基于變異系數(shù)的雙聚類算法及其在電信客戶細分的應(yīng)用研究
2016-03-17 03:51:43楊柏高
計算機應(yīng)用與軟件 2016年2期
林 勤 薛 云 楊柏高
1(廣東醫(yī)學(xué)院信息工程學(xué)院 廣東 東莞 523808)
2(華南師范大學(xué)物理與電信工程學(xué)院 廣東 廣州 510006)
?
基于變異系數(shù)的雙聚類算法及其在電信客戶細分的應(yīng)用研究
林勤1薛云2楊柏高2
1(廣東醫(yī)學(xué)院信息工程學(xué)院廣東 東莞 523808)
2(華南師范大學(xué)物理與電信工程學(xué)院廣東 廣州 510006)
摘要針對傳統(tǒng)客戶價值細分方法不夠精細化的問題,提出一種基于變異系數(shù)的雙聚類算法。該算法選用了變異系數(shù)作為相似性度量,運用啟發(fā)式貪心策略,通過迭代增刪行列的方式挖掘出客戶消費記錄中局部消費行為相似的客戶群體。以某電信公司的電信客戶細分為實例,將所提算法與K均值(K-means)算法進行性能比較,實驗結(jié)果表明,所提算法具有更優(yōu)的客戶細分能力和更強的客戶行為可解釋能力。因此,它更有助于指導(dǎo)企業(yè)制定差異化營銷策略。
關(guān)鍵詞變異系數(shù)客戶細分差異化營銷雙聚類K均值
ON VARIATION COEFFICIENT-BASED BICLUSTERING ALGORITHM AND ITS APPLICATION IN TELECOMMUNICATION CUSTOMER SEGMENTATION
Lin Qin1Xue Yun2Yang Baigao2
1(School of Information Engineering,Guangdong Medical College,Dongguan 523808,Guangdong,China)2(School of Physics and Telecommunication Engineering,South China Normal University,Guangzhou 510006,Guangdong,China)
AbstractTo improve the refinement degree of traditional customer value segmentation method, we proposed the variation coefficient-based biclustering algorithm. The algorithm selects the variation coefficient as the similarity measurement, applies the heuristic greedy strategy, and by the way of iterating the rows’ or columns’ insertion and deletion, the algorithm mines the customer groups with similar local consuming behaviours from their consumption records. Taking the telecommunication customers segmentation in a certain Telecom as the example, we compared the performances of the proposed algorithm with k-means clustering algorithm. Experimental result indicated that the proposed algorithm has better ability of customer segmentation and stronger interpretable ability on customer behaviours. Therefore, it is more conducive to guiding the enterprises to develop differentiated marketing strategies.
