面向網絡輿情數據的異常行為識別
2016-04-27 10:31:38郝亞洲鄭慶華陳艷平閆彩霞
計算機研究與發展 2016年3期
關鍵詞:數據挖掘
郝亞洲 鄭慶華 陳艷平 閆彩霞
(陜西省天地網技術重點實驗室(西安交通大學) 西安 710049)
(西安交通大學計算機科學與技術系 西安 710049)
(hyzxjtu@qq.com)
?
面向網絡輿情數據的異常行為識別
郝亞洲鄭慶華陳艷平閆彩霞
(陜西省天地網技術重點實驗室(西安交通大學)西安710049)
(西安交通大學計算機科學與技術系西安710049)
(hyzxjtu@qq.com)
Recognition of Abnormal Behavior Based on Data of Public Opinion on the Web
Hao Yazhou, Zheng Qinghua, Chen Yanping, and Yan Caixia
(SPKLSTNLaboratory(Xi’anJiaotongUniversity),Xi’an710049)
(DepartmentofComputerScienceandTechnology,Xi’anJiaotongUniversity,Xi’an710049)
AbstractWith the increasing popularity of the social network, public awareness and participation to hot topics has been much improved, mobile terminal equipment and fast Internet access make the spread of public opinion quickly. Public opinion on the Web has freedom, interactivity, diversity, deviation and burstiness as characteristics, has become an important factor that affects social stability. Therefore, how to timely detect, control and guide the development of public opinion is of great significance to the social stability. This article focuses on the behaviors that spread on the Web and contain “destruction”, “dangerous” and “loss” involves public security or judicial justice, and the behaviors is defined as abnormal behavior. We define the types of abnormal behavior that this article focuses on are aggression, injury, death, and arrests, four categories. From the point of view of information extraction, our method recognizes the abnormal behavior by identifying sentences that contain the abnormal behavior and constructs co-occurrence network of abnormal behavior, with provide the visualization analysis approach of public opinion on the Web.
Key wordspublic opinion; event extraction; recognition of abnormal behavior; co-occurrence network; data mining
摘要社交網絡的日益普及和移動設備快捷的網絡接入,使得網絡輿情的傳播十分迅捷,民眾對熱點話題的關注度和參與度得到很大的提升.網絡輿情具有自由性、交互性、多元性、偏差性、突發性等特點,能夠左右民眾的情感和判斷,能推動和改變事件的發展和走向,容易被反對分子利用,已經成為影響社會穩定的重要因素.因此,及時檢測、控制并引導輿情的發展具有十分重要的意義.研究關注網絡中傳播的蘊含有“破壞”、“危險”、“損失”等涉及公共安全或涉及司法公正的行為.根據課題的需要,定義4種關注的異常行為類型:攻擊行為、受傷行為、死亡行為、拘捕行為.從數據挖掘和信息抽取的角度研究識別異常行為的方法,首先通過分類器和觸發詞從海量的數據中過濾出包含異常行為的句子,然后抽取異常行為句中包含的命名實體,最后利用抽取的實體構建異常行為共現網絡,為分析人員提供可視化的網絡輿情分析方法.
關鍵詞網絡輿情;事件抽取;異常行為識別;共現網;數據挖掘
近年來,我國網民規模一直呈現十分迅速的增長趨勢,在全球互聯網中占據越來越重要的位置.隨之而來的是網絡數據的急速增加,互聯網已經成為我國最大的社交平臺和信息集散地.據中國互聯網信息中心(China Internet Network Information Center, CNNIC)于2015年1月發布的第35次中國互聯網發展狀況調查統計報告顯示,我國網民規模和互聯網普及率較上年有明顯提升.伴隨著我國網絡規模的不斷擴大,網絡媒體被越來越多的民眾認可和使用,成為一種新的信息傳播方式,并且漸漸地超越了傳統媒體,為信息的發布、傳遞和獲取帶來了更方便和快捷的全新概念.
與傳統的信息傳播媒體相比較而言,網絡媒體上的信息交流具有門檻低、規模大、傳播迅速、參與群體龐大、實時性強等特點,再加上BBS論壇、微博、博客、新聞跟帖等社交媒體的虛擬隱蔽性等特點,導致廣大網民積極地通過網絡參與熱點話題的討論與傳播,這些熱點話題大多屬于網絡新聞.在參與熱點話題的過程中,網民會對社會熱點表達自己的觀點,如果這種觀點引起了較大范圍網民的關注和共鳴,并通過網上討論、跟帖、轉帖等逐步形成一種網絡輿論傾向,就形成了網絡輿情.
網絡輿情中最引人關注的是現實中發生的,民眾熱切關注和議論并蘊含有“ 破壞 ”、“ 危害 ”、“ 損失 ”等涉及公共安全或涉及司法公正的行為.本文將這些行為定義為異常行為.異常行為通常關系到廣大民眾的切身利益,影響到社會的安定和諧.而且部分網民通過網絡進行個人情緒的發泄,從而發表一些過激片面的言論.部分反動或恐怖組織也會利用網絡發布虛假反動的信息,這類信息通常就屬于異常行為.由于信息傳播的不對稱性,大多數網民是無法辨別這些信息真偽的,很多人會盲目相信并傳播這些虛假言論,從而影響政府的形象和社會的安定.因此,及時地發現網絡中的異常行為并辨別其真實性至關重要.對于真實發生的異常行為,要調查核實并維護社會公平正義,對于虛假宣傳的異常行為,需要及時停止其在網絡上的傳播和擴散,以免產生更大的危害.
本文利用信息抽取的技術識別異常行為.信息抽取(information extraction, IE)是把文本里包含的信息進行結構化處理.抽取出的是結構化或半結構化的信息,將抽取結果存儲到數據庫中,方便人們進行相關的查詢和處理,從而在很大程度上提高人們的工作效率.本文根據事件抽取的相關概念,定義異常行為的識別對象和方法.事件抽取本質上是信息抽取領域一個很重要并且應用十分廣泛的研究方向,在信息檢索等諸多領域都有著廣泛的應用.在事件抽取領域主要有2個權威的研究機構:信息理解研討會議(Message Understanding Conference, MUC)[1]和自動內容抽取(automatic content extraction, ACE)會議[2].
MUC會議是ACE會議的前身,每2年舉辦一次,只從1987年維持召開到1998年,總共舉行了7屆,但即使如此,它也為事件抽取的任務目標與相關理論的制定做出了相當大的貢獻.在MUC會議停止召開后的2000年開始至今,美國NIST組織舉辦了ACE自動內容抽取會議,該會議召開后,由于其與信息理解研討MUC會議研究內容和研究領域的相似性,人們就認為該會議是MUC會議的擴展和延伸,被越來越多的專業人士所認可和關注,該會議所制定的抽取標準和目標也就自然而然成為了該領域比較權威的標準.
