基于VSM和LDA模型相結合的新聞文本分類研究
2016-03-15 09:40:21彭雨龍
山東工業技術 2016年6期
摘 要:針對傳統KNN算法在處理新聞分類時僅僅考慮文字層面上的相似性,而未涉及語義層面,本文提出了一種基于VSM和LDA模型相融合的新聞分類算法。首先,在深入研究VSM和LDA模型的基礎上,對新聞文檔進行VSM和LDA主題建模,結合LDA模型與VSM模型計算文檔之間的相似度;其次,以復合相似度運用到基于相似度加權表決的KNN算法對新聞報道集合進行分類。實驗驗證了改進后的相似度計算方法的有效性,實驗結果表明改進后的KNN算法與傳統算法相比,具有較好的效果。
關鍵詞:潛在狄利克雷分布( LDA);向量空間模型(VSM);文本相似度;KNN分類
DOI:10.16640/j.cnki.37-1222/t.2016.06.192
1 引言
目前,面對著互聯網上各種各樣、數量繁多的新聞網頁,人們不知道如何選擇自己需要和喜愛的新聞。因此,人們越來越迫切地需要一個對新聞進行分類的工具,能夠用來快速瀏覽自己需要的新聞內容。
常見的文本分類技術包括KNN算法、貝葉斯算法、支持向量機SVM算法以及基于語義網絡的概念推理網算法等。KNN算法在新聞等網頁文本分類中有著廣泛的應用,他的思想是對于待分類的文本,通過由與該樣本最接近的K個樣本來判斷該樣本歸屬的類別[1]。
本文針對傳統KNN算法在度量文本相似性時僅僅考慮文字層面的相似性,而未涉及語義層面。首先,對新聞文檔進行VSM和LDA主題建模,結合LDA模型與VSM模型計算文檔之間的相似度;其次,以復合相似度運用到基于相似度加權表決的KNN算法對新聞報道集合進行分類。
2 相關工作
2.1 向量空間模型
向量空間模型(VSM:Vector Space Model)由G.Salton、A. Wong、 C. S. Yang[2]等人于20世紀70年代提出。向量空間模型(VSM)以特征詞作為文檔表示的基本單位,每個文檔都可以表示為一個n維空間向量:T(F1,W1;F2,W2;…;Fn,Wn),簡記為T(W1,W2,…,Wn),Fi為文檔的特征詞,Wi為每個特征詞的權重,則T(W1,W2,…,Wn)為文本T的向量表示[3]。特征詞的權重值一般采用TF*IDF來計算。
向量空間模型把文本內容用n維空間向量表示,把對文本內容的處理簡化為向量空間中的向量運算,并且它以空間上的相似度表達語義的相似度,直觀易懂,但向量空間模型并沒有考慮到特征詞之間的語義關系,可能丟失很多有用的文本信息。
2.2 LDA主題模型
2.2.1 LDA主題模型基本思想
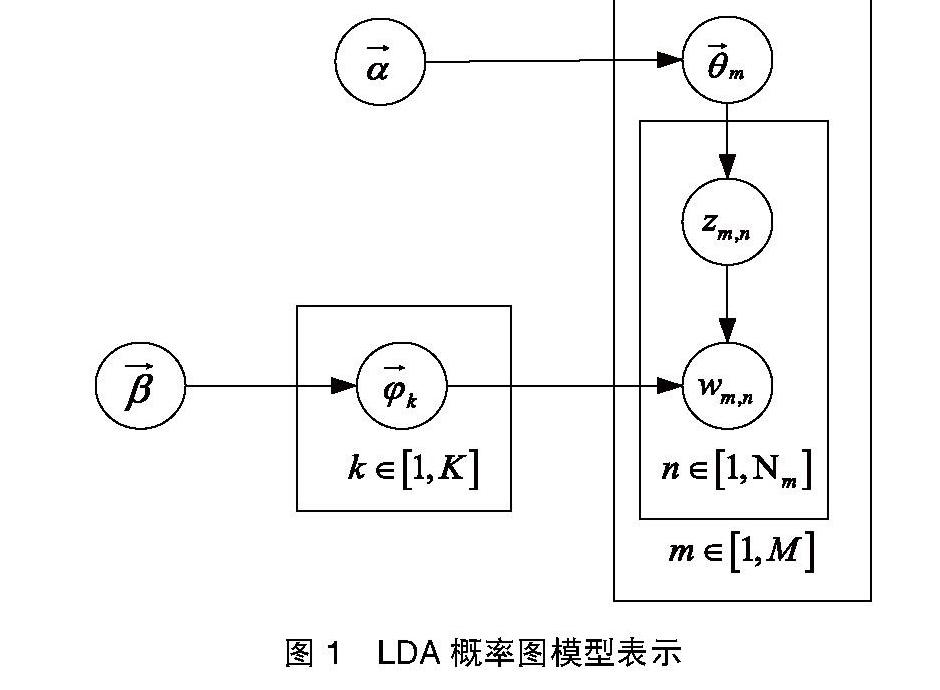
主題模型是統計模型的一種,用來發現在文檔集合中的抽象主題。LDA(Latent Dirichlet Allocation)是一種文檔主題生成模型,也稱為一個三層貝葉斯概率模型,包含詞、主題和文檔三層結構。首次是作為概率圖模型由David Blei、Andrew Ng和 Michael Jordan于2003年提出[4],圖1為LDA的概率圖模型。
