服務可用性監控系統的設計與實現
2016-04-08 02:30:38侯興林王曉云
軟件 2016年2期
侯興林++王曉云

摘要:隨著互聯網服務研究的不斷深入,人們對網絡服務的依賴程度也日漸增加。尤其在一些實時性要求較高的網絡服務應用上,服務的后臺核心系統是否具備高可用性,已經是影響該服務質量的關鍵因素。本文研究了針對服務可用性監控的服務可用性監控系統架構,提出了一個基于分層架構實現的多模塊服務可用性監控系統,架構可以對接入的服務進行實時的監控,并展示該服務的實時可用性數據,從而可以在服務出現故障的時候快速的對其報警。
關鍵詞:可用性;監控;報警
中圖分類號:TP393.08
文獻標識碼:A
DOI:10.3969/j.issn.1003-6970.2016.02.018
引言
隨著計算機技術與人們生活的緊密結合,在許多類似金融服務系統、飛行控制系統、醫療系統等應用領域,人們對這些系統的要求是不間斷的提供有保障的服務,因為這些服務系統的故障會造成災難性的后果。高可用性的服務解決方案就是為了解決這樣的需求,高可用性系統相比普通的計算機系統來說,復雜性高了很多,其對應的研發成本也高了很多。
對于高可用性系統來說,該系統的用戶會在系統設計之前,對系統的設計者提出一些量化標準,比如,要求該系統在一個時間范圍內宕機的時間被控制在一定的范圍內,高可用性系統由于其較高的設計難度,如果能在系統的運行期間引入量化分析的方法,就可以有效的對其可用性進行預測及報警,所以一個可用性監控系統對于一些大型系統的故障預測及報警有著非常重要的意義。
1 相關知識及研究
1.1 高可用性的定義
對于高可用性 的研究中,有三個相關的術語,分別是可用性 (Availability)、可靠性(Reliability)以及適用性(Serviceability)。其中可用性是指對于用戶的使用來說,系統總的可用時間與總時間的百分比;可靠性是指系統在不出故障的情況下持續正常工作的時間;適用性是指對于系統維護、升級的難易程度。
在服務系統的運行周期中,系統的可靠性通過平均無故障時間(MTTF)來表示,平均無故障時間是指系統正常運行的平均時間;系統的適用性通過平均修復時間(MTTR)來表示,平均修復時間是指從系統發成故障到修復完成并重新恢復的平均時間。通過平均無故障時間和平均修復時間可以得到可用性的定義:
從可用性定義的公式可以得出兩個影響系統可用性的因素,分別是:
(l)系統各組件的可靠性。這些組件包括服務器硬件、操作系統和服務系統本身,以及其他的支持組件如數據庫系統、網絡服務器等。
(2)當系統發生故障后,系統重新恢復所花費的時間。如果是服務系統本身的故障,則將該系統重新啟動就可以恢復服務了;如果是硬件設施發生故障的話,則需要對定位發生故障的組件并對其進行修復或更換,然后重新啟動操作系統和其他相關設備,最終啟動服務系統。
一個高可用性系統對系統中所有的組件及子系統都要求其正常工作。在一個系統中,如果大部分組件都具備高可用性,但是另一些組件不具備高可用性,對于整個系統來說,系統也無法保證高可用性,這個特點是高可用性系統的木桶原理。
