基于混合模重構(gòu)的kNN回歸
2016-03-17 03:51:43龔永紅朱永華程德波
計(jì)算機(jī)應(yīng)用與軟件 2016年2期
龔永紅 宗 鳴 朱永華 程德波
1(廣西師范大學(xué)廣西多源信息挖掘與安全重點(diǎn)實(shí)驗(yàn)室 廣西 桂林 541004)
2(桂林航天工業(yè)學(xué)院圖書館 廣西 桂林 541004)
3(廣西師范大學(xué)計(jì)算機(jī)科學(xué)與信息工程學(xué)院 廣西 桂林 541004)
4(廣西大學(xué)計(jì)算機(jī)與電子信息學(xué)院 廣西 南寧 530004)
?
基于混合模重構(gòu)的kNN回歸
龔永紅1,2宗鳴1,3朱永華4程德波1,3
1(廣西師范大學(xué)廣西多源信息挖掘與安全重點(diǎn)實(shí)驗(yàn)室廣西 桂林 541004)
2(桂林航天工業(yè)學(xué)院圖書館廣西 桂林 541004)
3(廣西師范大學(xué)計(jì)算機(jī)科學(xué)與信息工程學(xué)院廣西 桂林 541004)
4(廣西大學(xué)計(jì)算機(jī)與電子信息學(xué)院廣西 南寧 530004)
摘要對(duì)于線性回歸中kNN(k-Nearest Neighbor)算法的k值固定問題和訓(xùn)練樣本中的噪聲問題,提出一種新的基于重構(gòu)的稀疏編碼方法。該方法用訓(xùn)練樣本重構(gòu)每一個(gè)測(cè)試樣本,重構(gòu)過程中,l1-范數(shù)被用來確保每個(gè)測(cè)試樣本被不同數(shù)目的訓(xùn)練樣本來預(yù)測(cè),以此解決kNN算法固定k值問題;l2,1-范數(shù)導(dǎo)致的整行稀疏被用來去除噪聲樣本,以避免數(shù)據(jù)集上的噪聲對(duì)重構(gòu)產(chǎn)生不利影響。實(shí)驗(yàn)在UCI數(shù)據(jù)集上顯示:新的改進(jìn)算法比原來的kNN算法在線性回歸中具有更好的預(yù)測(cè)效果。
關(guān)鍵詞線性回歸稀疏編碼重構(gòu)l1-范數(shù)l2,1-范數(shù)噪聲樣本
KNN REGRESSION BASED ON MIXED-NORM RECONSTRUCTION
Gong Yonghong1,2Zong Ming1,3Zhu Yonghua4Cheng Debo1,3
1(Guangxi Key Lab of Multi-source Information Mining and Security,Guangxi Normal University,Guilin 541004,Guangxi,China)2(Guilin University of Aerospace Technology Library,Guilin 541004,Guangxi,China)3(School of Computer Science and Information Technology,Guangxi Normal University,Guilin 541004,Guangxi,China)4(School of Computer,Electronics and Information,Guangxi University,Nanning 530004,Guangxi,China)
AbstractThis paper proposes a new reconstruction-based sparse coding method for solving the problem of k value fixing of k-NN in linear regression and the problem of noise in training samples. The method reconstructs every test sample using training sample. In reconstruction process,thel1-norm is used to ensure each test sample will be predicted by training sample in different numbers and thus to solve the problem of k-NN algorithm in fixingkvalue,and the entire row sparse incurred byl2,1-norm is used to remove noise samples so as to prevent the noise in dataset from adverse impact on the reconstruction. Experimental results on UCI datasets show that the new improved algorithm outperforms the previous k-NN regression method in terms of prediction effect.
KeywordsLinear regressionSparse codingReconstructionl1-norml2,1-normNoise sample
0引言
kNN算法是一種應(yīng)用廣泛的分類方法,它是最近鄰算法(NN算法)的推廣形式。NN算法最早是由Cover和Hart在1967年提出,最早用于分類的研究[1]。kNN算法也可用于回歸:對(duì)于一個(gè)測(cè)試樣本,在所有訓(xùn)練樣本中選取最接近它的k個(gè)樣本的均值來進(jìn)行預(yù)測(cè)。然而本文發(fā)現(xiàn)傳統(tǒng)的kNN算法對(duì)每一個(gè)測(cè)試樣本,都用同樣k個(gè)數(shù)目的訓(xùn)練樣本來進(jìn)行預(yù)測(cè),這在應(yīng)用中不合實(shí)際。
圖1所示一個(gè)數(shù)據(jù)集分布,三角形代表測(cè)試樣本,圓圈代表訓(xùn)練樣本,如設(shè)k=3,用kNN算法預(yù)測(cè)測(cè)試樣本,對(duì)于左邊的測(cè)試樣本,用最鄰近的三個(gè)訓(xùn)練樣本去預(yù)測(cè),這比較合理。但對(duì)于右邊的測(cè)試樣本,僅有兩個(gè)訓(xùn)練樣本離它比較近,另一個(gè)離得很遠(yuǎn),顯然用最鄰近的這三個(gè)訓(xùn)練樣本來預(yù)測(cè)測(cè)試樣本是不合理的,應(yīng)該根據(jù)實(shí)際情況,選取不同的k值。