KeywordsVariation coefficientCustomer segmentationDifferentiated marketingBiclusteringK-means
0引言
近年來,隨著電信運營商網(wǎng)絡(luò)基礎(chǔ)設(shè)施間差距日益縮小,所涵蓋業(yè)務(wù)日趨同質(zhì),電信企業(yè)的發(fā)展模式逐步從以產(chǎn)品為中心的模式向以客戶為中心的模式轉(zhuǎn)變。精確識別和細分客戶市場,有助于電信企業(yè)合理配置企業(yè)資源,提高資源利用效率,降低運營成本;同時也有助于發(fā)現(xiàn)不同類別的客戶對服務(wù)的不同需求,為其提供個性化的服務(wù),從而使運營商和客戶價值發(fā)揮到最大,實現(xiàn)電信企業(yè)和客戶之間的雙贏。因此探究精細的數(shù)據(jù)挖掘方法對客戶進行細分是目前數(shù)據(jù)挖掘應(yīng)用的一個非常熱門且具有重要應(yīng)用價值的研究課題[1]。
文獻[2-5]相繼提出并完善了客戶生命周期價值CLV(Customer Lifetime Value)和客戶生命周期利潤CLP(Customer Lifetime Profit)的概念和計算模型,先篩選與客戶的當(dāng)前和潛在價值或者利潤相關(guān)的屬性,然后計算每一個客戶整個生命周期的凈利潤,最后運用閾值或者客戶價值矩陣對客戶進行細分。文獻[6-9]先根據(jù)RFM(Recency,Frequency,Monetary)模型或者其它的業(yè)務(wù)目標對消費數(shù)據(jù)進行屬性篩選,再分別運用粒子群優(yōu)化的模糊C均值聚類算法PSO-FCM(Particle Swarm Optimization- Fuzzy C-Means)、自組織映射聚類算法SOM(Self-Organization Mapping)、K均值(K-Means)聚類算法對客戶進行分群。文獻[10]指出了上述兩種方法的不足,并引入了一種專門從客戶的消費記錄中挖掘出高端消費客戶群體的大均值子矩陣LAS(Large Average Submatrices)雙聚類算法,該方法在很大程度解決了建模和傳統(tǒng)聚類方法存在的缺陷。然而,在現(xiàn)實應(yīng)用中客戶分群的目的并不僅僅限制于識別高價值客戶群體,很多時候還需要識別出具有一般性相似消費行為的客戶群體。
針對上述問題,本文提出了一種基于變異系數(shù)的雙聚類算法,該算法選用了一個用于衡量不同單位、平均值數(shù)據(jù)組之間離散程度的統(tǒng)計量——變異系數(shù)作為聚類的相似性度量,同時采用啟發(fā)式貪心策略,通過迭代增刪行列的方式在客戶消費記錄中挖掘出變異系數(shù)較小且規(guī)模較大的客戶群體。由于該算法所挖掘出來的客戶群體僅須在部分消費屬性的行為相似就可以聚集在一起。因此,類內(nèi)客戶與消費屬性間具有更高的關(guān)聯(lián)性,這也使得聚類結(jié)果的可解釋性大大提高。此外,本文還將該算法與成熟應(yīng)用于電信客戶細分的K-Means算法進行性能比較,結(jié)果表明該算法具有更高的聚類有效性和可解釋性。
1基本概念及定義
