基于模糊理論的高血壓藥物療效預測模型研究
2016-03-17 03:57:14曹小鳳謝紅薇安建成郝曉燕
計算機應用與軟件 2016年2期
曹小鳳 謝紅薇 安建成 郝曉燕 曹 杰
(太原理工大學計算機科學與技術學院 山西 太原 030024)
?
基于模糊理論的高血壓藥物療效預測模型研究
曹小鳳謝紅薇*安建成郝曉燕曹杰
(太原理工大學計算機科學與技術學院山西 太原 030024)
摘要針對評估期內藥物占有率MPR(Medication Possession Ratio)和血壓進行分析研究,建立用于發現二者關系的貝塔分布模型。利用模糊理論和遺傳算法通過交叉驗證對模型進行優化并與線性分布模型進行對比。實驗結果表明,利用貝塔分布模型確定的MPR與血壓值的關系能很好地對患者的用藥療效進行預測。對于大多數高血壓患者,只有接受長期的藥物治療,才能使血壓得到有效控制。
關鍵詞高血壓貝塔分布模型遺傳算法交叉驗證模糊理論
ON PREDICTION MODEL OF HYPERTENSION DRUGS EFFICACY BASED ON FUZZY THEORY
Cao XiaofengXie Hongwei*An JianchengHao XiaoyanCao Jie
(School of Computer College of Science and Technology,Taiyuan University of Technology,Taiyuan 030024,Shanxi,China)
AbstractAiming at the medication possession ratio (MPR) and blood pressure within evaluation period we carried out analysis and study, and built a beta distribution model for finding the relationship between them. Then we employed fuzzy theory, genetic algorithms (GA) and cross validation to optimise the model, and compared it with linear distribution model. Experimental results showed that the MPR and blood pressure value determined by using the beta distribution model can well forecast the meditation efficacy on patients. For most hypertensives, only by long-term treatment with medicine can the blood pressure be effectively controlled.
KeywordsHypertensionBeta distribution modelGenetic algorithmCross-validationFuzzy theory
0引言
2013年世界衛生日主題“控制你的血壓,減少心臟病突發和卒中風險”,可見高血壓已成為全球矚目的公共健康問題。高血壓是一種常見的威脅人類健康的慢性疾病,位居引起死亡的十大危險因素之首。因此,有效控制血壓對于提高人類的健康水平有重大現實意義。
《中國高血壓防治指南》[1]指出,高血壓是可以控制的疾病,有效地控制血壓可以減少患者心腦血管及其他并發癥的發生,進而提高患者的生存質量。Laura等人[2]通過研究發現,在老年人中使用阿替洛爾這類降壓藥會增加中風的風險;趙艷平[3]通過對治療原發性高血壓的不同藥物療效進行分析,發現洛沙坦和非洛地平的聯合用藥降低血壓變異性更為明顯,患者預后更佳;林彩美[4]利用統計分析的方法,研究抗高血壓藥物對治療老年人高血壓的效果,實驗結果表明,卡托普利聯合硝苯地平藥物治療高血壓效果顯著、不良反應少、易耐受, 是治療老年人高血壓的安全有效用藥方法。進行藥物治療是控制高血壓的有效方式,通過對患者堅持服藥程度和血壓值進行分析。根據Thusitha等人提出的計算框架[5]從電子處方中計算出患者的MPR,進而建立二者之間的關系,利用遺傳算法對所建立的模型進行評估優化,最終得出患者服藥時間與血壓的模型圖。此模型的建立,不僅可以通過患者堅持服藥程度對其血壓趨勢進行預測,還可以給患者提供堅持用藥建議,對于高血壓慢性病的控制與治療有一定的指導意義。
1高血壓定義和狀態分類
在沒有使用降壓藥物的情況下,非同日測量3次血壓,收縮壓≥140 mmHg和(或)舒張壓≥90 mmHg,被診斷為高血壓;患者有既往高血壓史,且目前正在服用降壓藥物,雖然血壓低于140/90 mmHg,也被診斷為高血壓[1]。通過對文獻[6]進行研究與總結,現將使用的收縮壓SBP(Systolic Blood Pressure)及其狀態定義如表1所示。
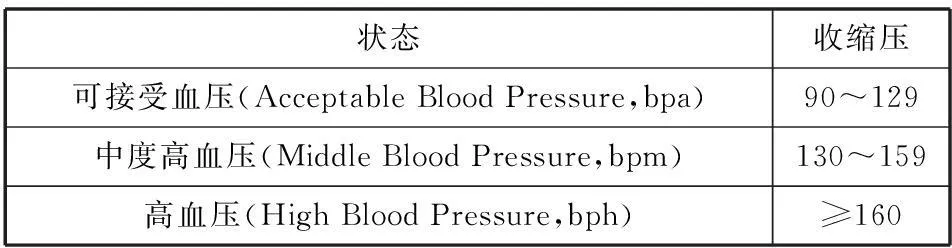
表1 收縮壓值與狀態對應關系 單位:mm Hg
2模型選擇
根據山西省某醫院提供的高血壓數據,通過研究發現,患者的收縮壓值和持續吃藥時間近似符合貝塔分布曲線。由于正態分布的曲線分布特點是以均數為中心,左右兩邊呈現對稱性并由均數處開始,分別向左右兩側呈逐漸均勻下降趨勢。而相比于正態分布,貝塔分布具有多種不同的分布形狀,其中包括對稱的和非對稱的分布,根據參數的不同呈現出完全不同的形狀,體現出良好的適應性和普適性。在此,選擇貝塔分布對數據進行研究分析。
2.1貝塔分布特點
貝塔分布的密度函數定義如下:
f(x;a,b)=xa-1(1-x)b-1/B(a,b)
(1)
2.2MPR值的計算
此處所研究的是患者持續吃藥時間與收縮壓的關系,由式(1)可知,該分布函數的自變量范圍為(0,1),因此,文中將持續吃藥時間轉換為MPR進行研究。MPR是計算有效藥物供給時間在一個評估期[5]EP內占有的比例。EP指從病人的電子處方記錄中選取感興趣的一段時期(此處選擇的是一年),根據Thusitha等人在文獻[5]中提出的一種方法[4]來計算藥物占有率,其計算如下:
(2)
3基于模糊規則的模型
Takagi 與 Sugeno(1985)和 Sugeno 與 Kang(1988)[7]給出了一個產生式規則系統的模糊推理工具。他們提出了一個多維模糊推理,該模糊模型是基于規則的[8,9],其輸出不是一個語言變量,而是輸入變量的函數。 規則庫由n條規則組成,規則的形式如下:

(3)

(4)
(5)
這里使用的“and”是在模糊系統中經常使用的運算。通常使用由Sugeno提供的模糊規則[10]得到復雜過程的輸出,其形式描述如下:
(6)
這樣,最終的輸出y可以按下式計算:
(7)
根據式(7),最終的輸出是由參數決定的復雜的非線性函數,參數的確定不能由傳統的方法得到。為了使用遺傳算法[11]確定式(7)的最優參數,必須建立適應度函數,表示如下:
(8)

4實驗過程及運行結果
4.1實驗過程
由于研究的是SBP與MPR之間的關系,根據前面的模型得出的數據值應該符合SBP的取值范圍。因此,需要對數據進行尺度變換,將模型得出的數據值模糊化為SBP值所符合的范圍,即是轉換為第一部分所列出的范圍。數據模糊化過程中用到的三個式子如下:
bph=u1/Maxu1×70+160
(9)
bpm=u2/Maxu2×30+130
(10)
bpa=u3/Maxu3×40+90
(11)
其中,ui是n維向量,其值是由式(2)計算出的MPR值根據初始的貝塔分布函數所確定的(初始貝塔分布的參數值說明如表2所示),Maxui是ui中的最大值,ui/Maxui表示相應規則(此處的規則是表1中所描述的3條規則)的隸屬度。通過式(10)-式(12)將相應的精確值分別模糊化為對應的規則區間。
根據山西某醫院提供的30 461條患者高血壓數據,經過數據清洗得到本實驗所使用的200條相關數據,將數據分成10組,每組20條數據,選取其中的8組作為訓練集,另外2組作為測試集。根據訓練集180條數據得到參數初值如表2所示。

表2 參數初值及種群初始范圍
實驗在MATLAB 7.0平臺下進行,根據表2的初值、范圍和適應度函數式(8),交叉概率Pc=0.8,變異概率Pm=0.05,利用遺傳算法對訓練集進行多次訓練得到參數的優化結果。表3給出了不同的訓練集得到的優化參數結果(由于篇幅有限,只列舉部分數據進行說明)。

表3 仿真算法得到的優化參數值
4.2參數對比
研究的最終目的是確定SBP與MPR的關系,每一個MPR值對應于三個屬于不同范圍的SBP值,也就是有三條不同的曲線。因此需要根據不同范圍的SBP值所對應的隸屬度對數據進行去模糊化處理,得到最終的輸出結果。對最終結果好壞的評價,通常用平均誤差來衡量,計算如下所示:
(12)
在對大量數據進行研究和實驗的基礎上,根據式(12)分別計算不同組的平均誤差如表4所示。

表4 4組模型對應的平均誤差
通過比較發現第4組所確定的模型所得到的平均誤差值最小,準確度最高;進行模糊化分段線性分布計算得到最終的RMSE為5.74473,相應的參數a4、b4、a5、b5、a6、b6值如表5所示。因此將第4組對應的模型作為我們的最佳預測模型,用于對持續吃藥時間和血壓值的預測。