圖1 k=3時(shí)兩個(gè)測(cè)試樣本
對(duì)此,一些學(xué)者展開了選取最優(yōu)k值的研究。例如Cora等人提出了自動(dòng)選取最優(yōu)k值的kNN方法[2]。Matthieu Kowalski在稀疏擴(kuò)展方法里引入了結(jié)構(gòu)化稀疏的概念[3],同時(shí)將這種方法與多層信號(hào)擴(kuò)展方法聯(lián)系起來,用來分解由許多不同成分構(gòu)成的信號(hào)。Hechenbichler等人提出了加權(quán)kNN法[4],該方法根據(jù)訓(xùn)練樣本到測(cè)試樣本距離的大小賦予不同的權(quán)值,距離大的權(quán)值反而小,該方法的分類識(shí)別率對(duì)k值的選取不再敏感。Zhang等人提出了代價(jià)敏感分類方法[5-8]。還有一些學(xué)者從特征加權(quán)的角度提出了一些算法,也在一定程度上改進(jìn)了kNN算法。
但是以上這些方法都是只利用了訓(xùn)練樣本中k個(gè)鄰近樣本提供的信息,沒有考慮測(cè)試樣本提供的信息,即沒有考慮訓(xùn)練樣本和測(cè)試樣本之間的相關(guān)性。而本文認(rèn)為樣本之間是存在相關(guān)性的,對(duì)于每個(gè)測(cè)試樣本,應(yīng)該用與之相關(guān)的訓(xùn)練樣本來對(duì)其進(jìn)行預(yù)測(cè),但是每一個(gè)測(cè)試樣本卻可能跟不同數(shù)目的訓(xùn)練樣本相關(guān)。為此,本文用訓(xùn)練樣本重構(gòu)[9]每一測(cè)試樣本獲得樣本之間的k相關(guān)性,同時(shí)用LASSO(the Least Absolute Shrinkage and Selection Operator)[10]來控制稀疏性以解決k值固定問題。另外實(shí)際數(shù)據(jù)集中一般會(huì)有噪聲存在[11,12],如在圖1中設(shè)k=7,對(duì)于左邊的測(cè)試樣本,圖中左上角的噪聲樣本會(huì)影響其真實(shí)值的預(yù)測(cè),并應(yīng)該剔除這些噪聲樣本,本文借助l2,1-范數(shù)能產(chǎn)生整行為0的特性來去除噪聲。因此,針對(duì)kNN算法存在的這兩個(gè)問題,本文提出一種新的基于混合模[13]重構(gòu)的kNN算法—Mixed-Norm Reconstruction-kNN,簡(jiǎn)記為MNR-kNN。
1基于混合模重構(gòu)的kNN算法
1.1重構(gòu)
用訓(xùn)練樣本重構(gòu)每一測(cè)試樣本時(shí),本文假設(shè)有訓(xùn)練樣本空間X∈Rn×d,n為訓(xùn)練樣本數(shù)目,d為樣本維數(shù);測(cè)試樣本空間Y∈Rd×m,m為測(cè)試樣本數(shù)目。一般我們用最小二乘法[14,15]解決線性回歸問題,即獲取投影矩陣W∈Rn×m:

(1)
其中,‖·‖F(xiàn)是Frobenius矩陣范數(shù),yi∈Rd×1,wi是W的第i列向量。
分類問題中yi一般為類標(biāo)簽,W表示Y與X的函數(shù)關(guān)系,在本文yi表示第i個(gè)測(cè)試樣本,而W表示訓(xùn)練樣本和測(cè)試樣本經(jīng)過重構(gòu)得到的相關(guān)性系數(shù)矩陣。以下面例子進(jìn)一步說明W,假設(shè)有4個(gè)訓(xùn)練樣本,2個(gè)測(cè)試樣本,樣本屬性數(shù)目為3,此時(shí)Y-XTW為:
(2)
由XTW知W中元素Wij表示第i個(gè)訓(xùn)練樣本與第j個(gè)測(cè)試樣本之間的相關(guān)性大小,Wij>0時(shí)代表正相關(guān),Wij<0時(shí)代表負(fù)相關(guān),Wij=0時(shí)代表不相關(guān)。所以,W表示測(cè)試樣本與訓(xùn)練樣本之間的相關(guān)性矩陣,本文考慮訓(xùn)練樣本和測(cè)試樣本之間的相關(guān)性,利用重構(gòu)方法獲得了訓(xùn)練樣本與測(cè)試樣本之間的相關(guān)性大小。
1.2正則化
一般得到的W不是稀疏的,考慮到列向量Wj表示第j個(gè)測(cè)試樣本與所有訓(xùn)練樣本的相關(guān)性,如果列向量中有r個(gè)元素值不為0,其余為0,則預(yù)測(cè)時(shí)k相應(yīng)地取r,并用對(duì)應(yīng)的這r個(gè)訓(xùn)練樣本來預(yù)測(cè)測(cè)試樣本。這樣選取的k個(gè)訓(xùn)練樣本就是與測(cè)試樣本最相關(guān)的k個(gè)樣本,也就可以解決kNN算法中k值固定問題。
通常使用最小二乘損失函數(shù)求解線性回歸問題,即:

