基于HMM的主題爬蟲(chóng)問(wèn)題研究
2016-04-24 09:05:02曹琨
河南科技 2016年17期
曹琨
(新鄉(xiāng)學(xué)院計(jì)算機(jī)與信息工程學(xué)院,河南 新鄉(xiāng) 453000)
基于HMM的主題爬蟲(chóng)問(wèn)題研究
曹琨
(新鄉(xiāng)學(xué)院計(jì)算機(jī)與信息工程學(xué)院,河南 新鄉(xiāng) 453000)
對(duì)HMM爬蟲(chóng)中K-means算法的K值選取方法作出相應(yīng)改進(jìn),然后針對(duì)爬取網(wǎng)頁(yè)的內(nèi)容與主題相關(guān)度不高的問(wèn)題,對(duì)隱馬爾科夫模型的假設(shè)條件進(jìn)行修改,完成改進(jìn)后的隱馬爾科夫爬蟲(chóng)設(shè)計(jì)。
網(wǎng)絡(luò)爬蟲(chóng);算法;改進(jìn)
隱馬爾科夫模型(Hidden Markov Model,HMM)應(yīng)用比較廣泛。最初應(yīng)用于通信工程領(lǐng)域,進(jìn)行信號(hào)處理,之后被應(yīng)用到自然語(yǔ)言處理方面,成為自然語(yǔ)言處理和通信系統(tǒng)聯(lián)系的紐帶;再到后來(lái),機(jī)器學(xué)習(xí)比較流行,開(kāi)始用隱馬爾科夫模型。該模型用于機(jī)器學(xué)習(xí)時(shí),主要用鮑姆-韋爾奇訓(xùn)練算法。HMM是一種具有統(tǒng)計(jì)特性的隨機(jī)過(guò)程概率模型,在該模型中參數(shù)表示尤為重要,并且是由馬爾科夫鏈和一般隨機(jī)過(guò)程組成。本文主要利用馬爾科夫鏈的隨機(jī)過(guò)程模型對(duì)網(wǎng)絡(luò)爬蟲(chóng)予以改進(jìn)。
1 HMM主題爬蟲(chóng)框架
將HMM引入到主題爬蟲(chóng)后,增加了爬蟲(chóng)對(duì)網(wǎng)頁(yè)主題的識(shí)別能力,使用訓(xùn)練好的HMM可以很好地預(yù)測(cè)爬取路徑。但是,經(jīng)過(guò)對(duì)隱馬爾科夫數(shù)學(xué)模型和基于隱馬爾科夫主題爬蟲(chóng)的理論進(jìn)行分析研究,可以發(fā)現(xiàn)在傳統(tǒng)的HMM模型中有部分不合理的地方。
HMM爬蟲(chóng)運(yùn)行主要有3個(gè)階段:①初始階段,對(duì)相關(guān)參數(shù)進(jìn)行設(shè)置,選定初始網(wǎng)頁(yè)初始訓(xùn)練集,進(jìn)行頁(yè)面預(yù)處理等;②學(xué)習(xí)階段,對(duì)網(wǎng)頁(yè)進(jìn)行文本相關(guān)度計(jì)算、類型聚類和構(gòu)建隱馬爾科夫模型訓(xùn)練優(yōu)化;③運(yùn)行階段,用優(yōu)化后的隱馬爾科夫模型對(duì)查找到的主體相關(guān)的站點(diǎn)進(jìn)行分析,主要包括網(wǎng)頁(yè)內(nèi)容相關(guān)度判斷和超鏈接分析處理,將分析結(jié)果儲(chǔ)存起來(lái),根據(jù)網(wǎng)址路徑爬取網(wǎng)頁(yè)到本地服務(wù)器。
經(jīng)過(guò)研究發(fā)現(xiàn),傳統(tǒng)的隱馬爾科夫模型爬蟲(chóng)存在以下幾個(gè)缺點(diǎn):①和一些經(jīng)典爬蟲(chóng)算法相比,HMM爬蟲(chóng)時(shí)間消耗較大,其建模方法和算法有待改進(jìn);②在HMM爬蟲(chóng)抓取的網(wǎng)頁(yè)中,主題相關(guān)度還有待提高;③對(duì)訓(xùn)練集處理過(guò)于簡(jiǎn)單,影響了爬行過(guò)程精確度,導(dǎo)致主題相關(guān)度降低很多。
2 改進(jìn)HMM模型聚類策略
網(wǎng)頁(yè)數(shù)據(jù)聚類是將網(wǎng)頁(yè)數(shù)據(jù)按照相似性進(jìn)行分類的過(guò)程,不同類中的網(wǎng)頁(yè)對(duì)象有很大的相異性。具體過(guò)程是:首先需要一個(gè)給定的分類體系和訓(xùn)練樣本集,如“天眼輿情分析系統(tǒng)”中的中文網(wǎng)頁(yè)分類體系,其將所有網(wǎng)頁(yè)分為15個(gè)大類,即任何網(wǎng)頁(yè)都可以根據(jù)內(nèi)容歸屬到某一類樣本,這種利用已標(biāo)記樣本集對(duì)未知樣本進(jìn)行類別劃分的方法稱作“有監(jiān)督的學(xué)習(xí)方法”[1]。