ACE將事件抽取的任務進行了更明確的規定,將其定義為事件的檢測與識別(event detection and recognition, VDR),即我們進行事件抽取的目標是從大量的文本數據中識別出所關注的某些特定類型的事件描述句,并對這些事件描述句進行相關信息的確定和抽取,例如事件的類型和子類型、事件的元素等.
現階段進行事件抽取有2種方法被廣泛應用,即模式匹配和機器學習,這2種方法各有利弊,針對不同領域的事件抽取任務,可采用對應的抽取方法.代表性的工作有1995年Riloff和Shoen[3]提出的基于無標注語料的自動事件抽取方法、 2001年Yangarber[4]提出的基于種子模式的自舉信息抽取模型學習系統ExDisco系統,這個系統以人工構造的質量較高的種子模板為基礎,多次迭代增量式地學習新的模板.2002年Chieu和Ng[5]在事件元素抽取問題上首次引入了最大熵分類器.2005年姜吉發[6]提出了基于領域無關概念知識庫的事件抽取模式學習方法GenPAM,它的優點是完全無指導,且對于標注語料基本沒需求.需要人工參與的部分只是要給出事件抽取的事件類型、事件元素及其所屬角色,最后人工對學習到的模式進行評價.如此,自動學習事件抽取模板,大幅度地減少了需要人工參與的工作量.2006年Ahn[7]將MegaM和TiMBL這2種機器學習方法進行結合并在ACE語料庫驗證證明優于單一算法的性能.2007年于江德等人[8]使用隱Markov模型(HMM)完成事件元素的抽取.2009年Chen和Ji[9]打破了事件抽取中分類的思想,從序列標注的角度來識別事件.同年付劍鋒等人[10]提出了基于依存分析的事件識別.2010年Llorens等人[11]使用CRF模型進行TimeML事件抽取中的語義角色標注,提升了系統的性能.同年許紅磊等人[12]提出自動識別事件類別的中文事件抽取技術,取得較好的效果.由于基于機器學習的事件抽取方法客觀高效的優點,目前國內外大多采用機器學習的方法進行事件抽取,而本文只需要識別事件類別,因此也采用該方法進行事件類型識別.
本文提出異常行為識別,基于此構建異常行為共現網的方法, 為蘊含在網絡中的異常行為提供可視化的分析方法.
1異常行為識別研究綜述
1.1異常行為識別相關概念
定義1. 事件.由觸發詞和描述時間結構的元素組成,表示一個動作的發生或狀態的變化.往往由動詞驅動,也可以由能表示動作的名詞等其他詞性的詞來觸發,它包括參與該動作行為的主要成份(如人物、地點、時間等).
定義2. 觸發詞.觸發詞是最能表現事件發生的詞語,通常是一個動詞或者能夠代表動作發生的名詞.
定義3. 事件描述句.事件描述句是文本中描述事件信息的句子或片段,通常包含了一個觸發詞.
定義4. 異常行為.現實中發生,民眾熱切關注和議論并蘊含有“破壞”、“危害”、“損失”等涉及公共安全或涉及司法公正的行為.
1.2異常行為識別研究目標
進行異常行為識別首先要確定我們需要關注的行為類型.本文中采用的是ACE中定義的事件類型,包括 8個大類和33個子類,如表1所示:
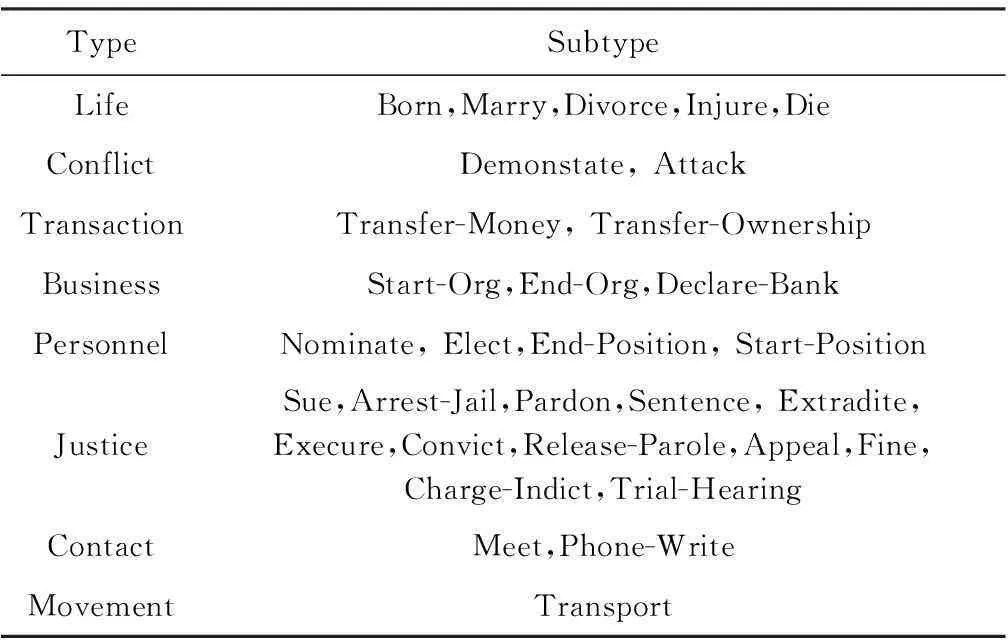
Tabel 1 Type of Event Defined in ACE
根據定義4,我們關注的是現實中發生,民眾熱切關注和議論并蘊含有“破壞”、“危害”、“損失”等涉及公共安全或涉及司法公正的行為.這些行為類型是ACE中定義的全部事件類型的子集.根據研究的需要和項目的需求,我們定義本文關注的異常行為類型是攻擊行為、受傷行為、死亡行為、拘捕行為4類,分別對應ACE事件類型中的Attack,Injure,Die,Arrest-Jail.
一個典型的事件抽取通常會識別事件的6個要素,我們將其作為一個六元組,即trigger,type,subject,object,time,place,其中,trigger表示引發事件發生的觸發詞,每個觸發詞一般觸發一種異常行為,從一定程度上決定了行為的類型;subject表示事件的行為主體,是動作活動的發起、狀態的主體,是有生命的人;object表示事件涉及的行為客體,是行為中的動作活動所涉及或者影響到的人或事物,是行為的被動承受者;time表示事件發生的時間;place表示事件發生的地點.六元組中的trigger和type不能為空,其他項為可選項,可以為空.以下面的新聞報道為例:
“2013年6月26日凌晨5時50分許,新疆吐魯番地區鄯善縣魯克沁鎮發生暴力恐怖襲擊案件,多名暴徒先后襲擊魯克沁鎮派出所.這是在新疆發生的民族分裂分子有預謀、有組織策劃制造的公然擾亂社會秩序、制造恐怖氣氛的惡性案件.”
