用半分布式匯流結構改善新安江模型參數外推能力研究
2016-03-23 00:28:36王加虎徐秀麗習雪飛
中國農村水利水電 2016年6期
關鍵詞:模型
王加虎,袁 瑩,李 麗,徐秀麗,習雪飛
(河海大學水文水資源學院,南京 210098)
利用水文模型對無歷史實測徑流資料的地區(本文簡稱無資料地區)進行水文預報是一個富有挑戰性的問題[1],多年來,眾多學者從模型參數的空間規律性出發,研究現有的水文模型在無資料地區的應用,如:周研來等[2]利用VIC(Variable Infiltration Capacity Macroscale Hydrologic Model)模型,采用了多元回歸方法建立了參數移用公式,并用來推求無資料地區的水文模型參數;再如柴曉玲等[3]研究了IHACRES模型在無資料地區徑流模擬中的應用,對模型進行參數優選之后移用于其他流域,并將該模型模擬結果與三水源新安江模型模擬結果進行對比。
在眾多水文模型當中,TOPMODEL(TOPography based hydrological MODEL)、SCS(Soil Conservation Service)等模型由于其設計、結構和參數等遙感數據有關,學者認為這類模型更容易應用到無資料地區、并不斷用實踐去加以證實。如胡彩虹等[4]將TOPMODEL模型應用在無資料的半濕潤半干旱地區,得到了比較滿意的結果;再如甘衍軍等[5]依據土地利用、土壤類型等遙感數據確定SCS模型參數,根據流域降水資料對東西汊湖集水域不同時段的徑流量進行了模擬,并采用徑流系數法對SCS產流模型的模擬精度進行了驗證,得到了可靠的模擬結果。
新安江模型是具有世界影響力的中國本土水文模型,在有資料的濕潤、半濕潤地區得到了廣泛的應用。姚成[6]等利用參數移植方法開展嵌套式流域無資料情況下的水文模擬研究,發現新安江模型的產流參數移植精度較高、匯流參數的移植精度相對較低。究其原因是洪水匯流參數隨下墊面狀況、流域地理特征量的差異而不同,因此洪水匯流參數就不能像產流參數一樣在相似流域直接移植使用。針對上述情況,本文借鑒半分布式水文模型的匯流計算思路,利用數字高程模型提取流域特征、計算出流域的時段單位線,并據此修改新安江模型的匯流計算模塊,進而提高了新安江模型在無資料地區的參數外推能力,詳述如下。
1 產流結構