表5 分段線性擬合的參數值
通過大量實驗得到表3-表5中的參數值,圖1-圖3分別是對得到的貝塔分布函數,分段線性分布函數及貝塔分布函數和分段線性分布函數的對比進行描述。

圖1 貝塔分布函數結果
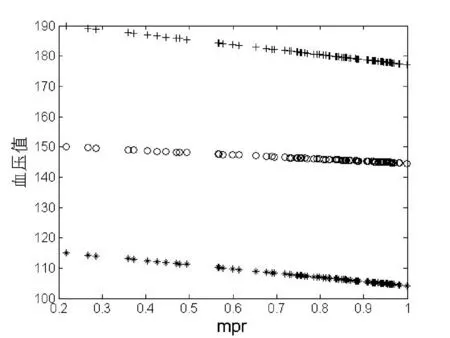
圖2 分段線性分布函數結果

圖3 分段線性分布函數和貝塔分布函數比較結果
經過實驗對比,確定圖1為最終的持續吃藥時間與血壓關系模型圖。由圖1的描述可以得到:當患者血壓水平處于90~130 mmHg時,患者持續服藥8個月,可以使血壓基本維持在較低水平;當患者血壓水平處于130~160 mmHg時,由于患者體質不同,服用的降壓藥的差別可能在短期內會使患者血壓有所上升,但服用半年后,這部分高血壓患者的血壓也可以維持在相對較低的水平;對于血壓水平處于160~230 mmHg的高血壓患者,在初期服用降壓藥的效果比較明顯,但是需要進行長期的藥物治療,才能使血壓維持在較低的水平。
5結語
通過對持續吃藥時間和血壓值的分析,建立用于預測二者關系的貝塔分布模型。與線性分布模型相比,該模型能夠很好地進行血壓趨勢分析,增強患者可持續服藥程度,更好地對血壓進行控制。在此研究的基礎上建立藥物、時間與血壓的模型,進而發現三者之間的關系對于指導患者用藥,對于提高患者生存質量有重大現實意義,建立相關的模型是下一步所要進行的工作。
參考文獻
[1] 劉力生,王文,姚崇華.中國高血壓防治指南(2010年基層版)[J].中華高血壓雜志,2011,18(1):11-18.
[2] Laura M Kuyper,MD Nadia A Khan,MD MSc.Atenolol vs Nonatenolol β-Blockers for the Treatment of Hypertension:A Meta-analysis[J].Canadian Journal of Cardiology,2014,30(5):S47-S53.
[3] 趙艷平.不同藥物治療原發性高血壓的療效分析與預后評價[J].醫藥論壇雜志,2012,33(7):96-97.
[4] 林彩美.卡托普利聯合硝苯地平藥物治療高血壓的臨床療效分析[J].中外醫療,2009,28(8):71.
[5] Thusitha Mabotuwana,Jim Warren,John Kennelly.A computational framework to identify patients with poor adherence to blood pressure lowering medication[J].International Journal of Medical Informatics,2009,78(11):745-756.
[6] 陳建華.國內外的高血壓診斷標準[J].中華實用中西醫雜志,2010,23(4):33-34.
[7] Jose Luis Aznarte,Jesus Alcala-Fdez,Antonio Arauzo-Azofra,et al.Financial time series forecasting with a bio-inspired fuzzy model[J].Expert Systems with Applications,2012,39(16):12302-12309.
[8] 張德豐.MATLAB模糊系統設計[M].北京:國防工業出版社,2009.
[9] Chen Chunhao,Hong Tzungpei,Tseng Vincent S.Fuzzy data mining for time-series data[J].Applied Soft Computing,2012,12(1):536-542.
[10] Chamani M R,Pourshahabi S,Sheikholeslam F.Fuzzy genetic algorithm approach for optimization of surge tanks[J].Scientis Iranica A,2013,20(2):278-285.
[11] 雷英杰.MATLAB遺傳算法工具箱及應用[M].西安:西安電子科技大學出版社,2005.
中圖分類號TP18
文獻標識碼A
DOI:10.3969/j.issn.1000-386x.2016.02.013
收稿日期:2014-08-25。山西省國際合作計劃項目(2014081018-2);山西省科技基礎條件平臺建設基金項目(2013091003-0103);山西省基礎研究基金項目(2012011011-2)。曹小鳳,碩士生,主研領域:人工智能,醫學信息學。謝紅薇,教授。安建成,副教授。郝曉燕,副教授。曹杰,碩士生。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
西部醫學(2021年10期)2021-10-28 08:25:50
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
基層中醫藥(2018年4期)2018-08-29 01:25:58
基層中醫藥(2018年6期)2018-08-29 01:20:14
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