這段話中就包含一個典型的事件,其中,觸發詞“襲擊”觸發了一個攻擊行為,再進一步分析句子中有關的主體、客體、時間、地點信息,可以得到完整的六元組“襲擊”,“攻擊行為”,“多名暴徒”,“魯克沁鎮派出所”,“2013年6月26日凌晨5時50分許”,“新疆吐魯番地區鄯善縣魯克沁鎮”.
由于傳統的事件識別正確率低,根據ACE評價標準,目前相關研究的性能在30%左右.其原因首先在于需要抽取觸發詞,行為主體、客體、時間、地點等事件要素,抽取性能較差;其次在開放的大數據環境下,數據的異質性、噪音、碎片化等特點,更加影響抽取性能.而本文提出的基于句子分類的異常行為識別方法先將帶異常行為的句子識別出來,再抽取異常行為句中的觸發詞、實體和實體的共現關系,相比ACE定義的事件抽取性能更好.同時識別出的句子加入人工干預,可以輔助輿情分析人員,提高效率.
本文的研究目標是從實際爬取的大量網絡輿情文檔集中,識別出攻擊、受傷、死亡、拘捕4類異常行為,并存儲在數據庫中,便于人們進行查詢,及時了解網絡輿情熱點信息,并且可以幫助政府更好地分析具有某種行為傾向的人和地點等信息,對決策做出一定的支持.
本文進行異常行為識別的具體目標有3點:
1) 識別出異常行為句.即為該新聞片段的第1個句子.
2) 判斷異常行為類型.該異常行為屬于攻擊行為.
3) 構建異常行為共現網.將異常行為句中的實體及其共現關系表示在異常行為共現網中并進行相關分析.如新疆吐魯番地區鄯善縣魯克沁鎮、多名暴徒、魯克沁鎮派出所這3個實體出現在一個異常行為句中,它們都屬于共現網中的節點,并且兩兩有共現關系.
1.3研究框架和技術路線
本文的研究框架如圖1所示:
圖1研究框架共分為4個部分:事件識別、異常行為句識別、異常行為共現網構建和共現網絡分析.其中,異常行為句識別和異常行為共現網構建這2部分是整個系統的核心部分,事件識別是預處理階段,共現網絡分析屬于擴展部分.
識別過程可以概括為3個步驟:
1) 預處理.采用LDA模型對網絡輿情文檔集進行文檔事件識別,對識別出的每個文檔事件分別進行后續操作.該階段可以識別出多個文檔事件,如釣魚島事件、占中事件等,為后續的操作提供輸入.通過對文檔事件單獨進行操作,每次處理的數據量更小且更有針對性.
2) 異常行為識別階段.首先根據觸發詞表,用觸發詞檢測的方法初步過濾掉非異常行為句,得到候選異常行為句的集合.然后用ACE的標準數據集訓練SVM異常行為識別分類器,選取句子的全詞特征[13]作為特征向量.最后用訓練好的分類器對候選異常行為句進行異常行為識別,并判斷行為類型.
3) 構建異常行為共現網.利用中國科學院分詞工具進行命名實體識別,將出現在同一個異常行為句中的實體定義為有共現關系.用igraph構建出包含關鍵實體及其共現關系的異常行為共現網,為異常行為提供可視化的分析方法.
2異常行為識別流程
2.1觸發詞檢測
1) 問題分析
在開放的網絡環境中爬取的網絡輿情數據具有數量大和異質性等特點.其中包含大量的無用和干擾數據,如果對這些數據全都進行處理,不僅浪費時間,也會影響系統的處理結果和性能.觸發詞檢測可以去除噪音,過濾掉大量的無用數據,提高系統的效率.
異常行為是由具體的行為發生或狀態改變所引發的,描述句通常包含一個觸發詞.異常行為觸發詞可以直接引起異常行為的發生,是決定行為類型的重要特征.對于不含異常行為觸發詞的句子,我們認為該句子不含異常行為,直接將其過濾掉.因此,我們可以根據句子中觸發詞的有無進行初步過濾.下面針對每種異常行為類型分別給出了一個含有觸發詞的句子.
① 死亡(Die).警方一直緊隨其后,最終順利擊斃逃犯.觸發詞:擊斃.
② 攻擊(Attack).當天在加沙地帶和約旦河西岸地區仍有零星的沖突發生.觸發詞:沖突.
③ 拘捕(Arrest-Jail).電焊工王呈泰等12名犯罪嫌疑人已被檢查機關批準逮捕.觸發詞:逮捕.
④ 受傷(Injure).巴基斯坦方面說:最近在平泊爾地區,有很多士兵被打傷.觸發詞:打傷.
2) 實驗數據集
本文采用的實驗數據分為2個部分:①ACE2005中文語料庫的682篇新聞報道;②人工標注網絡爬蟲爬取的真實網絡輿情數據318篇(條).其中ACE2005語料是由ACE評測會議發布,其中的中文語料分布如表2所示:
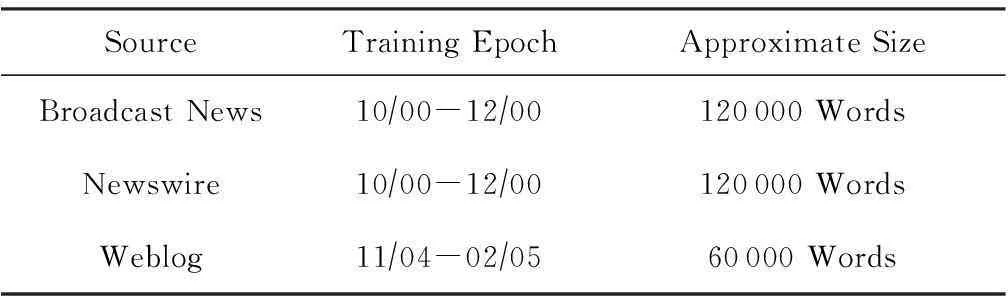
Table 2 2005ACE System Training Corpus Statistics for
Indication:1) Chinese Resources (1.5characters=1word);
由2部分數據構成的實驗數據總體分布如表3所示:
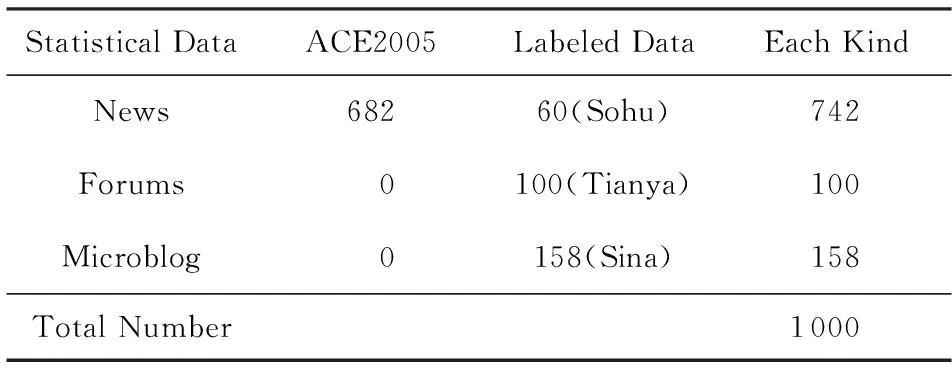
Table 3 Distribution of Data
Indication:Units of the numbers in the table is sheet or post.