在一個高可用性系統中,還有兩個相關的術語,即持續可用性(Continuous Availability)、容錯(Fault Tolerance)。持續可用性是指系統無故障提供服務的理想狀態,其也用來表示一個系統的可用性很高,故障時間較少;容錯是指即使某些組件出現故障,整個系統依舊可以無故障的提供服務,一些高可用性的解決方案已經提供了一定的容錯能力。
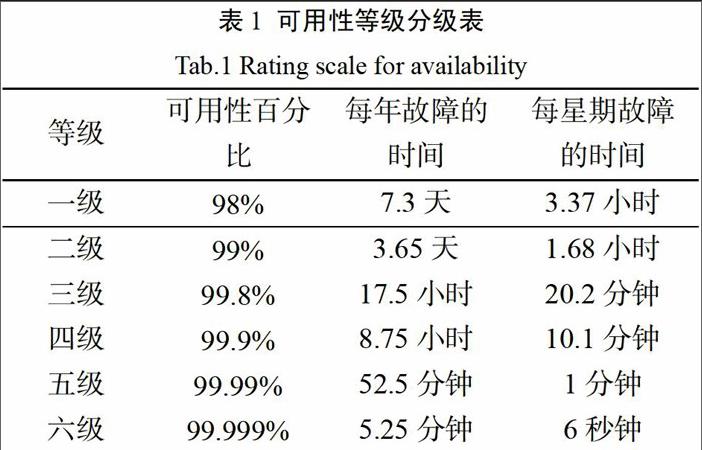
1.2 高可用性等級
高可用性等級明的分級是以可用性百分比中數字“9”的個數來區分的,如果一個系統達到二級高可用,則說明該系統的可用性百分比為99%,一年中總的故障時間為3.65天;如果一個系統達到四級可用,則說明該系統的可用性百分比為99.99%,一年中總的故障時間為52.5分鐘。可用性分級表如下表:
1.3 服務可用性監控系統相關研究
國內外已經有了許多關于服務可用性分析的研究與設計,例如一些成熟的商用服務可用性監控系統,如IBM Tivoli、HP Buiness Availability Center等,這些商業系統對服務可用性的分析基于強大的監控和數據分析能力,對部署于其上的服務進行實時的監控,并對不滿足可用性的服務進行報警,但是這些服務可用性監控系統的購買費用較高,且需要大量監控日志數據的支持,對于國內的一些論文作者的。
我們的目標是建立一個可靠、靈活的服務可用性監控系統,通過在服務可用性監控系統中部署業務系統,可以通過系統直觀的看出該業務系統在某段時間內的服務可用性。
2 服務可用性監控系統架構的分析與設計
本服務可用性監控系統提供了簡單的域名監控接入方式,采用主動拉取數據的方式,無需用戶參與,并提供了統一的可用性計算公式,以及豐富的圖表及歷史數據查詢對比。
2.1 服務可用性監控系統的整體架構
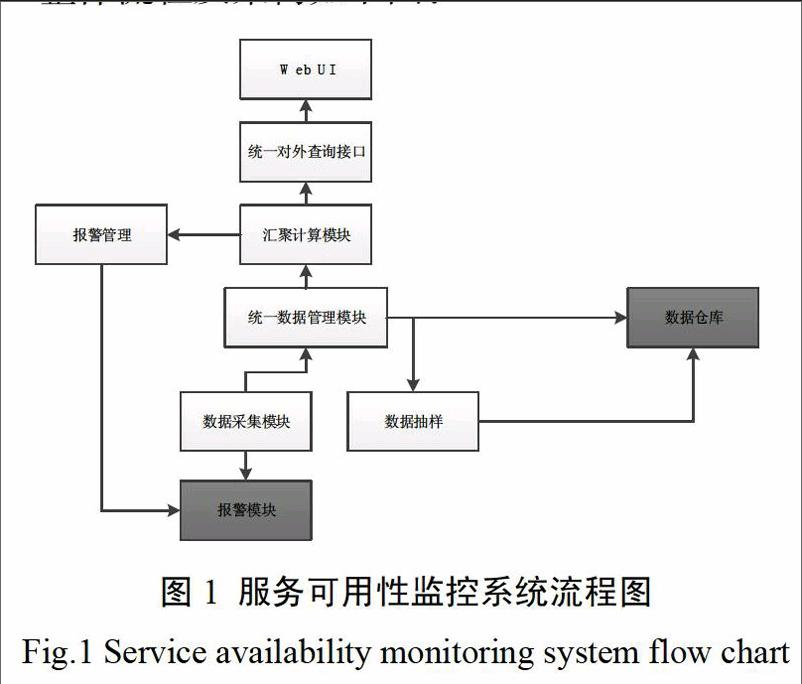
本服務可用性監控系統主要分為匯聚計算、統一數據管理、數據采集、數據抽樣四個模塊。
其中,匯聚計算模塊是本服務可用性監控系統的入口,本模塊負責接收用戶的查詢參數、獲取統一數據數據管理模塊傳來的監控數據,并對監控數據進行匯聚計算,以得到可用性數據。如果最終計算的可用性數據低于用戶配置的報警閥值時,對用戶進行報警通知。
統一數據管理模塊是本系統的中樞,本模塊負責收集用戶輸入的監控配置項(包括被監控服務的域名、正常服務的關鍵字、可用性報警閥值等),將其保存到數據庫中,并將監控配置項發送到數據采集模塊;當用戶點擊其配置的監控配置項時,系統將會根據其配置從數據倉庫中找到匹配的監控數據,并將監控數據發送至匯聚計算模塊,最終展示給用戶。
數據采集模塊是本系統的核心,本模塊首先取到監控配置項,然后根據監控配置項中的數據,調用監控集群中的多個監控機定時地對監控目標進行監控,得到監控的數據與用戶配置的數據進行對比,如果數據不一致,則認為當前監控的服務是不可用的,將同一時間點多個監控機的數據累計計算出一個百分比,并將這個數據發送到統一數據管理模塊。