經典的新安江流域三水源的水文模型結構如圖1所示[7]。圖1中輸入的有兩個量,分別為降雨量P以及水面蒸發能力EM,輸出的也是兩個量,分別為流域的蒸散發量E以及流域的出口斷面流量Q。方框外面的是在新安江模型中遇到的模型參數,方框里面的是狀態變量。模型由4部分構成,第一部分為蒸散發計算,第二部分為產流量計算,第三部分為水源劃分,第四部分為匯流計算。本文研究保留模型的前3個結構,只對第四部分的匯流結構做改進,參見圖1中的虛線部分結構。
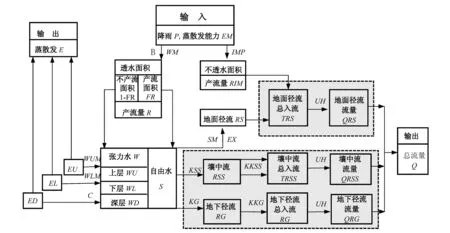
圖1 新安江流域水文模型(陰影框內為本次的改進對象)Fig.1 Xin'anjiang model(research within the shadow box)
2 匯流結構
在分布式水文模型中,常利用數字高程模型(DEM)將流域劃分為若干規則格網,每個格網單元不妨稱為“柵格”。利用常用的流域特征提取方法[8],可以得到每個柵格到達出口(通常是水文站)的路徑長L,如圖2所示
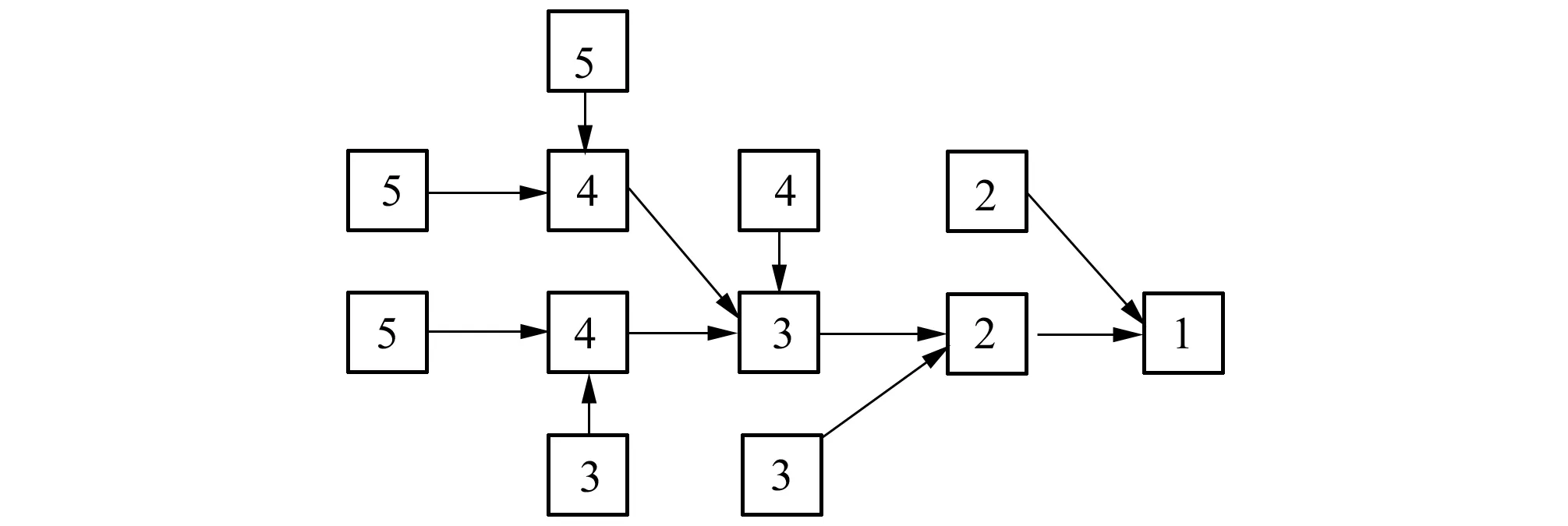
圖2 流域柵格化及路徑長計算示意圖Fig.2 Schematic diagram of basin rasterization and runoff flow
本文對新安江模型的匯流結構進行改進,利用DEM數值,得到每個柵格與出口柵格的高差dH,進而計算出這個柵格與出口之間的平均坡度S。根據流域的平均坡度,可以通過計算得到該柵格匯流到出口的平均速度,計算公式如下:
V=CkS1/2
(1)
式中:V是水流速度,m/s;S是坡面流平均坡度;k是坡面流速度常數,可以根據地表覆被的類型確定,如表1所示;C是一個調整系數,需要由實測資料率定。
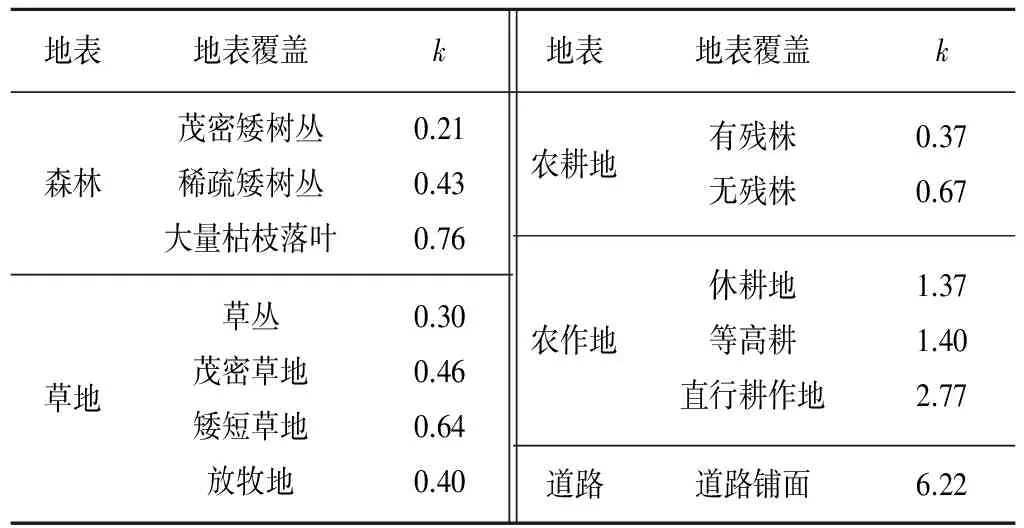
表1 坡地流速度常數k(SCS,1986年) m/sTab.1 The constant k of slope flow rate (SCS, 1986)
以地表水為例,按照水文模型常用的各水源匯流符合線性疊加原理的假定,在流域上不同柵格的自由水(產流和分水源計算的結果)會沿著各自的路徑、以不同的流速先后到達出口斷面,在出口對所有先后到達的各個柵格水量,按照指定的時段累加,就形成了地表水匯流時段單位線。利用該單位線對產流和分水源模塊計算出的水量過程進行卷積計算,就得到了地表水源的匯流計算結果。