3) 問題解決
基于詞的觸發詞檢測的首要任務是建立初始的觸發詞表,實驗數據所包含的1 000篇中文文檔進行統計,33個子類別的觸發詞共計976個.進一步對這976個觸發詞篩選,選出其中的4個子類別“Attack”,“Injure”,“Die”,“Arrest-Jail”的觸發詞來構建初始的觸發詞表,所構建的觸發詞表一共包含338個觸發詞,具體內容如表4所示:
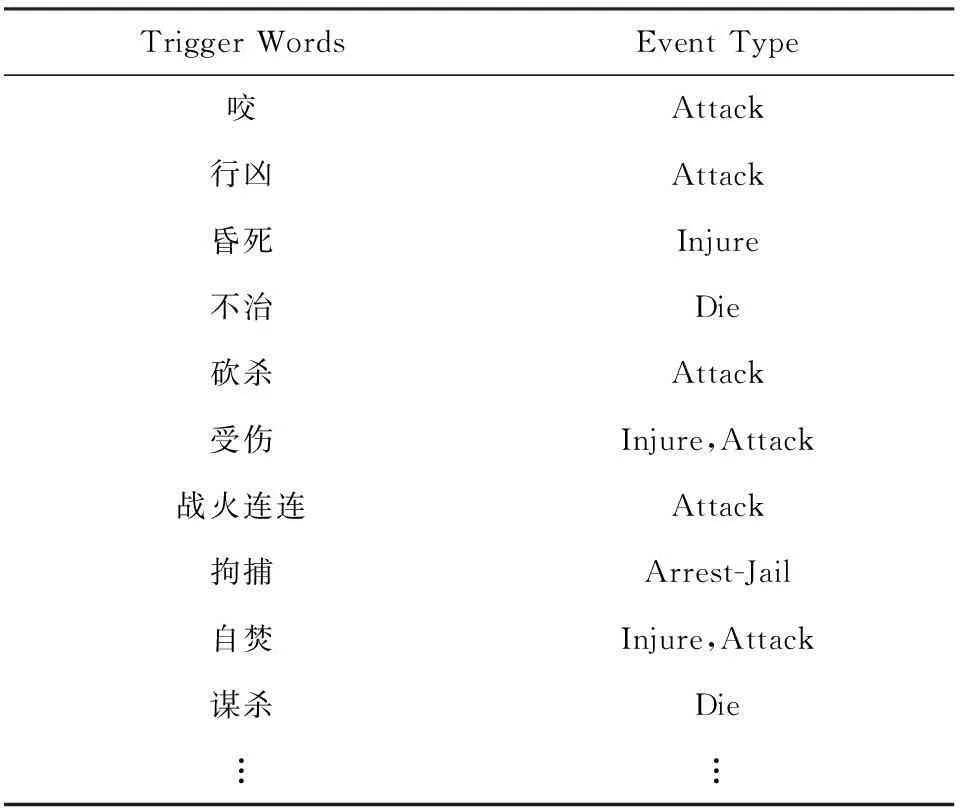
Table 4 Trigger Words
根據觸發詞表,采用基于關鍵詞匹配的方法,對于S中的每個句子進行檢測,過濾掉不含異常行為觸發詞的句子,得到候選異常行為句的集合S′.
2.2異常行為識別分類器
1) 構建分類器的原因
雖然“觸發詞”被定義為“最能表現事件發生的詞語”, 但并不意味著“觸發詞的出現一定代表了事件的發生”.例如“謀殺”這一觸發詞,在句子“根據加州法律,不管有意或無意殺害火車上的人,光是這一點就足以構成謀殺罪”中,這只是謀殺罪的一種構成方式,實際上并沒有謀殺行為的發生.本文關注的是例如“他被控于1989年同其他幾名成員一道將一名試圖脫離這個組織的21歲的成員謀殺”句子中“謀殺”所觸發的“Die”事件.因此,只通過句子有無觸發詞來判斷異常行為的發生是不一定正確的.
為了驗證觸發詞的出現是否代表著事件的發生,本文對觸發詞表中的每個觸發詞統計其在ACE語料中出現的總次數以及觸發事件的次數,統計結果如表5所示:
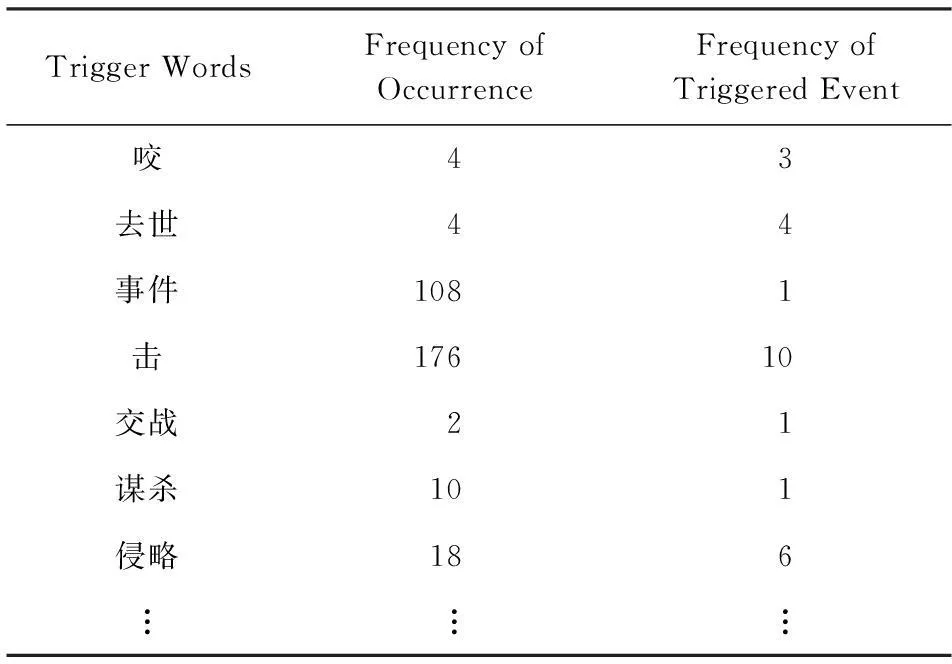
Table 5 Frequency of Triggers and Events
對表5中的出現總次數和觸發事件次數的對應關系分析,得到表6:

Table 6 Ratio of Triggers and Events
因此需要選擇合適的分類器篩選出真正地代表了4類事件發生的觸發詞所在的異常行為描述句,本文選擇支持向量機(support vector machine, SVM)分類器,這是由于SVM能夠將非線性的問題轉化為高維空間的線性問題,從很大程度上降低了問題的難度,并且依據結構風險最小化的原則和核函數的思想,在解決有限樣本的非線性以及高維模型識別問題中表現出優于其他模型的性能.而本文就選用了高維特征,因此SVM能更好地用于解決本文的分類問題,下面對SVM的具體原理以及本文如何使用SVM進行詳細介紹.
