協議MESP的基本思想:(1) 將消息分成消息頭和消息體兩部分。(2) 消息頭盡可能短,根據PDBP各個層次的結構設計層次化的消息頭。(3) 將數據統一封裝在消息體中,消息體的大小通過參數可調整,以適應長消息、短消息以及數據流消息通信的不同需要。 表1 協議格式參數 4.1 控制消息協議CMP CMP主要是為解決系統之間各個部分相互協調以及MNode管理CNode而設計的,主要有以下幾種: 1) 請求消息URMsg URMsg 2) 應答消息DAMsg DAMsg 3) 初始化消息 初始化消息主要有兩大類:主機信息消息和進程管道綁定信息消息。 主機信息消息HInfoMsg 進程管道綁定信息消息MBInfoMsg 4.2 利用CMP進行系統初始化 各臺主機根據業務邏輯編寫好各自的GP以后,就可以利用DBP和DDBP通信,但首先必須進行通信初始化,系統初始化的時序圖6所示。 圖6 PDBP初始化時序圖 4.3 數據消息協議DMP DMP主要是為解決系統之間各個部分收發數據消息而設計的,主要有以下幾種: UDataMsg LocalMsg RemoteMsg BPMsg 4.4 遠端消息傳輸 遠端消息傳輸是指在不同主機之間傳輸數據消息,通常傳輸的數據量比較大。因此采用分層的數據包格式而非統一的數據包格式,不但最大限度地減小數據包包頭的長度,而且減小了數據包解析封裝的復雜性。同時提高了有效負載的傳輸效率,遠端消息傳輸如圖7所示。 圖7 PDBP遠端數據消息傳輸圖 實驗主要測試各個不同節點SGP與SGP之間的通信,每對進行通信的SGP之間傳輸數據的規模均為64 GB,64 GB的數據由多個大小相同的單位數據包組成。為測得該系統本身傳輸速度的極限值以及排除磁盤讀寫速度的限制,發送方的數據由發送方SGP生成,傳輸到接收方SGP后,并不進行存盤操作,只執行簡單校驗工作。選取的通信模式均為主機SGP與SGP之間一對多、多對一和多對多模式,并在多對多模式下將PDBP與傳統MPI全互換的吞吐量進行對比。每種通信模式下選取的自變量主要是單位數據包的大小和通信域中的主機數目。 5.1 實驗環境 實驗所用的集群為12個節點組成的GPU同構集群,2個MNode(為保證集群的可靠性設置一對MNode,當其中的一個MNode出現故障時,另一個MNode接管主控工作)和10個CNode,MNode和CNode的功能詳見第1節,每個節點的配置信息如表2所示。 表2 實驗環境配置 說明:(1) 82579LM單向傳輸速度的峰值是1000 Mbps,雙向傳輸速度的峰值是2000 Mbps,即平常所說的千兆網卡的“千兆”是單向傳輸速度的峰值;(2) 圖8-圖11的橫坐標均為單位數據包大小(Byte),縱坐標均為單機吞吐量(Mbps)。(3) 圖8-圖11中每個點的數據均是用如下方法得到:在相同條件下,測得多組數據,去除一個最大值,去除一個最小值,求其它數據的均值。 5.2 一對多測試/多對一測試 一對多模式,每個CNode均有一個SGP,某個SGP為發送方,其他N個SGP為接收方,發送方向每個接收方并行發送64 GB數據,實驗結果如圖8所示。多對一模式,每個CNode均有一個SGP,N個SGP為發送方,其他某個SGP為接收方,每個發送方均向接收方并行發送64 GB的數據,實驗結果如圖9所示。在這兩種通信模式下,若通信域中有n臺主機,則通信域中就有n個并發的數據流。 圖8 一對多單向通信 圖9 多對一單向通信 由圖8、圖9可以看出,隨著主機數目的增加和數據包的不斷增大,使通信域中并發的數據流增多,數據密度增大,主機的吞吐量逐漸增大直至基本不變。在“1對8”模式下,峰值穩定吞吐量已達到835 Mbps,達到了網卡單向傳輸速度極限的83.5%;在“8對1”模式下,峰值穩定吞吐量達到了網卡單向傳輸速度極限的82.6%。 5.3 多對多測試 多對多模式,每個CNode均有一個SGP,每個SGP既向所有其它SGP并行發送數據,同時又從所有其他SGP并行接收數據,在這種通信模式下,若通信域中有n臺主機,則通信域中就有n×(n-1)個并發的數據流,實驗結果如圖10所示。 圖10 多對多雙向通信 從圖10中可以看出,隨著系統中并發數據流按n的平方次冪增長和數據密度增大,吞吐量不論是同一通信域內縱向比較還是在不同通信域內橫向比較,都有大幅提升,特別是在數據包大小大于291字節之后。與1對1相比,4對4和8對8在圖10中選取的6個不同大小的數據包下,吞吐量分別增加了(8.4%, 16%)、(23.4%, 29.2%)、(22.7%, 34.8%)、(21%, 33%)、(21.1%, 33.5%)、(20.1%, 32.6%),充分體現PDBP對并發多數據流極高的通信效率。 5.4 對比試驗:PDBP多對多與MPI全互換 MPI全互換(MPI_ALLTOALL)是MPICH標準庫函數,提供多對多通信支持[16]。由圖11可以看出,PDBP多對多與MPI全互換相比,單機吞吐量前者約是后者的9.9倍(求單位數據包相同的條件下兩者比較的各個倍數,再求這些倍數的均值)。 圖11 PDBP與MPI全互換單機吞吐量比較 5.5 PDBP提供通信支持的GPU大規模視頻流處理 實驗用的大規模數據流是10 000個QCIF(分辨率176×144)、10 000個CIF(分辨率352×288)、10 000個D1(分辨率704×576)格式的3G視頻流,每個視頻流采用H.264編碼。