假設(shè)客戶的消費記錄可以看成一個m×n的實數(shù)矩陣A,矩陣的m行代表m個不同的客戶,n列代表n種不同的消費屬性。同時,定義實數(shù)陣A的行集X={x1,x2,…,xm},列集Y={y1,y2,…,yn}。雙聚類是實數(shù)陣A的一個k×l子矩陣U,表示為:U=(I,J),其中I={i1,i2,…,ik}是行集X的子集,J={j1,j2,…,jl}是列集Y的子集。
定義1變異系數(shù)假設(shè)實數(shù)矩陣U是實數(shù)陣A的一個k×l子矩陣,ui,j是矩陣U第i行第j列的元素。定義矩陣U的變異系數(shù)為矩陣U的方差除以均值,其數(shù)學(xué)表達式為:
(1)
變異系數(shù)是一個用來比較不同行子集、列子集以及尺寸的兩個或者多個子矩陣內(nèi)元素值分布變異程度的重要指標。值越小代表該子矩陣的元素值比其他子矩陣的元素值的分布越集中,這也間接地說明了該矩陣內(nèi)的客戶群體在各屬性上的消費行為更加地相似。
定義2容量閾值假設(shè)實數(shù)矩陣U是實數(shù)陣A的一個規(guī)模為k×l子矩陣,定義容量閾值α為子矩陣U的尺寸與實數(shù)矩陣A的尺寸的比值,其數(shù)學(xué)表達式為:
(2)
容量閾值是衡量雙聚類質(zhì)量的另一個很重要的標準。由于容量閾值小會使得子矩陣的變異系數(shù)變得很小,但是這樣的雙聚類質(zhì)量不高。所以在尋找雙聚類的過程中,除了考慮子矩陣的變異系數(shù),還要考慮容量閾值的大小。
定義3Action(x,U)動作采用FLOC算法[11]在迭代優(yōu)化雙聚類種子過程中把刪除或者增加一行或者一列操作都統(tǒng)一為動作Action(x,U)的定義。具體定義如下:在給定實數(shù)矩陣A的行(列)x與子矩陣U的情況下,如果行(列)x在子矩陣U中,那么動作Action(x,U)表示從子矩陣U中移除行(列) x;如果行(列)x不在子矩陣U中,那么動作Action(x,U)表示將行(列)x添加到子矩陣U中。
定義4動作序列operation在每次迭代優(yōu)化每個雙聚類種子過程中必須對所有行或者列都執(zhí)行Action(x,U)動作。采用FLOC算法[11]將所有Action(x,U)動作先后次序定義為動作序列。具體定義如下:對于任一給定的子矩陣U,其動作序列operation為一個大小為(m+n)的數(shù)組,數(shù)組里的每個元素代表著Action(x,U)動作所操作的某一行或者一列,動作序列operation主要用于存放動作執(zhí)行的先后次序。
2基于變異系數(shù)的雙聚類算法描述
2.1雙聚類算法
雙聚類(Biclustering)術(shù)語最早于2000年見于Cheng等人[12]的基因表達數(shù)據(jù)分析之中。傳統(tǒng)聚類要求同類基因必須滿足在所有條件下的表達行為都要相似。但是,通常情況下,一些基因只在某些條件下有著非常相似的表達行為,而在另一些條件下它們的表達行為不相似甚至毫不相干。對比傳統(tǒng)聚類,雙聚類算法可以對數(shù)據(jù)矩陣的行和列同時進行聚類,把一些只在部分屬性下有著相似性質(zhì)的對象聚在一起,在對對象進行聚類的同時也完成了對屬性的篩選,這使得它更容易處理數(shù)據(jù)中存在噪聲或缺失,以及確定屬性權(quán)重等問題。正因為這些優(yōu)點,除了生物信息領(lǐng)域,雙聚類算法的思想也很快被應(yīng)用于市場劃分[13]、文本挖掘[14]、協(xié)同過濾推薦系統(tǒng)[15]等領(lǐng)域。
2.2基于變異系數(shù)的雙聚類算法
