融合學習者社交網絡的協同過濾學習資源推薦*
2016-05-06 02:30:14丁永剛桑秋俠金夢甜張紅波
現代教育技術 2016年2期
關鍵詞:資源
丁永剛 張 馨 桑秋俠 金夢甜 張紅波
(湖北大學 教育學院,湖北武漢 430062)
融合學習者社交網絡的協同過濾學習資源推薦*
丁永剛 張 馨 桑秋俠 金夢甜 張紅波
(湖北大學 教育學院,湖北武漢 430062)
傳統的協同過濾推薦算法存在冷啟動和數據稀疏的問題,使得新學習者因歷史學習行為記錄稀疏或缺失而無法獲得較準確的個性化學習資源推薦。鑒于此,文章提出將學習者社交網絡信息與傳統協同過濾相融合的方法,計算新學習者與好友之間的信任度,借助新學習者好友對學習資源的評分數據,來預測新學習者對學習資源的評分值,以填補新學習者在學習者—學習資源評分矩陣中的缺失,實現對新學習者的個性化學習資源推薦。實證研究結果表明,該方法在一定程度上能夠解決傳統協同過濾方法的冷啟動和數據稀疏問題,提高個性化學習資源推薦的準確率。
社交網絡;協同過濾;學習資源;個性化推薦
引言
計算機與互聯網的高速發展不僅影響著人們的生活方式,而且也改變著人們的學習方式乃至思維方式[1]。網絡學習因具有學習資源豐富、學習過程自主控制等優點,而成為學習者彌補傳統課堂學習不足和滿足個性化學習需求的首選學習方式。然而,一方面由于網絡學習資源數量急速增長,導致資源嚴重過載,使得學習者難以快速獲取自己感興趣的資源,因而在一定程度上加大了學習者的學習難度,延長了學習者的學習時間,降低了學習者的學習效率;另一方面,由于網頁之間以超鏈接的方式進行跳轉,大量符合學習者個性化學習需求的學習資源可能被放置在超鏈接的深層,使得學習者無法輕易獲取,從而降低了網絡學習資源的有效利用率。因此,針對學習者學習偏好為其提供個性化學習資源推薦,便成為了提高學習者學習效率和網絡學習資源利用率的有效手段。
個性化推薦技術被認為是目前解決信息過載問題的有效途徑之一,其中最著名和最廣泛應用的是基于協同過濾算法的推薦技術。該技術最早被應用于電子商務領域[2],其基本原理是從用戶對商品的瀏覽、收藏、購買、打分、評價等歷史行為信息中提取用戶偏好信息,據此預測用戶可能感興趣的商品,并通過動態即時地向用戶推送此類商品信息來促使用戶購買商品的行為不斷發生[3]。近年來,教育技術領域專家和學者致力于將協同過濾推薦技術應用于網絡學習領域來構建個性化學習資源推薦系統,為學習者提供個性化學習資源推薦服務,以提高學習者的網絡學習效率。如楊麗娜等[4]運用協同過濾、內容推薦及聚類分析相結合的方法,提出面向虛擬學習社區的個性化學習資源推薦框架;王永固等[5]在全面闡述協同過濾推薦技術的基礎上,提出學習資源個性化推薦系統理論模型;葉樹鑫等[6]采用協同過濾推薦技術,為協作學習中的相似學習者提供個性化學習資源推薦。
協同過濾推薦技術在一定程度上解決了學習資源信息過載的問題,但是傳統的協同過濾算法存在冷啟動和數據稀疏的問題,使得新學習者因歷史學習行為記錄稀疏或缺失而無法獲得較準確的推薦。對此,文章提出利用學習者社交網絡中的好友信息,計算學習者與其好友之間的信任度,并根據學習者好友—學習資源評分矩陣,預測學習者—學習資源評分值來填補新學習者在學習者—學習資源評分矩陣中的缺失數據,以提高個性化學習資源推薦的質量,滿足學習者個性化學習的需求。
