基于CUDA的RS糾刪碼性能優(yōu)化
2016-03-25 06:13:48戴世航李小勇
微型電腦應(yīng)用 2016年1期
戴世航,李小勇
?
基于CUDA的RS糾刪碼性能優(yōu)化
戴世航,李小勇
摘 要:目前分布式存儲(chǔ)系統(tǒng)中保證數(shù)據(jù)可用性的常用方法有多副本技術(shù)和糾刪碼技術(shù)。與多副本技術(shù)相比,糾刪碼技術(shù)有更高的存儲(chǔ)空間利用率,但附加的編碼流程不可避免地帶來了較高的時(shí)間延遲,影響了系統(tǒng)的實(shí)時(shí)性,限制了糾刪碼的應(yīng)用。為了提高糾刪碼的編碼效率,對(duì)開源代碼庫(kù)Jerasure提供的RS糾刪碼進(jìn)行優(yōu)化,利用CUDA對(duì)其進(jìn)行加速。實(shí)驗(yàn)結(jié)果顯示,相對(duì)于原始算法,該方法將編碼速度提高了約20倍,為糾刪碼技術(shù)應(yīng)用于實(shí)時(shí)系統(tǒng)提供了可能。
關(guān)鍵詞:RS糾刪碼;CUDA;GPU加速
0 引言
如今,人類社會(huì)已經(jīng)進(jìn)入了大數(shù)據(jù)時(shí)代。隨著各種新興媒體、數(shù)據(jù)倉(cāng)庫(kù)、社交網(wǎng)絡(luò)的飛速發(fā)展,預(yù)計(jì)2020年數(shù)據(jù)總量將達(dá)到35萬ZB。為存儲(chǔ)數(shù)量如此巨大的數(shù)據(jù),各種分布式存儲(chǔ)系統(tǒng)應(yīng)用而生。
分布式存儲(chǔ)系統(tǒng)往往建立在大量廉價(jià)機(jī)器上,系統(tǒng)中節(jié)點(diǎn)故障不可避免,如何才能在這樣的環(huán)境下保證存儲(chǔ)數(shù)據(jù)的高可用性得到了廣泛的研究。實(shí)踐中最常用的方法是多副本技術(shù),通過將文件以多個(gè)副本的形式存入存儲(chǔ)系統(tǒng)中以實(shí)現(xiàn)冗余容錯(cuò),只要其中一個(gè)副本沒有損壞,用戶就可以正常訪問到文件。但多副本技術(shù)存儲(chǔ)冗余度高這一缺點(diǎn)也隨著數(shù)據(jù)規(guī)模增大而日益突出,而糾刪碼技術(shù)在這一方面則具有明顯優(yōu)勢(shì)。不過由于糾刪碼的運(yùn)算開銷較大,實(shí)時(shí)性差,因此可應(yīng)用的場(chǎng)景受到限制。
本文針對(duì)糾刪碼技術(shù)的這一缺點(diǎn),在開源糾刪碼庫(kù)Jerasure[1]提供的RS糾刪碼reed_sol_r6_op算法(后文簡(jiǎn)稱為r6算法)的基礎(chǔ)上,利用GPU強(qiáng)大的并行計(jì)算能力,使用CUDA對(duì)其進(jìn)行加速,獲得了很好的加速效果,速度可達(dá)原始算法的20倍,為糾刪碼技術(shù)在對(duì)實(shí)時(shí)性要求較高的存儲(chǔ)系統(tǒng)中應(yīng)用提供了可能。