2) SVM概述
SVM 是對線性分類器的一種最佳設計準則,1965年由Vapnik和Cortes在統計學習理論基礎上提出之后就被人們廣泛應用,SVM的主要思想概括為2點:
① SVM本質上只分析和處理線性可分的情況,對于線性不可分的樣本,它會通過非線性映射算法將低維空間的樣本映射到高維空間的方法使得線性不可分的樣本變得可分,從而就可以對這些高維空間的樣本進行線性處理,降低處理的復雜度.
② SVM為使分類的風險最小化,在特征空間中構建分割平面的時候,會構建使得學習器得到全局最優化的分割平面,并且在分類時的全局期望風險以某個概率滿足一定上界,從而可以達到較好的分類效果.二元分類問題的最優分割平面滿足:
w·x+b=0,
(1)
其中,w·x為多維向量,表示向量與向量的內積.最優平面要求:如果訓練樣本被平面正確切分,并且距離平面越近的訓練樣本與平面的間距越大.最小化的約束條件為所有的數據點到最優平面的距離大于1,并且保證訓練樣本被正確切分.同時,引入非松弛變量來解決部分樣本不能被正確地分類的情況,因此平面最優解問題可以被表示為
(2)
其中,εi≥0,i=1,2,…,n.
目前,SVM的開源工具有很多,其中使用最多的是臺灣大學的林智仁教授等人開發的一個用于支持向量機分類的開源庫LibLinear,它也可以用來解決多類分類問題.LibLinear由于程序小、運用靈活、輸入參數少、易于擴展等優點成為目前國內應用最多的SVM庫.目前有C++,Python,Java,R,Matlab等多種語言的接口,可以方便地在Windows或Unix平臺下使用.另外,Windows平臺下還有可視化操作工具SVM-toy.
3) 特征選擇
本文訓練分類器所用的實驗數據共有1 000篇標注過的新聞文檔.要訓練分類器,首先要選擇合適的分類特征,由于分類器處理的是候選異常行為句這樣的短文本,信息量較少,為了充分利用句子的信息,我們選用全詞特征,逐字掃描句子,若匹配到在詞典中出現的詞,就把該詞放入特征向量中,這樣,句子中所有潛在的詞都被放入特征向量中,向量的維度就是詞典中詞的個數.全詞特征解決了傳統的分詞導致的詞語邊界錯誤問題,最大限度地利用句子中的信息.要想取得較好的效果,詞典的選擇就十分重要,我們將2個詞典合并作為本文的詞典.第1個詞典是The Lexicon Common Words in Contemporary Chinese.第2個詞典由ICTCLAS分詞工具對實際的輿情文檔集分詞得到,加入這個詞典以提高性能.