(3)
雖然上面目標(biāo)函數(shù)是凸的,易知其解W*=(XXT)-1XY。然而,實(shí)際應(yīng)用中XXT不一定可逆,為此,優(yōu)化函數(shù)式(3)被加上一正則化因子,即:
(4)


(5)
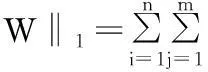
通過1.2節(jié)的方法可以求解目標(biāo)函數(shù)式(5)得到的W,如下形式:

其中,W的第二行全為0,即行稀疏。這是由于l2,1-范數(shù)導(dǎo)致的結(jié)果,這表明第二個(gè)訓(xùn)練樣本跟所有測(cè)試樣本無關(guān)。因此,第二個(gè)訓(xùn)練樣本可能是噪音樣本。此外第一列有兩個(gè)非零值,即第一個(gè)和第四個(gè),可以說第一個(gè)測(cè)試樣本與第一、第四個(gè)訓(xùn)練樣本相關(guān)。因此對(duì)第一個(gè)測(cè)試樣本預(yù)測(cè)時(shí)k=2。以此類推,如第二列有三個(gè)非零值,所以對(duì)第二個(gè)測(cè)試樣本而言k=3,對(duì)第四個(gè)測(cè)試樣本k=2。這就解決了kNN算法中k值固定問題,即對(duì)于不同測(cè)試樣本k值是不一樣的。而kNN算法中的k值通常由用戶決定,本文每個(gè)測(cè)試樣本的k值是通過稀疏學(xué)習(xí)得到的,是一種數(shù)據(jù)驅(qū)動(dòng)分析方法。
1.3MNR-kNN算法
根據(jù)以上例子,目標(biāo)函數(shù)式(5)利用l2,1-范數(shù)查找除了存在于訓(xùn)練集中的噪音樣本,而且還利用l1-范數(shù)學(xué)習(xí)出與每個(gè)測(cè)試樣本相關(guān)的訓(xùn)練樣本。每個(gè)測(cè)試樣本相關(guān)的訓(xùn)練樣本的個(gè)數(shù)不同,即為kNN回歸學(xué)習(xí)出了合適的k。這樣的學(xué)習(xí)方法是數(shù)據(jù)驅(qū)動(dòng)的,也解決了本文提出kNN回歸存在的兩個(gè)問題,即噪音樣本避免問題和固定k值問題。
本文預(yù)測(cè)測(cè)試樣本時(shí)用W列的非零值對(duì)應(yīng)的訓(xùn)練樣本去預(yù)測(cè),當(dāng)然此時(shí)k的取值等于W相應(yīng)列非零值的個(gè)數(shù),這種方法本文稱為不加權(quán)MNR-kNN算法。但是考慮到W中的元素值大小表示測(cè)試樣本和訓(xùn)練樣本的相關(guān)性大小,相應(yīng)的訓(xùn)練樣本和測(cè)試樣本之間的相關(guān)度大小是不同的,元素值越大,表明相關(guān)度越大;元素值越小,表明相關(guān)度越小。因此本文預(yù)測(cè)時(shí)根據(jù)Wj中的元素值對(duì)相應(yīng)的訓(xùn)練樣本做加權(quán)處理,可以得出第j個(gè)測(cè)試樣本的加權(quán)預(yù)測(cè)值:
(6)
其中,ytrain(i)表示第i個(gè)訓(xùn)練樣本的真實(shí)值,即第i個(gè)訓(xùn)練樣本的類標(biāo)號(hào)。這種回歸方法本文稱為加權(quán)MNR-kNN算法。
最后,本文給出加權(quán)/不加權(quán)MNR-kNN算法的步驟,見算法1。

算法1 加權(quán)/不加權(quán)MNR—kNN輸入:樣本數(shù)據(jù)輸出:預(yù)測(cè)值1)將數(shù)據(jù)進(jìn)行規(guī)范化處理2)通過算法2(下面給出)得到最優(yōu)解W3)加權(quán)/不加權(quán)情況下MNR-kNN算法對(duì)所有測(cè) 試樣本計(jì)算出相應(yīng)的k值4)根據(jù)k值,通過式(6)計(jì)算測(cè)試樣本的預(yù)測(cè) 值(注:不加權(quán)的情況相應(yīng)的用1代替W中的 非零值即可)
2算法優(yōu)化分析
雖然式(5)是凸的,但后面兩項(xiàng)正則化都是非光滑的。為此,本文提出一種有效的算法去求解目標(biāo)函數(shù)。
具體地,首先對(duì)wi(1≤i≤m)求導(dǎo)并命其為0,可得:
(7)