為了和三水源新安江模型相匹配,本文使用了3層上述匯流結構,不同水源的匯流速度不同,具體體現在速度公式中的系數C,對應的系數C由實測資料率定,C地表>C壤中>C地下。
3 參數外推能力驗證
3.1 目標站的選擇
黑龍江省是水文學界公認的新安江模型適用地區之一,為了檢驗參數外推后對目標站洪水的模擬效果,選擇了資料條件較好的南岔站作為目標站。南岔站位于黑龍江省伊春市南岔區,是湯旺河下游右岸一級支流西南岔河出口控制站,屬國家二類精度站,集水面積2 582 km2,斷面以上河長106 km,至河口的距離15 km,流域平均坡降0.695%,河底平均坡降0.420%,河系形狀略呈扇形。河寬80~180 m,總落差410 m。地貌屬小興安嶺山地,多丘陵和高山。
3.2 參證站的確定
按照李正最等[9]介紹的相似特征指標的灰色關聯度分析方法,逐一分析目標站附近的30個有長系列實測水文資料的站點,首先根據影響徑流的主要因素、流域的實際特征及解決問題的目的,建立了3大類11個水文相似性評價指標體系,具體為年平均降雨量、6月平均降雨量、7月平均降雨量、8月平均降雨量、9月平均降雨量、流域面積、主河道長、河道縱坡、形狀系數、土地利用及地質條件;然后根據選定的水文相似指標,通過使用Channel Network Tool-I(簡稱CNT-I)軟件包[10]對研究區域進行數字化,提取各個小流域的各項相似特征值數值,其中地質條件為定性指標;根據相應的相似特征值數值可以計算得到流域的特征指標的關聯系數;一般來說特征指標的關聯度越大,則參證流域與設計流域的關聯度越大,其相似程度也越大,因此最后選定帶嶺站作為率定參數的參證站。
帶嶺站是西南岔河上游左岸一級支流永翠河出口控制站,位于黑龍江省伊春市帶嶺區。流域呈西北東南走向,地勢北高南低。地貌屬小興安嶺山地,流域內山巒起伏,溝谷縱橫,河網發育,森林茂密,植被良好,多分布針闊混交林,地下水豐富。斷面以上河長61 km,至河口的距離為5.7 km,集水面積為677 km2。流域平均坡降1.18%,河底平均坡降0.771%,流域形狀為樹枝形。
3.3 流域特征提取
為了減少流域特征提取給研究結果帶來的不確定性,本文使用Channel Network Tool-I(簡稱CNT-I)軟件包提取流域特征。CNT-I是河海大學郝振純教授等開發的提取流域特征信息的通用軟件包,在復合信息(復合了自然水系位置的DEM)的控制下按照D8法來提取出與自然水系相匹配的流域特征信息,在洼地和平原區有更好的表現。