1 RS糾刪碼
糾刪碼技術(shù)的基本思想是:首先將文件分割成k個(gè)數(shù)據(jù)塊,然后依照特定的糾刪碼算法對(duì)這k個(gè)數(shù)據(jù)塊進(jìn)行計(jì)算得到m個(gè)編碼塊,這一過程被稱為編碼。編碼完成后,在存儲(chǔ)系統(tǒng)中分布式存儲(chǔ)這這k+m個(gè)文件塊。當(dāng)有任何文件塊出現(xiàn)錯(cuò)誤時(shí),利用其他文件塊來恢復(fù)它的信息,這一過程被稱為重構(gòu)或者解碼。一般而言,一組文件塊最多可以容忍m個(gè)文件塊出錯(cuò)。
和多副本技術(shù)相比,糾刪碼技術(shù)的最大特點(diǎn)是大大降低了數(shù)據(jù)冗余度,提高了存儲(chǔ)空間的利用率,減少了存儲(chǔ)成本。舉例來說,常用的多副本技術(shù)一般為每個(gè)文件提供3個(gè)副本,數(shù)據(jù)冗余度為300%,存儲(chǔ)空間的利用率僅為三分之一;而常用4+2糾刪碼(為每4個(gè)數(shù)據(jù)塊計(jì)算得到2個(gè)編碼塊),將數(shù)據(jù)冗余度降至150%,存儲(chǔ)空間的利用率翻了一倍達(dá)到了三分之二。糾刪碼技術(shù)在這方面的優(yōu)異性能也是它得到越來越多關(guān)注的原因。
RS糾刪碼,全稱為Reed-Solomon編碼,是目前應(yīng)用最廣的糾刪碼算法,使用特定的生成矩陣計(jì)算得到編碼塊,過程如圖1所示:
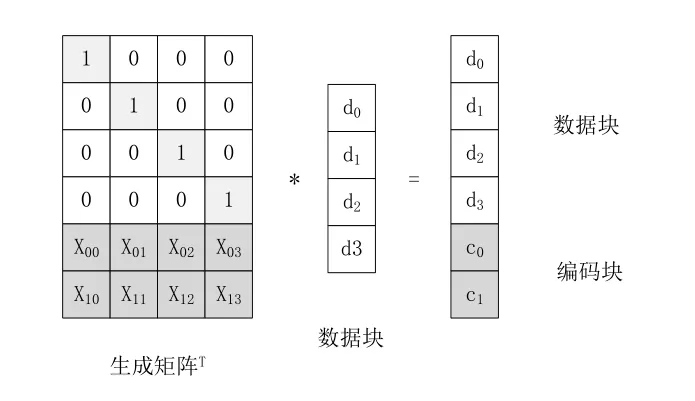
圖1 RS糾刪碼編碼過程
RS糾刪碼最大的特點(diǎn)在于它可以適用于任意k+m的組合。根據(jù)生成矩陣的不同RS糾刪碼被分為兩類:一類是范德蒙RS糾刪碼,另一類是柯西RS糾刪碼。范德蒙RS糾刪碼是以范德蒙矩陣為生成矩陣的,而柯西RS糾刪碼則是以柯西矩陣為生成矩陣的。但無論是哪一種,編碼原理都是在有限域上的多項(xiàng)式運(yùn)算,而有限域上乘法運(yùn)算極其復(fù)雜,這導(dǎo)致其編解碼運(yùn)算速度很慢,時(shí)間開銷很高。由于這樣的原因,RS糾刪碼在實(shí)踐中一般用在對(duì)實(shí)時(shí)性要求不高,或者是更新頻率較低的云存儲(chǔ)系統(tǒng)中[2]。
2 基于CUDA加速的r6算法
2.1 GPU計(jì)算優(yōu)勢(shì)
GPU最初用于3D圖形處理,但經(jīng)過不斷的發(fā)展,GPGPU(General Purpose GPU,通用計(jì)算GPU)技術(shù)得到了不斷發(fā)展。相對(duì)于CPU使用大量晶體管用作復(fù)雜的控制單元和緩存以提高少量執(zhí)行單元的執(zhí)行效率,GPU將更多的晶體管用作執(zhí)行單元,因此GPU在處理能力和存儲(chǔ)器帶寬上有明顯優(yōu)勢(shì)。同時(shí)由于GPU中可以同時(shí)運(yùn)行大量的線程,在并行計(jì)算上有著先天的優(yōu)勢(shì)。另外,GPU的造價(jià)和功耗相對(duì)于相同計(jì)算能力的CPU要低很多,在一定程度上滿足了無法使用高端主機(jī)卻需要處理海量數(shù)據(jù)的用戶的需求。