表3中的處理時間是指系統從啟動處理有節點的數據流當前幀開始,到每個節點對的所有數據流的當前幀處理完畢,所做的工作包括YUV圖像還原、模糊度分析和平滑度分析。 表3 H.264視頻流處理結果 從表3結果可以看出PDBP為GPU集群的大規模視頻流處理提供了高效的通信支持。 本文提出來一種提出了基于MPI的GPU并行通信系統PDBP的實現,適用于集群內部大規模數據流的高效傳輸。旨在解除GPU應用程序和MPI通信程序之間的耦合、提高通信編程效率及MPI并發多數據流的通信效率。 實驗表明,PDBP具有簡易的通信編程接口及良好的通信效率并可有效支持并發多數據流通信。未來將對動態緩沖池的調度策略和精準定制PDBP的通信速度展開研究。 [1] 王海峰,陳慶奎.圖形處理器通用計算關鍵技術研究綜述[J].計算機學報,2013,36(4):757-772. [2] Owens J D,Houston M,Luebke D,et al.GPU Computing[J].Proceedings of the IEEE,2008,96(5):879-899. [3] Roberto Ammendola,Massimo Bernaschi.GPU peer-to-peer techniques applied to a cluster interconnect[C]//Parallel and Distributed Processing Symposium Workshops & PhD Forum,2013:806-815. [4] 林一松,楊學軍,唐滔,等.一種基于并行度分析模型的GPU功耗優化技術[J].計算機學報,2011,34(4):706-716. [5] 王桂彬,楊學軍,唐滔,等.異構并行系統能耗優化分析模型[J].軟件學報,2012,23(6):1382-1396. [6] Ali Bakhoda,George L Yuan,Wilson W L.Analyzing CUDA Workloads Using a Detailed GPU Simulator[C]//Proc of IEEE International Symposium on Performance Analysis of Systems and Software.Boston,MA:IEEE Computer Society,2009:163-174. [7] Cheng Luo,Reiji Suda.A performance and energy consumption analytical model for GPU[C]//Proc of IEEE Ninth International Conference on Dependable,Autonomic and Secure Computing.Sydney,NSW:IEEE Computer Society,2011:658-665. [8] Alberto Cabrera,Francisco Almeida,Vicente Blanco,et al.Analytical modeling of the energy consumption for the High Performance Linpack[C]//Proc of 21st Euromicro International Conference on Parallel,Distributed and Network-Based Processing.Belfast:IEEE Computer Society,2013:343-350. [9] Andrea Bartolini,Matteo Cacciari.A Distributed and Self-Calibrating Model-Predictive Controller for Energy and Thermal management of High-Performance Multicores[C]//Design,Automation & Test in Europe Conference & Exhibition.Grenoble:IEEE Computer Society,2011:1-6. [10] Sam White,Niels Verosky,Tia Newhall.A CUDA-MPI Hybrid Bitonic Sorting Algorithm for GPU Clusters[C]//Proc of the 41st International Conference on Parallel Processing Workshops,2012:354-364. [11] Karunadasa N P,Ranasinghe D N.Accelerating high performance applications with CUDA and MPI[C]//Proc of the International Conference on Industrial and Information Systems,2009:331-336. [12] Shane Cook.CUDA Programming:A Developer’s Guide to Parallel Computing with GPUs[M].Morgan Kaufmann Publishers Inc.,2012. [13] NVIDIA.CUDA programming guide[M].2nd ed.NVIDIA Corporation,2008. [14] 陳慶奎,那麗春.