該軟件主要包括柵格河道矢量化、數字水系生成、流域特征提取等功能。所適用的資料包括:黑龍江省二十五萬分之一的天然水系圖和美國地球物理數據中心1999年發布的全球陸地1 km基礎高程(Global Land One-kilometer Base Elevation, GLOBE)數據,GLOBE數據按照經緯網描述高程的空間分布,其空間分辨率為30″(準1 km)。實際使用時,每個柵格的面積和邊長都根據柵格中心點的緯度做了簡單校正。
提取出的柵格河網如圖3所示。從圖3中可以看出,目標站和參證站都是南岔河上的水文站點、屬于上下游嵌套關系。
3.4 建模及其他資料
模型程序用C#開發,計算時段長1 h,預熱期30 d。降雨資料取自黑龍江省水文局的歷史數據庫,選用帶嶺站、寒月林場、碧水林場、朝陽林場、南列林場5站雨量資料。蒸發資料采用多年月平均值。植被數據采用中國國家自然地圖集中的中國植被區劃圖。
3.5 驗證方法
(1)模型建立之后,在參證站選擇10場次洪,包括帶嶺站建站以來最大洪水1968-07-26、洪峰流量802 m3/s、重現期相當于50年一遇,率定出一組方案參數。
(2)為了避免人為調參對結果的影響,采用SCE-UA算法率定模型參數[11]。SCE-UA算法的基本思路是將基于確定性的復合形搜索技術和自然界的生物競爭進化原理相結合。算法的關鍵部分分為競爭的復合形進化算法(CCE)。在CCE中,每個復合形的頂點都是潛在的父輩,都有可能參與產生下一代群體的計算。隨機方式在構建子復合形的應用,使得在可行域的搜索更加徹底。
(3)率定出的主要參數如表2所示。率定結果中:洪峰流量按照20%許可誤差衡量合格率60%;洪水總量按照20%許可誤差合格率80%;峰現時刻誤差絕對值(因為峰現時刻有正有負)的平均值為1.6 h;確定性系數的平均值為0.82。

表2 參數率定結果Tab.2 The situation of parameter calibration
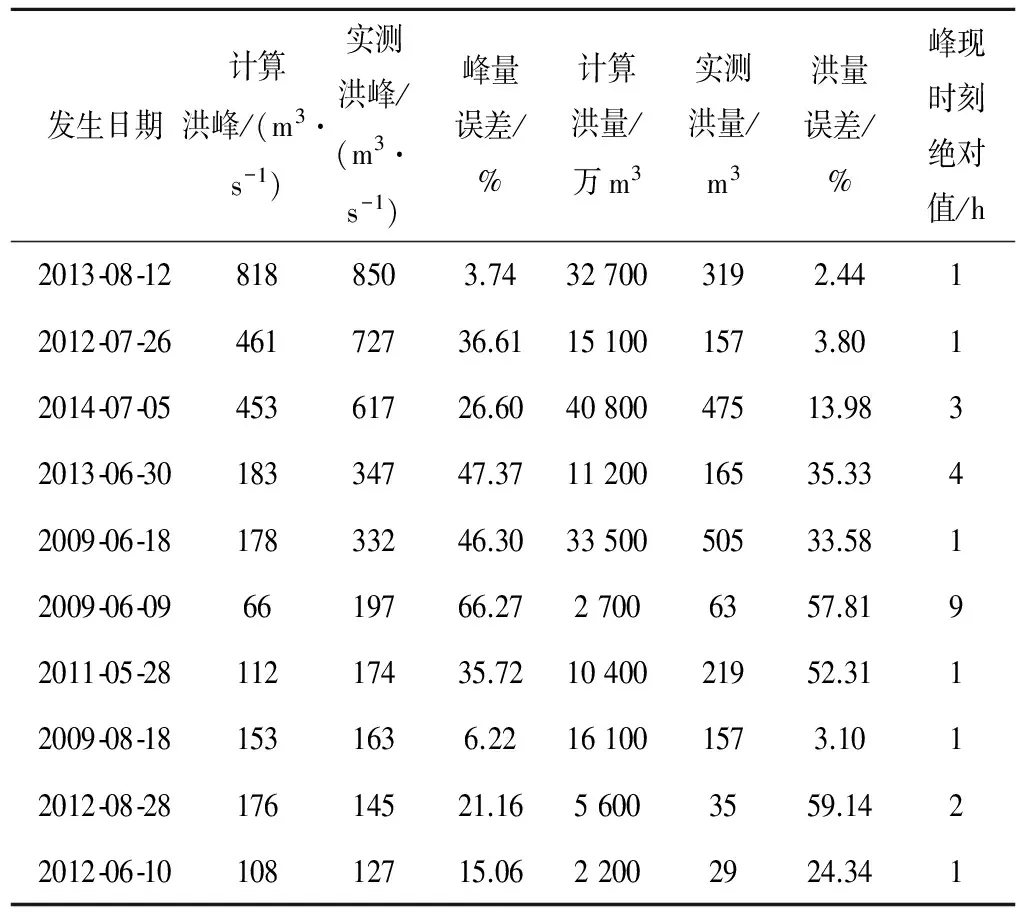
(4)在目標站選擇10場次洪,用參證站率定好的產匯流參數、和目標站的實測降雨,模擬出目標站的洪水過程,并與實測值相比較。洪峰流量按照20%許可誤差衡量合格率30%;洪水總量按照20%許可誤差合格率50%;峰現時刻誤差絕對值的平均值為2.4h;確定性系數的平均值為0.70(見表3)。