K-means算法對(duì)網(wǎng)頁(yè)進(jìn)行聚類的主要思想是認(rèn)為兩個(gè)鏈接越近的網(wǎng)頁(yè)其相似度越大,這一思想看似簡(jiǎn)單,但要確定劃分類別的數(shù)量K,同類的相似度高,不同類的相似度低。通常K的值是用戶給定的,而K值大小對(duì)爬蟲(chóng)抓取的效率和準(zhǔn)確度有很大的影響,很多用戶難以確定K值的大小。目前,很多學(xué)者致力于K值獲取方法的改進(jìn)研究,比如利用圖論、距離代價(jià)函數(shù)和遺傳算法等。
3 改進(jìn)HMM模型頁(yè)面采集方法
3.1 頁(yè)面與主題相關(guān)度判定
在傳統(tǒng)的HMM爬蟲(chóng)系統(tǒng)中,采用空間向量模型(VSM)進(jìn)行網(wǎng)頁(yè)主題相關(guān)度計(jì)算,通過(guò)計(jì)算用戶給出的關(guān)鍵字在當(dāng)前頁(yè)面中的權(quán)值來(lái)判斷與頁(yè)面相關(guān)度,關(guān)鍵字出現(xiàn)在頁(yè)面中的位置也是衡量權(quán)值的重要因素。
將網(wǎng)頁(yè)頁(yè)面分成4個(gè)部分:頁(yè)面標(biāo)題、副標(biāo)題、重點(diǎn)強(qiáng)調(diào)文字和普通正文。權(quán)重分配如下:
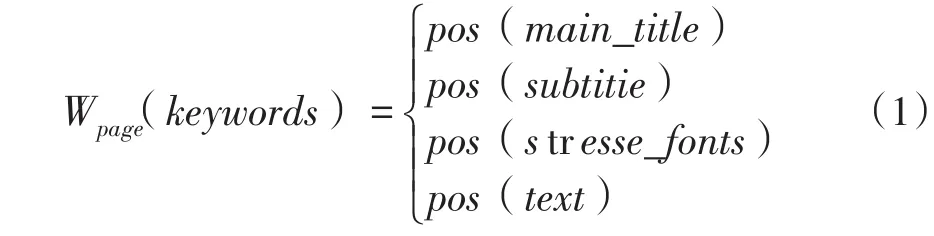
例如,關(guān)鍵字“Apple”在某個(gè)網(wǎng)頁(yè)P(yáng)的主標(biāo)題中出現(xiàn)了1次,正文中出現(xiàn)了5次,且強(qiáng)調(diào)字體出現(xiàn)3次,那么關(guān)鍵詞“Apple”在網(wǎng)頁(yè)P(yáng)中的權(quán)重計(jì)算方法為:
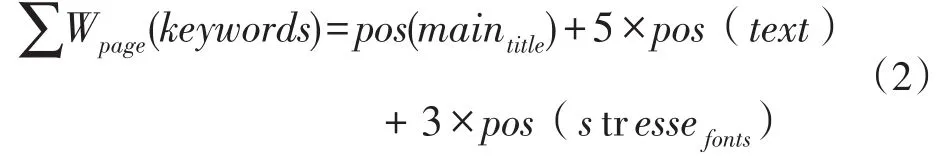
3.2 HMM爬蟲(chóng)建模方法改進(jìn)
HMM爬蟲(chóng)基本工作原理是根據(jù)頁(yè)面與查詢主題的相關(guān)度來(lái)抓取網(wǎng)頁(yè),如果相關(guān)則抓取,并且提取儲(chǔ)存此網(wǎng)頁(yè)的鏈接地址。如果不相關(guān)就舍棄,讀取下一個(gè)網(wǎng)頁(yè)。此方法最大弊端就是爬蟲(chóng)經(jīng)過(guò)判斷丟棄了不相關(guān)網(wǎng)頁(yè),而這些網(wǎng)頁(yè)中有可能存在著指向與主題相關(guān)度很高的超鏈接,這個(gè)問(wèn)題使爬蟲(chóng)丟失了部分有價(jià)值的頁(yè)面。這與HMM的假設(shè)條件和算法的不合理有關(guān)。HMM中存在如下2個(gè)假設(shè)。
假設(shè)1:系統(tǒng)狀態(tài)從t時(shí)刻向t+1時(shí)刻轉(zhuǎn)移時(shí),其轉(zhuǎn)移概率只與t時(shí)刻狀態(tài)有關(guān),與歷史狀態(tài)無(wú)關(guān),即:
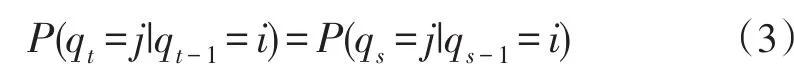
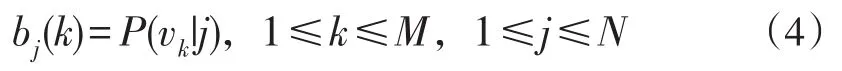
假設(shè)2:系統(tǒng)在時(shí)刻t輸出觀察值的概率只取決于當(dāng)前時(shí)刻1所處的狀態(tài)而與之前的狀態(tài)無(wú)關(guān),即:由于上述假設(shè)將網(wǎng)頁(yè)之間的鏈接關(guān)系割裂了,所以處理網(wǎng)頁(yè)之間的關(guān)系并不合理,如果和主題相關(guān)的網(wǎng)頁(yè)指向該網(wǎng)頁(yè)的概率大,那么就認(rèn)為這個(gè)網(wǎng)頁(yè)上的鏈接也有很大的概率指向該網(wǎng)頁(yè)。為了挖掘出頁(yè)面當(dāng)前狀態(tài)與歷史狀態(tài)之間的聯(lián)系,對(duì)上文兩個(gè)假設(shè)進(jìn)行如下修改。
假設(shè)1:系統(tǒng)狀態(tài)從t時(shí)刻向t+1時(shí)刻轉(zhuǎn)移時(shí),其轉(zhuǎn)移概率依賴于t和t-1時(shí)刻的狀態(tài),即:

假設(shè)2:系統(tǒng)在時(shí)刻t輸出觀察值的概率取決于系統(tǒng)當(dāng)前狀和系統(tǒng)前一時(shí)刻的狀態(tài),即:

本文在假設(shè)條件(5)和(6)的基礎(chǔ)上對(duì)HMM的學(xué)習(xí)算法Forward和Backward算法進(jìn)行了改進(jìn),此算法是在模型λ下計(jì)算產(chǎn)生觀察序列O=O0,O1…,Oi的概率,即P(O|λ)。
3.2.1 Forward算法。首先定義Forward變量?,如式(7)所示:
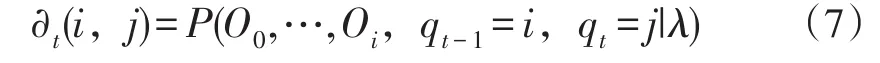
式(7)中,?t(i,j)表示在模型λ中,時(shí)刻為t時(shí),部分觀察值序列為P(O0,…,Oi)的概率。Forward變量?t(i,j)可以遞歸求解,步驟如下:
3.2.2 Backward算法。類似地定義Backward變量β,如式(8)所示:
式(8)中,1<t<T-1,0<i,j<N-1,Backward變量β(i,j)遞歸求解步驟如下:
初始化:βT-1(i)=1,0<i,j<N-1;
迭代:βt(i,j)=
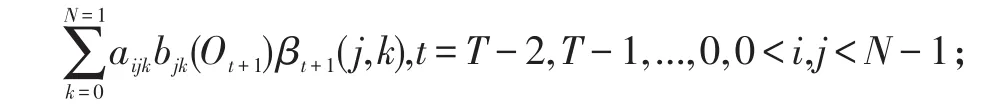
由此,根據(jù)Forward-Backward算法,在給定模型的情況下,產(chǎn)生觀察值序列的概率為:

4 結(jié)語(yǔ)
在傳統(tǒng)HMM爬蟲(chóng)的基礎(chǔ)上,對(duì)K-means算法中的K值的設(shè)置方法做了改進(jìn)。首先,通過(guò)訓(xùn)練集聚類策略,解決了用戶通過(guò)經(jīng)驗(yàn)來(lái)定義K值帶來(lái)的諸多問(wèn)題;其次,在傳統(tǒng)的方法上優(yōu)化了相關(guān)度的判別統(tǒng)計(jì)方法;最后,針對(duì)HMM爬蟲(chóng)爬取來(lái)的網(wǎng)頁(yè)與主題相關(guān)度不高的問(wèn)題,對(duì)兩個(gè)假設(shè)條件進(jìn)行了修改,從而改進(jìn)了HMM的建模方式。
[1]李光敏.文獻(xiàn)搜索引擎中特征項(xiàng)及權(quán)重的應(yīng)用[J].計(jì)算機(jī)系統(tǒng)應(yīng)用,2014(5):188-191.
Research on Topic Crawler Based on HMM
Cao Kun
(School of Computer and Information Engineering,Xinxiang College,Xinxiang Henan 453000)
This paper made corresponding improvement on K value selection method of K-means algorithm in HMM crawler,then aiming at the problem that the correlation between the content and theme of the crawled page is not high,improved the assumed condition of the hidden Markov model,and completed the improved hidden Markov crawler designing.
network crawler;algorithm;improvement
TP391.3
A
1003-5168(2016)09-0027-02
2016-08-20
曹琨(1983-),女,講師,碩士,研究方向:計(jì)算機(jī)科學(xué)與技術(shù)。
猜你喜歡
文萃報(bào)·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫(huà)報(bào)·益智版(2024年3期)2024-12-09 00:00:00
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
保健醫(yī)苑(2022年1期)2022-08-30 08:39:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
電腦愛(ài)好者(2011年11期)2011-06-22 08:20:18
河北軟件職業(yè)技術(shù)學(xué)院學(xué)報(bào)(2010年3期)2010-06-06 07:18:42