最后,抽取每個句子的全詞特征向量作為SVM分類器的輸入,訓練分類器.
2.3異常行為類型識別
第2.1節、第2.2節介紹了事件識別和觸發詞檢測,得到了候選異常行為句的集合.因此,現在只需要調用異常行為識別分類器對所有候選異常行為句進行分類.設C={-1,1,2,3,4}為行為類別的集合,-1代表非異常行為,1,2,3,4分別代表Attack,Injure,Die,Arrest-Jail這4種異常行為類型.我們的目標是識別每個句子對應的行為類別.
2.4實驗結果
1) 觸發詞檢測:The Peoples Daily的所有文檔中共檢測出579 113個候選異常行為句.
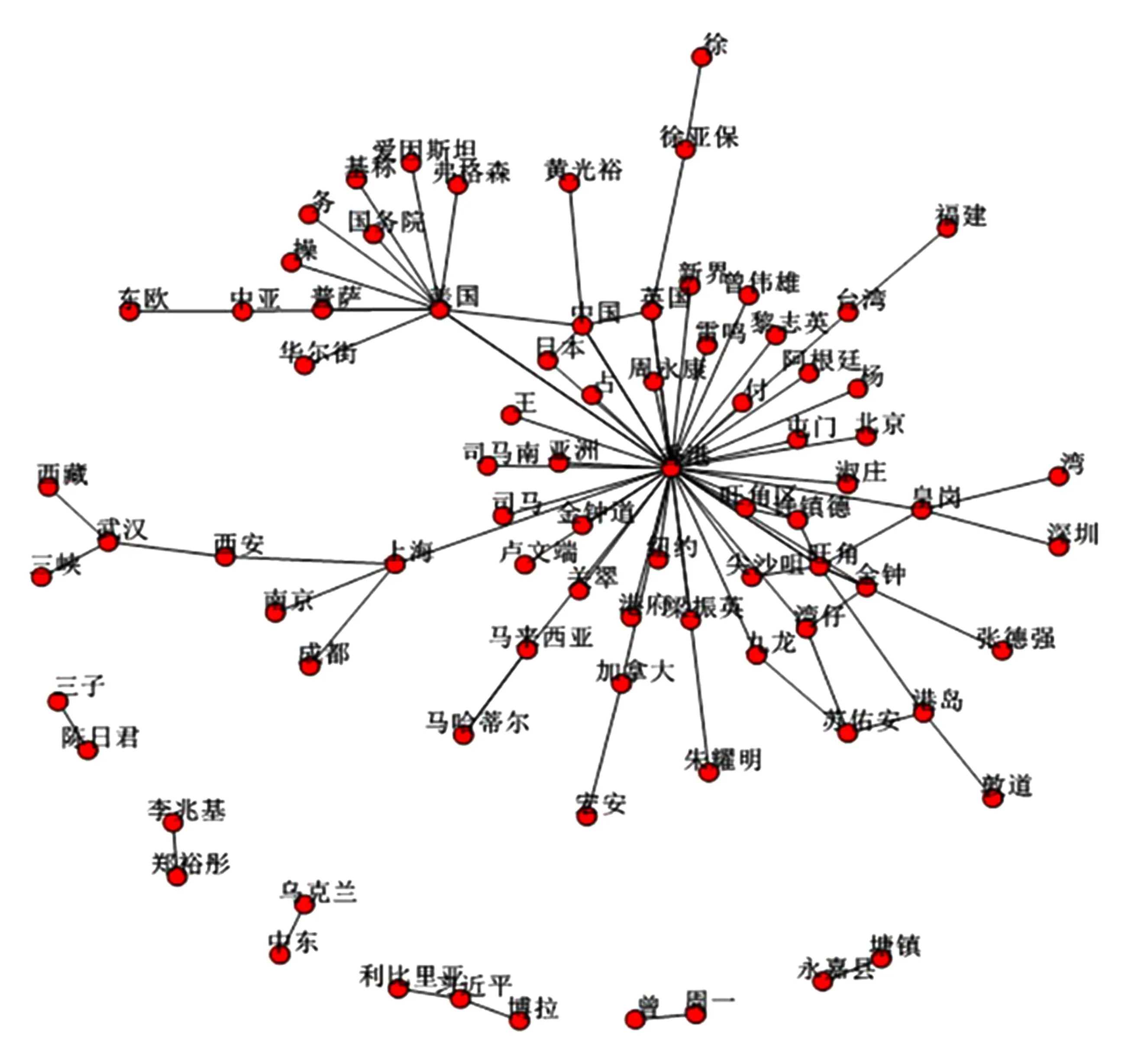
Fig. 2 Abnormal behavior co-occurrence network 1.圖2 異常行為共現網1
2) 異常行為識別分類器:一般情況(分類器的預測值大于0.5時,輸出為正例)下的性能如表7所示:
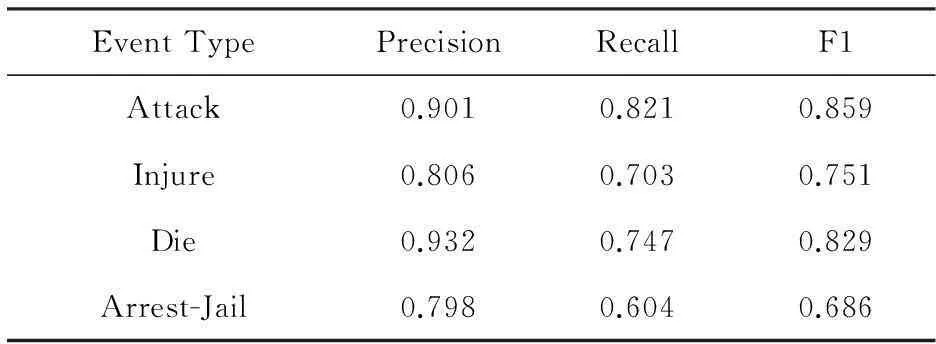
Table 7 Performance of Classifier
改進的方向是:在開放的大數據條件下,異常行為的數量十分龐大,因此我們更加注重識別的準確率而不是召回率.可以通過提高分類器的預測值來使準確率提高、召回率降低,符合我們的要求.
3) 異常行為識別:在所有的候選異常行為句中,共檢測出41 830條異常行為.
3異常行為共現網
異常行為共現網本質上來說是一種異質網絡,網絡中的每個點是一個實體(人名、地名、組織名),將這些實體作為共現網中的節點,對于共同出現在一個異常行為句中的實體,認為它們有共現關系,在共現網中給出連線.這樣,將一個事件中的所有實體及它們的關系都表現在共現網中就構成了異常行為共現網.
命名實體識別之后我們已經得到了異常行為句中的實體及其關系,可以根據共現次數篩選出其中的關鍵實體,將這些實體作為節點,實體關系作為邊,我們就得到了異常行為共現網.
我們還可以對共現網進行相關分析,如網絡拓撲分析,焦點分析和異常路徑分析.具體來說,我們可以從節點的度,節點所經過的最短路徑的條數以及節點與其他節點之間的路徑長度等角度來進行分析,從而挖掘共現網中中心性高的節點或比較關鍵的節點,并且衡量2個節點之間關系的密切程度.