(5)目標站的驗證結果表明,新安江產流模型加上改進的匯流結構,參數在空間上具備一定的外推能力。
4 對照試驗
為了研究新匯流方法的實用性和參數外推能力的改善,特設計了對照試驗:即以經典的新安江模型產匯流結構建立算例、用參證站的10場次洪率定出參數、移用到目標站上。結果中:峰量擬合的合格率為10%(改進方案為30%);洪水總量擬合的合格率為40%(改進方案為50%);峰現時刻誤差絕對值的平均值為5.7 h(改進方案為2);確定性系數的平均值小于0(改進方案為0.70)。
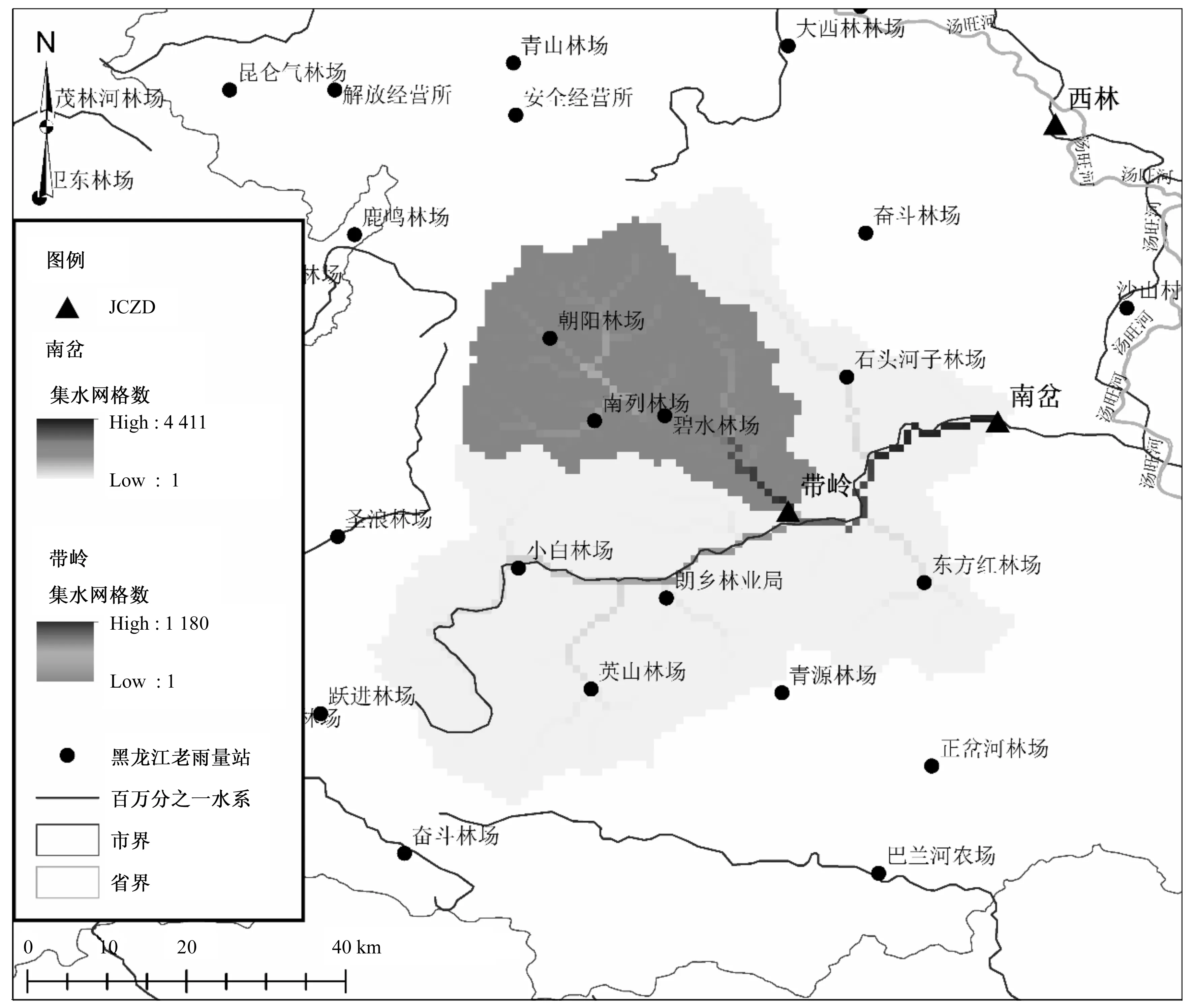
圖3 目標站和參證站柵格河網Fig.3 Raster river network of target area and reference station
發生日期計算洪峰/(m3·s-1)實測洪峰/(m3·s-1)峰量誤差/%計算洪量/萬m3實測洪量/m3洪量誤差/%峰現時刻絕對值/h201308128188503.74327003192.4412012072646172736.61151001573.8012014070545361726.604080047513.9832013063018334747.371120016535.3342009061817833246.303350050533.581200906096619766.2727006357.8192011052811217435.721040021952.311200908181531636.22161001573.1012012082817614521.1656003559.1422012061010812715.0622002924.341
對照試驗表明:相對于經典結構而言,改進匯流結構的新安江模型,參數外推后的擬合效果有了很大改善,尤其是峰量、峰現時刻和確定性系數的提高最為明顯。
5 結 語
本文學習分析了前人的研究結果,嘗試引入基于地形和流域特征的時段單位線方法、替換新安江模型的匯流結構,旨在提高模型在無資料地區的參數外推能力。
研究虛擬了一個無實測徑流資料的目標站,利用選擇無資料地區相似流域時使用較為廣泛的灰色關聯度分析方法確定了用于率定參數的參證站,避免了站點選擇上的人為偏好;利用參證站的10場次洪率定了模型參數,利用率定好的參數和目標站的實測降水,模擬了目標站的10場次洪,并與目標站的實測洪水過程比較。結果表明,搭配新匯流結構的新安江模型,其參數在空間上具備一定的外推能力。