(8)
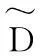

算法2:目標(biāo)函數(shù)優(yōu)化算法輸入:X,Y輸出:W(t)∈Rn×m1)初始化W1∈Rn×m,t=1;2) do{(1)計(jì)算對(duì)角矩陣D(t)i(1≤i≤m)和D~(t),其中D(t)i第k個(gè)對(duì)角元素為12|w(t)ki|,D~(t)第k個(gè)對(duì)角元素為12‖(w(t))k‖2;(2)For每個(gè)i(1≤i≤m), w(t+1)i=(XXT+ρ1D(t)i+ρ2D~(t))-1Xy(i);(3)t=t+1;}until收斂
定理1算法2在每次迭代中目標(biāo)值減小。
證明根據(jù)算法里的第2步可得到:
(9)
因此有:
Tr(XTW(t+1)-Y)T(XTW(t+1)-Y)+
≤Tr(XTW(t)-Y)T(XTW(t)-Y)+
?Tr(XTW(t+1)-Y)T(XTW(t+1)-Y)+
≤Tr(XTW(t)-Y)T(XTW(t)-Y)+




3實(shí)驗(yàn)結(jié)果與分析
實(shí)驗(yàn)數(shù)據(jù)來自UCI機(jī)器學(xué)習(xí)庫[18],具體細(xì)節(jié)見表1。