一 基于協同過濾算法的個性化學習資源推薦
協同過濾算法應用于個性化學習資源推薦的基本原理是:根據學習者的歷史學習記錄形成學習者—學習資源評分矩陣,利用相似性度量方法(如余弦相似度、皮爾森相關系數等),通過計算學習者或學習資源之間的相似度,挖掘出與目標學習者相似的學習者集合或與學習者歷史偏好相似的學習資源集合,形成“鄰居”,然后基于“鄰居”學習者對學習資源的評分信息,預測目標學習者對學習資源的預測評分值,并根據預測評分值的大小為目標學習者進行個性化推薦。如TopN推薦,便是將預測評分值最大的前N個學習資源推薦給目標學習者。協同過濾推薦算法的具體實現步驟如圖1所示。

圖1 協同過濾推薦算法實現原理
依據上述原理,目前將協同過濾推薦技術應用于學習資源推薦主要有兩種方法:
1 基于學習者的協同過濾算法(LearnerCF)
LearnerCF基于學習者對學習資源的公共評分信息計算學習者之間的相似度,并依據相似度大小來確定學習者的“鄰居”集合,將“鄰居”集合中學習者感興趣的、而目標學習者沒有學習過的學習資源推薦給目標學習者。LearnerCF向學習者推薦和他有共同學習興趣的學習者感興趣的學習資源,它隱含的機理是:兩個學習者之間相似度的大小,由他們共同感興趣的學習資源評分決定。
2 基于學習資源的協同過濾算法(ResourceCF)
ResourceCF基于被共同感興趣的學習者對學習資源的評分信息計算學習資源之間的相似性,并根據目標學習者的歷史學習偏好,向其推薦與之歷史學習偏好相似的學習資源。它隱含的機理是:學習資源之間相似度的大小,由它們被共同感興趣的學習者對學習資源的評分決定。
從相似度計算的代價考慮,在學習者數量小于學習資源數量的情況下,使用LearnerCF進行個性化資源推薦較為適合;反之,ResourceCF較為適合。在網絡學習中學習者的數量遠遠大于學習資源的數量,因此,采用ResourceCF方法能在較好地滿足學習者個性化學習需求的同時,降低系統的計算代價。
上述兩種方法應用于不同場合已取得了不錯的效果,但是仍然存在數據稀疏和冷啟動的問題。一方面,LearnerCF由于學習者評分數據的稀疏性,學習者之間的共同評分資源數很少,使得用戶相似度的計算不夠準確,從而導致推薦的準確度不高;另一方面,ResourceCF對資源相似度的計算主要基于學習者自身歷史學習記錄,避免了LearnerCF由于沒有共同評分的學習者而無法準確計算學習者相似度的問題,但對于沒有歷史學習記錄的新學習者,ResourceCF卻無法進行推薦,即存在冷啟動問題。
二 學習者社交網絡
學習者社交網絡是指學習者在網絡環境下,借助社交平臺(如QQ、微博、微信等)與好友交流溝通、分享信息,而形成的個性化、動態化的人際信任網絡。
1 學習者社交網絡和信任關系
學習者社交網絡中的好友大多是其現實生活中的朋友、同學、同事或學習者所關注的人,因此,學習者與其社交網絡中的好友存在一定的信任關系。但信任是一個具有主觀性的概念,不同研究領域的學者對信任的概念界定不同[7]。受學者Golbeck的啟發[8],文章將“信任”界定為:如果學習者甲認為根據學習者乙的學習行為進行學習能夠取得好的學習效果,則甲信任乙。
2 信任度的表示