以香港占中事件為例,數據庫中共有757條記錄,記錄中包含異常行為句2 587個、實體數245個、共現關系249個,我們分別采用2種策略構建共現網,根據共現次數多的方法構建的網絡如圖2所示:
從圖2可以看出,很多實體都與“香港”這個實體共現組成實體對,“香港”處于網絡比較中心的位置,該網絡就顯示出了與“香港”這個中心節點共現次數最多的節點,結合實際,網絡中表現的就是香港占中事件中,“香港”是中心節點以及與它共現次數最多的其他在該事件中比較關鍵的節點,從而可以幫助輿情分析人員及時發現熱點事件中的關鍵實體(人名、地名、組織名),并及時采取相應舉措控制和引導輿情向正常的方向發展.
根據度數最大的方法構建的網絡如圖3所示:
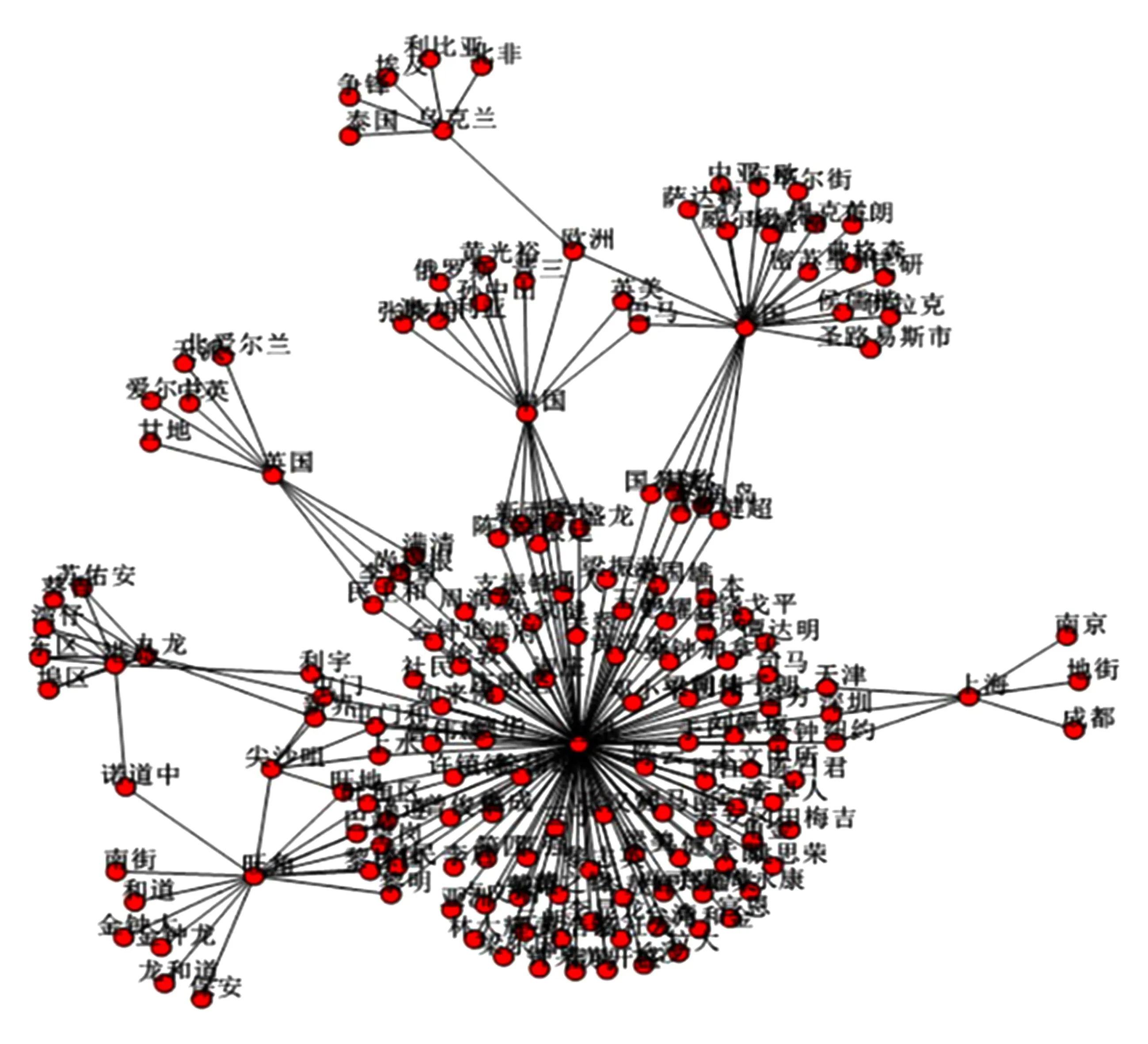
Fig. 3 Abnormal behavior co-occurrence network 2.圖3 異常行為共現網2
從圖3可以看出,在香港占中事件中,度數最大的一些節點分別是“香港”、“美國”、“中國”、“英國”、“九龍”、“旺角”等,這些都是該事件中比較重要的一些地點,需要重點分析它們之間的聯系,網絡中還有與這些關鍵節點共現過的其他節點,可以進行輔助分析,通過分析可以掌握關鍵節點之間的隱含聯系,為輿情分析和決策做出一定的支持.
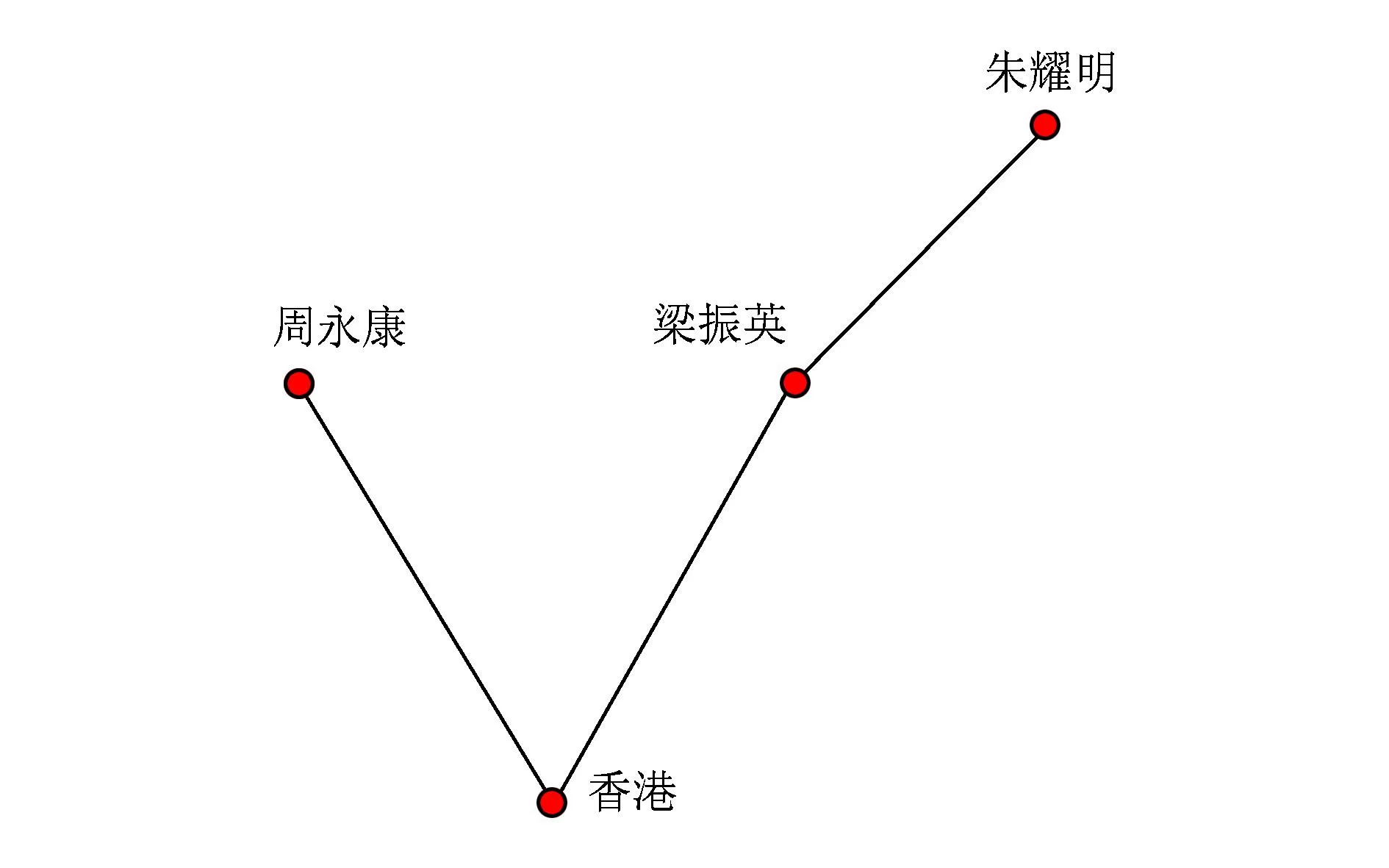
Fig. 4 Analysis of abnormal path.圖4 異常路徑分析
對于2種共現網絡,我們都可以對其進行異常路徑分析和焦點分析,對于網絡中的任意2個實體節點,我們都可以找出它們之間的所有路徑和最短路徑,從而分析該實體對與路徑上的實體之間的關系以及是如何通過這些實體進行連接的.例如在圖4中,“周永康”和“朱耀明”這2個支持占中的人名之間的最短路徑上就有“香港”和“梁振英”.擁有較高度數的節點,與其他較多節點之間有最短路徑的節點,其他節點對之間的最短路徑通過次數較多的節點等具有較高的“中心性”,把中心性高的節點作為網絡中的焦點進行重點分析,也可以根據網絡的動態變化來動態跟蹤關鍵實體.這些分析都是現實可行的,可以挖掘出某些熱點事件中隱含的信息,對決策做出一定的支持,有很重要的理論和現實意義.