表1 數(shù)據(jù)集基本情況
本次實(shí)驗(yàn)主要是比較kNN算法、不加權(quán)MNR-kNN算法和加權(quán)MNR-kNN算法這三種算法的預(yù)測(cè)效果,本文選用經(jīng)典評(píng)價(jià)指標(biāo)RMSE和相關(guān)系數(shù)CorrCoef。RMSE和CorrCoef定義分別如下:
(10)
(11)
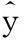
RMSE一般用來作為算法效果的評(píng)判依據(jù),通常RMSE越小,預(yù)測(cè)值和真實(shí)值之間的偏差就越小,算法的效果也就越好,否則越差。CorrCoef表示預(yù)測(cè)值和真實(shí)值之間的相關(guān)性大小,一般相關(guān)性越大,預(yù)測(cè)越準(zhǔn)確,反之相反。另外本文用Matlab編程實(shí)現(xiàn)具體程序代碼,在每個(gè)數(shù)據(jù)集上用10折交叉驗(yàn)證法做十次實(shí)驗(yàn)來看算法效果。為了保證公平性,kNN算法、不加權(quán)MNR-kNN算法和加權(quán)MNR-kNN算法在每一次實(shí)驗(yàn)中選用相同的訓(xùn)練集和測(cè)試集,記錄這三種算法十次實(shí)驗(yàn)取得的RMSE和CorrCoef情況。
圖2—圖5為四個(gè)數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果,縱坐標(biāo)為RMSE的大小,橫坐標(biāo)為十次實(shí)驗(yàn)次序。
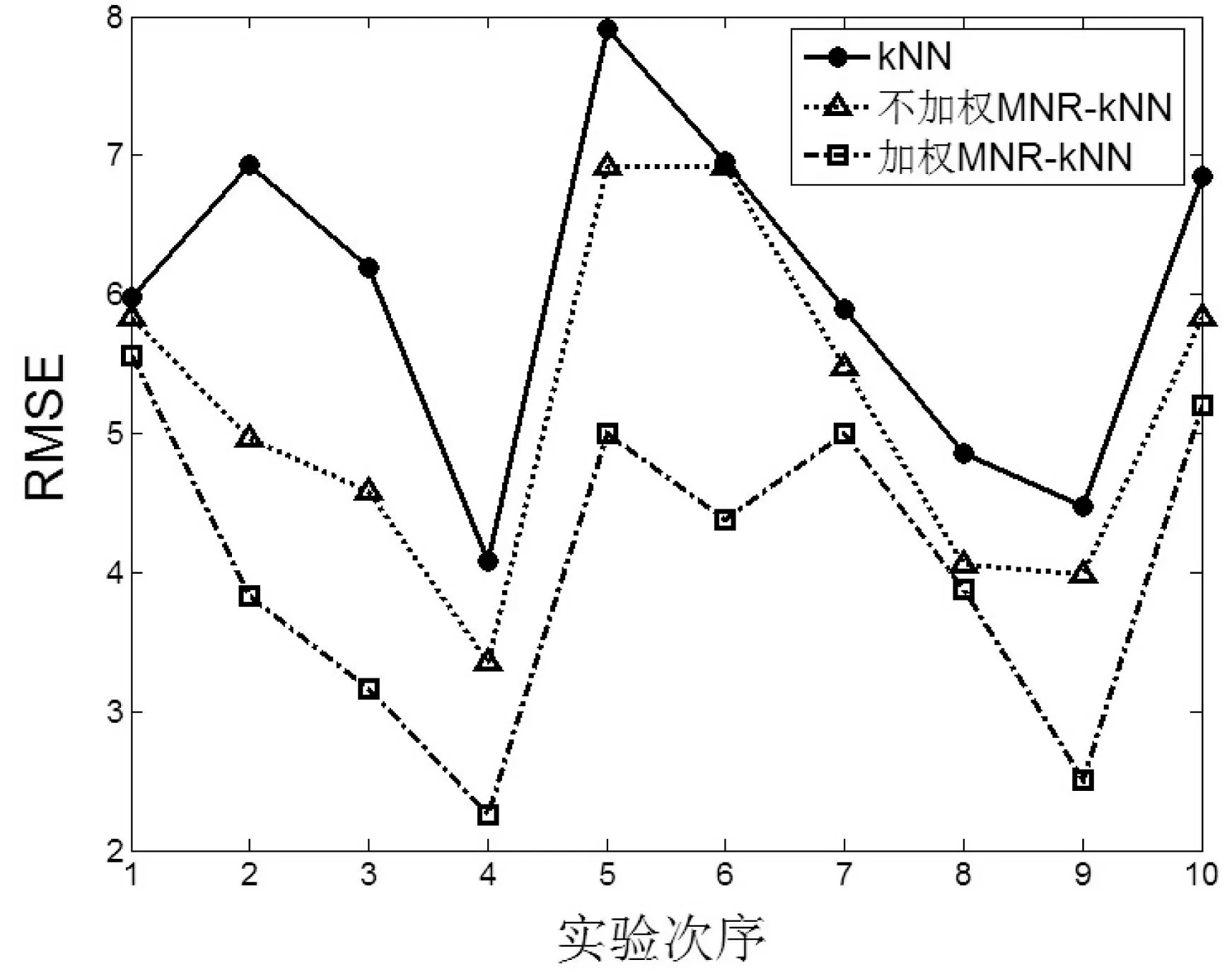
圖2 數(shù)據(jù)集ConcreteSlump
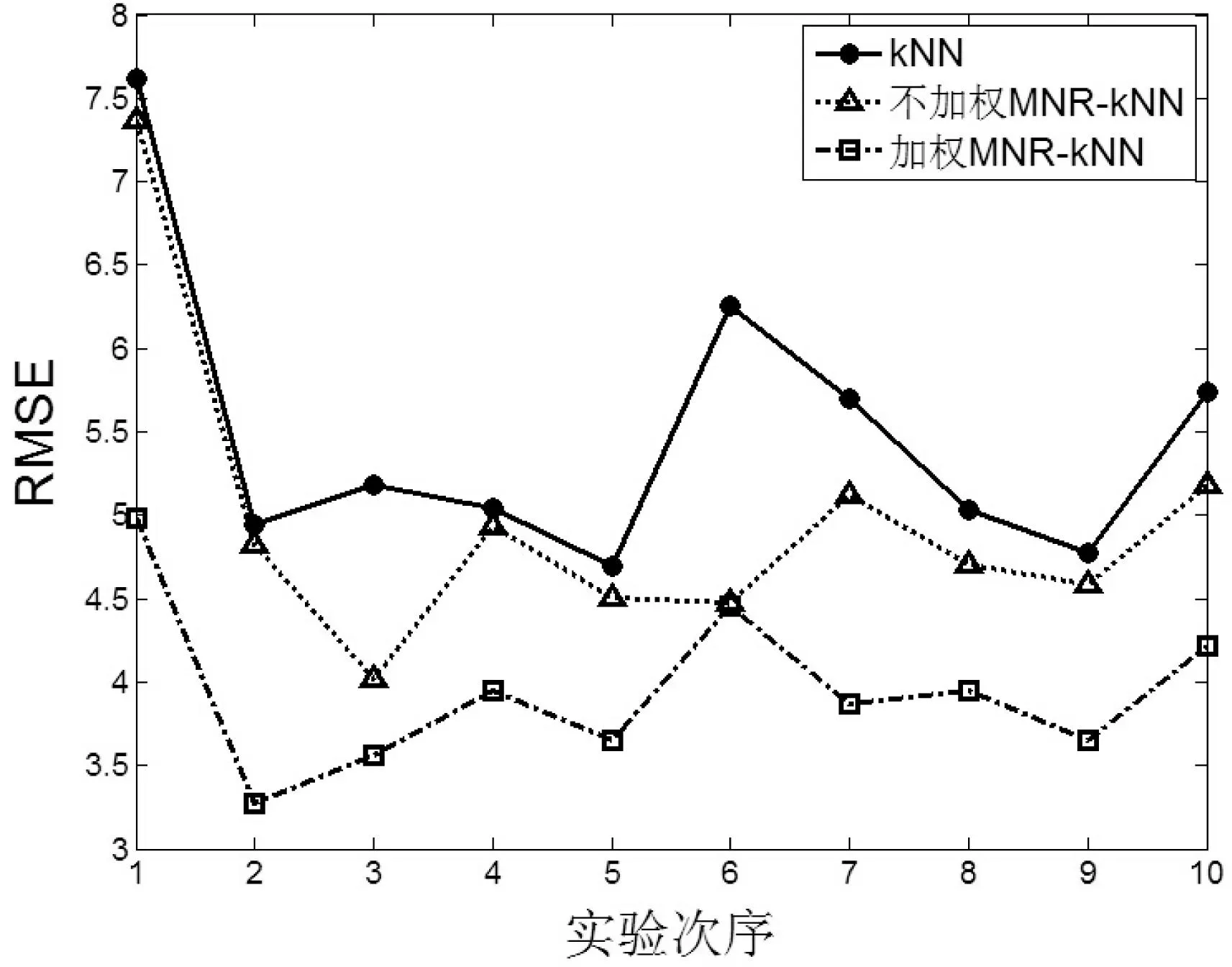
圖3 數(shù)據(jù)集Housing
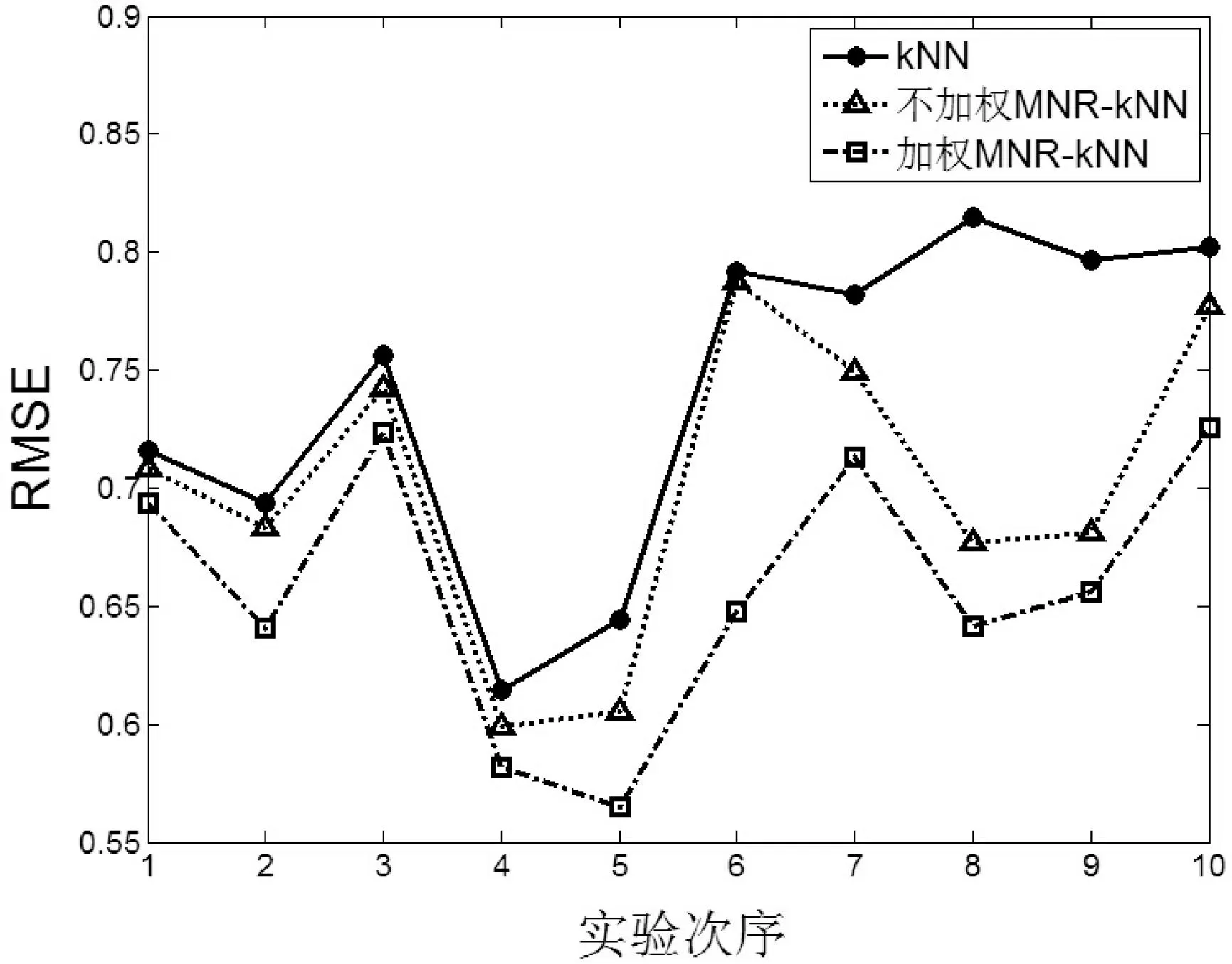
圖4 數(shù)據(jù)集Winequailty