算法的目的是在實數(shù)矩陣中挖掘出k個尺寸較大、變異系數(shù)較小的雙聚類。基本思想是首先隨機生成k個平均尺寸大于容量閾值的雙聚類種子;然后固定這些種子的行數(shù)和列數(shù),以行列交替抽樣的方式粗略優(yōu)化各個雙聚類種子;接著,順序執(zhí)行動作序列里對k個種子進行每個增或刪一行或一列的動作,每次動作只賦予使得變異系數(shù)下降得最快的雙聚類種子,不斷循環(huán)迭代直至k個雙聚類種子的平均尺寸小于容量閾值為止。最后,為了避免雙聚類的尺寸小有利于變異系數(shù)下降而造成以上迭代偏向于刪動作的情況,重復(fù)以上順序執(zhí)行動作序列中的增操作,每次操作只賦予使得變異系數(shù)下降得最快的雙聚類種子,不斷循環(huán)迭代直至k個雙聚類種子的平均變異系數(shù)值不再變化為止。
定理1動作序列operation里的某一動作Action(x,U)對所有的種子執(zhí)行操作后,該動作只賦予執(zhí)行后變異系數(shù)下降得最快的雙聚類種子,其他雙聚類種子不執(zhí)行該動作。假如該動作執(zhí)行后,所有雙聚類種子的變異系數(shù)都沒有下降,則所有雙聚類都不執(zhí)行該動作。
算法1基于變異系數(shù)的雙聚類算法
輸入:矩陣A, 聚類個數(shù)k,平均容量閾值threshold1,threshold2
輸出:k個滿足條件的聚類
初始化:隨機產(chǎn)生k個種子的行數(shù)和列數(shù),且k個種子的平均容量閾值不小于threshold1
方法:LCVS_SearchForBCs()
1) Bcseed = RoughOptimize( ) ;
//初略優(yōu)化種子,使得k個種子的變異系數(shù)不會太大,加速收斂
2) while(avg(Bcseed.size)/(m*n))> threshold2)//重復(fù)順序執(zhí)
//行動作序列里的動作,直到k個種子的平均容量閾值小于threshold2
3) 隨機產(chǎn)生一個大小為(m+n)的動作序列operation,用于存放行列操作順序;
4) for i = 1 to (m+n)
//順序執(zhí)行動作序列
5) for num = 1 to k//找出該動作執(zhí)行后變異系數(shù)下降最大的種
//子,將動作賦予該種子,其他保持不變
6) decv(num) = Action(operation(i, Bcseed(num));
//對第num個種子執(zhí)行動作,返回該種子執(zhí)行動作后變異系數(shù)下降量
7) decv(max) = max(decv);
//找出下降量最大的種子
8) 把該動作賦予序號為max的種子,修改其相應(yīng)的信息,其余種子保持不變
9) end for;
10) end for;
11) end while;
12) while(avg(currBcseed.cv) ~= avg(preBcseed.cv))
//重復(fù)順序執(zhí)行動作序列里的增一行或一列的動作,直到k個種子的平
//均變異系數(shù)不再變化為止
13) 重復(fù)3)到9)過程中增加一行或者一列過程,刪除的過程忽略。
總的來說,算法包括了三個階段。第一階段是步驟1),對k個種子進行了粗略地優(yōu)化,加快后面迭代的收斂速度;第二個階段是步驟2)到11),運用定理1對k個種子進行了自適應(yīng)地增或刪行列操作,同時控制平均的尺寸,使得k個種子的變異系數(shù)比較小,尺寸也不會太小;第三個階段是12)到13),由于變異系數(shù)值下降往往會傾向于刪除操作,為了避免第二階段過于側(cè)重刪操作,這個階段只執(zhí)行動作序列中的增操作。算法的全過程和第一階段的流程如圖1、圖2所示。

圖1 LCVS雙聚類算法總流程圖 圖2 粗略優(yōu)化種子的流程圖
3基于變異系數(shù)的雙聚類算法的應(yīng)用
3.1數(shù)據(jù)描述和預(yù)處理