4總結與展望
4.1工作總結
本文主要探索了對網絡輿情文本進行事件抽取的研究,采用事件抽取的主流會議ACE中對事件和事件抽取子任務的定義,結合本文所依托的課題背景和網絡輿情分析的需求,對網絡輿情分析中關注的4類異常行為進行抽取.
本文通過對真實數據的實驗驗證了該原型系統的有效性和可行性.論文的主要工作可以總結如下:
1) 根據ACE中對事件的定義并結合本文的研究需求,明確本文中事件的定義.結合網絡輿情的研究現狀和本文的研究需求,確定本文的抽取目標.
2) 對網絡輿情數據進行事件識別和觸發詞檢測,過濾干擾數據.
3) 使用合適的特征來訓練異常行為識別分類器,進行行為類別識別.
4) 構建異常行為共現網,為輿情分析提供可視化的研究方法.
5) 開發基于本文工作的原型系統,并在真實數據上進行驗證.
4.2未來展望
面向網絡輿情數據的異常行為識別是一個非常有意義的方向,可以從3個方面對本文的工作進行擴展和改進:
1) 完善未知觸發詞識別.本文目前采用的觸發詞表是固定大小的,包含了大部分的觸發詞,必定也會有一些觸發詞的遺漏,這樣有一些異常行為句就在觸發詞檢測時被錯誤過濾掉,影響了整體的性能.因此我們在下一步的工作中需要完善觸發詞表,可以采用基于詞語構詞結構和語義相似度的方法來識別未知觸發詞,并將其加入原有觸發詞表中,或者在本文方法的基礎上使用基于監督的方法來動態擴展觸發詞表.
2) 完善對分類特征的選擇.本文采用的分類特征是全詞特征,更加注重的是句子在詞法方面的信息,而要對異常行為進行分類,僅僅有詞法信息是不夠的,因此我們下一步需要在特征中加入更多的語法和語義信息,比如可以選擇句子中觸發詞左右的n個詞及其詞性作為分類特征,完善異常行為識別分類器的分類效果.
3) 完善對異常行為共現網的分析.本文構建了異常行為共現網,但并沒有進行共現網的詳細分析.因此未來需要完善網絡的分析,更加明確地體現出異常行為共現網的應用價值.
參考文獻
[1]Grishman R. Message Understanding Conf (MUC)[EBOL]. Philadelphia, PA: University of Pennsylvania1. (2002-07-01) [2013-07-21]. http:en.wikipedia.org-wikiMessage_Understanding_Conference
[2]Garofolo J. Automatic Content Extraction (ACE)[EBOL]. Philadelphia, PA: University of Pennsylvania1. (2005-07-01) [2013-07-21]. http:www.itl.nist.goviadmig-testsace2005
[3]Riloff E, Shoen J. Automatically acquiring conceptual answer patterns without an annotated corpus[C]Proc of the 3rd Workshop on Very Large Corpora. San Francisco: Morgan Kaufmann, 1995: 148-161
[4]Yangarber R. Scenario customization for information extraction[D]. New York: New York University, 2001
[5]Chieu H L, Ng H T. A maximum entropy approach to information extraction from semi-structured and free text[C]Proc of the 18th National Conf on Artificial Intelligence. Edmonton, Alberta: American Association for Artificial Intelligence, 2002: 786-791
[6]Jiang Jifa. A method to do Chinese event ie from a multiple sentences’ event narration[J]. Computer Engineering, 2005, 31(2): 27-29 (in Chinese)(姜吉發.一種跨語句漢語事件信息抽取方法[J]. 計算機工程, 2005, 31(2): 27-29)
[7]Ahn D. The stages of event extraction[C]Proc of the Workshop on Annotations and Reasoning about Time and Events. Stroudsburg, PA: Association for Computational Linguistics, 2006: 1-8
[8]Yu Jiangde, Xiao Xinfeng, Fan Xiaozhong. Event information extraction from Chinese text based on hidden Markov models[J]. Microelectronics & Computer, 2007, 24(10): 92-94 (in Chinese)(于江德, 肖新峰, 樊孝忠. 基于隱馬爾可夫模型的中文文本事件信息抽取[J]. 微電子學與計算機, 2007, 24(10): 92-94)
[9]Chen Z, Ji H. Language specific issue and feature exploration in Chinese event extraction[C]Proc of Human Language Technologies: The 2009 Annual Conf of the North American Chapter of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2009: 209-212
[10]Fu Jianfeng, Liu Zongtian, Fu Xuefeng, et al. Dependency parsing based event recognition[J]. Computer Science, 2009, 36(11): 217-219 (in Chinese)(付劍鋒, 劉宗田, 付雪峰, 等. 基于依存分析的事件識別[J]. 計算機科學, 2009, 36(11): 217-219)
[11]Llorens H, Saquete E, Navarro-Colorado B. TimeML events recognition and classification learning CRF models with semantic roles[C]Proc of the 23rd Int Conf on Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2010: 725-733
[12]Xu Honglei, Chen Jinxiu, Zhou Changle, et al. Research on event type identification for Chinese event extraction[J]. Mind and Computation, 2010, 4(1): 34-44 (in Chinese)(許紅磊, 陳錦繡, 周昌樂, 等. 自動識別事件類別的中文事件抽取技術研究[J]. 心智與計算, 2010, 4(1): 34-44)
[13]Chen Yanping, Zheng Qinghua, Zhang Wei. Omni-word feature and soft constraint for Chinese relation extraction[C]Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2014: 572-581

Hao Yazhou, born in 1989. PhD candidate in Xi’an Jiaotong University. Student member of China Computer Federation. His research interests include data mining, natural language processing and social media mining.

Zheng Qinghua, born in 1969. Professor and PhD supervisor. His main research interests include multi-media e-learning, computer network security, intelligent e-learning theory and algorithm.

Chen Yanping, born in 1980. PhD candidate in Xi’an Jiaotong University. His research interests include natural language processing, information extraction and data mining.

Yan Caixia, born in 1992. Master candidate in Xi’an Jiaotong University. Her research interests include information extraction and data mining.
中圖法分類號TP391
通信作者:鄭慶華(qhzheng@mail.xjtu.edu.cn)
基金項目:國家自然科學基金項目(91118005,91218301,91418205);國家“八六三”高技術研究發展計劃基金項目(2012AA011003)
收稿日期:2015-10-29;修回日期:2015-11-18
This work was supported by the National Natural Science Foundation of China (91118005,91218301,91418205) and the National High Technology Research and Development Program of China (863 Program) (2012AA011003).
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