圖5 數(shù)據(jù)集Mpg
圖6—圖9為四個(gè)數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果,縱坐標(biāo)為CorrCoef的大小,橫坐標(biāo)為十次實(shí)驗(yàn)次序。

圖6 數(shù)據(jù)集ConcreteSlump

圖7 數(shù)據(jù)集Housing

圖8 數(shù)據(jù)集Winequailty

圖9 數(shù)據(jù)集Mpg
RMSE和CorrCoef的均值以及方差見表2和表3。

表2 RMSE均值和方差情況
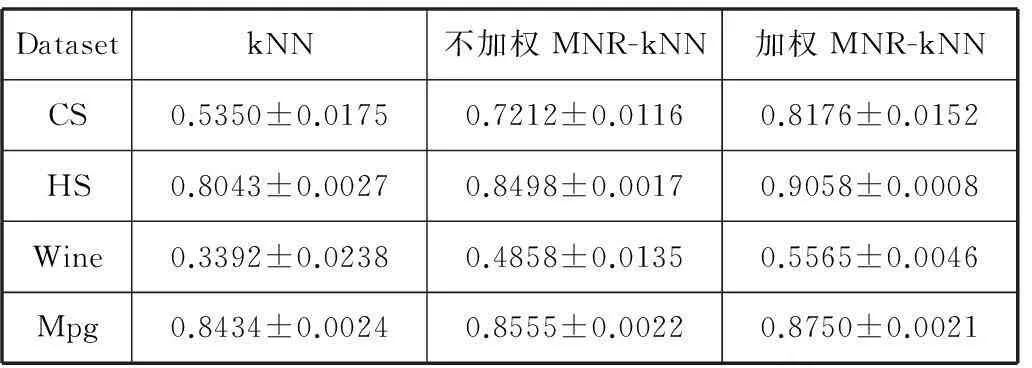
表3 CorrCoef均值和方差情況
圖2-圖9在四個(gè)UCI數(shù)據(jù)集上的實(shí)驗(yàn)顯示,對(duì)于評(píng)價(jià)指標(biāo)RMSE,加權(quán)MNR-kNN算法得出的RMSE均值最小,其次是不加權(quán)MNR-kNN算法,RMSE最大的是kNN算法。對(duì)于評(píng)價(jià)指標(biāo)CorrCoef,總體看來,加權(quán)MNR-kNN算法得出的CorrCoef均值最大,其次是不加權(quán)MNR-kNN算法,CorrCoef最大的是kNN算法。
根據(jù)表2,對(duì)于評(píng)價(jià)指標(biāo)RMSE,加權(quán)MNR-kNN算法取得的RMSE均值最小,其次分別是不加權(quán)MNR-kNN算法和kNN算法。最明顯的在CS數(shù)據(jù)集上,加權(quán)MNR-kNN算法比kNN算法在評(píng)價(jià)指標(biāo)RMSE均值上降低了1.936,同時(shí)不加權(quán)MNR-kNN算法也比kNN算法降低了0.8213。另外根據(jù)表3,加權(quán)MNR-kNN算法取得的相關(guān)系數(shù)均值最大,其次是不加權(quán)MMR-kNN算法和kNN算法。在CS數(shù)據(jù)集上的實(shí)驗(yàn)表明,加權(quán)MNR-kNN算法和不加權(quán)MNR-kNN算法比kNN算法在評(píng)價(jià)指標(biāo)上CorrCoef均值上分別提高了28.26%和18.62%,改善效果顯著。此外,從RMSE和CorrCoef方差總體情況來看,加權(quán)MNR-kNN算法方差最小,其次是不加權(quán)MMR-kNN算法和kNN算法。這說明本文提出的MNR-kNN算法比kNN算法算法更穩(wěn)定。
因此,綜合看來,加權(quán)MNR-kNN算法效果最好,其次是不加權(quán)MMR-kNN算法,效果最差的是kNN算法。這說明本文提出的MMR-kNN算法(包括加權(quán)和不加權(quán)兩種情況)預(yù)測(cè)準(zhǔn)確率更高,效果相比kNN算法也更好,同時(shí)加權(quán)MNR-kNN算法比不加權(quán)MNR-kNN算法要好。
4結(jié)語
針對(duì)kNN算法中k值固定不變問題以及如何在預(yù)測(cè)時(shí)去除噪聲樣本,本文提出了基于混合模重構(gòu)的kNN算法(MNR-kNN)。通過l1-范數(shù),MNR-kNN算法中k值根據(jù)樣本之間相關(guān)性情況取不同的值,同時(shí)在重構(gòu)過程中利用l2,1-范數(shù)去除噪聲。另外根據(jù)相關(guān)性大小可將MNR-kNN算法具體分加權(quán)情況和不加權(quán)情況。實(shí)驗(yàn)表明,在同樣的訓(xùn)練樣本和測(cè)試樣本情況下,使用三種算法進(jìn)行預(yù)測(cè),加權(quán)MNR-kNN算法效果最好,其次是不加權(quán)MNR-kNN算法,而kNN算法取得的效果不佳。
本文提出的MNR-kNN算法可以用于信號(hào)編碼和壓縮、降維去噪、人臉識(shí)別、文本挖掘等領(lǐng)域。將來可以進(jìn)一步考慮如何在實(shí)際應(yīng)用中降低MNR-kNN算法的時(shí)間復(fù)雜度,比如分塊處理等,以此來取得相應(yīng)的實(shí)際應(yīng)用價(jià)值。
參考文獻(xiàn)
[1] Qin Y S,Zhang S C,Zhang C Q. Combinining knn imputation and bootstrap calibreated:empirical likelihood for incomplete data analysis[J]. International Journal of Data Warehousing and Mining,2010,6(4):61-73.
[2] Cora G,Wojna A. A classifier combining rule induction and KNN method with automated selection of optimal neighbourhood[C]//Pr-oceedings of the 13rd European Conference on Machine Learning. London,UK: Springer-Verlag,2002:111-123.
[3] Matthieu Kowalski. Sparse regression using mixed norms[J]. Applied and Computational Harmonic Analysis, 2009,27(3):303-324.