本文實驗數(shù)據(jù)來源于第十屆亞太知識發(fā)現(xiàn)與數(shù)據(jù)挖掘國際會議提供的電信客戶數(shù)據(jù)。數(shù)據(jù)內(nèi)容包括月平均消費額、月平均通話時長、國際通話分鐘數(shù)等225個屬性。經(jīng)統(tǒng)計,該數(shù)據(jù)缺失數(shù)據(jù)多,數(shù)據(jù)取值范圍廣,數(shù)據(jù)取值類型多樣,本文通過數(shù)據(jù)清洗,選用了其中2 000條記錄,74個與消費相關(guān)的屬性。
由于算法是對子矩陣內(nèi)所有的消費屬性進行變異系數(shù)的計算,而各個消費屬性可能在單位或者平均數(shù)上存在差異。為了避免這些差異對算法性能的影響,本文將原始的消費記錄按照式(3)進行標準化處理:
(3)

3.2實驗結(jié)果分析
在實驗中,設(shè)置雙聚類算法的參數(shù)為:聚類個數(shù)k=6,平均容量閾值threshold1=0.05,threshold2=0.05。編程和運行的平臺是Matlab2010。算法運行的結(jié)果如表1所示。

表1 6個聚類的分群結(jié)果
首先,從整體分析。據(jù)表1可發(fā)現(xiàn)算法所挖掘出來的這6個類的變異系數(shù)都比較小,這說明各個客戶群體在各自類內(nèi)消費業(yè)務(wù)上的消費行為都很相似。同時,從各類分群的列數(shù)可以看出,對比于傳統(tǒng)的聚類算法,算法挖掘出來的客戶群體的消費屬性和客戶之間的關(guān)聯(lián)性、可解釋性更高。
其次,本文還細致地分析每個分群的典型特征,對各個分群進行描述,并根據(jù)各個分群的特點給出了相應(yīng)的服務(wù)方式和營銷策略的建議,具體如表2所示。由于篇幅關(guān)系,本文只對其中第5分群展開詳細地解析。
客戶分群5:客戶的人數(shù)是284,約占整體客戶的1/10,消費屬性是16個,類內(nèi)的客戶在各消費屬性的平均消費額與全體客戶在對應(yīng)屬性的平均消費額相比較高,倍數(shù)的范圍是2.3968~3.0833,其中比較核心的消費業(yè)務(wù)是近6個月平均移動通話分鐘數(shù)、近6個月國外平均忙時通話分鐘數(shù)、近6個月平均外部網(wǎng)通話次數(shù)、近6個月平均移動通話次數(shù)、近6個月平均主叫不同號碼數(shù)、近6個月平均國外通話次數(shù)。鑒于該類用戶的核心消費業(yè)務(wù)比較集中于外網(wǎng)、國外通話等商旅業(yè)務(wù)、消費額高、相對于其他5個客戶群體對企業(yè)整體的利潤貢獻最大,故可以將其定義于商旅型高價值客戶群體。可以采用重點維系的服務(wù)方式提高客戶的忠誠度和信任度。同時可以采取積極為其定制一些與商旅相關(guān)的個性化優(yōu)惠套餐、創(chuàng)新服務(wù)產(chǎn)品的營銷策略來達到提高服務(wù)質(zhì)量,提升企業(yè)的利潤。例如漫游優(yōu)惠套餐,國際通話優(yōu)惠套餐,飛機、酒店預(yù)訂優(yōu)惠等商旅創(chuàng)新產(chǎn)品等。
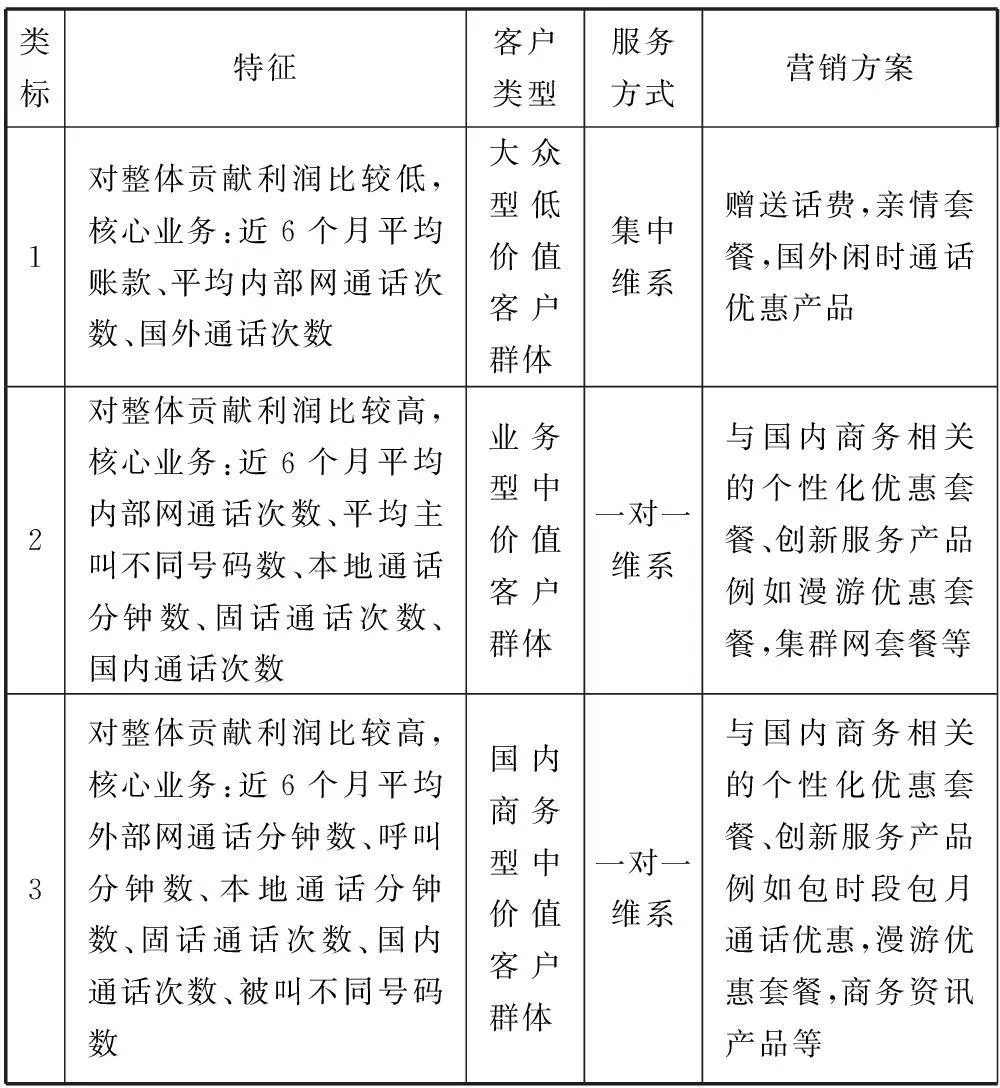
表2 6個雙聚類結(jié)果的分析和營銷方案

續(xù)表2
4聚類有效性驗證
為了進一步驗證基于變異系數(shù)的雙聚類算法的統(tǒng)計意義,本文將該算法與已經(jīng)成熟應(yīng)用于電信客戶細分的K-Means算法進行聚類有效性的比較。其中基于變異系數(shù)的雙聚類算法沿用以上的參數(shù)設(shè)置和實驗結(jié)果,K-Means算法的參數(shù)設(shè)置是聚類個數(shù)k為6個,迭代次數(shù)為100次,相似性度量選用歐氏距離,開始預(yù)分類選用隨機種子,編程和運行的平臺也選用Matlab2010。