采用動態緩池的SOAP并行通信模型[J].北京郵電大學學報,2008,31(1):40-44. [15] Yamagiwa S,Lisbon,Portugal L Sousa.CaravelaMPI:Message Passing Interface for Parallel GPU-Based Applications[C]//International Symposium on Parallel and Distributed Computing.Lisbon:IEEE,2009,10:161-168. [16] 都志輝.MPI并行程序設計[M].北京:清華大學出版社,2001. IMPLEMENTATION OF GPU CLUSTER PARALLEL COMMUNICATION SYSTEM BASED ON MPI Hou Jingde1Chen Qingkui1,2Zhao Haiyan1 1(SchoolofOptical-ElectricalandComputerEngineering,UniversityofShanghaiforScienceandTechnology,Shanghai200093,China)2(ShanghaiKeyLaboratoryofModernOpticalSystem,Shanghai200093,China) Given the complexity problem of GPU and MPI hybrid programming itself, we proposed a MPI-based GPU parallel communication system: the pipe dynamic buffer pool (PDBP) system. We described PDBP’s main components, architecture and implementation process, and defined the communication protocol. The system uses dynamic pipe pool and dynamic buffer pool technologies, extends the MPI parallel communication, and provides a simple and efficient communication programming interface for CUDA programmer. Experiments show that PDBP has a higher parallel communication efficiency, especially in many-to-many communication mode, the communication efficiency improves by about 9 times. MPI Dynamic pipe pool Dynamic buffer pool Communication protocol PDBP 2014-10-30。國家自然科學基金項目(60970012);高等學校博士學科點專項科研博導基金項目(20113120110008);上海重點科技攻關項目(14511107902);上海市工程中心建設項目(GCZX140 14);上海市一流學科建設項目(XTKX2012);滬江基金研究基地專項(C14001)。侯景德,碩士生,主研領域:并行計算。陳慶奎,教授。趙海燕,副教授。 TP3 A 10.3969/j.issn.1000-386x.2016.04.0283 通信編程接口CPI
4 消息協議MESP

5 實驗結果與分析


6 結 語
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58
中國外匯(2019年8期)2019-07-13 06:01:06
電腦愛好者(2018年15期)2018-08-23 17:24:06
民主與科學(2014年3期)2014-02-28 11:23:03
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
電腦迷(2012年24期)2012-04-29 00:44:03
中華女子學院學報(2012年6期)2012-03-25 13:52:27
俄羅斯問題研究(2012年1期)2012-03-25 09:54:45
杭州師范大學學報(社會科學版)(2011年3期)2011-04-04 08:58:20