其中M為文檔總數,K為主題個數,Nm是第m個文檔的單詞總數,β是每個Topic下詞的多項分布的Dirichlet先驗參數,α是每個文檔下Topic的多項分布的Dirichlet先驗參數。zm,n是第m個文檔中第n個詞的主題,wm,n是第m個文檔中的第n個詞。隱含變量θm和ψk分別表示第m個文檔下的Topic分布和第k個Topic下詞的分布,前者是k維(k為Topic總數)向量,后者是v維向量(v為詞典中詞項總數)。
2.2.2 Gibbs 抽樣
Gibbs Sampling是馬爾科夫鏈蒙特卡洛算法的一個實例。該算法每次選取概率向量的一個維度,給定其他維度的變量值采樣當前維度的值,不斷迭代至收斂輸出待估計的參數[5]。
從2.2.1中可知,zm,n、θm和ψk變量都是未知的隱含變量,也是我們需要根據觀察到的文檔集合中的詞來學習估計的。
學習步驟如下:
(1)應用貝葉斯統計理論中的標準方法[6],推理出有效信息P(w|T) ,確定最優主題數 T,使模型對語料庫數據中的有效信息擬合達到最佳。
(2)初始時為文本中的每個詞隨機分配主題Z(0),統計第z個主題下的詞項t的數量,以及第m篇文檔下出現主題z中的詞的數量。
(3)每一輪計算p(zi|z-I,d,w) 這里i=(m,n)是一個二維下標,對應于第m篇第n個詞,即排除當前詞的主題分配,根據其他所有詞的主題分配估計當前詞分配給各個主題的概率,根據這個概率分布,為該詞采樣一個新的主題Z(1)。同樣更新下一個詞的主題。直到每個文檔下Topic分布θm和每個Topic下詞的分布ψk收斂。
3 基于VSM和LDA模型的新聞分類
3.1 基于VSM和LDA模型的文本相似度計算
(1)對于文檔di,dj,由向量空間模型(VSM)進行預處理,得到的文本的特征詞向量di_VSM=(w1,w2,…,wN)和dj_VSM=( w1,w2,…,wN),N為特征詞個數。
3.2 基于VSM和LDA模型的新聞文本分類
本文改進的KNN算法的具體過程如下[8]:
輸入:待分類新聞文本d和已知類別的新聞文本D;
輸出:待分類新聞文本d的可能類別。
(1)對d和D集合進行預處理,構建其特征向量和主題向量;
(2)對d中的每個新聞文本,采用公式(3-3)計算其于D中每個新聞文本的相似度;
(3)從中選擇與d相似度最大的K個文本;
(4)對于待分類文本的K個鄰居,依次按公式(3-4)進行計算d隸屬每個類別的權重。
W(d)= ∑ Tj(di)* Sim(d,di) (3-4)
其中,y表示d的特征向量,Tj(di)表示指示函數,指示是否是同一類別,即di是否屬于Cj,若是,則值為1,否則為0。Sim(d,di)表示待分類文本與鄰居di的復合相似度。
(5)比較每個類的權重,將權重最大的類別定為d的類別。轉入(2)直至所有待分類文本分類完成。
4 實驗結果及分析
4.1 文本分類的性能評價
評價文本分類算法的有兩個指標:準確率(Precision)和召回率(Recall)。由于準確率和召回率是分別從兩個不同的方面來評價分類效果,所以一般采用F_measure來評估分類效果,如公式4-1。