采用文獻[10]提出的分離度,緊密度,PA指標來對兩個算法的有效性進行分析,具體公式如下所示:
定義5分離度V[10]定義各類中心與數(shù)據(jù)集中心點的距離平方(只挑選該雙聚類所涉及到的屬性來計算距離),再除以屬性數(shù)目之后的加權(quán)和為類間分離度,其數(shù)學(xué)表達式為:
(4)
其中,Ci指各類中心,C為數(shù)據(jù)中心,pi表示第i個聚類中屬性的個數(shù),NC表示類的數(shù)目。
V的值越大,說明聚類的結(jié)果類與類之間的差距越大,類與類之間的區(qū)分度越高。 反之,則說明聚類的結(jié)果類與類之間的差距越小,類與類之間的區(qū)分度越低。
定義6緊密度D[10]定義類中各點與類中心的最大距離平方和為類內(nèi)緊密度,其數(shù)學(xué)表達式為:
(5)
其中,x指各類內(nèi)的每個對象,Ci指各類中心。
D的值越大,說明聚類的結(jié)果各類類內(nèi)的對象越相似,反之則說明聚類的結(jié)果各類類內(nèi)的對象越相異。
定義7PA指標[10]定義分離度除以緊密度,再除以聚類數(shù)目為PA指標,其數(shù)學(xué)表達式為:
(6)
其中,Ci指各類中心,C為數(shù)據(jù)中心,pi表示第i個聚類中屬性的個數(shù),x指各類內(nèi)的每個對象,NC表示類的數(shù)目。
PA指標的值越大,說明聚類的結(jié)果類間的分離度越大,類內(nèi)的緊密度越小,聚類的綜合效果越好。反之則說明聚類的結(jié)果類間的分離度越小,類內(nèi)的緊密度越大,聚類的綜合效果越差。
所得的結(jié)果如表3所示。從表3可以看出基于變異系數(shù)的雙聚類算法所得結(jié)果的分離度V的值比K-Means算法大,緊密度D的值僅為K-Means算法的四分之一,PA指標接近K-Means算法的兩倍。這說明對比K-Means算法,該算法所得的結(jié)果類與類之間的區(qū)分度比較高,類內(nèi)的對象更加相似,聚類的綜合效果更好。

表3 K-means算法和基于變異系數(shù)的雙聚類算法的聚類有效性對比
5結(jié)語
目前電信行業(yè)正以前所未有的速度,成為發(fā)展最快的行業(yè)之一。但是同時,電信行業(yè)間的競爭也越趨加劇。精確地識別、細分客戶市場,有助于指導(dǎo)電信企業(yè)優(yōu)化資源配置,制定和設(shè)計個性化,差異化的創(chuàng)新產(chǎn)品,提升企業(yè)在行業(yè)中的競爭力。這已成為電信行業(yè)內(nèi)的一個共識。本文分析了傳統(tǒng)客戶細分方法存在的缺陷,并在此基礎(chǔ)上提出了一種基于變異系數(shù)的雙聚類方法,該方法在客戶樣本和消費屬性兩個維度上對消費記錄進行雙向聚類,可以挖掘出在部分消費屬性上行為比較相似的客戶群體。另外,結(jié)合某電信公司的客戶消費數(shù)據(jù),本文將該算法與K-Means算法進行聚類有效性的比較,實驗結(jié)果表明,該算法的聚類結(jié)果具有更好的客戶細分能力和更強的客戶行為可解釋能力,更有利于企業(yè)進一步實施差異化營銷。然而,由于現(xiàn)在電信客戶消費記錄急劇增長,當(dāng)面臨海量數(shù)據(jù)處理的時候,該算法還是會遇到單機內(nèi)存和計算能力不足的瓶頸。因此如何對該算法進行并行優(yōu)化設(shè)計,這將是后續(xù)亟待解決的問題。
參考文獻
[1] Hung S Y,Yen D C,Wang H Y.Applying datamining to tele-com churn management[J].Expert Systems with Applications,2006,31(3):515-524.