學習者之間的信任程度用信任度表示[8]。在某些情況下,信任度僅用二值表示,即信任和不信任,但是這種簡單度量方法在學習者社交網絡中不夠準確,不能充分體現學習者社交網絡中信任度的作用。因此,本研究采用離散值將信任度劃分成等級,其取值范圍設定為[0,1],其中0表示完全不信任,1表示完全信任。
3 信任度計算
社交網絡中學習者之間的信任度難以通過顯式的方法獲得,這是因為學習者主動輸入好友的信任度,需要花費學習者的時間;另外,由于學習者之間的信任度處于動態變化之中,不能用固定值代替。文章認為,社交網絡中學習者與好友之間的互動行為在一定程度上反映了學習者與好友之間的信任關系,這種互動行為主要包括評論和轉發。學習者對彼此所發布的消息評論次數越多,表示學習者之間的熟悉程度越大,其信任度越高;學習者對彼此所發布的消息轉發次數越多,表示學習者之間的認同感越強,其信任度越高。實際上,學習者一般會對自身感興趣或者不清楚的消息進行評論,但不一定轉發,而學習者轉發的消息往往是經過自身篩選并高度認同的內容,因此轉發行為的權重相對評論行為的權重應略大一些。受學者胡勛等[9]對移動用戶間信任度計算方法的啟發,網絡環境下學習者之間的信任度可以采用下面的公式1計算:
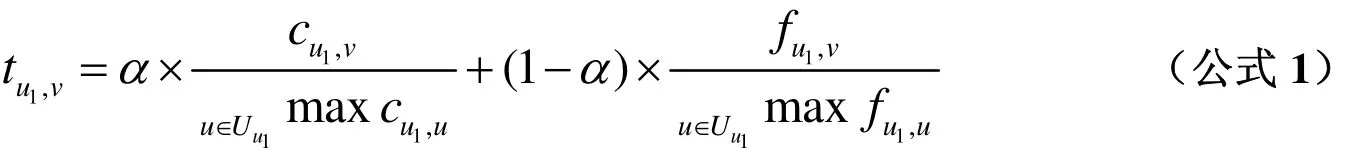
三 融合學習者社交網絡的協同過濾個性化學習資源推薦方法
個性化學習資源推薦技術作為滿足學習者個性化學習需求的有效支持服務,其推薦算法的好壞是決定推薦服務質量的關鍵。文章提出融合學習者社交網絡的學習資源協同過濾算法(SocialCF)進行個性化學習資源推薦,其實現流程如圖2所示。
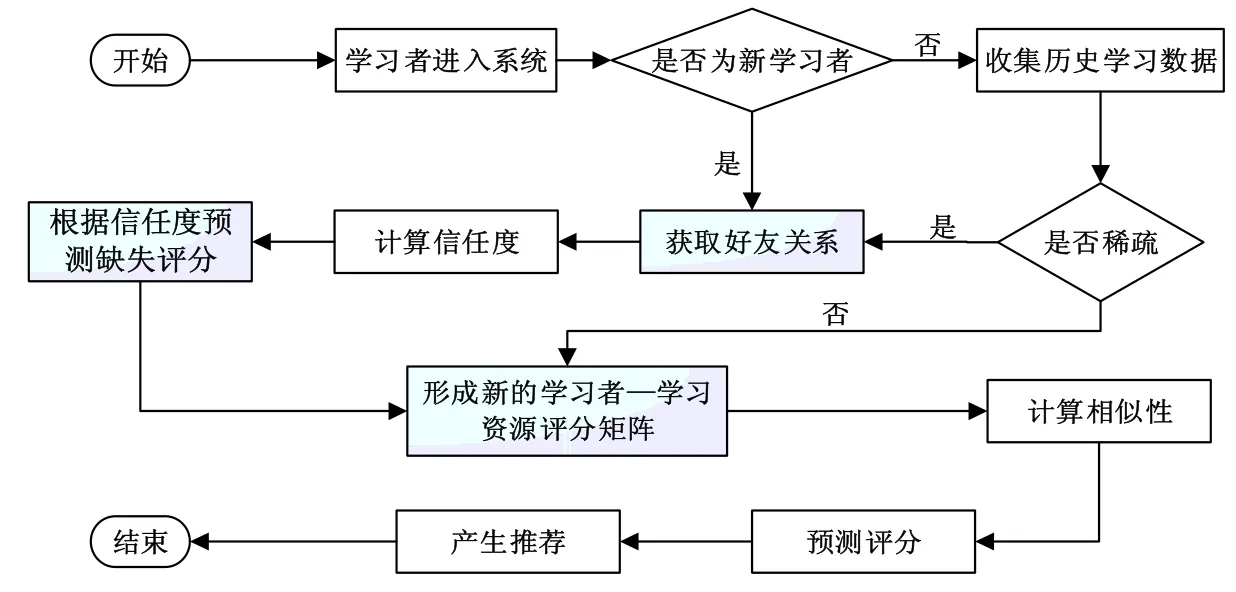
圖2 融合學習者社交網絡的協同過濾個性化學習資源推薦流程圖
從圖2可知,本方法需要解決以下三個關鍵問題:
1 學習者社交網絡信息的獲取
為了獲取學習者的社交網絡信息,網絡學習平臺允許學習者以其社交平臺賬號如QQ、微博等賬號登錄,并授權學習平臺獲得學習者的好友列表信息。為保護隱私,此操作僅允許學習平臺獲取學習者與其好友的交互行為信息,而不允許對學習者的社交內容進行獲取。
2 信任度與預測評分值的轉換
利用公式1計算得到學習者與好友之間的信任度后,即可利用公式2計算得到目標學習者對學習資源的預測值:

3 學習者信任度與學習者—學習資源評分矩陣的融合
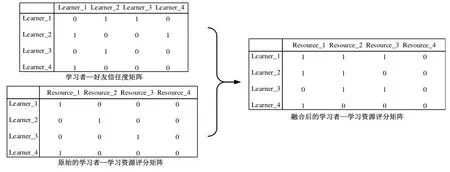
圖3 學習者—好友信任度矩陣與學習者—學習資源評分矩陣融合示意圖
如圖3所示,將學習者任度與學習者—學習資源矩陣相融合的方法是:借助學習者—好友信任度矩陣中Learner_1“JSP程序設計”課程網站獲得第十四屆全國多媒體課件大賽二等獎。與Learner_2的信任關系和Learner_2對Resource_2的評分信息,產生Learner_1對Resource_2的評分,該評分依據公式2進行計算。以此類推,可補充學習者—學習資源評分矩陣中的其它空白。從圖3不難看出,融合了學習者社交網絡信息的學習者—學習資源評分矩陣,明顯比原始的學習者—學習資源評分矩陣稠密。
四 融合學習者社交網絡的協同過濾個性化學習資源推薦效果分析