2.2 CUDA編程模型
2007年NVDIA公司推出了CUDA(Compute Unified Device Architecture,統(tǒng)一計(jì)算設(shè)備架構(gòu)),這是一種將GPU作為數(shù)據(jù)并行計(jì)算設(shè)備的軟硬件體系,為開發(fā)人員有效利用GPU的強(qiáng)大性能提供了條件。
CUDA編程模型采用單指令流多數(shù)據(jù)流(Single Instruction Multiple Data)執(zhí)行模式。在這個(gè)模型中,CPU 和GPU協(xié)同工作,CPU稱為主機(jī)(Host),負(fù)責(zé)進(jìn)行邏輯性強(qiáng)的事務(wù)處理和串行計(jì)算,GPU作為設(shè)備(Device),負(fù)責(zé)執(zhí)行高度線程化并行處理任務(wù)。運(yùn)行在GPU上的CUDA計(jì)算函數(shù)被稱為kernel(內(nèi)核函數(shù)),一個(gè)完整的CUDA程序時(shí)由一系列的設(shè)備端kernel并行步驟和主機(jī)端的串行步驟共同組成的,如圖2所示:

圖2 CUDA編程模型
一個(gè)CUDA程序中,基本的主機(jī)端代碼主要完成以下功能:?jiǎn)?dòng)CUDA,為數(shù)據(jù)分配內(nèi)存和顯存空間,將內(nèi)存中數(shù)據(jù)拷貝到顯存,調(diào)用設(shè)備端的kernel進(jìn)行計(jì)算,將顯存中的結(jié)果拷貝到內(nèi)存中,執(zhí)行串行代碼,釋放內(nèi)存和顯存空間,退出CUDA;基本的設(shè)備端代碼主要完成以下功能:從顯存讀數(shù)據(jù)到GPU片中,對(duì)數(shù)據(jù)進(jìn)行處理,將處理后的數(shù)據(jù)寫回顯存[3]。
CUDA通過將計(jì)算任務(wù)映射成大量的可以并行執(zhí)行的線程,并由硬件動(dòng)態(tài)調(diào)度和執(zhí)行這些線程來提供給使用者GPU強(qiáng)大的計(jì)算能力。為了便于使用和管理這些線程,CUDA將這些線程在2個(gè)層次上組織起來,分別是grid中block間的并行和block中thread間的并行,如圖3所示:
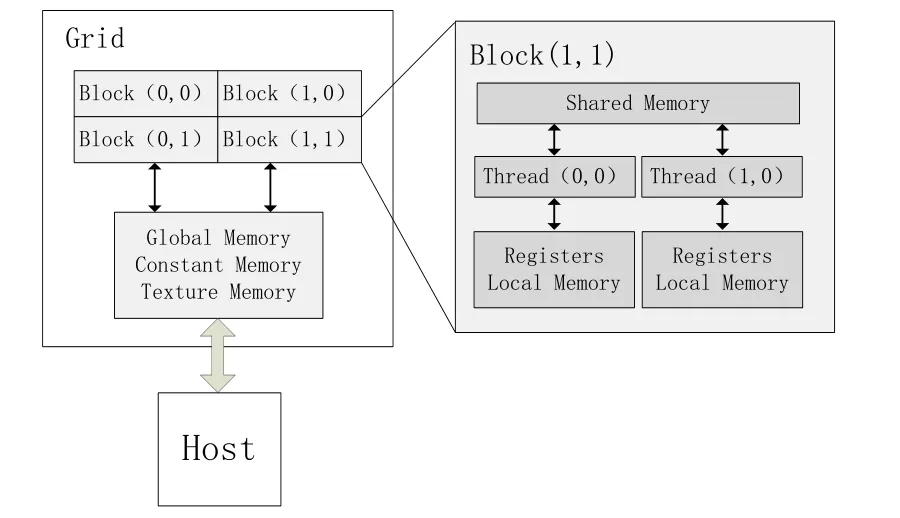
圖3 CUDA線程組織形式