數據抽樣模塊是一個輔助模塊,主要是由于監控的數據量較大,當計算跨月或者季度的可用性時,由于數據量過大,會導致計算的時間過長,從而影響用戶體驗。因此,數據抽樣模塊將會按天為粒度將監控數據計算出來并保存到數據倉庫中。
整體流程及架構如下圖:
2.2 監控數據采集
監控數據的采集是由數據采集模塊完成的,數據采集模塊會根據用戶配置的監控項調用監控集群中的多個監控機以10秒一次的頻率對監控目標進行監控,將同一時間點多個監控機的數據累計計算出一個百分比,該百分比就是當前監控項當前時間點的監控數據。具體的監控數據采集流程如下:
(l)數據采集模塊獲取配置的監控項中被監控服務的域名、關鍵字等監控項。
(2)監控機發起對被監控服務域名的訪問,獲取其返回數據并將其返回數據與關鍵字對比,如果關鍵字符合則計數加一,不符合則不增加計數。
(3)最終將多個監控機計數除以監控機的總個數得到一個百分比,該百分比作為當前時間點的監控數據。
(4)將監控數據按照時間和監控項ID作為主鍵存人數據倉庫的普通表。
2.3 監控數據抽樣
由于監控機的監控周期為10秒,對于一個服務的監控數據量會非常龐大,當對該服務的可用性進行計算的時候會造成查詢時間過長,影響用戶體驗。所以,數據抽樣模塊會以天為單位對服務的監控數據進行抽樣計算,并將其存人數據倉庫中。具體流程為,將前一天凌晨到當天凌晨的該被監控服務的監控數據計數并加和,將該計數和加和作為抽樣數據存人數據倉庫的抽樣表。
2.4 可用性計算
被監控服務的可用性計算分為兩種情況:
(l)用戶查詢時間區間在一天內。這種情況的可用性計算相對簡單,即統一數據管理模塊通過接口查詢數據倉庫,將該時間區間內所有該服務的監控數據取出,對其進行計數和加和,然后將該加和除以該計數就可以得到當前時間區間服務的可用性數值了。
(2)用戶查詢時間區間超過一天。在這種情況中,對總體可用性的計算由于需要的數據量過于龐大,需要使用抽樣數據。首先將查詢時間區間中整天的數據從數據倉庫的抽樣表中取出并累加到一起,最終得到一個計數count和一個加和sum,然后在數據倉庫的普通表中取出查詢時間區間的非整天數據,接著將查詢時間區間中非整天的數據累加到sum上,并每次對count加一,最終得到整體計數和整體加和,然后用整體加和除以整體計數,得到當前時間區間服務的可用性數值。
服務可用性監控系統的數據流圖如下:
3 結論
本文提出的服務可用性監控系統架構,包括了匯聚計算、統一數據管理、數據采集、數據抽樣四個模塊,一方面采用了分層的思想對業務邏輯進行分析,降低了模塊與模塊之間的耦合性,當邏輯需要發生變化的時候,只需要修改一個模塊,不會影響到其他模塊;另一方面在存儲數據時,對原始數據存儲時進行了一定的數據抽樣,從而在大數據量查詢時可以有效的降低查詢時延,提升了用戶體驗。本文的下一步研究重點是完成對除web服務以外,其他類型服務監控的接入,希望最終實現一個可接人多類型服務的服務可用性監控系統。