4.2 文本分類實驗結果及分析
本實驗語料采用搜狗實驗室文本分類語料庫,選取軍事、體育、旅游、教育、娛樂、財經六個類別,每個類別下挑選200篇文章,總共1200篇,其中訓練集占1/3,首先,針對不同的K值下的分類效果找出最佳的K值,然后,對傳統KNN算法和基于相似度加權的KNN算法進行對比試驗。傳統的KNN算法的權重計算方法如公式4-2所示:
W(d)= ∑ Tj(di)* SimVSM(d,di) (SimVSM(d,di)為公式3-1所求)(4-2)
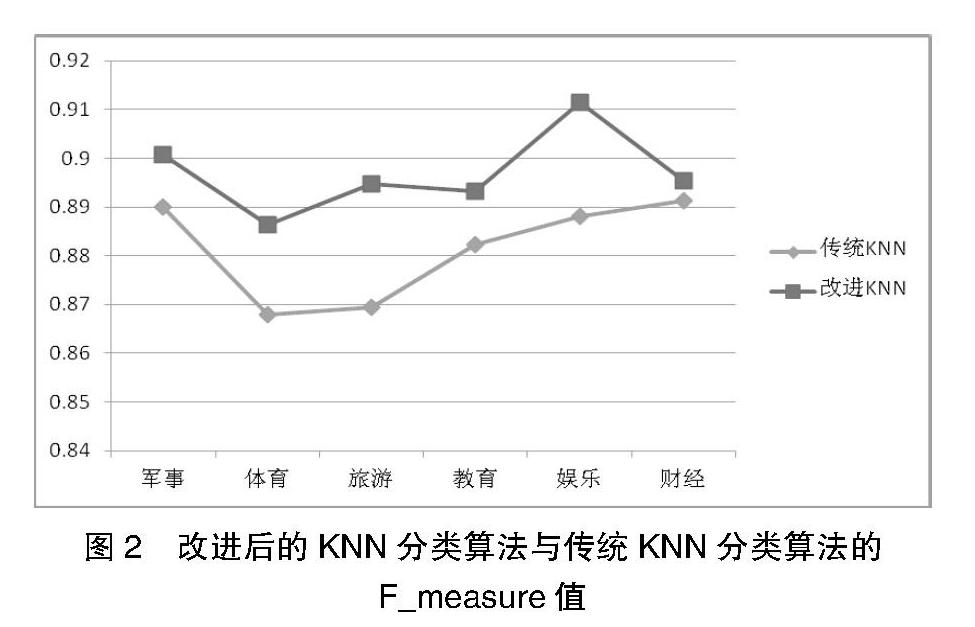
最終確定實驗的參數如下:KNN的K值取20,主題數K=30,Dirichlet先驗參數選取經驗值α=1,β=0.01,Gibbs抽樣次數設為5000; VSM和LDA模型線性結合參數λ設置為0.8,實驗效果如圖2所示。
從圖2中可以看出,改進后的KNN分類算法在軍事、體育、旅游、教育、娛樂、財經六個方面都較傳統KNN分類算法好一些,因為,傳統KNN算法只是單純第從文字層面來計算兩段文本之間的距離,而將VSM結合LDA模型后,既可以較完整地保留文本的信息,又可以提取語義層面的信息,這樣能更精確地計算兩段文本之間的相似度。
5 總結與展望
本文提出了基于VSM和LDA模型相結合的KNN分類算法,與傳統KNN分類算法相比,引進了LDA模型,從而在計算兩段文本之間的距離時融合了語義層面的相似度,在相似度計算方法上進行了改進,實驗也驗證了改進后算法的有效性。
由于當前所用的中文語料庫還有待完善,本文選用的搜狗實驗室文本語料庫,主題數較少,使得LDA主題模型的作用不太明顯,后續將考慮使用爬蟲程序從各大新聞網站上選取一些語料庫的來源。
參考文獻:
[1]張寧.使用 KNN 算法的文本分類[J].計算機工程,2005(04).
[2]G.Salton,A.Wong,C.S.Yang.A Vector Space Model for Automatic Indexing[J].Communications of the ACM: Volume 18 Issue 11,1975(11).
[3]王萌,何婷婷,姬東鴻,王曉榮.基于HowNet概念獲取的中文自動文摘[J].中文信息學報,2005,19(03):87-93.
[4]Blei D M, Ng A Y, Jordan M I.Latent dirichlet allocation[J].the Journal of machine Learning research, 2003(03):993-1022.
[5]趙愛華,劉培玉,鄭燕.基于LDA的新聞話題子話題劃分方法[J]. 小型微型計算機系統,2013(04).
[6]董婧靈,李芳,何婷婷.基于LDA模型的文本聚類研究[G].2011.
[7]王愛平,徐曉艷,國瑋瑋,李仿華.基于改進KNN算法的中文文本分類方法[J].微型機與應用,2011(18).
作者簡介:彭雨龍(1989-),男,湖南邵陽人,碩士研究生,研究方向:數據挖掘。