kernel實(shí)質(zhì)上是以block為單位執(zhí)行的,block之間無法通信,也沒有執(zhí)行順序,但同一block中的thread可以通過共享存儲(chǔ)器(shared memory)交換數(shù)據(jù),同時(shí)每個(gè)thread都有獨(dú)立的register和local memory用于儲(chǔ)存計(jì)算時(shí)所需數(shù)據(jù)。在kernel運(yùn)行時(shí),使用者可以通過相應(yīng)的索引準(zhǔn)確定位到grid中的每一個(gè)block和block中的每一個(gè)thread,進(jìn)而為每一個(gè)線程分配獨(dú)立的計(jì)算任務(wù)。從宏觀上看,同時(shí)可以能有成千上萬個(gè)線程正在工作,這也是GPU強(qiáng)大計(jì)算能力的體現(xiàn)[3]。
2.3 r6算法
傳統(tǒng)的RS糾刪碼能夠滿足任一k、m的組合,因而有很好的適用性,但正如前文所介紹的,由于在有限域上的乘法復(fù)雜度較高,性能不能令人滿意,雖然柯西RS糾刪碼可以可以將有限域上的乘法運(yùn)算轉(zhuǎn)換成異或運(yùn)算,但性能提升也比較有限,而且本身的運(yùn)算依然比較復(fù)雜,不易使用GPU運(yùn)算來進(jìn)行加速。而r6算法借鑒了陣列糾刪碼的思想,不再使用矩陣乘法來得到編碼塊,而是通過對(duì)數(shù)據(jù)塊進(jìn)行異或運(yùn)算來得到編碼塊。與陣列糾刪碼不同的是,r6算法中一個(gè)文件的編碼塊僅由自己的數(shù)據(jù)塊計(jì)算得到,而不是跨文件編碼。由于不再使用靈活的生成矩陣,r6算法無法應(yīng)用于任一k、m組合,而是像raid-6一樣,將m的值固定為2。算法流程如下:
1)將文件劃分成為多個(gè)數(shù)據(jù)塊d0、d1、d2、…、dk-1;
2)將d0、d1、d2、…、dk-1通過異或運(yùn)算得到第一個(gè)編碼塊c0;
3)對(duì)每一個(gè)數(shù)據(jù)塊進(jìn)行變換得到d0’、d1’、d2’、…、dk-1’,這里di'= 2i * di,其中0≤i≤k-1;
4)對(duì)d0’、d1’、d2’、…、dk-1’通過異或運(yùn)算得到第二個(gè)編碼塊c1;
本文使用CUDA對(duì)步驟2、3、4進(jìn)行加速,如圖4所示:
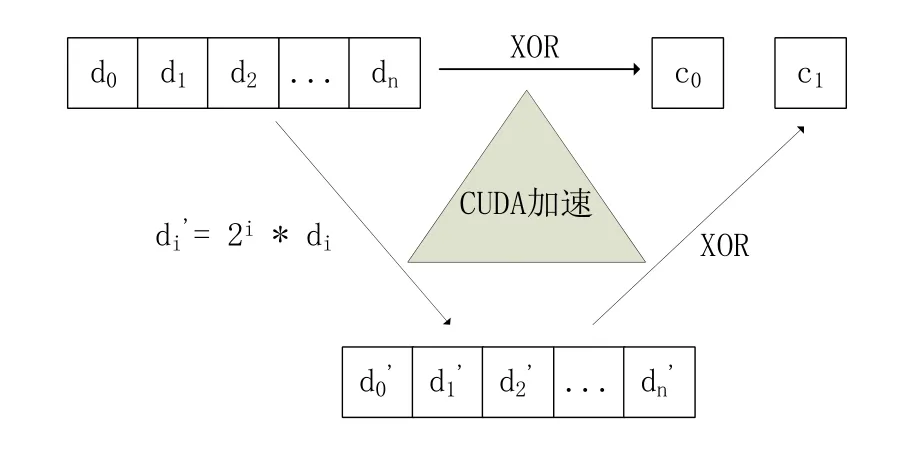
圖4 r6算法編碼示意圖
在r6算法的編碼過程中,不再需要生成生成矩陣,也回避了邏輯復(fù)雜的有限域上的矩陣乘法,算法實(shí)現(xiàn)邏輯簡(jiǎn)單,大大減少了使用CUDA編程時(shí)的工作量。當(dāng)由于數(shù)據(jù)丟失需要重構(gòu)時(shí),該算法與傳統(tǒng)k+2 RS糾刪碼一樣,可以在至多兩個(gè)文件塊損壞的情況下恢復(fù)出原數(shù)據(jù)。
雖然在r6算法中,m被指定為2,失去了一定的靈活性。但在實(shí)踐中依然可以通過調(diào)整k值來滿足特定的場(chǎng)景需求,比如如果數(shù)據(jù)比較重要,可以采用4+2的編碼方式,而如果存儲(chǔ)的是冷數(shù)據(jù),可以使用12+2的編碼方式,同時(shí)還可以通過調(diào)整編碼時(shí)的其他參數(shù)來優(yōu)化編碼性能,這些手段也使得該算法在實(shí)踐中依然具有一定的適用性。