為驗證SocialCF方法的有效性,本研究以湖北大學教育技術學專業的120名學生為實驗對象,在自主研發的“JSP程序設計”課程學習平臺上進行實證研究。該學習平臺在“JSP程序設計”課程網站1“JSP程序設計”課程網站獲得第十四屆全國多媒體課件大賽二等獎。的基礎上進行二次開發,增加了個性化推薦模塊和收集學習者歷史評分數據和學習者社交網絡數據的功能。學習者的平均好友數為4.5個,學習資源數為208個,評分記錄數為1252條,數據稀疏率為95%。實證采用問卷調查和離線實驗的方法對推薦效果進行評價。問卷調查方法從系統冷啟動、滿意度和信任度三個方面對推薦效果進行評價,離線實驗方法則使用準確率、召回率和覆蓋率指標對推薦效果進行評價。
1 調查問卷結果與分析
本實驗實際發放問卷120份,回收120份,有效回收率100%。表1顯示了CF和SocialCF調查問卷的結果。
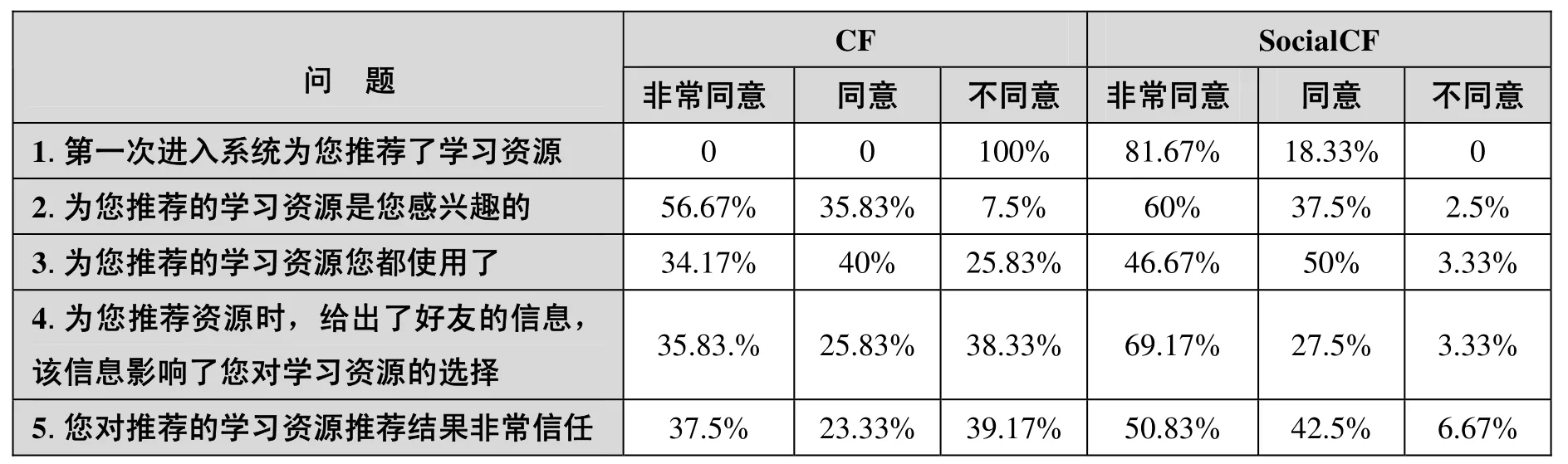
表1 CF和SocialCF調查問卷的反饋結果
在表1中,第一個問題用于評測兩種不同方法對新學習者的推薦情況,即冷啟動問題。由于SocialCF使用了社交網絡信息,所以新學習者第一次進入系統時即可獲得推薦。第二和第三個問題用于測評用戶的滿意度,可以看出,雖然92.5%的學習者認為CF推薦的學習資源與其學習興趣相關,但只有74.17%用戶使用了學習資源;而97.5%的學習者認為SocialCF推薦的學習資源與其學習興趣相關,且96.67%的學習者使用了學習資源。由此可知,學習者對SocialCF的推薦結果較滿意。第四和五個問題用于測評學習者對推薦結果的信任度。由于SocialCF在推薦時給出了好友信息,學習者對資源推薦結果的信任度比CF提高了32.5%,這表明學習者對SocialCF的推薦結果更加信任。
2 離線實驗對比與分析
隨機抽取100個用戶數據進行離線實驗,用于評測系統的準確率、召回率和覆蓋率。其中80個用戶數據用于訓練集,20個用戶數據用于測試集。
(1)不同topN情況下CF與SocialCF準確率和召回率的比較
準確率是指系統推薦給學習者感興趣的資源占所有推薦給學習者資源的比例,召回率則指推薦給學習者感興趣的資源占系統中學習者感興趣的所有資源的比例。選擇推薦列表長度分別為N=5,10,15,20,25,30,35,40,對CF與SocialCF的準確率與召回率進行測定,如圖4所示。可以看出,在N的各種取值下,SocialCF的準確率和召回率均高于CF,說明SocialCF能比CF為學習者推薦更準確且更多感興趣的學習資源。
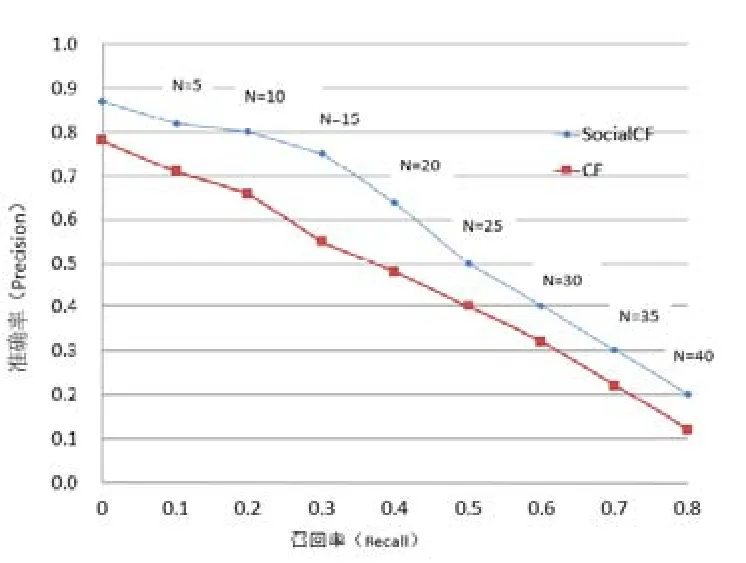
圖4 不同topN情況下兩種方法的精確率和召回率
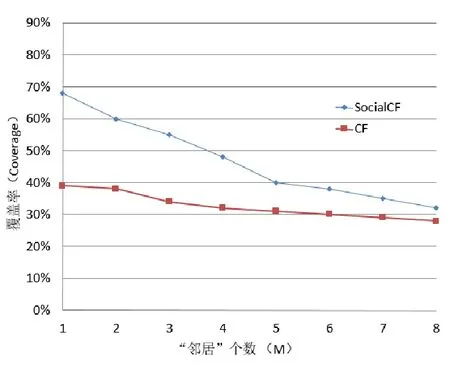
圖5 不同“鄰居”數情況下兩種方法的覆蓋
(2)不同“鄰居”個數下CF和SocialCF的覆蓋率
覆蓋率是指向學習者推薦的學習資源占總體學習資源的比例。分別選擇不同的“鄰居”個數,測試CF與SocialCF的覆蓋率,如圖5所示。可以看出,隨著“鄰居”個數的不斷增加,學習者的學習偏好被定位到一個較小范圍,推薦的學習資源越來越少,因此CF與SocialCF覆蓋率均呈下降趨勢。但從總體來看,SocialCF的覆蓋率仍高于CF,表明SocialCF能夠在一定程度上提高學習資源的利用率。