[2] Jackson B B.Build Customer Relationships That Last[J].Harvard Business Review,1985,63(10):120-128.
[3] Berger P D,Nasr N I.Customer lifetime value:marketing models and applications[J].Journal of interactive marketing,1998,12(1):17-30.
[4] 陳明亮.客戶保持與生命周期研究[D].西安:西安交通大學(xué),2001.
[5] 齊佳音.企業(yè)客戶價值研究[D].西安:西安交通大學(xué),2002.
[6] 張煥國,呂莎,李瑋.C均值算法的電信客戶細分研究[J].計算機仿真,2011,28(6):185-188.
[7] D Urso P,De Giovanni L.Temporal self-organizing maps for telecommunications market segmentation[J].Neurocomputing,2008,71(13):2880-2892.
[8] Ye L,Qiuru C,Haixu X,et al.Telecom customer segmentation with K-means clustering[C]//Computer Science & Education (ICCSE),2012 7th International Conference on IEEE.Melbourne.VIC:IEEE Computer Society,2012:648-651.
[9] 曾小青,徐秦,張丹,等.基于消費數(shù)據(jù)挖掘的多指標客戶細分新方法[J].計算機應(yīng)用研究,2013,30(10):2944-2947.
[10] 林勤,薛云.一種雙聚類算法在電信高價值客戶細分的應(yīng)用研究[J].計算機應(yīng)用,2014,34(6):1807-1811.
[11] Jiong Yang,Wei Wang,Haixun Wang,et al.Enhanced Biclustering on Expression Data[C]//Proceedings of the 3rd IEEE Conference on Bioinformatics and Bioengineering.Maryland:IEEE Computer Society,2003:321-327.
[12] Cheng Yizong,George M Church.Biclustering of expression data[C]//Proceeding of the 8th International Conference on Intelligent Systems for Molecular Biology.New York:ACM press,2000:93-103.
[13] Dhillon L S.Co-Clustering Documents and Words Using Bipartite Spectral Graph Partitioning[C]//Proceeding of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.San Francisco:ACM press.2001:269-274.
[14] Banerjee A,Dhillon L,Ghosh J,et al.A Generalized Maximum Entropy Approach to Bregman Co-clustering and Matrix Approximation[J].Journal of Machine Learning Research,2007,8(12):509-514.
[15] Su X,Khoshgoftaar T M.A Survey of Collaborative Filtering Techniques[J].Advances in Artificial Intelligence,2009(4):1-19.
中圖分類號TP391
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.02.052
收稿日期:2014-06-23。國家自然科學(xué)基金項目(71102146);廣東醫(yī)學(xué)院面上基金項目(XK1330);廣東醫(yī)學(xué)院青年基金項目(XQ1224)。林勤,助理實驗師,主研領(lǐng)域:數(shù)據(jù)挖掘,并行計算。薛云,副教授。楊柏高,本科。
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
小學(xué)生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學(xué)低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學(xué)一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
山東青年(2016年1期)2016-02-28 14:25:25
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 20:56:37
當(dāng)代修辭學(xué)(2014年3期)2014-01-21 02:30:44