2.4 CUDA加速策略
在編碼步驟2、3、4中,需要對(duì)待編碼的文件塊進(jìn)行規(guī)模巨大、但邏輯簡(jiǎn)單的算術(shù)運(yùn)算,在CPU中,這些無所謂先后順序運(yùn)算在循環(huán)中串行執(zhí)行,時(shí)間開銷巨大,因此對(duì)這里使用CUDA進(jìn)行加速。為充分運(yùn)用GPU的性能,設(shè)定每個(gè)block維護(hù)1024個(gè)線程,這也是一個(gè)block最多能夠維護(hù)的線程數(shù)量,然后根據(jù)每次處理的數(shù)據(jù)大小,動(dòng)態(tài)設(shè)定grid中維護(hù)的block數(shù)量。通過這樣的修改,將原來由CPU進(jìn)行的串行運(yùn)算轉(zhuǎn)換成為由GPU中大量線程同時(shí)執(zhí)行的并行運(yùn)算,大大減少了時(shí)間開銷。
在實(shí)驗(yàn)過程中,發(fā)現(xiàn)雖然單純的計(jì)算過程中使用CUDA加速的代碼有著明顯的計(jì)算優(yōu)勢(shì),但是一旦考慮到申請(qǐng)內(nèi)存、顯存,數(shù)據(jù)在內(nèi)存、顯存之間傳遞等操作帶來的時(shí)間開銷,GPU的執(zhí)行效率便大打折扣。因此如何減少申請(qǐng)內(nèi)存、顯存和數(shù)據(jù)在內(nèi)存、顯存中傳遞帶來的時(shí)間開銷成為了優(yōu)化算法的關(guān)鍵。為此本算法使用了zero-copy技術(shù),使用CUDA提供的API cudaHostAlloc()直接申請(qǐng)不會(huì)被換入低速虛擬內(nèi)存的頁(yè)鎖定內(nèi)存,并通過cudaHostGetDevicePointer()將頁(yè)鎖定內(nèi)存映射到設(shè)備地址空間,這樣GPU便可以直接訪問內(nèi)存中的數(shù)據(jù),無須分配顯存空間,也不必在內(nèi)存和顯存之間進(jìn)行數(shù)據(jù)拷貝,也就是達(dá)到了zero-copy的效果,申請(qǐng)空間和數(shù)據(jù)傳輸?shù)臅r(shí)間延遲得以回避,使得性能得到了極大的提升。
3 實(shí)驗(yàn)與性能分析
實(shí)驗(yàn)的環(huán)境如下:
CPU:Intel(R) Pentium(R) G630,主頻為2.70GHz;
內(nèi)存:6G;
顯卡:GTX 660,顯存為2G;
操作系統(tǒng):Ubuntu 14.04.2。
實(shí)驗(yàn)中,使用的糾刪碼模式為4+2,分別使用大小為154.3MB(文件1)和2.1G(文件2)的文件進(jìn)行測(cè)試,測(cè)試結(jié)果如圖5所示:
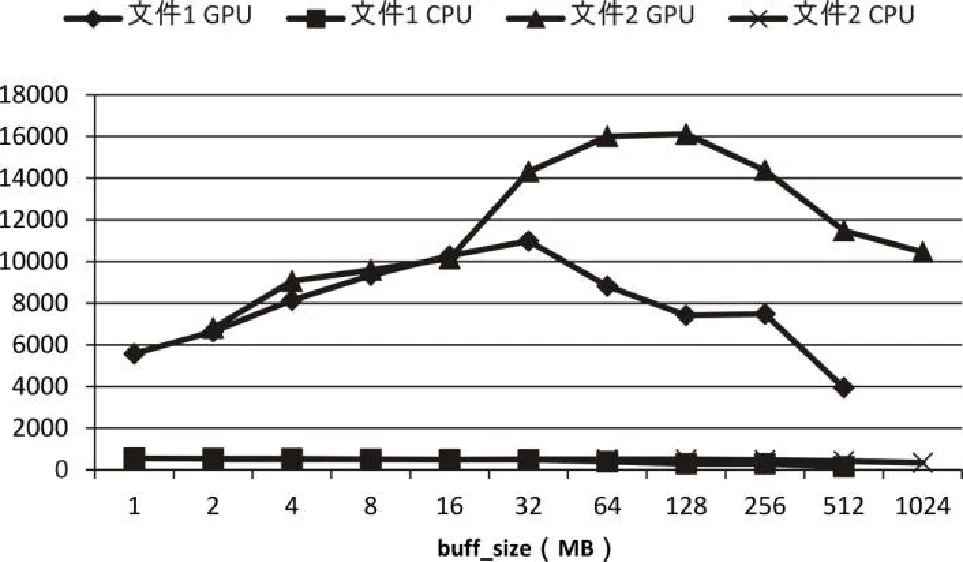
圖5 CPU/GPU編碼速度測(cè)試結(jié)果
為排除偶然因素帶來的誤差,每個(gè)數(shù)據(jù)都是測(cè)試10次之后取平均得到的。圖中buff_size為每次處理的數(shù)據(jù)大小。