[4] Hechenbichler K,Schliep K. Weighted k-nearest-neighbor techniques and ordinal classification,Discussion Paper 399[R]. Munich,Germ-any: Ludwing-Maximilians University Munich,2004.
[5] Wang T,Qin Z X,Zhang S C, et al. Cost-sensitive classification with inadequate labeled data[J]. Information Systems,2012,37(5):508-516.
[6] Zhang S C. Decision tree classifiers sensitive to heterogeneous costs[J]. Journal of Systems and Software,2012,85(4):771-779.
[7] Zhang S C. Cost-sensitive classification with respect to waiting cost[J]. Knowledge-Based Systems,2010,23(5):369-378.
[8] Zhu X,Zhang S,Zhang J,et al. Cost-sensitive imputing missing values ordering[J].Aaai Press,2007,2:1922-1923.
[9] 李長(zhǎng)彬,黃東,黎永壹.局部線性重構(gòu)分類算法研究[J].計(jì)算機(jī)應(yīng)用與軟件,2013,30(4):156-158,210.
[10] Zhu X F,Huang Z,Cheng H,et al. Sparse hashing for fast multi-media search[J]. ACM Transactions on Information System,2013,31(2):9.
[11] Zhang S C,Jin Z,Zhu X F. Missing data imputation by utilizing information within incomplete instances[J]. Journal of System and Software,2011,84(3):452-459.
[12] Zhu X F,Zhang S C,Jin Z,et al. Missing value estimation for mixed-attribute data sets[J]. IEEE Transactions on Knowledge and Engineering,2011,23(1):110-121.
[13] Zhu X F,Huang Z,Shen H T,et al. Dimensionality reduction by Mixed Kernel Canonical Correlation Analysis[J]. Pattern Recognition,2012,45(8):3003-3016.
[14] Zhu X F,Suk H,Shen D. A Novel Matrix-Similarity Based Loss Function for Joint Regression and Classification in AD Diagnosis[J]. NeuroImage,2014,100:91-105.
[15] Zhu X F,Huang Z,Shen H T,et al. Linear Cross-Modal Hashing for Effective Multimedia Search[C]//Proceedings of ACM M M,2013:143-152.
[16] Zhu X F,Huang Z,Yang Y,et al. Self-tau-ght dimensionality reduction on the high-dimensional small-sized data[J]. Pattern Recognition,2013,46(1):215-229.
[17] Zhu X F,Wu X D,Ding W,et al. Feature selection by joint graph sparse coding[C] // Proceedings of the 2013 Siam Intern-ational Conference on Data Mining,2013:803-811.
[18] UCI repository of machine learning datasets[DB/OL].[2012-01-15]. http://archive.ics.uci.edu/-ml/.
中圖分類號(hào)TP181
文獻(xiàn)標(biāo)識(shí)碼A
DOI:10.3969/j.issn.1000-386x.2016.02.054
收稿日期:2014-08-19。國家自然科學(xué)基金項(xiàng)目(61170131,61263035,61363009);國家高技術(shù)研究發(fā)展計(jì)劃項(xiàng)目(2012AA011005);國家重點(diǎn)基礎(chǔ)研究發(fā)展計(jì)劃項(xiàng)目(2013CB329404);廣西自然科學(xué)基金項(xiàng)目(2012GXNSFGA06004);廣西研究生教育創(chuàng)新計(jì)劃項(xiàng)目(YCSZ2015095,YCSZ2015096);廣西多源信息挖掘與安全重點(diǎn)實(shí)驗(yàn)室開放基金項(xiàng)目(MIMS13-08)。龔永紅,本科,主研領(lǐng)域:圖書情報(bào)學(xué),數(shù)據(jù)挖掘。宗鳴,碩士。朱永華,本科。程德波,碩士。