五 總結
利用個性化推薦技術,幫助學習者在海量的學習資源中輕松、準確、高效地獲取感興趣的學習資源,既是決定網絡學習效果的關鍵,也是避免網絡學習資源浪費的有效途徑。文章針對傳統協同過濾算法中的冷啟動和數據稀疏問題,提出運用學習者社交網絡信息與傳統協同過濾相融合的方法進行個性化學習資源推薦。問卷調查和離線實驗結果表明,SocialCF能夠在一定程度上緩解協同過濾的冷啟動和數據稀疏問題,且在學習者滿意度、準確度、信任度和覆蓋率等方面均優于CF,故提高了個性化學習資源的推薦質量。為了取得更好的推薦效果,未來我們將進一步考慮學習者對學習資源的隱式評分數據和學習者與好友在社交網絡中的其它交互行為。
[1]余勝泉.技術何以革新教育——在第三屆佛山教育博覽會“智能教育與學習的革命”論壇上的演講[J].中國電化教育,2011,(7):1-6.
[2]Lee L,Lu T C.Intelligent agent-based systems for personalized recommendations in internet commerce[J].Expert Systems with Applications,2002,(22):275-284.
[3]Cheung K W,Kwok J T,Law M H,et al.Mining customer product ratings for personalized marketing[J].Decision Support Systems,2003,(35):231-243.
[4]楊麗娜,劉科成,顏志軍.面向虛擬學習社區的學習資源個性化推薦研究[J].電化教育研究,2010,(4):67-71.
[5]王永固,邱飛岳,趙建龍,等.基于協同過濾技術的學習資源個性化推薦研究[J].遠程教育雜志,2011,(3):66-71.
[6]葉樹鑫,何聚厚.協作學習中基于協同過濾的學習資源推薦研究[J].計算機技術與發展,2014,(10):63-66.
[7]張富國.基于信任的電子商務個性化推薦關鍵問題研究[D].南昌:江西財經大學,2009:12-13.
[8]Golbeck J.Computing and applying trust in Web-based social networks[D].Maryland:University of Maryland,College Park 2005:15-16.
[9]胡勛,孟祥武,張玉潔,等.一種融合項目特征和移動用戶信任關系的推薦算法[J].軟件學報,2014,(8):1817-1830.
The Collaborative Filtering Recommendation of Learning Resources Combined with Learners’ Social Network
DING Yong-gang ZHANG Xin SANG Qiu-xia JIN Meng-tian ZHANG Hong-bo
(School of Education,Hubei University,Wuhan,Hubei,China 430062 )
The traditional collaborative filtering recommendation algorithm (CF) has the problems of cold start and data sparseness,so it is difficult for new learners to obtain learning resources recommendation because of the sparsity or the lack of history learning behavior records.Thus,in this paper,a new CF method was proposed which combined learners’social network information with traditional CF method.In order to fill the gap in the “learner - learning resource rating matrix” and achieve the recommendation of learning resources to new learners,it first calculated the trust degrees between new learners and their friends and then predicts new learners’ ratings on learning resources by virtue of that of their friends.The experimental results shown that this method can solve the cold start and data sparsity problems in some degree and improve the accuracy of personalized learning recommendation.
social network; collaborative filtering; learning resource; personalized recommendation
小西
G40-057
A 【論文編號】1009—8097(2016)02—0108—07
10.3969/j.issn.1009-8097.2016.02.016
本文為教育部人文社會科學研究青年基金項目“基于互動電視的課堂教學模式與策略研究”(項目編號:14YJC880109)階段性研究成果。
丁永剛,副教授,在讀博士,研究方向為教育數據挖掘、個性化資源推薦,郵箱為hddyg@hubu.edu.cn。
2015年8月27日
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
資源節約與環保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
藝術品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
當代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