從實(shí)驗(yàn)結(jié)果可以看出,無論測(cè)試文件大小,使用CUDA加速后的代碼編碼速度都有大幅度的提升,原r6算法編碼速度基本在500MB/s上下,而在CUDA加速后,雖然性能隨參數(shù)變化有較大波動(dòng),但最低也能達(dá)到4GB/s,平均速度在10GB/s左右,速度提高了接近20倍。特別是當(dāng)文件比較大時(shí),如果參數(shù)選擇合適甚至可以達(dá)到16GB/s,達(dá)到30倍的加速比。同時(shí)從圖5中可以看出,隨著buff_size的不斷增大,編碼速度呈現(xiàn)出先增后減的趨勢(shì),這是因?yàn)殡m然在編碼時(shí)每次并行處理的數(shù)據(jù)越多,編碼越快,但是維護(hù)較大內(nèi)存、顯存的開銷也會(huì)比較大,所以在具體實(shí)踐中時(shí)仍需要根據(jù)操作環(huán)境的不同,在并行度和內(nèi)存、顯存的維護(hù)之間做出適當(dāng)?shù)恼壑校x擇合適的參數(shù)以保證系統(tǒng)有較高的效率。從實(shí)驗(yàn)結(jié)果可以看出,對(duì)于大文件,buff_size選擇64MB或者128MB時(shí)性能較優(yōu)。
4 總結(jié)
本文以開源糾刪碼庫(kù)Jerasure中提供的r6算法為原型,利用CUDA對(duì)其代碼進(jìn)行加速,并通過申請(qǐng)、使用頁(yè)鎖定內(nèi)存,回避了數(shù)據(jù)在內(nèi)存和顯存中來回拷貝帶來的時(shí)間開銷。經(jīng)實(shí)驗(yàn)測(cè)試,經(jīng)加速后的r6算法編碼速度平均可達(dá)10GB/s,相當(dāng)于原r6算法的20倍,為糾刪碼在實(shí)時(shí)性要求比較高的分布式存儲(chǔ)系統(tǒng)中的應(yīng)用提供了可能。
參考文獻(xiàn)
[9] Plank J S, Simmerman S, Schuman C D. Jerasure: A library in C/C++ facilitating erasure coding for storage applications-Version 1.2[R]. Technical Report CS-08-627, University of Tennessee, 2008.
[10] 羅象宏,舒繼武.存儲(chǔ)系統(tǒng)中的糾刪碼研究綜述[J].計(jì)算機(jī)研究與發(fā)展,2012,01:1-11.
[11] Nvidia Corporation. NVIDIA CUDA Programming Guide[M]. Santa Clara, USA: Nvidia Corporation, 2011.
CUDA-based Performance Optimization of RS Erasure Coding
Dai Shihang, Li Xiaoyong