研究利用經典的新安江模型,重復了上述步驟,結果表明:擁有新匯流結構的新安江模型,參數外推之后在洪峰和過程模擬上表現更好。
本文選擇的參證站和目標站,同屬黑龍江省湯旺河上的南岔河流域且是上下游嵌套關系,兩站的洪水過程線本身具備一定的關聯性,這應該是本次參數移用實驗能夠成功的一個重要因素。在黑龍江及其他各省中小河流預警預報建設過程中,大量的新建站(相當于本文的目標站)需要做預報方案,這些站點與具備實測資料的老水文站(相當于本文的參 證站)差異更大,彼種條件下的參數外推還需要進一步深入研究。
□
[1] 談 戈,夏 軍,李 新.無資料地區水文預報研究的方法與出路[J]. 冰川凍土,2004,26(2):192-196.
[2] 周研來,郭生練,郭家力,等.VIC模型參數的地區分布規律及在無資料流域的移用[J]. 水資源研究,2012,1(3):56-63.
[3] 柴曉玲,郭生練,彭定志,等.IHACRES模型在無資料地區徑流模擬中的應用研究[J]. 水文,2006,26(2):31-33.
[4] 胡彩虹,郭生練,熊立華,等.TOPMODEL模型在無DEM資料地區的應用[J].人民黃河, 2005,27(6):23-25.
[5] 甘衍軍,李 蘭,楊夢斐.SCS模型在無資料地區產流計算中的應用[J].人民黃河, 2010,32(5):30-31.
[6] 姚 成,章玉霞,李致家,等.無資料地區水文模擬及相似性分析[J].河海大學學報(自然科學版),2012,41(2):109-113.
[7] 包為民.水文預報[M].北京:中國水利水電出版社,2009:143-167.
[8] 李 麗,郝振純.基于DEM的流域特征提取綜述[J].地球科學進展,2003,18(2):251-256.
[9] 李正最.參證流域灰色相似選擇[J].四川水利,1995,16(2):35-39.
[10] 郝振純,王加虎,李 麗,等.Channel Network Tool-Ⅰ的原理與功能[J]. 水文,2005,25(2):15-19.
[11] 唐運憶,欒成梅.SCE-UA算法在新安江模型及TOPMODEL參數優化應用中的研究[J].水文,2007,27(6):33-35.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