(College of Information Security, Shanghai Jiao Tong University, Shanghai 200240, China)
Abstract:At present, the ways used by distributed storage system to ensure the availability of data mainly have multi-replicate and erasure coding technologies. Compared with multi-replicate, erasure coding saves more storage space, however, it takes more time in encoding, which has a bad effect in speed, and limits its application. In order to improve the encoding efficiency of erasure coding, an algorithm provided in the open-source library Jerasure is accelerated by CUDA in this paper. The test result shows that the accelerated algorithm is about 20 times faster than the original one.
Key words:RS Erasure Coding; CUDA; GPU Acceleration
收稿日期:(2015.09.21)
作者簡(jiǎn)介:戴世航(1991-),男,吉林延邊,上海交通大學(xué),信息安全工程學(xué)院,碩士研究生,研究方向:云存儲(chǔ)、糾刪碼,上海,200240李小勇(1972-),男,甘肅天水,上海交通大學(xué),信息安全工程學(xué)院,副教授,博士,研究方向:海量存儲(chǔ)、高性能網(wǎng)絡(luò)、嵌入式系統(tǒng)、上海,200240
文章編號(hào):1007-757X(2016)01-0070-03
中圖分類號(hào):TP311
文獻(xiàn)標(biāo)志碼:A

- 微型電腦應(yīng)用的其它文章
- 基于zookeeper和強(qiáng)一致性復(fù)制實(shí)現(xiàn)MySQL分布式數(shù)據(jù)庫(kù)集群
- Access數(shù)據(jù)庫(kù)實(shí)現(xiàn)對(duì)象間數(shù)據(jù)“流動(dòng)”的方法
- 基于引力搜索算法的RSSI 模型優(yōu)化與在消防定位中的應(yīng)用
- 基于SVPWM單臺(tái)逆變器的電機(jī)傳動(dòng)系統(tǒng)控制策略研究
- 基于3D打印機(jī)傳輸中斷解決方案的設(shè)計(jì)與實(shí)現(xiàn)
- 基于Mjpg-streamer的跨平臺(tái)無線視頻傳輸系統(tǒng)